

Mysql과 관련된 작업은 무엇입니까?
1》데이터베이스 생성:
구문: 데이터베이스 데이터베이스 이름 생성, 참고하세요>
예:
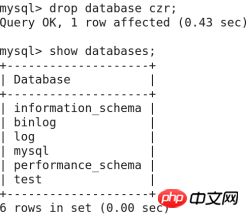
Mysql->drop 데이터베이스 zytest; 삭제 zytest
Innodb는 auto_increment를 사용하는 자동 증가 열을 지원합니다. 자동 증가 열의 값은 비워둘 수 없습니다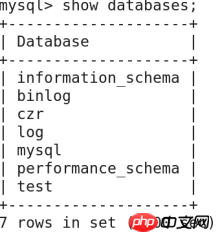 ” ” 하위 테이블의 외부 검사와 연결된 상위 테이블의 필드는 기본 키여야 합니다. 부모 테이블의 정보가 삭제되거나 업데이트되면 그에 따라 자식 테이블도 변경되어야 합니다. innodb 스토리지 엔진에서는 생성된 테이블의 테이블 구조가 저장됩니다. frm 파일에는 데이터와 인덱스가 저장됩니다. innodb_data_home_dir 및 innodb_data_file_path에 의해 정의된 테이블스페이스.
” ” 하위 테이블의 외부 검사와 연결된 상위 테이블의 필드는 기본 키여야 합니다. 부모 테이블의 정보가 삭제되거나 업데이트되면 그에 따라 자식 테이블도 변경되어야 합니다. innodb 스토리지 엔진에서는 생성된 테이블의 테이블 구조가 저장됩니다. frm 파일에는 데이터와 인덱스가 저장됩니다. innodb_data_home_dir 및 innodb_data_file_path에 의해 정의된 테이블스페이스.
innodb_data_home_dir 매개변수가 정의되지 않은 경우 모든 테이블의 메타데이터 파일 ibdata1입니다. 기본적으로 datadir 아래에 있습니다. InnoDB의 각 데이터 테이블의 메타데이터는 항상 ibdata1의 공유 테이블스페이스에 저장되므로 이 파일은 필수입니다.
innodb_data_file_path = ibdata1:10M:autoextend
 데이터 및 인덱스 파일은 함께 수집됩니다: *.ibd 각 테이블에는 별도의 메타데이터가 있습니다.
데이터 및 인덱스 파일은 함께 수집됩니다: *.ibd 각 테이블에는 별도의 메타데이터가 있습니다.
모든 테이블의 전체 메타데이터 파일은 ibdata1입니다.
Inoodb 스토리지 엔진의
장점: 우수한 트랜잭션 관리, 충돌, 복구 기능 및 동시성 제어,
단점: 읽기 및 쓰기 효율성이 약간 낮고 상대적으로 큰 데이터 공간을 차지합니다.
트랜잭션이란 무엇입니까? ? 먼저 ACID 원칙을 살펴보겠습니다 ACID는 데이터베이스 트랜잭션의 정상적인 실행을 위한 4가지 기본 요소로 각각 원자성, 일관성, 독립성 및 내구성을 나타냅니다.
원자성
:
트랜잭션의 원자성은 하나를 나타냅니다. 거래가 실행되거나 실행되지 않습니다. 즉, 거래가 절반만 수행될 수 없습니다. 예를 들어 카드를 긁었지만 돈이 나오지 않았을 수 있습니다. 이 두 단계는 동시에 완료되어야 합니다. 또는 완료되지 않았습니다.
