

공유할 57가지 Python 인터뷰 질문


이 기사는 특정 참고 가치가 있는 Python 인터뷰 질문 공유를 소개합니다. 이제 모든 사람과 공유합니다. 도움이 필요한 친구들은 이를 참조할 수 있습니다
추천 관련 기사: " 2020년 Python 면접 질문 요약(최신) 》
1. Python 문자열 형식화에서 %s와 .format의 주요 차이점은 무엇입니까
Python은 튜플을 사용하여 여러 값을 전달합니다. 각 값은 형식 문자
print (" my name is %s ,im %d year old" %("gaoxu",19))
python2.6부터 문자열 형식 지정을 위한 새로운 함수에 해당합니다. str.format()이 추가되었습니다. 기존 %를 {} 및 로 대체합니다. 주요 차이점은 문자열이나 숫자 유형을 지정할 필요가 없다는 것입니다.
print('ma name is {} ,age is {} year old'.format("小明",17))
print('my name is {1},age is {0}'.format(15,'小明'))
#:位置攒参的方式li=['hollo',18]print('may name is {0},my year old is {1}'.format(*li))
# 按照关键字传参hash={'name':'hoho','age':18}print ('my name is {name},age is {age}'.format(**hash))2. ' a'),('b')),(('c'),('d')) 익명 함수를 사용하여 {{'a':'c'},{'b': 'd '}}t1=(('a'),('b'))
t2=(('c'),('d'))
res=lambda:t1,t2;[i:j}for i,j in zip(t1,t2)]
print(res(t1,t2))로그인 후 복사
t1=(('a'),('b'))
t2=(('c'),('d'))
res=lambda:t1,t2;[i:j}for i,j in zip(t1,t2)]
print(res(t1,t2))3.목록을 중복 제거하고 원래 순서를 유지하는 방법l=[11,2,3,4,7,6,4,3,54,3,]
now_l=[]for i in l:if i not in now_l:
now_l.append(i)print(now_l)
也可以用set直接去重和排序print(set(l)
로그인 후 복사
l=[11,2,3,4,7,6,4,3,54,3,] now_l=[]for i in l:if i not in now_l: now_l.append(i)print(now_l) 也可以用set直接去重和排序print(set(l)
4.익명 함수가 무엇인지, 그 이점은 무엇인지 설명하세요
익명 함수는 함수와 동일한 범위를 가지지만 이름이 없으면 참조 횟수가 0이라는 의미입니다.이점: 일회성 사용, 언제 어디서나 정의를 더 쉽게 읽을 수 있고 수행된 작업이 명확합니다. 한눈에
5. Python에서 변수 매개변수 및 키워드 매개변수 작성 방법
Python에서 함수를 정의할 때 필수 함수, 기본 매개변수, 변수 매개변수, 키워드 매개변수를 사용할 수도 있습니다. 함께 사용하거나 일부만 사용하되, 매개변수 정의 순서는 필수 매개변수, 기본 매개변수, 변수 매개변수, 키워드 매개변수
6 이어야 한다는 점 참고해주세요.
