
이 기사의 내용은 Python을 사용하여 NetEase Cloud Music에서 인기 있는 댓글을 크롤링하는 방법을 공유하는 것입니다. 여기에는 특정 참조 가치가 있습니다. 도움이 필요한 친구는 이를 참조할 수 있습니다.
최근 텍스트 마이닝 관련 콘텐츠를 공부하고 있는데, 좋은 여자는 빨대 없이는 밥을 못 짓는다고 합니다. 텍스트 분석을 하려면 먼저 텍스트가 있어야 합니다. 텍스트를 얻는 방법은 인터넷에서 미리 만들어진 텍스트 문서를 다운로드하거나 제3자가 제공하는 API를 통해 데이터를 얻는 등 여러 가지가 있습니다. 하지만 데이터를 얻을 수 있는 직접 다운로드 채널이나 API가 없기 때문에 원하는 데이터를 직접 얻을 수 없는 경우도 있습니다. 그렇다면 이때 우리는 무엇을 해야 할까요? 더 좋은 방법은 웹 크롤러를 사용하는 것인데, 이는 원하는 데이터를 얻기 위해 사용자인 것처럼 가장하는 컴퓨터 프로그램을 작성하는 것입니다.
컴퓨터의 효율성을 이용하여 쉽고 빠르게 데이터를 얻을 수 있습니다.
크롤러 정보
그렇다면 크롤러를 작성하는 방법은 무엇일까요? 크롤러를 작성하는 데 사용할 수 있는 언어는 Java, PHP, Python 등 여러 가지가 있습니다. 저는 개인적으로 Python을 사용하는 것을 선호합니다. Python에는 강력한 네트워크 라이브러리가 내장되어 있을 뿐만 아니라 뛰어난 타사 라이브러리도 많이 있기 때문에 다른 사람들이 직접 휠을 구축했고 우리는 이를 사용하면 크롤러 작성에 큰 편리함을 제공합니다. 실제로 10줄 미만의 Python 코드로 작은 크롤러를 작성할 수 있다고 해도 과언이 아니지만, 다른 언어를 사용하려면 훨씬 더 많은 코드를 작성해야 할 수 있습니다.
간단하고 이해하기 쉽다는 것입니다. Python의 큰 장점. 자, 더 이상 고민하지 말고 오늘의 주요 주제로 들어가겠습니다. NetEase Cloud Music은 최근 몇 년 동안 큰 인기를 끌었습니다. 저는 NetEase Cloud Music의 사용자이며 몇 년 동안 사용해 왔습니다. 저는 QQ뮤직과 쿠거우를 사용해본 적이 있는데, NetEase Cloud Music의 가장 큰 특징은 정확한 노래 추천과 독특한 사용자 댓글이라고 생각합니다
(참고로!!! 이건 부드러운 기사가 아닙니다. 광고입니다! 개인적인 의견이니 비난은 삼가해주세요!)
네트워크 라이브러리
라는 두 개의 내장 네트워크 라이브러리가 있지만 이 두 라이브러리는 사용하기가 특별히 편리하지 않으므로 여기서는 널리 사용되는 타사 라이브러리 요청. 요청을 사용하면 단 몇 줄의 코드만으로 에이전트 설정 및 로그인 시뮬레이션과 같은 보다 복잡한 크롤러 작업을 수행할 수 있습니다. 이미 pip을 설치한 경우 pip 설치 요청을 사용하여 설치하세요. Chinese 문서 주소는 http://docs.python-requests.org/zh_cn/latest/user/quickstart.html
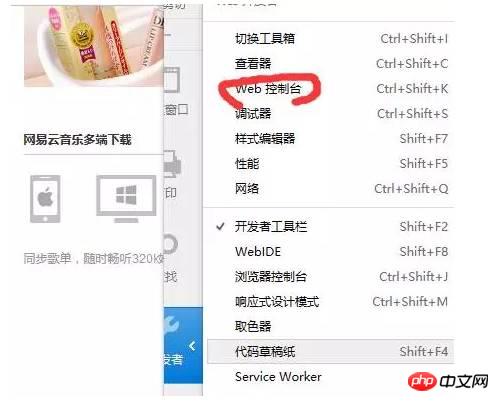
무엇을 가지고 있습니까? ? 질문이 있는 경우 매우 자세한 소개를 제공하는 공식 문서를 참조할 수 있습니다. urllib와 urllib2라는 두 라이브러리도 꽤 유용합니다. 나중에 기회가 된다면 소개하겠습니다. 작동 원리크롤러를 공식적으로 소개하기 전에 먼저 크롤러의 기본 작동 원리에 대해 이야기해 보겠습니다. 브라우저를 열고 특정 URL을 방문하면 기본적으로 요청 코드를 사용한다면 브라우저의 이 단계를 건너뛰고 그러나 문제는 때때로 서버가 우리가 보낸 요청을 확인해야 한다는 것입니다. 요청이 불법이라고 생각되면 데이터를 반환하지 않거나 잘못된 데이터를 반환합니다. 따라서 이러한 상황을 피하기 위해 서버로부터 성공적으로 응답을 받기 위해 때때로 프로그램을 일반 사용자로 위장해야 합니다. 변장하는 방법? 이는 사용자가 브라우저를 통해 웹 페이지에 액세스하는 것과 우리가 프로그램을 통해 웹 페이지에 액세스하는 것의 차이에 따라 다릅니다. 접속한 URL 외에 헤더(헤더 정보) 등의 추가 정보도 서비스로 전송됩니다. 