일관성
:
: 트랜잭션의 독립성을 격리라고도 합니다. 이는 두 개 이상의 트랜잭션이 엇갈린 실행 2>MyISAM 엔진 L q mysql-& gt; 쇼 엔진g 3>查询Mysql默认存储引擎 如果想修改存储引擎,可以在 my.ini中进行修改或者my.cnf中的Default-storage-engine=引擎类型; 5》如何选择存储引擎: 在企业生产环境中,选择一个款合适的存储引擎是一个很复杂的问题。每一种存储引擎都有各自的优势,不能笼统的说,谁比谁好。通常用的比较多的 是innodb存储引擎 ==========================创建,修改,删除表: 1》创建表的方法: 2》表的完整性约束: | 约束条件 | 说明| | (1)primary key | 标识该字段为表的主键,具备唯一性| | (2)foreign key | 标识该字段为表的外键,与某表的主键联系| | (3)not null | 标识该属于的值不能为空| | (4)unique | 标识这个属性值是唯一| | (5)auto_increment | 标识该属性值的自动增加 | (6)default | 为该属性值设置默认值| 1>设置表的主键: 举例: 2>设置多个字段做主键 3>设置表的外键: (1) yy1表存储了zhangsan姓名和ID号 (2) yy2表存储了ID号和zhangsan的年龄(old) (3)数据填充yy1和yy2表 (4)更新测试: (5)删除测试: 4>设置表的非空值 5> 设置表的唯一性约束 6>设置表的属性值自动增加 7>、设置表的默认值 插入数据,应为ID为自增,值为空,user_name设置了默认值,所以也为空。 3》查看表结构的方法: 2>修改表的数据类型 3>修改表的字段名称 4>修改增加字段 v 增加没有约束条件的字段: v 增加有完整约束条件的字段 v 在表的第一个位置增加字段默认情况每次增加的字段。都在表的最后。 v 执行在那个位置插入新的字段,在phone后面增加 总结: 6>更改表的存储引擎 7>删除表的外键约束 4》删除表的方法 1>删除没有被关联的普通表
을 갖지 않음을 의미합니다. 데이터 불일치.
내구성:트랜잭션의 내구성은 트랜잭션이 성공적으로 실행된 후의 트랜잭션 내구성을 의미하며 데이터베이스에 영구적으로 저장되며 아무 이유 없이 롤백되지 않습니다.
파일 및 테이블과 이름이 같고 확장자는 frm, MYD 및 MYI를 포함한 3개의 파일로 업,
ccogene 담당자
logue Myi는 확장자를 가진 파일 저장 인덱스입니다.
장점: 공간을 적게 차지합니다. . 빠른 처리 속도,
단점: 트랜잭션 로그의 무결성 및 동시성을 지원하지 않습니다. 3>MEMORY 엔진 Mysql의 특수 엔진으로 기업 생산 환경에서 모든 데이터가 메모리에 저장됩니다. 거의 쓸모가 없습니다. 데이터는 메모리에 저장되기 때문에 메모리에 예외가 있는 경우. 데이터 무결성에 영향을 미칩니다. 장점: 빠른 저장
MyISAM: 외래 키를 지원하지 않고, 트랜잭션을 지원하지 않으며, 인덱스와 데이터가 분리되고, 더 많은 인덱스를 로드할 수 있으며, 메모리에 비해 인덱스가 압축됩니다. 사용 효율성 측면에서 그는 테이블 잠금 메커니즘을 사용하여 다중 동시 읽기 및 쓰기 작업을 최적화했습니다. MYISAM은 빠른 읽기 작업을 강조합니다. 사용 사례: 수행되는 대부분의 프로젝트 중 소수의 프로젝트 플랫폼에서 MyISAM의 읽기 성능은 Innodb
Innodb: 외래 키, 트랜잭션 및 롤백을 지원하지만 인덱스와 데이터가 단단히 바인딩되어 있으며 압축이 사용되지 않으므로 INNODB가 MYISAM보다 훨씬 큽니다.
사용 사례: 호스팅된 대부분의 프로젝트에서 삽입 및 업데이트를 수행하는 경우 InnoDB를 선택해야 합니다. 잠금, 페이지 잠금, 행 수준 잠금에는 테이블 공유 읽기 잠금과 테이블 독점 쓰기라는 두 가지 모드가 있습니다. 자물쇠.
