

프로그래머의 고급 장: 해시 테이블의 기질

Zhang Yanpo 씨는 2016년에 Baishan Cloud Technology에 합류했으며 주로 개체 스토리지 연구 및 개발, 컴퓨터실 전체의 데이터 배포, 수리 및 문제 해결을 담당하고 있습니다. 그는 100PB 수준의 데이터 스토리지 달성을 목표로 팀을 이끌고 네트워크 전체 분산 스토리지 시스템의 설계, 구현 및 배포를 완료하고 "콜드" 데이터와 "핫" 데이터를 분리하여 콜드 데이터 비용을 1.2로 줄였습니다. 중복의 배.
Mr. Zhang Yanpo는 2006년부터 2015년까지 Sina에서 근무하며 아키텍처 설계, 협업 프로세스 공식화, 코드 사양 및 구현 표준 공식화, Cross-IDC PB 수준 클라우드 스토리지 서비스의 대부분 기능 구현을 담당했으며 Sina Weibo를 지원했습니다. 2015년부터 2016년까지 마이크로디스크, 비디오, SAE, 음악, 소프트웨어 다운로드 및 기타 Sina 내부 스토리지 사업을 담당한 그는 Meituan에서 수석 기술 전문가로 근무했으며 컴퓨터실 전반에 걸쳐 100PB 개체 스토리지 솔루션을 설계했습니다. 매우 안정적인 다중 복사본 복제 전략, 최적화된 삭제 코드로 IO 오버헤드를 90% 줄입니다.
소프트웨어 개발에서 해시 테이블은 b 단위 공간에 n 데이터를 저장하기 위해 n 키를 b 버킷에 무작위로 배치하는 것과 같습니다.
해시 테이블에서 몇 가지 흥미로운 현상을 발견했습니다.
해시 테이블의 키 분포 패턴
해시 테이블의 키와 버킷 수가 동일한 경우(n/b=1) :
37%의 버킷이 비어 있습니다
37%의 버킷에 키가 1개만 있습니다.
26%의 버킷에 키가 2개 이상 있습니다(해시 충돌)
다음 그림 n =b=20일 때 해시 테이블의 각 버킷에 있는 키 수를 직관적으로 표시합니다(키 수에 따라 버킷 정렬).
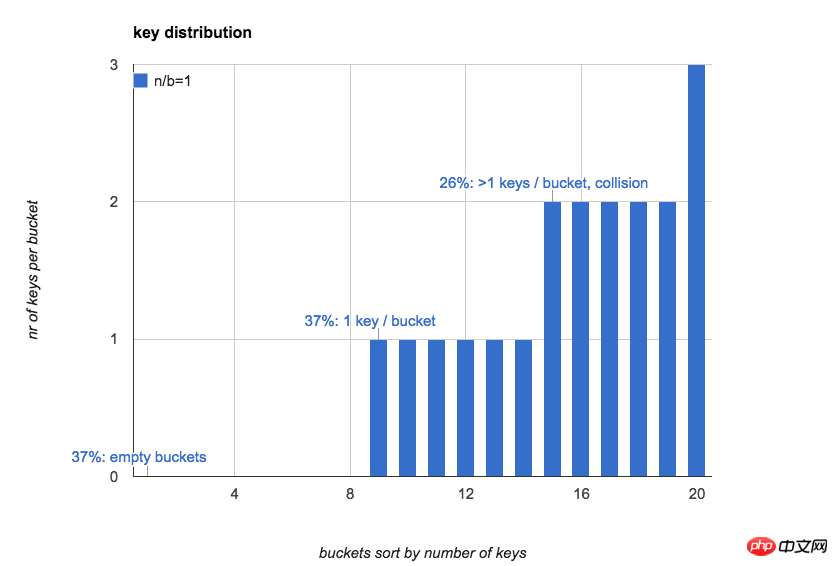
종종 해시 테이블에 대한 첫인상은 다음과 같습니다. 버킷의 키 개수는 비교적 균일하며 각 버킷의 예상 키 개수는 1개입니다.
실제로 n이 작을 때는 버킷의 키 분포가 매우 불균등합니다. n이 증가하면 점차 평균이 됩니다.
