
이 글에 소개된 내용은 PHP 인터뷰를 요약한 것인데, 이제 모든 분들과 공유합니다. 도움이 필요한 친구들이 참고할 수 있습니다
ㅋㅋㅋ
환경 준비
테스트 테이블 만들기
CREATE TABLE people( id bigint auto_increment primary key, zipcode char(32) not null default '', address varchar(128) not null default '', lastname char(64) not null default '', firstname char(64) not null default '', birthdate char(10) not null default '' ); CREATE TABLE people_car( people_id bigint, plate_number varchar(16) not null default '', engine_number varchar(16) not null default '', lasttime timestamp );
<br/>
테스트 데이터 삽입
insert into people (zipcode,address,lastname,firstname,birthdate) values ('230031','anhui','zhan','jindong','1989-09-15'), ('100000','beijing','zhang','san','1987-03-11'), ('200000','shanghai','wang','wu','1988-08-25') insert into people_car (people_id,plate_number,engine_number,lasttime) values (1,'A121311','12121313','2013-11-23 :21:12:21'), (2,'B121311','1S121313','2011-11-23 :21:12:21'), (3,'C121311','1211SAS1','2012-11-23 :21:12:21')
 테스트용 인덱스 만들기
테스트용 인덱스 만들기
alter table people add key(zipcode,firstname,lastname);
 EXPLAIN 소개
EXPLAIN 소개
가장 간단한 쿼리부터 시작해 보겠습니다.
Query-1 explain select zipcode,firstname,lastname from people;
EXPLAIN 출력 결과에는 id, select_type, table, type, available_keys, key, key_len, 심판, 행 및 추가 열.
idQuery-2 explain select zipcode from (select * from people a) b;
id는 전체 쿼리에서 SELELCT 문을 순차적으로 식별하는 데 사용됩니다. 위의 간단한 중첩 쿼리를 통해 ID가 더 큰 문이 먼저 실행되는 것을 확인할 수 있습니다. UNION 문과 같이 이 행이 다른 행의 통합 결과를 설명하는 데 사용되는 경우 값은 NULL일 수 있습니다. 진술은 다음과 같을 수 있습니다.
UNION이나 하위 쿼리를 사용하지 않는 가장 간단한 SELECT 쿼리입니다.
쿼리-1을 참조하세요. 
은 중첩 쿼리에서 가장 바깥쪽 SELECT 문이고 UNION 쿼리에서는 맨 앞의 SELECT 문입니다.  Query-2 및
Query-2 및
을 참조하세요.