MyISAM: 테이블 수준 잠금: myisam 테이블에서 읽기 작업을 수행할 때 동일한 테이블에 대한 다른 사용자의 읽기 요청을 차단하지는 않지만 차단합니다. 동일한 테이블에 대한 다른 사용자의 읽기 요청> 쓰기 작업 myisam 테이블에 쓸 때 동일한 테이블에 대한 다른 사용자의 읽기 및 쓰기 요청을 차단합니다.
또한 행 잠금 기능을 제공합니다. InnoDB 테이블의 행 잠금은 절대적이지 않습니다. MySQL이 SQL 문을 실행할 때 스캔할 범위를 결정할 수 없으면 InnoDB 테이블도 전체 테이블을 잠급니다.
행 수준의 장점 잠금은 다음과 같습니다.
1) 많은 연결이 각각 다른 쿼리를 수행하는 경우 LOCK 상태를 줄입니다.
2) 예외가 발생하면 데이터 손실을 줄일 수 있습니다. 한 번에 하나의 행 또는 소량의 데이터 행만 롤백할 수 있기 때문입니다. 행 수준 잠금의 단점은 다음과 같습니다. 1) 페이지 수준 잠금 및 테이블 수준 잠금보다 메모리를 더 많이 차지합니다. 2) 쿼리에는 페이지 수준 잠금 및 테이블 수준 잠금보다 더 많은 I/O가 필요하므로 읽기 작업보다는 쓰기 작업에 행 수준 잠금을 사용하는 경우가 많습니다. 3) 교착상태가 발생하기 쉽습니다.
참고: inodb는 현재 작업 행을 결정할 수 없습니다. 즉, 행 수준의 테이블 잠금이 사용됩니다. 스토리지 엔진: 스토리지 엔진 Mysql은 여러 스토리지 엔진과 다양한 저장 방법을 선택할 수 있으며, 트랜잭션 처리 등을 수행할 수 있습니다. Mysql->show 엔진 ;
2 & gt; MySQL 엔진 세부 정보 쿼리: Mysql->show engine innodb status\G;
Mysql-> show variables like 'storage_engine';

以下是存储引擎的对比: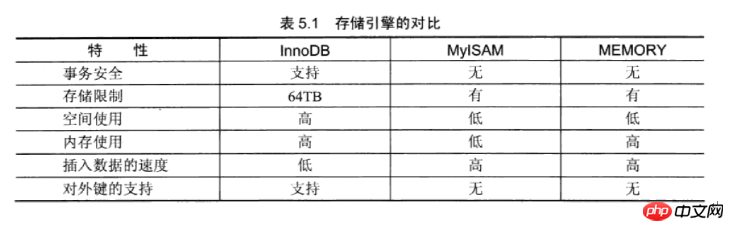
语法:create table 表名(
属性名数据类型完整约束条件,
属性名数据类型条完整约束件,
。。。。。。。。。
属性名数据类型
);
举例: create table example0(
id int,
name varchar(20),
sexboolean);
主键是一个表的特殊字段,这个字段是唯一标识表中的每条信息,主键和记录的关系,跟人的身份证一样。名字可以一样,但是身份证号码觉得不会一样, 主键用来标识每个记录,每个记录的主键值都不同,主键可以帮助Mysql以最快的速度查找到表中的某一条信息,主键必须满足的条件那就是它的唯一性,表中的 任意两条记录的主键值,不能相同,否则就会出现主键值冲突,主键值不能为空,可以是单一的字段,也可以多个字段的组合。 create table sxkj(
User_id int primary key,
user_name varchar(20),
user_sexchar(7));
举例: create table sxkj2(
user_id int ,
user_name float,
grade float,
primary key(user_id,user_name));
外键是表的一个特殊字段,如果aa是B表的一个属性且依赖于A表的主键,那么A表被称为父表。B表为被称为子表,
举例说明:
user_id 是A 表的主键,aa 是B表的外键,那么user_id的值为zhangsan,如果这个zhangsan离职了,需要从A表中删除,那么B表关于 zhangsan的信息也该得到相应的删除,这样可以保证信息的完整性。
语法:
constraint外键别名 foreign key(外键字段1,外键字段2)
references 表名(关联的主键字段1,主键字段2)
create table yy1(
user_id int primary key not null,
user_name varchar(20));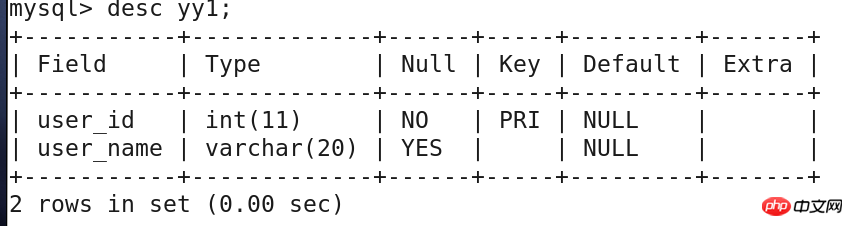
create table yy2(
user_id int primary key not null,