따라서 서버는 요청된 신원 인증서를 볼 때 우리가 일반 브라우저를 통해 액세스하고 있음을 알고 순종적으로 우리에게 데이터를 반환합니다. 따라서 우리 프로그램은 브라우저처럼 요청을 보낼 때 우리의 신원을 표시하는 정보를 가져와 데이터를 원활하게 얻을 수 있어야 합니다. 때로는 데이터를 얻기 위해 로그인해야 하므로 로그인을 시뮬레이션해야 합니다. 기본적으로 브라우저를 통해 로그인한다는 것은 일부 양식 정보(사용자 이름, 비밀번호 및 기타 정보 포함)를 서버에서 확인한 후 원활하게 로그인할 수 있음을 의미합니다. 브라우저는 어떤 데이터가 게시되어도 그대로 보낼 수 있습니다. 시뮬레이션 로그인에 대해서는 나중에 구체적으로 소개하겠습니다. 물론 일부 웹사이트에서는 크롤링 방지 조치를 설정했기 때문에 상황이 원활하게 진행되지 않을 때도 있습니다. 예를 들어 접속 속도가 너무 빠르면 IP 주소가 차단되는 경우도 있습니다(일반적으로 Douban). 이때 프록시 서버를 설정해야 합니다. 즉, IP 주소를 변경해야 합니다. 하나의 IP가 차단된 경우 이를 다른 IP로 변경하는 방법은 나중에 설명하겠습니다. Tips 마지막으로 크롤러를 작성하는 과정에서 매우 유용하다고 생각되는 작은 트릭을 소개하겠습니다. Firefox 또는 Chrome을 사용하는 경우 개발자 도구(chrome) 또는 웹 콘솔(firefox)이라는 곳을 발견했을 수 있습니다. 이 도구를 사용하면 웹 사이트를 방문할 때 브라우저가 보내는 정보와 서버가 반환하는 정보를 명확하게 확인할 수 있기 때문에 매우 유용합니다. 이 정보는 크롤러 작성의 핵심입니다. 아래에서 이것이 얼마나 유용한지 확인할 수 있습니다. 댓글 크롤링 방법 먼저 NetEase Cloud Music의 웹 버전을 열고 노래를 선택하여 웹 페이지를 엽니다. 여기서는 주걸륜의 "Sunny Day"를 예로 들어 보겠습니다. 아래와 같이:
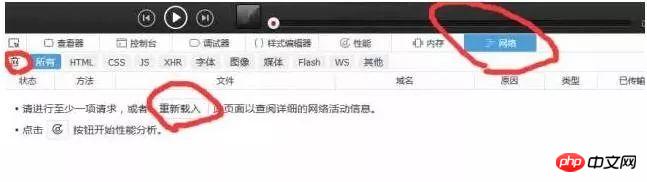
다음으로, 아래와 같이 웹 콘솔을 엽니다(크롬용 개발자 도구를 엽니다. 다른 브라우저에서도 비슷해야 합니다). 그런 다음 이때 네트워크를 클릭하고 모든 정보를 지운 다음 재전송(브라우저 새로 고침과 동일)을 클릭해야 브라우저가 보내는 정보와 서버 응답 어떤 정보. 아래와 같이
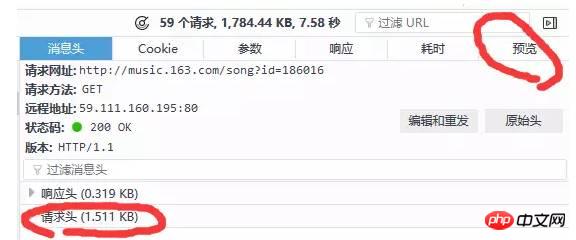
새로 고침 후 얻은 데이터는 다음과 같습니다. 브라우저에서 많은 정보가 전송된 것을 확인할 수 있습니다. 그래서 우리가 원하는 것은 무엇입니까? 여기서는 상태 코드를 통해 예비적인 판단을 내릴 수 있습니다. 상태 코드(status code)는 서버 요청의 상태를 나타냅니다. 여기서 상태 코드 200은 요청이 정상이라는 것을 의미하고, 304는 요청이 정상이라는 것을 의미합니다. 비정상 (상태코드 종류가 많이 있습니다. 더 알고 싶으시면 직접 검색해보시면 됩니다. 여기서 304의 구체적인 의미는 다루지 않겠습니다.). 따라서 일반적으로 상태 코드가 200인 요청만 보면 됩니다. 또한 오른쪽 열의 미리보기를 통해 서버가 어떤 정보를 반환하는지(또는 응답을 보는지) 대략적으로 관찰할 수 있습니다. 아래와 같이
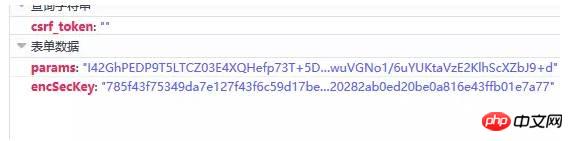
라는 두 가지 요청 방법이 있습니다. 집중해야 할 또 다른 사항은 user-Agent(고객 터미널)가 포함된 요청 헤더입니다. 정보), 참조(점프 위치) 및 기타 정보 일반적으로 get 또는 post 메소드인지 헤더 정보를 가져옵니다. 헤더 정보는 다음과 같습니다. 또한 요청 가져오기의 경우 일반적으로 요청 매개변수가 ?로 직접 변경된다는 점에 유의해야 합니다. 매개변수1=value1¶meter2=value2 등은 이 형식으로 전송되므로 추가 요청 매개변수를 가져올 필요가 없습니다. 게시물 요청은 일반적으로 매개변수를 URL에 직접 배치하는 대신 추가 매개변수를 가져와야 하므로 때로는 매개변수 열에 주의하세요. 주의 깊게 검색한 끝에 마침내 아래와 같이 요청 http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016?csrf_token=에서 원래 댓글 관련 요청을 발견했습니다. 요청에 두 개의 매개변수가 있는 것을 확인했습니다. 하나는 params이고 다른 하나는 encSecKey입니다. 매우 길어요. 암호화된 것처럼 느껴져야 합니다. 아래와 같이
