
ELK는 현재 가장 인기 있는 중앙 집중식 로그 솔루션이 되었습니다. 주로 Beats, Logstash, Elasticsearch, Kibana 및 기타 구성 요소로 구성되어 실시간 로그의 수집, 저장, 표시 및 기타 원스톱 솔루션을 공동으로 완성합니다. 이번 글에서는 주로 분산 실시간 로그 분석 솔루션의 ELK 배포 아키텍처를 소개합니다. 도움이 필요한 친구들은 한 번 살펴보세요
1. 개요 ELK는 현재 가장 널리 사용되는 중앙 집중식 로깅 솔루션이 되었습니다. 주로 Beats, Logstash로 구성됩니다. , Elasticsearch 및 Kibana 실시간 로그의 수집, 저장, 표시 및 기타 원스톱 솔루션을 공동으로 완성하기 위해 다른 구성 요소로 구성됩니다. 이 기사에서는 ELK의 일반적인 아키텍처를 소개하고 관련 문제를 해결합니다.강좌 추천→:"Elasticsearch 전체 텍스트 검색 실습"(실습 영상)
Lucene을 기반으로 구현된 분산 데이터 검색 엔진은 클러스터링이 가능하고 중앙 집중식 데이터 저장, 분석, 강력한 데이터 검색 및 집계 기능을 제공합니다.
2.1. 로그 수집기로서의 Logstash
이 아키텍처는 상대적으로 원시적인 배포 아키텍처입니다. Logstash 구성 요소는 로그 수집기로 각 애플리케이션 서버에 배포됩니다. Logstash에 의해 수집된 정보는 필터링, 분석 및 포맷된 후 Elasticsearch 스토리지로 전송되며, 최종적으로 Kibana는 시각적 표시에 사용됩니다. 이 아키텍처의 단점은 Logstash가 서버 리소스를 소비하므로 애플리케이션 서버의 부하 압력이 증가한다는 것입니다.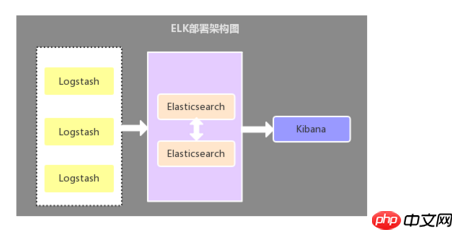
2.2. 로그 수집기로서의 Filebeat
이 아키텍처와 첫 번째 아키텍처의 유일한 차이점은 애플리케이션 측 로그 수집기가 Filebeat로 대체된다는 것입니다. 이므로 Filebeat를 애플리케이션 서버의 로그 수집기로 사용합니다. 일반적으로 Filebeat는 Logstash와 함께 사용되며 현재 가장 일반적으로 사용되는 아키텍처이기도 합니다.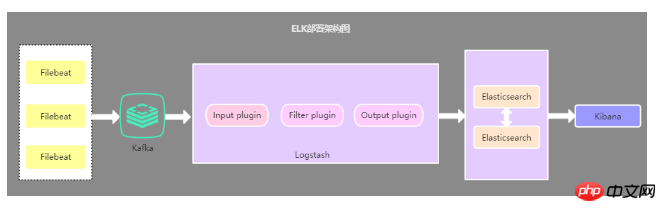
2.3. 캐시 큐를 도입한 배포 아키텍처
이 아키텍처는 Filebeat에서 수집한 데이터를 Kafka로 전송하는 두 번째 아키텍처를 기반으로 Kafka 메시지 큐(다른 메시지 큐일 수도 있음)를 도입합니다. Logstasth를 통해 Kafka의 데이터를 읽습니다. 이 아키텍처는 주로 대용량 데이터의 로그 수집 솔루션을 해결하는 데 사용됩니다. 캐시 큐의 사용은 주로 Logstash와 Elasticsearch의 로드 압력 균형을 맞추는 데 사용됩니다.
2.4.위의 세 가지 아키텍처 요약
첫 번째 배포 아키텍처는 리소스 점유 문제로 인해 거의 사용되지 않습니다. 개인적으로는 세 번째 배포 아키텍처가 가장 많이 사용됩니다. 다른 요구 사항이 없는 한 배포 아키텍처에 메시지 대기열을 도입할 필요가 없습니다. 왜냐하면 데이터 양이 많을 때 Filebeat는 압력 감지 프로토콜을 사용하여 데이터를 Logstash 또는 Elasticsearch로 보내기 때문입니다. Logstash가 데이터 처리에 바쁜 경우 Filebeat에 읽기 속도를 늦추라고 지시합니다. 정체가 해결되면 Filebeat는 원래 속도를 재개하고 데이터 전송을 계속합니다. 커뮤니케이션 및 학습 그룹 추천: 478030634, 수석 설계자가 녹화한 일부 비디오(Spring, MyBatis, Netty 소스 코드 분석, 높은 동시성, 고성능, 분산, 마이크로서비스 아키텍처, JVM 성능 최적화 등의 원칙)가 녹화한 비디오를 공유합니다. A 건축가에게 꼭 필요한 지식 시스템. 또한 무료 학습 리소스를 받고 지금까지 많은 혜택을 누릴 수 있습니다.