키 수가 유형 3의 버킷 수에 미치는 영향
다음 표는 b가 변경되지 않고 n이 증가할 때 n/b 값이 유형 3의 버킷 수에 어떤 영향을 미치는지 보여줍니다(충돌 rate에는 1개 이상의 버킷 비율이 포함되어 있음):
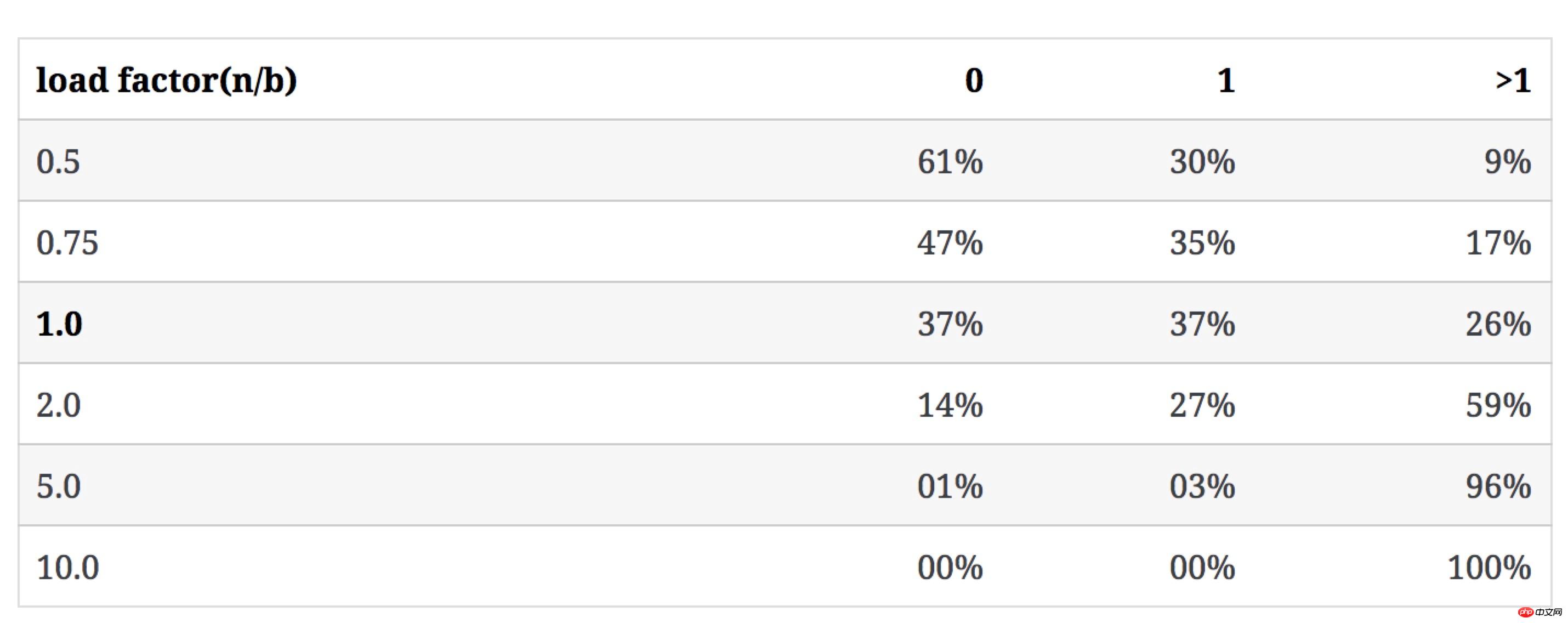
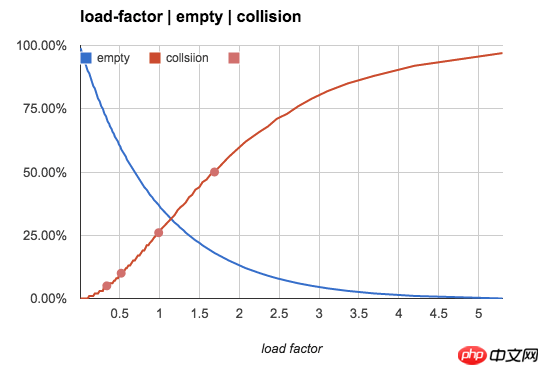
보다 직관적으로 다음 그림을 사용하여 빈 버킷 비율과 n/b 값에 따른 충돌 비율의 변화 추세를 보여줍니다.
