

웹 페이지가 깨지는 근본적인 원인은 무엇입니까?
先看段代码:
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>网页编码</title> </head> <body> </body> </html>
HTML代码中的 指定了网页的编码为utf-8。
网页编码涉及的知识点比较多,总的说来它也是一个历史遗留问题。
第一台计算机(ENIAC)于1946年2月诞生于美国,当时美国只考虑自己使用,并在计算机诞生后的几年里制定了一套ASCII码标准(American Standard Code for Information Interchange,美国信息交换标准代码),它是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII码使用8位二进制数组合来表示256种可能的字符(2的8次方=256),包含了大小写字母,数字0到9,标点符号,以及在美式英语中使用的特殊控制字符。一个字符占1个字节。ASCII码表部分编码如下:
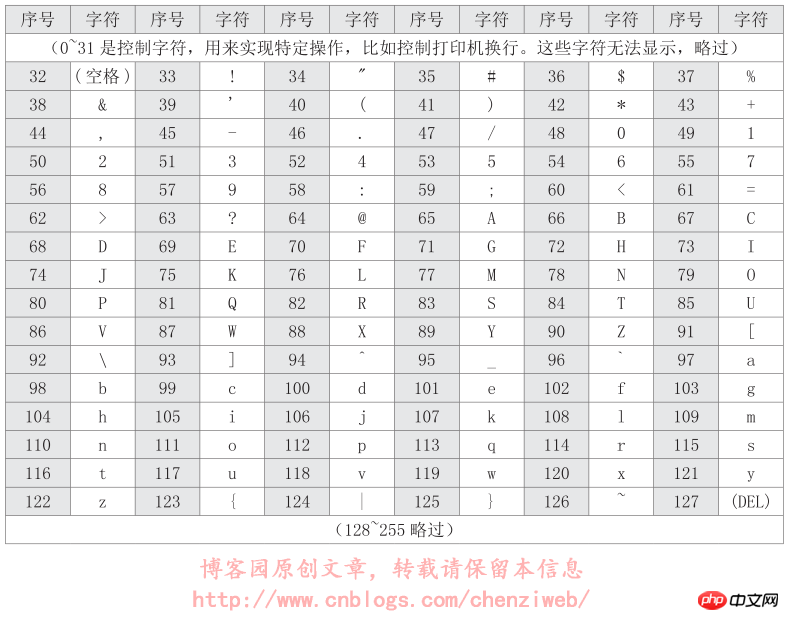
HTML的转义符(字符实体),比如符号“<”的转义符为“<”或“<”,其中的数字编号“60”即是ASCII码表的第60序号。类似的,大写字母“K”也可以转义为“K”。
我们使用转义符做个试验: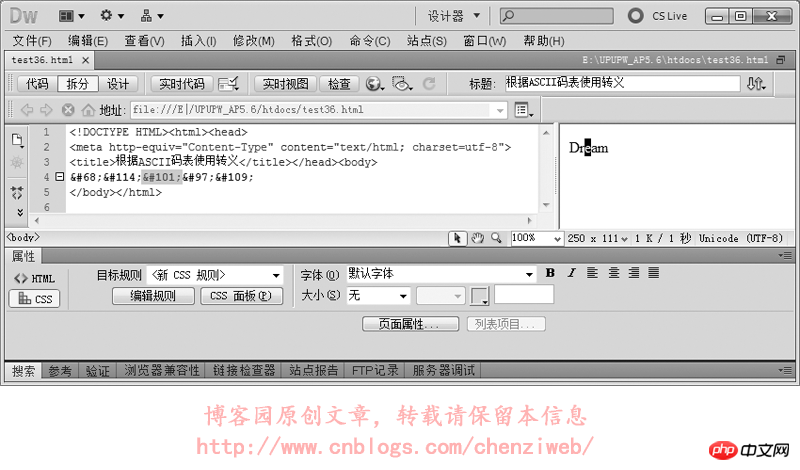
美国制定ASCII码的意思是:ASCII码可以满足在计算机领域所有字符和表示上的需要。不过这只是美国自己的意思,毕竟所有的英文单词都可以拆分来自26个英文字母,ASCII码表能表达256个字符,确实足够美国使用。
后来世界各地也都开始使用计算机,很多国家的语言文字并不是英文,这些国家的文字都没被包含在ASCII码表里。以我们中国为例,汉字近10万个,根本无法排进ASCII码表。于是我们国家对ASCII码表进行拓展并形成自己的的一套标准,在标准中一个汉字占2个字节,新的码表可以表达65536个汉字。但一开始并没有将码表全部填充使用完,只收录了常用的6000多个汉字、英文及其它符号,这套标准称为GB2312(信息交换用汉字编码字符集,GB是“国家标准”的简化词“国标”的拼音首字母缩写,2312是国标序号)。后来又制定了一套收录更多汉字的标准(收录的汉字有2万多个),称为GBK(汉字编码扩展规范,K是“扩”的拼音首字母)。
