

PHP는 텍스트 기반 모스 부호를 생성합니다.
Dec 28, 2017 pm 03:29 PM최근 입력 텍스트를 기반으로 모스 부호 오디오 파일을 생성해야 하는 필요성이 발생했습니다. 몇 번의 성과 없는 검색 끝에 나는 나만의 생성기를 작성하기로 결정했습니다. 이 글은 주로 PHP에서 텍스트 기반 모스 부호 생성기를 구현하는 것과 관련된 정보를 소개합니다. 도움이 필요한 친구들이 참고할 수 있습니다. 그것이 모두에게 도움이 되기를 바랍니다.
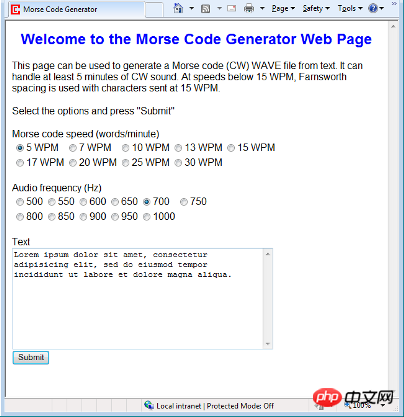
웹을 통해 모스 부호 오디오 파일에 액세스하고 싶기 때문에 PHP를 주요 프로그래밍 언어로 사용하기로 결정했습니다. 위 스크린샷은 모스 부호 생성을 시작하는 웹페이지를 보여줍니다. 다운로드한 zip 파일에는 텍스트를 제출하기 위한 웹 페이지와 오디오 파일을 생성하고 표시하기 위한 PHP 소스 파일이 포함되어 있습니다. PHP 코드를 테스트하려면 웹 페이지 및 관련 PHP 파일을 PHP 지원 서버에 복사해야 합니다.
많은 사람들에게 모스 부호는 오래된 영화에서처럼 일련의 "점"과 "대시" 또는 일련의 경고음일 뿐입니다. 분명히, 컴퓨터 코드를 사용하여 모스 부호를 생성하려는 경우 이 지식만으로는 충분하지 않습니다. 이 기사에서는 모스 부호를 생성하는 요소, WAVE 형식의 오디오 파일을 생성하는 방법, PHP를 사용하여 모스 부호를 오디오 파일로 변환하는 방법을 소개합니다.
모스 부호
모스 부호는 텍스트 인코딩 방식입니다. 장점은 인코딩하기 쉽고 사람의 귀로 쉽게 해독할 수 있다는 것입니다. 기본적으로 오디오(또는 무선 주파수)는 짧거나 긴 오디오 펄스를 형성하기 위해 켜지거나 꺼집니다. 일반적으로 점과 대시 또는 라디오 용어로 "dits" 및 "dash"라고 합니다. 현대 디지털 통신 용어에서 모스 부호는 ASK(진폭 편이 키잉)의 한 형태입니다.
모스 부호에서 문자(문자, 숫자, 문장 부호 및 특수 기호)는 일련의 "틱"과 "다"로 인코딩됩니다. 따라서 텍스트를 모스 부호로 변환하려면 먼저 "틱"과 "다"를 어떻게 표현해야 하는지 결정해야 합니다. 확실한 선택은 "tick"에 0을 사용하고 "dah"에 1을 사용하거나 그 반대로 사용하는 것입니다. 불행하게도 모스 부호는 가변 길이 인코딩 방식을 사용합니다. 따라서 가변 길이 시퀀스를 사용하거나 데이터를 컴퓨터 메모리에 일반적으로 사용되는 고정 비트 크기 형식으로 압축하는 방법을 채택해야 합니다. 또한 모스 부호는 대문자와 소문자를 구분하지 않으며 일부 특수 기호를 인코딩할 수 없다는 점에 유의하는 것이 중요합니다. 구현 시 정의되지 않은 문자와 기호는 무시됩니다.