질문: 로그의 여러 줄 병합 기능을 구현하는 방법은 무엇입니까?
시스템 애플리케이션의 로그는 일반적으로 특정 형식으로 인쇄되므로 동일한 로그에 속한 데이터가 여러 줄로 인쇄될 수 있습니다. 따라서 ELK를 사용하여 로그를 수집하는 경우 동일한 로그에 속한 데이터를 여러 줄로 병합해야 합니다.
해결책: Filebeat 또는 Logstash에서 다중 행 다중 행 병합 플러그인을 사용하여
다중 행 다중 행 병합 플러그인을 사용할 때 다양한 ELK 배포 아키텍처가 다중 행을 다르게 사용할 수 있다는 사실에 주의해야 합니다. 기사라면 첫 번째 배포 아키텍처라면 Logstash에서 멀티라인을 구성하고 사용해야 하며, 두 번째 배포 아키텍처라면 Filebeat에서 멀티라인을 구성하여 사용해야 합니다. 로그스태시에서.
1. Filebeat에서 여러 줄을 구성하는 방법:
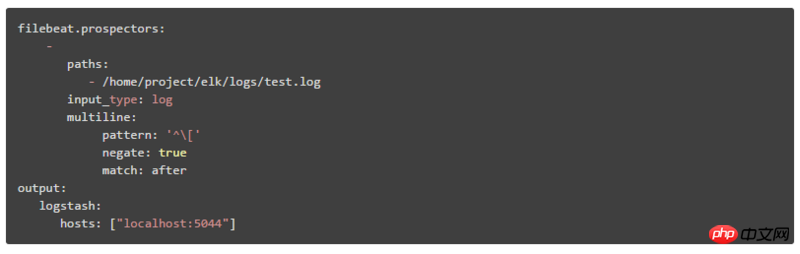
pattern: 정규 표현식
negate: 기본값은 false이며, 이는 패턴과 일치하는 줄이 이전 줄에 병합됨을 의미합니다. true는 패턴과 일치하지 않는 줄이 이전 줄로 병합됨을 의미합니다
match: after는 이전 줄의 끝으로 병합됨을 의미하고 before는 이전 줄의 시작 부분으로 병합됨을 의미합니다
예:
pattern: '['
negate: true
match: after
이 구성은 패턴 패턴과 일치하지 않는 줄을 이전 줄의 끝 부분에 병합한다는 의미입니다
2 Logstash에서 여러 줄을 구성하는 방법

(1) Logstash에 구성된 what 속성 값은 이전으로 Filebeat의 after와 동일하고, Logstash에 구성된 what 속성의 값은 next로 Filebeat의 before와 동일합니다.
(2) 패턴 => "%{LOGLEVEL}s*]" "%{LOGLEVEL}s*]"의 LOGLEVEL은 Logstash가 미리 만들어 놓은 정규 매칭 패턴입니다. https://github.com /logstash-p...
질문: Kibana에 표시된 로그의 시간 필드를 로그 정보의 시간으로 바꾸는 방법은 무엇입니까?
기본적으로 Kibana에서 보는 시간 필드는 로그 정보의 시간과 일치하지 않습니다. 기본 시간 필드 값은 로그가 수집되는 현재 시간이므로 이 필드의 시간을 다음으로 바꿔야 합니다. 로그 정보의 시간입니다.
해결책: grok 단어 분할 플러그인 및 날짜 시간 형식 지정 플러그인을 사용하여
Logstash 구성 파일 필터에서 grok 단어 분할 플러그인 및 날짜 시간 형식 지정 플러그인 구성:

일치할 로그 형식이 "DEBUG[DefaultBeanDefinitionDocumentReader:106] Loading bean 정의"인 경우 로그의 시간 필드를 구문 분석하는 방법은 다음과 같습니다.
① 작성된 표현식 파일을 도입하여 예를 들어 표현식 파일은 customer_patterns이고 내용은 다음과 같습니다.
CUSTOMER_TIME %{YEAR}%{MONTHNUM}%{MONTHDAY}s+%{TIME}
참고: 내용 형식은 [사용자 정의 표현식 이름] [정규 표현식]
그런 다음 logstash에서 다음과 같이 인용할 수 있습니다.

② 구성 항목의 형태에서 규칙은 다음과 같습니다. (?정규 일치 규칙), 예:

질문: Kibana에서 전달하는 방법 데이터를 보려면 다양한 시스템 로그 모듈을 선택하세요
일반적으로 Kibana에 표시되는 로그 데이터는 다양한 시스템 모듈의 데이터가 혼합되어 있으므로 로그 데이터만 보려면 선택하거나 필터링하는 방법 지정된 시스템 모듈의?
