

phpspider 크롤러를 사용하는 방법

이 기사에서는 주로 phpspider 크롤러를 사용하는 방법을 공유합니다. Python 크롤러를 사용하는 것이 매우 편리하지만 프레임워크 크롤러를 사용하는 것이 실제로는 훨씬 더 효율적이라는 점을 발견했습니다.
1, 먼저 phpspider
2의 구조를 살펴보세요. 예를 들어 Nanchang News Network
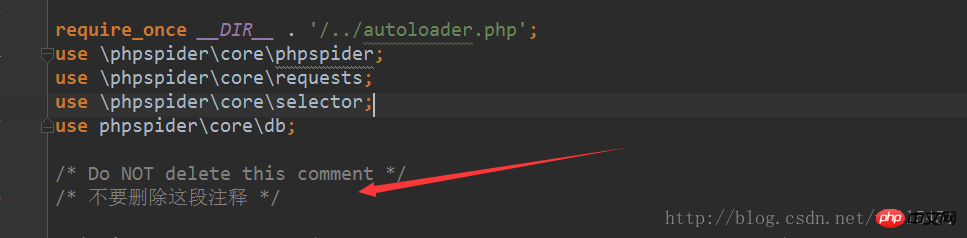
카테고리를 크롤링하면 이 댓글이 추가되어야 하고, 그렇지 않으면 오류가 발생합니다. 보고되면 소스 코드를 살펴볼 수 있습니다. 소스 코드에는
3 많은 메소드가 있습니다. 그런 다음 크롤러를 구성합니다.
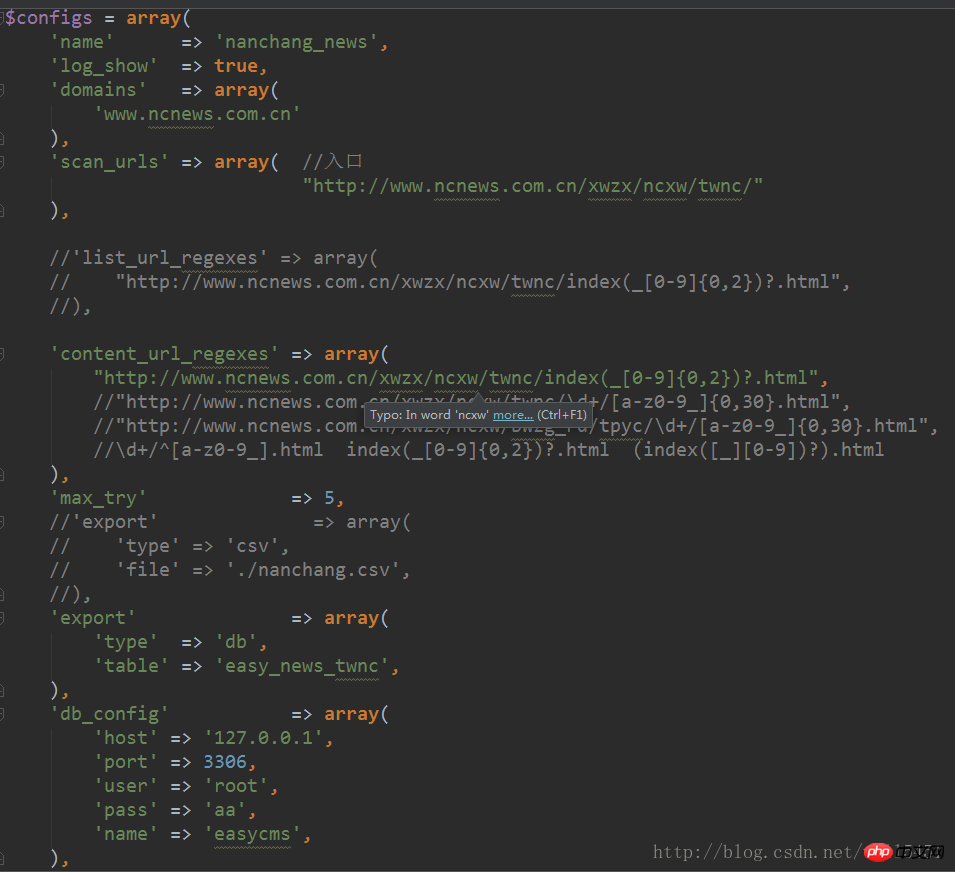

