

Node.js는 데이터 구조를 구현합니다: 트리 및 이진 트리, 이진 트리 탐색 및 기본 작업 방법
트리 구조는 비선형 구조의 매우 중요한 유형입니다. 직관적으로 트리 구조는 분기 관계로 정의되는 계층 구조입니다.
트리는 컴퓨터 분야에서도 널리 사용됩니다. 예를 들어, 컴파일러에서 트리는 소스 프로그램의 문법 구조를 나타내는 데 사용되며, 알고리즘의 동작을 분석할 때 트리는 정보를 구성하는 데 사용될 수 있습니다. 나무는 실행 프로세스 등을 설명하는 데 사용할 수 있습니다.
먼저, 나무의 몇 가지 개념을 살펴보겠습니다. 1. 나무는 n(n>=0) 노드의 유한 집합입니다. 비어 있지 않은 트리에는:
(1) 루트라는 특정 노드가 하나만 있습니다.
(2) n>1일 때 나머지 노드는 서로 분리된 유한 집합으로 m(m>0)개로 나눌 수 있습니다. T1, T2, T3,...Tm, 각각은 그 자체로 트리이며 루트의 하위 트리라고 합니다.
예를 들어, (a)는 루트 노드가 하나만 있는 트리이고, (b)는 13개의 노드가 있는 트리입니다. 여기서 A는 루트이고 나머지 노드는 3개의 분리된 하위 집합으로 나뉩니다. T1={B ,E ,F,K,L},t2={D,H,I,J,M};T1, T2 및 T3은 모두 루트 A의 하위 트리이며 그 자체가 트리입니다. 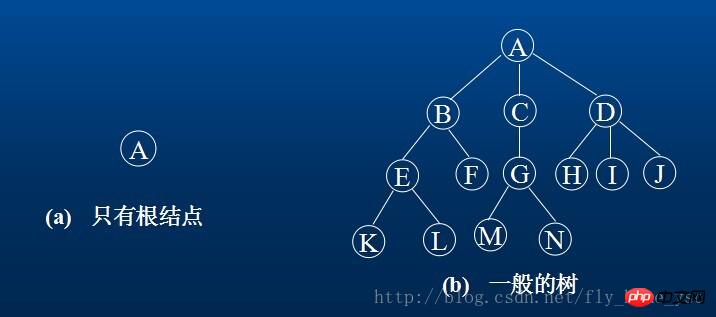
2. 트리의 노드에는 데이터 요소와 해당 하위 트리를 가리키는 여러 가지가 포함되어 있습니다. 노드가 가지고 있는 하위 트리의 수를 노드의 차수라고 합니다. 예를 들어 (b)에서 A의 차수는 3, C의 차수는 1, F의 차수는 0입니다. 차수가 0인 노드를 리프 또는 터미널 노드라고 합니다. 0이 아닌 차수를 가진 노드를 비종단 노드 또는 분기 노드라고 합니다. 트리의 차수는 트리에 있는 각 노드의 최대 차수입니다. (b)의 트리 차수는 3입니다. 노드의 하위 트리의 루트를 노드의 자식이라고 합니다. 따라서 이 노드를 자식의 부모라고 합니다. 같은 부모 밑에서 자란 아이들은 서로를 형제라고 부른다. 노드의 조상은 루트에서 노드까지 분기에 있는 모든 노드입니다. 반대로, 노드를 루트로 하는 하위 트리의 모든 노드를 해당 노드의 자손이라고 합니다.
3. 노드의 레벨은 루트부터 정의됩니다. 루트가 첫 번째 레벨이고 다음 하위 레벨이 두 번째 레벨입니다. 노드가 레벨 l에 있으면 해당 하위 트리의 루트는 레벨 l+1에 있습니다. 부모가 같은 레벨에 있는 노드는 서로 사촌입니다. 예를 들어 노드 G와 E, F, H, I, J는 서로 사촌입니다. 트리의 최대 노드 수준을 트리의 깊이 또는 높이라고 합니다. (b)의 트리 깊이는 4입니다.
4. 트리에 있는 노드의 하위 트리를 왼쪽에서 오른쪽으로 순서대로 보면(즉, 교환할 수 없음) 해당 트리를 순서 있는 트리라고 하고, 그렇지 않으면 순서 없는 트리라고 합니다. 순서 트리에서는 가장 왼쪽 하위 트리의 루트를 첫 번째 자식이라고 하고, 가장 오른쪽 하위 트리의 루트를 마지막 자식이라고 합니다.
