
php-ml은 PHP로 작성된 기계 학습 라이브러리입니다. Python이나 C++가 더 많은 기계 학습 라이브러리를 제공한다는 것을 알고 있지만 실제로는 대부분이 약간 복잡하고 많은 초보자가 이를 구성할 때 절망감을 느낍니다. 이번 글에서는 주로 PHP 머신러닝 라이브러리인 php-ml의 간단한 테스트와 사용법을 소개합니다. 편집자님이 꽤 좋다고 생각하셔서 지금 공유하고 모두에게 참고용으로 드리고자 합니다. 편집자를 따라가서 모두에게 도움이 되기를 바랍니다.
기계 학습 라이브러리 php-ml에는 특별히 고급 알고리즘이 없지만 가장 기본적인 기계 학습, 분류 및 기타 알고리즘이 포함되어 있어 우리 소규모 회사에서는 간단한 데이터 분석, 예측 등을 수행하기에 충분합니다. 우리의 프로젝트에서 우리가 추구하는 것은 과도한 효율성과 정확성이 아니라 비용 효율성이어야 합니다. 일부 알고리즘과 라이브러리는 매우 강력해 보이지만 빠르게 온라인에 접속하는 것을 고려하고 기술 직원이 기계 학습에 대한 경험이 없다면 복잡한 코드와 구성으로 인해 실제로 프로젝트가 지연될 것입니다. 그리고 간단한 기계 학습 애플리케이션을 만드는 경우 복잡한 라이브러리와 알고리즘을 연구하는 데 드는 학습 비용이 분명히 약간 높습니다. 또한 프로젝트에서 이상한 문제가 발생하면 해결할 수 있습니까? 요구 사항이 변경되면 어떻게 해야 합니까? 누구나 이런 경험을 했을 거라 생각합니다. 작업 중 프로그램에서 갑자기 오류가 발생했는데 이유를 알 수 없었습니다. 구글이나 바이두에서 검색해보니 조건에 맞는 질문이 5~10개 정도 나왔습니다. 몇 년 전, 그리고 답장이 없습니다. . .
그래서 가장 간단하고 효율적이며 비용 효율적인 방법을 선택하는 것이 필요합니다. php-ml 속도도 느리지 않고(php7로 빠르게 변경) 정확도도 좋습니다. 결국 알고리즘은 같고, php는 c를 기반으로 합니다. 블로거가 가장 싫어하는 것은 Python, Java 및 PHP 간의 성능과 응용 프로그램 범위를 비교하는 것입니다. 정말 성능을 원한다면 C로 개발하세요. 정말로 적용 범위를 추구하고 싶다면 C를 사용하거나 심지어 어셈블리까지 사용하세요. . .
우선, 이 라이브러리를 사용하려면 먼저 다운로드해야 합니다. 이 라이브러리 파일은 github(https://github.com/php-ai/php-ml)에서 다운로드할 수 있습니다. 물론, Composer를 사용하여 라이브러리를 다운로드하고 자동으로 구성하는 것이 더 좋습니다.
다운로드한 후 이 라이브러리의 문서를 살펴볼 수 있습니다. 문서는 몇 가지 간단한 예입니다. 직접 파일을 만들어 사용해 볼 수 있습니다. 모두 이해하기 쉽습니다. 다음으로 실제 데이터를 대상으로 테스트해 보겠습니다. 데이터셋 중 하나는 붓꽃 수술 데이터셋이고, 다른 하나는 기록 유실로 인한 데이터셋이라 무슨 데이터인지는 모르겠습니다. . .
붓꽃 수술 데이터에는 세 가지 범주가 있습니다.
