

요청 모듈을 사용하여 페이지 콘텐츠를 크롤링하는 Python3의 자세한 예
이 글은 주로 python3을 사용하여 요청 모듈을 사용하여 페이지 콘텐츠를 크롤링하는 실제 사례를 소개합니다. 관심 있는 사람은 이에 대해 알아볼 수 있습니다.
1. 내 개인 데스크톱 시스템에 pip
linuxmint를 설치하세요. 시스템은 기본적으로 pip를 설치하지 않습니다. 나중에 요청 모듈을 설치하는 데 pip가 사용된다는 점을 고려하면 여기서 첫 번째 단계는 pip를 설치하는 것입니다.
$ sudo apt install python-pip
설치가 성공했습니다. PIP 버전을 확인하세요.
$ pip -V
2 요청 모듈을 설치합니다.
여기에서 pip를 통해 설치했습니다.
$ pip install requests
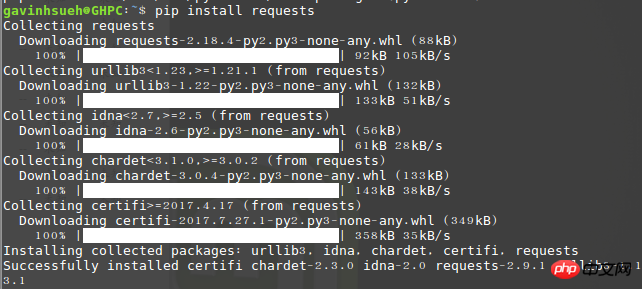
가져오기 실행 요청, 오류가 없다면 설치가 성공한 것입니다!

설치 성공 여부 확인
3. beautifulsoup4 설치
Beautiful Soup은 HTML 또는 XML 파일에서 데이터를 추출할 수 있는 Python 라이브러리입니다. 이는 관례적인 문서 탐색을 가능하게 하며 즐겨 사용하는 변환기를 통해 문서를 찾고 수정하는 방법을 제공합니다. Beautiful Soup을 사용하면 몇 시간, 심지어 며칠의 작업 시간을 절약할 수 있습니다.
$ sudo apt-get install python3-bs4
참고: 여기서는 python3 설치 방법을 사용하고 있습니다. python2를 사용하는 경우 다음 명령을 사용하여 설치할 수 있습니다.
$ sudo pip install beautifulsoup4
4 요청 모듈에 대한 간략한 분석
1) 요청 보내기
우선 요청 모듈을 가져와야 합니다.
>>> import requests
그런 다음 get 대상 크롤링 웹페이지. 여기서는 다음을 예로 들어 보겠습니다.
>>> r = requests.get('http://www.jb51.net/article/124421.htm')
여기서 r이라는 응답 개체가 반환됩니다. 우리는 이 객체로부터 원하는 모든 정보를 얻을 수 있습니다. get here는 http의 응답 방식이므로 비유적으로 put, delete, post, head로 대체할 수도 있습니다.
2) URL 매개변수 전달
때때로 URL의 쿼리 문자열에 대한 일종의 데이터를 전달하고 싶을 때가 있습니다. URL을 직접 작성하는 경우 데이터는 키/값 쌍으로 URL에 배치되고 그 뒤에 물음표가 표시됩니다. 예를 들어 cnblogs.com/get?key=val입니다. 요청을 통해 params 키워드 인수를 사용하여 이러한 매개변수를 문자열 사전으로 제공할 수 있습니다.
예를 들어, Google에서 "python 크롤러"라는 키워드를 검색할 때 newwindow(새 창 열기), q 및 oq(검색 키워드)와 같은 매개변수를 URL에 수동으로 구성할 수 있으며 다음 코드를 사용할 수 있습니다.
>>> payload = {'newwindow': '1', 'q': 'python爬虫', 'oq': 'python爬虫'}
>>> r = requests.get("https://www.google.com/search", params=payload)3) 응답 내용
r.text 또는 r.content를 통해 페이지 응답 내용을 가져옵니다.
>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.text요청은 서버의 콘텐츠를 자동으로 디코딩합니다. 대부분의 유니코드 문자 집합은 원활하게 디코딩될 수 있습니다. r.text와 r.content의 차이점에 대해 간단히 설명하면 다음과 같습니다.
resp.text는 유니코드 데이터를 반환합니다.
resp.content는 바이너리 데이터인 바이트 유형을 반환합니다. 텍스트를 얻으려면 r.text를 사용하면 됩니다. 사진이나 파일을 얻으려면 r.content를 사용하면 됩니다.