버킷의 키 개수는 짝수 정도의 영향
위의 숫자 집합은 n/b가 작을 때 의미 있는 참고 값이지만 n/b가 점차 증가함에 따라 빈 버킷의 개수와 1- 키 버킷은 거의 0이며 대부분의 버킷에는 여러 키가 포함되어 있습니다.
n/b가 1을 초과하면(하나의 버킷에 여러 개의 키를 저장할 수 있음), 우리의 주요 관찰 개체는 버킷에 있는 키 수의 분포 패턴이 됩니다.
다음 표는 n/b가 크고 각 버킷의 키 수가 균일한 경향이 있을 때 불균일 정도를 보여줍니다.
불균일 정도를 설명하기 위해 버킷에 있는 키의 최대 개수와 최소 개수의 비율((최소)/가장)을 사용하여 표현합니다.
다음 표에는 b=100일 때 n이 증가함에 따라 키의 분포가 나열되어 있습니다.
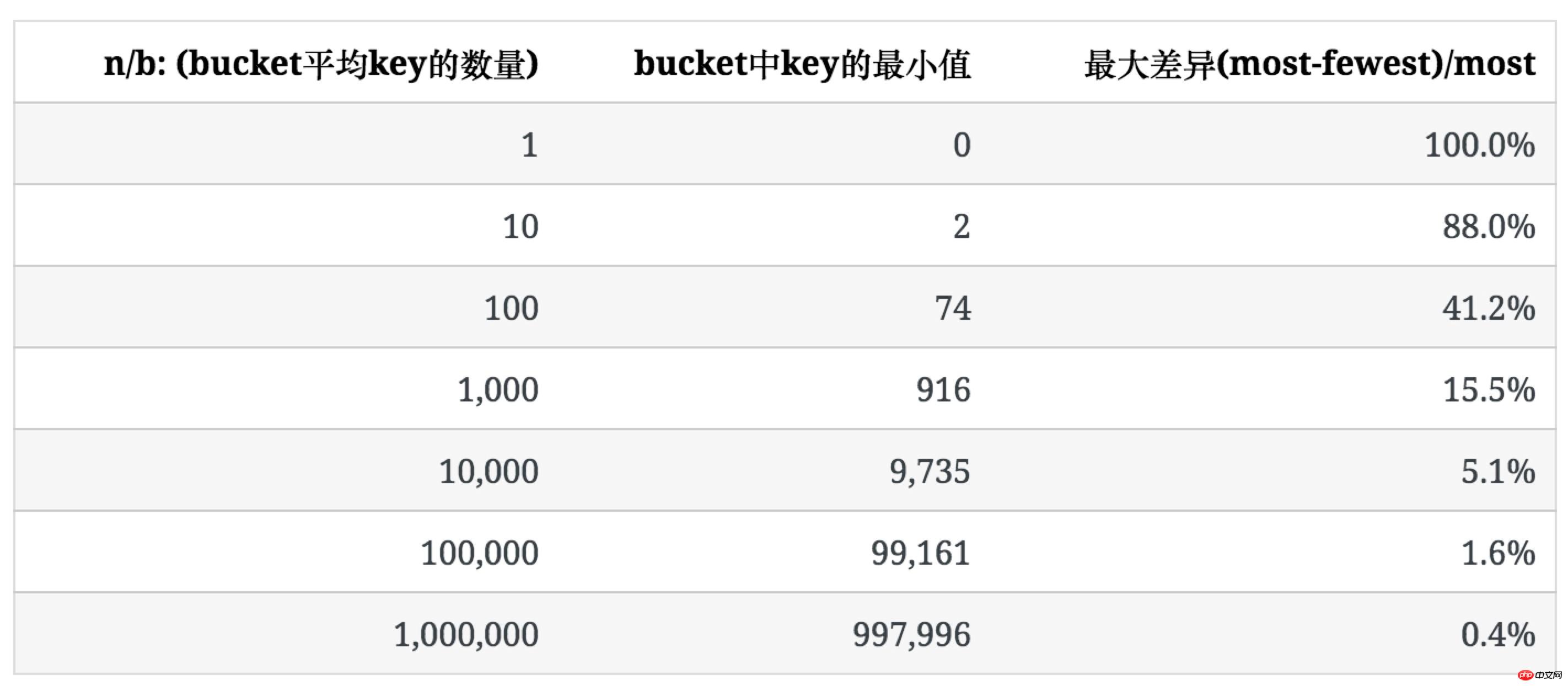
버킷의 평균 키 수가 증가함에 따라 분포의 불균일성이 점차 감소하는 것을 볼 수 있습니다.