old int(5),
constraint y_fk foreign key(user_id)
references yy1(user_id)on delete cascade on update cascade);
insert into yy1 values('110','zhangsan');
insert into yy2 values('110','30');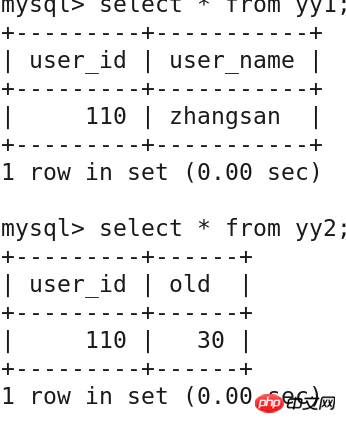
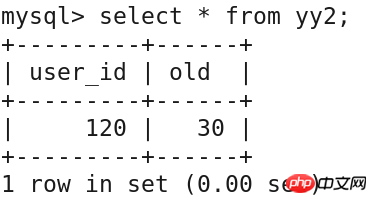
update yy1 set user_id='120' where user_name='zhangsan';
查询验证
select * from yy2;
delete from yy1 where user_id='120';
查询验证
select * from yy2;

语法:属性名数据类型 NOT NULL
举例: create table C(
user_id int NOT NULL);
唯一性指的就是所有记录中该字段。不能重复出现。
语法:属性名数据类型 unique
举例: root@zytest 15:43>create table D(
->user_id int unique);
root@zytest 15:44>show create table D;
Auto_increment 是Mysql数据库中特殊的约束条件,它的作用是向表中插入数据时自动生成唯一的ID,一个表只能有一个字段使用 auto_increment 约束,必须是唯一的;
语法:属性名数据类型 auto_increment,默认该字段的值从1开始自增。
举例:
create table F( user_id int primary key auto_increment);
root@zytest 15:56>insert into F values();插入一条空的信息
Query OK, 1 row affected, 1 warning (0.00 sec)
root@zytest 15:56>select * from F;值自动从1开始自增
+---------+
| user_id |
+---------+
| 1 |
+---------+
1 row in set (0.01 sec)
在创建表时,可以指定表中的字段的默认值,如果插入一条新的纪录时,没有给这个字段赋值,那么数据库会自动的给这个字段插入一个默认 值,字段的默认值用default来设置。
语法: 属性名数据类型 default 默认值
举例: root@zytest 16:05>create table G(
user_id int primary key auto_increment,
user_name varchar(20) default 'zero');
root@zytest 16:05>insert into G values('','');
DESCRIBE可以查看那表的基本定义,包括、字段名称,字段的数据类型,是否为主键以及默认值等。。
(1)语法:describe 表名;可以缩写为desc
(2) show create table查询表详细的结构语句,
1>修改表名
语法:alter table 旧表名 rename 新表名;
举例; root@zytest 16:11>alter table A rename zyA;
Query OK, 0 rows affected (0.02 sec)
语法:alter table 表名 modify 属性名 数据类型;
举例; root@zytest 16:15>alter table A modify user_name double;
Query OK, 0 rows affected (0.18 sec)
语法: alter table 表名 change 旧属性名 新属性名 新数据类型; root@zytest 16:15>alter table A change user_name user_zyname float;
Query OK, 0 rows affected (0.10 sec) alter table 表名 ADD 属性名1 数据类型 [完整性约束条件] [FIRST |AFTER 属性名2]