이 프로젝트에서 메모리 사용량은 특별히 고려해야 할 문제가 아닙니다. 따라서 우리는 간단한 인코딩 방식을 제안합니다. 즉, 각 "틱"을 나타내는 데 "0"을 사용하고 각 "dah"를 나타내는 데 "1"을 사용하여 문자열 연관 배열에 넣습니다. 모스 부호 인코딩 테이블을 정의하는 PHP 코드는 다음과 같습니다.
$CWCODE = array ('A'=>'01','B'=>'1000','C'=>'1010','D'=>'100','E'=>'0', 'F'=>'0010','G'=>'110','H'=>'0000','I'=>'00','J'=>'0111', 'K'=>'101','L'=>'0100','M'=>'11','N'=>'10', 'O'=>'111', 'P'=>'0110','Q'=>'1101','R'=>'010','S'=>'000','T'=>'1', 'U'=>'001','V'=>'0001','W'=>'011','X'=>'1001','Y'=>'1011', 'Z'=>'1100', '0'=>'11111','1'=>'01111','2'=>'00111', '3'=>'00011','4'=>'00001','5'=>'00000','6'=>'10000', '7'=>'11000','8'=>'11100','9'=>'11110','.'=>'010101', ','=>'110011','/'=>'10010','-'=>'10001','~'=>'01010', '?'=>'001100','@'=>'00101');
특히 메모리 사용량을 걱정하는 경우 위 코드가 비트로 해석될 수 있다는 점에 유의하세요. 각 코드에 시작 비트를 추가함으로써 비트 패턴을 형성할 수 있으며, 각 문자를 1바이트에 저장할 수 있습니다. 동시에 최종 인코딩을 구문 분석할 때 시작 비트 왼쪽에 있는 비트가 삭제되어 진정한 가변 길이 인코딩을 얻습니다.
많은 사람들이 깨닫지 못하지만, 사실 "시간 간격"은 모스 부호를 정의하는 주요 요소이므로 이를 이해하는 것이 모스 부호 생성의 핵심입니다. 그러므로 우리가 가장 먼저 해야 할 일은 모스 부호의 내부 부호(즉, "틱"과 "다")의 시간 간격을 정의하는 것이다. 편의상 "틱" 소리의 길이를 시간 단위 dt로 정의하고 "틱"과 "dah" 사이의 간격도 시간 단위 dt로 정의합니다. "dah"의 길이를 3으로 정의합니다. dt, 문자(문자 사이의 간격)도 3dt입니다. 정의 단어(단어) 사이의 간격은 7dt입니다. 요약하면 시간 간격 테이블은 다음과 같습니다.