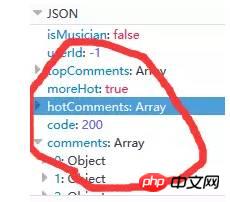
서버에서 반환되는 댓글 관련 데이터는 json 형식으로 매우 풍부한 정보(댓글 작성자 정보, 댓글 날짜 등)를 담고 있습니다. , 좋아요 수, 댓글 내용 등), 아래 그림 9와 같이: (사실 hotComments는 핫 댓글이고 댓글은 댓글의 배열입니다.) 이 시점에서 우리는 방향을 결정했습니다. 즉, params와 encSecKey의 두 매개변수 값만 결정하면 됩니다. 이 문제는 오후 내내 나를 괴롭혔습니다. 시간이 지났는데도 이 두 매개변수의 암호화 방식을 알 수 없습니다. 그런데 패턴을 발견했습니다. http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016?csrf_token= 그 이후의 숫자입니다. R_SO_4_ 은 이 노래의 id 값이고, 서로 다른 노래의 Param 및 encSecKey 값의 경우 A와 같은 이 두 매개변수 값이 노래 B에 전달되면 페이지 수가 같으면 이 매개변수는 보편적입니다. 즉, A의 첫 번째 페이지 두 개의 매개변수 값을 다른 노래의 두 매개변수에 전달하면 해당 노래의 첫 번째 페이지에 대한 설명을 얻을 수 있습니다. 두 번째 페이지, 세 번째 페이지 등도 마찬가지입니다. 하지만 안타깝게도 다른 페이지 번호 매개변수는 다릅니다. 이 방법은 제한된 수의 페이지만 크롤링할 수 있습니다(물론 원하는 경우 총 댓글 수와 인기 댓글을 크롤링하는 데 충분합니다). 모든 데이터를 캡처하려면 이 두 매개변수 값의 암호화 방법을 이해해야 합니다. 제가 이해하지 못했다고 생각했는데 어젯밤에 Zhihu에 가서 이 질문을 검색했는데 실제로 답을 찾았습니다. @ Flat-chested Little Fairy 이 친구는 이 두 매개변수의 암호화 프로세스를 해독하는 방법을 자세히 설명했습니다. 연구한 결과 friend가 작성한 방법에 따라 약간 변경한 내용이 있습니다. 모든 댓글을 성공적으로 획득했습니다. Zhihu@납작가슴요정님께 감사의 말씀을 전하고 싶습니다. 지금까지 NetEase Cloud Music 댓글의 모든 데이터를 캡처하는 방법에 대한 설명을 마쳤습니다. 평소와 마찬가지로 코드를 마지막에 업로드했고 자체 테스트에서는 작동했습니다. 위 코드를 사용하여 뛰어다녔고 Jay Chou의 인기곡 "Sunny Day"(130만 개 이상의 댓글 포함) 두 곡을 포착했고 '고백풍선'(댓글 2만개)은 전자가 20분 정도 걸렸고, 후자는 6,600초 이상(즉 거의 2시간)이 걸렸습니다. 스크린샷은 다음과 같습니다. 이 내용이 포함됩니다. 학생들 (서버가 데이터를 매우 느리게 반환하는 기간이 있었습니다. 저는 그렇지 않습니다. 액세스가 제한되었는지 알고 있었지만 나중에는 더 좋아졌습니다. ). 나중에 댓글 데이터에 대한 시각적 분석을 직접 수행할 수도 있으니 계속 지켜봐 주시기 바랍니다! 부록: 마음이 따뜻해지는 댓글
시뮬레이션된 로그인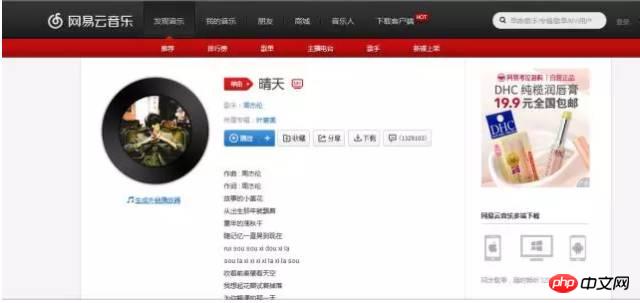

이 두 가지 방법을 결합하면 분석하려는 요청을 빠르게 찾을 수 있습니다. 그림 5의 요청 URL 열은 우리가 요청하려는 URL입니다. 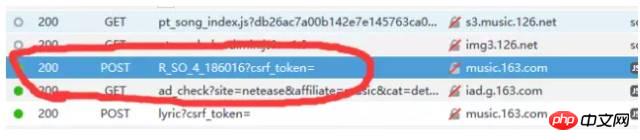
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
# @Time : 2017/3/28 8:46
# @Author : Lyrichu
# @Email : 919987476@qq.com
# @File : NetCloud_spider3.py '''
@Description:
网易云音乐评论爬虫,可以完整爬取整个评论
部分参考了@平胸小仙女的文章
来源:知乎
''' from Crypto.Cipher import AES
import base64
import requests
import json
import codecs
