

분류 평가 지표와 회귀 평가 지표에 대한 자세한 설명과 Python 코드 구현

이 글의 내용은 분류 평가 지표와 회귀 평가 지표에 대한 자세한 설명과 Python 코드 구현에 대한 내용입니다. 이제 필요한 친구들이 참고할 수 있도록 공유하겠습니다.
1. 개념
성과 측정(평가) 지표는 크게 두 가지 범주로 나뉜다.
1) 분류 평가 지표(분류), 주로 분석, 이산, 정수. 구체적인 지표로는 정확도(accuracy), 정밀도(precision), 리콜(recall), F값, P-R 곡선, ROC 곡선, AUC 등이 있습니다.
2) 회귀평가지수(regression)는 주로 정수와 실수의 관계를 분석합니다. 구체적인 지표로는 explianed_variance_score, 평균 절대 오차 MAE(mean_absolute_error), 평균 제곱 오차 MSE(mean-squared_error), 평균 제곱근 차이 RMSE, 교차 엔트로피 손실(Log 손실, 교차 엔트로피 손실), R 제곱 값(결정 계수)이 있습니다. , r2_score).
1.1. 전제
긍정적인 범주와 부정적인 범주만 있다고 가정합니다. 일반적으로 우려되는 범주는 긍정적인 범주이고 다른 범주는 부정적인 범주입니다. 따라서 다중 클래스 문제도 두 가지로 요약될 수 있습니다. 카테고리 )
혼동행렬은 다음과 같습니다
| 실제 카테고리 | 예측 카테고리 | |||
| 긍정적 | 부정적 | summary | ||
| 긍정적 | TP | FN | P(실제로는 긍정) | |
| negative | FP | TN | N(실제로는 부정) | |
AB 모드: 첫 번째는 예측 결과가 right 또는 false , 두 번째 항목은 예측된 카테고리를 나타냅니다. 예를 들어 TP는 참 긍정(True Positive)을 의미합니다. 즉, 올바른 예측은 긍정 클래스입니다. FN은 거짓 부정(False Negative)을 의미합니다. 즉, 잘못된 예측은 부정 클래스입니다.
2. 평가 지표(성과 측정)
2.1. 분류 평가 지표
2.1.1 가치 지표 - 정확도, 정밀도, 재현율, F 값
| 측정 | 정확도(정확도) | 정밀도 ( Precision) | Recall(Recall) | F value |
| Definition | 총 샘플 수 대비 정확하게 분류된 샘플 수의 비율(스팸으로 예측되는 실제 스팸 문자 메시지의 비율) | 결정 as 긍정 사례 수에 대한 참 긍정 사례 수의 비율(올바르게 분류되어 발견된 모든 실제 스팸 문자 메시지의 비율) | 전체 긍정 사례 수에 대한 참 긍정 사례 수의 비율 | 정확도 조화 평균 F-score |
| (재현율 포함)은 | accuracy=
| 을 의미합니다. 정밀도=
|
회상=
|
F - 점수 =
|
1. 정밀도는 정밀도율이라고도 하고, 재현율은 재현율이라고도 합니다
2. 더 일반적으로 사용되는 것은 F1,
python3.6 코드 구현:
#调用sklearn库中的指标求解from sklearn import metricsfrom sklearn.metrics import precision_recall_curvefrom sklearn.metrics import average_precision_scorefrom sklearn.metrics import accuracy_score#给出分类结果y_pred = [0, 1, 0, 0]
y_true = [0, 1, 1, 1]
print("accuracy_score:", accuracy_score(y_true, y_pred))
print("precision_score:", metrics.precision_score(y_true, y_pred))
print("recall_score:", metrics.recall_score(y_true, y_pred))
print("f1_score:", metrics.f1_score(y_true, y_pred))
print("f0.5_score:", metrics.fbeta_score(y_true, y_pred, beta=0.5))
print("f2_score:", metrics.fbeta_score(y_true, y_pred, beta=2.0))2.1.2 상관 곡선-P-R 곡선, ROC 곡선 및 AUC 값
