
이 글은 통계정보의 개념 소개와 MYSQL 통계정보의 장점을 통해 MySQL 통계정보 관련 지식 포인트를 종합적으로 소개하고 있어 도움이 필요한 친구들에게 도움이 되기를 바랍니다.
MySQL은 SQL을 실행할 때 SQL 구문 분석 및 쿼리 최적화 과정을 거치게 됩니다. 파서는 SQL을 데이터 구조로 분해하여 후속 단계에 전달합니다. 쿼리 최적화 프로그램은 SQL 쿼리 실행에 가장 적합한 솔루션을 찾아 실행 계획을 생성합니다. 쿼리 최적화 프로그램은 데이터베이스의 통계에 따라 SQL이 실행되는 방식을 결정합니다. 아래에서는 MySQL 5.7의 innodb 통계 관련 내용을 소개합니다.
MySQL 통계 저장은 비영구적 통계와 지속적 통계의 두 가지 유형으로 구분됩니다.
비영구적 통계 정보는 메모리에 저장되며 데이터베이스를 다시 시작하면 통계 정보가 손실됩니다. 비지속적 통계를 설정하는 방법에는 두 가지가 있습니다.
|
2 CREATE/ALTER 테이블 매개변수 | STATS_PERSISTENT=0
|
비지속적 통계는 다음 상황에서 자동으로 업데이트됩니다. |
1 ANALYZE TABLE
|
2 실행 innodb_stats_on_metadata=ON일 때 SHOW TABLE STATUS, SHOW INDEX, 쿼리 INFORMATION _SCHEMAUnder TABLES, STATISTICS 실행 |
3 --auto-rehash 기능이 활성화된 상태에서 mysql 클라이언트를 사용하여 로그인하세요 |
4 마지막 통계 업데이트 이후 테이블이 처음으로 열립니다 |
5 참고로, 테이블 1/16의 데이터가 수정되었습니다 |
비지속적 통계의 단점은 명백히 데이터베이스를 재시작한 후 많은 수의 테이블이 통계를 업데이트하기 시작하면 큰 영향을 미칠 것입니다. 인스턴스에서는 지속성이 현재 사용됩니다. | 2. 지속성 통계
지속성 통계는 다음 상황에서 자동으로 업데이트됩니다.
1 INNODB_STATS_AUTO_RECALC=ON
|
2 새 인덱스 추가
|
| 테이블 이름 | |
| last_update | 통계 마지막 업데이트 시간 |
| n_row s | 테이블의 행 수 |
| clustered_index_size | 클러스터형 인덱스의 페이지 수 |
| sum_of_other_index_sizes | 다른 인덱스의 페이지 수 |
|
innodb_index_stats |
| database_name | 데이터베이스 이름 |
| 테이블 이름 | |
| index_name | index |
| last_update | 통계 최종 업데이트 |
| stat_name | 통계 이름 |
| stat_value | 통계 값 |
| sample_size | 샘플링 크기 |
| stat_description | 유형 설명 |
|
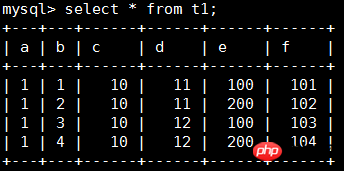
innodb_index_stats를 더 잘 이해하려면 설명을 위한 테스트 테이블을 만듭니다. CREATE TABLE t1 ( a INT, b INT, c INT, d INT, e INT, f INT, PRIMARY KEY (a, b), KEY i1 (c, d), UNIQUE KEY i2uniq (e, f) ) ENGINE=INNODB; 로그인 후 복사 데이터를 다음과 같이 작성합니다.
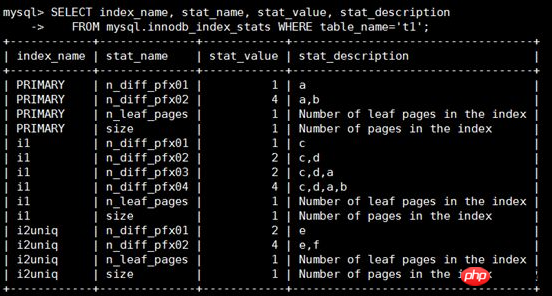
t1 테이블의 통계 정보를 보려면 stat_name 및 stat_value에 집중해야 합니다. fields
tat_name=size일 때: stat_value는 인덱싱된 페이지 수를 나타냅니다. stat_name=n_leaf_pages일 때: stat_value는 리프 노드 수를 나타냅니다. stat_name=n_diff_pfxNN일 때: stat_value는 인덱싱된 페이지의 고유 값 수를 나타냅니다. index 필드에 대한 자세한 설명은 다음과 같습니다. 1, n_diff_pfx01은 인덱스의 첫 번째 열 구별 뒤의 숫자를 나타냅니다. 예를 들어 PRIMARY의 a 열에는 값 1만 있으므로 index_name='PRIMARY' 및 stat_name일 때. ='n_diff_pfx01', stat_value=1. 2. n_diff_pfx02는 인덱스의 처음 두 열의 구별 뒤의 숫자를 나타냅니다. 예를 들어 i2uniq의 e 및 f 열에는 4개의 값이 있으므로 index_name='i2uniq' 및 stat_name='n_diff_pfx02'이면 stat_value= 4. 3 고유하지 않은 인덱스의 경우 기본 키 인덱스는 index_name='i1' 및 stat_name='n_diff_pfx03'과 같이 원래 열 뒤에 추가되고 기본 키 열 a는 원래 인덱스 열 뒤에 추가됩니다. c, d, (c, d, a)의 고유 결과는 2입니다. stat_name 및 stat_value의 구체적인 의미를 이해하면 SQL 실행 시 적합한 인덱스가 사용되지 않는 이유를 해결하는 데 도움이 됩니다. 예를 들어 특정 인덱스 n_diff_pfxNN의 stat_value가 실제 값보다 훨씬 작다고 생각합니다. 잘못 선택되었기 때문에 잘못된 인덱스를 사용할 가능성이 있습니다. 3. 부정확한 통계 정보 처리실행 계획을 확인한 결과, innodb_index_stats의 통계 정보 차이가 커서 발생하는 경우 다음과 같은 방법으로 처리할 수 있습니다. 1. 통계 정보를 수동으로 업데이트합니다. 실행 중에 읽기 잠금이 추가됩니다. 2. 업데이트 후에도 통계 정보가 정확하지 않으면 테이블 샘플링을 위한 데이터 페이지를 추가하는 것을 고려할 수 있습니다. 수정하는 두 가지 방법: a) 전역 변수 INNODB_STATS_PERSISTENT_SAMPLE_PAGES, 기본값은 20입니다. b) 단일 테이블은 테이블의 샘플링을 지정할 수 있습니다. ALTER TABLE TABLE_NAME STATS_SAMPLE_PAGES=40; 여기서 STATS_SAMPLE_PAGES 값은 65535입니다. 이 값을 초과하면 오류가 보고됩니다. 현재 MySQL은 히스토그램 기능을 제공하지 않습니다. 경우에 따라(불균일한 데이터 분포 등) 통계 정보를 업데이트하는 것만으로는 반드시 정확한 실행 계획을 얻을 수 없는 경우가 있습니다. 인덱스 힌트를 통해서만 인덱스를 지정할 수 있습니다. 새 버전 8.0에는 히스토그램 기능이 추가될 예정입니다. MySQL이 더욱 강력해지기를 기대해 보겠습니다! 관련 권장 사항:분석 예: 통계 정보 관리, Spring 주석 개발 및 EasyUI | |
위 내용은 MySQL 통계의 자세한 개요의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