1 2 3 |
|
로드 팩터: n/b
해시 테이블에서 일반적으로 사용되는 개념은 해시 테이블의 특성을 설명하기 위해 로드 팩터 α=n/b입니다.
보통 메모리 저장 해시 테이블 기준으로 n/b는 0.75 이하입니다. 이 설정은 공간을 절약할 뿐만 아니라 키 충돌률을 상대적으로 낮게 유지할 수 있습니다. 충돌률이 낮다는 것은 해시 재배치 빈도가 낮음을 의미하며 해시 테이블 삽입 속도가 빨라집니다.
1 |
|
n/b=0.75인 이 시나리오에서 선형 감지를 사용하지 않는 경우(예: 여러 키를 저장하기 위해 버킷에 연결된 목록을 사용하는 경우) 선형 감지를 사용하면 버킷의 약 47%가 비어 있습니다. 47%의 버킷 중 약 절반이 선형 감지로 채워집니다.
1 |
|
해시 테이블 자체는 효율성을 위해 일정량의 공간을 교환하는 알고리즘입니다. 낮은 시간 오버헤드(O(1)), 낮은 공간 낭비 및 낮은 충돌률을 동시에 달성할 수 없습니다.
해시 테이블은 순수 메모리 데이터 구조의 저장에만 적합합니다.
해시 테이블은 공간을 통과합니다. 액세스 속도를 높이기 위해 낭비를 교환합니다. 디스크 공간 낭비는 용납할 수 없지만 약간의 메모리 낭비는 허용됩니다.
해시 테이블은 빠른 무작위 액세스가 가능한 저장 매체에만 적합합니다. 하드 디스크의 데이터 저장은 대부분 B트리 또는 기타 정렬된 데이터 구조를 사용합니다.
대부분의 고급 언어(내장 해시 테이블, 해시 세트 등)는 n/b≤
해시 테이블은 n/b일 때 키를 균등하게 분배하지 않습니다. 작습니다.
Load Factor:n/b>1
另外一种hash表的实现,专门用来存储比较多的key,当 n/b>1n/b1.0时,线性探测失效(没有足够的bucket存储每个key)。这时1个bucket里不仅存储1个key,一般在一个bucket内用chaining,将所有落在这个bucket的key用链表连接起来,来解决冲突时多个key的存储。
1 |
|
n/b值较大的使用场景之一是:将一个网站的用户随机分配到多个不同的web-server上,这时每个web-server可以服务多个用户。多数情况下,我们都希望这种分配能尽可能均匀,从而有效利用每个web-server资源。
这就要求我们关注hash的均匀程度。因此,接下来要讨论的是,假定hash函数完全随机的,均匀程度根据n和b如何变化。
n/b 越大,key的分布越均匀
当 n/b 足够大时,空bucket率趋近于0,且每个bucket中key的数量趋于平均。每个bucket中key数量的期望是:
1 |
|
定义一个bucket平均key的数量是100%:bucket中key的数量刚好是n/b,下图分别模拟了 b=20,n/b分别为 10、100、1000时,bucket中key的数量分布。
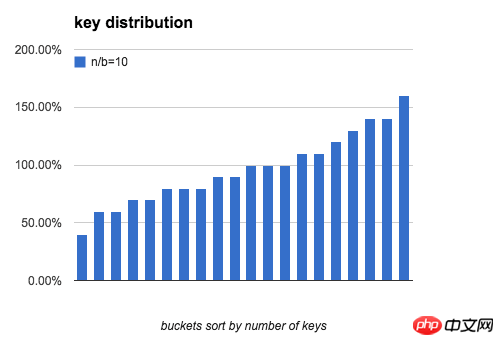
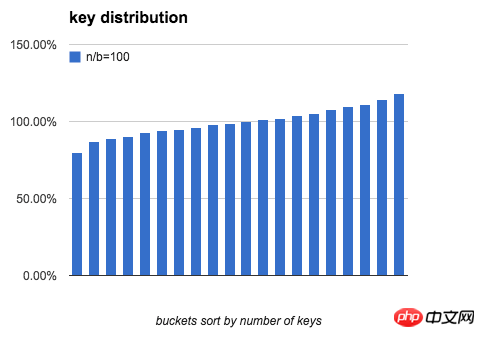
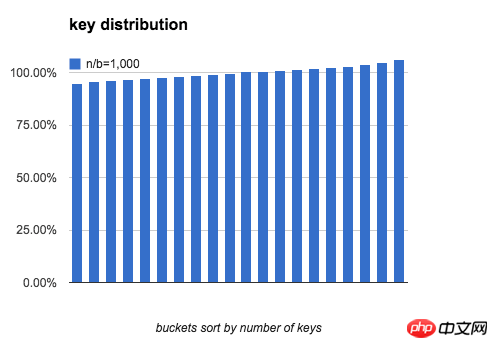
可以看出,当 n/b 增大时,bucket中key数量的最大值与最小值差距在逐渐缩小。下表列出了随b和n/b增大,key分布的均匀程度的变化:
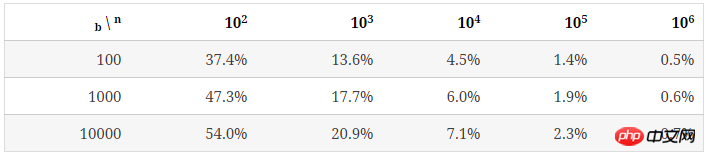
结论:
计算
上述大部分结果来自于程序模拟,现在我们来解决从数学上如何计算这些数值。
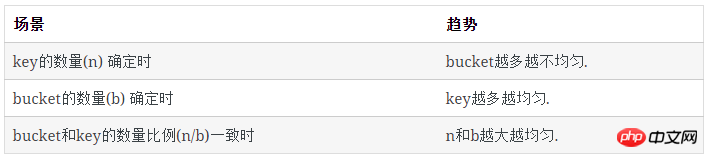
每类bucket的数量
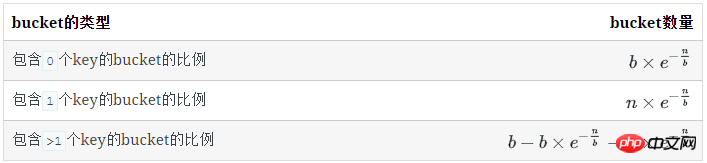
