
때때로 업무나 필요에 따라 필요한 데이터를 얻기 위해 여러 웹사이트를 탐색하게 되면서 크롤러가 탄생하게 되었습니다. 다음은 간단한 크롤러를 개발하는 과정과 제가 겪은 문제입니다.
크롤러를 개발하려면 먼저 크롤러가 어떤 용도로 사용될지 알아야 합니다. 다양한 웹사이트에서 특정 키워드가 포함된 기사를 찾고, 해당 기사의 링크를 얻어 빠르게 읽을 수 있도록 하고 싶습니다.
개인 습관에 따라 먼저 인터페이스를 작성하고 아이디어를 명확히 해야 합니다.
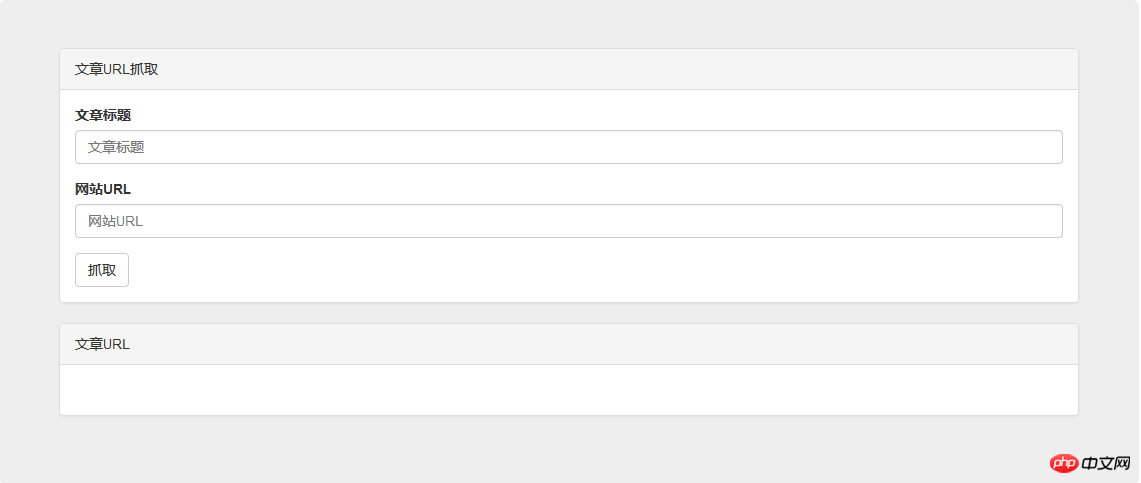
1. 다른 웹사이트로 이동합니다. 그런 다음 URL 입력 상자가 필요합니다.
2. 특정 키워드가 포함된 기사를 찾아보세요. 그런 다음 기사 제목 입력 상자가 필요합니다.
3. 기사 링크를 받으세요. 그런 다음 검색 결과를 표시하는 컨테이너가 필요합니다.
<p class="jumbotron" id="mainJumbotron">
<p class="panel panel-default">
<p class="panel-heading">文章URL抓取</p>
<p class="panel-body">
<p class="form-group">
<label for="article_title">文章标题</label>
<input type="text" class="form-control" id="article_title" placeholder="文章标题">
</p>
<p class="form-group">
<label for="website_url">网站URL</label>
<input type="text" class="form-control" id="website_url" placeholder="网站URL">
</p>
<button type="submit" class="btn btn-default">抓取</button>
</p>
</p>
<p class="panel panel-default">
<p class="panel-heading">文章URL</p>
<p class="panel-body">
<h3></h3>
</p>
</p>
</p>코드를 직접 입력하고 스타일을 직접 조정하면 인터페이스가 완성됩니다.