UNION
DERIVED
파생 테이블 SELECT 문의 FROM 절에 있는 SELECT 문. 쿼리-2
를 참조하세요.
UNION 결과
一个UNION查询的结果。见Query-3。 DEPENDENT UNION 顾名思义,首先需要满足UNION的条件,及UNION中第二个以及后面的SELECT语句,同时该语句依赖外部的查询。 Query-4中select id from people where zipcode = 200000的select_type为DEPENDENT UNION。你也许很奇怪这条语句并没有依赖外部的查询啊。 这里顺带说下MySQL优化器对IN操作符的优化,优化器会将IN中的uncorrelated subquery优化成一个correlated subquery(关于correlated subquery参见这里)。 类似这样的语句会被重写成这样: 所以Query-4实际上被重写成这样: 题外话:有时候MySQL优化器这种太过“聪明” 的做法会导致WHERE条件包含IN()的子查询语句性能有很大损失。可以参看《高性能MySQL第三版》6.5.1关联子查询一节。 SUBQUERY 子查询中第一个SELECT语句。 DEPENDENT SUBQUERY 和DEPENDENT UNION相对UNION一样。见Query-5。 除了上述几种常见的select_type之外还有一些其他的这里就不一一介绍了,不同MySQL版本也不尽相同。 显示的这一行信息是关于哪一张表的。有时候并不是真正的表名。 可以看到如果指定了别名就显示的别名。 还有 注意:MySQL对待这些表和普通表一样,但是这些“临时表”是没有任何索引的。 type列很重要,是用来说明表与表之间是如何进行关联操作的,有没有使用索引。MySQL中“关联”一词比一般意义上的要宽泛,MySQL认为任何一次查询都是一次“关联”,并不仅仅是一个查询需要两张表才叫关联,所以也可以理解MySQL是如何访问表的。主要有下面几种类别。 const 当确定最多只会有一行匹配的时候,MySQL优化器会在查询前读取它而且只读取一次,因此非常快。const只会用在将常量和主键或唯一索引进行比较时,而且是比较所有的索引字段。people表在id上有一个主键索引,在(zipcode,firstname,lastname)有一个二级索引。因此Query-8的type是const而Query-9并不是: 注意下面的Query-10也不能使用const table,虽然也是主键,也只会返回一条结果。 system 这是const连接类型的一种特例,表仅有一行满足条件。 eq_ref eq_ref类型是除了const外最好的连接类型,它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY。 需要注意InnoDB和MyISAM引擎在这一点上有点差别。InnoDB当数据量比较小的情况type会是All。我们上面创建的people 和 people_car默认都是InnoDB表。 我们创建两个MyISAM表people2和people_car2试试: 我想这是InnoDB对性能权衡的一个结果。 eq_ref可以用于使用 = 操作符比较的带索引的列。比较值可以为常量或一个使用在该表前面所读取的表的列的表达式。如果关联所用的索引刚好又是主键,那么就会变成更优的const了: ref 这个类型跟eq_ref不同的是,它用在关联操作只使用了索引的最左前缀,或者索引不是UNIQUE和PRIMARY KEY。ref可以用于使用=或<=>操作符的带索引的列。 为了说明我们重新建立上面的people2和people_car2表,仍然使用MyISAM但是不给id指定primary key。然后我们分别给id和people_id建立非唯一索引。 然后再执行下面的查询: 看上面的Query-15,Query-16和Query-17,Query-18我们发现MyISAM在ref类型上的处理也是有不同策略的。 对于ref类型,在InnoDB上面执行上面三条语句结果完全一致。 fulltext 链接是使用全文索引进行的。一般我们用到的索引都是B树,这里就不举例说明了。 ref_or_null 该类型和ref类似。但是MySQL会做一个额外的搜索包含NULL列的操作。在解决子查询中经常使用该联接类型的优化。(详见这里)。 注意Query-20使用的并不是ref_or_null,而且InnnoDB这次表现又不相同(数据量大的情况下有待验证)。 index_merger 该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。关于索引合并优化看这里。 unique_subquery 该类型替换了下面形式的IN子查询的ref: unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。 index_subquery 该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引:<br/> range 只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。在该类型中ref列为NULL。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range: 注意在我的测试中:发现只有id是主键或唯一索引时type才会为range。 这里顺便挑剔下MySQL使用相同的range来表示范围查询和列表查询。 但事实上这两种情况下MySQL如何使用索引是有很大差别的: 我们不是挑剔:这两种访问效率是不同的。对于范围条件查询,MySQL无法使用范围列后面的其他索引列了,但是对于“多个等值条件查询”则没有这个限制了。 ——出自《高性能MySQL第三版》 index 该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。这个类型通常的作用是告诉我们查询是否使用索引进行排序操作。 至于什么情况下MySQL会利用索引进行排序,等有时间再仔细研究。最典型的就是order by后面跟的是主键。 ALL 가장 느린 방법은 전체 테이블 스캔입니다. 일반적으로 위 연결 유형의 성능은 순서대로(시스템>const) 감소하며, MySQL 버전, 스토리지 엔진, 데이터 볼륨에 따라 성능이 달라질 수 있습니다. possible_keys 열은 MySQL이 이 테이블에서 행을 찾는 데 사용할 수 있는 인덱스를 나타냅니다. 키 열에는 MySQL이 실제로 사용하기로 결정한 키(인덱스)가 표시됩니다. 인덱스를 선택하지 않으면 키는 NULL입니다. MySQL이 available_keys 열의 인덱스를 사용하거나 무시하도록 하려면 쿼리에서 FORCE INDEX, USE INDEX 또는 IGNORE INDEX를 사용하십시오. key_len 열은 MySQL이 사용하기로 결정한 키 길이를 보여줍니다. 키가 NULL이면 길이도 NULL입니다. 사용된 인덱스의 길이입니다. 정확도를 잃지 않으면서 길이가 짧을수록 좋습니다. ref 열은 테이블에서 행을 선택하기 위해 키와 함께 사용되는 열 또는 상수를 보여줍니다. 행 열은 MySQL이 쿼리를 실행할 때 확인해야 한다고 생각하는 행 수를 표시합니다. 이는 추정치임을 참고하세요. Extra는 EXPLAIN 출력의 또 다른 매우 중요한 열입니다. 이 열에는 쿼리 프로세스 중에 MySQL에 대한 몇 가지 자세한 정보가 표시됩니다. 소개 대상으로 선정되었습니다. 파일 정렬 사용 <br/> 임시 테이블을 사용한다는 것은 임시 테이블을 사용한다는 의미입니다. 일반적으로 보면 임시 테이블 사용을 피할 수 없더라도 피하는 것이 좋습니다. 하드 디스크의 임시 테이블 사용. 존재하지 않음 색인 사용 은 쿼리가 색인을 포함한다는 것을 의미하며 이는 좋은 일입니다. MySQL은 인덱스에서 원하지 않는 레코드를 직접 필터링하고 조회수를 반환합니다. 이는 MySQL 서비스 계층에 의해 수행되지만 레코드를 쿼리하기 위해 테이블로 돌아갈 필요가 없습니다. 인덱스 조건 사용 이것은 "인덱스 조건 푸시"라고 불리는 MySQL 5.6의 새로운 기능입니다. 간단히 말해서 MySQL은 원래 인덱스와 같은 작업을 수행할 수 없었지만 이제는 불필요한 IO 작업을 줄일 수 있지만 자세한 내용을 보려면 여기를 클릭하세요. where 를 사용하면 WHERE 절을 사용하여 다음 테이블과 일치하거나 사용자에게 반환될 행을 제한합니다. Note EXPLAIN의 출력 내용은 기본적으로 소개되었습니다. 여기에는 SHOW WARNINGS 명령과 결합하여 더 많은 정보를 볼 수 있는 EXPLAIN EXTENDED라는 확장 명령도 있습니다. 더 유용한 것 중 하나는 MySQL 최적화 프로그램으로 재구성한 후 SQL을 볼 수 있다는 것입니다. 자, EXPLAIN은 여기까지입니다. 사실 이런 콘텐츠는 온라인에서도 볼 수 있지만, 직접 연습해보면 더 감동을 받을 것입니다. 다음 섹션에서는 SHOW PROFILE, 느린 쿼리 로그 및 일부 타사 도구를 소개합니다. <br/> OAuth는 전 세계적으로 널리 사용되는 개방형 네트워크 표준입니다. 이 글은 OAuth 2.0의 디자인 아이디어와 운영 프로세스에 대한 간결하고 대중적인 설명을 제공합니다. 주요 참고 자료는 RFC 6749입니다. OAuth의 적용 가능한 시나리오를 이해하기 위해 가상의 예를 들어보겠습니다. 구글에 사용자가 저장한 사진을 인쇄할 수 있는 '클라우드 프린팅' 웹사이트가 있습니다. 이 서비스를 이용하려면 사용자는 Google에 저장된 사진을 '클라우드 프린트'에서 읽을 수 있도록 허용해야 합니다. 문제는 Google이 사용자 승인이 있는 경우에만 "클라우드 프린트"가 이러한 사진을 읽을 수 있도록 허용한다는 것입니다. 그렇다면 "클라우드 프린트"는 어떻게 사용자의 인증을 얻나요? 전통적인 방법은 사용자가 '클라우드 프린트'에 Google 사용자 이름과 비밀번호를 알려주면 후자가 사용자의 사진을 읽을 수 있는 것입니다. 이 접근 방식에는 몇 가지 심각한 단점이 있습니다. (1) "클라우드 프린팅"은 후속 서비스를 위해 사용자의 비밀번호를 저장하므로 매우 안전하지 않습니다. (2) Google은 비밀번호 로그인을 배포해야 하며, 단순 비밀번호 로그인이 안전하지 않다는 것을 알고 있습니다. (3) "클라우드 프린팅"은 Google에 저장된 모든 사용자 데이터를 얻을 수 있는 권리를 가지며, 사용자는 "클라우드 프린팅" 승인의 범위와 유효 기간을 제한할 수 없습니다. (4) 사용자는 비밀번호를 변경해야만 "클라우드 프린팅"에 부여된 권한을 되돌릴 수 있습니다. 그러나 그렇게 하면 사용자가 승인한 다른 모든 타사 응용 프로그램이 무효화됩니다. (5) 하나의 타사 애플리케이션이 깨지는 한 사용자 비밀번호가 유출되고 비밀번호로 보호된 모든 데이터가 유출됩니다. OAuth는 위와 같은 문제를 해결하기 위해 탄생했습니다. OAuth 2.0을 자세히 설명하기 전에 몇 가지 특수명사에 대해 이해해야 합니다. 이는 다음 설명, 특히 여러 그림을 이해하는 데 중요합니다. (1) 타사 애플리케이션: 이 문서에서는 "클라이언트"라고도 하는 타사 애플리케이션으로, 이전 섹션의 예에서는 "클라우드 인쇄"입니다. (2)HTTP 서비스: 이 문서에서는 "서비스 공급자"라고 하는 HTTP 서비스 공급자(이전 섹션의 예에서는 Google)입니다. (3)리소스 소유자: 이 문서에서는 "사용자"라고도 하는 리소스 소유자입니다. (4)User Agent: 이 문서에서 사용자 에이전트는 브라우저를 의미합니다. (5)인증 서버: 인증 서버, 즉 서비스 제공자가 인증을 처리하는 데 사용하는 서버입니다. (6)리소스 서버: 리소스 서버, 즉 서비스 제공자가 사용자 생성 리소스를 저장하는 서버입니다. 해당 서버와 인증 서버는 동일한 서버일 수도 있고 다른 서버일 수도 있습니다. 위의 용어를 알고 나면 "클라이언트"가 "사용자"의 승인을 안전하고 제어 가능하게 획득하고 "서비스 제공자"와 상호 작용할 수 있도록 하는 것이 OAuth의 기능임을 이해하는 것은 어렵지 않습니다. OAuth의 개념은 "클라이언트"와 "서비스 제공자" 사이에 인증 계층을 설정합니다. "클라이언트"는 "서비스 제공자"에 직접 로그인할 수 없으며 사용자와 클라이언트를 구별하기 위해 인증 레이어에만 로그인할 수 있습니다. 인증 레이어에 로그인하기 위해 "클라이언트"가 사용하는 토큰은 사용자의 비밀번호와 다릅니다. 사용자는 로그인 시 인증 레이어 토큰의 권한 범위와 유효 기간을 지정할 수 있습니다. "클라이언트"가 인증 레이어에 로그인한 후 "서비스 제공자"는 토큰의 권한 범위 및 유효 기간에 따라 사용자의 저장된 정보를 "클라이언트"에게 공개합니다. OAuth 2.0의 작업 프로세스는 RFC 6749에서 발췌하여 아래와 같습니다. (A) 사용자가 클라이언트를 연 후 클라이언트는 사용자에게 승인을 요구합니다. (B) 사용자는 클라이언트에게 권한을 부여하는 데 동의합니다. (C) 클라이언트는 이전 단계에서 얻은 인증을 사용하여 인증 서버에서 토큰을 신청합니다. (D) 클라이언트 인증 후, 인증 서버는 그것이 맞는지 확인하고 토큰 발급에 동의합니다. (E) 클라이언트는 토큰을 사용하여 리소스 서버에 적용하여 리소스를 얻습니다. (F)资源服务器确认令牌无误,同意向客户端开放资源。 不难看出来,上面六个步骤之中,B是关键,即用户怎样才能给于客户端授权。有了这个授权以后,客户端就可以获取令牌,进而凭令牌获取资源。 下面一一讲解客户端获取授权的四种模式。 客户端必须得到用户的授权(authorization grant),才能获得令牌(access token)。OAuth 2.0定义了四种授权方式。 授权码模式(authorization code) 简化模式(implicit) 密码模式(resource owner password credentials) 客户端模式(client credentials) 授权码模式(authorization code)是功能最完整、流程最严密的授权模式。它的特点就是通过客户端的后台服务器,与"服务提供商"的认证服务器进行互动。 它的步骤如下: (A)用户访问客户端,后者将前者导向认证服务器。 (B)用户选择是否给予客户端授权。 (C)假设用户给予授权,认证服务器将用户导向客户端事先指定的"重定向URI"(redirection URI),同时附上一个授权码。 (D)客户端收到授权码,附上早先的"重定向URI",向认证服务器申请令牌。这一步是在客户端的后台的服务器上完成的,对用户不可见。 (E)认证服务器核对了授权码和重定向URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。 下面是上面这些步骤所需要的参数。 A步骤中,客户端申请认证的URI,包含以下参数: response_type:表示授权类型,必选项,此处的值固定为"code" client_id:表示客户端的ID,必选项 redirect_uri:表示重定向URI,可选项 scope:表示申请的权限范围,可选项 state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。 下面是一个例子。 C步骤中,服务器回应客户端的URI,包含以下参数: code:表示授权码,必选项。该码的有效期应该很短,通常设为10分钟,客户端只能使用该码一次,否则会被授权服务器拒绝。该码与客户端ID和重定向URI,是一一对应关系。 state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。 下面是一个例子。 D步骤中,客户端向认证服务器申请令牌的HTTP请求,包含以下参数: grant_type:表示使用的授权模式,必选项,此处的值固定为"authorization_code"。 code:表示上一步获得的授权码,必选项。 redirect_uri:表示重定向URI,必选项,且必须与A步骤中的该参数值保持一致。 client_id:表示客户端ID,必选项。 下面是一个例子。 E步骤中,认证服务器发送的HTTP回复,包含以下参数: access_token:表示访问令牌,必选项。 token_type:表示令牌类型,该值大小写不敏感,必选项,可以是bearer类型或mac类型。 expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。 refresh_token:表示更新令牌,用来获取下一次的访问令牌,可选项。 scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。 下面是一个例子。 从上面代码可以看到,相关参数使用JSON格式发送(Content-Type: application/json)。此外,HTTP头信息中明确指定不得缓存。 简化模式(implicit grant type)不通过第三方应用程序的服务器,直接在浏览器中向认证服务器申请令牌,跳过了"授权码"这个步骤,因此得名。所有步骤在浏览器中完成,令牌对访问者是可见的,且客户端不需要认证。 它的步骤如下: (A)客户端将用户导向认证服务器。 (B)用户决定是否给于客户端授权。 (C)假设用户给予授权,认证服务器将用户导向客户端指定的"重定向URI",并在URI的Hash部分包含了访问令牌。 (D)浏览器向资源服务器发出请求,其中不包括上一步收到的Hash值。 (E)资源服务器返回一个网页,其中包含的代码可以获取Hash值中的令牌。 (F)浏览器执行上一步获得的脚本,提取出令牌。 (G)浏览器将令牌发给客户端。 下面是上面这些步骤所需要的参数。 A步骤中,客户端发出的HTTP请求,包含以下参数: response_type:表示授权类型,此处的值固定为"token",必选项。 client_id:表示客户端的ID,必选项。 redirect_uri:表示重定向的URI,可选项。 scope:表示权限范围,可选项。 state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。 下面是一个例子。 C步骤中,认证服务器回应客户端的URI,包含以下参数: access_token:表示访问令牌,必选项。 token_type:表示令牌类型,该值大小写不敏感,必选项。 expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。 scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。 state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。 下面是一个例子。 在上面的例子中,认证服务器用HTTP头信息的Location栏,指定浏览器重定向的网址。注意,在这个网址的Hash部分包含了令牌。 根据上面的D步骤,下一步浏览器会访问Location指定的网址,但是Hash部分不会发送。接下来的E步骤,服务提供商的资源服务器发送过来的代码,会提取出Hash中的令牌。 密码模式(Resource Owner Password Credentials Grant)中,用户向客户端提供自己的用户名和密码。客户端使用这些信息,向"服务商提供商"索要授权。 在这种模式中,用户必须把自己的密码给客户端,但是客户端不得储存密码。这通常用在用户对客户端高度信任的情况下,比如客户端是操作系统的一部分,或者由一个著名公司出品。而认证服务器只有在其他授权模式无法执行的情况下,才能考虑使用这种模式。 它的步骤如下: (A)用户向客户端提供用户名和密码。 (B)客户端将用户名和密码发给认证服务器,向后者请求令牌。 (C)认证服务器确认无误后,向客户端提供访问令牌。 B步骤中,客户端发出的HTTP请求,包含以下参数: grant_type:表示授权类型,此处的值固定为"password",必选项。 username:表示用户名,必选项。 password:表示用户的密码,必选项。 scope:表示权限范围,可选项。 下面是一个例子。 C步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。 上面代码中,各个参数的含义参见《授权码模式》一节。 整个过程中,客户端不得保存用户的密码。 客户端模式(Client Credentials Grant)指客户端以自己的名义,而不是以用户的名义,向"服务提供商"进行认证。严格地说,客户端模式并不属于OAuth框架所要解决的问题。在这种模式中,用户直接向客户端注册,客户端以自己的名义要求"服务提供商"提供服务,其实不存在授权问题。 它的步骤如下: (A)客户端向认证服务器进行身份认证,并要求一个访问令牌。 (B)认证服务器确认无误后,向客户端提供访问令牌。 A步骤中,客户端发出的HTTP请求,包含以下参数: granttype:表示授权类型,此处的值固定为"clientcredentials",必选项。 scope:表示权限范围,可选项。 认证服务器必须以某种方式,验证客户端身份。 B步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。 上面代码中,各个参数的含义参见《授权码模式》一节。 如果用户访问的时候,客户端的"访问令牌"已经过期,则需要使用"更新令牌"申请一个新的访问令牌。 客户端发出更新令牌的HTTP请求,包含以下参数: granttype:表示使用的授权模式,此处的值固定为"refreshtoken",必选项。 refresh_token:表示早前收到的更新令牌,必选项。 scope:表示申请的授权范围,不可以超出上一次申请的范围,如果省略该参数,则表示与上一次一致。 下面是一个例子。 (完) <br/> yii2框架的安装我们在之前文章中已经提到下面我们开始了解YII2框架 强大的YII2框架网上指南:http://www.yii-china.com/doc/detail/1.html?postid=278或者<br/> http://www.yiichina.com/doc/guide/2.0<br/> Yii2的应用结构:<br/> 目录篇:<br/> <br/> <br/> <br/>3.console 콘솔 애플리케이션에는 시스템에 필요한 콘솔 명령이 포함되어 있습니다. <br/> 그 중 config이 일반적인 구성이며 이러한 구성은 프런트엔드와 백엔드 및 명령줄에 적용됩니다. mail은 애플리케이션 프런트엔드와 백엔드 및 명령줄의 이메일 관련 레이아웃 파일입니다. models은 프런트엔드와 백엔드, 명령줄 모두에서 사용할 수 있는 데이터 모델입니다. 이는 common에서 가장 중요한 부분이기도 합니다. <br/> 공용 디렉터리(Common)에 포함된 파일은 다른 응용 프로그램 간에 공유하는 데 사용됩니다. 예를 들어, 각 애플리케이션은 ActiveRecord를 사용하여 데이터베이스에 액세스해야 할 수 있습니다. 따라서 AR 모델 클래스를 공통 디렉터리에 배치할 수 있습니다. 마찬가지로 일부 도우미나 위젯이 여러 애플리케이션에서 사용되는 경우 코드 중복을 피하기 위해 이들을 공통 디렉터리에 배치해야 합니다. 곧 설명하겠지만, 애플리케이션은 공통 구성의 일부를 공유할 수도 있습니다. 따라서 일반적인 공통 구성을 config 디렉터리에 저장할 수도 있습니다. <br/>개발 주기가 긴 대규모 프로젝트를 개발할 때는 데이터베이스 구조를 지속적으로 조정해야 합니다. 이러한 이유로 DB 마이그레이션 기능을 사용하여 데이터베이스 변경 사항을 추적할 수도 있습니다. 또한 모든 DB 마이그레이션 디렉터리를 공통 디렉터리 아래에 배치합니다. <br/><br/>5.environment 각 Yii 환경은 항목 스크립트 index.php 및 다양한 구성 파일을 포함한 구성 파일 세트입니다. 실제로 이들은 모두 /environments 디렉터리에 있습니다. <br/> 디렉터리 dev 디렉터리 prod 파일 index.php 그 중 dev와 prod는 동일한 구조를 가지며 각각 4개의 디렉터리와 1개의 파일을 포함합니다. frontend 디렉터리는 프런트엔드 응용 프로그램에 사용되며 저장할 구성이 포함되어 있습니다. 구성 파일 웹 항목 스크립트를 저장하는 디렉토리 및 웹 디렉토리 백엔드 디렉토리, 백그라운드 애플리케이션에 사용, 내용은 프론트엔드와 동일 콘솔 디렉토리, 명령줄 애플리케이션에 사용, 구성 디렉토리만 포함 , 명령줄 응용 프로그램 웹 항목 스크립트에는 필요하지 않으므로 웹 디렉터리가 없습니다. common 디렉터리는 다양한 웹 애플리케이션과 명령줄 애플리케이션의 공통 환경 구성에 사용됩니다. 서로 다른 애플리케이션이 동일한 입력 스크립트를 공유할 수 없기 때문에 여기에는 config 디렉터리만 포함됩니다. 이 공통성의 수준은 환경의 수준보다 낮습니다. 즉, 그 보편성은 모든 환경이 아닌 특정 환경에서만 공통적입니다. yii 파일은 명령줄 응용 프로그램의 입력 스크립트 파일입니다. 여기저기 흩어져 있는 웹 및 구성 디렉터리의 경우에도 공통점이 있습니다. 모든 웹 디렉토리는 웹 애플리케이션의 입력 스크립트, index.php 및 index-test.php의 테스트 버전을 저장합니다. 모든 구성 디렉토리는 로컬 구성 정보 main-local.php 및 params-local을 저장합니다. .php <br/>6.vendor 1、入口文件路径:<br/> http://127.0.0.1/yii2/advanced/frontend/web/index.php 每个应用都有一个入口脚本 web/index.PHP,这是整个应用中唯一可以访问的 PHP 脚本。一个应用处理请求的过程如下: 1.用户向入口脚本 web/index.php 发起请求。 <br/>2.入口脚本加载应用配置并创建一个应用实例去处理请求。 <br/>3.应用通过请求组件解析请求的路由。 <br/>4.应用创建一个控制器实例去处理请求。 <br/>5.控制器创建一个操作实例并针对操作执行过滤器。 <br/>6.如果任何一个过滤器返回失败,则操作退出。 <br/>7.如果所有过滤器都通过,操作将被执行。 <br/>8.操作会加载一个数据模型,或许是来自数据库。<br/>9.操作会渲染一个视图,把数据模型提供给它。 <br/>10.渲染结果返回给响应组件。 <br/>11.响应组件发送渲染结果给用户浏览器 可以看到中间有模型-视图-控制器 ,即常说的MVC。入口脚本并不会处理请求,而是把请求交给了应用主体,在处理请求时,会用到控制器,如果用到数据库中的东西,就会去访问模型,如果处理请求完成,要返回给用户信息,则会在视图中回馈要返回给用户的内容。<br/> 2、为什么我们访问方法会出现url加密呢? 我们找到文件:vendor/yiisoft/yii2/web/UrlManager.php <br/> MVC篇: 一、控制器详解: 1、修改默认控制器和方法 修改全局控制器:打开vendor/yiisoft/yii2/web/Application.php eg: 2、建立控制器示例:StudentController.php //命名空间<br/> <br/> <br/><br/> //显示视图<br/> return $this->render('add'); 默认.php<br/> return $this->render('upda',["data"=>$data]); <br/><br/> } <br/>}<br/><br/> 二、模型层详解 简单模型建立: <br/> <br/><br/> 三、视图层详解首先在frontend下建立与控制器名一致的文件(小写)eg:student 在文件下建立文件<br/> eg:index.php<br/>每一个controller对应一个view的文件夹,但是视图文件yii不要求是HTML,而是php,所以每个视图文件php里面都是视图片段: 当然了,视图与模板之间还有数据传递以及继承覆盖的功能。<br/><br/><br/><br/><br/><br/> YII2框架数据的运用 1、数据库连接 简介 一个项目根据需要会要求连接多个数据库,那么在yii2中如何链接多数据库呢?其实很简单,在配置文件中稍加配置即可完成。 配置 打开数据库配置文件common\config\main-local.php,在原先的db配置项下面添加db2,配置第二个数据库的属性即可 [php] view plain copy 如上配置就可以完成yii2连接多个数据库的功能,但还是需要注意几个点 如果使用的数据库前缀 在建立模型时 这样: eg:这个库叫 haiyong_test return {{%test}}<br/> 应用 1.我们在hyii数据库中新建一个测试表test 2.通过gii生成模型,这里需要注意的就是数据库链接ID处要改成db2<br/> 3.查看生成的模型,比正常的model多了红色标记的地方 所以各位童鞋,如果使用多数据配置,在建db2的模型的时候,也要加上上图红色的代码。 好了,以上步骤就完成了,yii2的多数据库配置,配置完成之后可以和原因一样使用model或者数据库操作 2、数据操作: <br/>方式一:使用createCommand()函数<br/> 增加 <br/> 获取自增id [php] view plain copy 批量插入数据 [php] view plain copy 修改 [php] view plain copy 方式二:模型处理数据(优秀程序媛必备)!! <br/> 新增(因为save方法有点low)所以自己在模型层中定义:add和addAll方法<br/> 注意:!!!当setAttributes($attributes,fase);时不用设置rules规则,否则则需要设置字段规则;<br/> 删除<br/> 使用model::delete()进行删除 [php] view plain copy 直接删除:删除年龄为30的所有用户 [php] view plain copy 根据主键删除:删除主键值为1的用户<br/> [php] view plain copy <br/> <br/> <br/> <br/> <br/> 修改<br/> 使用model::save()进行修改 <br/> <br/> <br/> 直接修改:修改用户test的年龄为40<br/> <br/> <br/> 基础查询 <br/> <br/> 关联查询 <br/> <br/> <br/> 翻译 2015年07月30日 10:29:03 <br/> yii2 rbac 详解DbManager <br/> 1.yii config文件配置(我用的高级模板)(配置在common/config/main-local.php或者main.php) 'authManager' => [ 'class' => 'yiirbacDbManager', 'itemTable' => 'auth_item', 'itemChildTable' => <br/> 2.물론 구성에서 기본 역할을 설정할 수도 있지만 쓰지 않았습니다. Rbac는 PhpManager 및 DbManager라는 두 가지 클래스를 지원합니다. 여기서는 DbManager을 사용합니다. yii migration (이 명령을 실행하여 사용자 테이블 생성) <br/>yii migration --migrationPath=@yii/rbac/migrations/ 이 명령을 실행하여 아래와 같이 권한 데이터 테이블을 생성합니다<br/>3.yii rbac 실제 작업 테이블은 4개입니다 <br/> 推荐文章 微信H5支付完整版含PHP回调页面.代码精简2018年2月 <br/>支付宝手机支付,本身有提供一个手机网站支付DEMO,是lotusphp版本的,里面有上百个文件,非常复杂.本文介绍的接口, <br/>只需通过一个PHP文件即可实现手机支付宝接口的付款,非常简洁,并兼容微信. <br/>代码在最下面. 注意事项(重要): <br/>一,支付宝接口已经升级了加密方式,现在申请的接口都是公钥加私钥的加密形式.公钥与私钥都需要申请者自己生成,而且是成对的,不能拆开用.并把公钥保存到支付宝平台,该公钥对应的私钥不需要保存在支付宝,只能自己保存,并放在api支付宝接口文件中使用.下面会提到. APPID 应该填哪个呢? 这个是指开放平台id,格式应该填2018或2016等日期开头的,不要填合作者pid,那个pid新版不需要的.APPID下面还对应一个网关.这个也要对应填写.正式申请通过的网关为https://openapi.alipay.com/gateway.do 如果你是沙箱测试账号, <br/>则填https://openapi.alipaydev.com/gateway.do 注意区别 <br/>密钥生成方式为, https://docs.open.alipay.com/291/105971 打开这个地址,下载该相应工具后,解压打开文件夹,运行“RSA签名验签工具.bat”这个文件后.打开效果如下图 <br/>如果你的网站是jsp的,密钥格式如下图,点击选择第一个pkcs8的,如果你的网站是php,asp等,则点击pkcs1 <br/>密钥长度统一为2048位. <br/>然后点击 生成密钥 <br/>然后,再点击打开密钥文件路径按钮.即可看到生成的密钥文件,打开txt文件.即可看到生成的公钥与私钥了. <br/>公钥复制后(注意不要换行),需提供给支付宝账号管理者,并上传到支付宝开放平台。如下图第二 <br/>界面示例: <br/> 二,如下,同步回调地址与异步回调地址的区别. <br/>同步地址是指用户付款成功,他自动跳转到这个地址,以get方式返回,你可以设置为跳转回会员中心,也可以转到网站首页或充值日志页面,通过$_GET 的获取支付宝发来的签名,金额等参数.然后进本地数据库验证支付是否正常. <br/>而异步回调地址指支付成功后,支付宝会自动多次的访问你的这个地址,以静默方式进行,用户感受不到地址的跳转.注意,异步回调地址中不能有问号,&等符号,可以放在根目录中.如果你设置为notify_url.php,则你也需要在notify_url.php这个文件中做个判断.比如如果用户付款成功了.则用户的余额则增加多少,充值状态由付款中.修改为付款成功等. 1 2 三,orderName 订单名称,注意编码,否则签名可能会失败 <br/>向支付宝发起支付请求时,有个orderName 订单名称参数.注意这个参数的编码,如果你的本页面是gb2312编码,$this->charset = ‘UTF-8’这个参数最好还是UTF-8,不需要修改.否则签名时,可能会出现各种问题.,可用下面的方法做个转码. 1 四,微信中如何使用支付宝 <br/>支付宝有方案,可以进这个页面把ap.js及pay.htm下载后,保存到你的支付文件pay.php文件所在的目录中. <br/>方案解释,会员在微信中打开你网站的页面,登录,并点击充值或购买链接时,他如果选择支付宝付款,则ap.js会自动弹出这个pay.htm页面,提示你在右上角选择用浏览器中打开,打开后,自动跳转到支付宝app中,不需要重新登录原网站的会员即可完成充值,并跳转回去. <br/>注意,在你的客户从微信转到手机浏览器后,并没有让你重新登录你的商城网站,这是本方案的优势所在. <br/>https://docs.open.alipay.com/203/105285/ 五,如果你申请的支付宝手机支付接口在审核中,则可以先申请一个沙箱测试账号,该账号申请后就可以使用非常方便.同时会提供你一个支付宝商家账号及买家测试账号.登录即可测试付款情况. 代码如下(参考) <br/>一.表单付款按钮所在页面代码 <br/> 二,pay.php页面代码(核心代码) 三,回调页面案例一,即notify_url.php文件. post回调, 四.异步回调案例2, 与上面三是重复的,可选择其中一个.本回调可直接放根目录中 如果你服务器不支持mysqli 就替换为mysql 测试回调时, 请先直接访问本页面,进行测试.订单号可以先写一个固定值. 参考原文 <br/>http://blog.csdn.net/jason19905/article/details/78636716 <br/>https://github.com/dedemao/alipay <br/> 抓包就是把网络数据包用软件截住或者纪录下来,这样做我们可以分析网络数据包,可以修改它然后发送一个假包给服务器,这种技术多应用于网络游戏外挂的制作方面或者密码截取等等 常用的几款抓包工具!<br/>标签: 软件测试软件测试方法软件测试学习<br/>原创来自于我们的微信公众号:软件测试大师 <br/>最近很多同学,说面试的时候被问道,有没有用过什么抓包工具,其实抓包工具并没有什么很难的工具,只要你知道你要用抓包是干嘛的,就知道该怎么用了!一般<br/>对于测试而言,并不需要我们去做断点或者是调试代码什么的,只需要用一些抓包工具抓取发送给服务器的请求,观察下它的请求时间还有发送内容等等,有时候,<br/>可能还会用到这个去观察某个页面下载组件消耗时间太长,找出原因,要开发做性能调优。那么下面就给大家推荐几款抓包工具,好好学习下,下次面试也可以拿来<br/>装一下了! <br/>1<br/>Flidder<br/>Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 <br/>HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是<br/>web调试的利器。<br/>小编发现了有个兄台写的不错的文章,分享给大家,有兴趣的同学,可以自己去查阅并学习下,反正本小编花了点时间就学会了,原来就这么回事!作为测试学会这点真的是足够用了!<br/>学习链接如下:<br/>http://blog.csdn.net/ohmygirl/article/details/17846199<br/>http://blog.csdn.net/ohmygirl/article/details/17849983<br/>http://blog.csdn.net/ohmygirl/article/details/17855031 2<br/>Httpwatch<br/>火狐浏览器下有著名的httpfox,而HttpWatch则是IE下强大的网页数据分析工具。教程小编也不详述了,找到了一个超级棒的教程!真心很赞!要想学习的同学,可以点击链接去感受下!<br/>http://jingyan.baidu.com/article/5553fa820539ff65a339345d.html <br/>3其他浏览器的内置抓包工具<br/>如果用过Firefox的F12功能键,应该也知道这里也有网络抓包的工具,是内置在浏览器里面的,貌似现在每款浏览器都有这个内置的抓包工具,虽然没有上面两个工具强大,但是对于测试而言,我觉得是足够了!下面是一个非常详细的教程,大家可以去学习下。<br/>http://jingyan.baidu.com/article/3c343ff703fee20d377963e7.html 对于想学习点新知识去面试装逼的同学,小编只能帮你们到这里了,要想学习到新知识,除了动手指去点击这些链接,还需要你们去动脑好好学习下! <br/> <br/> 超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。 为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。 一、HTTP和HTTPS的基本概念 HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。 HTTPS: 보안을 목표로 하는 HTTP 채널입니다. 간단히 말해서 HTTP의 보안 버전입니다. 즉, HTTP에 SSL 레이어가 추가된 것입니다. HTTPS의 보안 기반은 SSL이므로 암호화 세부 사항에는 SSL이 필요합니다. HTTPS 프로토콜의 주요 기능은 두 가지 유형으로 나눌 수 있습니다. 하나는 데이터 전송의 보안을 보장하기 위한 정보 보안 채널을 구축하는 것이고, 다른 하나는 웹사이트의 신뢰성을 확인하는 것입니다. 2. HTTP와 HTTPS의 차이점은 무엇인가요? HTTP 프로토콜로 전송되는 데이터는 암호화되지 않습니다. 즉, 일반 텍스트이므로 개인 정보를 전송하기 위해 HTTP 프로토콜을 사용하는 것은 매우 안전하지 않습니다. Netscape에서 설계한 SSL(Secure Sockets Layer) 프로토콜은 HTTP 프로토콜에서 전송되는 데이터를 암호화하는 데 사용되므로 HTTPS가 탄생했습니다. 간단히 말해서 HTTPS 프로토콜은 암호화된 전송과 신원 인증을 수행할 수 있는 SSL+HTTP 프로토콜로 구축된 네트워크 프로토콜로 http 프로토콜보다 더 안전합니다. HTTPS와 HTTP의 주요 차이점은 다음과 같습니다. 1. https 프로토콜은 CA에서 인증서를 신청해야 합니다. 일반적으로 무료 인증서가 적기 때문에 일정한 수수료가 필요합니다. 2. http는 하이퍼텍스트 전송 프로토콜이며 정보는 일반 텍스트로 전송되는 반면 https는 안전한 SSL 암호화 전송 프로토콜입니다. 3. http와 https는 전혀 다른 연결 방식을 사용하며, 전자는 80이고 후자는 443입니다. 4. http 연결은 매우 간단하고 상태가 없습니다. HTTPS 프로토콜은 암호화된 전송 및 ID 인증을 수행할 수 있는 SSL+HTTP 프로토콜로 구축된 네트워크 프로토콜이며 http 프로토콜보다 더 안전합니다. 3. HTTPS 작동 방식 우리는 HTTPS가 정보를 암호화하여 제3자가 민감한 정보를 얻는 것을 방지할 수 있다는 것을 알고 있으므로 보안 수준이 더 높은 많은 은행 웹사이트나 이메일 및 기타 서비스가 HTTPS 프로토콜을 사용합니다. . 1. 클라이언트가 HTTPS 요청을 시작합니다 이에 대해 사용자는 브라우저에 https URL을 입력한 다음 서버의 443 포트에 연결합니다. 2. 서버 구성 HTTPS 프로토콜을 사용하는 서버에는 디지털 인증서 세트가 있어야 합니다. 직접 만들 수도 있고 기관에 신청할 수도 있습니다. 차이점은 직접 발급한 인증서를 인증해야 한다는 것입니다. 신뢰할 수 있는 회사가 적용한 인증서를 사용하는 경우 프롬프트 페이지가 나타나지 않습니다(startssl은 1년 무료 서비스를 제공하는 좋은 선택입니다). 이 인증서 세트는 실제로 공개 키와 개인 키의 쌍입니다. 공개 키와 개인 키를 이해하지 못하면 키와 자물쇠로 생각할 수 있습니다. 이 열쇠를 가진 사람은 자물쇠를 다른 사람에게 줄 수 있고, 그 사람은 이 자물쇠를 이용해 중요한 물건을 잠근 후 당신에게 보낼 수 있습니다. 