空bucket数量
对于1个key, 它不在某个特定的bucket的概率是 (b−1)/b
所有key都不在某个特定的bucket的概率是( (b−1)/b)n
已知:
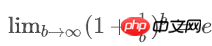
空bucket率是:
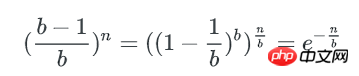
空bucket数量为:

有1个key的bucket数量
n个key中,每个key有1/b的概率落到某个特定的bucket里,其他key以1-(1/b)的概率不落在这个bucket里,因此,对某个特定的bucket,刚好有1个key的概率是:
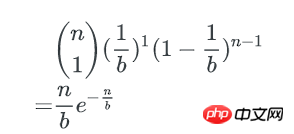
刚好有1个key的bucket数量为:
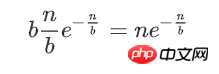
多个key的bucket
剩下即为含多个key的bucket数量:
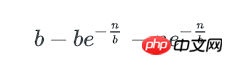
key在bucket中分布的均匀程度
类似的,1个bucket中刚好有i个key的概率是:n个key中任选i个,并都以1/b的概率落在这个bucket里,其他n-i个key都以1-1/b的概率不落在这个bucket里,即:
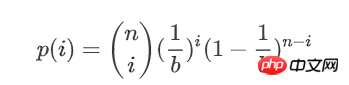
这就是著名的二项式分布。
我们可通过二项式分布估计bucket中key数量的最大值与最小值。
通过正态分布来近似
当 n, b 都很大时,二项式分布可以用正态分布来近似估计key分布的均匀性:
p=1/b,1个bucket中刚好有i个key的概率为:
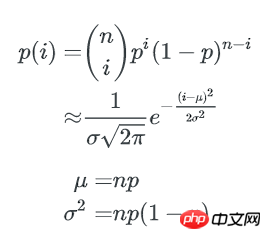
1个bucket中key数量不多于x的概率是:
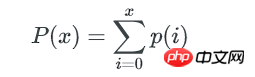
所以,所有不多于x个key的bucket数量是:
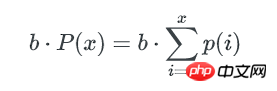
bucket中key数量的最小值,可以这样估算: 如果不多于x个key的bucket数量是1,那么这唯一1个bucket就是最少key的bucket。我们只要找到1个最小的x,让包含不多于x个key的bucket总数为1, 这个x就是bucket中key数量的最小值。
计算key数量的最小值x
一个bucket里包含不多于x个key的概率是:
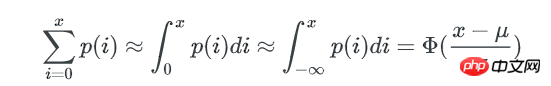
Φ(x) 是正态分布的累计分布函数,当x-μ趋近于0时,可以使用以下方式来近似:
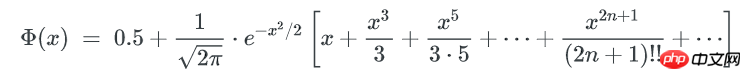
这个函数的计算较难,但只是要找到x,我们可以在[0~μ]的范围内逆向遍历x,以找到一个x 使得包含不多于x个key的bucket期望数量是1。
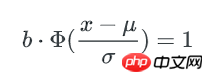
x可以认为这个x就是bucket里key数量的最小值,而这个hash表中,不均匀的程度可以用key数量最大值与最小值的差异来描述: 因为正态分布是对称的,所以key数量的最大值可以用 μ + (μ-x) 来表示。最终,bucket中key数量最大值与最小值的比例就是:
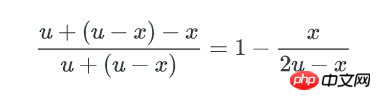
(μ是均值n/b)
程序模拟
以下python脚本模拟了key在bucket中分布的情况,同时可以作为对比,验证上述计算结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