在GB2312或GBK里,许多标点符号都使用2个字节进行了重新编码,这类占2个字节的标点符号称为“全角”字符(“全角”也称“全形”或“全宽”或“全码”),原来ASCII码表中占1个字节的标点符号则称为“半角”字符(“半角”也称“半形”或“半宽”或“半码”)。全角的逗号、括号、句号等与半角是不一样的:
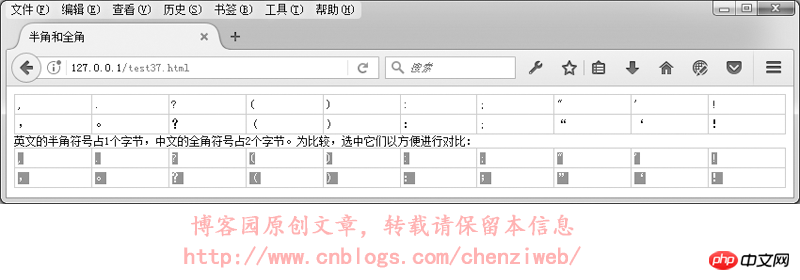
중국어 입력 방법의 경우 기본 구두점은 전자이고, 영어 입력 방법의 경우 구두점은 반각 문자입니다.
이야기를 계속해 보겠습니다. 점점 더 많은 국가에서 컴퓨터를 사용함에 따라 점점 더 많은 국가에서 자체 컴퓨터 코딩 표준을 제정하고 있습니다. 그 결과 여러 국가의 컴퓨터 코딩이 서로를 지원하거나 이해하지 못합니다. 예를 들어, 미국 컴퓨터에서 중국어 문자를 표시하려면 중국어 문자 시스템을 설치해야 합니다. 그렇지 않으면 중국어 파일을 미국 시스템 컴퓨터에서 열 때 깨질 수 있습니다.
이렇게 여러 나라의 코딩 문제를 해결하기 위해 ISO(국제표준화기구, 국제표준화기구)라는 국제기구가 탄생했습니다. ISO는 지구상의 모든 단어와 기호를 기록하는 데 사용되는 UNICODE(Universal Multiple-Octet Coded Character Set, UCS라고도 함)라는 코딩 체계를 통일적으로 제작했습니다. UNICODE 문자는 17개의 그룹으로 나누어지며, 각 그룹을 플레인(plane)이라고 합니다. 각 플레인은 65536개의 코드 포인트를 가지며, 총 1114112개의 문자를 기록할 수 있습니다(111만 문자, 충분히 큰 용량). UNICODE 인코딩은 통일된 한 문자가 2바이트를 차지합니다.