import time
# 头部信息
headers = {
'Host':"music.163.com",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Cookie':"_ntes_nnid=754361b04b121e078dee797cdb30e0fd,1486026808627; _ntes_nuid=754361b04b121e078dee797cdb30e0fd; JSESSIONID-WYYY=yfqt9ofhY%5CIYNkXW71TqY5OtSZyjE%2FoswGgtl4dMv3Oa7%5CQ50T%2FVaee%2FMSsCifHE0TGtRMYhSPpr20i%5CRO%2BO%2B9pbbJnrUvGzkibhNqw3Tlgn%5Coil%2FrW7zFZZWSA3K9gD77MPSVH6fnv5hIT8ms70MNB3CxK5r3ecj3tFMlWFbFOZmGw%5C%3A1490677541180; _iuqxldmzr_=32; vjuids=c8ca7976.15a029d006a.0.51373751e63af8; vjlast=1486102528.1490172479.21; __gads=ID=a9eed5e3cae4d252:T=1486102537:S=ALNI_Mb5XX2vlkjsiU5cIy91-ToUDoFxIw; vinfo_n_f_l_n3=411a2def7f75a62e.1.1.1486349441669.1486349607905.1490173828142; P_INFO=m15527594439@163.com|1489375076|1|study|00&99|null&null&null#hub&420100#10#0#0|155439&1|study_client|15527594439@163.com; NTES_CMT_USER_INFO=84794134%7Cm155****4439%7Chttps%3A%2F%2Fsimg.ws.126.net%2Fe%2Fimg5.cache.netease.com%2Ftie%2Fimages%2Fyun%2Fphoto_default_62.png.39x39.100.jpg%7Cfalse%7CbTE1NTI3NTk0NDM5QDE2My5jb20%3D; usertrack=c+5+hljHgU0T1FDmA66MAg==; Province=027; City=027; _ga=GA1.2.1549851014.1489469781; __utma=94650624.1549851014.1489469781.1490664577.1490672820.8; __utmc=94650624; __utmz=94650624.1490661822.6.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; playerid=81568911; __utmb=94650624.23.10.1490672820",
'Connection':"keep-alive",
'Referer':'http://music.163.com/' }
# 设置代理服务器
proxies= {
'http:':'http://121.232.146.184',
'https:':'https://144.255.48.197'
}
# offset的取值为:
(评论页数-1)*20,total第一页为true,其余页为false # first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
# 第一个参数 second_param = "010001"
# 第二个参数
# 第三个参数 third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
# 第四个参数 forth_param = "0CoJUm6Qyw8W8jud"
# 获取参数 def get_params(page):
# page为传入页数
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
if(page == 1): # 如果为第一页
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page-1)*20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' %(offset,'false')