5. 숲은 m(m>=0)개의 분리된 나무의 집합입니다. 트리의 각 노드에 대한 하위 트리 집합은 숲입니다.
이진 트리와 관련된 개념을 살펴보겠습니다.
이진 트리는 또 다른 트리 구조입니다. 그 특징은 각 노드가 최대 2개의 하위 트리를 갖는다는 것입니다(즉, 이진 트리에는 2보다 큰 차수를 갖는 노드가 없습니다). . 포인트), 이진 트리의 하위 트리는 왼쪽과 오른쪽 하위 트리로 나눌 수 있습니다(순서는 임의로 바뀔 수 없습니다.)
이진 트리의 속성:
1. 최대 2개의 i-1번째 전원 노드가 있습니다. 이진 트리의 i번째 레벨(i>=1).
2. 깊이 k인 이진 트리는 최대 2k 거듭제곱 - 1개 노드(k>=1)를 가집니다.
3. 임의의 이진 트리 T에 대해 터미널 노드 수가 n0이고 차수 2인 노드 수가 n2이면 n0 = n2 + 1;
깊이 k와 2를 k제곱한 트리 - 노드가 1개인 이진 트리를 완전 이진 트리라고 합니다.
깊이 k의 n 노드가 있는 이진 트리는 각 노드가 깊이 k의 전체 이진 트리에서 1부터 n까지 번호가 매겨진 노드와 일대일로 대응하는 경우에만 완전하다고 합니다.
다음은 완전 이진 트리의 두 가지 특성입니다.
4. n 노드가 있는 완전 이진 트리의 깊이는 Math.floor(log 2 n) + 1
5입니다. n 노드가 있는 트리의 경우 노드는 완전한 이진 트리(깊이는 Math.floor(log 2 n) + 1)는 순서대로 번호가 매겨집니다(첫 번째 레벨부터 Math.floor(2 n) + 1까지, 각 레벨은 왼쪽에서 오른쪽으로) , 모든 노드(1
(1) i=1이면 노드 i는 이진 트리의 루트이고 i>1이면 부모가 없습니다. i )는 Math.floor(i/2) 노드입니다.
(2) 2i > n이면 노드 i에는 왼쪽 자식이 없습니다(노드 i는 리프 노드입니다). 그렇지 않으면 왼쪽 자식 LChild(i)는 노드 2i입니다.