하지만 유니코드는 인터넷이 등장하기 전까지 오랫동안 홍보될 수 없었습니다. 데이터의 전송과 교환으로 인해 국가 간 코딩 통일이 시급해졌습니다. 그러나 초기 하드디스크 및 네트워크 트래픽은 매우 비쌌으며, UNICODE 인코딩의 각 문자는 2바이트의 용량을 차지하므로 파일 저장 시 차지하는 하드디스크 공간을 절약하고 문자 전송에 소요되는 시간도 절약하기 위해 노력했습니다. 네트워크 트래픽을 점유하기 위해 UNICODE를 기반으로 한 많은 전송 지향 표준이 제정되었습니다. 이러한 전송 지향 표준을 통칭하여 UTF(UCS Transfer Format)라고 합니다. UNICODE 인코딩과 UTF 인코딩은 직접적인 일대일 대응이 아니지만 일부 알고리즘과 규칙을 통해 변환되어야 합니다. UNICODE와 UTF의 관계는 다음과 같습니다. UNICODE는 기초, 토대, 목적인 반면 UTF는 UNICODE를 실현하기 위한 수단, 방법 및 프로세스일 뿐입니다.
일반적인 UTF 형식은 UTF-8, UTF-16, UTF-32입니다. 그중 UTF-8은 인터넷에서 가장 널리 사용되는 UNICODE 구현으로, 전송을 위해 특별히 설계되었습니다. 바로 UTF-8은 UNICODE를 기반으로 설계된 전송 구현 방식이기 때문에 국경 없이 인코딩이 가능하고, 어느 나라의 텍스트도 어느 나라의 컴퓨터 브라우저에서나 정상적으로 표시될 수 있다. UTF-8의 가장 큰 특징 중 하나는 1~4바이트를 사용하여 기호를 표현할 수 있다는 점입니다. 기호를 표현하는 데 1바이트가 사용됩니다. 기호를 표현하는 데 2바이트가 필요한 경우 2바이트, 최대 4바이트까지 사용되므로 하드 디스크 저장 공간과 네트워크 트래픽이 절약됩니다. .
따라서 웹 사이트를 개발할 때 GB2312 또는 GBK 인코딩을 사용하고 다른 국가의 컴퓨터가 중국어 문자 인코딩을 지원하지 않으면 다음과 같이 왜곡된 코드가 표시됩니다. 웹사이트가 UTF-8 인코딩을 사용하는 경우, 어느 국가의 컴퓨터에서 웹사이트를 열 때 콘텐츠가 자동으로 UNICODE 인코딩으로 변환되며, 최신 컴퓨터는 모두 UNICODE 인코딩을 지원하므로 모든 텍스트가 정상적으로 표시될 수 있습니다!
그러나 많은 국내 웹사이트는 여전히 GB2312 또는 GBK 인코딩을 사용합니다. 이러한 웹사이트는 일반적으로 국내 사용자에게만 서비스를 제공하며 국내 사용자에게는 표시 문제가 없습니다. 그러나 다른 나라의 시청자가 이러한 웹사이트를 열면 대체로 왜곡된 것처럼 보일 것입니다.
웹사이트의 높은 호환성과 국제화를 위해 GB2312 또는 GBK 인코딩 대신 UTF-8 인코딩을 사용하는 것이 좋습니다.
웹 페이지를 UTF-8, GB2312 및 GBK로 지정하는 태그는 다음과 같습니다:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <meta http-equiv="Content-Type" content="text/html; charset=gbk">
那么有一个问题出现了:网页各种编码的区别,仅仅是在于这一行meta标签的设置差别吗?仅仅是“utf-8”这5个字符换成“gb2312”这6个字符之类的这种“小差别”吗?