re.match()는 항상 문자열의 시작과 일치하고 일치하는 수학 객체를 반환합니다. 문자열의 시작하지 않는 부분과 일치하면 전체 문자열에 대해 nonere.search() 함수를 반환합니다. 문자열
7과 일치하는 첫 번째 일치 개체를 반환합니다. 1과 2, 1 or2
의 출력 결과는 무엇이며, Python에서는 값이 모두 다음과 같은 경우 왼쪽에서 오른쪽으로 계산됩니다. 모두 true, false가 있는 경우 첫 번째 false가 반환되고 0이 아니므로 반환 값은 18입니다. args 및 **kwargs
*args (실제 매개변수는 위치에 따라 전달되고 초과분은 args에 주어지며 모든 것이 튜플 형식으로 구현된다는 의미)**kwargs: (즉, 키워드에 따라 실제 매개변수가 전달된다는 점 Word 매개변수는 사전 형태로 저장됩니다
9.写出打印结果
print(next(i%2 for i in range(10))) #:<generator object <genexpr> at 0X000001c577DDE258>print([i%2 for i in range(10)]) [0,,1,0,1,0,1,0,1]
总结:
1,把列表解析【】换成()得到生成器表达式
2,列表解析和生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存
3,pyrhon不但使用迭代器协议,让for循环变得更加通用,大部分内置函数,也是使用迭代器协议
访问对象的,列如:sun是python的内置函数,该函数使用迭代器协议访问对象,而生成器实现了迭代器协议
10.python2和python3的区别
python3的字节是python2的字符串
python3的字符窜是python2的unciode
在python3中print要加括号
在python3中数字除法有小数点
11.请描述unIcode,utf-8,gbk之间的关系
Unicode--->encode----->utf-8utf-------->decode------>unicode
12.迭代器,生成器,装饰器
迭代器即迭代工具,那么什么是迭代那
迭代重复上一个重复的过程,每一次重复即一次迭代,并且每一次迭代的结果都是下一次迭代的开始
为何要用迭代器
对于序列类型:字符串,列表,元组,我们可以使用索引的方式迭代取出包含的元素
对于字典,集合,文件等类型没有索引,若还行取出内部包的元素,则需要找出不依赖索引的方式,那这就是迭代器
什么是可迭代的对象,具有init方法返回就是迭代器,具有next方法
特点优点:提供了一种不依赖索引的取值的方式
缺点: 只能往前循环,不能往后找无法获取长度,
注意的是:迭代器对象一定是可迭代对象,但可迭代对象不一定是迭代器的对象
生成器迭代器的一种关键字yield+关键字,next方法,yield语句一次返回一个结果,在每个
结果中间挂起钩子函数,以便下次重它离开的地方继续
生成器表达式类似于列表推导式,但是生成器返回按需求产生结果的一个对象,而不是一次构建
一个结果的列表
特点:惰性运算,节省空间
装饰器:在不改变原来函数和函数的调用方式进行扩展,就是对外开放,对内封闭的原则
目标:为被装饰的对象添加新的功能
13.def func(a,b=[])这样写有什么陷阱?
Python函数在定义的时候。默认b的值就被计算出来了,即[],因为默认参数b也是一个变量,它指向
对象即[],每次调用这个函数,如果改变b的内容每次调用时候默认参数也就改变了,不在是定义时候的[]了
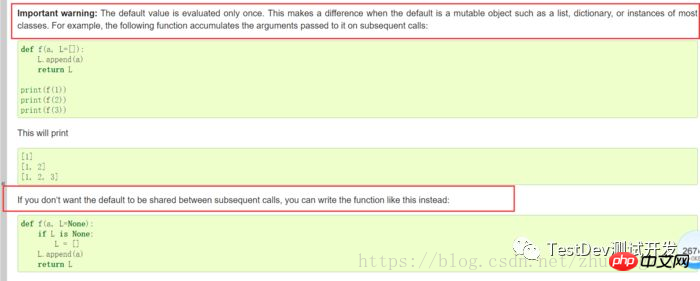
image.png
所以默认参数要牢记一点:默认参数必须指向不变对象
14.python实现9乘9乘法两种方法?
