

CSS 선택기 필드 구문 분석을 구현하는 방법

위에서 배운 기본적인 CSS 구문 지식을 바탕으로 이제 필드 파싱을 구현해 보겠습니다. 먼저 제목을 분석합니다. 웹 개발자 도구를 열고 제목에 해당하는 소스 코드를 찾으세요. 이 글은 필드 파싱을 구현하기 위한 CSS 선택기 관련 정보를 주로 소개합니다. 혹시 도움이 되실 분들이 참고하시면 좋을 것 같습니다. 아래 h1 노드에서 찾아서 디버깅용으로 스크랩해두었습니다
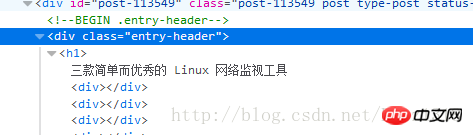
그런데
과 같은 태그를 원하지 않으면 어떻게 해야 하나요? 이 경우 CSS 선택기에서 의사 클래스 메서드를 사용해야 합니다. 아래 그림과 같습니다. p class="entry-header"


# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
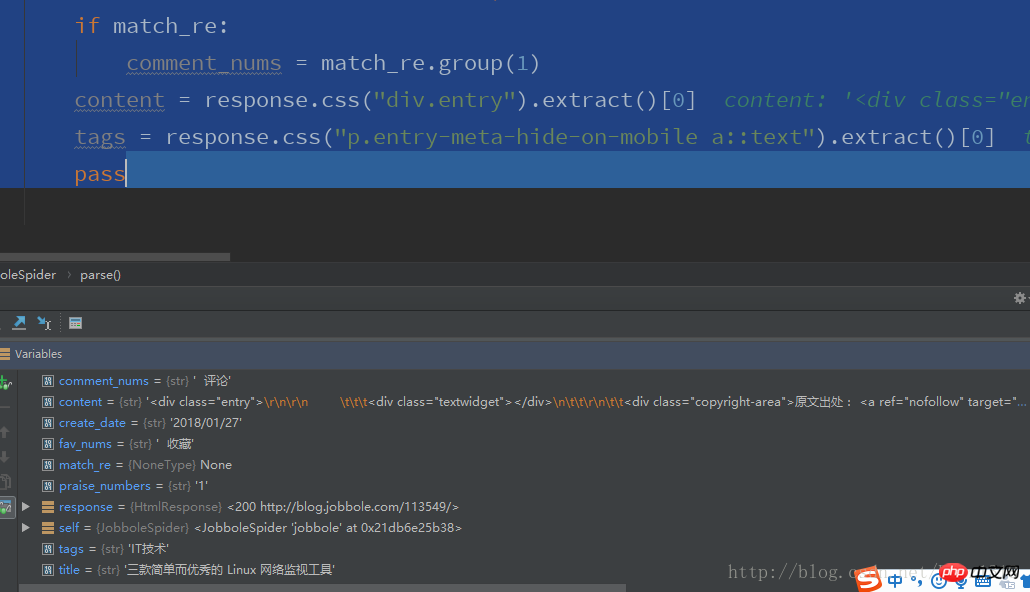
pass관련 추천 :
 OpenERP 직원(employee) 테이블 및 사용자 테이블 관련 필드 분석
OpenERP 직원(employee) 테이블 및 사용자 테이블 관련 필드 분석
위 내용은 CSS 선택기 필드 구문 분석을 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7514
7514
 15
1378
52
79
11
53
19
19
64
15
1378
52
79
11
53
19
19
64

