
크롤러에 대해 오랫동안 들어왔습니다. 지난 며칠간 nodejs를 배우기 시작했고 이제 블로그 파크 홈페이지의 기사 제목, 사용자 이름, 읽기 번호, 추천 번호 및 사용자 아바타를 크롤링해 보겠습니다. 짧은 요약.
다음 사항을 사용하세요.
1. 노드의 핵심 모듈 - 파일 시스템
2. http 요청을 위한 타사 모듈 - superagent 3. DOM 구문 분석을 위한 타사 모듈 - -cherio
자세한 내용은 여러 모듈에 대한 설명과 API는 각 링크로 이동하세요. 데모에는 간단한 사용법만 나와 있습니다.
준비
npm을 사용하여 종속성을 관리하고 종속성 정보는 package.json에 저장됩니다
//安装用到的第三方模块 cnpm install --save superagent cheerio
필요한 기능 모듈을 소개하세요
//引入第三方模块,superagent用于http请求,cheerio用于解析DOM
const request = require('superagent');
const cheerio = require('cheerio');
const fs = require('fs');요청 + 구문 분석 페이지
홈페이지의 콘텐츠로 크롤링하려는 경우 먼저 홈페이지 주소를 요청하고 반환된 html을 가져와야 합니다. 여기서 superagent를 사용하여 http 요청을 수행합니다.
request.get(url)
.end(error,res){
//do something
}지정된 get 요청을 시작합니다. url. 요청이 잘못된 경우 오류가 반환됩니다(오류가 없으면 오류는 null이거나 정의되지 않음). res는 반환된 데이터입니다.
html 콘텐츠를 가져온 후에는 우리가 원하는 데이터를 얻어야 합니다. 이때 우리는 DOM을 파싱하기 위해 Cherio를 사용해야 합니다. Cheerio는 먼저 대상 HTML을 로드한 다음 이를 파싱해야 합니다. API는 다음과 매우 유사합니다. jquery의 API. jquery에 익숙하다면 매우 빠르게 시작할 수 있습니다. 코드예제를 직접 보면
//目标链接 博客园首页
let targetUrl = 'https://www.cnblogs.com/';
//用来暂时保存解析到的内容和图片地址数据
let content = '';
let imgs = [];
//发起请求
request.get(targetUrl)
.end( (error,res) => {
if(error){ //请求出错,打印错误,返回
console.log(error)
return;
}
// cheerio需要先load html
let $ = cheerio.load(res.text);
//抓取需要的数据,each为cheerio提供的方法用来遍历
$('#post_list .post_item').each( (index,element) => {
//分析所需要的数据的DOM结构
//通过选择器定位到目标元素,再获取到数据
let temp = {
'标题' : $(element).find('h3 a').text(),
'作者' : $(element).find('.post_item_foot > a').text(),
'阅读数' : +$(element).find('.article_view a').text().slice(3,-2),
'推荐数' : +$(element).find('.diggnum').text()
}
//拼接数据
content += JSON.stringify(temp) + '\n';
//同样的方式获取图片地址
if($(element).find('img.pfs').length > 0){
imgs.push($(element).find('img.pfs').attr('src'));
}
});
//存放数据
mkdir('./content',saveContent);
mkdir('./imgs',downloadImg);
})Storing data
위의 DOM을 파싱한 후 필요한 정보 내용을 스플라이싱하여 이미지의 URL을 얻었으니 이제 그 내용이 txt 파일로 저장됩니다. 지정된 디렉터리에 그림을 다운로드했습니다
먼저 디렉터리를 만들고 nodejs 코어 파일 시스템을 사용하세요
//创建目录
function mkdir(_path,callback){
if(fs.existsSync(_path)){
console.log(`${_path}目录已存在`)
}else{
fs.mkdir(_path,(error)=>{
if(error){
return console.log(`创建${_path}目录失败`);
}
console.log(`创建${_path}目录成功`)
})
}
callback(); //没有生成指定目录不会执行
}지정된 디렉터리가 있으면 데이터를 쓸 수 있습니다. txt 파일의 내용이 이미 있습니다. writeFile()을 사용해서 직접 작성하시면 됩니다
//将文字内容存入txt文件中
function saveContent() {
fs.writeFile('./content/content.txt',content.toString());
}이미지 링크를 얻었으니 슈퍼에이전트를 사용해서 이미지를 다운로드해서 로컬에 저장하셔야 합니다. Superagent는 응답 스트림을 직접 반환한 다음 nodejs 파이프라인과 협력하여 이미지 콘텐츠를 로컬
//下载爬到的图片
function downloadImg() {
imgs.forEach((imgUrl,index) => {
//获取图片名
let imgName = imgUrl.split('/').pop();
//下载图片存放到指定目录
let stream = fs.createWriteStream(`./imgs/${imgName}`);
let req = request.get('https:' + imgUrl); //响应流
req.pipe(stream);
console.log(`开始下载图片 https:${imgUrl} --> ./imgs/${imgName}`);
} )
}Effect
에 직접 쓸 수 있습니다. 데모를 실행하고 효과를 확인하면 데이터가 정상적으로 내려갔습니다
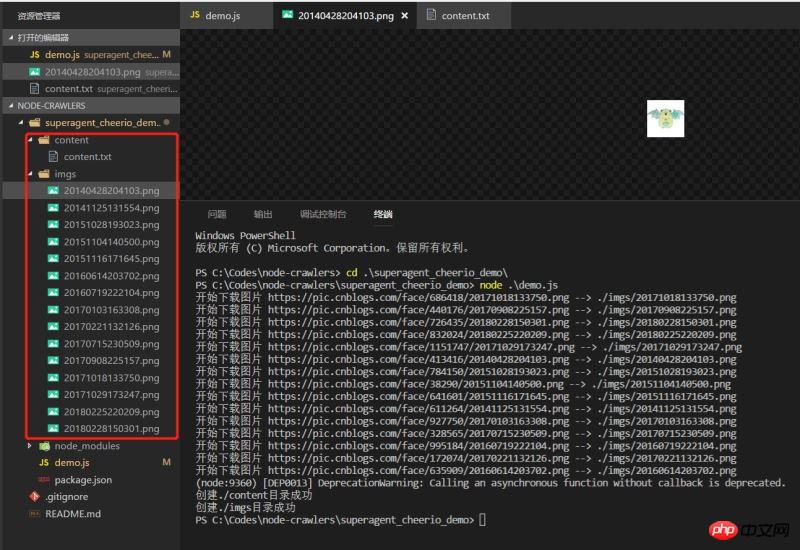 매우 간단한 것 데모는 그다지 엄격하지는 않지만 항상 노드를 향한 첫 번째 작은 단계입니다.
매우 간단한 것 데모는 그다지 엄격하지는 않지만 항상 노드를 향한 첫 번째 작은 단계입니다.
관련 추천:
위 내용은 nodejs 크롤러 슈퍼에이전트 및 치리오 체험사례의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