for i in range(1,10): for j in range(1,i+1): print('%s * %s= %s'%(i,j,i*j),end="") print('')print( '\n'.join([' '.join(['%s*%s=%-2s' % (y,x,x*y) for y in range(1,x+1)])for x in range(1,10)]))
15.如何在python中拷贝一个对象,并说出他们的区别
拷贝有两种方式:浅拷贝和深拷贝copy.copy()and copy.deepcopy()
我们寻常意义上的复制就是深复制,即将被复制的对象完全再复制一遍作为独立的新个体单独存在,所以
改变原有被复制的到对象不会对已经复制的新对象产生影响。
而浅复制并不会产生一个独立的对象存在,他只是将原有的数据打上一块新标签,所以当其中一块标签被
改变时候,数据就会变化,另一个标签也会随之改变,数据块就发生变化,另一个标签也会随着改变,
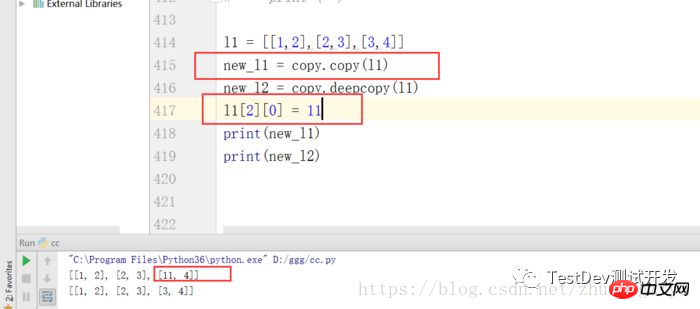
image.png
16.谈谈你对python装饰器的理解
装饰器本质上就是一个python函数,它可以让其他函数在不需要任何代码变动的前提下增加额外的功能
,装饰器的返回值也是一个函数对象,她有很多的应用场景,比如:插入日志,事物处理,缓存,权限装饰器就是为已经存在的对象
添加额外功能
def outher(func):
def good(*args,**kwargs):
ret=func(*args,**kwargs) return ret return good@outherdef bar():
print('狗241131313')
bar()17.python基础:
计算列表中的元素的个数和向末尾追加元素所用到的方法?len(),append()
判断字典中有没有某个key的方法?用到get('key')方法,若没有,将返回值none
现有my_list=range(100)
18.简述python中垃圾回收机制
主要是以对象引用计数为主标记清除和分带技术为辅的那么一种方式
Python在内存中存储了每个对象的引用计数(reference count)。如果计数值变为0,那么相应的对象就会消失。分配给该对象的内存就会释放出来用作他用。
偶尔也会出现引用循环。垃圾回收器会定时寻找这个循环,并将其回收。
Python中还使用了某些启示算法来加速回收。
19.如何判断一个变量是否是字符串
a='sadsadada'print(isinstasnce(a,str))
20.Differences between list and tuple in python link:
http://www.hacksparrow.com/python-difference-between-list-and-tuple.html
21.range和xrange的区别
首先xrange在python3中已经不适用了
range:
函数说明:range([start,]stop[,step]),根据start与stop指定的范围以及step设定的步长
生成一个列表
xrange与range类似,只是返回的是一个“xrange object"对象,而非数组list
要生成很大的数字序列的时候,用xrange会比range性能优很多
区别:range会生成一个list对象,而xrange会返回一个生成器对象
22.'1','2','3'如何变成['1','2','3']?
x='1','2','3'li=[]for i in x: li .append(i)print(li)'1','2','3' 如何变成[1,2,3] x='1','2','3'li=[]for i in x: li .append(int(i))print(li)
23.一行实现[1,4,9,16,25,36,49,81,100]
target=list(map(lambda x: x*x,[1,2,3,4,5,6,7,8,9,10]
24.print(map(str,[1,2,3,4])))输出的是什么
map obj
25.请解释Python中的statimethod(静态方法)和classmethod(类方法),
并补全下面的代码
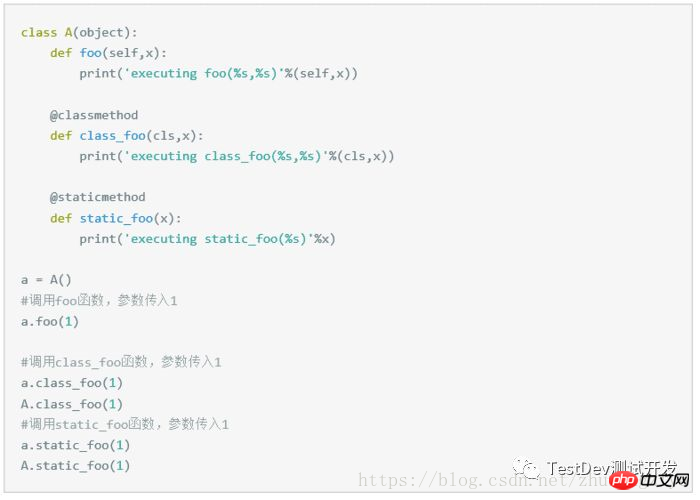
image.png
26.如何用python删除一个文件?