不是的,差别不仅仅是这几个字符的差别。当网页指定meta标签中的编码为utf-8后,DreamWeaver在保存网页时会自动将网页文件保存为utf-8的编码格式(二进制码使用utf-8的编码格式),meta标签中的utf-8编码是为了告诉浏览器:这个网页用的是utf-8编码,请在显示时使用utf-8编码的格式解析并呈现出来;而如果meta标签中指定编码为gb2312,DreamWeaver在保存网页时会自动将网页文件保存为gb2312的编码格式(二进制码使用gb2312的编码格式),同样,meta标签中的gb2312编码只是为了告诉浏览器:这个网页用的是gb2312编码,请在显示时使用gb2312编码的格式解析并呈现出来。我们做个试验,将一个文本文件分别保存为utf-8格式(打开记事本新建文本文件,输入内容后,选择菜单:文件→另存为,编码选择为UTF-8)和gb2312格式(另存时编码选择为ANSI,ANSI代表当前操作系统的默认编码,在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码,类推),对比其二进制数据。这里使用UltraEdit-32文件编辑器对文本文件进行16进制查看,即使用16进制查看文件的二进制数据: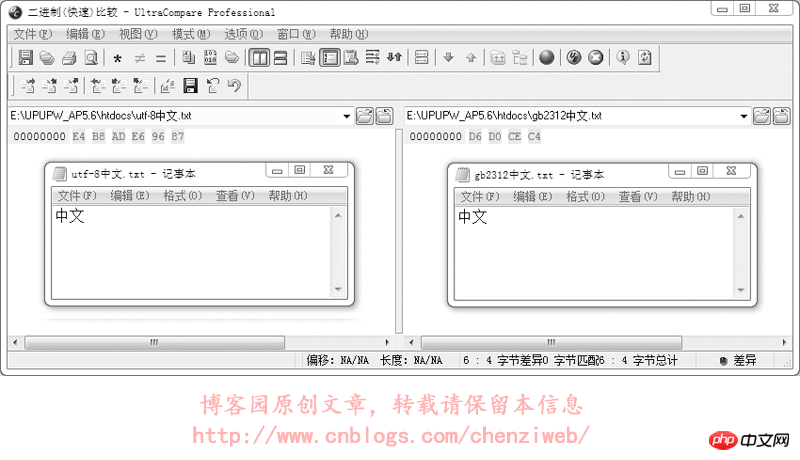
从上图中可以看到,使用utf-8编码和使用gb2312编码保存的文件,其二进制数据是不一样的,即这两个文件的二进制数据内容是不一样的。记事本软件在打开文本文件时,会尝试识别文件的编码并进行解析和显示,即文字保存在记事本里,无论保存成utf-8编码还是gb2312编码,通常情况下记事本都能正常识别和显示,不需要在文件里额外记录数据以告知记事本该文件是什么编码。但很多软件却无法做到智能识别文本文件的编码,这就要求文本文件在保存时,必须附带一些特殊的内容(额外的数据)以告知该文件是什么编码。UNICODE规范中有一个BOM(Byte Order Mark)的概念,就是字节序标记,在文件头部开始位置写入三个字节(EF BB BF)以告知该文件是utf-8编码格式。但这个BOM又带出了新的问题:不是所有的软件或处理程序都支持BOM,即不是所有的软件或处理程序都能识别文件开头的(EF BB BF)这三个字节。当不支持识别时,这三个字节又会被当成文件的实际数据内容。早期的火狐不支持对BOM的识别,当遇到BOM时会对这三个字节显示出特殊的乱码符号;而到目前为止,PHP处理程序仍然不支持BOM,即当一个PHP文件保存为utf-8时,如果附带了BOM,那么PHP处理程序会将BOM解析为PHP文件的实际数据内容而导致出错!在DreamWeaver中,选择软件头部菜单:修改→页面属性(也可以直接按快捷键ctrl+j),在弹出的页面属性面板中点选“标题/编码”,即可看到可供选择的编码。通常在改变网页的编码时,使用这种方式改变。如下图: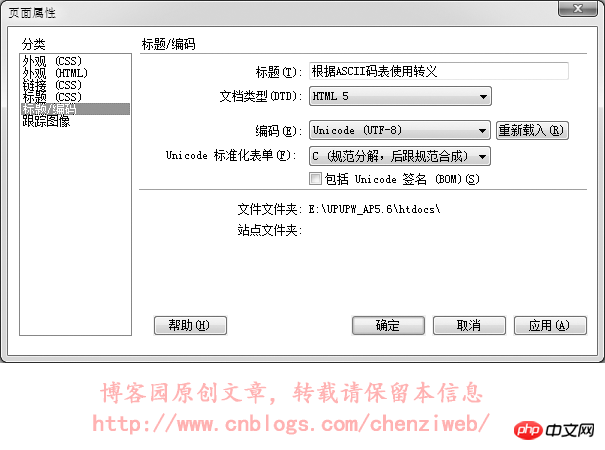
所以:当我们在meta标签中设置为utf-8编码格式时,网页文件就必须要存储为utf-8格式,这样浏览器才能正常显示网页而不是显示乱码。如果在meta标签中设置utf-8编码格式,网页文件却保存为gbk或其它格式,那么在打开网页时浏览器会接到网页meta标签中格式的通知:使用utf-8编码格式来解析和显示网页,而网页的二进制码(数据内容)却为gbk编码或其它格式,显示出来就会是乱码!这好比相亲时,红娘手里的资料有误,错误的告知男方:女方讲英语(meta标签中设置为utf-8编码)。结果女方却不懂英语(文件却不是utf-8编码)。男方开口一句“Hello”就让女方不知所谓了(乱码)。