4 그런 다음 구성 파일을 프레임워크에 넣습니다. 클래스 파일 및 인스턴스화:
여기의 on_scan_page는 크롤러입니다. 이 URL은 제가 구성한 content_url_regxes 일반 규칙과 일치하므로 후속 크롤링 프로세스에서 이 페이지의 데이터가
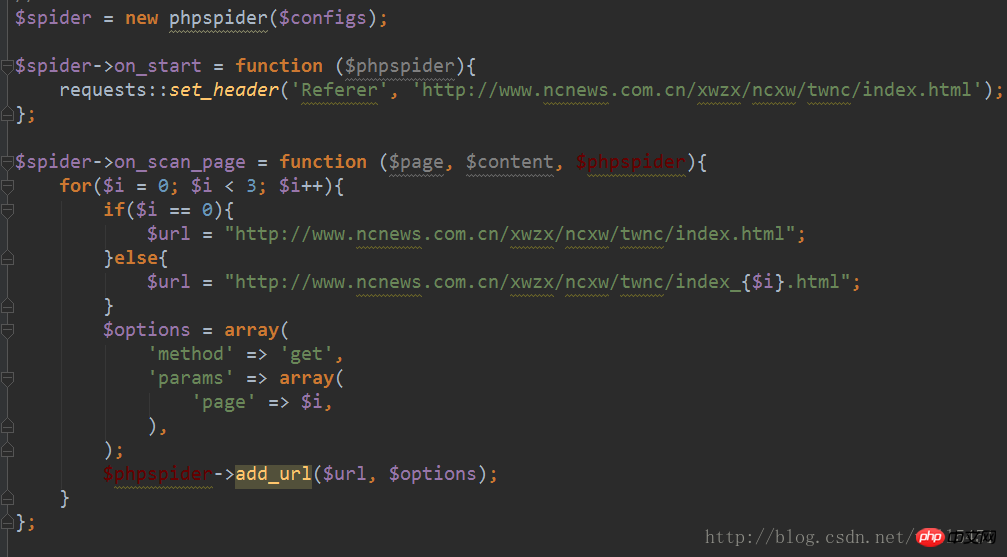
5 크롤링되고 일치하는 필드가 됩니다. 콜백 처리:
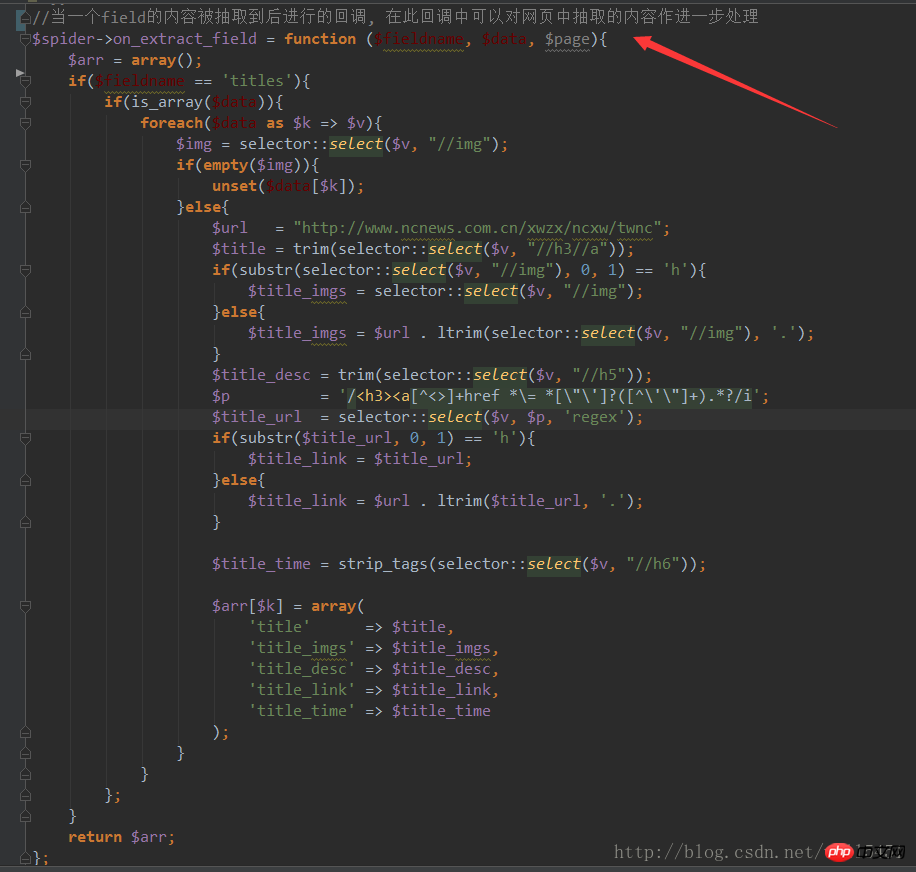
6, 크롤링된 데이터를 데이터베이스로 처리하고 실행합니다.
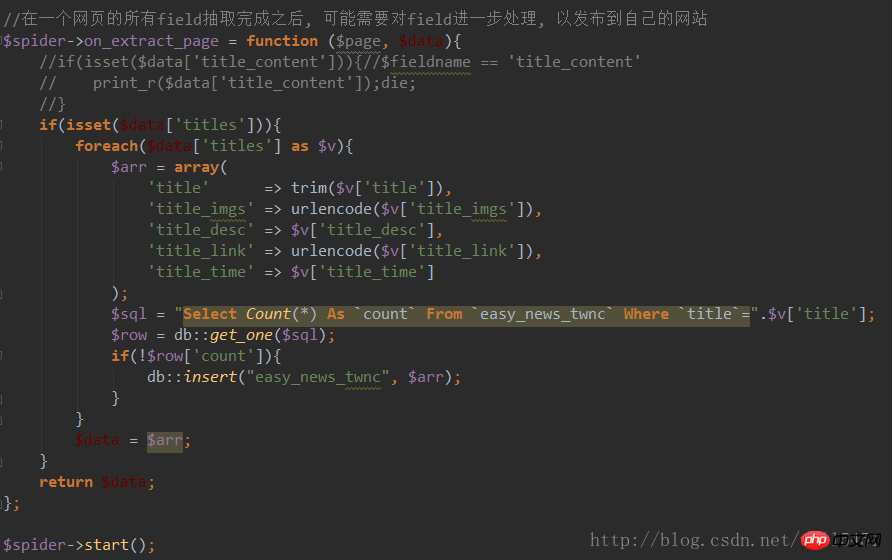
위는 단순한 예일 뿐이며 다중 프로세스 크롤링, 프록시 크롤러도 수행할 수 있습니다. , 그리고 많은 재미.
관련 권장 사항:
위 내용은 phpspider 크롤러를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7403
7403
 15
1630
14
1358
52
1268
25
1218
29
15
1630
14
1358
52
1268
25
1218
29