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
# 获取 encSecKey
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
# 解密过程
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
# 获得评论json数据
def get_json(url, params, encSecKey):
data = {
"params": params,
"encSecKey": encSecKey
}
response = requests.post(url, headers=headers, data=data,proxies = proxies)
return response.content
# 抓取热门评论,返回热评列表
def get_hot_comments(url):
hot_comments_list = []
hot_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容")
params = get_params(1) # 第一页
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
hot_comments = json_dict['hotComments'] # 热门评论
print("共有%d条热门评论!" % len(hot_comments))
for item in hot_comments:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userID'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = userID + " " + nickname + " " + avatarUrl + " " + comment_time + " " + likedCount + " " + comment + u""
hot_comments_list.append(comment_info)
return hot_comments_list
# 抓取某一首歌的全部评论
def get_all_comments(url):
all_comments_list = [] # 存放所有评论
all_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容") # 头部信息
params = get_params(1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
comments_num = int(json_dict['total'])
if(comments_num % 20 == 0):
page = comments_num / 20
else:
page = int(comments_num / 20) + 1
print("共有%d页评论!" % page)
for i in range(page): # 逐页抓取
params = get_params(i+1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
if i == 0:
print("共有%d条评论!" % comments_num) # 全部评论总数
for item in json_dict['comments']:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userId'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = unicode(userID) + u" " + nickname + u" " + avatarUrl + u" " + unicode(comment_time) + u" " + unicode(likedCount) + u" " + comment + u""
all_comments_list.append(comment_info)
print("第%d页抓取完毕!" % (i+1))
return all_comments_list
# 将评论写入文本文件
def save_to_file(list,filename):
with codecs.open(filename,'a',encoding='utf-8') as f:
f.writelines(list)
print("写入文件成功!")