이 자물쇠로. 3. 인증서 전송 이 인증서는 실제로 공개 키이지만 인증서 발급 기관, 만료 시간 등 많은 정보가 포함되어 있습니다. 4. 클라이언트가 인증서를 구문 분석합니다. 이 작업은 클라이언트의 TLS에 의해 수행됩니다. 먼저 발급 기관, 만료 시간 등 공개 키가 유효한지 확인합니다. 이상이 발견되면 인증서에 문제가 있음을 알리는 경고 상자가 나타납니다. 인증서에 문제가 없으면 임의의 값을 생성한 후 인증서를 사용하여 임의의 값을 암호화합니다. 위에서 언급한 것처럼 임의의 값을 잠금 장치로 잠궈서 키가 없으면 암호화할 수 없습니다. 라이브 콘텐츠가 잠겨 있는지 확인하세요. 5. 암호화된 정보 전송 이 부분은 인증서로 암호화된 임의의 값을 전송하는 부분입니다. 앞으로는 클라이언트와 서버 간의 통신을 통해 암호화할 수 있습니다. 이 임의의 값이 해독되었습니다. 6. 서비스 세그먼트 복호화 정보 서버는 개인 키로 정보를 복호화한 후 클라이언트가 전달한 임의의 값(개인 키)을 얻은 다음 이 값을 사용하여 콘텐츠를 대칭적으로 암호화합니다. 대칭암호라고 불리는 것은 정보와 개인키가 일정한 알고리즘을 통해 혼합되어 개인키를 모르면 내용을 얻을 수 없고, 암호화가 이루어지기만 하면 클라이언트와 서버 모두 이 개인키를 알고 있는 것을 의미한다. 알고리즘은 충분히 강력하고 개인 키는 충분히 복잡하며 데이터는 충분히 안전합니다. 7. 암호화된 정보 전송 이 부분의 정보는 서비스 세그먼트에서 개인키로 암호화된 정보로 클라이언트에서 복원이 가능합니다. 8. 클라이언트는 정보를 복호화합니다. 클라이언트는 이전에 생성된 개인 키를 사용하여 서비스 세그먼트가 전달한 정보를 복호화한 후, 전체 과정에서 제3자가 데이터를 모니터링하더라도 복호화된 내용을 얻습니다. 할 일이 없습니다. 6. HTTPS의 장점 HTTPS는 매우 안전하기 때문에 공격자가 시작점을 찾을 수 없습니다. 웹마스터의 관점에서 HTTPS의 장점은 다음 두 가지입니다. 1. SEO 측면에서 Google은 2014년 8월 검색 엔진 알고리즘을 조정하고 "동등한 HTTP 웹 사이트와 비교하여 HTTPS 암호화를 사용하는 웹 사이트가 검색 결과에서 더 높은 순위를 차지할 것"이라고 밝혔습니다. 2. 보안 HTTPS는 절대적으로 안전하지는 않지만 루트 인증서를 마스터하는 조직과 암호화 알고리즘을 마스터하는 조직도 중간자 공격을 수행할 수 있습니다. 그러나 HTTPS는 여전히 가장 안전한 솔루션입니다. 현재 아키텍처의 주요 이점은 다음과 같습니다. (1), HTTPS 프로토콜을 사용하여 사용자와 서버를 인증하여 데이터가 올바른 클라이언트와 서버로 전송되도록 합니다. (2), HTTPS 프로토콜은 암호화된 전송 및 ID를 수행할 수 있는 SSL+HTTP 프로토콜로 구축된 네트워크입니다. 인증 프로토콜은 HTTP 프로토콜보다 더 안전하며 전송 중에 데이터가 도난당하거나 변경되는 것을 방지하여 데이터 무결성을 보장할 수 있습니다. (3) HTTPS는 현재 아키텍처에서 가장 안전한 솔루션이지만 절대적으로 안전하지는 않지만 중간자 공격 비용을 크게 증가시킵니다. 7. HTTPS의 단점 HTTPS는 상대적으로 큰 장점을 갖고 있지만, 구체적으로 다음과 같은 2가지 점이 있습니다. 1. SEO 측면 ACM CoNEXT 데이터에 따르면. , HTTPS 프로토콜을 사용하면 페이지 로딩 시간이 거의 50% 연장되고 전력 소비도 10~20% 증가합니다. 또한 HTTPS 프로토콜은 캐싱에도 영향을 미치고 데이터 오버헤드와 전력 소비를 증가시킵니다. 영향을 받고 이로 인해 영향을 받는 안전 조치도 있습니다. 게다가 HTTPS 프로토콜의 암호화 범위도 상대적으로 제한되어 있어 해커 공격, 서비스 거부 공격, 서버 하이재킹 등에 거의 영향을 미치지 않습니다. 가장 중요한 점은 SSL 인증서의 신용 체인 시스템이 안전하지 않다는 것입니다. 특히 일부 국가에서 CA 루트 인증서를 제어할 수 있는 경우 중간자 공격도 가능합니다. 2. 경제적 측면 (1) SSL 인증서는 비용이 많이 듭니다. 인증서가 강력할수록 비용도 높아집니다. 개인 웹사이트나 소규모 웹사이트는 일반적으로 필요하지 않으면 사용하지 않습니다. (2) SSL 인증서는 일반적으로 IP에 바인딩되어야 합니다. 여러 도메인 이름은 동일한 IP에 바인딩될 수 없습니다. IPv4 리소스는 이러한 사용을 지원할 수 없습니다. SSL에는 이 문제를 부분적으로 해결할 수 있는 확장이 있지만 더 까다롭습니다. 브라우저, 운영 체제 지원이 필요합니다. Windows XP는 이 확장 기능을 지원하지 않으며 XP의 설치 용량을 고려하면 이 기능은 거의 쓸모가 없습니다. (3) HTTPS 연결 캐싱은 HTTP만큼 효율적이지 않으며 트래픽이 많은 웹사이트에서는 필요하지 않으면 사용하지 않으며 트래픽 비용도 너무 높습니다. (4) HTTPS 연결 서버 측 리소스는 훨씬 높으며 방문자가 약간 더 많은 웹 사이트를 지원하려면 더 많은 비용이 필요합니다. 모든 HTTPS를 채택하면 대부분의 컴퓨팅 리소스가 유휴 상태라는 가정에 따라 VPS의 평균 비용이 증가합니다. (5) HTTPS 프로토콜의 핸드셰이크 단계는 시간이 많이 걸리고 웹사이트의 응답 속도에 부정적인 영향을 미칩니다. 필요하지 않다면 사용자 경험을 희생할 이유가 없습니다. <br/> <br/> 퍼지 쿼리에 msyql을 사용할 때는 like 문을 사용하는 것이 당연합니다. 일반적으로 데이터의 양이 적을 때는 보기가 쉽지 않습니다. 그러나 데이터의 양이 수백만 또는 수천만에 도달하면 쿼리 효율성이 쉽게 드러납니다. 이때 쿼리의 효율성이 매우 중요해집니다! <br/><br/> <br/><br/>일반적으로 유사 퍼지 쿼리는 다음과 같이 작성됩니다(필드가 색인화됨): <br/><br/>SELECT `column` FROM `table` WHERE `field` like '%keyword%';<br/><br/>위 명령문은 explain Look으로 설명됩니다. , SQL 문은 인덱스를 사용하지 않으며 전체 테이블 검색입니다. 데이터의 양이 엄청나게 많으면 최종 효율성은 이 정도일 것이라고 짐작할 수 있습니다<br/><br/>다음 작성을 비교해 보세요. <br/><br/>SELECT`column ` FROM `table ` WHERE `field` like 'keyword%';<br/><br/> 이 작성 방법을 설명을 사용하여 설명하면 SQL 문이 인덱스를 사용하고 검색 효율성이 크게 향상되는 것을 볼 수 있습니다! <br/><br/> <br/><br/>하지만 가끔 퍼지 쿼리를 할 때 쿼리하려는 키워드가 모두 시작 부분에 있지 않기 때문에 특별한 요구 사항이 없는 한 "keywork%"는 모든 퍼지 쿼리에 적합하지 않습니다 <br/><br/> <br/><br/> 이에 시간이 지나면 다른 방법을 사용해 볼 수 있습니다<br/><br/>1.LOCATE('substr',str,pos) 방법<br/>코드 복사<br/><br/>SELECT LOCATE('xbar',`foobar`) <br/>###Return 0 <br/><br/> SELECT LOCATE ('bar',`foobarbar`); <br/>###Return 4<br/><br/>SELECT LOCATE('bar',`foobarbar`,5);<br/>###Return 7<br/><br/>코드 복사<br/><br/>Remarks: Return substr At the str에서 str이 처음 나타나는 경우, str에 substr이 없으면 반환 값은 0입니다. pos가 존재하면 str의 pos번째 위치 이후에 substr이 처음 나타나는 위치를 반환합니다. str에 substr이 존재하지 않으면 반환 값은 0입니다. <br/><br/>SELECT `column` FROM `table` WHERE LOCATE('keyword', `field`)>0<br/><br/>Remarks: 키워드는 검색할 내용, field는 일치하는 필드, 키워드로 존재하는 모든 데이터를 쿼리<br/> <br/> <br/><br/>2.POSITION('substr' IN `field`) 방법 <br/><br/>position은 Locate와 동일한 기능을 사용하여 Locate의 별칭으로 간주될 수 있습니다. <br/><br/>SELECT `column` FROM `table` WHERE POSITION('keyword' IN `filed`)<br/><br/>3.INSTR(`str`,'substr') 메소드<br/><br/>SELECT `column` FROM `table` WHERE INSTR(`field`, 'keyword' )>0 <br/><br/> <br/><br/>추가로 위의 방법에는 FIND_IN_SET<br/><br/>FIND_IN_SET(str1,str2):<br/><br/> 함수가 있습니다. str2에서 str1의 위치 인덱스를 반환합니다. 여기서 str2는 ","로 구분해야 합니다. <br/><br/>SELECT * FROM `사람` WHERE FIND_IN_SET('적용',`이름`);<br/> 4월 30일 , 2013년 15시 36분:36 : UNIONoperator UNION <br/>연산자는 두 개의 다른 결과 테이블(예: TABLE1 및 TABLE2)을 결합하고 테이블에서 중복 행을 제거하여 결과 테이블을 파생합니다. ALL을 UNION (예: UNION ALL)과 함께 사용하면 중복 행이 제거되지 않습니다. 두 경우 모두 파생 테이블의 각 행은 TABLE1 또는 TABLE2에서 나옵니다. B<br/>: EXCEPToperatorEXCEPT <br/>연산자는 TABLE1에 있는 모든 것을 포함하여 작동하지만 에는 포함하지 않습니다. 행을 에 추가하고 모든 중복 행을 제거하여 결과 테이블을 도출합니다. ALL을 EXCEPT (EXCEPT ALL)과 함께 사용하면 중복 행이 제거되지 않습니다. C<br/>: INTERSECToperatorINTERSECT 연산자에는 <br/> TABLE1 및 TABLE2 만 포함됩니다. 모든 중복 행을 제거하고 결과 테이블을 파생시킵니다. ALL을 INTERSECT (INTERSECT ALL)과 함께 사용하면 중복 행이 제거되지 않습니다. 참고: 연산자 단어를 사용하는 여러 쿼리 결과 줄은 일관성이 있어야 합니다. <br/>다음 문으로 변경하는 것이 좋습니다 --중복 행을 포함한 두 결과 세트를 정렬하지 않고 통합합니다. SELECT * FROM 4 포함 기본 규칙에 따라 정렬하는 동안 행을 복제합니다. SELECT *FROM dbo.banji INTERSECT SELECT * FROM dbo.banjinew; --运算符通过包括所有在TABLE1中但不在TABLE2中的行并消除所有重复行而派生出一个结果表 SELECT * FROM dbo.banji EXCEPT SELECT * FROM dbo.banjinew;<br/>有些DBMS不支持except all和intersect all <br/> 1. 接口<br/> 在php编程语言中接口是一个抽象类型,是抽象方法的集合。接口通常以interface来声明。一个类通过实现接口的方式,从而来实现接口的方法(抽象方法)。<br/> 接口定义: 特别注意:<br/> * 类全部为抽象方法(不需要声明abstract) <br/> * 接口抽象方法是public <br/> * 成员(字段)必须是常量 2. 继承<br/> 继承自另一个类的类被称为该类的子类。这种关系通常用父类和孩子来比喻。子类将继 <br/>承父类的特性。这些特性由属性和方法组成。子类可以增加父类之外的新功能,因此子类也 <br/>被称为父类的“扩展”。<br/> 在PHP中,类继承通过extends关键字实现。继承自其他类的类成为子类或派生类,子 <br/>类所继承的类成为父类或基类。 特别注意:<br/> 有时候并不需要父类的字段和方法,那么可以通过子类的重写来修改父类的字段和方法。 通过重写调用父类的方法<br/> 有的时候,我们需要通过重写的方法里能够调用父类的方法内容,这个时候就必须使用<br/> 语法:父类名::方法()、parent::方法()即可调用。<br/>final关键字可以防止类被继承,有些时候只想做个独立的类,不想被其他类继承使用。 3. 抽象类和方法<br/>抽象类特性:<br/>* 抽象类不能产生实例对象,只能被继承; <br/>* 抽象方法一定在抽象类中,抽象类中不一定有抽象方法; <br/>* 继承一个抽象类时,子类必须重写父类中所有抽象方法; <br/>* 被定义为抽象的方法只是声明其调用方式(参数),并不实现。 3. 多态<br/>多态是指OOP 能够根据使用类的上下文来重新定义或改变类的性质或行为,或者说接口的多种不同的实现方式即为多态。<br/> 관련 추천 : <br/> PHP 객체지향 식별 객체 PHP 객체지향 프로그래밍의 개발 아이디어 및 사례 분석 PHP 객체지향 실무 기초지식 이상은 php 객체지향 상속, 다형성에 대한 소개입니다. , 캡슐화 자세한 내용은 PHP 중국어 웹사이트의 다른 관련 기사를 주목하세요! 태그: PHP의 다형성 캡슐화 이전 기사: PHP에서 WeChat 애플릿 결제 코드 공유 구현 다음 기사: PHP 세션 제어 세션 및 쿠키 소개 추천 2018 -02- 1174 2018-02-1074 2018-02-1059 2018-01-0567 <br/> MVC 패턴 (모델-뷰-컨트롤러)은 소프트웨어 엔지니어링 중 하나입니다. 소프트웨어 아키텍처 패턴 소프트웨어 시스템을 모델, 뷰, 컨트롤러의 세 가지 기본 부분으로 나눕니다. ㅋㅋ A Smalltalk MVC 패턴의 목적은 동적 프로그램 설계를 구현하고, 프로그램의 후속 수정 및 확장을 단순화하며, 프로그램의 특정 부분을 재사용할 수 있도록 하는 것입니다. 또한 이 모드는 복잡성을 단순화하여 프로그램 구조를 보다 직관적으로 만듭니다. 소프트웨어 시스템은 기본 부분을 분리하고 각 기본 부분에 적절한 기능을 부여합니다. 전문가는 자신의 전문 지식에 따라 그룹화될 수 있습니다. (컨트롤러) - 요청 전달 및 처리를 담당합니다. (보기) - 인터페이스 디자이너는 그래픽 인터페이스 디자인을 수행합니다. 데이터가 온라인에 저장되어 있든 직원 목록에 저장되어 있든 뷰에서는 실제 처리가 발생하지 않습니다. 뷰는 데이터를 출력하고 사용자가 이를 조작할 수 있는 방법으로만 사용됩니다. <br/>Model: <br/>모델은 기업 데이터와 비즈니스 규칙을 나타냅니다. MVC의 세 가지 구성 요소 중 모델은 처리 작업이 가장 많습니다(). 예를 들어 EJB 및 ColdFusionComponents와 같은 구성 요소 객체를 사용하여 데이터베이스를 처리할 수 있습니다. 모델이 반환하는 데이터는 중립적입니다. 즉, 모델은 데이터 형식과 아무 관련이 없으므로 모델은 여러 보기에 데이터를 제공할 수 있습니다. 모델에 적용된 코드는 한 번만 작성하면 여러 뷰에서 재사용할 수 있으므로 코드 중복이 줄어듭니다. Controller: <br/>Controller는 사용자 입력을 받아들이고 모델과 뷰를 호출하여 사용자 요구를 완성합니다<br/>. 따라서 웹 페이지의 하이퍼링크를 클릭하고 HTML 양식이 전송되면 컨트롤러 자체는 아무것도 출력하거나 처리하지 않습니다. 단지 요청을 수신하고 요청을 처리하기 위해 호출할 모델 구성 요소를 결정한 다음 반환된 데이터를 표시하는 데 사용할 뷰를 결정합니다. MVC의 장점<br/>1. 낮은 결합<br/> 뷰 레이어와 비즈니스 레이어가 분리되어 있어 모델 및 컨트롤러 코드를 다시 컴파일하지 않고도 뷰 레이어 코드를 변경할 수 있습니다 애플리케이션 비즈니스 프로세스 또는 비즈니스 규칙을 변경하려면 MVC의 모델 계층만 변경하면 됩니다. 모델이 컨트롤러와 뷰와 분리되어 있기 때문에 애플리케이션의 데이터 계층과 비즈니스 규칙을 쉽게 변경할 수 있습니다. <br/>2. 높은 재사용성 및 적용성<br/> 기술이 지속적으로 발전함에 따라 애플리케이션에 액세스하는 데 점점 더 많은 방법이 필요합니다. MVC 패턴을 사용하면 다양한 스타일의 뷰를 사용하여 동일한 서버 측 코드에 액세스할 수 있습니다. 여기에는 웹(HTTP) 브라우저나 무선 브라우저(wap)가 포함됩니다. 예를 들어, 사용자는 컴퓨터나 휴대폰을 통해 특정 상품을 주문할 수 있습니다. 주문 방법은 다르지만 주문한 상품을 처리하는 방법은 동일합니다. 모델에서 반환된 데이터는 형식이 지정되지 않으므로 동일한 구성 요소를 다른 인터페이스에서 사용할 수 있습니다. 예를 들어 많은 데이터가 HTML로 표현될 수도 있지만 WAP로 표현될 수도 있습니다. 이러한 표현에 필요한 명령은 뷰 레이어의 구현을 변경하는 것이지만 컨트롤 레이어와 모델 레이어는 이를 변경할 필요가 없습니다. 모든 변경 사항. <br/>3. 낮은 수명 주기 비용<br/> MVC를 사용하면 사용자 인터페이스를 덜 기술적으로 개발하고 유지 관리할 수 있습니다. <br/>4. 신속한 배포<br/>MVC 패턴을 사용하면 개발 시간을 크게 단축할 수 있어 프로그래머(Java 개발자)는 비즈니스 로직에 집중할 수 있고, 인터페이스 프로그래머(HTML 및 JSP 개발자)는 표현에 집중할 수 있습니다. <br/>5. 유지 관리 가능성<br/> 뷰 레이어와 비즈니스 로직 레이어를 분리하면 웹 애플리케이션을 더 쉽게 유지 관리하고 수정할 수 있습니다. <br/>6. 소프트웨어 엔지니어링 관리에 도움이 됩니다<br/>다양한 계층이 자체 임무를 수행하므로 각 계층의 서로 다른 애플리케이션은 동일한 특성을 가지며 이는 엔지니어링 및 툴링을 통한 프로그램 코드 관리에 도움이 됩니다. 확장자: WAP(무선 응용 프로그램 프로토콜)은 글로벌 네트워크 통신 프로토콜인 무선 응용 프로그램 프로토콜입니다. WAP는 모바일 인터넷에 대한 공통 표준을 제공하며, 그 목표는 인터넷의 풍부한 정보와 고급 서비스를 휴대폰과 같은 무선 단말기에 도입하는 것입니다. WAP은 현재 인터넷상의 HTML 언어 정보를 WML(Wireless Markup Language)로 기술된 정보로 변환하여 휴대폰 디스플레이에 표시하는 범용 플랫폼을 정의합니다. WAP는 휴대폰과 WAP 프록시 서버의 지원만 필요하며 기존 이동통신 네트워크네트워크 프로토콜을 변경할 필요가 없으므로 GSM, CDMA, TDMA, 3G 및 기타 네트워크에서 널리 사용할 수 있습니다. 모바일 인터넷 액세스가 인터넷 시대의 새로운 인기가 되면서 WAP에 대한 다양한 애플리케이션 요구 사항이 등장했습니다. PDA와 같은 일부 휴대용 장치에서는 마이크로 브라우저를 설치한 후 WAP를 사용하여 인터넷에 액세스합니다. 마이크로 브라우저 파일은 매우 작기 때문에 휴대용 장치의 작은 메모리 제한과 부족한 무선 네트워크 대역폭을 더 잘 해결할 수 있습니다. WAP는 HTHL 및 XML을 지원할 수 있지만 WML은 작은 화면과 키보드가 없는 휴대용 장치용으로 특별히 설계된 언어입니다. WAP는 WMLScript도 지원합니다. 이 스크립팅 언어는 JavaScript와 유사하지만 기본적으로 다른 스크립팅 언어에 포함된 쓸모 없는 기능이 없기 때문에 메모리 및 CPU 요구 사항이 낮습니다. <br/> <br/> 까지 제한되며 이후 5번째 추가 -in은 이전 파일이 로드될 때까지 차단됩니다. CDN 파일은 서로 다른 영역(IP 서로 다름)에 저장되므로 브라우저는 페이지에 필요한 모든 파일을 동시에( 4보다 훨씬 더) 로드할 수 있습니다. 따라서 페이지 로딩 속도가 향상됩니다. 2. 파일이 로드되어 캐시에 저장되었을 수 있습니다. js 라이브러리 또는 css 스타일 라이브러리(예: jQuery) 네트워크 의 사용은 매우 일반적입니다. 사용자가 귀하의 웹 페이지 중 하나를 탐색할 때 귀하의 웹 사이트에서 사용하는 CDN을 통해 다른 웹 사이트를 방문했을 가능성이 높습니다. 그런데 이때 이 웹 사이트도 jQuery를 사용합니다. , 사용자의 브라우저는 이미 jQuery 파일을 캐시했기 때문에(IP과 동일한 이름의 파일이 캐시된 경우 브라우저는 캐시된 파일을 직접 사용하고 다시 로드하지 않습니다.) 한 번만 로드하면 웹사이트 액세스 속도가 간접적으로 향상됩니다. 3. 높은 효율성 NB , BaiduNBpass NB Google 맞죠? 좋은 CDN은 더 높은 효율성, 더 낮은 네트워크 대기 시간 및 더 작은 패킷 손실률을 제공합니다. 4. 분산 데이터 센터 귀하의 사이트가 베이징에 있는 경우, 홍콩 또는 그보다 더 멀리 있는 사용자가 귀하의 사이트를 방문하면 그의 데이터 요청은 필연적으로 매우 느려질 것입니다. 그리고 CDNs을 사용하면 사용자가 가장 가까운 노드에서 필요한 파일을 로드할 수 있으므로 로딩 속도가 빨라지는 것은 당연합니다. 5. 내장 버전 관리 일반적으로 CSS 파일과 JavaScript 라이브러리에는 버전 번호가 있습니다. CDN 필요한 파일을 로드하세요. latest를 사용하여 최신 버전을 로드할 수도 있습니다(권장하지 않음). 6. 사용 분석 일반적으로 제공업체(예: Baidu Cloud Acceleration)는 사용자의 자체 웹사이트 방문에 대해 자세히 알아볼 수 있는 데이터 통계 기능을 제공합니다. 통계 데이터를 기반으로 사이트를 적절하게 조정합니다. 7. 웹사이트 공격을 효과적으로 방지합니다일반적인 상황에서는 공급업체에서도 웹사이트 보안 서비스를 제공합니다. 우리가 흔히 말하는 인터넷은 실제로 두 개의 계층으로 구성됩니다. 하나는 TCP/IP를 핵심으로 하는 네트워크 계층, 즉 인터넷이고, 다른 하나는 World Wide Web WWW로 대표되는 애플리케이션 계층입니다. 서버에서 클라이언트로 데이터가 전달될 때 네트워크 정체가 발생할 수 있는 곳은 최소 4곳이 있습니다. 1. "퍼스트마일"은 월드와이드웹(World Wide Web) 트래픽이 사용자에게 전송되는 첫 번째 출구를 의미하며, 웹사이트 서버가 인터넷에 접속하기 위한 링크입니다. 이 송신 대역폭은 웹사이트가 사용자에게 제공할 수 있는 액세스 속도와 동시 방문을 결정합니다. 사용자 요청이 웹 사이트의 송신 대역폭을 초과하면 송신 시 정체가 발생합니다. <br/>2. "라스트 마일", 월드 와이드 웹 트래픽이 사용자에게 전송되는 마지막 링크, 즉 사용자가 인터넷에 접속하는 링크입니다. 사용자 액세스 대역폭은 사용자의 트래픽 수신 능력에 영향을 미칩니다. 통신 사업자의 활발한 발전으로 사용자 액세스 대역폭이 크게 향상되었으며 "라스트 마일" 문제가 기본적으로 해결되었습니다. 3. ISP 상호 연결은 두 네트워크 사업자인 China Telecom과 China Unicom 간의 상호 연결과 같이 인터넷 서비스 제공업체 간의 상호 연결입니다. A 사업자의 전산실에 웹 사이트 서버가 구축되어 있고, B 사업자의 사용자가 해당 웹 사이트에 접속하고자 할 경우, 교차 네트워크 접속을 위해서는 A와 B 사이의 상호 연결 지점을 거쳐야 합니다. 인터넷 아키텍처의 관점에서 볼 때, 서로 다른 운영자 간의 상호 연결 대역폭은 모든 운영자의 네트워크 트래픽에서 매우 작은 부분을 차지합니다. 따라서 이는 네트워크 전송의 정체 지점이 되는 경우가 많습니다. 사용자가 브라우저를 통해 기존(CDN이 없는) 웹사이트에 액세스하는 프로세스는 다음과 같습니다. <br/> CDN을 사용하는 경우 프로세스는 다음과 같습니다. <br/> 웹사이트와 사용자 사이에 CDN을 도입한 후에도 사용자는 원본과 아무런 차이를 느끼지 못할 것입니다. <br/>CDN 서비스를 사용하는 웹사이트는 도메인 이름의 해결 권한을 CDN의 로드 밸런싱 장치에 넘겨주기만 하면 됩니다. CDN 로드 밸런싱 장치는 사용자에게 적합한 캐시 서버를 선택하고 사용자는 액세스하여 필요한 것을 얻을 수 있습니다. 이 캐시 서버. <br/>캐시 서버는 네트워크 사업자의 전산실에 배치되어 있으며, 이들 사업자는 사용자의 네트워크 서비스 제공자이기 때문에 사용자는 최단 경로, 가장 빠른 속도로 웹 사이트에 접속할 수 있습니다. 따라서 CDN은 사용자 액세스 속도를 높이고 원점 센터의 부하 압력을 줄일 수 있습니다. <br/> <br/> 로드 밸런싱 전략: 1. 네트워크의 각 요청은 차례로 내부 서버에 할당됩니다. 그런 다음 다시 시작하세요. 이 균형 조정 알고리즘은 서버 그룹의 모든 서버가 동일한 하드웨어 및 소프트웨어 구성을 갖고 평균 서비스 요청이 상대적으로 균형을 이루는 상황에 적합합니다. 2. Weighted Round Robin: 서버의 다양한 처리 능력에 따라 각 서버에 서로 다른 가중치가 할당되어 해당 가중치로 서비스 요청을 수락할 수 있습니다. 예를 들어 서버 A의 가중치는 1, B의 가중치는 3, C의 가중치는 6으로 설계되면 서버 A, B, C는 서비스의 10%, 30%, 60%를 받게 됩니다. 각각 요청합니다. 이 밸런싱 알고리즘은 고성능 서버의 활용률을 높이고 저성능 서버의 과부하를 방지합니다. 3. 랜덤 밸런스(Random): 네트워크의 요청을 여러 내부 서버에 무작위로 배포합니다. 4. Weighted Random Balancing(Weighted Random): 이 밸런싱 알고리즘은 Weighted Round-Robin 알고리즘과 유사하지만 요청 공유 처리 시 무작위 선택 프로세스입니다. 5. 응답 시간 밸런싱(Response Time): 로드 밸런싱 장치는 각 내부 서버에 감지 요청(Ping 등)을 보낸 후 감지에 대한 각 내부 서버의 가장 빠른 응답 시간을 기준으로 어느 서버에 응답할지 결정합니다. 요청. 클라이언트의 서비스 요청. 이 밸런싱 알고리즘은 서버의 현재 실행 상태를 더 잘 반영할 수 있지만 가장 빠른 응답 시간은 클라이언트와 서버 간의 가장 빠른 응답 시간이 아니라 로드 밸런싱 장치와 서버 간의 가장 빠른 응답 시간만을 의미합니다. 6. > 최소 연결 밸런스 각 서버의 연결 프로세스는 크게 다를 수 있으며 진정한 로드 밸런싱은 달성되지 않습니다. 최소 연결 수 밸런싱 알고리즘에는 내부적으로 로드되어야 하는 각 서버에 대한 데이터 레코드가 있으며, 서버에서 현재 처리 중인 연결 수를 기록합니다. 새로운 서비스 연결 요청이 있는 경우 현재 요청이 할당됩니다. 서버는 연결 수가 가장 적은 서버로 실제 상황과 균형을 맞추고 부하의 균형을 유지합니다. 이 균형 조정 알고리즘은 FTP와 같은 장기 처리 요청 서비스에 적합합니다. 7. 처리 용량 밸런싱: 이 밸런싱 알고리즘은 내부 처리 부하가 가장 적은 서버에 서비스 요청을 할당합니다(서버 CPU 모델, CPU 수, 메모리 크기, 현재 연결 수 등에 따라 변환됨). 내부 서버의 처리 능력과 현재 네트워크 작동 상태를 고려하므로 이 밸런싱 알고리즘은 상대적으로 더 정확하며 특히 일곱 번째 계층(애플리케이션 계층) 로드 밸런싱에 적합합니다. 8. DNS 응답 밸런싱(플래시 DNS): 인터넷에서 HTTP, FTP 또는 기타 서비스 요청이든 클라이언트는 일반적으로 도메인 이름 확인을 통해 서버의 정확한 IP 주소를 찾습니다. 이 밸런싱 알고리즘에 따라 서로 다른 지리적 위치에 있는 로드 밸런싱 장치는 동일한 클라이언트로부터 도메인 이름 확인 요청을 수신하고 동시에 도메인 이름을 해당 서버(즉, 로드 밸런싱 장치)의 IP 주소로 확인합니다. 동일한 지리적 위치에 있는 서버의 IP 주소)를 클라이언트에 반환하면 클라이언트는 처음 수신한 도메인 이름 확인 IP 주소로 계속 서비스를 요청하고 다른 IP 주소 응답은 무시합니다. 이 밸런싱 전략이 글로벌 로드 밸런싱에 적합한 경우 로컬 로드 밸런싱에는 의미가 없습니다. 서비스 오류 감지 방법 및 기능: 1. 핑 감지: 핑을 통해 서버 및 네트워크 시스템 상태를 감지하는 방법은 간단하고 빠르지만 네트워크 및 서버의 운영 체제만 대략적으로 감지할 수 있습니다. 정상이든 아니든 서버에서 애플리케이션 서비스를 탐지하기 위해 할 수 있는 일은 없습니다. 2. TCP 개방 감지: 각 서비스는 TCP 연결을 열고 서버의 특정 TCP 포트(예: Telnet 포트 23, HTTP 포트 80 등)가 열려 있는지 감지하여 서비스가 정상인지 확인합니다. 3. HTTP URL 감지: 예를 들어 main.html 파일에 대한 액세스 요청이 HTTP 서버로 전송된 경우 오류 메시지가 수신되면 서버에 결함이 있는 것으로 간주됩니다. <br/> <br/> 1. 브라우저 캐시 3. 서버 캐시 4. 역방향 프록시 캐시 6. 요약 이 문서의 제목은 우선 "고성능 웹 캐시에 대한 간략한 분석"입니다. "간단한 분석"이라고 명시해야 합니다. "겸손하게 하는 것이 아니라 정말 "얕은" 분석입니다. 저는 신입생으로서 이 글을 쓰기 일주일 전에 프로그래머로서 첫 공식 시스템을 막 시작했습니다. .모든 내용은 제가 직접 읽은 내용이며, 실제 제작 환경과 다를 수 있으니 양해 바랍니다. 1. 동적 콘텐츠 캐싱 1.1 페이지 캐시 동적 웹 페이지의 경우 페이지 캐시(페이지 캐시)라고 하는 생성된 HTML을 캐시합니다. 동적 사진 및 동적 XML 데이터와 같은 다른 동적 콘텐츠의 경우에도 동일한 전략을 사용하여 캐시할 수 있습니다. 결과는 전체적으로 캐시됩니다. Smarty와 같은 템플릿 엔진이나 Zend 및 Diango와 같은 MVC 프레임워크 등 페이지 캐싱을 구현하는 방법은 다양하며 컨트롤러는 자체 캐시 제어를 쉽게 가질 수 있습니다. 일반적으로 우리는 동적 콘텐츠의 캐시를 디스크에 저장합니다. 디스크는 많은 수의 파일을 저장할 수 있는 저렴한 방법을 제공합니다. 공간 문제. 이는 배포하기 쉬운 방법입니다. 그러나 캐시 디렉터리에 많은 수의 캐시 파일이 있어 CPU가 디렉터리를 탐색하는 데 많은 시간을 소비하게 될 가능성은 여전히 있습니다. 따라서 캐시 디렉터리 계층을 사용하여 이 문제를 해결할 수 있습니다. 각 디렉토리 아래의 하위 디렉토리는 다음과 같습니다. 또는 파일 수를 작은 범위 내로 유지하십시오. 이렇게 하면 많은 수의 캐시 파일이 저장될 때 디렉터리를 순회하는 CPU의 시간 소모를 줄일 수 있습니다. 캐시 데이터를 디스크 파일에 저장하는 경우 캐시 로드 및 만료 확인 시마다 디스크 I/O 오버헤드가 발생하며, 디스크 I/O 로드가 클 경우에도 디스크 로드의 영향을 받습니다. 캐시 파일의 I/O 작업이 다소 지연될 수 있습니다. 또한 로컬 메모리에 캐시를 배치할 수 있는데, 이는 PHP의 APC 모듈이나 PHP 캐시 확장 XCache의 도움으로 쉽게 구현할 수 있으므로 캐시를 로드할 때 디스크 I/O 작업이 없습니다. . 마지막으로 캐시를 독립적인 캐시 서버에 저장할 수도 있습니다. Memcached를 사용하면 TCP를 통해 다른 서버에 캐시를 쉽게 저장할 수 있습니다. memcached를 사용하면 로컬 메모리를 사용하는 것보다 약간 느리지만 로컬 메모리에 캐시를 저장하는 것과 비교할 때 memcached를 사용하여 캐싱을 구현하면 두 가지 장점이 있습니다. 웹 서버 메모리는 소중하며 HTML 캐싱을 위한 많은 공간을 제공할 수 없습니다. 별도의 캐시 서버를 사용하면 확장성이 좋습니다. 캐시 만료 확인에 대해 이야기해야 합니다. 캐시 만료 확인은 주로 캐시 유효 기간 메커니즘을 기반으로 확인됩니다. 캐시 생성 시간을 기준으로 캐시 유효 기간에 설정된 시간과 현재 시간을 기준으로 캐시가 생성된 후 현재 시간이 유효 기간을 초과했는지 여부를 판단합니다. 캐시는 만료된 것으로 간주됩니다. 캐시 만료 시간과 현재 시간을 기준으로 판단합니다. 캐시 유효 기간을 설정하는 것이 쉽지 않습니다. 너무 길면 캐시 적중률이 높지만 너무 짧으면 동적 콘텐츠가 제때 업데이트되지 않습니다. 시간이 지나면 업데이트되므로 캐시 적중률이 감소합니다. 따라서 합리적인 유효기간을 설정하는 것도 매우 중요하지만, 더 중요한 것은 유효기간을 언제 변경해야 하는지를 인지하고 언제든지 적절한 값을 찾아내는 능력이 필요하다는 것입니다. 캐시 유효 기간 외에도 캐시는 언제든지 강제로 캐시를 지울 수 있는 제어 방법도 제공합니다. 경우에 따라 페이지의 특정 영역의 콘텐츠를 적시에 업데이트해야 하는 경우 해당 영역을 다시 빌드하는 것은 가치가 없습니다. 전체 페이지 캐시. 널리 사용되는 템플릿 프레임워크는 Smary와 같은 부분적인 캐시 없는 지원을 제공합니다. 이전 방법은 캐시 사용 여부를 동적으로 제어해야 합니다. 정적 방법은 동적 콘텐츠에서 정적 콘텐츠를 생성한 다음 사용자가 정적 콘텐츠를 직접 요청할 수 있도록 하여 처리 속도를 크게 향상시킵니다. 마찬가지로 정적 콘텐츠도 업데이트해야 합니다. 일반적으로 두 가지 방법이 있습니다. 데이터가 업데이트될 때 정적 콘텐츠를 다시 생성합니다. 정적 콘텐츠를 정기적으로 다시 생성하세요. 앞서 언급한 동적 캐시와 유사하게 정적 페이지는 전체 페이지를 업데이트할 필요가 없습니다. SSI(서버 포함) 기술을 통해 각 부분 페이지를 독립적으로 업데이트할 수 있으므로 계산 오버헤드와 재구축에 드는 디스크 I가 크게 줄어듭니다. 전체 페이지 /O 오버헤드 및 배포 시 네트워크 I/O 오버헤드. 요즘 주류 웹 서버는 Apache, lighttpd 등과 같은 SSI 기술을 지원합니다. 공모의 관점에서 사람들은 브라우저를 단지 PC의 소프트웨어로 생각하는 데 익숙하지만 실제로는 브라우저가 웹사이트의 중요한 부분입니다. 브라우저에 콘텐츠를 캐시하면 서버 컴퓨팅 오버헤드를 줄일 수 있을 뿐만 아니라 불필요한 전송 및 대역폭 낭비도 피할 수 있습니다. 캐시된 콘텐츠를 브라우저 측에 저장하기 위해 일반적으로 사용자의 파일 시스템에 캐시된 파일을 저장하는 디렉터리가 생성되고, 각 캐시된 파일에는 만료 시간 등과 같은 필요한 태그가 지정됩니다. 또한 브라우저마다 캐시 파일을 저장하는 방법에 미묘한 차이가 있습니다. 브라우저 캐시 콘텐츠는 브라우저 측에 저장되며, 콘텐츠는 웹 서버에서 생성됩니다. 브라우저 캐시를 활용하려면 브라우저와 웹 서버가 통신해야 합니다. . 当 Web 服务器接收到浏览器请求后,Web 服务器需要告知浏览器哪些内容可以缓存,一旦浏览器知道哪些内容可以缓存后,下次当浏览器需要请求这个内容时,浏览器便不会直接向服务器请求完整内容,二是询问服务器是否可以使用本地缓存,服务器在收到浏览的询问后回应是使用浏览器本地缓存还是将最新内容传回给浏览器。 Last-Modified Last-Modified 是一种协商方式。通过动态程序为 HTTP 相应添加最后修改时间的标记 此时,Web 服务器的响应头部会多出一条: 这代表 Web 服务器对浏览器的暗示,告诉浏览器当前请求内容的最后修改时间。收到 Web 服务器响应后,再次刷新页面,注意到发出的 HTTP 请求头部多了一段标记: 这表示浏览器询问 Web 服务器在该时间后是否有更新过请求的内容,此时,Web 服务器需要检查请求的内容在该时间后是否有过更新并反馈给浏览器,这其实就是缓存过期检查。 如果这段时间里请求的内容没有发生变化,服务器做出回应,此时,Web 服务器响应头部: 注意到此时的状态码是304,意味着 Web 服务器告诉浏览器这个内容没有更新,浏览器使用本地缓存。如下图所示: ETag HTTP/1.1 还支持ETag缓存协商方法,与最后过期时间不同的是,ETag不再采用内容的最后修改时间,而是采用一串编码来标记内容,称为ETag,如果一个内容的 ETag 没有变化,那么这个内容就一定没有更新。 ETag 由 Web 服务器生成,浏览器在获得内容的 ETag 后,会在下次请求该内容时,在 HTTP 请求头中附加上相应标记来询问服务器该内容是否发生了变化: 这时,服务器需要重新计算这个内容的 ETag,并与 HTTP 请求中的 ETag 进行对比,如果相同,便返回 304,若不同,则返回最新内容。如下图所示,服务器发现请求的 ETag 与重新计算的 ETag 不同,返回最新内容,状态码为200。 Last-Modified VS ETag 基于最后修改时间的缓存协商存在一些缺点,如有时候文件需频繁更新,但内容并没有发生变化,这种情况下,每次文件修改时间变化后,无论内容是否发生变化,都会重新获取全部内容。另外,在采用多台 Web 服务器时,用户请求可能在多台服务器间变化,而不同服务器上同一文件最后修改时间很难保证完全一样,便会导致重新获取所有内容。采用 ETag 方法就可以避免这些问题。 首先,原本使用浏览器缓存的动态内容,在使用浏览器缓存后,能否获得大的吞吐率提升,关键在于是否能避免一些额外的计算开销,同事,还取决于 HTTP 响应正文的长度,若 HTTP 响应较长,如较长的视频,则能带来大的吞吐率提到。 但使用浏览器缓存的最大价值并不在此,而在于减少带宽消耗。使用浏览器缓存后,如果 Web 服务器计算后发现可以使用浏览器端缓存,则返回的响应长度将大大减少,从而,大大减少带宽消耗。 The goal of caching in HTTP/1.1 is to eliminate the need to send requests in many cases. 在上面两图中,有个 对于主流浏览器,有三种请求页面方式: Ctrl + F5:强制刷新,使网页以及所有组件都直接向 Web 浏览器发送请求,并且不适用缓存协商,从而获取所有内容的最新版本。等价于按住 Ctrl 键后点击浏览器刷新按钮。 F5:允许浏览器在请求中附加必要的缓存协商,但不允许直接使用本地缓存,即让Last-Modified生效、Expires无效。等价于单击浏览器刷新按钮。 单击浏览器地址栏“转到”按钮或通过超链接跳转:浏览器对于所有没过期的内容直接使用本地缓存,Expires只对这种方式生效。等价于在地址栏输入 URL 后回车。 Expires指定的过期时间来源于 Web 服务器的系统时间,如果与用户本地时间不一致,就会影响到本地缓存的有效期检查。 一般情况下,操作系统都使用基于 GMT 的标准时间,然后通过时区来进行偏移计算,HTTP 中也使用 GMT 时间,所以,一般不会因为时区导致本地与服务器相差数个小时,但没人能保证本地时间与服务器一直,甚至有时服务器时间也是错误的。 针对这个问题,HTTP/1.1 添加了标记 Cache-Control,如上图1所示, HTTP 是浏览器与 Web 服务器沟通的语言,且是它们唯一的沟通方式,好好学学 HTTP 吧! 前面提到的动态内容缓存和静态化基本都是通过动态程序来实现的,下面讨论 Web 服务器自己实现缓存机制。 Web 服务器接收到 HTTP 请求后,需要解析 URL,然后将 URL 映射到实际内容或资源,这里的“映射”指服务器处理请求并生成响应内容的过程。很多时候,在一段时间内,一个 URL 对应一个唯一的响应内容,比如静态内容或更新不频繁的动态内容,如果将最终内容缓存起来,下次 Web 服务器接收到请求后可以直接将响应内容返回给浏览器,从而节省大量开销。现在,主流 Web 服务器都提供了对这种类型缓存的支持。 当使用 Web 服务器缓存时,如果直接命中,那么将省略后面的一系列操作,如 CPU 计算、数据库查询等,所以,Web 服务器缓存能带来较大性能提升,但对于普通 HTML 也,带来的性能提升较有限。 那么,缓存内容存储在什么位置呢?一般来说,本机内存和磁盘是主要选择,也可以采用分布式设计,存储到其它服务器的内存或磁盘中,这点跟前面提到的动态内容缓存类似,Apache、lighttpd 和 Nginx 都提供了支持,但配置上略有差别。 提到缓存,就不得不提有效期控制。与浏览器缓存相似,Web 服务器缓存过期检查仍然建立在 HTTP/1.1 协议上,要指定缓存有效期,仍然是在 HTTP 响应头中加入 这样一来,Web服务器就不会将这个动态内容缓存起来,当然,也有其它方法实现这个功能。 如果动态内容没有输出 Expires 标记,也可以采用 那么,是否可以使用 Web 服务器缓存取代动态程序自身的缓存机制呢?当然可以,但有些注意: 让动态程序依赖特定 Web 服务器,降低应用的可移植性。 Web 服务器缓存机制实质上是以 URL 为键的 key-value 结构缓存,所以,必须保证所有希望缓存的动态内容有唯一的 URL。 编写面向 HTTP 缓存友好的动态程序是唯一需要考虑的事。 对静态内容,特别是大量小文件站点, Web 服务器很大一部分开销花在了打开文件上,所以,可以考虑将打开后的文件描述符直接缓存到 Web 服务器的内存中,从而减少开销。但是,缓存文件描述符仅仅适用于静态内容,而且仅适用于小文件,对大文件,处理它们的开销主要在传送数据上,打开文件开销小,缓存文件描述符带来的收益小。 