(3) 2i + 1 > n이면 노드 i에는 오른쪽 자식이 없습니다. 그렇지 않으면 오른쪽 자식 RChild(i)는 노드 2i + 1입니다. 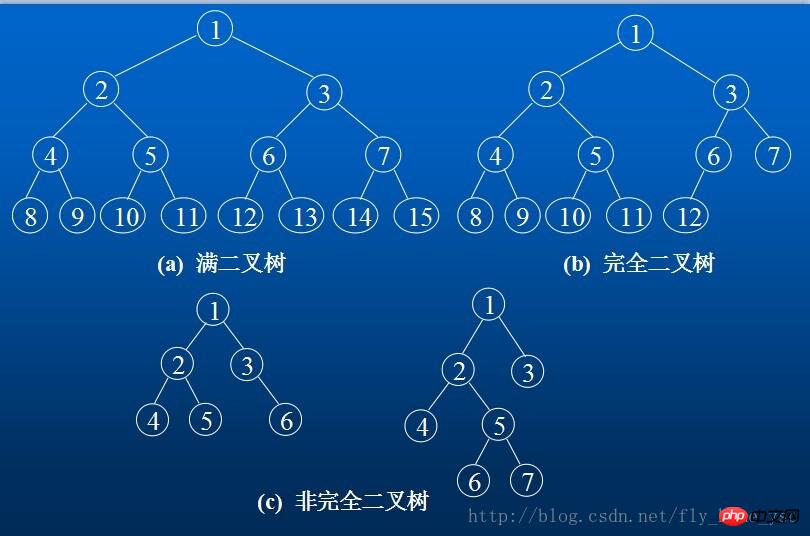
이진 트리의 저장 구조
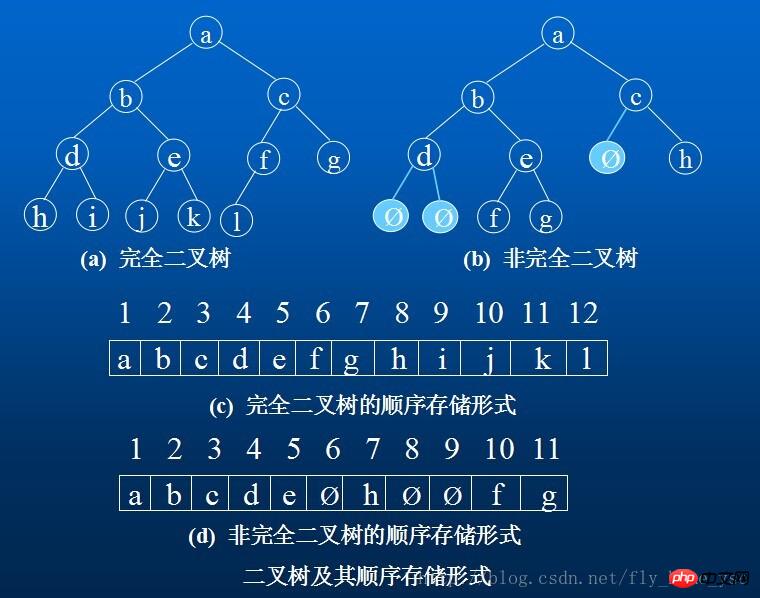
1. 순차 저장 구조
연속 저장 장치 세트를 사용하여 완전한 이진 트리에 위에서 아래로, 왼쪽에서 오른쪽으로 노드 요소를 저장합니다. 즉, 이진 트리에서 번호가 붙은 노드 요소는 a에 저장됩니다. 차원 배열의 아래 첨자 i-1이 있는 구성 요소에 정의됩니다. "0"은 이 노드가 존재하지 않음을 나타냅니다. 이 순차 저장 구조는 완전한 이진 트리에만 적합합니다.
최악의 경우 깊이가 k이고 노드가 k개뿐인 단일 트리(트리에 2차 노드가 없음)에는 길이가 2의 n승 -1인 1차원 배열이 필요하기 때문입니다.
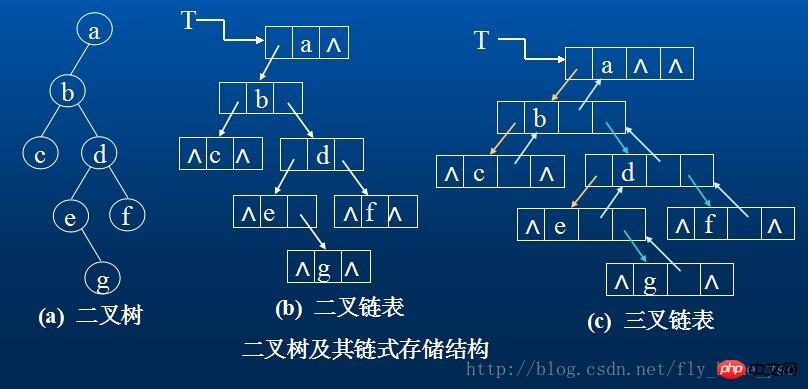
2. 연결된 저장 구조
이진 트리의 노드는 데이터 요소와 왼쪽 및 오른쪽 하위 트리를 각각 가리키는 두 개의 가지로 구성됩니다. 이는 이진 트리의 연결된 목록에 있는 노드에 최소한 세 개의 필드가 포함되어 있음을 의미합니다. 데이터 필드와 왼쪽 및 오른쪽 포인터. 때로는 노드의 부모를 쉽게 찾기 위해 부모 노드를 가리키는 포인터 필드를 노드 구조에 추가할 수 있습니다. 이 두 가지 구조를 이용하여 얻은 이진 트리의 저장 구조를 각각 이진 연결 리스트(Binary Linked List)와 삼중 연결 리스트(Triple Linked List)라고 한다.
n개의 노드를 포함하는 이진 연결 목록에는 n+1개의 빈 링크 필드가 있습니다. 이 빈 링크 필드를 사용하여 다른 유용한 정보를 저장함으로써 또 다른 연결된 저장 구조인 단서 연결 목록을 얻을 수 있습니다.
이진 트리 탐색에는 세 가지 주요 유형이 있습니다.