모스 부호에서 인코딩된 사운드의 "재생 속도"는 일반적으로 분당 단어 수(WPM)로 표시됩니다. 영어 단어의 길이가 다르고 문자의 클릭 횟수와 클릭 수가 다르기 때문에 WPM에서 (오디오) 디지털 샘플로 변환하는 것은 보기만큼 간단하지 않습니다. 국제기구에서 채택한 방식에서는 5자를 평균 단어 길이로 사용하고, 숫자나 구두점은 2자로 취급합니다. 이런 식으로 평균 단어는 50시간 단위 dt입니다. 이러한 방식으로 WPM을 지정하면 총 재생 시간은 50 * WPM 시간 단위/분이고 각 "틱"의 길이(즉, 1시간 단위 dt)는 1.2/WPM초와 같습니다. 이러한 방식으로 "틱"의 시간 길이가 주어지면 다른 요소의 시간 길이를 쉽게 계산할 수 있습니다.
你可能已经注意到,在上面显示的网页中,对于低于15WPM的选项,我们使用了“Farnsworth spacing”。那么这个“Farnsworth spacing”又是个什么鬼?
当报务员学习用耳朵来解码莫斯代码的时候,他就会意识到,当播放速度变化的时候,字符出现的节奏也会跟着变化。当播放速度低于10WPM的时候,他能够从容的识别“嘀”和“嗒”,并且知道发送的哪个字符。但是当播放速度超过10WPM的时候,报务员的识别就会出错,他识别出来的字符会多于实际的“嘀”和“嗒”。当一个学习的时候习惯低速莫斯代码的人,在处理高速播放代码的时候,就会出现问题。因为节奏变了,他潜意识的识别就会出错。
为了解决这个问题,“Farnsworth spacing”就被发明出来了。本质上来讲,字母和符号的播放速度依然采取高于15WPM的速度,同时,通过在字符之间插入更多的空格,来使整体的播放速度降低。这样,报务员就能够以一个合理的速度和节奏来识别每个字符,一旦所有的字符都学习完毕,就可以增加速度,而接收员只需要加快识别字符的速度就可以了。本质上来说,“Farnsworth spacing”这个技巧解决了节奏变化这个问题,使接收员能够快速学习。
所以,在整个系统中,对于更低的播放速度,都统一成15WPM。相对应的,一个“嘀”的长度是0.08秒,但是字符之间和单词之间的间隔就不再是3个dit或者7个dit,而是进行的调整以适应整体速度。
生成声音
在PHP代码中,一个字符(即前面数组的索引)代表一组由“嘀”、“嗒”和空白间隔组成的莫斯声音。我们用数字采样来组成音频序列,并且将其写入到文件中,同时加上适当的头信息来将其定义成WAVE格式。
生成声音的代码其实相当简单,你可以在项目中PHP文件中找到它们。我发现定义一个“数字振荡器”相当方便。每调用一次osc(),它就会返回一个从正玄波产生的定时采样。运用声音采样和声频规范,生成WAVE格式的音频已经足够了。在产生的正玄波中的-1到+1之间是被移动和调整过的,这样声音的字节数据可以用0到255来表示,同时128表示零振幅。
同时,在生成声音方面我们还要考虑另外一个问题。一般来讲,我们是通过正玄波的开关来生成莫斯代码。但是你直接这样来做的话,就会发现你生成的信号会占用非常大的带宽。所以,通常无线电设备会对其加以修正,以减少带宽占用。
在我们的项目中,也会做这样的修正,只不过是用数字的方式。既然我们已经知道了一个最小声音样本“嘀”的时间长度,那么,可以证明,最小带宽的声幅发生在长度等于“嘀”的正玄波半周期。事实上,我们使用低通滤波器(low pass filter)来过滤音频信号也能达到同样的效果。不过,既然我们已经知道所有的信号字符,我们直接简单的过滤一下每一个字符信号就可以了。
生成“嘀”、“嗒”和空白信号的PHP代码就像下面这样:
while ($dt < $DitTime) {
$x = Osc();
if ($dt < (0.5*$DitTime)) {
// Generate the rising part of a dit and dah up to half the dit-time
$x = $x*sin((M_PI/2.0)*$dt/(0.5*$DitTime));
$ditstr .= chr(floor(120*$x+128));
$dahstr .= chr(floor(120*$x+128));
}
else if ($dt > (0.5*$DitTime)) {
// For a dah, the second part of the dit-time is constant amplitude
$dahstr .= chr(floor(120*$x+128));
// For a dit, the second half decays with a sine shape
$x = $x*sin((M_PI/2.0)*($DitTime-$dt)/(0.5*$DitTime));
$ditstr .= chr(floor(120*$x+128));
}
else {
$ditstr .= chr(floor(120*$x+128));
$dahstr .= chr(floor(120*$x+128));
}
// a space has an amplitude of 0 shifted to 128
$spcstr .= chr(128);
$dt += $sampleDT;
}
// At this point the dit sound has been generated
// For another dit-time unit the dah sound has a constant amplitude
$dt = 0;
while ($dt < $DitTime) {
$x = Osc();