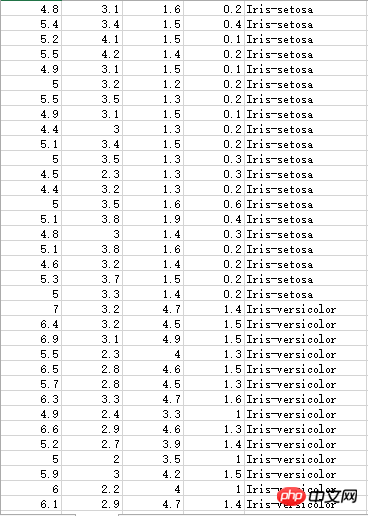
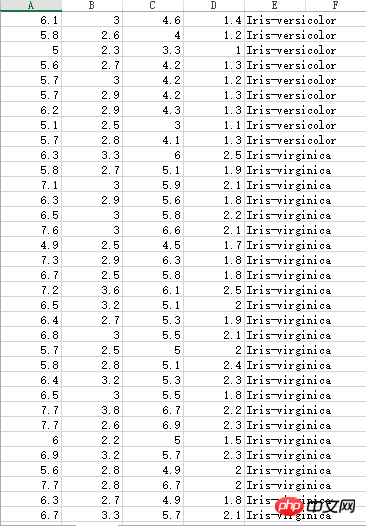
알 수 없는 데이터 세트, 소수점이 쉼표로 표시되므로 계산 시 처리가 필요합니다.

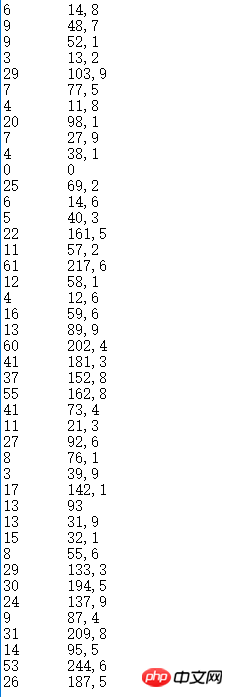
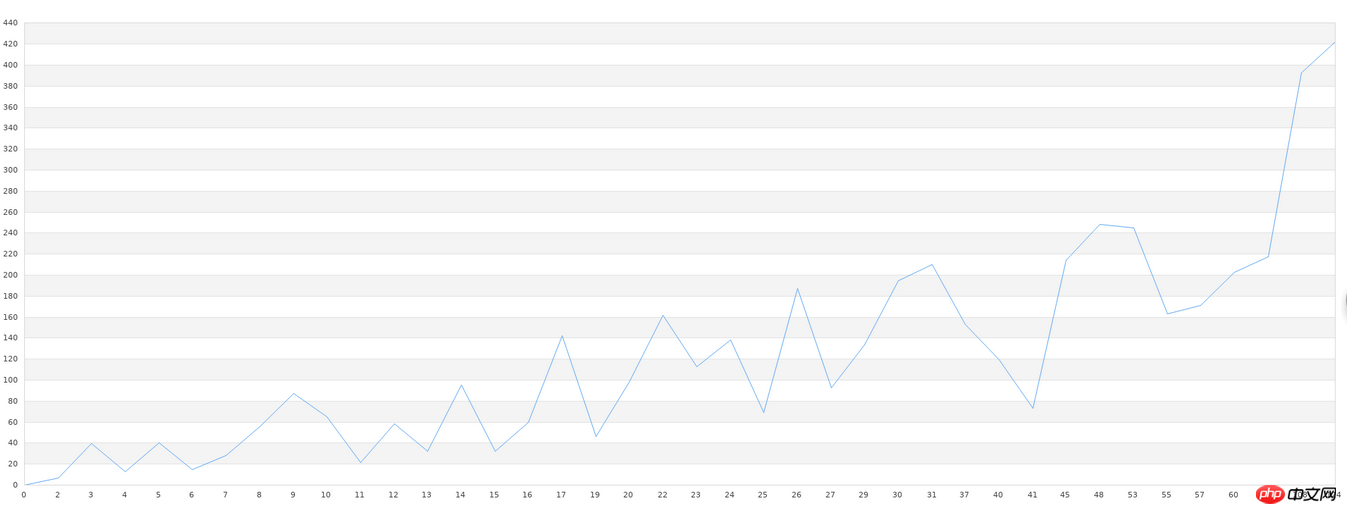
알 수 없는 데이터를 먼저 처리합니다. 데이터 세트. 먼저, 알 수 없는 데이터 세트의 파일 이름은 data.txt입니다. 그리고 이 데이터 세트는 먼저 x-y 선 차트로 그려질 수 있습니다. 따라서 먼저 원본 데이터를 꺾은선형 차트로 그립니다. x축이 상대적으로 길기 때문에 대략적인 모양만 보면 됩니다.
그림을 그리는 데는 PHP의 jpgraph 라이브러리가 사용됩니다.