첫 번째(루트) 순서 탐색: 왼쪽 및 오른쪽 루트
중간(루트) 순서 탐색: 왼쪽 루트 오른쪽
마지막(루트) 순서 탐색: 왼쪽 및 오른쪽 루트
이진 트리의 순차 저장 구조:
이진 트리의 연결 저장 형태:
// 顺序存储结构
var tree = [1, 2, 3, 4, 5, , 6, , , 7];
// 链式存储结构
function BinaryTree(data, leftChild, rightChild) {
this.data = data || null;
// 左右孩子结点
this.leftChild = leftChild || null;
this.rightChild = rightChild || null;
}Traversing Binary Tree(Traversing Binary Tree): 이진 트리의 각 노드를 다음에 따라 한 번씩만 방문하는 것을 말합니다. 지정된 규칙.
1. 이진 트리의 선주문 순회
1) 알고리즘의 재귀적 정의는 다음과 같습니다.
이진 트리가 비어 있으면 순회가 종료됩니다. 그렇지 않으면
⑴ 루트 노드를 방문합니다. 왼쪽 하위 트리(재귀 호출 이 알고리즘)
⑶ 오른쪽 하위 트리를 순서대로 탐색합니다(이 알고리즘을 재귀적으로 호출).
알고리즘 구현:
// 顺序存储结构的递归先序遍历
var tree = [1, 2, 3, 4, 5, , 6, , , 7]; console.log('preOrder:');
void function preOrderTraverse(x, visit) {
visit(tree[x]);
if (tree[2 * x + 1]) preOrderTraverse(2 * x + 1, visit);
if (tree[2 * x + 2]) preOrderTraverse(2 * x + 2, visit);
}(0, function (value) {
console.log(value);
});
// 链式存储结构的递归先序遍历
BinaryTree.prototype.preOrderTraverse = function preOrderTraverse(visit) {
visit(this.data);
if (this.leftChild) preOrderTraverse.call(this.leftChild, visit);
if (this.rightChild) preOrderTraverse.call(this.rightChild, visit);
};2) 비재귀 알고리즘:
T가 이진 트리의 루트 노드를 가리키는 변수라고 가정합니다. 비재귀 알고리즘은 다음과 같습니다. 이진 트리가 비어 있으면 반환합니다. let p=T;
( 1) p는 루트 노드입니다.
(2) p가 비어 있지 않거나 스택이 비어 있지 않으면
(3) p가 비어 있지 않으면 p가 가리키는 노드에 액세스합니다. , p가 스택에 푸시되고, p = p .leftChild, 왼쪽 하위 트리에 액세스
(4) 그렇지 않으면 스택을 p로 다시 팝하고, p = p.rightChild, 오른쪽 하위 트리에 액세스
(5) (2) 스택이 빌 때까지.
코드 구현:
// 链式存储的非递归先序遍历
// 方法1
BinaryTree.prototype.preOrder_stack = function (visit) {
var stack = new Stack();
stack.push(this);
while (stack.top) {
var p; // 向左走到尽头
while ((p = stack.peek())) {
p.data && visit(p.data);
stack.push(p.leftChild);
}
stack.pop();
if (stack.top) {
p = stack.pop();
stack.push(p.rightChild);
}
}
}; // 方法2
BinaryTree.prototype.preOrder_stack2 = function (visit) {
var stack = new Stack();
var p = this;
while (p || stack.top) {
if (p) {
stack.push(p);
p.data && visit(p.data);
p = p.leftChild;
} else {
p = stack.pop();
p = p.rightChild;
}
}
};2. 이진 트리의 순회:
1) 알고리즘의 재귀 정의는 다음과 같습니다.
이진 트리가 비어 있으면 순회가 종료됩니다.