4) 웹 페이지 인코딩 가져오기
>>> r = requests.get('http://www.cnblogs.com/') >>> r.encoding 'utf-8'
5) 응답 상태 코드 가져오기
응답 상태 코드를 감지할 수 있습니다:
>>> r = requests.get('http://www.cnblogs.com/') >>> r.status_code 200
5. 회사에서 방금 최근 OA 시스템을 도입했습니다. 여기서는 공식 문서 페이지를 예로 들어 페이지의 기사 제목 및 내용과 같은 유용한 정보만 캡처합니다.
데모 환경
운영 체제: linuxmintPython 버전: python 3.5.2사용 모듈: 요청, beautifulsoup4코드는 다음과 같습니다.#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'GavinHsueh'
import requests
import bs4
#要抓取的目标页码地址
url = 'http://www.ranzhi.org/book/ranzhi/about-ranzhi-4.html'
#抓取页码内容,返回响应对象
response = requests.get(url)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(id='book')
print(status_code)
print(element)프로그램이 실행되고 크롤링 결과를 반환합니다.
크롤링이 성공했습니다
 크롤링 결과가 왜곡되는 문제에 대해
크롤링 결과가 왜곡되는 문제에 대해
Postscript
Python에는 크롤러 관련 모듈이 많이 있고 요청 모듈 외에 urllib, pycurl, tornado 등도 있습니다. 이에 비해 저는 개인적으로 요청 모듈이 비교적 간단하고 사용하기 쉽다고 생각합니다. 텍스트를 통해 Python의 요청 모듈을 사용하여 페이지 콘텐츠를 크롤링하는 방법을 빠르게 배울 수 있습니다. 제 능력에는 한계가 있습니다. 기사에 실수가 있으면 언제든지 알려주시기 바랍니다. 둘째, Python으로 크롤링된 페이지의 내용에 대해 궁금한 점이 있으면 누구나 토론하실 수 있습니다.위 내용은 요청 모듈을 사용하여 페이지 콘텐츠를 크롤링하는 Python3의 자세한 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7548
7548
 15
1382
52
83
11
57
19
22
90
15
1382
52
83
11
57
19
22
90

 C++의 모드 함수에 대한 자세한 설명
Nov 18, 2023 pm 03:08 PM
C++의 모드 함수에 대한 자세한 설명
Nov 18, 2023 pm 03:08 PM
C++의 모드 함수에 대한 자세한 설명 통계에서 모드는 데이터 집합에서 가장 자주 나타나는 값을 의미합니다. C++ 언어에서는 모드 함수를 작성하여 모든 데이터 세트에서 모드를 찾을 수 있습니다. 모드 기능은 다양한 방법으로 구현될 수 있으며, 일반적으로 사용되는 두 가지 방법을 아래에서 자세히 소개합니다. 첫 번째 방법은 해시 테이블을 사용하여 각 숫자의 발생 횟수를 계산하는 것입니다. 먼저, 각 숫자를 키로, 발생 횟수를 값으로 사용하여 해시 테이블을 정의해야 합니다. 그런 다음 주어진 데이터 세트에 대해 다음을 실행합니다.
 Win11에서 관리자 권한을 얻는 방법에 대한 자세한 설명
Mar 08, 2024 pm 03:06 PM
Win11에서 관리자 권한을 얻는 방법에 대한 자세한 설명
Mar 08, 2024 pm 03:06 PM
Windows 운영 체제는 세계에서 가장 인기 있는 운영 체제 중 하나이며, 새로운 버전의 Win11이 많은 주목을 받았습니다. Win11 시스템에서 관리자 권한을 얻는 것은 사용자가 시스템에서 더 많은 작업과 설정을 수행할 수 있도록 하는 중요한 작업입니다. 이번 글에서는 Win11 시스템에서 관리자 권한을 얻는 방법과 권한을 효과적으로 관리하는 방법을 자세히 소개하겠습니다. Win11 시스템에서 관리자 권한은 로컬 관리자와 도메인 관리자의 두 가지 유형으로 나뉩니다. 로컬 관리자는 로컬 컴퓨터에 대한 모든 관리 권한을 갖습니다.