해결책: 다양한 시스템 모듈을 식별하는 새 필드를 추가하거나 다양한 시스템 모듈을 기반으로 ES 인덱스를 구축하세요
1. 다양한 시스템 모듈을 식별하는 새 필드를 추가한 다음 Kibana에서 결과를 필터링하고 쿼리할 수 있습니다. 이 필드를 기반으로 하는 다양한 모듈의 Data
두 번째 배포 아키텍처는 여기에서 설명하는 데 사용됩니다. Filebeat의 구성 콘텐츠는 다음과 같습니다. log_from 필드를 추가하여 다양한 시스템 모듈 로그를 식별합니다
2. 시스템 모듈 구성 ES 인덱스를 선택한 다음 Kibana에서 일치하는 해당 인덱스 패턴을 생성합니다. 페이지의 인덱스 패턴 드롭다운 상자를 통해 다양한 시스템 모듈 데이터를 선택할 수 있습니다. 두 번째 배포 아키텍처는 여기에서 설명되며 두 단계로 나뉩니다. 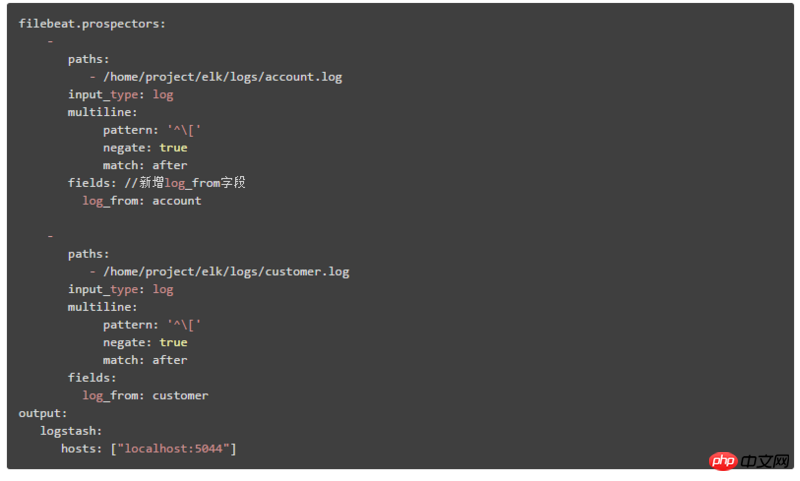 ① Filebeat의 구성 콘텐츠는 다음과 같습니다.
① Filebeat의 구성 콘텐츠는 다음과 같습니다.
document_type을 통해 다양한 시스템 모듈을 식별합니다.
② Logstash의 출력 구성 콘텐츠를 다음과 같이 수정합니다. 출력에 인덱스 속성을 추가합니다. %{type}은 다양한 document_type 값에 따라 ES 인덱스를 구축한다는 의미입니다 이 글에서는 ELK 실시간 로그 분석의 3가지 배포 아키텍처를 주로 소개하며, 이 3가지 아키텍처 중 두 번째 배포 방법이 현재 가장 널리 사용되고 널리 사용되는 배포 방법입니다. 마지막으로 로그 분석에서 ELK의 몇 가지 문제점과 해결 방법을 소개합니다. 결국 ELK는 분산 로그 데이터의 중앙 쿼리 및 관리에 사용될 수 있을 뿐만 아니라 프로젝트 애플리케이션 및 서버 리소스 모니터링 및 기타 시나리오에도 사용될 수 있습니다. . 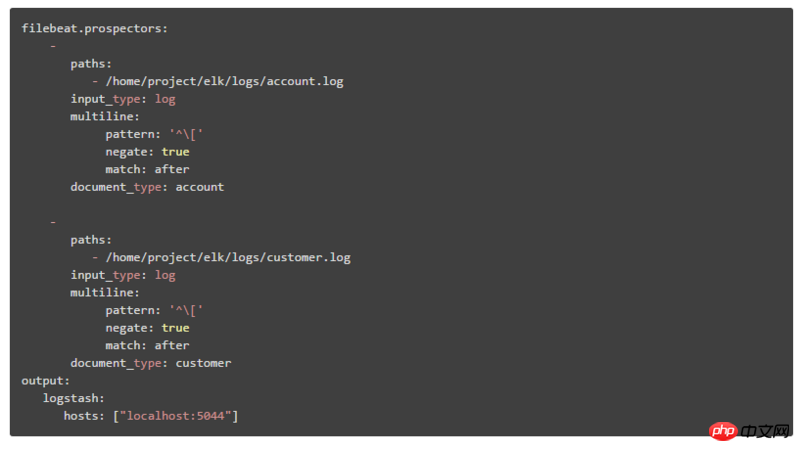
IV.Summary
위 내용은 분산 실시간 로그 분석 솔루션 ELK 배포 아키텍처의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