⑴ 왼쪽 하위 트리 순회 순서(재귀적으로 이 알고리즘 호출)
⑵ 루트 노드 방문
⑶ 오른쪽 하위 트리 순회(이 알고리즘을 재귀적으로 호출)
// 顺序存储结构的递归中序遍历
var tree = [1, 2, 3, 4, 5, , 6, , , 7];
console.log('inOrder:');
void function inOrderTraverse(x, visit) {
if (tree[2 * x + 1]) inOrderTraverse(2 * x + 1, visit);
visit(tree[x]);
if (tree[2 * x + 2]) inOrderTraverse(2 * x + 2, visit);
}(0, function (value) {
console.log(value);
});
// 链式存储的递归中序遍历
BinaryTree.prototype.inPrderTraverse = function inPrderTraverse(visit) {
if (this.leftChild) inPrderTraverse.call(this.leftChild, visit);
visit(this.data);
if (this.rightChild) inPrderTraverse.call(this.rightChild, visit);
};2) 비재귀 알고리즘
T는 이진 트리의 루트 노드를 가리키는 변수입니다. 비재귀 알고리즘은 이진 트리가 비어 있으면 반환하고, 그렇지 않으면 p=T
⑴입니다. p가 비어 있지 않으면 p는 스택을 진행합니다. p=p.leftChild; 그렇지 않으면(즉, p가 비어 있는 경우) 스택을 p로 다시 팝하고 p가 가리키는 노드에 액세스합니다. p=p.rightChild; ⑶ (1)로 이동
스택이 빌 때까지.
<br/>
<br/> 이진 트리가 비어 있으면 순회가 종료되고, 그렇지 않으면
⑴ 왼쪽 하위 트리의 순회가 종료됩니다(이 알고리즘을 호출하세요).
⑵ 오른쪽 하위 트리를 탐색합니다(이 알고리즘을 재귀적으로 호출).
⑶ 루트 노드를 방문합니다.
// 方法1
inOrder_stack1: function (visit) {
var stack = new Stack();
stack.push(this);
while (stack.top) {
var p; // 向左走到尽头
while ((p = stack.peek())) {
stack.push(p.leftChild);
}
stack.pop();
if (stack.top) {
p = stack.pop();
p.data && visit(p.data);
stack.push(p.rightChild);
}
}
}, // 方法2
inOrder_stack2: function (visit) {
var stack = new Stack();
var p = this;
while (p || stack.top) {
if (p) {
stack.push(p);
p = p.leftChild;
} else {
p = stack.pop();
p.data && visit(p.data);
p = p.rightChild;
}
}
},<br/> Mark=0은 이 노드가 방금 액세스되었음을 의미하고, mark=1은 왼쪽 하위 트리가 처리되어 반환되었음을 의미하며,
mark=2는 오른쪽 하위 트리가 액세스되었음을 의미합니다. 처리되어 반환되었습니다. 매번 스택 상단의 mark 필드에 따라 동작이 결정됩니다
알고리즘 구현 아이디어:
(1) 루트 노드가 스택에 푸시되고 mark = 0;
(2) 스택이 비어 있지 않으면 노드에 팝합니다.
(3) 노드의 표시가 0이면 현재 노드의 표시를 1로 수정하고 왼쪽 하위 트리를 스택에 푸시합니다. 노드의 표시 = 1, 현재 노드의 표시를 2로 수정하고 오른쪽 하위 트리를 스택 Stack에 놓습니다.
(5) 노드의 표시 = 2이면 현재 노드 노드의 값에 액세스합니다.
(6) 스택이 빌 때까지 종료합니다.
// 顺序存储结构的递归后序遍历
var tree = [1, 2, 3, 4, 5, , 6, , , 7];
console.log('postOrder:');
void function postOrderTraverse(x, visit) {
if (tree[2 * x + 1]) postOrderTraverse(2 * x + 1, visit);
if (tree[2 * x + 2]) postOrderTraverse(2 * x + 2, visit);
visit(tree[x]);
}(0, function (value) {
console.log(value);
});
// 链式存储的递归后序遍历
BinaryTree.prototype.postOrderTraverse = function postOrderTraverse(visit) {
if (this.leftChild) postOrderTraverse.call(this.leftChild, visit);
if (this.rightChild) postOrderTraverse.call(this.rightChild, visit);
visit(this.data);
};postOrder_stack: function (visit) {
var stack = new Stack();
stack.push([this, 0]);
while (stack.top) {
var a = stack.pop();
var node = a[0];
switch (a[1]) {
case 0:
stack.push([node, 1]); // 修改mark域
if (node.leftChild) stack.push([node.leftChild, 0]); // 访问左子树
break;
case 1:
stack.push([node, 2]);
if (node.rightChild) stack.push([node.rightChild, 0]);
break;
case 2:
node.data && visit(node.data);
break;
default:
break;
}
}
}위 내용은 Node.js는 데이터 구조를 구현합니다: 트리 및 이진 트리, 이진 트리 탐색 및 기본 작업 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7469
7469
 15
1376
52
77
11
48
19
19
29
15
1376
52
77
11
48
19
19
29

 Java 함수 비교를 사용하여 복잡한 데이터 구조 비교
Apr 19, 2024 pm 10:24 PM
Java 함수 비교를 사용하여 복잡한 데이터 구조 비교
Apr 19, 2024 pm 10:24 PM
Java에서 복잡한 데이터 구조를 사용할 때 Comparator는 유연한 비교 메커니즘을 제공하는 데 사용됩니다. 구체적인 단계에는 비교기 클래스 정의, 비교 논리를 정의하기 위한 비교 메서드 재작성 등이 포함됩니다. 비교기 인스턴스를 만듭니다. Collections.sort 메서드를 사용하여 컬렉션 및 비교기 인스턴스를 전달합니다.