|
위 내용은 프로그래머의 고급 장: 해시 테이블의 기질의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.
인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7386
7386
 15
1630
14
1357
52
1267
25
1216
29
15
1630
14
1357
52
1267
25
1216
29

 최고의 AI 프로그래머는 누구일까요? Devin, Tongyi Lingma 및 SWE 에이전트의 잠재력을 살펴보세요.
Apr 07, 2024 am 09:10 AM
최고의 AI 프로그래머는 누구일까요? Devin, Tongyi Lingma 및 SWE 에이전트의 잠재력을 살펴보세요.
Apr 07, 2024 am 09:10 AM
세계 최초의 AI 프로그래머 데빈(Devin)이 태어난 지 한 달도 채 안 된 2022년 3월 3일, 프린스턴 대학의 NLP팀은 오픈소스 AI 프로그래머 SWE-에이전트를 개발했습니다. GPT-4 모델을 활용하여 GitHub 리포지토리의 문제를 자동으로 해결합니다. SWE-bench 테스트 세트에서 SWE-agent의 성능은 Devin과 유사하며 평균 93초가 걸리고 문제의 12.29%를 해결합니다. SWE-agent는 전용 터미널과 상호 작용하여 파일 내용을 열고 검색하고, 자동 구문 검사를 사용하고, 특정 줄을 편집하고, 테스트를 작성 및 실행할 수 있습니다. (참고: 위 내용은 원문 내용을 약간 조정한 것이지만 원문의 핵심 정보는 그대로 유지되며 지정된 단어 수 제한을 초과하지 않습니다.) SWE-A
 C 언어의 매력을 밝히다: 프로그래머의 잠재력을 발견하다
Feb 24, 2024 pm 11:21 PM
C 언어의 매력을 밝히다: 프로그래머의 잠재력을 발견하다
Feb 24, 2024 pm 11:21 PM
C 언어 학습의 매력: 프로그래머의 잠재력을 여는 것 지속적인 기술 발전으로 컴퓨터 프로그래밍은 많은 주목을 받는 분야가 되었습니다. 많은 프로그래밍 언어 중에서 C 언어는 항상 프로그래머들에게 사랑을 받아 왔습니다. C 언어의 단순성, 효율성 및 폭넓은 적용 덕분에 많은 사람들이 프로그래밍 분야에 입문하는 첫 번째 단계는 C 언어입니다. 이 기사에서는 C 언어 학습의 매력과 C 언어 학습을 통해 프로그래머의 잠재력을 발휘하는 방법에 대해 설명합니다. 우선, C 언어 학습의 매력은 단순함에 있습니다. C언어는 다른 프로그래밍 언어에 비해
 PHP에서 Redis Hash 작업을 구현하는 방법
May 30, 2023 am 08:58 AM
PHP에서 Redis Hash 작업을 구현하는 방법
May 30, 2023 am 08:58 AM
해시 연산 //해시 테이블의 필드에 값을 할당합니다. 성공하면 1을, 실패하면 0을 반환합니다. 해시 테이블이 없으면 테이블이 먼저 생성된 후 값이 할당됩니다. 필드가 이미 있으면 이전 값을 덮어씁니다. $ret=$redis->hSet('user','realname','jetwu');//해시 테이블에서 지정된 필드의 값을 가져옵니다. 해시 테이블이 없으면 false를 반환합니다. $ret=$redis->hGet('사용자','지역
 개인 작업을 통해 돈을 벌어보세요! 2023년 프로그래머를 위한 주문 접수 플랫폼 전체 목록!