1) P-R curve
단계:
1. "점수" 값을 높은 것에서 낮은 것으로 정렬하고 이를 임계값으로 순서대로 사용합니다.
2. 각 임계값에 대해 이 임계값보다 크거나 같은 "점수" 값을 가진 샘플을 테스트합니다. 긍정적인 사례로 간주되고 나머지는 부정적인 사례로 간주됩니다. 따라서 일련의 예측 수치가 형성됩니다.
eg. 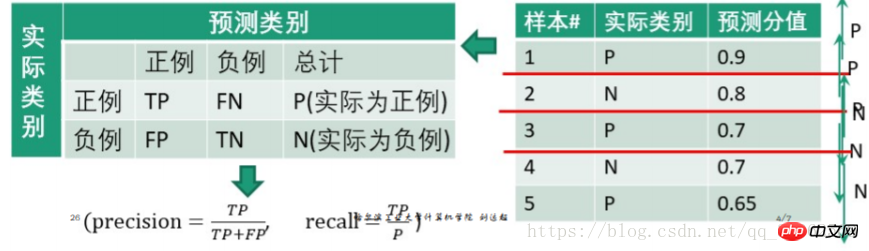
0.9를 임계값으로 설정하면 첫 번째 테스트 샘플은 긍정적인 예이고 2, 3, 4, 5는 부정적인 예입니다.
우리는
| 긍정적인 것으로 예측합니다. 예를 들어 부정적인 예로 예측 된 예는 | toTalSpositive 사례 (점수는 임계 값보다 큽니다) | 0.9 | |
| 1 | 1INGITATION CASE (점수는 임계 값보다 작음) | 0.2+0.3+0.3+0.35 = 1.15 | |
| 4 | 정밀도= | ||
| recall=
임계값 아래 부분은 음의 예로 처리되며 예측된 음의 예의 값은 올바른 예측 값입니다. 즉, 양의 예인 경우 음의 예인 경우 TP가 사용됩니다. TN이 취해지며 둘 다 예측 점수입니다. |
Python은 의사 코드를 구현합니다|||
세로축: True 양성률 tp 비율 = TP / N가로축: 거짓양성률 fp 비율 = FP/N
2) ROC 곡선
단계:
1. "점수" 값을 높은 값에서 낮은 값으로 정렬하여 차례로 임계값으로 사용합니다. 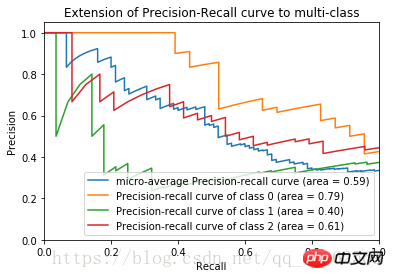 2. 각 임계값에 대해 더 큰 "점수" 값으로 샘플을 테스트합니다. 이 임계값 이상이면 긍정적인 예로 간주되고, 다른 것들은 부정적인 예로 간주됩니다. 따라서 일련의 예측 수치가 형성됩니다.
2. 각 임계값에 대해 더 큰 "점수" 값으로 샘플을 테스트합니다. 이 임계값 이상이면 긍정적인 예로 간주되고, 다른 것들은 부정적인 예로 간주됩니다. 따라서 일련의 예측 수치가 형성됩니다.
P-R 곡선 계산과 유사하므로 자세히 설명하지 않겠습니다
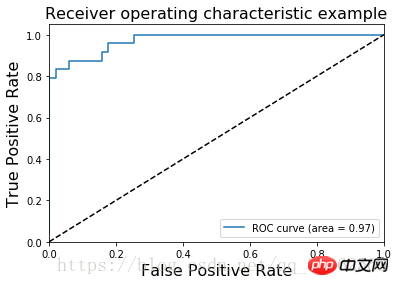
붓꽃 데이터 세트의 ROC 이미지는
AUC 값은 분류기에 대한 전체 수치 값을 제공합니다. 일반적으로 AUC가 클수록 분류기가 우수하며 값은 [0, 1]2) 평균 절대 오차 MAE(Mean Absolute Error)
2.2입니다. 회귀 평가 지수
1) 해석 가능한 분산 점수
3) MSE(평균 제곱 오차) 
 4) 물류 회귀 손실
4) 물류 회귀 손실  5) 일관성 평가 - 피어슨 상관 계수 방법
5) 일관성 평가 - 피어슨 상관 계수 방법 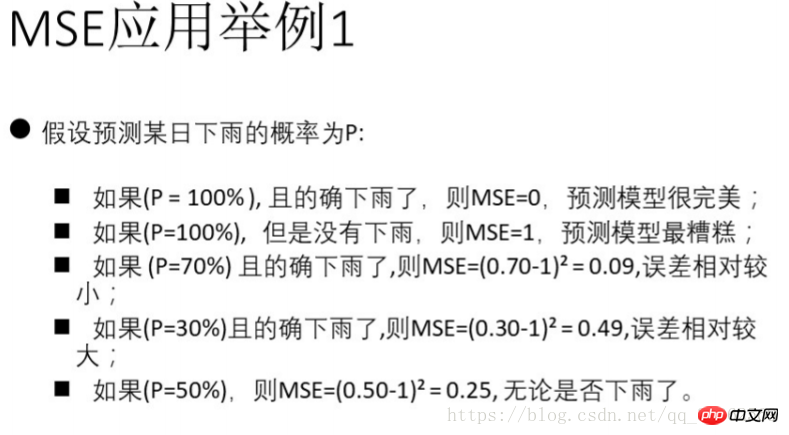
파이썬 코드 구현
from sklearn.metrics import log_loss log_loss(y_true, y_pred)from scipy.stats import pearsonr pearsonr(rater1, rater2)from sklearn.metrics import cohen_kappa_score cohen_kappa_score(rater1, rater2)
위 내용은 분류 평가 지표와 회귀 평가 지표에 대한 자세한 설명과 Python 코드 구현의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7643
7643
 15
1392
52
91
11
72
19
33
150
15
1392
52
91
11
72
19
33
150

 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 vScode를 Mac에 사용할 수 있습니다
Apr 15, 2025 pm 07:36 PM
vScode를 Mac에 사용할 수 있습니다
Apr 15, 2025 pm 07:36 PM
VS 코드는 Mac에서 사용할 수 있습니다. 강력한 확장, GIT 통합, 터미널 및 디버거가 있으며 풍부한 설정 옵션도 제공합니다. 그러나 특히 대규모 프로젝트 또는 고도로 전문적인 개발의 경우 VS 코드는 성능 또는 기능 제한을 가질 수 있습니다.