 Oracle SQL의 나누기 연산에 대한 자세한 설명
Mar 10, 2024 am 09:51 AM
Oracle SQL의 나누기 연산에 대한 자세한 설명
Mar 10, 2024 am 09:51 AM
OracleSQL의 나눗셈 연산에 대한 자세한 설명 OracleSQL에서 나눗셈 연산은 두 숫자를 나눈 결과를 계산하는 데 사용되는 일반적이고 중요한 수학 연산입니다. 나누기는 데이터베이스 쿼리에 자주 사용되므로 OracleSQL에서 나누기 작업과 사용법을 이해하는 것은 데이터베이스 개발자에게 필수적인 기술 중 하나입니다. 이 기사에서는 OracleSQL의 나누기 작업 관련 지식을 자세히 설명하고 독자가 참고할 수 있는 특정 코드 예제를 제공합니다. 1. OracleSQL의 Division 연산
 C++의 나머지 함수에 대한 자세한 설명
Nov 18, 2023 pm 02:41 PM
C++의 나머지 함수에 대한 자세한 설명
Nov 18, 2023 pm 02:41 PM
C++의 나머지 함수에 대한 자세한 설명 C++에서는 나머지 연산자(%)를 사용하여 두 숫자를 나눈 나머지를 계산합니다. 피연산자가 모든 정수 유형(char, short, int, long 등 포함) 또는 부동 소수점 숫자 유형(예: float, double)일 수 있는 이진 연산자입니다. 나머지 연산자는 피제수와 동일한 부호를 가진 결과를 반환합니다. 예를 들어 정수의 나머지 연산의 경우 다음 코드를 사용하여 구현할 수 있습니다. inta=10;intb=3;
 Vue.nextTick 함수의 사용법과 비동기 업데이트에서의 적용에 대한 자세한 설명
Jul 26, 2023 am 08:57 AM
Vue.nextTick 함수의 사용법과 비동기 업데이트에서의 적용에 대한 자세한 설명
Jul 26, 2023 am 08:57 AM
Vue.nextTick 함수의 사용법과 비동기 업데이트에서의 적용에 대한 자세한 설명 Vue 개발에서는 데이터를 비동기적으로 업데이트해야 하는 상황이 자주 발생합니다. 예를 들어 DOM 또는 관련 작업을 수정한 후 즉시 데이터를 업데이트해야 합니다. 데이터가 업데이트된 후 즉시 수행됩니다. 이런 문제를 해결하기 위해 Vue에서 제공하는 .nextTick 함수가 등장했습니다. 이 기사에서는 Vue.nextTick 함수의 사용법을 자세히 소개하고 이를 코드 예제와 결합하여 비동기 업데이트에서의 애플리케이션을 설명합니다. 1. Vue.nex
 PHP 모듈로 연산자의 역할과 사용법에 대한 자세한 설명
Mar 19, 2024 pm 04:33 PM
PHP 모듈로 연산자의 역할과 사용법에 대한 자세한 설명
Mar 19, 2024 pm 04:33 PM
PHP의 모듈로 연산자(%)는 두 숫자를 나눈 나머지를 구하는 데 사용됩니다. 이 글에서는 모듈로 연산자의 역할과 사용법을 자세히 논의하고 독자의 이해를 돕기 위해 구체적인 코드 예제를 제공합니다. 1. 모듈로 연산자의 역할 수학에서는 정수를 다른 정수로 나누면 몫과 나머지가 나옵니다. 예를 들어 10을 3으로 나누면 몫은 3이고 나머지는 1입니다. 이 나머지를 얻기 위해 모듈로 연산자가 사용됩니다. 2. 모듈러스 연산자의 사용법 PHP에서는 모듈러스를 나타내기 위해 % 기호를 사용합니다.
 리눅스 시스템콜 system() 함수에 대한 자세한 설명
Feb 22, 2024 pm 08:21 PM
리눅스 시스템콜 system() 함수에 대한 자세한 설명
Feb 22, 2024 pm 08:21 PM
Linux 시스템 호출 system() 함수에 대한 자세한 설명 시스템 호출은 Linux 운영 체제에서 매우 중요한 부분으로 시스템 커널과 상호 작용하는 방법을 제공합니다. 그 중 system() 함수는 흔히 사용되는 시스템 호출 함수 중 하나이다. 이 기사에서는 system() 함수의 사용법을 자세히 소개하고 해당 코드 예제를 제공합니다. 시스템 호출의 기본 개념 시스템 호출은 사용자 프로그램이 운영 체제 커널과 상호 작용하는 방법입니다. 사용자 프로그램은 시스템 호출 기능을 호출하여 운영 체제를 요청합니다.
 Linux 컬 명령에 대한 자세한 설명
Feb 21, 2024 pm 10:33 PM
Linux 컬 명령에 대한 자세한 설명
Feb 21, 2024 pm 10:33 PM
Linux의 컬 명령에 대한 자세한 설명 요약: 컬은 서버와의 데이터 통신에 사용되는 강력한 명령줄 도구입니다. 이 글에서는 컬 명령어의 기본적인 사용법을 소개하고, 독자들이 명령어를 더 잘 이해하고 적용할 수 있도록 실제 코드 예제를 제공할 것입니다. 1. 컬이란 무엇인가? 컬은 다양한 네트워크 요청을 보내고 받는 데 사용되는 명령줄 도구입니다. HTTP, FTP, TELNET 등과 같은 다중 프로토콜을 지원하며 파일 업로드, 파일 다운로드, 데이터 전송, 프록시와 같은 풍부한 기능을 제공합니다.