Jan 09, 2023 am 09:50 AM
개인 작업을 통해 돈을 벌어보세요! 2023년 프로그래머를 위한 주문 접수 플랫폼 전체 목록!
Jan 09, 2023 am 09:50 AM
지난 주에 우리는 "2023PHP 창업"에 대한 공공 복지 생방송을 진행했습니다. 많은 학생들이 주문을 받기 위한 구체적인 플랫폼에 대해 문의했습니다. 아래 PHP 중국어 웹사이트는 참고용으로 비교적 신뢰할 수 있는 22개의 플랫폼을 정리했습니다!
 2023过年,又限制放烟花?程序猿有办法!
Jan 20, 2023 pm 02:57 PM
2023过年,又限制放烟花?程序猿有办法!
Jan 20, 2023 pm 02:57 PM
本篇文章给大家介绍如何用前端代码实现一个烟花绽放的绚烂效果,其实主要就是用前端三剑客来实现,也就是HTML+CSS+JS,下面一起来看一下,作者会解说相应的代码,希望对需要的朋友有所帮助。
 프로그래머는 무슨 일을 하는가
Aug 03, 2019 pm 01:40 PM
프로그래머는 무슨 일을 하는가
Aug 03, 2019 pm 01:40 PM
프로그래머의 직무: 1. 소프트웨어 프로젝트의 내부 테스트의 세부 설계, 코딩, 구성 및 구현을 담당합니다. 2. 프로젝트 관리자 및 관련 인력이 고객과 소통하고 좋은 고객 관계를 유지하도록 지원합니다. 3. 수요 조사 및 프로젝트에 참여합니다. 타당성 성적 분석, 기술적 타당성 분석 및 수요 분석 4. 소프트웨어 부서에서 개발한 소프트웨어 프로젝트 제공을 위한 관련 소프트웨어 기술에 익숙하고 능숙합니다. 5. 소프트웨어 개발 상황에 대해 프로젝트 관리자에게 적시에 피드백을 제공할 책임이 있습니다. . 소프트웨어 개발 및 유지 관리에 참여합니다. 프로세스 중 주요 기술 문제를 해결합니다. 7. 관련 기술 문서 작성 등을 담당합니다.
 520명의 프로그래머만의 로맨틱한 감정 표현 방법! 거절할 수 없어!
May 19, 2022 pm 03:07 PM
520명의 프로그래머만의 로맨틱한 감정 표현 방법! 거절할 수 없어!
May 19, 2022 pm 03:07 PM
520이 다가오고 있습니다. 그는 매년 열리는 개들을 괴롭히는 쇼를 위해 다시 여기에 왔습니다! 가장 이성적인 코드와 가장 로맨틱한 고백이 어떻게 충돌하는지 보고 싶으신가요? 프로그래머들의 로맨스가 여신들의 마음을 사로잡을 수 있을지 가장 완벽하고 완성도 높은 광고 코드를 하나씩 살펴볼까요?
 Laravel 개발: Laravel Hash를 사용하여 비밀번호 해시를 생성하는 방법은 무엇입니까?
Jun 17, 2023 am 10:59 AM
Laravel 개발: Laravel Hash를 사용하여 비밀번호 해시를 생성하는 방법은 무엇입니까?
Jun 17, 2023 am 10:59 AM
Laravel은 현재 가장 인기 있는 PHP 웹 프레임워크 중 하나이며 개발자에게 많은 강력한 기능과 구성 요소를 제공하며 LaravelHash도 그 중 하나입니다. LaravelHash는 비밀번호를 안전하게 유지하고 애플리케이션의 사용자 데이터를 더욱 안전하게 만드는 데 사용할 수 있는 비밀번호 해싱용 PHP 라이브러리입니다. 이 글에서는 LaravelHash의 작동 방식과 이를 사용하여 비밀번호를 해시하고 확인하는 방법을 알아봅니다. 라라 학습을 위한 필수 지식