root@zytest 16:18>alter table A add phone varchar(20);
Query OK, 0 rows affected (0.13 sec)root@zytest 16:42>alter table A add age int(4) not null;
Query OK, 0 rows affected (0.13 sec)root@zytest 16:45>alter table tt add num int(8) primary key first;
Query OK, 1 row affected (0.12 sec)
Records: 1 Duplicates: 0 Warnings: 0 root@zytest 16:46>alter table A add address varchar(30) not null after phone;
Query OK, 0 rows affected (0.10 sec)
Records: 0 Duplicates: 0 Warnings: 0
(1) 默认ADD 增加字段是在最后面增加
(2) 如果想在表的最前端增加字段用first关键字
(3) 如果想在某一个字段后面增加的新的字段,使用after关键字
5>删除一个字段
alter table 表名DROP 属性名;
举例: 删除A 表的age字段 root@zytest 16:51>alter table A drop age;
Query OK, 0 rows affected (0.11 sec)
Records: 0 Duplicates: 0 Warnings: 0 alter table表名 engine=存储引擎
alter table A engine=MyISAM; alter table 表名drop foreign key 外键别名;
alter table yy2 drop foreign key y_fk;
drop table 表名;
2>删除被其它表关联的父表
在数据库中某些表之间建立了一些关联关系。一些成为了父表,被其子表关联,要删除这些父表,就不是那么简单了。删除方法,先删除所关联的 子表的外键,在删除主表。
위 내용은 Mysql과 관련된 작업은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7399
7399
 15
1630
14
1358
52
1268
25
1217
29
15
1630
14
1358
52
1268
25
1217
29

 PHP의 빅데이터 구조 처리 능력
May 08, 2024 am 10:24 AM
PHP의 빅데이터 구조 처리 능력
May 08, 2024 am 10:24 AM
빅 데이터 구조 처리 기술: 청킹(Chunking): 데이터 세트를 분할하고 청크로 처리하여 메모리 소비를 줄입니다. 생성기: 전체 데이터 세트를 로드하지 않고 데이터 항목을 하나씩 생성하므로 무제한 데이터 세트에 적합합니다. 스트리밍: 파일을 읽거나 결과를 한 줄씩 쿼리하므로 대용량 파일이나 원격 데이터에 적합합니다. 외부 저장소: 매우 큰 데이터 세트의 경우 데이터를 데이터베이스 또는 NoSQL에 저장합니다.
 PHP에서 MySQL 백업 및 복원을 사용하는 방법은 무엇입니까?
Jun 03, 2024 pm 12:19 PM
PHP에서 MySQL 백업 및 복원을 사용하는 방법은 무엇입니까?
Jun 03, 2024 pm 12:19 PM
PHP에서 MySQL 데이터베이스를 백업하고 복원하는 작업은 다음 단계에 따라 수행할 수 있습니다. 데이터베이스 백업: mysqldump 명령을 사용하여 데이터베이스를 SQL 파일로 덤프합니다. 데이터베이스 복원: mysql 명령을 사용하여 SQL 파일에서 데이터베이스를 복원합니다.
 PHP에서 MySQL 쿼리 성능을 최적화하는 방법은 무엇입니까?
Jun 03, 2024 pm 08:11 PM
PHP에서 MySQL 쿼리 성능을 최적화하는 방법은 무엇입니까?