代理(Proxy),也称网络代理,是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(Proxy Server)。 위는 Wikipedia의 프록시 정의입니다. 이 경우 사용자는 프록시 서버 뒤에 숨겨져 있으며, 역방향 프록시 서버는 그 반대입니다. 이 메커니즘은 역방향 프록시 서버입니다. . (역방향 프록시) 마찬가지로 이 메커니즘을 구현하는 서버를 역방향 프록시 서버(역방향 프록시 서버)라고 합니다. 우리는 일반적으로 역방향 프록시 서버 뒤에 있는 웹 서버를 백엔드 서버(Back-end Server)라고 부릅니다. 이에 따라 역방향 프록시 서버를 프런트엔드 서버(Front-end Server)라고 합니다. 인터넷에 노출되어 있으면 백엔드 웹 서버가 내부 네트워크를 통해 연결되고 사용자는 역방향 프록시 서버를 통해 간접적으로 웹 서버에 액세스하게 됩니다. 이는 어느 정도 보안을 제공할 뿐만 아니라 캐시 기능도 제공합니다. 기반 가속. 역방향 프록시를 구현하는 방법에는 여러 가지가 있습니다. 예를 들어 가장 일반적인 Nginx 서버를 역방향 프록시 서버로 사용할 수 있습니다. 사용자 브라우저와 웹 서버가 제대로 작동하려면 역방향 프록시 서버를 거쳐야 합니다. 따라서 역방향 프록시 서버는 뛰어난 제어력을 갖고 이를 통과하는 데이터를 다시 쓸 수 있습니다. 어떤 방식으로든 HTTP 헤더 정보는 다른 사용자 지정 메커니즘을 통해 캐시 전략에 직접 개입할 수도 있습니다. 이전 콘텐츠에서 알 수 있듯이 HTTP 헤더 정보는 콘텐츠를 캐시할 수 있는지 여부를 결정하므로 성능 향상을 위해 역방향 프록시 서버는 자신을 통과하는 데이터의 HTTP 헤더 정보를 수정하여 어떤 콘텐츠를 캐시할 수 있는지 결정할 수 있습니다. 캐시되며 캐시될 수 없습니다. 역방향 프록시 서버는 캐시를 지우는 기능도 제공합니다. 그러나 동적 콘텐츠 캐시와 달리 동적 콘텐츠 캐시에서는 캐시가 만료되기 전에 캐시를 적극적으로 삭제할 수 있습니다. 기반 역방향 프록시 캐싱 메커니즘은 역방향 프록시 서버의 캐시 영역이 지워지지 않으면 백엔드 동적 프로그램이 캐시된 콘텐츠를 적극적으로 삭제할 수 없습니다. memcached와 같은 성숙한 분산 캐싱 시스템이 많이 있습니다. 캐싱을 달성하기 위해 우리는 캐시 내용을 디스크에 넣지 않을 것입니다. 이 원칙에 따라 memcached는 물리적 메모리를 캐시 영역으로 사용하고 데이터를 키-값 방식으로 저장합니다. 각 키와 해당 값을 함께 데이터 항목이라고 합니다. 모든 데이터 항목은 키를 고유한 인덱스로 사용합니다. 사용자는 키 기반을 통해 이 데이터 항목을 읽거나 업데이트할 수 있습니다. 해시 알고리즘을 사용하여 저장 데이터 구조를 설계하고 신중하게 설계된 메모리 할당자를 사용하여 데이터 항목 쿼리 시간 복잡도가 O(1)에 도달하도록 합니다. memcached는 LRU(Lease Recent Used) 알고리즘을 기반으로 한 제거 메커니즘을 사용하여 데이터를 제거하는 동시에 데이터 항목에 대해 만료 시간을 설정할 수도 있습니다. Memcached는 분산형 캐시 시스템으로서 독립된 서버에서 실행될 수 있으며, 동적 콘텐츠는 TCP 소켓을 통해 액세스할 수 있습니다. 이 경우 memcached 자체의 네트워크 동시성 처리 모델이 매우 중요합니다. Memcached는 libevent 함수 라이브러리를 사용하여 네트워크 동시성 모델을 구현합니다. Memcached는 동시 사용자가 많은 환경에서 사용할 수 있습니다. 캐시 시스템을 사용하여 읽기 작업을 구현하는 것은 데이터베이스의 "사전 읽기 캐시"를 사용하는 것과 동일하며 처리 속도를 크게 향상시킬 수 있습니다. 쓰기 작업의 경우 캐싱 시스템도 큰 이점을 가져올 수 있습니다. 일반적인 데이터 쓰기 작업에는 삽입, 업데이트, 삭제가 포함됩니다. 이러한 쓰기 작업에는 검색 및 인덱스 업데이트가 수반되는 경우가 많으며 이로 인해 엄청난 오버헤드가 발생하는 경우가 많습니다. 분산 캐시를 사용하면 임시로 캐시에 데이터를 저장한 후 일괄 쓰기 작업을 수행할 수 있습니다. memcached 분산형 캐시 시스템으로서 작업을 잘 완료할 수 있는 동시에 memcached는 몇 가지 중요한 정보를 포함하여 실시간 상태를 얻을 수 있는 프로토콜도 제공합니다. 공간 사용량: 캐시 공간 사용량에 주의를 기울이면 캐시 공간이 가득 차서 데이터가 수동적으로 제거되는 것을 방지하기 위해 캐시 시스템을 확장해야 하는 시기를 알 수 있습니다. 캐시 적중률 I/O 트래픽: 캐시 시스템의 작업 부하를 반영하며 이를 통해 memcached가 유휴 상태인지 사용 중인지 알 수 있습니다. 동시 처리 능력, 캐시 공간 용량 등이 한계에 도달할 수 있으며 확장은 불가피합니다. 여러 개의 캐시 서버가 있을 때 우리가 직면하는 문제는 어떻게 캐시 데이터를 여러 캐시 서버에 균등하게 배포할 수 있는가 하는 것입니다. 이 경우 나머지 방법을 사용하는 등 키 기반 분할 방법을 선택하여 여러 서버에 있는 모든 데이터 항목의 키를 균등하게 배포할 수 있습니다. 이 경우 시스템을 확장할 때 파티셔닝 알고리즘 변경으로 인해 캐시된 데이터를 한 캐시 서버에서 다른 캐시 서버로 마이그레이션해야 합니다. 실제로 마이그레이션을 전혀 고려할 필요가 없습니다. 캐시된 데이터이므로 캐시를 다시 빌드하세요. 캐시를 사용하려면 구체적인 문제에 대한 자세한 분석이 필요합니다. 예를 들어, 제가 Baidu에서 인턴이었을 때 검색 결과만을 위해 동적 콘텐츠 캐싱의 사용이 여러 계층으로 나누어졌습니다. 즉, 가능하면 캐싱을 사용하고 가능한 한 빨리 캐싱을 사용하십시오. 현재 스타트업인 Youzan은 이제 동적 콘텐츠 캐싱을 위해 redis를 사용하고 있습니다. 비즈니스 규모가 증가함에 따라 단계적으로 개선되고 있습니다. 아, 브라우저 캐싱도 있다는 사실을 잊어버릴 뻔했습니다. <br/> 페이지 열기 및 탐색 속도를 높이세요. 정적 페이지는 데이터베이스에 연결할 필요가 없으며 동적 페이지보다 훨씬 빠릅니다. 검색 엔진 최적화와 Google이 도움이 됩니다. 더 빠르게 포함될 뿐만 아니라 모두 포함되는 정적 페이지를 우선적으로 포함합니다. 서버 부담을 줄이고 웹 탐색 시 시스템 데이터베이스를 호출할 필요가 없습니다. 웹사이트가 더 안전합니다. , HTML 페이지는 PHP 관련 취약점의 영향을 받지 않습니다. 기본적으로 정적 페이지인 대규모 웹사이트를 살펴보세요. 공격을 줄이고 SQL 삽입을 방지할 수도 있습니다. 물론 장점도 있지만 단점도 있죠? 정보가 동기화되지 않았습니다. HTML 페이지를 다시 생성해야만 정보를 동기화할 수 있습니다. 서버 저장 문제. 데이터는 계속 증가하고 정적 HTML 페이지도 계속 증가하여 많은 디스크 공간을 차지합니다. 이 문제를 고려해야 합니다 정적 알고리즘의 정밀도. 데이터, 웹 페이지 템플릿 및 다양한 파일 링크 경로를 적절하게 처리하려면 정적 알고리즘의 모든 측면을 고려해야 합니다. 약간의 실수로 인해 생성된 페이지에 어떤 종류의 잘못된 링크가 생성되거나 심지어 작동하지 않는 링크가 발생할 수도 있습니다. 그러므로 우리는 이러한 문제를 적절하게 해결해야 합니다. 알고리즘의 가능성을 높일 수는 없지만 모든 측면을 고려해야 합니다. 실제로 이렇게 하는 것은 쉽지 않습니다. 참고 기사: "페이지 정적화의 몇 가지 일반적인 방법 공유" PHP 정적화에 대한 간단한 이해는 웹사이트에서 생성된 페이지를 방문자 앞에 정적 형식으로 표시하는 것입니다. HTML, PHP 정적은 순수 정적과 의사-정적으로 구분됩니다. 둘 사이의 차이점은 PHP가 정적 페이지를 생성하는 처리 메커니즘이 다르다는 것입니다. Pure static: PHP는 HTML 파일을 생성합니다. <br/>Pseudo-static: 콘텐츠를 nosql 메모리(memcached)에 저장한 다음 페이지에 액세스할 때 메모리에서 직접 읽습니다. 참고 기사: "대규모 웹사이트의 정적화 처리" 대규모 웹사이트(높은 트래픽, 높은 동시성), 정적 웹사이트라면 충분한 웹 서버를 확장할 수 있으며 그런 다음 극도로 지원합니다. 대규모 동시 액세스. 동적 웹사이트, 특히 데이터베이스를 사용하는 웹사이트의 경우 웹 서버 수를 늘려 웹사이트의 동시 접속 용량을 효과적으로 늘리기가 어렵습니다. Taobao 및 JD.com과 같은. 대규모 정적 웹사이트가 신속하고 높은 동시성으로 응답할 수 있는 이유는 동적 웹사이트를 정적으로 만들기 위해 최선을 다하기 때문입니다 . js, css, img 및 기타 리소스는 서버 측에서 병합되어 반환됩니다. CDN 콘텐츠 배포 네트워크 기술 [네트워크 전송의 효율성은 거리와 관련이 있다는 원리, 가장 가까운 정적 서버 노드 알고리즘을 통해 계산됩니다] 웹 서버 동적 및 정적 조합입니다. 머리글 및 바닥글 부분과 같은 페이지의 일부 부분은 변경되지 않습니다. 그러면 이 부분을 캐시에 넣을 수 있는지 여부입니다. 웹 서버 apache 또는 ngnix, appache에는 ESI, CSI라는 모듈이 있습니다. 동적으로, 정적으로 접속할 수 있습니다. 웹 서버에서 정적 부분을 캐시한 다음 서버에서 반환된 동적 페이지와 함께 연결합니다. 브라우저는 동적 및 정적 프런트엔드 MVC의 조합을 구현합니다. 1. 정적 페이지 장점:다른 두 가지 유형의 페이지(동적 페이지 및 의사 정적 페이지)에 비해 데이터베이스에서 데이터를 추출해야 하는데, 이는 빠르고 서버에 부담을 주지 않습니다. 단점: 데이터가 HTML로 저장되기 때문에 파일 용량이 매우 큽니다. 그리고 가장 심각한 문제는 소스코드를 변경하면 소스코드 전체를 변경해야 한다는 점인데, 한 곳도 변경할 수 없고 전체 사이트의 정적 페이지가 자동으로 변경된다는 점이다. 데이터가 많은 대규모 웹사이트라면 서버 공간을 많이 차지하게 되고, 콘텐츠가 추가될 때마다 새로운 HTML 페이지가 생성됩니다. 전문가가 아니면 유지관리가 번거롭습니다. 2. 동적 페이지 장점: 공간 사용량이 매우 작습니다. 일반적으로 수만 개의 데이터가 있는 웹 사이트는 동적 페이지를 사용하면 파일 크기가 몇 M에 불과하지만 정적 페이지는 적게는 12M, 많게는 수십M 또는 그 이상이 될 수 있습니다. 데이터베이스는 데이터베이스에서 가져오기 때문에 일부 값을 수정하고 데이터베이스를 직접 변경해야 하는 경우 모든 동적 웹 페이지가 자동으로 업데이트됩니다. 정적 페이지에 비해 이러한 이점은 명백합니다. 단점: 사용자 액세스 속도가 느린데 동적 페이지 액세스가 느린 이유는 무엇입니까? 이 문제는 동적 페이지의 액세스 메커니즘에서 시작됩니다. 실제로 우리 서버에는 사용자가 액세스하면 이 해석 엔진이 동적 페이지를 정적 페이지로 변환하여 모든 사람이 볼 수 있도록 합니다. 브라우저에서 소스 코드를 확인하세요. 그리고 이 소스코드는 해석엔진에 의해 번역된 소스코드입니다. 느린 액세스 속도와 더불어 동적 페이지의 데이터는 데이터베이스에서 호출됩니다. 방문하는 사람이 많아지면 데이터베이스에 대한 부담도 커집니다. 그러나 오늘날 대부분의 동적 프로그램은 캐싱 기술을 사용합니다. 그러나 일반적으로 동적 페이지는 서버에 더 큰 부담을 줍니다. 동시에 동적 페이지가 있는 웹사이트는 일반적으로 동시에 방문하는 사람이 많을수록 서버에 대한 부담이 더 커집니다. 3. 의사 정적 페이지 URL 재작성을 통해 index.php는 index.html이 됩니다. <br/> 의사 정적 페이지 정의 : 본질적으로 동적 페이지인 "가짜" 정적 페이지 . 장점: 정적 페이지와 비교할 때 "가짜" 정적 페이지이기 때문에 속도가 눈에 띄게 향상되지는 않지만 실제로는 동적 페이지이고 정적 페이지로 변환해야 합니다. 가장 큰 장점은 검색 엔진이 웹 페이지를 정적 페이지로 처리할 수 있다는 것입니다. 단점: 이름에서 알 수 있듯이 "의사 정적"은 "의사 정적"을 의미합니다. 이는 우리가 경험과 논리를 바탕으로 분석한 것일 뿐, 그렇지 않습니다. 반드시 정확합니다. 아마도 검색 엔진은 이를 동적 페이지로 직접 생각할 수도 있습니다. 간단한 요약: 정적 페이지는 액세스가 가장 빠르며 유지관리가 더 까다롭습니다. 동적 페이지는 공간을 거의 차지하지 않고 유지 관리가 간단하며 액세스 속도가 느리고 많은 사람이 방문하면 데이터베이스에 부담을 줍니다. SEO(검색 엔진 최적화: 검색 엔진 최적화)에 순수 정적과 의사 정적을 사용하는 것에는 본질적인 차이가 없습니다. pseudo-static을 사용하면 일정량의 CPU 사용량을 차지하며 과도하게 사용하면 CPU 과부하가 발생합니다. <br/> 이 기간 동안 CSS 스프라이트의 개념을 여러 번 접하게 되었습니다. 하나는 CSS를 사용하여 미닫이 문을 만들 때였고, 다른 하나는 YSlow를 사용하여 웹사이트 성능을 분석할 때였습니다. CSS 스프라이트 개념에 깊은 관심을 가지고 있습니다. 인터넷에서 많은 정보를 검색했지만 안타깝게도 대부분은 외국 정보를 직접 번역한 것이었고 일부는 직접 추천하는 외국 정보 사이트였습니다. 안타깝게도 영어 시험에 합격하지 못했습니다. 그리고 나는 그것을 사용하는 방법은 말할 것도 없고 어떤 CSS 스프라이트도 이해하지 못했습니다. 마지막으로 저는 Blue Ideal의 기사에서 영감을 얻었고 오랫동안 그것에 대해 생각한 끝에 마침내 내 이해를 활용하여 다른 사람들이 CSS 스프라이트를 더 빨리 마스터할 수 있도록 하겠습니다. 먼저 개념을 간략히 소개하겠습니다. 개념에 관해서는 인터넷에 널려 있는 내용이라 여기서는 간단히 언급하겠습니다. css 스프라이트란 무엇입니까 css 스프라이트는 말 그대로 CSS 스프라이트로 번역되지만 이 번역만으로는 충분하지 않습니다. 실제로 여러 이미지를 하나의 이미지로 융합한 다음 일부 CSS를 통해 웹페이지에 배치하는 것입니다. 기법. 이렇게 하면 이점도 분명합니다. 왜냐하면 사진이 많으면 http 요청이 늘어나고, 이는 의심할 여지 없이 웹 사이트의 성능을 저하시키게 되기 때문입니다. 특히 CSS 스프라이트를 사용하여 사진이 많은 웹 사이트의 경우 더욱 그렇습니다. 사진 수가 많아지면 속도가 향상됩니다. 下面我们来用一个实例来理解css sprites,受蓝色理想中的《制作一副扑克牌系列教程》启发。 我们仅仅只需要制作一个扑克牌,拿黑桃10为例子。 可以直接把蓝色理想中融合好的一幅大图作为背景,这也是css sprites的一个中心思想,就是把多个图片融进一个图里面。 这就是融合后的图,相信对PS熟悉的同学应该很容易的理解,通过PS我们就可以组合多个图为一个图。 现在我们书写html的结构: 在这里我们来分析强调几点: 一:card为这个黑桃十的盒子或者说快,对p了解的同学应该很清楚这点。 二:我用span,b,em三种标签分别代表三种不同类型的图片,span用来表标中间的图片,b用来表示数定,em用来表示数字下面的小图标。 三:class里面的声明有2种,一个用来定位黑桃10中间的图片的位置,一个用来定义方向(朝上,朝下)。 上面是p基本概念,这还不是重点,不过对p不太清楚的同学可以了解。 下面我们重点谈下定义CSS: span{display:block;width:20px;height:21px; osition:absolute;background:url(images/card.gif) no-repeat;} 这个是对span容器的CSS定义,其他属性就不说了,主要谈下如何从这个里面来理解css sprites。 背景图片,大家看地址就是最开始我们融合的一张大图,那么如何将这个大图中的指定位置显示出来呢?因为我们知道我们做的是黑桃10,这个大图其他的图像我们是不需要的,这就用到了css中的overflow:hidden; 但大家就奇怪了span的CSS定义里面没有overflow:hidden啊,别急,我们已经在定义card的CSS里面设置了(这是CSS里面的继承关系): .card{width:125px;height:170px; position:absolute;overflow:hidden;border:1px #c0c0c0 solid;} 理解到这点还不够,还要知道width:125px;height:170px; 这个可以理解成是对这个背景图片的准确切割,当然其实并不是切割,而是把多余其他的部分给隐藏了,这就是overflow:hidden的妙用。 通过以上的部分的讲解,你一定可以充分的把握css sprites的运用,通过这个所谓的“切割”,然后再通过CSS的定位技术将这些图准确的分散到这个card里面去! PS:CSS的定位技术,大家可以参考其他资料,例如相对定位和绝对定位,这里我们只能尝试用绝对定位。 最后我们来补充一点: 为什么要采取这样的结构? span这个容器是主要作用就是存放这张大的背景图片,并在里面实现”切割“,span里面切割后的背景是所有内容块里面通用的! 后面class为什么要声明2个属性? 很显然,一个是用来定位内容块的位置,一个是用来定义内容块中的图像的朝上和朝下,方位的! 下面我们附上黑桃10的完整源码: 最后感谢蓝色理想提供的参考资料! <br/> <br/> 1、前言 최근 직장에서 역방향 프록시를 사용했는데 네트워크 프록시를 사용하는 방법에는 배워야 할 것이 많이 있다는 것을 알게 되었습니다. 이전에는 프록시 소프트웨어만 사용하여 Google에 액세스하려면 프록시 소프트웨어를 사용했고 브라우저에서 프록시 주소를 구성해야 했습니다. 저는 에이전시라는 개념만 알고 있었을 뿐 정방향 에이전시와 역방향 에이전시가 있다는 사실을 몰랐기 때문에 빠르게 배우고 지식을 보충했습니다. 먼저 순방향 프록시가 무엇인지, 역방향 프록시가 무엇인지 파악한 다음 두 가지가 실제 사용에서 어떻게 시연되는지, 마지막으로 순방향 프록시가 어떤 용도로 사용되고 역방향 프록시가 무엇을 할 수 있는지 요약합니다. 2. 정방향 프록시 정방향 프록시는 외부 리소스에 대한 액세스를 프록시하는 스프링보드와 같습니다. 예: 저는 특정 웹사이트에 접속할 수 없지만 프록시 서버에 접속할 수 있습니다. 이 프록시 서버는 제가 접속할 수 없는 웹사이트에 접속할 수 있으므로 먼저 프록시 서버에 접속합니다. 그에게 접근할 수 없는 웹사이트의 콘텐츠가 필요하다고 말하면 프록시 서버가 이를 검색하여 나에게 반환합니다. 웹사이트 입장에서는 프록시 서버가 콘텐츠를 가져오면 단 하나의 기록만 남게 되는데, 때로는 그것이 사용자의 요청인지 알 수 없고, 사용자의 정보도 숨겨져 있습니다. 아니다. 클라이언트는 순방향 프록시 서버를 설정해야 합니다. 물론, 순방향 프록시 서버의 IP 주소와 프록시 프로그램의 포트를 알아야 합니다. 예를 들어 이전에 CCproxy, http://www.ccproxy.com/과 같은 이러한 유형의 소프트웨어를 사용한 적이 있다면 브라우저에서 프록시 주소를 구성해야 합니다. 요약하자면: 전향 프록시는 클라이언트와 원본 서버 사이에 위치한 서버로 원본 서버에서 콘텐츠를 얻기 위해 클라이언트가 프록시에 요청을 보내고 대상(원본 서버)을 지정합니다. ), 프록시는 요청을 원본 서버로 전달하고 획득한 콘텐츠를 클라이언트에 반환합니다. 클라이언트는 정방향 프록시를 사용하려면 몇 가지 특별한 설정을 지정해야 합니다. 순방향 프록시의 목적: (1) google 과 같이 원래 접근할 수 없었던 리소스에 액세스합니다. (2) 리소스에 대한 액세스 속도를 높이기 위해 캐싱을 수행할 수 있습니다. (3) 클라이언트 권한 부여 접속, 인증을 위한 온라인 접속 (4) 프록시는 사용자 접속 기록(온라인 행동 관리)을 기록하고 사용자 정보를 외부에서 숨길 수 있습니다 예: CCProxy 사용: 3. 방향성 프록시와의 첫 접촉 느낌 네, 클라이언트는 프록시의 존재를 알지 못하며, 역방향 프록시는 외부 세계에 투명하게 공개되어 프록시를 방문하고 있다는 사실을 알 수 없습니다. 클라이언트에 액세스하는 데 구성이 필요하지 않기 때문입니다. 역방향 프록시의 실제 작동 방법은 프록시 서버를 사용하여 인터넷에서 연결 요청을 수락한 다음 해당 요청을 내부 네트워크의 서버로 전달하고, 서버에서 얻은 결과를 인터넷으로 반환하여 연결을 요청하는 것입니다. .클라이언트, 이때 프록시 서버는 외부 세계에 서버로 나타납니다. 역방향 프록시의 역할: (1) 인트라넷의 보안을 보장하기 위해 역방향 프록시를 사용하여 WAF 기능을 제공하고 웹 공격을 방지할 수 있습니다. 대형 웹사이트에서는 일반적으로 공용 네트워크 액세스 주소로 역방향 프록시를 사용하며, 웹 서버는 인트라넷입니다. (2) 로드 밸런싱, 역방향 프록시 서버를 통해 웹사이트 로드 최적화 에서 Zhihu의 두 장의 사진을 빌려 표현됩니다. ://www.zhihu.com/question/24723688 nginx는 역방향 프록시 구성을 지원하고 역방향 프록시를 통해 웹 사이트의 부하 분산을 달성합니다. 이 부분에서는 먼저 nginx 구성을 작성한 다음 nginx의 프록시 모듈과 로드 밸런싱 모듈을 심층적으로 연구해야 합니다. nginx는 Proxy_pass_http를 통해 프록시 사이트를 구성하고, 업스트림에서는 로드 밸런싱을 구현합니다. Proxy는 이름에서 알 수 있듯이 자신을 통해서가 아닌 제3자를 통해 자신이 원하는 작업을 수행하는 것을 의미합니다. 로컬 머신과 대상 사이에 추가 중간 서버(프록시 서버)를 갖는 것으로 상상할 수 있습니다. server 정방향 프록시는 클라이언트와 원본 서버 사이에 위치한 서버(프록시 서버)입니다. 클라이언트는 먼저 몇 가지 필요한 설정을 해야 합니다(프록시 서버의 IP와 포트를 알고 있어야 함). 각 요청 보내기 프록시 서버에서는 프록시 서버가 응답을 실제 서버로 전달하고 이를 클라이언트에 반환합니다. ). 클라이언트 숨기기) 클라이언트는 특별한 설정을 할 필요가 없습니다. 일반 요청을 보내면 역방향 프록시가 해당 요청을 원래 서버로 전송하고 획득한 콘텐츠를 클라이언트에 반환합니다. 대상 서버 숨기기) Usage 정방향 프록시 Forward Proxy mysql은 마스터-슬레이브 동기화 방법을 사용하여 읽기와 쓰기를 분리하고 메인 서버에 대한 부담을 줄여줍니다. 마스터-슬레이브 동기화는 기본적으로 실시간 동기화를 달성할 수 있습니다. 다른 웹사이트에서 마스터-슬레이브 동기화 회로도를 빌렸습니다. <br/> <br/> 마스터-슬레이브 동기화가 구성된 후 마스터 서버는 업데이트 문을 binlog에 기록하고 슬레이브 서버의 IO 스레드(여기서 IO 스레드는 5.6.3 이전에는 하나만 있습니다. 5.6.3 이후에는 멀티스레딩을 사용하여 자연스럽게 속도가 빨라집니다. ) 돌아가서 메인 서버의 binlog를 읽고 의 Relay 로그에 씁니다. 그러면 슬레이브 서버의 SQL 스레드가 릴레이 로그에 있는 SQL을 하나씩 실행하여 데이터 복구를 수행합니다. <br/> 릴레이는 전송을 의미하고, 릴레이 레이스는 릴레이 레이스를 의미합니다. <br/> 1. 마스터-슬레이브 동기화가 지연되는 이유 우리는 서버가 클라이언트 연결을 위해 N개의 링크를 열어준다는 것을 알고 있습니다. 이렇게 하면 동시 업데이트 작업이 많아지지만 서버에서 binlog를 읽는 스레드는 하나뿐입니다. 슬레이브 서버에서 특정 SQL을 실행하는 데 시간이 조금 더 걸리거나 특정 SQL이 테이블을 잠가야 하는 경우, 마스터 서버에 대규모 SQL 백로그가 있고 슬레이브 서버에 동기화되지 않은 경우가 발생합니다. 이로 인해 마스터-슬레이브 불일치, 즉 마스터-슬레이브 지연이 발생합니다. <br/> 2. 마스터-슬레이브 동기화 지연에 대한 솔루션 실제로 모든 SQL은 슬레이브 서버에서 실행되어야 하지만 마스터-슬레이브 동기화 지연에 대한 원스톱 솔루션은 없습니다. 슬레이브 동기화 지연 서버에 계속해서 업데이트 작업이 기록되면 지연이 발생하면 지연이 악화될 가능성이 더 커집니다. 물론 우리는 몇 가지 완화 조치를 취할 수 있습니다. a. 마스터 서버가 업데이트 작업을 담당하기 때문에 슬레이브 서버보다 보안 요구 사항이 더 높다는 것을 알고 있습니다. sync_binlog=1, innodb_flush_log_at_trx_commit = 1 및 기타 설정은 수정할 수 있습니다. 이러한 높은 데이터 보안이 필요한 경우 sync_binlog를 0으로 설정하거나 binlog를 끌 수 있습니다. innodb_flushlog, innodb_flush_log_at_trx_commit을 0으로 설정하여 SQL 실행 효율성을 향상시킬 수도 있습니다. 이는 SQL의 실행 효율성을 크게 향상시킬 수 있습니다 . 다른 하나는 메인 라이브러리보다 좋은 하드웨어 장치를 슬레이브로 사용하는 것입니다. b. 쿼리를 제공하지 않고 슬레이브 서버를 백업으로 사용하면 부하가 줄어들면 자연스럽게 릴레이 로그의 SQL 실행 효율성이 높아집니다. c. 슬레이브 서버를 추가하는 목적은 읽기 부담을 분산하여 서버 부하를 줄이는 것입니다. <br/> 3. 마스터-슬레이브 지연을 판단하는 방법 MySQL은 슬레이브 서버 상태 명령을 제공하는데, 이는 showslave status를 통해 확인할 수 있습니다. Seconds_Behind_Master 매개변수를 사용하여 마스터-슬레이브 지연이 발생하는지 여부를 결정합니다. <br/>다음과 같은 여러 값이 있습니다. <br/>NULL - io_thread 또는 sql_thread가 실패했음을 나타냅니다. 즉, 스레드의 실행 상태가 No이고 Yes가 아님을 나타냅니다. <br/>0 - 값이 0입니다. 우리는 마스터-슬레이브 복제 상태가 정상 <br/> <br/> > 1. Redis는 더욱 풍부한 데이터 저장 유형인 String, Hash, List, Set 및 Sorted Set을 지원합니다. Memcached는 단순한 키-값 구조만 지원합니다. <br/>> 2. Memcached 키-값 저장은 키-값 저장에 해시 구조를 사용하는 Redis보다 메모리 활용도가 더 높습니다. <br/>> 3. Redis는 일련의 명령의 원자성을 보장할 수 있는 트랜잭션 기능을 제공합니다. <br/>> 4. Redis는 데이터 지속성을 지원하고 디스크의 메모리에 데이터를 보관할 수 있습니다. 5. Redis는 단일 코어만 사용합니다. Memcached는 여러 코어를 사용할 수 있으므로 작은 데이터를 저장할 때 각 코어의 Redis는 평균적으로 Memcached보다 성능이 더 높습니다. <br/><br/>- Redis는 어떻게 지속성을 달성합니까? <br/><br/>> 1. RDB 지속성, 메모리의 Redis 상태를 하드 디스크에 저장하는 것은 데이터베이스 상태를 백업하는 것과 같습니다. <br/>> 2. AOF 지속성(Append-Only-File), AOF 지속성은 Redis 서버 잠금 실행의 쓰기 상태를 저장하여 데이터베이스를 기록합니다. 백업 데이터베이스에서 수신한 명령과 동일하게 AOF에 작성된 모든 명령은 Redis 프로토콜 형식으로 저장됩니다. <br/><br/> <br/> <br/> 컴퓨터 플랫폼을 사용했습니다. 응용 프로그램 서버에 속합니다. Apache는 많은 모듈을 지원하고 안정적인 성능을 가지고 있습니다. Apache 자체는 정적 분석이므로 정적 HTML, 그림 등에 적합하지만 확장 스크립트를 통해 동적 페이지 등을 지원할 수 있습니다. , 모듈 등 ( 은 PHPcgiperl, 을 지원할 수 있지만 Java을 사용하려면 Apache에서 Tomcat이 필요합니다. 백엔드 지원, Java 요청은 처리를 위해 Apache에서 Tomcat으로 전달됩니다.)단점: 구성이 비교적 복잡하고 동적 페이지를 지원하지 않습니다. 2. Tomcat: Java) 서버이며, 단지 Servlet(JSP은 Servlet으로도 번역됨) 컨테이너입니다. Apache의 확장으로 간주되지만 Apache와 독립적으로 실행할 수 있습니다. 3. Nginxinnginx는 매우 가벼운 서버 , nginx로 발음은 "Engine X"입니다. 고성능 HTTP입니다. 서버 및 IMAP/POP3/SMTP 프록시 서버도 있습니다. 2. 비교 1. Apache와 Tomcat의 비교 동일점: l l 특징에 의해 개발됨 둘 다 HTTPservice l 둘 다 무료입니다 차이점: l Apache은 특별히 HTTP 서비스 및 관련 구성(가상 호스트, URL 전달 등)을 제공하는 데 사용됩니다. 반면 고양이 는 Apache 조직에서 JSP, Servlet 표준을 준수하는 Java EE 표준에 따라 개발한 JSP 서버 입니다. . l Apache는 Web서버 환경 프로그램이므로 Web서버,으로 사용할 수 있지만 ( ASP , PHP, CGI, JSP) 및 기타 동적 웹 페이지는 작동하지 않습니다. Apache 환경에서 JSP을 실행하려면 JSPwebpage,을 실행하는 인터프리터가 필요합니다. 이 JSP인터프리터는 톰캣 . Apache: 는 HTTPServer 에 중점을 둡니다. Tomcat: 는 Servlet 엔진에 중점을 둡니다. 단독으로 모드에서 실행되며 기능적으로는 Apache 동등하며 JSP을 지원하지만 정적 웹 페이지에는 적합하지 않습니다. Apache는 서버입니다. Tomcat은 응용 프로그램입니다 ( Java ) 서버는 Servlet(JSP 또한 Servlet으로 번역됨) 컨테이너입니다. 이는 Apache의 확장으로 간주될 수 있지만 독립적으로 실행될 수 있습니다. 아파치. 실제 사용에서는 Apache과 Tomcat 이 종종 통합되어 사용됩니다. l 클라이언트가 정적 페이지를 요청하는 경우 Ap 고통이 필요하다 서버 요청에 응답합니다. l 클라이언트가 동적 페이지를 요청하는 경우 해당 요청에 응답하는 것은 Tomcat 서버입니다. l 왜냐하면 JSP는 코드를 서버측에서 해석하므로 통합하면 의 서비스 오버헤드를 줄일 수 있습니다. Tomcat은 Apache의 확장이라고 이해할 수 있습니다. l 경량, 동일하게 시작 웹 서비스와 비교 apache메모리와 리소스를 덜 차지합니다 l 동시성 방지, nginx 요청 처리는 비동기식이며 비차단입니다. 반면 apache는 차단형입니다 , 높은 동시성에서 nginx 는 낮은 리소스 소비와 높은 성능을 유지할 수 있습니다. l 고도의 모듈식 설계, 모듈 작성이 비교적 간단합니다. l 로드 밸런싱 제공 l 커뮤니티가 활발하고 다양한 고성능 모듈이 빠르게 제작됩니다 l 아파치 rewrite 는 nginx l 보다 강력합니다. l 기본적으로 모든 애플리케이션을 포괄하는 더 많은 모듈을 지원합니다. l 은 안정적인 성능을 가지고 있는 반면, nginx는 상대적으로 bugs을 가지고 있습니다. 3) Nginx 간단한 구성, Apache 복잡함; l Nginx 정적 처리 성능 Apache 3배 더 ; 단순함, Nginx 은 다른 백엔드와 함께 사용해야 함 ; l Apache 에는 다음보다 더 많은 구성요소가 있습니다. Nginx ; l apache 은 동기 다중 프로세스 모델이며 하나의 연결은 하나의 프로세스에 해당합니다. 연결(10,000레벨) 하나의 프로세스에 대응할 수 있습니다. l nginx는 정적 파일 처리에 능숙합니다. , 는 메모리를 덜 소비합니다. l 동적 요청은 apache, 에 의해 수행됩니다. nginx 정적에만 적합 및 reverse ; 장점. 는 apache보다 빠르게 정적 요청을 처리합니다. l Apache장점: Tomcat 서버와 비교할 때 정적 파일 처리 속도가 빠릅니다. . HTML, 그림 등에 적합합니다. l Tomcat: 동적 구문 분석 컨테이너는 동적 요청을 처리하며 JSPServlet Nginx에는 동적 분리 메커니즘이 있으며 정적 요청은 를 통해 직접 전달될 수 있습니다. Nginx 처리 중인 동적 요청은 Tomcat에서 처리할 수 있도록 백그라운드로 전달됩니다. ㅋㅋㅋ 자주 다시 작성한다면, 아니면 Apache 22. Port, process1을 사용하여 포트가 사용 중인지 확인하세요 2.넷스타트를 사용하세요. 자세한 내용은 여기를 클릭하세요: http://www.findme.wang/blog/detail/id/1.html View CPU top 명령은 다음과 같습니다. Linux 일반적으로 사용되는 성능 분석 도구는 시스템 내 각 프로세스의 리소스 사용량을 실시간으로 표시할 수 있습니다. Windows 작업 관리자와 유사하게 top 명령을 사용하여 %MEM의 내용을 직접 볼 수 있습니다. 프로세스별 또는 사용자별 보기를 선택할 수 있습니다. oracle 사용자의 프로세스 메모리 사용량을 보려면 다음 명령을 사용하면 됩니다. $ top -u oracleLinux 프로세스 보기 및 프로세스 삭제 1. 在 LINUX 命令平台输入 1-2 个字符后按 Tab 键会自动补全后面的部分(前提是要有这个东西,例如在装了 tomcat 的前提下, 输入 tomcat 的 to 按 tab)。<br/>2. ps 命令用于查看当前正在运行的进程。<br/>grep 是搜索<br/>例如: ps -ef | grep java<br/>表示查看所有进程里 CMD 是 java 的进程信息<br/>ps -aux | grep java<br/>-aux 显示所有状态<br/>ps<br/>3. kill 命令用于终止进程<br/>例如: kill -9 [PID]<br/>-9 表示强迫进程立即停止<br/>通常用 ps 查看进程 PID ,用 kill 命令终止进程<br/>网上关于这两块的内容<br/> <br/> <br/> <br/> 优化手段主要有缓存、集群、异步等。 网站性能优化第一定律:优先考虑使用缓存。 1 2 <br/> <br/> <br/> 任何可以晚点做的事情都应该晚点再做。 摘自《大型网站技术架构》–李智慧 <br/> 手机网站支付主要应用于手机、掌上电脑等无线设备的网页上,通过网页跳转或浏览器自带的支付宝快捷支付实现买家付款的功能,资金即时到账。 1、您申请前必须拥有企业支付宝账号(不含个体工商户账号),且通过支付宝实名认证审核。<br/>2、如果您有已经建设完成的无线网站(非淘宝、天猫、诚信通网店),网站经营的商品或服务内容明确、完整(古玩、珠宝等奢侈品、投资类行业无法申请本产品)。<br/>3、网站必须已通过ICP备案,备案信息与签约商户信息一致。 假设我们已经成功申请到手机网站支付接口,在进行开发之前,需要使用公司账号登录支付宝开放平台。 1、开发者登录开放平台,点击右上角的“账户及密钥管理”。<br/> 2、选择“合作伙伴密钥”,即可查询到合作伙伴身份(PID),以2088开头的16位纯数字。<br/> 支付宝提供了DSA、RSA、MD5三种签名方式,本次开发中,我们使用RSA签名和加密,那就只配置RSA密钥就好了。 关于RSA加密的详解,参见《支付宝签名与验签》。 本节可以忽略,本节可以忽略,本节可以忽略!因为官方文档并没有提及应用环境配置的问题。 进入管理中心,对应用进行设置。<br/> return_url,支付完成后的回调url;notify_url,支付完成后通知的url。支付宝发送给两个url的参数是一样的,只不过一个是get,一个是post。 以上两种发起请求的方式中,return_url在Node端,notify_url在后端。我们也可以根据需要,把两个url都放在后端,或者都放在Node端,改变相应业务逻辑即可。 Node端发起支付请求有两种选择,一种是获取到后端给的参数后,通过request模块发起get请求,获取到支付宝返回的支付页面,然后显示到页面上;另一种是获取到后端给的参数后,把参数全部输出到页面中的form表单,然后通过js自动提交表单,获取到支付宝返回的支付页面(同时显示出来)。 理论上完全正确的请求,然而,获取到的支付页面,输出到页面上,却是乱码。没错,还是一个错误提示页面。<br/> 神奇的地方在于,在刷新页面多次后,正常了!!!啊嘞,这是什么鬼? 先解决乱码问题,看看报什么错! 很遗憾,无效!乱码依然是乱码。。。和沈晨帅哥讨论很久,最终决定换一种方案——利用表单提交。 开始时,打算把alidata直接输出到form表单的action中接口的后面,因为这样似乎最简便。但是,提交表单时,后面的参数全部被丢弃了。所以,不得不得把所有参数放在form表单中。Node端拆分了一下参数,组装成了一个alipayParam对象,这个工作也可以交给后端来做。 显然,request模拟表单提交和真实表单提交结果的不同,得出的结论是,request并不能完全模拟表单提交。或者,request可以模拟,而我不会-_-|||。 以上,大功告成?不!还有一个坑要填,因为微信屏蔽了支付宝!<br/>在电脑上,跳转支付宝支付页面正常,很完美!然而,在微信浏览器中测试时,却没有跳转,而是出现如下信息。<br/> 微信端支付宝支付,iframe改造<br/>http://www.cnblogs.com/jiqing9006/p/5584268.html 该办法的核心在于:把微信屏蔽的链接,赋值给iframe的src属性。 然而,在改造时,先是报错ILLEGAL_SIGN,于是利用urlencode处理了字符串。接着,又报错ILLEGAL_EXTERFACE,没有找到解决办法。 暂时放弃,以后如果有了解决办法再补上。 关于微信公众平台无法使用支付宝收付款的解决方案说明<br/>https://cshall.alipay.com/enterprise/help_detail.htm?help_id=524702 该方法的核心在于:确认支付时,提示用户打开外部系统浏览器,在系统浏览器中支付。 该页面会自动跳转到同一文件夹下的pay.htm,该文件官方已经提供,把其中的引入ap.js的路径修改一下即可。最终效果如下:<br/> 支付宝的支付流程和微信的支付流程,有很多相似之处。沈晨指出一点不同:支付宝支付完成后有return_url和notify_url;微信支付完成后只有notify_url。 研读了一下微信支付的开发文档,确实如此。微信支付完成后的通知也分成两路,一路通知到notify_url,另一路返回给调用支付接口的JS,同时发微信消息提示。也就是说,跳转return_url的工作我们需要自己做。 最后,感谢沈晨帅哥提供的思路和帮助,感谢体超帅哥辛苦改后端。 Alipay 오픈 플랫폼<br/>https://openhome.alipay.com/platform/home.htm Alipay 오픈 플랫폼-모바일 웹사이트 결제-문서 센터<br/>https://doc.open.alipay.com/doc2/ Detail?treeId=60&articleId=103564&docType=1 Alipay WAP 결제 인터페이스 개발<br/>http://blog.csdn.net/tspangle/article/details/39932963 wap h5 모바일 웹사이트 결제 인터페이스는 Alipay 지갑 결제를 연상시킵니다 가맹점 서비스 - 알리페이는 위탁을 알고 있습니다! <br/>https://b.alipay.com/order/techService.htm WeChat 결제-개발 문서<br/>https://pay.weixin.qq.com/wiki/doc/api/jsapi.php?chapter=7_1 위챗 알리페이 결제, 아이프레임 수정<br/>http://www.cnblogs.com/jiqing9006/p/5584268.html 위챗 알리페이 봉쇄를 돌파하는 방법<br/>http://blog.csdn.net/lee_sire/article /details /49530875 JavaScript 주제(2): iframe에 대한 심층적인 이해<br/>http://www.cnblogs.com/fangjins/archive/2012/08/19/2645631.html 불능에 대한 해결책에 대해 WeChat 공개 플랫폼에서 Alipay를 사용하여 수신 및 결제 솔루션 설명<br/>https://cshall.alipay.com/enterprise/help_detail.htm?help_id=524702 <br/> 오늘날 하루 수천 건의 트래픽이 발생하는 웹사이트의 경우 수만, 심지어 수억 건의 트래픽 문제를 해결하는 방법은 무엇입니까? 다음은 몇 가지 요약 방법입니다. 먼저 서버 하드웨어가 지원하기에 충분한지 확인합니다. 현재 교통 상황. 일반 P4 서버는 일반적으로 하루 최대 100,000개의 독립 IP를 지원할 수 있습니다. 방문 횟수가 이보다 많으면 먼저 문제를 해결하기 위해 고성능 전용 서버를 구성해야 합니다. 그렇지 않으면 어떻게 최적화하든 마찬가지입니다. 