 CakePHP 프로젝트 구성
Sep 10, 2024 pm 05:25 PM
CakePHP 프로젝트 구성
Sep 10, 2024 pm 05:25 PM
이번 장에서는 CakePHP의 환경 변수, 일반 구성, 데이터베이스 구성, 이메일 구성에 대해 알아봅니다.
 Ubuntu 및 Debian용 PHP 8.4 설치 및 업그레이드 가이드
Dec 24, 2024 pm 04:42 PM
Ubuntu 및 Debian용 PHP 8.4 설치 및 업그레이드 가이드
Dec 24, 2024 pm 04:42 PM
PHP 8.4는 상당한 양의 기능 중단 및 제거를 통해 몇 가지 새로운 기능, 보안 개선 및 성능 개선을 제공합니다. 이 가이드에서는 Ubuntu, Debian 또는 해당 파생 제품에서 PHP 8.4를 설치하거나 PHP 8.4로 업그레이드하는 방법을 설명합니다.



 CakePHP 토론
Sep 10, 2024 pm 05:28 PM
CakePHP 토론
Sep 10, 2024 pm 05:28 PM
CakePHP는 PHP용 오픈 소스 프레임워크입니다. 이는 애플리케이션을 훨씬 쉽게 개발, 배포 및 유지 관리할 수 있도록 하기 위한 것입니다. CakePHP는 강력하고 이해하기 쉬운 MVC와 유사한 아키텍처를 기반으로 합니다. 모델, 뷰 및 컨트롤러 gu
 CakePHP 데이터베이스 작업
Sep 10, 2024 pm 05:25 PM
CakePHP 데이터베이스 작업
Sep 10, 2024 pm 05:25 PM
CakePHP에서 데이터베이스 작업은 매우 쉽습니다. 이번 장에서는 CRUD(생성, 읽기, 업데이트, 삭제) 작업을 이해하겠습니다.