我们来实验一下,网页指定meta标签中的编码为utf-8,文件却保存为gbk格式:我们先用DreamWeaver编辑一个utf-8格式的网页并保存,然后再用记事本打开该网页,另存为,编码选择为ANSI。
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>中文</title> </head> <body> 本文件使用dreamweaver保存后,再使用记事本打开,并另存为ANSI编码。 </body> </html>
在浏览器中的执行结果如下:
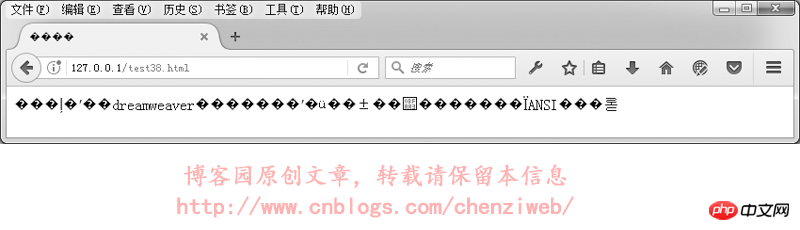
요약하자면: 웹페이지를 개발할 때는 utf-8 인코딩 형식을 사용해보고, 파일을 저장할 때는 utf-8 인코딩으로 저장하세요. (dreamweaver는 웹 페이지 파일을 저장할 때 , 그러나 메모장, 에디트플러스 등 다른 웹사이트 코드 편집기를 사용하는 경우 파일 저장 시 올바른 인코딩 선택에 주의가 필요합니다.
위 내용은 웹 페이지가 깨지는 근본적인 원인은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7363
7363
 15
1628
14
1353
52
1265
25
1214
29
15
1628
14
1353
52
1265
25
1214
29

 스크린캐스팅이 실패하는 이유는 무엇입니까? '초보자를 위한 필독서: 무선 스크린캐스팅 연결 실패 문제를 해결하는 방법'
Feb 07, 2024 pm 05:03 PM
스크린캐스팅이 실패하는 이유는 무엇입니까? '초보자를 위한 필독서: 무선 스크린캐스팅 연결 실패 문제를 해결하는 방법'
Feb 07, 2024 pm 05:03 PM
무선 스크린캐스팅이 연결에 실패하는 이유는 무엇입니까? 무선 화면 미러링 사용 시 연결이 되지 않는다는 친구들의 신고가 접수되었습니다. 무슨 일인가요? 무선 화면 미러링 연결에 실패하면 어떻게 해야 하나요? 컴퓨터, TV, 휴대폰이 동일한 WiFi 네트워크에 연결되어 있는지 확인하세요. 화면 미러링 소프트웨어가 제대로 작동하려면 장치가 동일한 네트워크에 있어야 하며 Quick Screen Mirroring도 예외는 아닙니다. 따라서 네트워크 설정을 빠르게 확인하시기 바랍니다. 화면 미러링 기능이 지원되는지 확인하는 것이 중요합니다. 스마트 TV와 휴대폰은 일반적으로 DLNA 또는 AirPlay 기능을 지원합니다. 스크린캐스트 기능이 지원되지 않으면 스크린캐스트가 불가능합니다. 기기가 올바르게 연결되었는지 확인하세요. 동일한 WiFi에 여러 기기가 있을 수 있습니다. 화면을 공유하려는 기기에 연결되어 있는지 확인하세요. 4. 네트워크가
 WPS Office가 인쇄 작업을 시작할 수 없는 원인은 무엇입니까?