성능 문제를 완전히 해결하는 것은 불가능합니다. 둘째, 데이터베이스 액세스를 최적화하세요. 서버에 과도한 부하가 걸리는 중요한 이유는 CPU 부하가 너무 높기 때문입니다. 서버 CPU의 부하를 줄여야 병목 현상을 효과적으로 해결할 수 있습니다. 정적 페이지를 사용하면 CPU 부하를 최소화할 수 있습니다. 물론 데이터베이스에 전혀 접근할 필요가 없기 때문에 프론트 데스크의 완전한 정적화를 달성하는 것이 가장 좋습니다. 그러나 자주 업데이트되는 웹사이트의 경우 정적화는 특정 기능을 충족시키지 못하는 경우가 많습니다. 캐싱 기술은 동적 데이터를 캐시 파일에 저장하는 또 다른 솔루션입니다. 동적 웹 페이지는 데이터베이스에 액세스하지 않고도 이러한 파일을 직접 호출합니다. WordPress와 Z-Blog는 모두 이 캐싱 기술을 광범위하게 사용합니다. 나는 또한 이 원칙에 기초한 Z-Blog 카운터 플러그인을 작성했습니다. 실제로 데이터베이스에 액세스하는 것이 불가피한 경우 데이터베이스의 쿼리 SQL을 최적화해 볼 수 있습니다. Select *from과 같은 문을 사용하지 마세요. 각 쿼리는 필요한 결과만 반환하므로 짧은 시간에 많은 수의 SQL 쿼리가 발생하지 않습니다. 기간. 셋째, 외부 핫링크를 금지합니다. 외부 웹사이트의 사진이나 파일을 핫링크하면 부하가 많이 걸리는 경우가 많기 때문에 자신의 사진이나 파일에 대한 외부 핫링크는 엄격하게 제한해야 합니다. 다행히 핫링크는 참조를 통해 간단히 제어할 수 있으며, Apache 자체에서 핫링크를 금지하도록 구성할 수 있습니다. , IIS에는 동일한 기능을 수행할 수 있는 일부 타사 ISAPI도 있습니다. 물론 가짜 추천을 사용하여 코드를 통해 핫링크를 달성할 수도 있지만 현재는 의도적으로 가짜 추천과 핫링크를 사용하는 사람이 많지 않습니다. 지금은 이를 무시하거나 워터마크 추가와 같은 비기술적인 수단을 사용하여 해결할 수 있습니다. 사진에. 넷째, 대용량 파일의 다운로드를 제어합니다. 큰 파일을 다운로드하면 트래픽이 많이 소모되고, SCSI가 아닌 하드 드라이브의 경우 많은 수의 파일을 다운로드하면 CPU가 소모되고 웹 사이트의 응답성이 저하됩니다. 따라서 2M를 초과하는 대용량 파일의 다운로드는 제공하지 않도록 하세요. 제공이 필요한 경우에는 대용량 파일을 다른 서버에 보관하는 것이 좋습니다. 현재 이미지 공유 및 파일 공유 기능을 제공하는 무료 Web2.0 웹사이트가 많이 있으므로 이러한 공유 웹사이트에 이미지와 파일을 업로드해 볼 수 있습니다. 다섯째, 다른 호스트를 사용하여 주요 트래픽을 전환하세요. 파일을 다른 호스트에 배치하고 사용자가 다운로드할 수 있는 다른 이미지를 제공하세요. 예를 들어 RSS 파일이 많은 트래픽을 차지한다고 생각되면 FeedBurner 또는 FeedSky와 같은 서비스를 사용하여 RSS 출력을 다른 호스트에 배치하면 다른 사람의 액세스에 대한 대부분의 트래픽 압력이 집중됩니다. FeedBurner의 호스트와 RSS는 너무 많은 리소스를 차지하지 않습니다. 여섯째, 트래픽 분석 및 통계 소프트웨어를 사용해 보세요. 웹사이트에 트래픽 분석 및 통계 소프트웨어를 설치하면 어디에서 트래픽이 많이 소비되는지, 어떤 페이지를 최적화해야 하는지 즉시 알 수 있으므로 트래픽 문제를 해결하려면 정확한 통계 분석이 필요합니다. 제가 추천하는 트래픽 분석 및 통계 소프트웨어는 Google Analytics입니다. 나중에 Google Analytics를 사용하는 상식과 기술을 자세히 소개하겠습니다. 1. 테이블 분할 2. 읽기와 쓰기 분리 3. 프런트엔드 최적화. Nginx는 Apache(프론트엔드 로드 밸런싱)를 대체합니다. 개인적으로 가장 중요한 것은 분산 아키텍처가 있는지 여부입니다. mysql과 캐시의 최적화는 제한적입니다. 그러나 분산 아키텍처가 구축된 후에는 PV가 성장합니다. , 힙 머신만 확장할 수 있습니다. 몇 가지 최적화 경험을 첨부합니다. 먼저 explain 문을 사용하여 select 문을 분석하고 인덱스 및 테이블 구조를 최적화하는 방법을 배웁니다. 둘째, memcache와 같은 캐시를 합리적으로 사용하여 mysql의 부하를 줄여보세요. -php는 프로그램 효율성을 높이기 위해 컴파일되었습니다. <br/> NoSQL과 관계형 데이터베이스 설계 개념 비교 <br/> 관계형 데이터베이스의 테이블은 Store some입니다. 형식화된 데이터 구조 각 튜플 필드는 동일한 구성을 갖습니다. 모든 튜플에 모든 필드가 필요한 것은 아니지만 데이터베이스는 모든 필드를 각 튜플에 할당합니다. 이 구조는 테이블 간에 수행되는 연결 및 기타 작업을 용이하게 합니다. , 관계형 데이터베이스의 성능 병목 현상을 일으키는 요인이기도 합니다. 비관계형 데이터베이스는 키-값 쌍을 저장하며 그 구조는 고정되어 있지 않습니다. 각 튜플은 필요에 따라 자체 키-값 쌍 중 일부를 추가할 수 있으므로 고정된 구조로 제한되지 않습니다. 구조는 시간과 공간의 오버헤드를 일부 줄일 수 있습니다. <br/><br/>특징: <br/>매우 많은 양의 데이터를 처리할 수 있습니다. <br/>저렴한 PC 서버 클러스터에서 실행됩니다. <br/>성능 병목 현상을 해결합니다. <br/>과도한 작업은 금지됩니다. <br/>부트스트랩 지원 <br/><br/>단점: <br/>그러나 일부 사람들은 공식적인 공식적인 지원 없이는 문제가 발생하면 끔찍할 수 있다는 점을 인정합니다. 적어도 많은 관리자가 이를 보고 있습니다. <br/>또한 nosql은 일정한 표준이 정해져 있지 않고, 다양한 제품이 속속 등장하고 있고, 내부 혼란, 다양한 프로젝트는 아직 테스트에 시간이 필요하다 MySQL 또는 NoSQL 선택 방법 오픈 소스 시대의 데이터베이스 요약: 관계형 데이터베이스인 MySQL은 수많은 지지자들을 보유하고 있습니다. 비관계형 데이터베이스인 NoSQL은 혁신적인 데이터베이스로 평가됩니다. 둘은 서로 싸울 운명인 것처럼 보이지만 둘 다 오픈소스 계열에 속하지만 서로 손을 잡고 조화롭게 살며 협력하여 개발자에게 더 나은 서비스를 제공할 수 있습니다. 선택 방법: 항상 올바른 고전적인 대답은 여전히 특정 문제에 대한 구체적인 분석입니다. <br/> MySQL은 크기가 작고, 빠르며, 비용이 저렴하고, 구조가 안정적이며, 쿼리하기 쉽습니다. 하지만 유연성이 부족합니다. NoSQL은 고성능, 고확장성, 고가용성을 갖추고 있지만, 고정된 구조에 국한되지 않고 시간과 공간의 오버헤드를 줄여주지만, 데이터 일관성을 보장하기는 어렵습니다. 둘 다 많은 수의 사용자와 지지자를 보유하고 있으며 둘의 조합을 찾는 것은 의심할 여지 없이 좋은 솔루션입니다. 저자 John Engates는 Rackspace 호스팅 부서의 CTO이자 개방형 클라우드 지지자로서 우리에게 자세한 분석을 제공합니다. http://www.csdn.net/article/2014-03-05/2818637-open-source-data-grows-choosing-mysql-nosql 하나를 선택하시겠습니까? 아니면 둘 다 원하시나요? 물론 애플리케이션을 관계형 데이터베이스 또는 NoSQL(아마도 둘 다)에 맞춰야 하는지 여부는 생성되거나 검색되는 데이터의 특성에 따라 다릅니다. 기술 분야의 대부분의 경우와 마찬가지로 결정을 내릴 때 장단점이 있습니다. 24시간 데이터 일관성보다 규모와 성능이 더 중요하다면 NoSQL이 이상적인 선택입니다. NoSQL은 BASE 모델(기본적으로 사용 가능, 소프트 상태, 최종 일관성)에 의존합니다. 그러나 특히 기밀 정보 및 금융 정보에 대해 "항상 일관성"을 보장하려면 아마도 MySQL이 최선의 선택일 것입니다(MySQL은 ACID 모델(원자성, 일관성, 독립성 및 내구성)에 의존합니다). 오픈 소스 데이터베이스로서 관계형 데이터베이스와 비관계형 데이터베이스 모두 지속적으로 발전하고 있으며 ACID 및 BASE 모델을 기반으로 하는 새로운 애플리케이션이 많이 나올 것으로 예상됩니다. 2009년에 "관계형 데이터베이스는 죽었다"라는 상대적으로 급진적인 기사가 등장했지만, 우리 모두는 관계형 데이터베이스가 실제로 여전히 건재하며 여전히 관계형 데이터베이스를 사용해야 한다는 것을 마음속으로 알고 있습니다. 그러나 이는 또한 WEB2.0 데이터를 처리할 때 관계형 데이터베이스에 실제로 병목 현상이 나타났다는 사실을 보여줍니다. 그렇다면 NoSQL을 사용해야 할까요, 아니면 관계형 데이터베이스를 사용해야 할까요? 저는 우리가 절대적인 대답을 할 필요는 없다고 생각합니다. 우리는 애플리케이션 시나리오에 따라 무엇을 사용할지 결정해야 합니다. 관계형 데이터베이스가 귀하의 애플리케이션 시나리오에서 매우 잘 작동할 수 있고 귀하가 관계형 데이터베이스를 사용하고 유지 관리하는 데 매우 능숙하다면, 엉망으로 만드는 것을 좋아하는 사람이 아니라면 NoSQL로 마이그레이션할 필요가 없다고 생각합니다. 주위에. 금융, 통신 등 데이터가 중요한 주요 분야에 종사하는 경우 현재 Oracle 데이터베이스를 사용하여 높은 안정성을 제공하고 있으며, 특별히 큰 병목 현상이 발생하지 않는 한 서두르지 말고 NoSQL을 사용해 보세요. 그러나 Web2.0 웹사이트에서는 대부분의 관계 데이터베이스에 병목 현상이 발생합니다. 개발자는 데이터베이스 샤딩, 마스터-슬레이브 복제, 이기종 복제 등 디스크 IO 및 데이터베이스 확장성을 최적화하기 위해 많은 노력을 기울입니다. 그러나 이러한 작업에는 더 높은 기술 역량이 필요하고 더 어려워집니다. 이러한 상황을 겪고 있다면 NoSQL을 시도해 보아야 한다고 생각합니다. <br/> 비정형 데이터베이스는 필드 길이가 가변적인 데이터베이스를 말하며, 각 필드의 레코드는 반복 가능하거나 반복 불가능한 하위 필드로 구성될 수 있습니다. 이는 구조화된 데이터(예: 숫자, 기호 및 기타 정보)를 처리할 수 있을 뿐만 아니라 구조화되지 않은 데이터(전체 텍스트, 이미지, 사운드, 영화, 하이퍼미디어 및 기타 정보) 처리에 더 적합합니다. 비정형 WEB 데이터베이스는 주로 비정형 데이터를 대상으로 생성되며, 과거 대중적인 관계형 데이터베이스와 비교하여 변경이 쉽지 않은 관계형 데이터베이스 구조 정의의 한계와 고정된 길이의 한계를 극복한 것이 가장 큰 차이점입니다. 반복 필드, 하위 필드 및 가변 길이 필드를 지원하며 연속 정보(전체 텍스트 정보 포함) 및 비정형 처리에서 가변 길이 데이터 및 반복 필드 처리와 데이터 항목의 가변 길이 저장 관리를 실현합니다. 정보(다양한 멀티미디어 정보 포함) 전통적인 관계형 데이터베이스가 따라올 수 없는 장점을 가지고 있습니다. 비정형 데이터(Office 문서, 텍스트, 그림 등 모든 형식 포함) XML, HTML, 각종 보고서, 이미지 및 오디오/비디오 정보 등 소위 반구조화된 데이터는 완전히 구조화된 데이터(예: 관계형 데이터베이스 및 객체 지향 데이터베이스의 데이터)와 완전히 구조화되지 않은 데이터 사이에 있습니다. 데이터(사운드, 이미지 파일 등) 간의 데이터, HTML 문서는 반구조화된 데이터입니다. 일반적으로 자기 설명적이며, 데이터의 구조와 내용이 뚜렷한 구별 없이 혼합되어 있습니다. 데이터 모델: 반구조화된 데이터: 트리, 그래프 비구조화된 데이터: 없음 <br/><br/> RMDBS의 데이터 모델에는 네트워크 데이터 모델, 계층적 데이터 등이 포함됩니다. 모델, 관계형 기타: 구조화된 데이터: 구조 먼저, 그 다음 데이터 <br/> 반구조적 데이터: 데이터 먼저, 그 다음 구조 네트워크 기술의 발전, 특히 인터넷 및 인트라넷 기술의 급속한 발전으로 비정형 데이터의 양이 날로 증가하고 있습니다. 낮. 이때 주로 정형 데이터를 관리하는 데 사용되는 관계형 데이터베이스의 한계가 점점 더 분명해졌습니다. 이에 따라 데이터베이스 기술은 '포스트 관계형 데이터베이스 시대'에 진입하였고, 네트워크 응용을 기반으로 한 비정형 데이터베이스 시대로 발전하게 되었다. 우리나라의 비정형 데이터베이스는 Beijing Guoxin Base(iBase) Software Co., Ltd.의 IBase 데이터베이스로 대표됩니다. IBase 데이터베이스는 최종 사용자를 위한 비정형 데이터베이스로, 비정형 정보, 전문 정보, 멀티미디어 정보, 대용량 정보 처리 분야는 물론 인터넷/인트라넷 응용 분야에서도 국제적으로 앞선 수준입니다. 비정형 데이터 관리 및 관리 수준 전체 텍스트 검색의 획기적인 발전입니다. 주로 다음과 같은 장점이 있습니다. (1) 인터넷 애플리케이션에는 복잡한 데이터 유형이 많습니다. iBase는 외부 파일 데이터 유형을 통해 다양한 문서 정보 및 멀티미디어 정보를 관리할 수 있으며, 다양한 문서 정보도 관리할 수 있습니다. HTML, DOC, RTF, TXT 등과 같은 검색 중요성이 있는 멀티미디어 정보도 강력한 전체 텍스트 검색 기능을 제공합니다. (2) 하위 필드, 다중 값 필드 및 가변 길이 필드의 메커니즘을 사용하여 다양한 유형의 비구조적 또는 임의 형식 필드를 생성할 수 있으므로 관계형 데이터베이스의 매우 엄격한 테이블 구조를 깨고 구조화되지 않은 필드를 만들 수 있습니다. 데이터를 저장하고 관리할 수 있습니다. (3)iBase는 비정형 데이터와 정형 데이터를 모두 리소스로 정의하므로 비정형 데이터베이스의 기본 요소는 리소스 자체이며 데이터베이스의 리소스에는 정형 정보와 비정형 정보가 모두 포함될 수 있습니다. 따라서 비정형 데이터베이스는 다양한 비정형 데이터를 저장하고 관리할 수 있어 데이터베이스 시스템 데이터 관리에서 콘텐츠 관리로의 전환을 실현합니다. (4) iBase는 기업 비즈니스 데이터와 비즈니스 로직을 긴밀하게 통합하기 위해 객체지향 초석을 채택했으며, 특히 복잡한 데이터 객체와 멀티미디어 객체를 표현하는 데 적합합니다. (5)iBase는 인터넷의 발전 요구에 부응하기 위해 제작된 데이터베이스입니다. 이는 웹이 광역 네트워크의 대규모 데이터베이스라는 생각을 바탕으로 온라인 자원 관리 시스템인 iBase Web을 제공합니다. 네트워크 서버(WebServer)와 데이터베이스 서버(Database Server)를 직접 통합하여 데이터베이스 시스템과 데이터베이스 기술을 웹의 중요하고 필수적인 부분으로 만들어 데이터베이스만의 역할을 하는 한계를 뛰어넘었습니다. 웹 시스템의 백엔드 역할로서 데이터베이스와 웹의 유기적이고 빈틈없는 결합을 구현하여 인터넷/인트라넷 정보관리는 물론 전자상거래 애플리케이션까지의 기반을 마련하게 되었습니다. (6)iBase는 다양한 대형, 중형 및 소형 데이터베이스와 완벽하게 호환되며 Oracle, Sybase, SQLServer, DB2, Informix 등과 같은 기존 관계형 데이터베이스에 대한 가져오기 및 링크 지원을 제공합니다. 위의 분석을 통해 우리는 네트워크 기술과 네트워크 응용 기술의 급속한 발전으로 인해 계층적 데이터베이스, 네트워크 데이터베이스, 관계형 데이터베이스에 이어 전적으로 인터넷 응용 프로그램에 기반한 비정형 데이터베이스가 또 다른 주목을 받을 것이라고 예측할 수 있습니다. 정보 시스템을 설계할 때 반드시 데이터의 저장이 수반되기 마련입니다. 일반적으로 우리는 지정된 관계형 데이터베이스에 시스템 정보를 저장하게 됩니다. 데이터를 업종별로 분류하고, 해당 테이블을 디자인한 후, 해당 테이블에 해당 정보를 저장하게 됩니다. 예를 들어, 비즈니스 시스템을 구축하고 기본 직원 정보(직업 번호, 이름, 성별, 생년월일 등)를 저장해야 하는 경우 해당 직원 테이블을 생성합니다. 그러나 시스템의 모든 정보가 테이블의 필드 사용과 쉽게 일치할 수 있는 것은 아닙니다. 위의 예와 같습니다. 이러한 유형의 데이터는 해당 테이블을 생성하는 것만으로도 가장 잘 처리됩니다. 사진, 소리, 동영상 등 우리는 일반적으로 이러한 종류의 정보 내용을 직접 알 수 없으며 데이터베이스는 이를 BLOB 필드에만 저장할 수 있으므로 향후 검색에 매우 번거롭습니다. 일반적인 접근 방식은 세 개의 필드(번호, 콘텐츠 설명 varchar(1024), 콘텐츠 blob)를 포함하는 테이블을 만드는 것입니다. 인용은 번호로 이루어지며, 검색은 내용 설명으로 이루어집니다. 비정형 데이터를 처리하는 도구는 다양하며, 시중에서 흔히 볼 수 있는 콘텐츠 관리자도 그 중 하나입니다. 이런 종류의 데이터는 위의 두 가지 범주와는 다르지만 구조가 크게 변합니다. 데이터의 내용을 파악해야 하기 때문에 단순히 데이터를 파일로 정리하여 비정형 데이터로 처리할 수는 없으며, 구조가 크게 변하기 때문에 단순히 이에 대응하는 테이블을 생성할 수는 없습니다. 이 기사에서는 반구조화된 데이터 저장에 일반적으로 사용되는 두 가지 방법을 주로 설명합니다. 先举一个半结构化的数据的例子,比如存储员工的简历。不像员工基本信息那样一致每个员工的简历大不相同。有的员工的简历很简单,比如只包括教育情况;有的员工的简历却很复杂,比如包括工作情况、婚姻情况、出入境情况、户口迁移情况、党籍情况、技术技能等等。还有可能有一些我们没有预料的信息。通常我们要完整的保存这些信息并不是很容易的,因为我们不会希望系统中的表的结构在系统的运行期间进行变更。 这种方法通常是对现有的简历中的信息进行粗略的统计整理,总结出简历中信息所有的类别同时考虑系统真正关心的信息。对每一类别建立一个子表,比如上例中我们可以建立教育情况子表、工作情况子表、党籍情况子表等等,并在主表中加入一个备注字段,将其它系统不关心的信息和已开始没有考虑到的信息保存在备注中。 优点:查询统计比较方便。 缺点:不能适应数据的扩展,不能对扩展的信息进行检索,对项目设计阶段没有考虑到的同时又是系统关心的信息的存储不能很好的处理。 XML可能是最适合存储半结构化的数据了。将不同类别的信息保存在XML的不同的节点中就可以了。 优点:能够灵活的进行扩展,信息进行扩展式只要更改对应的DTD或者XSD就可以了。 缺点:查询效率比较低,要借助XPATH来完成查询统计,随着数据库对XML的支持的提升性能问题有望能够很好的解决。 <br/> 单链表<br/><br/> 1、链接存储方法<br/> 链接方式存储的线性表简称为链表(Linked List)。<br/> 链表的具体存储表示为:<br/> ① 用一组任意的存储单元来存放线性表的结点(这组存储单元既可以是连续的,也可以是不连续的)<br/> ② 链表中结点的逻辑次序和物理次序不一定相同。为了能正确表示结点间的逻辑关系,在存储每个结点值的同时,还必须存储指示其后继结点的地址(或位置)信息(称为指针(pointer)或链(link))<br/> 注意:<br/> 链式存储是最常用的存储方式之一,它不仅可用来表示线性表,而且可用来表示各种非线性的数据结构。<br/> <br/> 2、链表的结点结构<br/> ┌──┬──┐<br/> │data│next│<br/> └──┴──┘ <br/> data域--存放结点值的数据域<br/> next域--存放结点的直接后继的地址(位置)的指针域(链域)<br/>注意:<br/> ①链表通过每个结点的链域将线性表的n个结点按其逻辑顺序链接在一起的。<br/> ②每个结点只有一个链域的链表称为单链表(Single Linked List)。<br/> 【例】线性表(bat,cat,eat,fat,hat,jat,lat,mat)的单链表示如示意图<br/><br/> 单链表的反转是常见的面试题目。本文总结了2种方法。 单链表node的数据结构定义如下: 把当前链表的下一个节点pCur插入到头结点dummy的下一个节点中,就地反转。 dummy->1->2->3->4->5的就地反转过程: pCur是需要反转的节点。 prev连接下一次需要反转的节点 反转节点pCur 纠正头结点dummy的指向 pCur指向下一次要反转的节点 伪代码 1个头结点,2个指针,4行代码 注意初始状态和结束状态,体会中间的图解过程。 新建一个头结点,遍历原链表,把每个节点用头结点插入到新建链表中。最后,新建的链表就是反转后的链表。 pCur是要插入到新链表的节点。 pNex是临时保存的pCur的next。 pNex保存下一次要插入的节点 把pCur插入到dummy中 纠正头结点dummy的指向 pCur指向下一次要插入的节点 伪代码 <br/> MySQL官方对索引的定义:索引是帮助MySQL高效获取数据的数据结构。索引是在存储引擎中实现的,所以每种存储引擎中的索引都不一样。如MYISAM和InnoDB存储引擎只支持BTree索引;MEMORY和HEAP储存引擎可以支持HASH和BTREE索引。 这里仅针对常用的InnoDB存储引擎所支持的BTree索引进行介绍: 先创建一个新表,用于演示索引类型 这是最基本的索引,没有任何限制。 索引列的值必须唯一,可以有空值 是一种特殊的唯一索引,必须指定为 PRIMARY KEY,如我们常用的AUTO_INCREMENT自增主键 也称为组合索引,就是在多个字段上联合建立一个索引 这里一个组合索引,相当于在有如下三个索引: name; name,age; name,age,phoneNum; 这里或许有这样一个疑惑:为什么age或者age,phoneNum字段上没有索引。这是由于BTree索引因要遵守最左前缀原则,这个原则在后面详细展开。 创建索引简单,但是在哪些列上创建索引则需要好好思考。可以考虑在where字句中出现列或者join字句中出现的列上建索引 联合索引(name,age,phoneNum) ,B+树是按照从左到右的顺序来建立搜索树的。如('张三',18,'18668247652')来检索数据的时候,B+树会优先匹配name来确定搜索方向,name匹配成功再依次匹配age、phoneNum,最后检索到最终的数据。也就是说这种情况下是有三级索引,当name相同,查找age,age也相同时,去比较phoneNum;但是如果拿 (18,'18668247652')来检索时,B+树没有拿到一级索引,根本就无法确定下一步的搜索方向。('张三','18668247652')这种场景也是一样,当name匹配成功后,没有age这个二级索引,只能在name相同的情况下,去遍历所有的phoneNum。 B+树的数据结构决定了在使用索引的时候必须遵守最左前缀原则,在创建联合索引的时候,尽量将经常参与查询的字段放在联合索引的最左边。 一般情况下不建议使用like操作,如果非使用不可的话,需要注意:like '%abd%'不会使用索引,而like ‘aaa%’可以使用索引。这也是前面的最左前缀原则的一个使用场景。 mysql会按照联合索引从左往右进行匹配,直到遇到范围查询,如:>,<,between,like等就停止匹配,a = 1 and b =2 and c > 3 and d = 4,如果建立(a,b,c,d)顺序的索引,d是不会使用索引的。但如果联合索引是(a,b,d,c)的话,则a b d c都可以使用到索引,只是最终c是一个范围值。 order by排序有两种排序方式:using filesort使用算法在内存中排序以及使用mysql的索引进行排序;我们在部分不情况下希望的是使用索引。 如果ID是单列索引,则order by会使用索引 ID가 단일 열 색인이고 이름이 색인이 아니거나 이름도 단일 열 색인인 경우 order by에서는 색인을 사용하지 않습니다. MySQL 쿼리는 여러 인덱스 중에서 하나의 인덱스만 선택하고 이 쿼리에서는 이름 열 인덱스가 아닌 ID 열 인덱스가 사용되기 때문입니다. 이 시나리오에서 order by도 인덱스를 사용하려면 공동 인덱스(id, name)를 생성하세요. 여기서 가장 왼쪽 접두사 원칙에 주의해야 하며 그러한 공동 인덱스(name, id)를 생성하지 마세요. ). 마지막으로 MySQL에는 정렬된 레코드의 크기에 제한이 있다는 점에 유의해야 합니다. max_length_for_sort_data의 기본값은 1024입니다. 즉, 정렬할 데이터의 양이 1024보다 크면 order by는 인덱스를 사용하지 않습니다. , 파일 정렬을 사용하세요. <br/> <br/> 현재 분산형 대규모 웹사이트에는 여러 카테고리가 있습니다. 1. NetEase, Sina 등과 같은 대형 포털 2. Xiaonei, Kaixin.com 등의 SNS 웹사이트 3. Alibaba, JD.com, Gome Online, Autohome 등의 전자상거래 웹사이트 客户需求: 建立一个全品类的电子商务网站(B2C),用户可以在线购买商品,可以在线支付,也可以货到付款; 用户购买时可以在线与客服沟通; 用户收到商品后,可以给商品打分,评价; 目前有成熟的进销存系统;需要与网站对接; 希望能够支持3~5年,业务的发展; 预计3~5年用户数达到1000万; 定期举办双11,双12,三八男人节等活动; 其他的功能参考京东或国美在线等网站。 客户就是客户,不会告诉你具体要什么,只会告诉你他想要什么,我们很多时候要引导,挖掘客户的需求。好在提供了明确的参考网站。因此,下一步要进行大量的分析,结合行业,以及参考网站,给客户提供方案。 需求管理传统的做法,会使用用例图或模块图(需求列表)进行需求的描述。这样做常常忽视掉一个很重要的需求(非功能需求),因此 本电商网站的需求矩阵如下: 以上是对电商网站需求的简单举例,目的是说明(1)需求分析的时候,要全面,大型分布式系统重点考虑非功能需求;(2)描述一个简单的电商需求场景,使大家对下一步的分析设计有个依据。 一般网站,刚开始的做法,是三台服务器,一台部署应用,一台部署数据库,一台部署NFS文件系统。这是前几年比较传统的做法,之前见到一个网站10万多会员,垂直服装设计门户,N多图片。使用了一台服务器部署了应用,数据库以及图片存储。出现了很多性能问题。如下图: 但是,目前主流的网站架构已经发生了翻天覆地的变化。 지원할 수 있기를 바랍니다. 3~5년 내 사업 발전 ; 최대 추정치: 평소의 2~3배 동시성(동시성, 트랜잭션 수) 및 저장 용량을 기준으로 시스템 용량을 계산합니다. 고객 수요: 사용자 수가 3년에 1,000명에 도달합니다. 5년까지 등록된 사용자 10,000명 초당 예상 동시 횟수: 일일 UV는 200만 회입니다(28개 원칙). 以上预估仅供参考,因为服务器配置,业务逻辑复杂度等都有影响。在此CPU,硬盘,网络等不再进行评估。 根据以上预估,有几个问题: 需要部署大量的服务器,高峰期计算,可能要部署30台Web服务器。并且这三十台服务器,只有秒杀,活动时才会用到,存在大量的浪费。 所有的应用部署在同一台服务器,应用之间耦合严重。需要进行垂直切分和水平切分。 大量应用存在冗余代码。 服务器SESSION同步耗费大量内存和网络带宽。 数据需要频繁访问数据库,数据库访问压力巨大。 大型网站一般需要做以下架构优化(优化是架构设计时,就要考虑的,一般从架构/代码级别解决,调优主要是简单参数的调整,比如JVM调优;如果调优涉及大量代码改造,就不是调优了,属于重构): 业务拆分 应用集群部署(分布式部署,集群部署和负载均衡) 多级缓存 单点登录(分布式Session) 数据库集群(读写分离,分库分表) 服务化 消息队列 其他技术 拆分后的架构图: 参考部署方案2: (1)如上图每个应用单独部署; (2)核心系统和非核心系统组合部署; 모든 애플리케이션이 동일한 서버에 배포되며 애플리케이션 간의 결합이 심각합니다. 수직 및 수평 절단이 필요합니다. 캐시는 일반적으로 저장 위치 缓存的比例,一般1:4,即可考虑使用缓存。(理论上是1:2即可)。 根据业务特性可使用以下缓存过期策略: (1)缓存自动过期; (2)缓存触发过期; 系统分割为多个子系统,独立部署后,不可避免的会遇到会话管理的问题。 再进一步可以根据分布式Session,建立完善的单点登录或账户管理系统。 流程说明: (1)用户第一次登录时,将会话信息(用户Id和用户信息),比如以用户Id为Key,写入分布式Session; (2)用户再次登录时,获取分布式Session,是否有会话信息,如果没有则调到登录页; (3)一般采用Cache中间件实现,建议使用Redis,因此它有持久化功能,方便分布式Session宕机后,可以从持久化存储中加载会话信息; (4)存入会话时,可以设置会话保持的时间,比如15分钟,超过后自动超时; 结合Cache中间件,实现的分布式Session,可以很好的模拟Session会话。 大型网站需要存储海量的数据,为达到海量数据存储, 本案例在业务拆分的基础上,结合分库分表和读写分离。如下图: (1)业务拆分后:每个子系统需要单独的库; (2)如果单独的库太大,可以根据业务特性,进行再次分库,比如商品分类库,产品库; (3)分库后,如果表中有数据量很大的,则进行分表,一般可以按照Id,时间等进行分表;(高级的用法是一致性Hash) (4)在分库,分表的基础上,进行读写分离; 相关中间件可参考Cobar(阿里,目前已不在维护),TDDL(阿里),Atlas(奇虎360),MyCat(在Cobar基础上,国内很多牛人,号称国内第一开源项目)。 分库分表后序列的问题,JOIN,事务的问题,会在分库分表主题分享中,介绍。 캐시 비율은 일반적으로 1:4이므로 캐시 사용을 고려해 볼 수 있습니다. (이론적으로는 1:2면 충분합니다.) 비즈니스 특성에 따라 다음과 같은 캐시 만료 전략을 사용할 수 있습니다. (1) 자동 캐시 만료 目前使用较多的MQ有Active MQ,Rabbit MQ,Zero MQ,MS MQ等,需要根据具体的业务场景进行选择。 除了以上介绍的业务拆分, 此处不详细介绍,大家可以问度娘/Google,有机会的话也可以分享给大家。 <br/> RESTful是"分布式超媒体应用"的架构风格<br/>1.采用URI标识资源;<br/><br/>2.使用“链接”关联相关的资源;<br/><br/>3.使用统一的接口;<br/><br/>4.使用标准的HTTP方法;<br/><br/>5.支持多种资源表示方式;<br/><br/> 6.无状态性; <br/> <br/> windows 最近要熟悉一下网站优化,包括前端优化,后端优化,涉及到的细节Opcode,Xdebuge等,都会浅浅的了解一下。 像类似于,刷刷CSDN博客的人气啦,完全是得心应手啊。 我测试了博客园,使用ab并不能刷访问量,为什么CSDN可以,因为两者统计的方式不同。 1 2 3 4 5 6 PV与来访者的数量成正比,但是PV并不直接决定页面的真实来访者数量。比如一个网站就你一个人进来,通过不断的刷新页面,也可以制造出非常高的PV。这也就是ab可以刷csdn访问的原因了。 UV是指不同的、通过互联网访问、浏览一个网页的自然人。类似于注册用户,保存session的形式 IP就不用说啦。类似于博客园,使用的统计方式就必须是IP啦 ab是Apache的自带的工具,如果是window安装的,找到Apache的bin目录,在系统全局变量中添加Path,然后就可以使用ab了 1 2 3 4 5 6 1 2 3 1 2 3 本文介绍ab测试,并没有恶意使用它。途中的博客地址,也只是测试过程中借用了一下,没有别的恶意。 原创 2015年10月19日 18:24:31 <br/> 安装ab工具 ubuntu安装ab apt-get install apache2-utils centos安装ab yum install httpd-tools ab 测试命令 ab -kc 1000-n 1000 http://localhost/ab.html(是服务器下的页面) <br/> ySQL의 로그에는 오류 로그, 바이너리 로그, 일반 쿼리 로그, 느린 쿼리 로그 등이 포함됩니다. 여기서는 일반적으로 사용되는 두 가지 기능인 일반 쿼리 로그와 느린 쿼리 로그를 주로 소개합니다. 1) 일반 쿼리 로그: 설정된 클라이언트 연결 및 실행된 명령문을 기록합니다. 2) 느린 쿼리 로그 : 실행 시간이 long_query_time 초를 초과하는 모든 쿼리 또는 인덱스를 사용하지 않는 쿼리를 기록합니다. (1) 일반 쿼리 로그 기본적으로 닫혀 있습니다). 질문: MySQL 일반 쿼리 로그를 활성화하는 방법과 일반 로그 출력 형식을 출력하도록 설정하는 방법은 무엇입니까? 일반 로그 쿼리 활성화: set globalgeneral_log=on; 일반 로그 쿼리 끄기: set globalgeneral_log=off; 테이블 모드에서 일반 로그 출력 설정: set globallog_output='TABLE'; 일반 로그 출력을 파일 모드로 설정: set globallog_output='FILE'; 참고: 위 명령은 현재 유효한 경우, MySQL이 다시 시작되고 실패하는 경우에만 적용됩니다. 영구적으로 적용하려면 my.cnf를 구성해야 합니다) my.cnf 파일 구성은 다음과 같습니다. (2) 느린 쿼리 로그 질문: 느린 쿼리 로그의 현재 상태를 확인하는 방법은 무엇입니까? (2) Slow_query_log_file (3) long_query_time (4) log_queries_not_using_indexes 값을 ON으로 설정하면 인덱스를 활용하지 않는 모든 쿼리가 기록됩니다. (참고: log_queries_not_using_indexes를 ON으로 설정하고 Slow_query_log를 OFF로 설정하면 이 설정은 현재 적용되지 않습니다. 즉, 이 설정이 적용되기 위해서는 일반적으로 성능 튜닝 중에 일시적으로 활성화되는 Slow_query_log 값이 ON으로 설정되어 있어야 합니다. 질문: MySQL 느린 쿼리의 출력 로그 형식을 파일이나 테이블, 아니면 둘 다로 설정하시겠습니까? 명령어 사용: '%log_output%'와 같은 변수 표시; log_output 값을 통해 출력 형식을 확인할 수 있으며 위 값은 TABLE입니다. 물론 출력 형식을 텍스트로 설정할 수도 있고, 텍스트와 데이터베이스 테이블을 동시에 기록할 수도 있습니다. 설정 명령은 다음과 같습니다. #느린 쿼리 로그를 테이블에 출력합니다(예: mysql.slow_log) set globallog_output='TABLE' ; #느린 쿼리 로그는 텍스트(즉, Slow_query_log_file에 지정된 파일)에만 출력됩니다. setglobal log_output='FILE'; #느린 쿼리 로그는 두 로그 모두에 출력됩니다. text and the table setglobal log_output='FILE, TABLE'; 느린 쿼리 로그 테이블의 데이터 텍스트에 대한 데이터 형식 분석 정보: myql.slow_log 테이블의 느린 쿼리 로그 기록 , 형식은 다음과 같습니다. 느린 쿼리 로그hostname.log 파일에 기록되며 형식은 다음과 같습니다. 테이블인지 파일인지, 어떤 문이 느린 쿼리를 발생시켰는지(sql_text), 느린 쿼리문의 쿼리 시간(query_time), 테이블 잠금 시간(Lock_time), 스캔된 행 수(rows_examined) 등의 정보가 구체적으로 기록됩니다. 질문: 현재 느린 쿼리 문 수를 쿼리하는 방법은 무엇입니까? MySQL에는 현재 느린 쿼리 문의 수를 구체적으로 기록하는 변수가 있습니다: 명령을 입력하세요: show global status like '%slow%'; (참고: 위의 모든 내용 명령, 매개변수가 MySQL 셸을 통해 설정된 경우 MySQL이 다시 시작되면 설정된 모든 매개변수가 유효하지 않게 됩니다. 영구적으로 적용하려면 구성 매개변수를 my.cnf 파일에 작성해야 합니다. 보충 지식 포인트: MySQL의 느린 쿼리 로그 분석 도구인 mysqldumpslow를 사용하여 로그를 분석하는 방법은 무엇입니까? perlmysqldumpslow –s c –t 10 Slow-query.log 구체적인 매개변수 설정은 다음과 같습니다. -s는 정렬 방법을 나타내며, c, t, l, r은 레코드 수, 시간을 기준으로 합니다. , 쿼리 시간은 각각 반환된 레코드 수에 따라 정렬되며, ac, at, al, ar은 해당 플래시백을 나타냅니다. -t는 top의 의미를 나타내며 다음 데이터는 반환된 이전 레코드 수를 나타냅니다. -g 뒤에는 정규 표현식이 올 수 있습니다. 일치하며 대소문자를 구분하지 않습니다. 위 매개변수의 의미는 다음과 같습니다. Count:414 문이 414번 나타납니다. Time=3.51s (1454) 최대 실행 시간은 3.51s이고 총 누적 시간은 1454s입니다. Lock =0.0s (0) 잠금을 기다리는 최대 시간은 0초이고, 잠금을 위한 누적 대기 시간은 0초입니다. Rows=2194.9 (9097604) 클라이언트에 전송되는 최대 행 수는 2194.9입니다. 클라이언트로 전송된 함수의 누적 개수는 90976404 http://blog.csdn.net/a600423444/article/details/6854289 (참고: mysqldumpslow 스크립트는 Perl 언어로 작성되었으며, 구체적인 사용법은 mysqldumpslow에 대해서는 나중에 논의하겠습니다) 질문: 실제로 학습 과정에서 설정한 느린 쿼리가 효과적인지 어떻게 알 수 있나요? 매우 간단합니다. 예를 들어 느린 쿼리 log_query_time의 값이 1로 설정된 경우 다음 명령문을 실행할 수 있습니다. selectsleep(1); 이 명령문은 다음과 같습니다. 느림 해당 명령문을 쿼리한 후 해당 로그 출력 파일이나 테이블에 해당 명령문이 존재하는지 확인할 수 있습니다. <br/> 2017년 7월 10일 13:36:47 ThinkPHP简称TP,TP借鉴了Java思想,基于PHP5,充分利用了PHP5的特性,部署简单只需要一个入口文件,一起搞定,简单高效。中文文档齐全,入门超级简单。自带模板引擎,具有独特的数据验证和自动填充功能,框架更新速度比较速度。 优点:这个框架易使用 易学 安全 对bae sae支持很好提供的工具也很强大 可以支持比较大的项目开发 易扩展 全中文文档 总的来说这款框架适合非常适合国人使用 性能 上比CI还要强一些 缺点:配置对有些人来说有些复杂(其实是因为没有认真的读过其框架源码)文档有些滞后 有些组件未有文档说明。 CodeIgniter简称CI 简单配置,上手很快,全部的配置使用PHP脚本来配置,没有使用很多太复杂的设计模式,(MVC设计模式)执行性能和代码可读性上都不错。执行效率较高,具有基本的MVC功能,快速简洁,代码量少,框架容易上手,自带了很多简单好用的library。 框架适合中小型项目,大型项目也可以,只是扩展能力差。优点:这个框架的入门槛很底 极易学 极易用 框架很小 静态化非常容易 框架易扩展 文档比较详尽 缺点:在极易用的极小下隐藏的缺点即是不安全 功能不是太全 缺少非常多的东西 比如你想使用MongoDB你就得自己实现接口… 对数据的操作亦不是太安全 比如对update和delete操作等不够安全 暂不支持sae bae等(毕竟是欧洲)对大型项目的支持不行 小型项目会非常好。 CI和TP的对比(http://www.jcodecraeer.com/a/phpjiaocheng/2012/0711/309.html) Laravel的设计思想是很先进的,非常适合应用各种开发模式TDD, DDD和BDD(http://blog.csdn.net/bennes/article/details/47973129 TDD DDD BDD解释 ),作为一个框架,它为你准备好了一切,composer是个php的未来,没有composer,PHP肯定要走向没落。laravel最大的特点和处优秀之就是集合了php比较新的特性,以及各种各样的设计模式,Ioc容器,依赖注入等。因此laravel是一个适合学习的框架,他和其他的框架思想有着极大的不同,这也要求你非常熟练php,基础扎实。 优点:http://www.codeceo.com/article/why-laravel-best-php-framework.html Yii是一个基于组件的高性能的PHP的框架,用于开发大规模Web应用。Yii采用严格的OOP编写,并有着完善的库引用以及全面的教程。从MVC,DAO/ActiveRecord,widgets,caching,等级式RBAC,Web服务,到主体化,I18N和L10N,Yii提供了今日Web 2.0应用开发所需要的几乎一切功能。而且这个框架的价格也并不太高。事实上,Yii是最有效率的PHP框架之一。 <br/> 原创 2016年11月09日 17:58:50 <br/> 在PHP中,出现同名函数或是同名类是不被允许的。为防止编程人员在项目中定义的类名或函数名出现重复冲突,在PHP5.3中引入了命名空间这一概念。 1.命名空间,即将代码划分成不同空间,不同空间的类名相互独立,互不冲突。一个php文件中可以存在多个命名空间,第一个命名空间前不能有任何代码。内容空间声明后的代码便属于这个命名空间,例如: 2.调用不同空间内类或方法需写明命名空间。例如: 3.在命名空间内引入其他文件不会属于本命名空间,而属于公共空间或是文件中本身定义的命名空间。例: 首先定义一个1.php和2.php文件: 4.下面我们来看use的使用方法:(use以后引用可简写) 相关推荐: 위 내용은 PHP 인터뷰 요약의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!Query-4 explain select * from people where id in (select id from people where zipcode = 100000 union select id from people where zipcode = 200000 );