<?php
include_once './src/jpgraph.php';
include_once './src/jpgraph_line.php';
$g = new Graph(1920,1080);//jpgraph的绘制操作
$g->SetScale("textint");
$g->title->Set('data');
//文件的处理
$file = fopen('data.txt','r');
$labels = array();
while(!feof($file)){
$data = explode(' ',fgets($file));
$data[1] = str_replace(',','.',$data[1]);//数据处理,将数据中的逗号修正为小数点
$labels[(int)$data[0]] = (float)$data[1];//这里将数据以键值的方式存入数组,方便我们根据键来排序
}
ksort($labels);//按键的大小排序
$x = array();//x轴的表示数据
$y = array();//y轴的表示数据
foreach($labels as $key=>$value){
array_push($x,$key);
array_push($y,$value);
}
$linePlot = new LinePlot($y);
$g->xaxis->SetTickLabels($x);
$linePlot->SetLegend('data');
$g->Add($linePlot);
$g->Stroke();비교를 위해 원본 사진을 사용합니다. 다음 연구. 우리는 학습을 위해 php-ml에서 LeastSquars를 사용합니다. 비교 차트를 그릴 수 있도록 테스트 결과를 파일에 저장해야 합니다. 학습코드는 다음과 같습니다.
<?php
require 'vendor/autoload.php';
use Phpml\Regression\LeastSquares;
use Phpml\ModelManager;
$file = fopen('data.txt','r');
$samples = array();
$labels = array();
$i = 0;
while(!feof($file)){
$data = explode(' ',fgets($file));
$samples[$i][0] = (int)$data[0];
$data[1] = str_replace(',','.',$data[1]);
$labels[$i] = (float)$data[1];
$i ++;
}
fclose($file);
$regression = new LeastSquares();
$regression->train($samples,$labels);
//这个a数组是根据我们对原数据处理后的x值给出的,做测试用。
$a = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];
for($i = 0; $i < count($a); $i ++){
file_put_contents("putput.txt",($regression->predict([$a[$i]]))."\n",FILE_APPEND); //以追加的方式存入文件
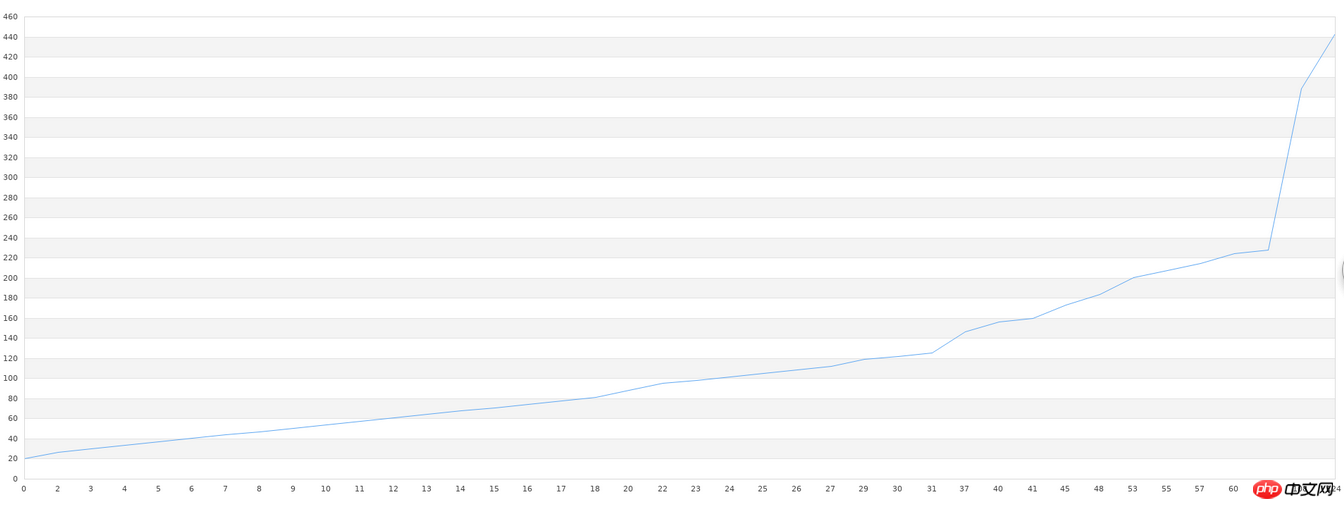
}이후 파일에 저장된 데이터를 읽어와 그래프를 그리고 최종 렌더링을 먼저 붙여넣습니다.