if __name__ == "__main__":
start_time = time.time() # 开始时间
url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016/?csrf_token="
filename = u"晴天.txt"
all_comments_list = get_all_comments(url)
save_to_file(all_comments_list,filename)
end_time = time.time() #结束时间
print("程序耗时%f秒." % (end_time - start_time))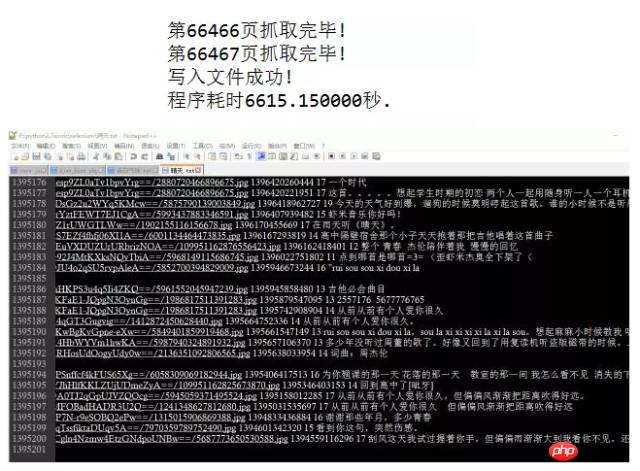 사용자 ID, 사용자 닉네임, 사용자 아바타 주소, 댓글 시간, 총 좋아요 수, 댓글 내용
사용자 ID, 사용자 닉네임, 사용자 아바타 주소, 댓글 시간, 총 좋아요 수, 댓글 내용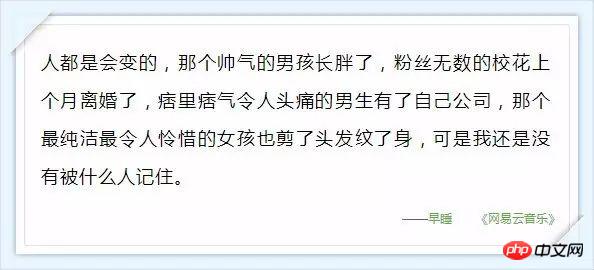
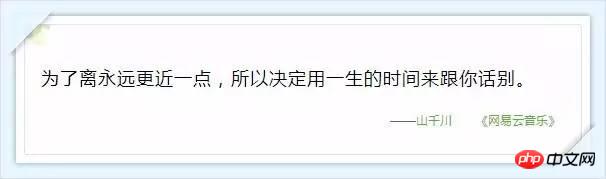
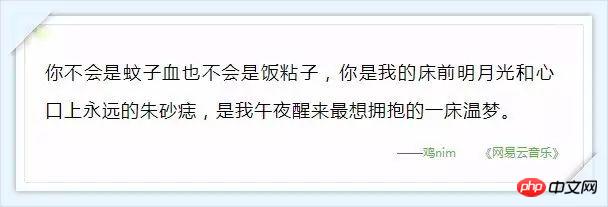
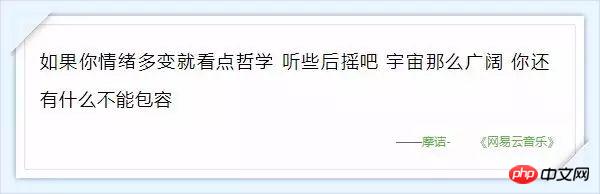

위 내용은 Python을 사용하여 NetEase Cloud Music의 인기 댓글을 크롤링하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