 부트 스트랩에 분할 라인을 작성하는 방법
Apr 07, 2025 pm 03:12 PM
부트 스트랩에 분할 라인을 작성하는 방법
Apr 07, 2025 pm 03:12 PM
부트 스트랩 분할 라인을 만드는 두 가지 방법이 있습니다 : 태그를 사용하여 수평 분할 라인이 생성됩니다. CSS 테두리 속성을 사용하여 사용자 정의 스타일 분할 라인을 만듭니다.
 부트 스트랩에 사진을 삽입하는 방법
Apr 07, 2025 pm 03:30 PM
부트 스트랩에 사진을 삽입하는 방법
Apr 07, 2025 pm 03:30 PM
Bootstrap에 이미지를 삽입하는 방법에는 여러 가지가 있습니다. HTML IMG 태그를 사용하여 이미지를 직접 삽입하십시오. 부트 스트랩 이미지 구성 요소를 사용하면 반응 형 이미지와 더 많은 스타일을 제공 할 수 있습니다. 이미지 크기를 설정하고 IMG-Fluid 클래스를 사용하여 이미지를 적응할 수 있도록하십시오. IMG 통과 클래스를 사용하여 테두리를 설정하십시오. 둥근 모서리를 설정하고 IMG 라운드 클래스를 사용하십시오. 그림자를 설정하고 그림자 클래스를 사용하십시오. CSS 스타일을 사용하여 이미지를 조정하고 배치하십시오. 배경 이미지를 사용하여 배경 이미지 CSS 속성을 사용하십시오.

 부트 스트랩을위한 프레임 워크를 설정하는 방법
Apr 07, 2025 pm 03:27 PM
부트 스트랩을위한 프레임 워크를 설정하는 방법
Apr 07, 2025 pm 03:27 PM
부트 스트랩 프레임 워크를 설정하려면 다음 단계를 따라야합니다. 1. CDN을 통해 부트 스트랩 파일 참조; 2. 자신의 서버에서 파일을 다운로드하여 호스팅하십시오. 3. HTML에 부트 스트랩 파일을 포함; 4. 필요에 따라 Sass/Less를 컴파일하십시오. 5. 사용자 정의 파일을 가져옵니다 (선택 사항). 설정이 완료되면 Bootstrap의 그리드 시스템, 구성 요소 및 스타일을 사용하여 반응 형 웹 사이트 및 응용 프로그램을 만들 수 있습니다.
 HTML, CSS 및 JavaScript의 역할 : 핵심 책임
Apr 08, 2025 pm 07:05 PM
HTML, CSS 및 JavaScript의 역할 : 핵심 책임
Apr 08, 2025 pm 07:05 PM
HTML은 웹 구조를 정의하고 CSS는 스타일과 레이아웃을 담당하며 JavaScript는 동적 상호 작용을 제공합니다. 세 사람은 웹 개발에서 의무를 수행하고 화려한 웹 사이트를 공동으로 구축합니다.
 부트 스트랩 버튼을 사용하는 방법
Apr 07, 2025 pm 03:09 PM
부트 스트랩 버튼을 사용하는 방법
Apr 07, 2025 pm 03:09 PM
부트 스트랩 버튼을 사용하는 방법? 부트 스트랩 CSS를 소개하여 버튼 요소를 만들고 부트 스트랩 버튼 클래스를 추가하여 버튼 텍스트를 추가하십시오.
 Vue에서 부트 스트랩을 사용하는 방법
Apr 07, 2025 pm 11:33 PM
Vue에서 부트 스트랩을 사용하는 방법
Apr 07, 2025 pm 11:33 PM
vue.js에서 bootstrap 사용은 5 단계로 나뉩니다 : Bootstrap 설치. main.js.의 부트 스트랩 가져 오기 부트 스트랩 구성 요소를 템플릿에서 직접 사용하십시오. 선택 사항 : 사용자 정의 스타일. 선택 사항 : 플러그인을 사용하십시오.
 부트 스트랩 날짜를 보는 방법
Apr 07, 2025 pm 03:03 PM
부트 스트랩 날짜를 보는 방법
Apr 07, 2025 pm 03:03 PM
답 : 부트 스트랩의 날짜 선택기 구성 요소를 사용하여 페이지에서 날짜를 볼 수 있습니다. 단계 : 부트 스트랩 프레임 워크를 소개하십시오. HTML에서 날짜 선택기 입력 상자를 만듭니다. 부트 스트랩은 선택기에 스타일을 자동으로 추가합니다. JavaScript를 사용하여 선택한 날짜를 얻으십시오.