$dahstr .= chr(floor(120*$x+128));
$dt += $sampleDT;
}
// Finally during the 3rd dit-time, the dah sound must be completed
// and decay during the final half dit-time
$dt = 0;
while ($dt < $DitTime) {
$x = Osc();
if ($dt > (0.5*$DitTime)) {
$x = $x*sin((M_PI/2.0)*($DitTime-$dt)/(0.5*$DitTime));
$dahstr .= chr(floor(120*$x+128));
}
else {
$dahstr .= chr(floor(120*$x+128));
}
$dt += $sampleDT;
}WAVE格式的文件
WAVE是一种通用的音频格式。从最简单的形式来看,WAVE文件通过在头部包含一个整数序列来表示指定采样率的音频振幅。关于WAVE文件的详细信息请查看这里Audio File Format Specifications website。对于产生莫斯代码,我们并不需要用到WAVE格式的所有参数选项,仅仅需要一个8位的单声道就可以了,所以,so easy。需要注意的是,多字节数据需要采用低位优先(little-endian)的字节顺序。WAVE文件使用一种由叫做“块(chunks)”的记录组成的RIFF格式。
WAVE文件由一个ASCII标识符RIFF开始,紧跟着一个4字节的“块”,然后是一个包含ASCII字符WAVE的头信息,最后是定义格式的数据和声音数据。
在我们的程序中,第一个“块”包含了一个格式说明符,它由ASCII字符fmt和一个4倍字节的“块”。在这里,由于我使用的是普通脉冲编码调制(plain vanilla PCM)格式,所以每个“块”都是16字节。然后,我们还需要这些数据:声道数、声音采样/秒、平均字节/秒、一个区块(block)对齐指示器、位(bit)/声音采样。另外,由于我们不需要高质量立体声,我们只采用单声道,我们使用 11050采样/秒(标准的CD质量音频的采样率是 44200采样/秒)的采样率来生成声音,并且用8位(bit)保存。
最后,真实的音频数据储存在接下来的“块”中。其中包含ASCII字符data,一个4字节的“块”,最后是由字节序列(因为我们采用的是8位(bit)/采样)组成的真实音频数据。
在程序中,由8位音频振幅序列组成的声音保存在变量$soundstr中。一旦音频数据生成完毕,就可以计算出所有的“块”大小,然后就可以把它们合并在一起写入磁盘文件中。下面的代码展示了如何生成头信息和音频“块”。需要注意的是,$riffstr表示RIFF头,$fmtstr表示“块”格式,$soundstr表示音频数据“块”。
$riffstr = 'RIFF'.$NSizeStr.'WAVE';
$x = SAMPLERATE;
$SampRateStr = '';
for ($i=0; $i<4; $i++) {
$SampRateStr .= chr($x % 256);
$x = floor($x/256);
}
$fmtstr = 'fmt '.chr(16).chr(0).chr(0).chr(0).chr(1).chr(0).chr(1).chr(0)
.$SampRateStr.$SampRateStr.chr(1).chr(0).chr(8).chr(0);
$x = $n;
$NSampStr = '';
for ($i=0; $i<4; $i++) {
$NSampStr .= chr($x % 256);
$x = floor($x/256);
}
$soundstr = 'data'.$NSampStr.$soundstr;总结和评论
我们的文本莫斯代码生成器目前看起来还不错。当然,我们还可以对它做很多的修改和完善,比如使用其他字符集、直接从文件中读取文本、生成压缩音频等等。因为我们这个项目的目的是使其能够在网络上方便的使用,所以我们这个简单的方案,已经达到我们的目的了。
相关推荐:
PHP实现迪菲赫尔曼密钥交换(Diffie–Hellman)算法
위 내용은 PHP는 텍스트 기반 모스 부호를 생성합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

인기 기사


인기 기사

뜨거운 기사 태그

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7287
7287
 9
1622
14
1342
46
1259
25
1206
29
9
1622
14
1342
46
1259
25
1206
29

 Ubuntu 및 Debian용 PHP 8.4 설치 및 업그레이드 가이드
Dec 24, 2024 pm 04:42 PM
Ubuntu 및 Debian용 PHP 8.4 설치 및 업그레이드 가이드
Dec 24, 2024 pm 04:42 PM
Ubuntu 및 Debian용 PHP 8.4 설치 및 업그레이드 가이드






 PHP 개발을 위해 Visual Studio Code(VS Code)를 설정하는 방법
Dec 20, 2024 am 11:31 AM
PHP 개발을 위해 Visual Studio Code(VS Code)를 설정하는 방법
Dec 20, 2024 am 11:31 AM
PHP 개발을 위해 Visual Studio Code(VS Code)를 설정하는 방법