import os os.remove(r'D:\ggg\fileobj) os.remove(‘路径’)
27.面向对象
28.python如何生成随机数
import random print(random.randint(1,10))
29.如何在function里面设置一个全局变量

image.png
30.请用python写一个获取用户输入数字,并根据数字大小输出不同脚本信息

image.png
31.请解释生成器和函数的不同,并实现简单的生成器与函数
# def beautiful(c): # for i in range(c): # yield i**2 # for item in beautiful(5): # print(item)#函数 # def gensquares(N): # res=[0] # for i in range(N): # res.append(i*i) # return res# for item in gensquares(5): # print(item)
总结:
1语法上和函数类似:生成器函数和常规函数几乎一模一样的,他们都是使用def语句进行
定义,区别在于,生成器使用yield语句返回一个值,而常规函数使用return语句返回一个值
2.自动实现迭代器的协议:对于生成器,python自动实现迭代器协议,所以我们可以调用它的next
方法,并且在没有值返回的时候,生成器自动生成Stopltwration异常
3.状态挂起,生成器使用yield语句返回一个值.yield语句挂起该生成器函数的状态,保留足够的信息,方便之后离开的
地方继续执行
32.请写出自己的计算方法,按照升序合并如下列表
list1=[2,3,4,9,6] list2=[5,6,10,17,11,2] list1.extend(list2)print(sorted(list(set(list))))####33.到底什么是python?你可以在回答中进行技术对比(也鼓励这样做)。python是一门解释性语言,这里说与c语言和c的衍生语言不同,python代码不需要编译,其他解释语言还包括Ruby和pyp python是动态语言,在声明变量的时候,不需要声明变量的类型 python非常适合面向对象编程,因为它支持通过组合和继承的方式定义类 python代码编写快,但是运行速度比编译语言通常要慢,好在python允许加入基于c语言编写扩展,因此我们能优化代码,消除瓶颈,这点通常是可以实现的numpy就是一个很好的例子 python用途很广泛----网络应用,自动化,科学建模,大数据应用,等等通常被称为胶水语言
33.http状态码的不同,列出你所知道的http状态码,然后讲出他们都是什么意思
状态代码有三位数字组成,第一个数字定义响应的类别,共分5种类型
1xx:提示信息--表示请求接受,继续处理
2xx:成功表示请求成功接收,理解,接受
3xx:重定向要完成请求必须更进一步操作
4xx:客户端错误,请求有语法错误或请求无法实现
5xx:服务器端错误--服务器没有实现合法请求
常见状态码:
200 OK//客户端请求成功 400 Bad Request//客户端请求有语法错误,不能被服务器所理解401 Unauthorized//请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用 403 Forbidden//服务器收到请求,但是拒绝提供服务 404 Not Found//请求资源不存在,eg:输入了错误的URL 500 Internal Server Error//服务器发生不可预期的错误 503 Server Unavailable//服务器当前不能处理客户端的请求,一段时间后可能恢复正常
34.lambda表达式和列表推导式
l2=[lambda:i for i in range(10)] l1=[i for i in range(10)] print(l1[0]) print(l2[0]) print(l2[0]())
35.eval和exce的区别
eval有返回值
exec没有返回值
print(eval('2+3'))print(exec('2+1'))exec("print('1+1')")eval还可以将字符串转化成对象
class obj(object):
passa = eval('obj()')
print(a,type(a)) #<__main__.obj object at 0x000001F1F6897550> <class '__main__.obj'>36.cookie和session的区别
session在服务器,cooking在客户端(浏览器)
session默认存在服务器上的文件里面(也可以是内存,数据库)
session的运行依赖session_id,而session_id是存在cookie中,也就是说,若果浏览器禁用lcookie,同时session也会失效(但是可以通过其他方式实现,比如在url中传入session_id)
session可以放在文件,数据库,内存中都可以的
用户验证通常会用session
维持一个会话核心就是客户端的唯一标识,即session_id
37.http是有状态协议还是无状态协议?如何从两次请求判断是否是同一用户?