Mar 20, 2024 am 09:52 AM
WPS Office가 인쇄 작업을 시작할 수 없는 원인은 무엇입니까?
Mar 20, 2024 am 09:52 AM
프린터를 LAN에 연결하고 인쇄 작업을 시작하면 몇 가지 사소한 상황이 발생할 수 있습니다. 예를 들어 "wpsoffice가 인쇄 작업을 시작할 수 없습니다..."라는 문제가 가끔 발생하여 파일을 인쇄할 수 없는 등의 문제가 발생할 수 있습니다. ., 작업과 공부가 지연되고 나쁜 영향을 미치게 됩니다. wpsoffice가 인쇄 작업을 시작할 수 없는 문제를 해결하는 방법을 알려 드리겠습니다. 물론 소프트웨어를 업그레이드하거나 드라이버를 업그레이드하여 문제를 해결할 수 있지만, 아래에서는 몇 분 안에 해결할 수 있는 솔루션을 제공하겠습니다. 우선, wpsoffice가 인쇄 작업을 시작할 수 없어 인쇄할 수 없는 현상을 발견했습니다. 이 문제를 해결하려면 하나씩 조사해야 합니다. 또한 프린터의 전원이 켜져 있고 연결되어 있는지 확인하세요. 일반적으로 비정상적인 연결로 인해
 Linux에서 중국어 왜곡 문자를 해결하는 방법
Feb 21, 2024 am 10:48 AM
Linux에서 중국어 왜곡 문자를 해결하는 방법
Feb 21, 2024 am 10:48 AM
Linux 중국어 왜곡 문제는 중국어 문자 세트 및 인코딩을 사용할 때 흔히 발생하는 문제입니다. 잘못된 파일 인코딩 설정, 시스템 로케일이 설치 또는 설정되지 않음, 터미널 디스플레이 구성 오류 등으로 인해 문자가 깨질 수 있습니다. 이 문서에서는 몇 가지 일반적인 해결 방법을 소개하고 특정 코드 예제를 제공합니다. 1. 파일 인코딩 설정을 확인하십시오. 파일 인코딩을 보려면 터미널에서 file 명령을 사용하십시오. 출력에 "charset"이 있는 경우.
 PHP 500 오류에 대한 종합 안내서: 원인, 진단 및 수정 사항
Mar 22, 2024 pm 12:45 PM
PHP 500 오류에 대한 종합 안내서: 원인, 진단 및 수정 사항
Mar 22, 2024 pm 12:45 PM
PHP 500 오류에 대한 종합 가이드: 원인, 진단 및 수정 사항 PHP 개발 중에 HTTP 상태 코드 500과 관련된 오류가 자주 발생합니다. 이 오류는 일반적으로 "500InternalServerError"라고 불리며, 이는 서버 측에서 요청을 처리하는 동안 알 수 없는 오류가 발생했음을 의미합니다. 이 기사에서는 PHP500 오류의 일반적인 원인, 진단 방법, 수정 방법을 살펴보고 참조할 수 있는 구체적인 코드 예제를 제공합니다. 1.500 오류의 일반적인 원인 1.
 Windows 10에서 중국어 문자가 깨지는 문제를 해결하는 방법
Jan 16, 2024 pm 02:21 PM
Windows 10에서 중국어 문자가 깨지는 문제를 해결하는 방법
Jan 16, 2024 pm 02:21 PM
Windows 10 시스템에서는 잘못된 문자가 일반적입니다. 그 이유는 종종 운영 체제가 일부 문자 집합에 대해 기본 지원을 제공하지 않거나 문자 집합 옵션 설정에 오류가 있기 때문입니다. 올바른 약을 처방하기 위해 실제 수술 과정을 아래에서 자세히 분석해 보겠습니다. Windows 10 잘못된 코드를 해결하는 방법 1. 설정을 열고 "시간 및 언어"를 찾습니다. 2. 그런 다음 "언어"를 찾습니다. 3. "언어 설정 관리"를 찾습니다. 4. 여기에서 "시스템 지역 설정 변경"을 클릭합니다. 5. 표시된 대로 확인하고 클릭합니다. 그냥 확인하세요.