SELECT ... FROM t1 WHERE t1.a IN (SELECT b FROM t2);
SELECT ... FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.b = t1.a);
Query-5 explain select * from people o where exists (
select id from people where zipcode = 100000 and id = o.id union select id from people where zipcode = 200000 and id = o.id);

Query-6 explain select * from people where id = (select id from people where zipcode = 100000);

table
Query-7 explain select * from (select * from (select * from people a) b ) c;

<strong><em>N</em></strong>>N就是id值,指该id值对应的那一步操作的结果。type
Query-8 explain select * from people where id=1;

Query-9 explain select * from people where zipcode = 100000;

Query-10 explain select * from people where id >2;

Query-11 explain select * from (select * from people where id = 1 )b;

Query-12 explain select * from people a,people_car b where a.id = b.people_id;

CREATE TABLE people2(
id bigint auto_increment primary key,
zipcode char(32) not null default '',
address varchar(128) not null default '',
lastname char(64) not null default '',
firstname char(64) not null default '',
birthdate char(10) not null default '' )
ENGINE = MyISAM; CREATE TABLE people_car2(
people_id bigint,
plate_number varchar(16) not null default '',
engine_number varchar(16) not null default '',
lasttime timestamp
)ENGINE = MyISAM;
Query-13 explain select * from people2 a,people_car2 b where a.id = b.people_id;

Query-14 explain select * from people2 a,people_car2 b where a.id = b.people_id and b.people_id = 1;

reate index people_id on people2(id); create index people_id on people_car2(people_id);
Query-15 explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id > 2;

Query-16 explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id = 2;

Query-17 explain select * from people2 a,people_car2 b where a.id = b.people_id;

Query-18 explain select * from people2 where id = 1;

Query-19 mysql> explain select * from people2 where id = 2 or id is null;

Query-20 explain select * from people2 where id = 2 or id is not null;

value IN (SELECT primary_key FROM single_table WHERE some_expr)
value IN (SELECT key_column FROM single_table WHERE some_expr)
Query-21 explain select * from people where id = 1 or id = 2;
 <br/>
<br/>explain select * from people where id >1;

explain select * from people where id in (1,2);

Query-22 explain select * from people order by id;

possible_keys
ref
Extra
MySQL에는 정렬 작업이나 인덱스 사용을 통해 정렬된 결과를 생성하는 두 가지 방법이 있습니다. Extra에 나타나는 파일 정렬 사용은 MySQL이 후자를 사용한다는 의미입니다. filesort 하지만 이는 파일 정렬이 가능할 때마다 메모리에서 수행된다는 의미는 아닙니다. 대부분의 경우 인덱스 정렬이 더 빠르므로 일반적으로 이때 쿼리 최적화도 고려해야 합니다.
MYSQL은 LEFT JOIN 기준과 일치하는 행을 찾으면 더 이상 검색하지 않습니다.
2. author 2.0 인증 방법

1. 응용 시나리오

2. 명사의 정의
3. OAuth
4. 작업 프로세스

五、客户端的授权模式
六、授权码模式

GET /authorize?response_type=code&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host: server.example.com
HTTP/1.1 302 Found Location: https://client.example.com/cb?code=SplxlOBeZQQYbYS6WxSbIA &state=xyz
POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=authorization_code&code=SplxlOBeZQQYbYS6WxSbIA &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA", "example_parameter":"example_value" }七、简化模式

GET /authorize?response_type=token&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host: server.example.com
HTTP/1.1 302 Found Location: http://example.com/cb#access_token=2YotnFZFEjr1zCsicMWpAA &state=xyz&token_type=example&expires_in=3600
八、密码模式

POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=password&username=johndoe&password=A3ddj3w
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA", "example_parameter":"example_value" }九、客户端模式

POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=client_credentials
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "example_parameter":"example_value" }十、更新令牌
POST /token HTTP/1.1
Host: server.example.com
Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
Content-Type: application/x-www-form-urlencoded
grant_type=refresh_token&refresh_token=tGzv3JOkF0XG5Qx2TlKWIA3. yii 配置文件
 <br/>
<br/>
 <br/> advance版本的特点是:根目录下预先分配了三个模块,分别是前台、后台、控制台模块。1.backend它主要用于管理后台,网站管理员来管理整个系统。<br/>
<br/> advance版本的特点是:根目录下预先分配了三个模块,分别是前台、后台、控制台模块。1.backend它主要用于管理后台,网站管理员来管理整个系统。<br/> <br/>assets 目录用于存放前端资源包PHP类。 这里不需要了解什么是前端资源包,只要大致知道是用于管理CSS、js等前端资源就可以了。config 用于存放本应用的配置文件,包含主配置文件 main.php 和全局参数配置文件 params.php 。models views controllers 3个目录分别用于存放数据模型类、视图文件、控制器类。这个是我们编码的核心,也是我们工作最多的目录。widgets 目录用于存放一些常用的小挂件的类文件。tests 目录用于存放测试类。web 目录从名字可以看出,这是一个对于Web服务器可以访问的目录。 除了这一目录,其他所有的目录不应对Web用户暴露出来。这是安全的需要。runtime 这个目录是要求权限为 chmod 777 ,即允许Web服务器具有完全的权限, 因为可能会涉及到写入临时文件等。 但是一个目录并未对Web用户可见。也就是说,权限给了,但是并不是Web用户可以访问到的。<br/> <br/>2.frontend
<br/>assets 目录用于存放前端资源包PHP类。 这里不需要了解什么是前端资源包,只要大致知道是用于管理CSS、js等前端资源就可以了。config 用于存放本应用的配置文件,包含主配置文件 main.php 和全局参数配置文件 params.php 。models views controllers 3个目录分别用于存放数据模型类、视图文件、控制器类。这个是我们编码的核心,也是我们工作最多的目录。widgets 目录用于存放一些常用的小挂件的类文件。tests 目录用于存放测试类。web 目录从名字可以看出,这是一个对于Web服务器可以访问的目录。 除了这一目录,其他所有的目录不应对Web用户暴露出来。这是安全的需要。runtime 这个目录是要求权限为 chmod 777 ,即允许Web服务器具有完全的权限, 因为可能会涉及到写入临时文件等。 但是一个目录并未对Web用户可见。也就是说,权限给了,但是并不是Web用户可以访问到的。<br/> <br/>2.frontend <br/>我们的目标最终用户提供的主要接口的前端应用。其实,前台和后台是一样的,只是我们逻辑上的一个划分.。<br/> 好了,现在问题来了。对于 frontend backend console 等独立的应用而言, 他们的内容放在各自的目录下面,他们的运作必然用到Yii框架等 vendor 中的程序。 他们是如何关联起来的?这个秘密,或者说整个Yii应用的目录结构的秘密, 就包含在一个传说中的称为入口文件的地方。<br/>
<br/>我们的目标最终用户提供的主要接口的前端应用。其实,前台和后台是一样的,只是我们逻辑上的一个划分.。<br/> 好了,现在问题来了。对于 frontend backend console 等独立的应用而言, 他们的内容放在各自的目录下面,他们的运作必然用到Yii框架等 vendor 中的程序。 他们是如何关联起来的?这个秘密,或者说整个Yii应用的目录结构的秘密, 就包含在一个传说中的称为入口文件的地方。<br/><?phpdefined('YII_DEBUG') or define('YII_DEBUG', true);
defined('YII_ENV') or define('YII_ENV', 'dev');
require(__DIR__ . '/../../vendor/autoload.php');
require(__DIR__ . '/../../vendor/yiisoft/yii2/Yii.php');
require(__DIR__ . '/../../common/config/bootstrap.php');
require(__DIR__ . '/../config/bootstrap.php');
$config = yii\helpers\ArrayHelper::merge(
require(__DIR__ . '/../../common/config/main.php'),
require(__DIR__ . '/../../common/config/main-local.php'),
require(__DIR__ . '/../config/main.php'),
require(__DIR__ . '/../config/main-local.php'));
$application = new yii\web\Application($config);$application->run();
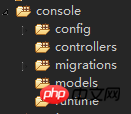 <br/><br/><br/>다음은 전역 공용 폴더 4.common
<br/><br/><br/>다음은 전역 공용 폴더 4.common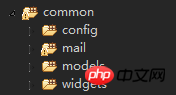 <br/>
<br/>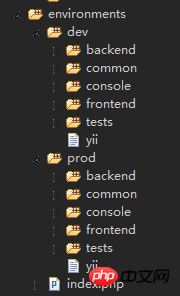 <br/> 위의 디렉터리 구조 다이어그램에서 환경 디렉터리 아래에 3가지 항목이 있음을 알 수 있습니다.
<br/> 위의 디렉터리 구조 다이어그램에서 환경 디렉터리 아래에 3가지 항목이 있음을 알 수 있습니다. 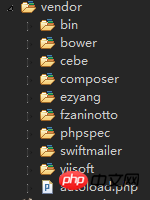 vendor 。 这个目录从字面的意思看,就是各种第三方的程序。 这是Composer安装的其他程序的存放目录,包含Yii框架本身,也放在这个目录下面。 如果你向composer.json 目录增加了新的需要安装的程序,那么下次调用Composer的时候, 就会把新安装的目录也安装在这个 vendor 下面。<br/><br/>下面也是一些不太常用的文件夹7.vagrant
vendor 。 这个目录从字面的意思看,就是各种第三方的程序。 这是Composer安装的其他程序的存放目录,包含Yii框架本身,也放在这个目录下面。 如果你向composer.json 目录增加了新的需要安装的程序,那么下次调用Composer的时候, 就会把新安装的目录也安装在这个 vendor 下面。<br/><br/>下面也是一些不太常用的文件夹7.vagrant  8.tests
8.tests  <br/>
<br/>入口文件篇:
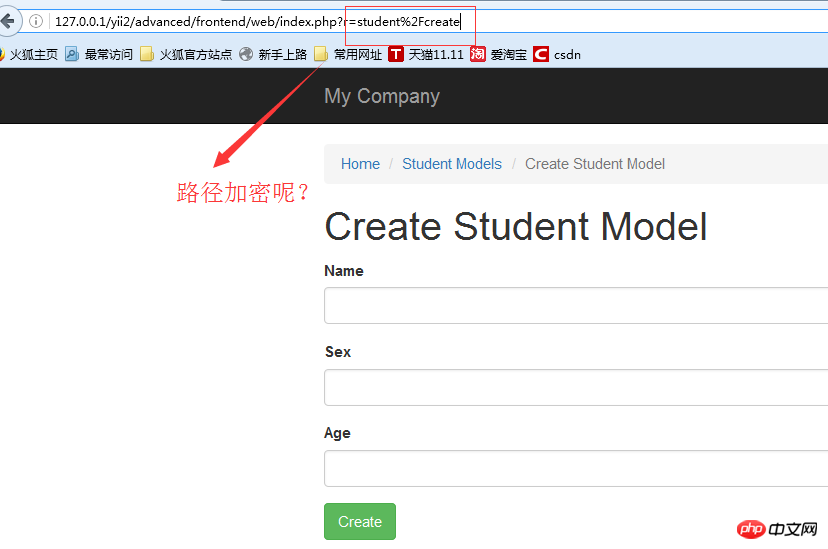 <br/>
<br/> return "$baseUrl/{$route}{$anchor}"; } else { $url = "$baseUrl?{$this->routeParam}=" . urlencode($route); if (!empty($params) && ($query = http_build_query($params)) !== '') { $url .= '&' . $query; } 将urlencode去掉就可以了 3、入口文件内容 入口文件流程如下: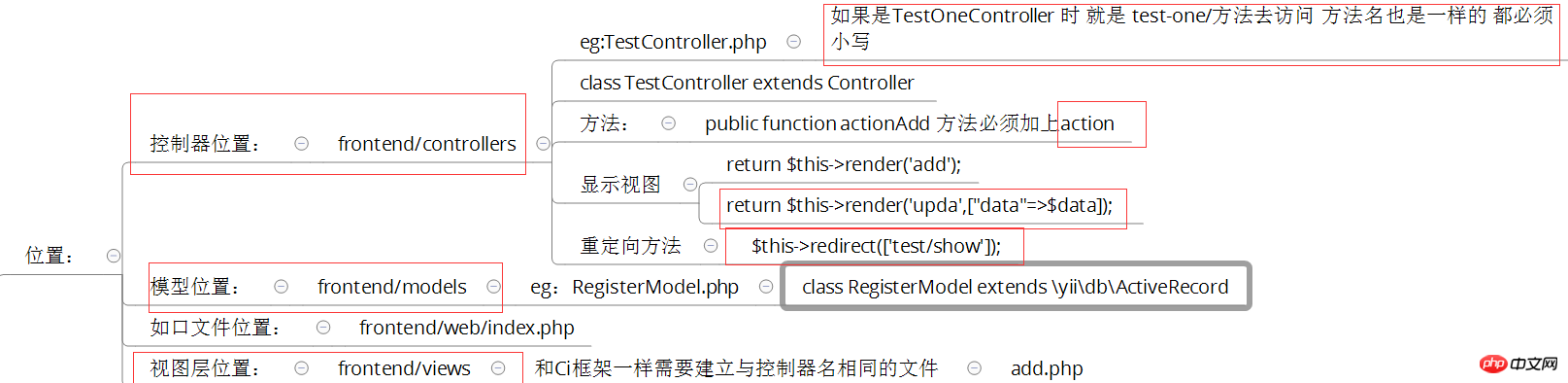 <br/>
<br/>public $defaultRoute = 'student/show';
修改前台或者后台控制器: eg :打开 frontend/config/main.php 中
'params' => $params, 'defaultRoute' => 'login/show',
namespace frontend\controllers;
use Yii;
use yii\web\Controller;
vendor/yiisoft/yii2/web/Controller.php
(该控制器继承的是\yii\base\Controller) \web\Controller.php中干了些什么
1、默认开启了 授权防止csrf攻击
2、响应Ajax请求的视图渲染
3、将参数绑定到动作(就是看是不是属于框架自己定义的方法,如果没有定义就走run方法解析)
4、检测方法(beforeAction)beforeAction() 方法会触发一个 beforeAction 事件,在事件中你可以追加事件处理操作;
5、重定向路径 以及一些http Response(响应) 的设置
<br/>
use yii\db\Query; //使用query查询
use yii\data\Pagination;//分页
use yii\data\ActiveDataProvider;//活动记录
use frontend\models\ZsDynasty;//自定义数据模型
class StudentController extends Controller {
$request = YII::$app->request;//获取请求组件
$request->get('id');//获取get方法数据
$request->post('id');//获取post方法数据
$request->isGet;//判断是不是get请求
$request->isPost;//判断是不是post请求
$request->userIp;//获取用户IP地址
$res = YII::$app->response;//获取响应组件
$res->statusCode = '404';//设置状态码
$this->redirect('http://baodu.com');//页面跳转
$res->sendFile('./b.jpg');//文件下载
$session = YII::$app->session;
$session->isActive;//判断session是否开启
$session->open();//开启session
//设置session值
$session->set('user','zhangsan');//第一个参数为键,第二个为值
$session['user']='zhangsan';
//获取session值
$session->get('user');
$session['user'];
//删除session值
$session-remove('user');
unset($session['user']);
$cookies = Yii::$app->response->cookies;//获取cookie对象
$cookie_data = array('name'=>'user','value'=>'zhangsan')//新建cookie数据
$cookies->add(new Cookie($cookie_data));
$cookies->remove('id');//删除cookie
$cookies->getValue('user');//获取cookie<?php
namespace frontend\models;
class ListtModel extends \yii\db\ActiveRecord {
public static function tableName()
{
return 'listt';
}
public function one(){
return $this->find()->asArray()->one();
}
}控制器引用
<?php namespace frontend\controllers; use Yii; use yii\web\controller; use frontend\models\ListtModel; class ListtController extends Controller{ public function actionAdd(){ $model=new ListtModel; $list=$model->one(); $data=$model->find()->asArray()->where("id=1")->all(); print_r($data); } } ?> <br/>
<br/> <br/> 而views下面会有一个默认的layouts文件夹,里面存放的就是布局文件,什么意思呢?:在控制器中,会有一个layout字段,如果制定他为一个layout视图文件,比如common.php,那么视图就会以他为主视图,其他的view视图片段都会作为显示片段嵌入到layout文件common.php中.而如果不明确重载layout字段,那么默认layout的值是main,意味着layouts的main.php是视图模板。控制器:
<br/> 而views下面会有一个默认的layouts文件夹,里面存放的就是布局文件,什么意思呢?:在控制器中,会有一个layout字段,如果制定他为一个layout视图文件,比如common.php,那么视图就会以他为主视图,其他的view视图片段都会作为显示片段嵌入到layout文件common.php中.而如果不明确重载layout字段,那么默认layout的值是main,意味着layouts的main.php是视图模板。控制器: <br/>common.php:
<br/>common.php: <br/><br/>layouts
<br/><br/>layouts 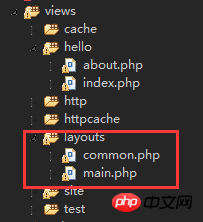 <br/>这样就达到了视图复用的作用。<br/> 控制器中写入$layout <br/>
<br/>这样就达到了视图复用的作用。<br/> 控制器中写入$layout <br/>//$layout="main" 系统默认文件
//$layout=null 会找父类中默认定义的main public $layout="common";
public function actionIndex(){
return $this->render('index');
}
将以下内容插入 common中 <?=$content;?>
它就是index文件中的内容
'db' => [
'class' => 'yii\db\Connection',
'dsn' => 'mysql:host=localhost;dbname=hyii2', //数据库hyii2
'username' => 'root',
'password' => 'pwhyii2',
'charset' => 'utf8',
],
'db2' => [
'class' => 'yii\db\Connection',
'dsn' => 'mysql:host=localhost;dbname=hyii', //数据库hyii
'username' => 'root',
'password' => 'pwhyii',
'charset' => 'utf8',
],


$id=Yii::$app->db->getLastInsertID();
Yii::$app->db->createCommand()->insert('user', [
'name' => 'test',
'age' => 30,
])->execute();Yii::$app->db->createCommand()->batchInsert('user', ['name', 'age'], [
['test01', 30],
['test02', 20],
['test03', 25],
])->execute();
删除[php] view plain copy
Yii::$app->db->createCommand()->delete('user', 'age = 30')->execute();Yii::$app->db->createCommand()->update('user', ['age' => 40], 'name = test')->execute();
查询[php] view plain copy
//createCommand(执行原生的SQL语句)
$sql= "SELECT u.account,i.* FROM sys_user as u left join user_info as i on u.id=i.user_id";
$rows=Yii::$app->db->createCommand($sql)->query();
查询返回多行:
$command = Yii::$app->db->createCommand('SELECT * FROM post');
$posts = $command->queryAll();
返回单行
$command = Yii::$app->db->createCommand('SELECT * FROM post WHERE id=1');
$post = $command->queryOne();
查询多行单值:
$command = Yii::$app->db->createCommand('SELECT title FROM post');
$titles = $command->queryColumn();
查询标量值/计算值:
$command = Yii::$app->db->createCommand('SELECT COUNT(*) FROM post');
$postCount = $command->queryScalar();
//入库一维数组
public function add($data)
{
$this->setAttributes($data);
$this->isNewRecord = true;
$this->save();
return $this->id;
}
//入库二维数组
public function addAll($data){
$ids=array();
foreach($data as $attributes)
{
$this->isNewRecord = true;
$this->setAttributes($attributes);
$this->save()&& array_push($ids,$this->id) && $this->id=0;
}
return $ids;
}
public function rules()
{
return [
[['title','content'],'required'
]];
}
控制器:
$ids=$model->addAll($data);
var_dump($ids);$user = User::find()->where(['name'=>'test'])->one();
$user->delete();
$result = User::deleteAll(['age'=>'30']);
$result = User::deleteByPk(1);
/**
* @param $files 字段
* @param $values 值
* @return int 影响行数
*/ public function del($field,$values){
//
$res = $this->find()->where(['in', "$files", $values])->deleteAll();
$res=$this->deleteAll(['in', "$field", "$values"]);
return $res;
}[php] view plain copy
$user = User::find()->where(['name'=>'test'])->one(); //获取name等于test的模型
$user->age = 40; //修改age属性值
$user->save(); //保存
[php] view plain copy
$result = User::model()->updateAll(['age'=>40],['name'=>'test']);
/** * @param $data 修改数据 * @param $where 修改条件 * @return int 影响行数 */ public function upda($data,$where){ $result = $this->updateAll($data,$where); // return $this->id; return $result; }Customer::find()->one();
此方法返回一条数据;
Customer::find()->all();
此方法返回所有数据;
Customer::find()->count();
此方法返回记录的数量;
Customer::find()->average();
此方法返回指定列的平均值;
Customer::find()->min();
此方法返回指定列的最小值 ;
Customer::find()->max();
此方法返回指定列的最大值 ;
Customer::find()->scalar();
此方法返回值的第一行第一列的查询结果;
Customer::find()->column();
此方法返回查询结果中的第一列的值;
Customer::find()->exists();
此方法返回一个值指示是否包含查询结果的数据行;
Customer::find()->batch(10);
每次取10条数据
Customer::find()->each(10);
每次取10条数据,迭代查询
//根据sql语句查询:查询name=test的客户 Customer::model()->findAllBySql("select * from customer where name = test");
//根据主键查询:查询主键值为1的数据 Customer::model()->findByPk(1);
//根据条件查询(该方法是根据条件查询一个集合,可以是多个条件,把条件放到数组里面)
Customer::model()->findAllByAttributes(['username'=>'admin']);
//子查询 $subQuery = (new Query())->select('COUNT(*)')->from('customer');
// SELECT `id`, (SELECT COUNT(*) FROM `customer`) AS `count` FROM `customer` $query = (new Query())->select(['id', 'count' => $subQuery])->from('customer');
//关联查询:查询客户表(customer)关联订单表(orders),条件是status=1,客户id为1,从查询结果的第5条开始,查询10条数据 $data = (new Query())
->select('*')
->from('customer')
->join('LEFT JOIN','orders','customer.id = orders.customer_id')
->where(['status'=>'1','customer.id'=>'1'])
->offset(5) ->limit(10) ->all()[php] view plain copy
/**
*客户表Model:CustomerModel
*订单表Model:OrdersModel
*国家表Model:CountrysModel
*首先要建立表与表之间的关系
*在CustomerModel中添加与订单的关系
*/
Class CustomerModel extends \yii\db\ActiveRecord
{
...
//客户和订单是一对多的关系所以用hasMany
//此处OrdersModel在CustomerModel顶部别忘了加对应的命名空间
//id对应的是OrdersModel的id字段,order_id对应CustomerModel的order_id字段
public function getOrders()
{
return $this->hasMany(OrdersModel::className(), ['id'=>'order_id']);
}
//客户和国家是一对一的关系所以用hasOne
public function getCountry()
{
return $this->hasOne(CountrysModel::className(), ['id'=>'Country_id']);
}
....
}
// 查询客户与他们的订单和国家
CustomerModel::find()->with('orders', 'country')->all();
// 查询客户与他们的订单和订单的发货地址(注:orders 与 address都是关联关系)
CustomerModel::find()->with('orders.address')->all();
// 查询客户与他们的国家和状态为1的订单
CustomerModel::find()->with([
'orders' => function ($query) {
$query->andWhere('status = 1');
},
'country',
])->all();yii2 rbac 详解
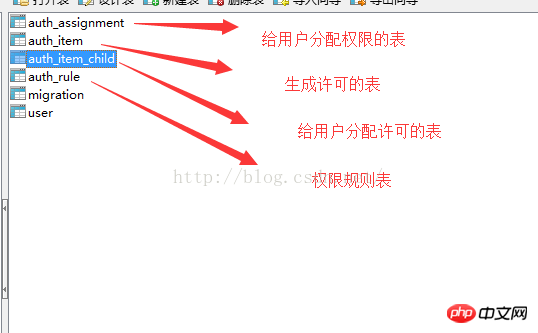 <br/><br/>4. 작업에는 yii rbac를 사용합니다(수행하는 모든 작업은 rbac의 4개 테이블에 있는 데이터를 작업합니다. 관련 권한이 설정되었는지 확인합니다. 직접 할 수 있습니다. enter 이 테이블을 확인하세요)<br/>권한 등록: (위에 설명된 권한 테이블에서 데이터가 생성됩니다) public function createPermission($item) { $auth = Yii::$app->authManager;<br/> $createPost = $auth ->createPermission($item); $createPost->description = 'Created' . $auth->add($createPost) }<br/>역할 만들기: <br/>public function createRole($item) { $auth = Yii::$app->authManager;<br/> $role = $auth->createRole($item); $role->description = 'Created' . 역할'; $auth->add($role); }<br/>역할에 권한 할당public function createEmpowerment($items) { $auth = Yii::$app->authManager;<br/> $ parent = $auth- >createRole($items['name']); $child = $auth->createPermission($items['description']);<br/> $auth->addChild($parent, $child ) }<br/> 권한에 규칙 추가: 규칙은 역할 및 권한에 추가 제약 조건을 추가하는 것입니다. 규칙은
<br/><br/>4. 작업에는 yii rbac를 사용합니다(수행하는 모든 작업은 rbac의 4개 테이블에 있는 데이터를 작업합니다. 관련 권한이 설정되었는지 확인합니다. 직접 할 수 있습니다. enter 이 테이블을 확인하세요)<br/>권한 등록: (위에 설명된 권한 테이블에서 데이터가 생성됩니다) public function createPermission($item) { $auth = Yii::$app->authManager;<br/> $createPost = $auth ->createPermission($item); $createPost->description = 'Created' . $auth->add($createPost) }<br/>역할 만들기: <br/>public function createRole($item) { $auth = Yii::$app->authManager;<br/> $role = $auth->createRole($item); $role->description = 'Created' . 역할'; $auth->add($role); }<br/>역할에 권한 할당public function createEmpowerment($items) { $auth = Yii::$app->authManager;<br/> $ parent = $auth- >createRole($items['name']); $child = $auth->createPermission($items['description']);<br/> $auth->addChild($parent, $child ) }<br/> 권한에 규칙 추가: 규칙은 역할 및 권한에 추가 제약 조건을 추가하는 것입니다. 규칙은 yiirbacRuleyiirbacRule的类,必须实现execute()클래스는 구현해야 합니다execute() 메소드. <br/>🎜계층 구조에서 앞서 생성한 author 캐릭터가 자신의 글을 편집할 수 없는 문제를 해결해 보겠습니다. <br/>먼저 이 사용자가 기사의 작성자인지 확인하는 규칙이 필요합니다. <br/>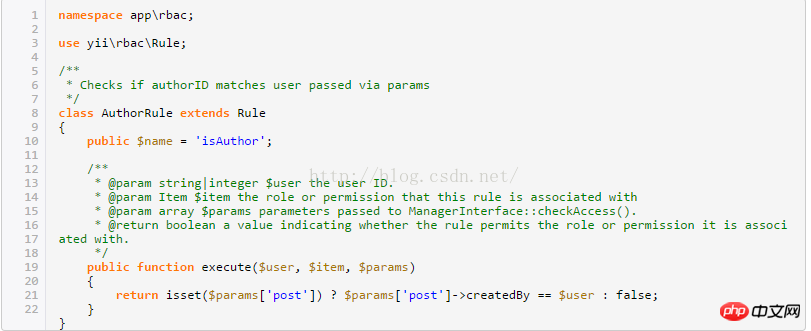 <br/><br/>참고: 위 방법의 excute에서 $user가 뒤에 옵니다. 사용자가 로그인합니다. user_id<br/>
<br/><br/>참고: 위 방법의 excute에서 $user가 뒤에 옵니다. 사용자가 로그인합니다. user_id<br/>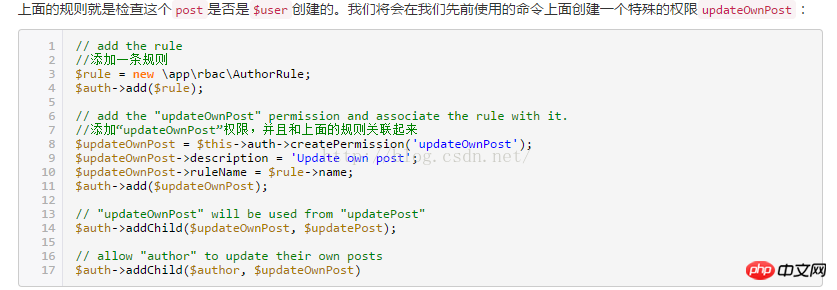 <br/>은 사용자가 로그인한 후 사용자의 권한을 결정합니다
<br/>은 사용자가 로그인한 후 사용자의 권한을 결정합니다 <br/><br/> 기사 참조 링크 : http://www.360us.net/article/13.html http://www.open-open.com/lib/view/open1424832085843.html<br/>
<br/><br/> 기사 참조 링크 : http://www.360us.net/article/13.html http://www.open-open.com/lib/view/open1424832085843.html<br/>4. 在微信里调支付宝
 <br/>
<br/>
$returnUrl = 'http://域名/user/h5_alipay/return_url.php'; //付款成功后的 同步回调地址,可直接设置为会员中心的地址 $notifyUrl = 'http://域名/notify_url.php'; //付款成功后的异回调地址,如果你的回调地址中包含&符号,最好把回调直接放根目录
$orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');