다음 단계는 PHP를 사용하여 함수를 구현하는 것입니다. 첫 번째 단계는 얻는 것입니다. 웹사이트의 html 코드를 얻는 방법은 다양하므로 하나씩 소개하지는 않겠습니다. 여기서는 Curl을 사용하여 html 코드를 얻습니다.
private function get_html($url){
$ch = curl_init();
$timeout = 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
return $html;
}HTML 코드를 얻었지만 곧 문제, 즉 인코딩 문제에 직면하게 될 것이며, 이로 인해 일치의 다음 단계가 헛될 수 있습니다. 여기서는 얻은 HTML 콘텐츠를 utf8 인코딩으로 균일하게 변환합니다.
$coding = mb_detect_encoding($html); if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8")) $html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
得到网站的html,要获取文章的url,那么下一步就是要匹配该网页下的所有a标签,需要用到正则表达式,经过多次测试,最终得到一个比较靠谱的正则表达式,不管a标签下结构多复杂,只要是a标签的都不放过:(最关键的一步)
$pattern = '|<a[^>]*>(.*)</a>|isU'; preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,它大概是这样的一个多维素组:
array(2) {
[0]=>
array(*) {
[0]=>
string(*) "完整的a标签"
.
.
.
}
[1]=>
array(*) {
[0]=>
string(*) "与上面下标相对应的a标签中的内容"
}
}只要能得到这个数据,其他就完全可以操作啦,你可以遍历这个素组,找到你想要a标签,然后获取a标签相应的属性,想怎么操作就怎么操作啦,下面推荐一个类,让你更方便操作a标签:
$dom = new DOMDocument();
@$dom->loadHTML($a);//$a是上面得到的一些a标签
$url = new DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //这里获取a标签的href属性
}当然,这只是一种方式,你也可以通过正则表达式匹配你想要的信息,把数据玩出新花样。
得到并匹配得出你想要的结果,下一步当然就是传回前端将他们显示出来啦,把接口写好,然后前端用js获取数据,用jquery动态添加内容显示出来:
var website_url = '你的接口地址';
$.getJSON(website_url,function(data){
if(data){
if(data.text == ''){
$('#article_url').html('<p><p>暂无该文章链接</p></p>');
return;
}
var string = '';
var list = data.text;
for (var j in list) {
var content = list[j].url_content;
for (var i in content) {
if (content[i].title != '') {
string += '<p class="item">' +
'<em>[<a href="http://' + list[j].website.web_url + '" target="_blank">' + list[j].website.web_name + '</a>]</em>' +
'<a href=" ' + content[i].url + '" target="_blank" class="web_url">' + content[i].title + '</a>' +
'</p>';
}
}
}
$('#article_url').html(string);
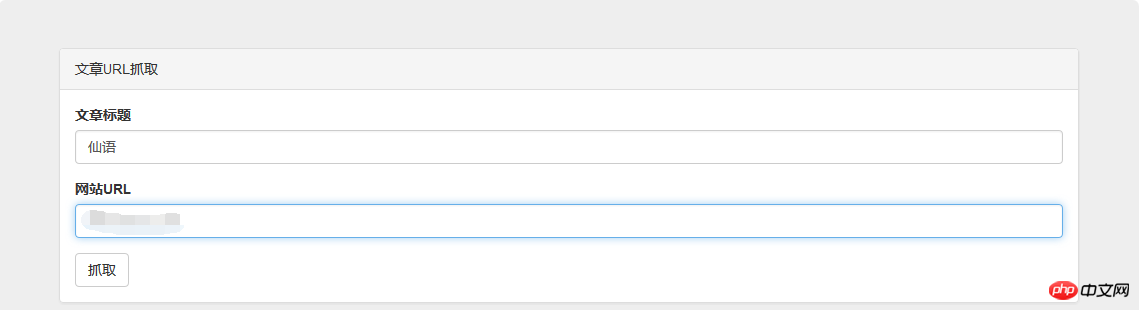
});上最终效果图:

위 내용은 PHP로 간단한 크롤러를 구현한 개발 사례의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