 Java 데이터 구조 및 알고리즘: 심층 설명
May 08, 2024 pm 10:12 PM
Java 데이터 구조 및 알고리즘: 심층 설명
May 08, 2024 pm 10:12 PM
데이터 구조와 알고리즘은 Java 개발의 기초입니다. 이 기사에서는 Java의 주요 데이터 구조(예: 배열, 연결 목록, 트리 등)와 알고리즘(예: 정렬, 검색, 그래프 알고리즘 등)을 자세히 살펴봅니다. 이러한 구조는 배열을 사용하여 점수를 저장하고, 연결된 목록을 사용하여 쇼핑 목록을 관리하고, 스택을 사용하여 재귀를 구현하고, 대기열을 사용하여 스레드를 동기화하고, 트리 및 해시 테이블을 사용하여 빠른 검색 및 인증을 저장하는 등 실제 사례를 통해 설명됩니다. 이러한 개념을 이해하면 효율적이고 유지 관리가 가능한 Java 코드를 작성할 수 있습니다.
 Go 언어의 참조 유형에 대한 심층적인 이해
Feb 21, 2024 pm 11:36 PM
Go 언어의 참조 유형에 대한 심층적인 이해
Feb 21, 2024 pm 11:36 PM
참조 유형은 Go 언어의 특수 데이터 유형입니다. 해당 값은 데이터 자체를 직접 저장하지 않고 저장된 데이터의 주소를 저장합니다. Go 언어에서 참조 유형에는 슬라이스, 맵, 채널 및 포인터가 포함됩니다. Go 언어의 메모리 관리 및 데이터 전송 방법을 이해하려면 참조 유형에 대한 깊은 이해가 중요합니다. 이 기사에서는 특정 코드 예제를 결합하여 Go 언어의 참조 유형의 특징과 사용법을 소개합니다. 1. 슬라이스 슬라이스는 Go 언어에서 가장 일반적으로 사용되는 참조 유형 중 하나입니다.
 PHP 데이터 구조: AVL 트리의 균형, 효율적이고 질서 있는 데이터 구조 유지
Jun 03, 2024 am 09:58 AM
PHP 데이터 구조: AVL 트리의 균형, 효율적이고 질서 있는 데이터 구조 유지
Jun 03, 2024 am 09:58 AM
AVL 트리는 빠르고 효율적인 데이터 작업을 보장하는 균형 잡힌 이진 검색 트리입니다. 균형을 이루기 위해 좌회전 및 우회전 작업을 수행하고 균형을 위반하는 하위 트리를 조정합니다. AVL 트리는 높이 균형을 활용하여 노드 수에 비해 트리 높이가 항상 작게 되도록 함으로써 로그 시간 복잡도(O(logn)) 검색 작업을 달성하고 대규모 데이터 세트에서도 데이터 구조의 효율성을 유지합니다.
 Java 컬렉션 프레임워크 전체 분석: 데이터 구조를 분석하고 효율적인 저장의 비밀을 밝힙니다.
Feb 23, 2024 am 10:49 AM
Java 컬렉션 프레임워크 전체 분석: 데이터 구조를 분석하고 효율적인 저장의 비밀을 밝힙니다.