无状态协议,判断session_id是否相同。
38.有一组数组[3,4,1,2,5,6,6,5,4,3,3]请写一个函数,找出该数组中没有重复的数的总和
def MyPlus(l): new_l = [] for i in l: if i not in new_l: new_l.append(i) return sum(new_l) print(MyPlus(l = [2,3,4,4,5,5,6,7,8]))
39.Python一行print出1-100的偶数列表:
print(i for i in range(1,100)if i%2 ==0])
40.1,2,3,4,5能组成多少个互不相同且无重复的元素?
nums = [] for i in range(1,6): for j in range(1,6): for k in range(1,6): if i != j and j != k and i !=k: new_num = i*100 + k*10 + j if new_num not in nums: nums.append(new_num) print(nums)
41.请写出五中不同的http的请求方法:
get,post,put,delete,head,connect
42.描述多进程开发中的join与daemon的区别
守护进程(daemon)
主进程创建守护进程
其一:守护进程会在主进程代码执行结束后就终止
其二:守护进程内无法开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
注意:进程之间是相互独立的,主进程的代码运行结束,守护进程随即终止
p.join([timeout]): 主进程等待相应的子进程p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。需要强调的是p.join()只能join住start开始的进程,而不能join住run开启的进程
43.简述GRL对python的影响
由于GIL的影响,python无法利用多核优势
CIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁都一样将并发运行转化为串行,此时来控制同一时间内只能被一个任务修改,进而保证数据的安全.可以肯定的是:保护不同数据的安全,需要加不同的锁。
现在计算机基本都是多核,python对于计算密集型任务开多线程的效率并不能带来多大的技术提升,甚至不如串行(没有大量的切换),但是对于io密集型任务效率还是有显著的提升的
因此,对于io密集型任务,python多线程更加的适合。
44.执行python脚本的两种方式
./run.py.shell直接调用python脚本 python run.py 调用python 解释器来调用python脚本
45.TCP协议和UDP协议的区别是什么?
1、TCP协议是有连接的,有连接的意思是开始传输实际数据之前TCP的客户端和服务器端必须通过三次握手建立连接,会话结束后也要结束连接。而UDP是无连接的
2、TCP协议保证数据发送,按序送达,提供超时重传保证数据可靠性,但是UDP不保证按序到达,甚至不能保证到达,还是努力交付,即便是按序发送的序列,也不保证按序送到。
3、TCP协议所需资源多,TCP首部需20个字节(不算可选项),UDP首部字段只需8个字节。
4、TCP有流量控制和拥塞控制,UDP没有。网络拥堵不会影响发送端的发送速率。
5、TCP面向的字节流的服务,UDP面向的是报文的服务。
三次握手建立连接时,发送方再次发送确认的必要性?
主 要是为了防止已失效的连接请求报文段突然又传到了B,因而产生错误。假定出现一种异常情况,即A发出的第一个连接请求报文段并没有丢失,而是在某些网络结 点长时间滞留了,一直延迟到连接释放以后的某个时间才到达B,本来这是一个早已失效的报文段。但B收到此失效的连接请求报文段后,就误认为是A又发出一次 新的连接请求,于是就向A发出确认报文段,同意建立连接。假定不采用三次握手,那么只要B发出确认,新的连接就建立了,这样一直等待A发来数据,B的许多 资源就这样白白浪费了。
四次挥手释放连接时,等待2MSL的意义?