Jun 03, 2024 pm 08:11 PM
선형 복잡성에서 로그 복잡성까지 조회 시간을 줄이는 인덱스를 구축하여 MySQL 쿼리 성능을 최적화할 수 있습니다. SQL 삽입을 방지하고 쿼리 성능을 향상하려면 PREPAREDStatements를 사용하세요. 쿼리 결과를 제한하고 서버에서 처리되는 데이터의 양을 줄입니다. 적절한 조인 유형 사용, 인덱스 생성, 하위 쿼리 사용 고려 등 조인 쿼리를 최적화합니다. 쿼리를 분석하여 병목 현상을 식별하고, 캐싱을 사용하여 데이터베이스 로드를 줄이고, 오버헤드를 최소화합니다.
 PHP를 사용하여 MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:26 PM
PHP를 사용하여 MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:26 PM
MySQL 테이블에 데이터를 삽입하는 방법은 무엇입니까? 데이터베이스에 연결: mysqli를 사용하여 데이터베이스에 대한 연결을 설정합니다. SQL 쿼리 준비: 삽입할 열과 값을 지정하는 INSERT 문을 작성합니다. 쿼리 실행: query() 메서드를 사용하여 삽입 쿼리를 실행하면 확인 메시지가 출력됩니다.
 PHP를 사용하여 MySQL 테이블을 만드는 방법은 무엇입니까?
Jun 04, 2024 pm 01:57 PM
PHP를 사용하여 MySQL 테이블을 만드는 방법은 무엇입니까?
Jun 04, 2024 pm 01:57 PM
PHP를 사용하여 MySQL 테이블을 생성하려면 다음 단계가 필요합니다. 데이터베이스에 연결합니다. 데이터베이스가 없으면 작성하십시오. 데이터베이스를 선택합니다. 테이블을 생성합니다. 쿼리를 실행합니다. 연결을 닫습니다.
 PHP에서 MySQL 저장 프로시저를 사용하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:13 PM
PHP에서 MySQL 저장 프로시저를 사용하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:13 PM
PHP에서 MySQL 저장 프로시저를 사용하려면: PDO 또는 MySQLi 확장을 사용하여 MySQL 데이터베이스에 연결합니다. 저장 프로시저를 호출하는 문을 준비합니다. 저장 프로시저를 실행합니다. 결과 집합을 처리합니다(저장 프로시저가 결과를 반환하는 경우). 데이터베이스 연결을 닫습니다.
 MySQL 8.4에서 mysql_native_password가 로드되지 않음 오류를 수정하는 방법
Dec 09, 2024 am 11:42 AM
MySQL 8.4에서 mysql_native_password가 로드되지 않음 오류를 수정하는 방법
Dec 09, 2024 am 11:42 AM
MySQL 8.4(2024년 최신 LTS 릴리스)에 도입된 주요 변경 사항 중 하나는 "MySQL 기본 비밀번호" 플러그인이 더 이상 기본적으로 활성화되지 않는다는 것입니다. 또한 MySQL 9.0에서는 이 플러그인을 완전히 제거합니다. 이 변경 사항은 PHP 및 기타 앱에 영향을 미칩니다.
 오라클 데이터베이스와 mysql의 차이점
May 10, 2024 am 01:54 AM
오라클 데이터베이스와 mysql의 차이점
May 10, 2024 am 01:54 AM
Oracle 데이터베이스와 MySQL은 모두 관계형 모델을 기반으로 하는 데이터베이스이지만 호환성, 확장성, 데이터 유형 및 보안 측면에서 Oracle이 우수하고, MySQL은 속도와 유연성에 중점을 두고 중소 규모 데이터 세트에 더 적합합니다. ① Oracle은 광범위한 데이터 유형을 제공하고, ② 고급 보안 기능을 제공하고, ③ 엔터프라이즈급 애플리케이션에 적합하고, ① MySQL은 NoSQL 데이터 유형을 지원하고, ② 보안 조치가 적고, ③ 중소 규모 애플리케이션에 적합합니다.