Feb 23, 2024 am 10:49 AM
Java 컬렉션 프레임워크 개요 Java 컬렉션 프레임워크는 Java 프로그래밍 언어의 중요한 부분으로, 데이터를 저장하고 관리할 수 있는 일련의 컨테이너 클래스 라이브러리를 제공합니다. 이러한 컨테이너 클래스 라이브러리는 다양한 시나리오의 데이터 저장 및 처리 요구 사항을 충족하기 위해 다양한 데이터 구조를 가지고 있습니다. 컬렉션 프레임워크의 장점은 통합된 인터페이스를 제공하여 개발자가 서로 다른 컨테이너 클래스 라이브러리를 동일한 방식으로 작동할 수 있도록 하여 개발의 어려움을 줄일 수 있다는 것입니다. Java 컬렉션 프레임워크의 데이터 구조 Java 컬렉션 프레임워크에는 다양한 데이터 구조가 포함되어 있으며 각 데이터 구조에는 고유한 특성과 적용 가능한 시나리오가 있습니다. 다음은 몇 가지 일반적인 Java 컬렉션 프레임워크 데이터 구조입니다. 1. 목록: 목록은 요소가 반복될 수 있도록 정렬된 컬렉션입니다. 리
 Go 언어 데이터 구조의 비밀을 자세히 알아보세요.
Mar 29, 2024 pm 12:42 PM
Go 언어 데이터 구조의 비밀을 자세히 알아보세요.
Mar 29, 2024 pm 12:42 PM
Go 언어 데이터 구조의 신비에 대한 심층적인 연구에는 간결하고 효율적인 프로그래밍 언어로서 Go 언어는 데이터 구조 처리에서도 독특한 매력을 보여줍니다. 데이터 구조(Data Structure)는 컴퓨터 과학의 기본 개념으로, 데이터를 보다 효율적으로 접근하고 조작할 수 있도록 데이터를 구성하고 관리하는 것을 목표로 합니다. Go 언어 데이터 구조의 신비를 심층적으로 학습함으로써 데이터가 어떻게 저장되고 작동되는지 더 잘 이해할 수 있으며 이를 통해 프로그래밍 효율성과 코드 품질이 향상됩니다. 1. 배열 배열은 가장 간단한 데이터 구조 중 하나입니다.
 PHP SPL 데이터 구조: 프로젝트에 속도와 유연성을 추가합니다.
Feb 19, 2024 pm 11:00 PM
PHP SPL 데이터 구조: 프로젝트에 속도와 유연성을 추가합니다.
Feb 19, 2024 pm 11:00 PM
PHPSPL 데이터 구조 라이브러리 개요 PHPSPL(표준 PHP 라이브러리) 데이터 구조 라이브러리에는 다양한 데이터 구조를 저장하고 조작하기 위한 클래스 및 인터페이스 세트가 포함되어 있습니다. 이러한 데이터 구조에는 배열, 연결된 목록, 스택, 큐 및 세트가 포함되며, 각 항목은 데이터 조작을 위한 특정 메서드 및 속성 세트를 제공합니다. 배열 PHP에서 배열은 일련의 요소를 저장하는 정렬된 컬렉션입니다. SPL 배열 클래스는 정렬, 필터링 및 매핑을 포함하여 기본 PHP 배열에 대한 향상된 기능을 제공합니다. 다음은 SPL 배열 클래스를 사용하는 예입니다: useSplArrayObject;$array=newArrayObject(["foo","bar","baz"]);$array
 오피스 PPT 소프트웨어의 기본 운영 기술
Mar 19, 2024 pm 07:52 PM
오피스 PPT 소프트웨어의 기본 운영 기술
Mar 19, 2024 pm 07:52 PM
많은 회사원들이 프로젝트 발표를 할 때 주로 ppt를 사용하여 그림과 텍스트를 함께 만드는 것이 보기에 더 즐겁습니다. 따라서 ppt는 직장인에게 워드, 엑셀 못지않게 중요하며, 모두 꼭 필요한 사무용 소프트웨어입니다. 몇 가지 기본적인 운영 기술을 습득하는 것이 매우 필요합니다. 1. 먼저 PPT의 메뉴바를 살펴보겠습니다. 보시다시피 빨간색 프레임은 PPT의 기능 표시줄입니다. "시작", "삽입", "디자인", "애니메이션", "슬라이드 쇼", "검토", "보기"를 포함합니다. 또한, 왼쪽 상단의 주황색 상자인 "WPS Demo"에는 일반적으로 사용되는 많은 기능이 포함되어 있습니다. 2. "시작"을 시작합니다. 해당 기능에는 다른 많은 메뉴가 포함됩니다.