第 一,为了保证A发送的最有一个ACK报文段能够到达B。这个ACK报文段有可能丢失,因而使处在LAST-ACK状态的B收不到对已发送的FIN和ACK 报文段的确认。B会超时重传这个FIN和ACK报文段,而A就能在2MSL时间内收到这个重传的ACK+FIN报文段。接着A重传一次确认。
第二,就是防止上面提到的已失效的连接请求报文段出现在本连接中,A在发送完最有一个ACK报文段后,再经过2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。
46.一句话总结tcp和udp的区别
tcp是面向连接的,可靠的字节流服务,udp是面向无连接的,不可靠而数据服务
47.python有如下一个字典
python有如下的字典,
dic_tmp={'carry':17,'bob':21,'matty':23,'jack':33,'tom':17,'alex':23}
print(sorted(dic_tmp.items(),key=lambda dic_tmp:dic_tmp[0]))48.简述inndb和myisam的特点:
innodb是mysql最常用的一种存储引擎,Facebook,google等公司的成功已证明了innodb存储引擎具有高可用性,高性能以及高扩展性,支持事物,其特点是行锁设计,支持外键,并支持类似oracle的非锁定读,对于表中数据的存储,inndb存储引擎采用了聚集的方式,每张表都是按主键的顺序进行存储的,如果没有显示地在表定义时候指定主键,innodb,存储引擎会为每一行生成六个字节的ROWId,并以此为主键。
myisam不支持事物,表锁设计,支持全文索引,主要面向一些olap数据库应用,此外myisam存储引擎的另一个与众不同的地方是,它的缓冲池只缓存索引文件,而不缓存数据文件,这与大多数数据库不一样
49.利用python上下文管理器,实现一个写入文件的功能(写入内容为'hello world')
class Open(object):
def __init__(self,name,mode):
self.name=name
self.mode=mode
def __enter__(self):
self.opened=open(self.name,self.mode)
return self.opened
def __exit__(self,exc_type,exc_val,exc_tb):
self.opened.close()
with open('mytext.txt','w') as write:
write.write('hello qaweqwe world')50.Django的请求生命周期
1,当用户在浏览器中输入url时浏览器会生成请求头和请求体发送给服务端请求头和请求体中会包含浏览器的动作(action)这个动作通常为get或者post提现在url之中
2.url经过Django中的wsgi再经过django的中间件,最后url到路由的映射表一条一条进行匹配一旦其中的某一条匹配成功就执行视图函数,后面的路由就不在继续匹配了
3视图函数根据客户端的请求查询相应的数据,返回给Django,然后Django把客户端想要的数据作为一个字符串返回给客户端
4客户端浏览器接受到返回的数据,经过渲染后显示给用户
51.django rest framework规范
1url后尽量用名词,因为rest frame是面向资源的编程,因此url命名时能体现出资源
2method的不同,实现增删改查的操作
3版本号,因为有版本的更替,为了体现出版本的过度,因此在发请求的时候,要体现出版本号
4返回值,与以往只返回json不同,rest api规范要加上状态码。
5域名,由于前后端分离,因此要处理跨域问题,解决方法:jsonp,cors
6过滤,通过url传参的形式传递搜索条件(列如:指定返回的记录数量,指定分页等)
52.jsonp和cors
jsonp的本质就是利用script的src属性绕过同源策略
cors
整个cors通信过程,都是浏览器自动完成,不需要用户参与,对于开发者来说cors通信和同源的ajax没有什么区别,挨代码完全一样,浏览器一旦发现ajax请求跨源,就会自动添加一些附加头的信息,有时还会多出一次附加的请求,但用户不会有感觉.
53.现有字典dic = {'a':1,'b':2,'c':23,'d':11,'e':4,'f':21},请按照字段中的value进行排序
print(sorted(dic.items(),key=lambda dic:dic[1]))
54.mysql 搜索引擎和局域网权限,mysql中的锁
innodb存储引擎(最常用的引擎,支持事物,特点是行锁,特点是行锁设计,支持外键)
myisam存储引擎(不支持事物,表锁的设计,支持全文索引)
nod存储引擎
memory存储引擎
55.二叉树的遍历
class BiTreeNode(object):
def __init__(self,data):
self.data = data
self.lchild = None
self.rchild = Nonea = BiTreeNode('A')
b= BiTreeNode('B')
c = BiTreeNode('C')
d = BiTreeNode('D')
e = BiTreeNode('E')
f = BiTreeNode('F')
g = BiTreeNode('G')
e.lchild = a
e.rchild = g
a.rchild = c
c.lchild = b
c.rchild = d
g.rchild = f
root = e# 前序遍历 (先找做子树,后找右子树)def pre_order(root):
if root:
print(root.data,end='') # EACBDGF
pre_order(root.lchild)
pre_order(root.rchild)
pre_order(root)
print('')# 中序遍历def in_order(root):
if root:
in_order(root.lchild)
print(root.data,end='') # ABCDEGF
in_order(root.rchild)
in_order(root) # ABCDEGFprint('')# 后序遍历def post_order(root):
if root:
post_order(root.lchild)
post_order(root.rchild)
print(root.data,end='')
post_order(root) #BDCAFGE56.实现页面刷新的方法:
1轮训
2长轮训
3websocket
轮训:客户端定向向服务器发送ajax请求,服务器接到请求后马上返回响应信息并关闭连接.