코드는 다음과 같습니다.
<?php
include_once './src/jpgraph.php';
include_once './src/jpgraph_line.php';
$g = new Graph(1920,1080);
$g->SetScale("textint");
$g->title->Set('data');
$file = fopen('putput.txt','r');
$y = array();
$i = 0;
while(!feof($file)){
$y[$i] = (float)(fgets($file));
$i ++;
}
$x = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];
$linePlot = new LinePlot($y);
$g->xaxis->SetTickLabels($x);
$linePlot->SetLegend('data');
$g->Add($linePlot);
$g->Stroke();할 수 있습니다. 특히 들쭉날쭉한 그래픽이 있는 부분에서는 그래픽이 여전히 상대적으로 크다는 것을 알 수 있습니다. 그러나 이는 결국 40개 세트의 데이터이며, 전반적인 그래픽 추세가 일관됨을 알 수 있습니다. 일반 도서관이 이런 학습을 할 경우 데이터량이 적을수록 정확도가 매우 떨어진다. 상대적으로 높은 정확도를 얻으려면 많은 양의 데이터가 필요하며, 10,000개 이상의 데이터가 필요합니다. 이 데이터 요구 사항을 충족할 수 없다면 우리가 사용하는 모든 라이브러리는 쓸모없게 될 것입니다. 따라서 머신러닝 실습에서 실제 어려운 점은 정확도가 낮고 구성이 복잡하다는 기술적 문제가 아니라, 데이터 양이 부족하거나 품질이 너무 낮은(데이터 집합에 쓸모 없는 데이터가 너무 많은 경우) 것입니다. 머신러닝을 하기 전에 데이터 전처리도 필요합니다.
다음으로 수술 데이터를 테스트해 보겠습니다. 총 3가지 카테고리가 있습니다. csv 데이터를 다운로드했으므로 php-ml에서 제공하는 공식적인 csv 파일 조작 방법을 사용할 수 있습니다. 이는 분류 문제이므로 분류를 위해 라이브러리에서 제공하는 SVC 알고리즘을 선택합니다. 암술 데이터의 파일 이름을 Iris.csv로 지정했으며, 코드는 다음과 같습니다.
<?php require 'vendor/autoload.php'; use Phpml\Classification\SVC; use Phpml\SupportVectorMachine\Kernel; use Phpml\Dataset\CsvDataset; $dataset = new CsvDataset('Iris.csv' , 4, false); $classifier = new SVC(Kernel::LINEAR,$cost = 1000); $classifier->train($dataset->getSamples(),$dataset->getTargets()); echo $classifier->predict([$argv[1],$argv[2],$argv[3],$argv[4]]);//$argv是命令行参数,调试这种程序使用命令行较方便
是不是很简单?短短12行代码就搞定了。接下来,我们来测试一下。根据我们上面贴出的图,当我们输入5 3.3 1.4 0.2的时候,输出应该是Iris-setosa。我们看一下:

看,至少我们输入一个原来就有的数据,得到了正确的结果。但是,我们输入原数据集中没有的数据呢?我们来测试两组:
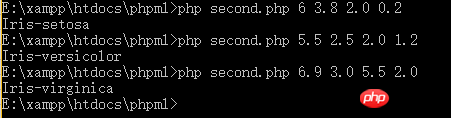
由我们之前贴出的两张图的数据看,我们输入的数据在数据集中并不存在,但分类按照我们初步的观察来看,是合理的。
所以,这个机器学习库对于大多数的人来说,都是够用的。而大多数鄙视这个库鄙视那个库,大谈性能的人,基本上也不是什么大牛。真正的大牛已经忙着捞钱去了,或者正在做学术研究等等。我们更多的应该是掌握算法,了解其中的道理和玄机,而不是夸夸其谈。当然,这个库并不建议用在大型项目上,只推荐小型项目或者个人项目等。
jpgraph只依赖GD库,所以下载引用之后就可以使用,大量的代码都放在了绘制图形和初期的数据处理上。由于库的出色封装,学习代码并不复杂。需要所有代码或者测试数据集的小伙伴可以留言或者私信等,我提供完整的代码,解压即用。
相关推荐:
위 내용은 php-ml의 간단한 테스트 및 사용 공유의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