 dll 파일 열 때 문자 깨짐 문제 해결을 위한 편집 방법
Jan 06, 2024 pm 07:53 PM
dll 파일 열 때 문자 깨짐 문제 해결을 위한 편집 방법
Jan 06, 2024 pm 07:53 PM
많은 사용자가 컴퓨터를 사용할 때 접미사 dll이 포함된 파일이 많이 있지만 이러한 파일을 여는 방법을 모르는 사용자가 많다는 것을 알게 될 것입니다. 알고 싶은 사용자는 다음 세부 정보를 살펴보십시오. 튜토리얼~열기 방법 dll 파일 편집: 1. "exescope"라는 소프트웨어를 다운로드하여 설치합니다. 2. 그런 다음 dll 파일을 마우스 오른쪽 버튼으로 클릭하고 "exescope로 리소스 편집"을 선택합니다. 3. 그런 다음 팝업 오류 프롬프트 상자에서 "확인"을 클릭하십시오. 4. 그런 다음 오른쪽 패널에서 각 그룹 앞에 있는 "+" 기호를 클릭하면 해당 그룹에 포함된 콘텐츠를 볼 수 있습니다. 5. 보려는 dll 파일을 클릭한 다음 "파일"을 클릭하고 "내보내기"를 선택합니다. 6. 그러면 할 수 있다
 win11 메모장에서 문자가 깨지는 문제 해결
Jan 05, 2024 pm 03:11 PM
win11 메모장에서 문자가 깨지는 문제 해결
Jan 05, 2024 pm 03:11 PM
일부 친구는 메모장을 열고 싶어하는데 win11 메모장이 깨져서 무엇을 해야 할지 모릅니다. 실제로 우리는 일반적으로 지역과 언어만 수정하면 됩니다. Win11 메모장이 깨졌습니다. 첫 번째 단계에서는 검색 기능을 사용하여 "제어판"을 검색하고 엽니다. 두 번째 단계에서는 시계 및 지역 아래에서 "날짜, 시간 또는 숫자 형식 변경"을 클릭합니다. 세 번째 단계에서는 카드 위의 "관리" 옵션을 클릭합니다. 네 번째 단계는 아래의 "시스템 지역 설정 변경"을 클릭하는 것입니다. 다섯 번째 단계는 현재 시스템 지역 설정을 "중국어(간체, 중국)"로 변경하고 "확인"을 클릭하여 저장하는 것입니다.
 win11 블루스크린의 근본 원인을 밝히다
Jan 04, 2024 pm 05:32 PM
win11 블루스크린의 근본 원인을 밝히다
Jan 04, 2024 pm 05:32 PM
많은 친구들이 시스템 블루 스크린 문제에 직면했다고 생각하지만, win11 블루 스크린의 원인이 무엇인지는 알 수 없습니다. 실제로 시스템 블루 스크린의 원인은 여러 가지가 있으며, 순서대로 조사하고 해결할 수 있습니다. win11 블루 스크린의 원인: 1. 메모리 부족 1. 너무 많은 소프트웨어를 실행하거나 게임이 너무 많은 메모리를 소비할 때 발생할 수 있습니다. 2. 특히 지금은 win11에 메모리 오버플로 버그가 있어서 자주 마주칠 확률이 높습니다. 3. 이때 가상 메모리를 설정하여 문제를 해결할 수 있지만 가장 좋은 방법은 메모리 모듈을 업그레이드하는 것입니다. 2. CPU 오버클럭 및 과열 1. CPU 문제의 원인은 사실 메모리 문제와 유사합니다. 2. 후처리, 모델링, 기타 소프트웨어를 사용하거나 대규모 게임을 할 때 주로 발생합니다. 3. CPU 소모가 너무 높으면 블루 스크린이 나타납니다.