优点:后端程序编写比较容易
缺点:请求中有大半是无用浪费带宽和服务器资源.
实例:适用小型应用
长轮训:客户端向服务器发送ajax请求,服务器连接到hold住连接,直到有新消息才返回响应信息并关闭连接,客户端处理完响应后再向服务端发送新的请求.
优点:在无消息的情况下不会频繁的请求
缺点:服务器hold连接会消耗资源。
实例:webqq,hi网页版,facebook im。
57.写出你知道的常见异常
AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入模块或包;基本上是路径问题或名称错误 IndentationError 语法错误(的子类) ;代码没有正确对齐 IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5] KeyError 试图访问字典里不存在的键 KeyboardInterrupt Ctrl+C被按下 NameError 使用一个还未被赋予对象的变量SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了)TypeError 传入对象类型与要求的不符合 UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,导致你以为正在访问它 ValueError 传入一个调用者不期望的值,即使值的类型是正确的`
相关学习推荐:python视频教程
위 내용은 공유할 57가지 Python 인터뷰 질문의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7708
7708
 15
1640
14
1394
52
1288
25
1232
29
15
1640
14
1394
52
1288
25
1232
29

 Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 보려고 할 때 Linux 터미널에서 Python 버전을 볼 때 권한 문제에 대한 솔루션 ... Python을 입력하십시오 ...
 중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?
Apr 02, 2025 am 07:15 AM
중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?
Apr 02, 2025 am 07:15 AM
Fiddlerevery Where를 사용할 때 Man-in-the-Middle Reading에 Fiddlereverywhere를 사용할 때 감지되는 방법 ...
 10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?
Apr 02, 2025 am 07:18 AM
10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?
Apr 02, 2025 am 07:18 AM
10 시간 이내에 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법은 무엇입니까? 컴퓨터 초보자에게 프로그래밍 지식을 가르치는 데 10 시간 밖에 걸리지 않는다면 무엇을 가르치기로 선택 하시겠습니까?
 한 데이터 프레임의 전체 열을 Python의 다른 구조를 가진 다른 데이터 프레임에 효율적으로 복사하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:15 PM
한 데이터 프레임의 전체 열을 Python의 다른 구조를 가진 다른 데이터 프레임에 효율적으로 복사하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:15 PM
Python의 Pandas 라이브러리를 사용할 때는 구조가 다른 두 데이터 프레임 사이에서 전체 열을 복사하는 방법이 일반적인 문제입니다. 두 개의 dats가 있다고 가정 해
 Uvicorn은 Serving_forever ()없이 HTTP 요청을 어떻게 지속적으로 듣습니까?
Apr 01, 2025 pm 10:51 PM
Uvicorn은 Serving_forever ()없이 HTTP 요청을 어떻게 지속적으로 듣습니까?
Apr 01, 2025 pm 10:51 PM
Uvicorn은 HTTP 요청을 어떻게 지속적으로 듣습니까? Uvicorn은 ASGI를 기반으로 한 가벼운 웹 서버입니다. 핵심 기능 중 하나는 HTTP 요청을 듣고 진행하는 것입니다 ...

 Linux 터미널에서 Python (Version 명령)을 사용할 때 권한 문제를 해결하는 방법은 무엇입니까?
Apr 02, 2025 am 06:36 AM
Linux 터미널에서 Python (Version 명령)을 사용할 때 권한 문제를 해결하는 방법은 무엇입니까?
Apr 02, 2025 am 06:36 AM
Linux 터미널에서 Python 사용 ...
 Inversiting.com의 크롤링 메커니즘을 우회하는 방법은 무엇입니까?
Apr 02, 2025 am 07:03 AM
Inversiting.com의 크롤링 메커니즘을 우회하는 방법은 무엇입니까?
Apr 02, 2025 am 07:03 AM
Investing.com의 크롤링 전략 이해 많은 사람들이 종종 Investing.com (https://cn.investing.com/news/latest-news)에서 뉴스 데이터를 크롤링하려고합니다.