密钥管理->开放平台密钥,填写添加了电脑网站支付的应用的APPID
$notifyUrl = 'http://域名/user/h5_alipay/notify_url.php';
//付款成功后的异步回调地址支付宝以post的方式回调
$returnUrl = 'http://域名/user/pay_chongzhi.php';
//付款成功后,支付宝以 get同步的方式回调给发起支付方
$sj=date("Y-m-d H:i:s");
$userid=returnuserid($_SESSION["SHOPUSER"]);
$ddbh=$bh="h5_ali_".time()."_".$userid;
//订单编号
$uip=$_SERVER["REMOTE_ADDR"];
//ip地址 $money1=$_POST[t1];
//bz备注,ddzt与alipayzt及ifok表示订单状态,
intotable("yjcode_dingdang","bh,ddbh,userid,sj,uip,money1,ddzt,alipayzt,bz,ifok","'".$bh."','".$ddbh."',".$userid.",'".$sj."','".$uip."',".$money1.",'等待买家付款','','支付宝充值',0");
//订单入库
//die(mysql_error());
//数据库错误
//订单名称
$orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');
//注意编码
$body = $orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');
$outTradeNo = $ddbh;
//你自己的商品订单号
$payAmount = $money1;
//付款金额,单位:元
$signType = 'RSA2';
//签名算法类型,支持RSA2和RSA,推荐使用RSA2
$saPrivateKey='这里填2048位的私钥';
//私钥
$aliPay = new AlipayService($appid,$returnUrl,$notifyUrl,$saPrivateKey);
$payConfigs = $aliPay->doPay($payAmount,$outTradeNo,$orderName,$returnUrl,$notifyUrl);
class AlipayService {
protected $appId;
protected $returnUrl;
protected $notifyUrl;
protected $charset;
//私钥值
protected $rsaPrivateKey;
public function __construct($appid, $returnUrl, $notifyUrl,$saPrivateKey) {
$this->appId = $appid;
$this->returnUrl = $returnUrl;
$this->notifyUrl = $notifyUrl;
$this->charset = 'UTF-8';
$this->rsaPrivateKey=$saPrivateKey;
}
/**
* 发起订单
* @param float $totalFee 收款金额 单位元
* @param string $outTradeNo 订单号
* @param string $orderName 订单名称
* @param string $notifyUrl 支付结果通知url 不要有问号
* @param string $timestamp 订单发起时间
* @return array
*/
public function doPay($totalFee, $outTradeNo, $orderName, $returnUrl,$notifyUrl)
{
//请求参数
$requestConfigs = array( 'out_trade_no'=>$outTradeNo, 'product_code'=>'QUICK_WAP_WAY', 'total_amount'=>$totalFee,
//单位 元 'subject'=>$orderName, //订单标题 );
$commonConfigs = array(
//公共参数
'app_id' => $this->appId, 'method' => 'alipay.trade.wap.pay',
//接口名称 'format' => 'JSON',
'return_url' => $returnUrl, 'charset'=>$this->charset, 'sign_type'=>'RSA2',
'timestamp'=>date('Y-m-d H:i:s'), 'version'=>'1.0', 'notify_url' => $notifyUrl,
'biz_content'=>json_encode($requestConfigs), );
$commonConfigs["sign"] = $this->generateSign($commonConfigs, $commonConfigs['sign_type']);
return $commonConfigs;
}
public function generateSign($params, $signType = "RSA") {
return $this->sign($this->getSignContent($params), $signType);
}
protected function sign($data, $signType = "RSA") {
$priKey=$this->rsaPrivateKey;
$res = "-----BEGIN RSA PRIVATE KEY-----\n" .
wordwrap($priKey, 64, "\n", true) .
"\n-----END RSA PRIVATE KEY-----";
($res) or die('您使用的私钥格式错误,请检查RSA私钥配置');
if ("RSA2" == $signType) {
openssl_sign($data, $sign, $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
//OPENSSL_ALGO_SHA256是php5.4.8以上版本才支持
} else {
openssl_sign($data, $sign, $res);
}
$sign = base64_encode($sign);
return $sign;
}
/**
* 校验$value是否非空
* if not set ,return true;
* if is null , return true;
**/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
}
/**
* 转换字符集编码
* @param $data
* @param $targetCharset
* @return string
*/
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
}
}
return $data;
} }
function isWeixin(){
if ( strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessenger') !== false ) {
return true;
}
return false;
}
$queryStr = http_build_query($payConfigs); if(isWeixin()):
//注意下面的ap.js ,文件的存在目录,如果不确定.可以写绝对地址.否则可能微信中没法弹出提示窗口,
?>
<script>
var gotoUrl = 'https://openapi.alipaydev.com/gateway.do?<?=$queryStr?>';
//注意上面及下面的alipaydev.com,用的是沙箱接口,去掉dev表示正式上线
_AP.pay(gotoUrl); </script> <?php
header('Content-type:text/html; Charset=GB2312');
//支付宝公钥,账户中心->密钥管理->开放平台密钥,找到添加了支付功能的应用,根据你的加密类型,查看支付宝公钥
$alipayPublicKey=''; $aliPay = new AlipayService($alipayPublicKey);
//验证签名,如果签名失败,注意编码问题.特别是有中文时,可以换成英文,再测试
$result = $aliPay->rsaCheck($_POST,$_POST['sign_type']);
if($result===true){
//处理你的逻辑,例如获取订单号
$_POST['out_trade_no'],订单金额$_POST['total_amount']等
//程序执行完后必须打印输出“success”(不包含引号)。
如果商户反馈给支付宝的字符不是success这7个字符,支付宝服务器会不断重发通知,直到超过24小时22分钟。
一般情况下,25小时以内完成8次通知(通知的间隔频率一般是:4m,10m,10m,1h,2h,6h,15h);
$out_trade_no = $_POST['out_trade_no'];
//支付宝交易号
$trade_no = $_POST['trade_no'];
//交易状态
$trade_status = $_POST['trade_status'];
switch($trade_status){
case "WAIT_BUYER_PAY";
$nddzt="等待买家付款";
break;
case "TRADE_FINISHED": case "TRADE_SUCCESS"; $nddzt="交易成功";
break;
}
if(empty($trade_no)){echo "success";exit;}
//注意,这里的查询不能 强制用户登录,则否支付宝没法进入本页面.没法通知成功
$sql="select ifok,jyh from yjcode_dingdang where ifok=1 and jyh='".$trade_no."'";mysql_query("SET NAMES 'GBK'");$res=mysql_query($sql);
//支付宝生成的流水号
if($row=mysql_fetch_array($res)){echo "success";exit;
}
$sql="select * from yjcode_dingdang where ddbh='".$out_trade_no."' and ifok=0 and ddzt='等待买家付款'";
mysql_query("SET NAMES 'GBK'");
$res=mysql_query($sql);
if($row=mysql_fetch_array($res)){
if(1==$row['ifok']){
echo "success";exit;
}
if($trade_status=="TRADE_SUCCESS" || $trade_status=="TRADE_FINISHED"){
if($row['money1']== $_POST['total_fee'] ){
$sj=time();$uip=$_SERVER["REMOTE_ADDR"];
updatetable("yjcode_dingdang","sj='".$sj."',uip='".$uip."',alipayzt='".$trade_status."',ddzt='".$nddzt."',ifok=1,jyh='".$trade_no."' where id=".$row[id]);
$money1=$row["money1"];
//修改订单状态为成功付款
PointIntoM($userid,"支付宝充值".$money1."元",$money1);
//会员余额增加 echo "success";exit;
}
}
}
//——请根据您的业务逻辑来编写程序(以上代码仅作参考)——
echo 'success';exit();
}
echo 'fail';exit();
class AlipayService {
//支付宝公钥
protected $alipayPublicKey;
protected $charset;
public function __construct($alipayPublicKey) {
$this->charset = 'utf8';
$this->alipayPublicKey=$alipayPublicKey;
}
/** * 验证签名 **/
public function rsaCheck($params) {
$sign = $params['sign'];
$signType = $params['sign_type'];
unset($params['sign_type']);
unset($params['sign']);
return $this->verify($this->getSignContent($params), $sign, $signType);
}
function verify($data, $sign, $signType = 'RSA') {
$pubKey= $this->alipayPublicKey;
$res = "-----BEGIN PUBLIC KEY-----\n" .
wordwrap($pubKey, 64, "\n", true) .
"\n-----END PUBLIC KEY-----";
($res) or die('支付宝RSA公钥错误。请检查公钥文件格式是否正确');
//调用openssl内置方法验签,返回bool值
if ("RSA2" == $signType) {
$result = (bool)openssl_verify($data, base64_decode($sign), $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
} else {
$result = (bool)openssl_verify($data, base64_decode($sign), $res);
} // if(!$this->checkEmpty($this->alipayPublicKey)) { //
//释放资源 //
openssl_free_key($res);
// }
return $result;
}
/** * 校验$value是否非空 * if not set ,return true; * if is null , return true; **/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
}
/** * 转换字符集编码 * @param $data * @param $targetCharset * @return string */
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
//$data = iconv($fileType, $targetCharset.'//IGNORE', $data);
}
}
return $data;
}
}<?php
define('PHPS_PATH', dirname(__FILE__).DIRECTORY_SEPARATOR);
//$_POST['trade_no']=1; if($_POST['trade_no']){ $alipayPublicKey='MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAyg8BC9UffA4ZoMl12zz';
//RSA公钥,与支付时的私钥对应
$aliPay = new AlipayService2($alipayPublicKey);
//验证签名
$result = $aliPay->rsaCheck($_POST,$_POST['sign_type']);
//file_put_contents('333.txt',$_POST);
if($result===true){
//处理你的逻辑,例如获取订单号
$_POST['out_trade_no'],订单金额$_POST['total_amount']等
$out_trade_no = $_POST['out_trade_no'];
//$out_trade_no = '2018022300293843964';
//支付宝交易号
$trade_no = $_POST['trade_no'];
//交易状态
$trade_status = $_POST['trade_status'];
//$trade_status='';
$userinfo = array();
if($trade_status=="TRADE_SUCCESS" || $trade_status=="TRADE_FINISHED"){
//ini_set('display_errors',1);
//错误信息
//ini_set('display_startup_errors',1);
//php启动错误信息
//error_reporting(-1);
//打印出所有的 错误信息
$mysql_user=include(PHPS_PATH.'/caches/configs/database.php');
$username=$mysql_user['default']['username'];
$password=$mysql_user['default']['password'];
$tablepre=$mysql_user['default']['tablepre'];
$database=$mysql_user['default']['database'];
$con = mysqli_connect($mysql_user['default']['hostname'],$username,$password); mysqli_select_db($con,$database);
$sql = ' SELECT * FROM '.$tablepre."pay_account where trade_sn='".$out_trade_no."'";
$result2=mysqli_query($con,$sql);
$orderinfo=mysqli_fetch_array($result2);;
$uid=$orderinfo['userid'];
$sql2 = ' SELECT * FROM '.$tablepre."member where userid=".$uid;
$result1=mysqli_query($con,$sql2); $userinfo=mysqli_fetch_array($result1);;
if($orderinfo){
if($orderinfo['status']=='succ'){
//file_put_contents('31.txt',1);
echo 'success';
mysqli_close($con);
exit();
}else{
// if($orderinfo['money']== $_POST['total_amount'] ){
$money = $orderinfo['money'];
$amount = $userinfo['amount'] + $money;
$sql3 = ' update '.$tablepre."member set amount= ".$amount." where userid=".$uid;
$result3=mysqli_query($con,$sql3);
$sql4 = ' update '.$tablepre."pay_account set status= 'succ' where userid=".$uid ." and trade_sn='".$out_trade_no."'";
$result4=mysqli_query($con,$sql4);
//file_put_contents('1.txt',$result4);
echo 'success';
mysqli_close($con);
exit();
// }
}
} else {
echo 'success';exit();
}
}
echo 'success';exit();
} echo 'fail';exit();
} class AlipayService2 {
//支付宝公钥
protected $alipayPublicKey;
protected $charset;
public function __construct($alipayPublicKey) {
$this->charset = 'utf8';
$this->alipayPublicKey=$alipayPublicKey;
}
/** * 验证签名 **/
public function rsaCheck($params) {
$sign = $params['sign'];
$signType = $params['sign_type'];
unset($params['sign_type']);
unset($params['sign']);
return $this->verify($this->getSignContent($params), $sign, $signType);
}
function verify($data, $sign, $signType = 'RSA') {
$pubKey= $this->alipayPublicKey;
$res = "-----BEGIN PUBLIC KEY-----\n" .
wordwrap($pubKey, 64, "\n", true) .
"\n-----END PUBLIC KEY-----";
($res) or die('支付宝RSA公钥错误。请检查公钥文件格式是否正确');
//调用openssl内置方法验签,返回bool值
if ("RSA2" == $signType) {
$result = (bool)openssl_verify($data, base64_decode($sign), $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
} else {
$result = (bool)openssl_verify($data, base64_decode($sign), $res);
}
// if(!$this->checkEmpty($this->alipayPublicKey)) {
//
//释放资源 //
openssl_free_key($res); //
}
return $result;
}
/** * 校验$value是否非空 * if not set ,return true; * if is null , return true; **/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
} /** * 转换字符集编码 * @param $data * @param $targetCharset * @return string */
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
//$data = iconv($fileType, $targetCharset.'//IGNORE', $data);
}
}
return $data;
}
}
?>5. 抓包
常用抓包工具
6. https / http
7. like 효율성
8. 왼쪽, 오른쪽, 조인, 데카르트 곱 풀기
sql 합집합, 교차, 문 제외
9. oop封装、继承、多态
php面向对象之继承、多态、封装简介
作者:PHP中文网2018-03-02 09:49:15
interface InterAnimal{
public function speak();
public function name($name);
}//接口实现 class cat implements InterAnimal{
public function speak(){
echo "speak";
}
public function name($name){
echo "My name is ".$name;
}
}<br/>class Computer {
private $_name = '联想';
public function __get($_key) {
return $this->$_key;
}
public function run() {
echo '父类run方法';
}}class NoteBookComputer extends Computer {}$notebookcomputer = new NoteBookComputer ();
$notebookcomputer->run ();
//继承父类中的run()方法echo $notebookcomputer->_name;
//通过魔法函数__get()获得私有字段<br/>class Computer {
public $_name = '联想';
protected function run() {
echo '我是父类';
}}//重写其字段、方法class NoteBookComputer extends Computer {
public $_name = 'IBM';
public function run() {
echo '我是子类';
}}<br/>abstract class Computer {
abstract function run();
}
final class NotebookComputer extends Computer {
public function run() {
echo '抽象类的实现';
}
}<br/>interface Computer {
public function version();
public function work();
}class NotebookComputer implements Computer {
public function version() {
echo '联想<br>';
}
public function work() {
echo '笔记本正在随时携带运行!';
}}class desktopComputer implements Computer {
public function version() {
echo 'IBM';
}
public function work() {
echo '台式电脑正在工作站运行!';
}}class Person {
public function run($type) {
$type->version ();
$type->work ();
}}
$person = new Person ();
$desktopcomputer = new desktopComputer ();
$notebookcomputer = new NoteBookComputer ();
$person->run ( $notebookcomputer );<br/> PHP 객체 지향 식별 객체
PHP 객체 지향 식별 객체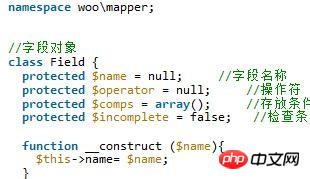 PHP 객체지향식별 객체 인스턴스 상세 설명
PHP 객체지향식별 객체 인스턴스 상세 설명 이미지 워터마크 클래스 캡슐화 코드 공유 PHP 구현
이미지 워터마크 클래스 캡슐화 코드 공유 PHP 구현 PHP 캡슐화 MySQL 연산 상세 설명 class
PHP 캡슐화 MySQL 연산 상세 설명 class 10. mvc
11. 유료 CDN 전송과 무료 CDN 전송의 차이 요청(파일 로드) 횟수는 일반적으로 최대 4
위의 네트워크 정체 분석을 바탕으로 네트워크의 데이터가 소스 사이트에서 사용자에게 직접 전달된다면 접속 정체가 발생할 가능성이 높습니다.
사용자가 가장 빠른 속도로 데이터를 얻을 수 있도록 사용자와 가장 가까운 곳에 데이터를 캐시하는 기술적 솔루션이 있다면 웹 사이트의 대역폭 내보내기 압력을 줄이고 네트워크 전송 혼잡을 줄이는 데 큰 역할을 할 것입니다. 효과. CDN은 바로 그러한 기술적 솔루션입니다. 기본 프로세스
 <br/>1. 사용자는 브라우저에 액세스하려는 도메인 이름을 입력합니다. <br/>2. 브라우저는 DNS 서버에 도메인 이름 확인을 요청합니다. <br/>3. DNS 서버는 도메인 이름의 IP 주소를 브라우저에 반환합니다. <br/>4. 브라우저는 IP 주소를 사용하여 서버에 콘텐츠를 요청합니다. <br/>5. 서버는 사용자가 요청한 콘텐츠를 브라우저에 반환합니다.
<br/>1. 사용자는 브라우저에 액세스하려는 도메인 이름을 입력합니다. <br/>2. 브라우저는 DNS 서버에 도메인 이름 확인을 요청합니다. <br/>3. DNS 서버는 도메인 이름의 IP 주소를 브라우저에 반환합니다. <br/>4. 브라우저는 IP 주소를 사용하여 서버에 콘텐츠를 요청합니다. <br/>5. 서버는 사용자가 요청한 콘텐츠를 브라우저에 반환합니다.  <br/>1. 사용자는 브라우저에 액세스하려는 도메인 이름을 입력합니다. <br/>2. 브라우저는 DNS 서버에 도메인 이름 확인을 요청합니다. CDN이 도메인 이름 확인을 조정하므로 DNS 서버는 결국 CNAME이 가리키는 CDN 전용 DNS 서버에 도메인 이름 확인 권한을 넘겨줍니다. <br/>3. CDN의 DNS 서버는 CDN의 부하 분산 장치 IP 주소를 사용자에게 반환합니다. <br/>4. 사용자는 CDN의 로드 밸런싱 장치에 대한 콘텐츠 URL 액세스 요청을 시작합니다. <br/>5. CDN 로드 밸런싱 장치는 사용자에게 서비스를 제공하기 위해 적합한 캐시 서버를 선택합니다. <br/>선택 기준에는 사용자의 IP 주소를 기준으로 사용자에게 가장 가까운 서버를 판단하고, 사용자가 요청한 URL에 포함된 콘텐츠 이름을 기준으로 사용자에게 필요한 콘텐츠가 있는지 판단하고, 로드 상태를 쿼리합니다. 각 서버에서 로드가 더 적은 서버를 결정합니다. <br/>위의 종합적인 분석을 바탕으로 로드 밸런싱 설정은 캐시 서버의 IP 주소를 사용자에게 반환합니다. <br/>6. 사용자가 캐시 서버에 요청합니다. <br/>7. 캐시 서버는 사용자의 요청에 응답하고 사용자가 요구하는 콘텐츠를 사용자에게 전달합니다. <br/>이 캐시 서버에 사용자가 원하는 콘텐츠가 없고 로드 밸런싱 장치가 이를 사용자에게 계속 할당하는 경우, 이 서버는 콘텐츠의 소스를 다시 추적할 때까지 상위 캐시 서버에 콘텐츠를 요청합니다. 웹사이트 서버는 콘텐츠를 로컬로 가져옵니다.
<br/>1. 사용자는 브라우저에 액세스하려는 도메인 이름을 입력합니다. <br/>2. 브라우저는 DNS 서버에 도메인 이름 확인을 요청합니다. CDN이 도메인 이름 확인을 조정하므로 DNS 서버는 결국 CNAME이 가리키는 CDN 전용 DNS 서버에 도메인 이름 확인 권한을 넘겨줍니다. <br/>3. CDN의 DNS 서버는 CDN의 부하 분산 장치 IP 주소를 사용자에게 반환합니다. <br/>4. 사용자는 CDN의 로드 밸런싱 장치에 대한 콘텐츠 URL 액세스 요청을 시작합니다. <br/>5. CDN 로드 밸런싱 장치는 사용자에게 서비스를 제공하기 위해 적합한 캐시 서버를 선택합니다. <br/>선택 기준에는 사용자의 IP 주소를 기준으로 사용자에게 가장 가까운 서버를 판단하고, 사용자가 요청한 URL에 포함된 콘텐츠 이름을 기준으로 사용자에게 필요한 콘텐츠가 있는지 판단하고, 로드 상태를 쿼리합니다. 각 서버에서 로드가 더 적은 서버를 결정합니다. <br/>위의 종합적인 분석을 바탕으로 로드 밸런싱 설정은 캐시 서버의 IP 주소를 사용자에게 반환합니다. <br/>6. 사용자가 캐시 서버에 요청합니다. <br/>7. 캐시 서버는 사용자의 요청에 응답하고 사용자가 요구하는 콘텐츠를 사용자에게 전달합니다. <br/>이 캐시 서버에 사용자가 원하는 콘텐츠가 없고 로드 밸런싱 장치가 이를 사용자에게 계속 할당하는 경우, 이 서버는 콘텐츠의 소스를 다시 추적할 때까지 상위 캐시 서버에 콘텐츠를 요청합니다. 웹사이트 서버는 콘텐츠를 로컬로 가져옵니다. 요약
12. nginx 로드 밸런싱
13. 캐싱(7개 수준 설명)
Directory
1.1.1 저장 방법
1.1.2 만료 확인
1.1.3 부분 캐싱 없음
1.2 정적 콘텐츠
2. 브라우저 캐시
2.1 구현
2.1.1 缓存协商
header("Last-Modified: " . gmdate("D, d M Y H:i:s") . " GMT");Last-Modified: Fri, 9 Dec 2014 23:23:23 GMT
If-Modified-Since: Fri, 9 Dec 2014 23:23:23 GMT
HTTP/1.1 304 Not Modified
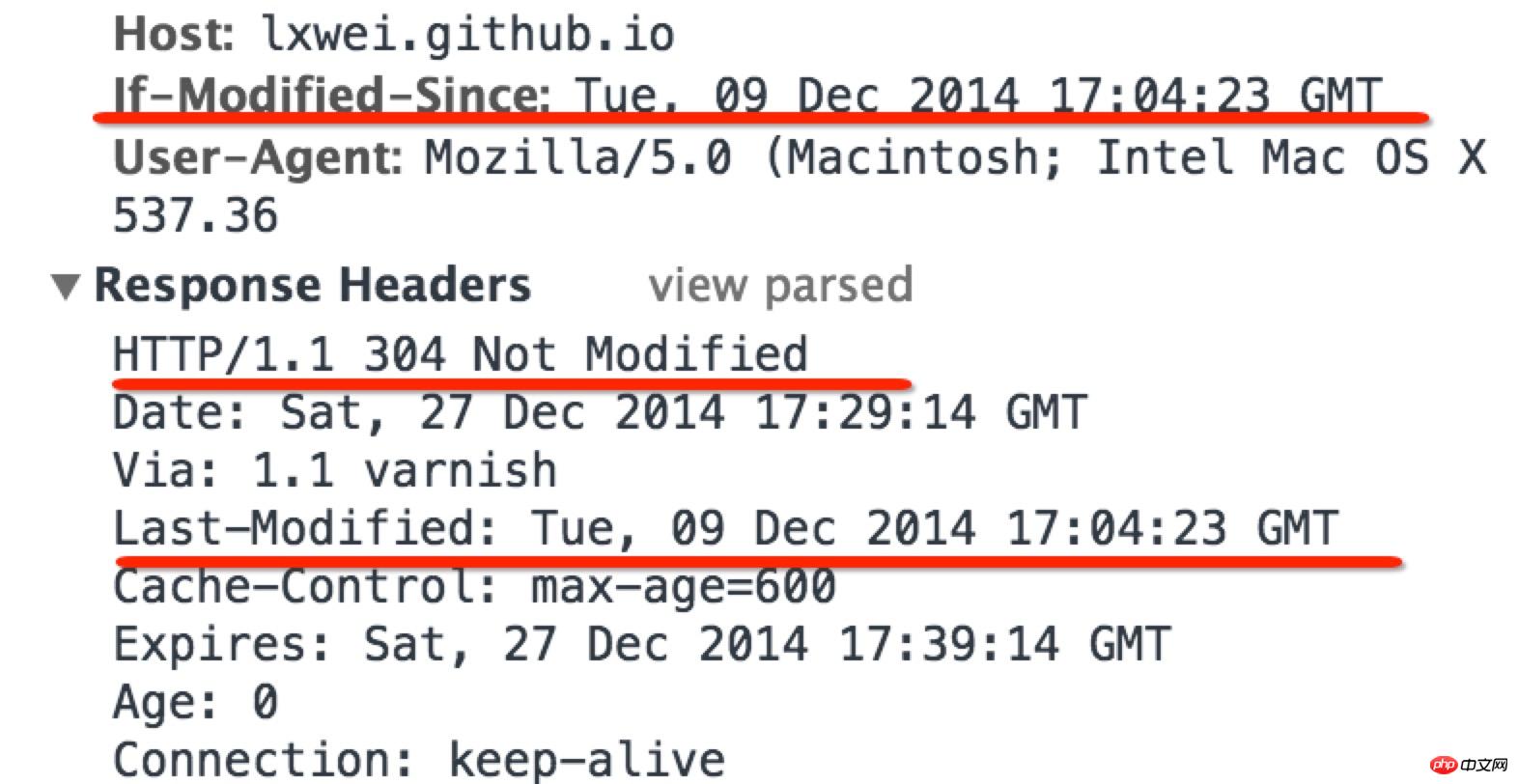
If-None-Match: "87665-c-090f0adfadf"
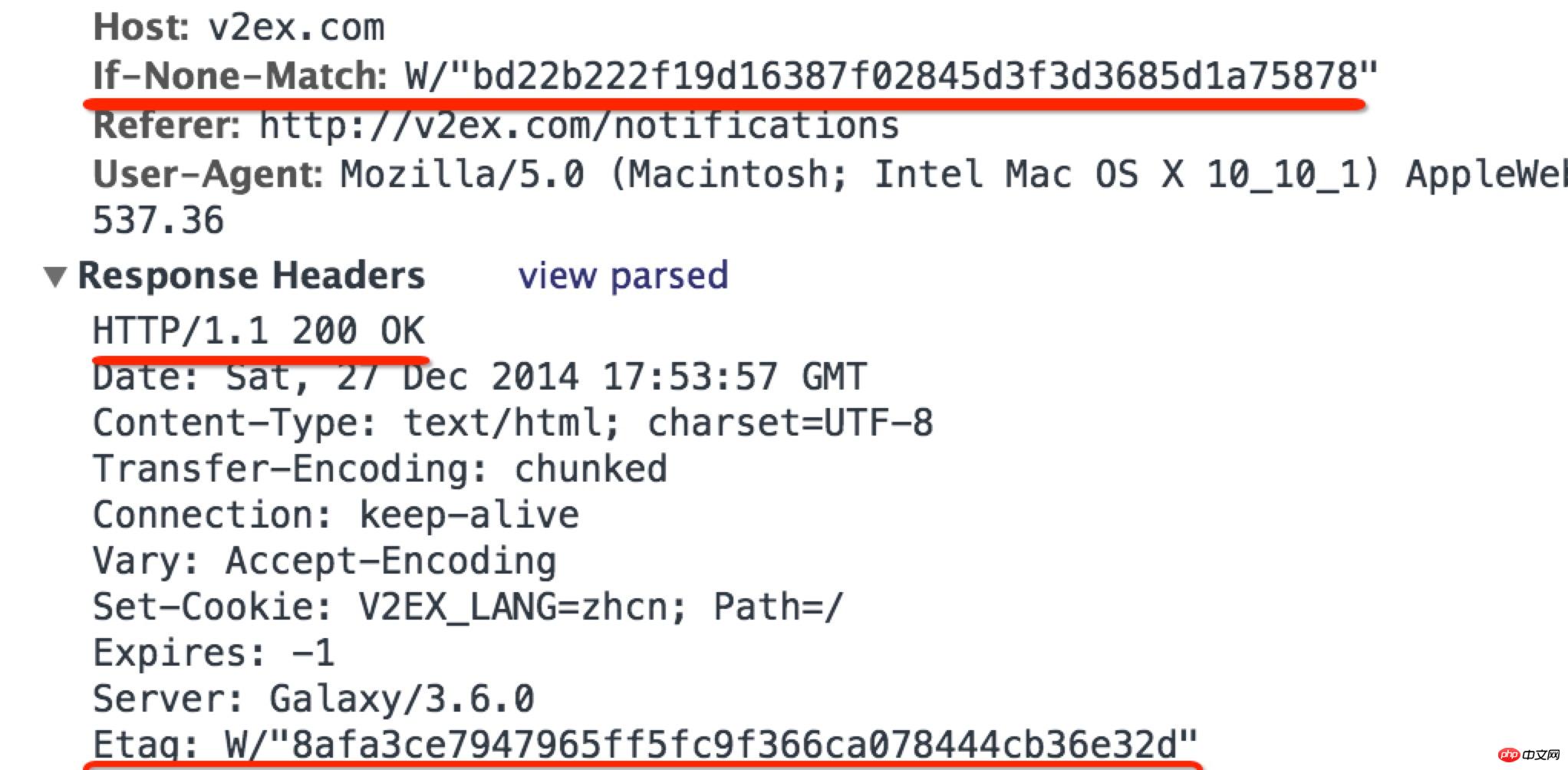
2.1.2 性能
2.2 彻底消灭请求
2.2.1 Expires 标记
Expires标记,告诉浏览器该内容何时过期,在内容过期前不需要再询问服务器,直接使用本地缓存即可。2.2.2 请求页面方式
최종 수정 만료 Ctrl + F5 유효하지 않음 유효하지 않음 F5 유효함 유효하지 않음 유효 유효로 이동 2.2.3 适应过期时间
max-age 指定缓存过期的相对时间,单位是秒,相对时间指相对浏览器本地时间。目前,当 HTTP 响应中同时含有 Expires 和 Cache-Control 时,浏览器会优先使用 Cache-Control。2.3 总结
3. Web 服务器缓存
3.1 简介
Expires 标记,如果希望不缓存某个动态内容,那么最简单的办法就是使用:header("Expires: 0");Last-Modified来实现,具体方法不再叙述。3.2 取代动态内容缓存
3.3 缓存文件描述符
4. 反向代理缓存
4.1 反向代理简介
4.2 역방향 프록시 캐시
4.2.1 캐싱 규칙 수정
4.2.2 캐시 지우기
5. 분산 캐싱
5.1 memcached
5.2 읽기-쓰기 캐시
5.3 캐시 모니터링
5.4 캐시 확장
6. 요약
14. 콘텐츠 전환, cms 정적화
1. 왜 정적인가요?
2. PHP 정적화
대규모 동적 웹사이트의 안정화
정적 솔루션:
정적 페이지, 동적 페이지 및 의사 정적 페이지의 차이점
15. spirit css는 클수록 좋은가요?
사용 시기: 요청량이 특히 크고 요청 데이터가 작은 경우 여러 개의 작은 그림을 하나의 큰 그림으로 집계하고 그림이 상대적으로 큰 경우 위치 지정을 통해 구현할 수 있다는 원칙부터 시작해 보겠습니다. , 리소스를 줄이기 위해 Cut graphs를 사용해야 합니다. 여러 요청을 하나로 병합하여 네트워크 리소스를 덜 소비하고 프런트엔드 액세스를 최적화합니다. <br/>

<p>
<p>
<b class="N1 n10"></b>
<em class="First small_up1"></em>
<span class="A1 up1"></span>
<span class="A2 up1"></span>
<span class="A3 down1"></span>
<span class="A4 down1"></span>
<span class="B1 up1"></span>
<span class="B2 down1"></span>
<span class="C1 up1"></span>
<span class="C2 up1"></span>
<span class="C3 down1"></span>
<span class="C4 down1"></span>
<em class="Last small_down1"></em>
<b class="N2 n10_h"></b>
</p>
</p>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>制作一幅扑克牌--黑桃10</title>
<style type="text/css"><!--
.card{width:125px;height:170px; position:absolute;overflow:hidden;border:1px #c0c0c0 solid;}
/*中间图片通用设置*/
span{display:block;width:20px;height:21px; position:absolute;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat;}
/*小图片通用设置*/
b{display:block;width:15px;height:10px; position:absolute;font-size:10pt;text-align:center;font-weight:bold;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat; overflow:hidden;}
/*数字通用设置*/
em{display:block;width:15px;height:10px; position:absolute;font-size:10pt;text-align:center;font-weight:bold;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat;overflow:hidden;}
/*各坐标点位置*/
.N1{left:1px;top:8px;}
.First{left:5px;top:20px;}
.A1{left:20px;top:20px;}
.A2{left:20px;top:57px;}
.A3{left:20px;top:94px;}
.A4{left:20px;top:131px;}
.B1{left:54px;top:38px;}
.B2{left:54px;top:117px;}
.C1{left:86px;top:20px;}
.C2{left:86px;top:57px;}
.C3{left:86px;top:94px;}
.C4{left:86px;top:131px;}
.Last{bottom:20px;right:0px;}
.N2{bottom:8px;right:5px;
}
/*大图标黑红梅方四种图片-上方向*/
.up1{background-position:0 1px;}/*黑桃*/
/*大图标黑红梅方四种图片-下方向*/
.down1{background-position:0 -19px;}/*黑桃*/
/*小图标黑红梅方四种图片-上方向*/
.small_up1{background-position:0 -40px;}/*黑桃*/
/*小图标黑红梅方四种图片-下方向*/
.small_down1{background-position:0 -51px;}/*黑桃*/
/*A~k数字图片-左上角*/
.n10{background-position:-191px 0px;left:-4px;width:21px;}
/*A~k数字图片-右下角*/
.n10_h{background-position:-191px -22px;right:3px;width:21px;}
/*A~k数字图片-左上角红色字*/
.n10_red{background-position:-191px 0px;}
/*A~k数字图片-右下角红色字*/
.n10_h_red{background-position:-191px -33px;}
-->
</style>
</head>
<body>
<!--10字符-->
<p>
<p>
<b class="N1 n10"></b>
<em class="First small_up1"></em>
<span class="A1 up1"></span>
<span class="A2 up1"></span>
<span class="A3 down1"></span>
<span class="A4 down1"></span>
<span class="B1 up1"></span>
<span class="B2 down1"></span>
<span class="C1 up1"></span>
<span class="C2 up1"></span>
<span class="C3 down1"></span>
<span class="C4 down1"></span>
<em class="Last small_down1"></em>
<b class="N2 n10_h"></b>
</p>
</p>
</body>
</html>16. 反向代理/正向代理
正向代理与反向代理【总结】

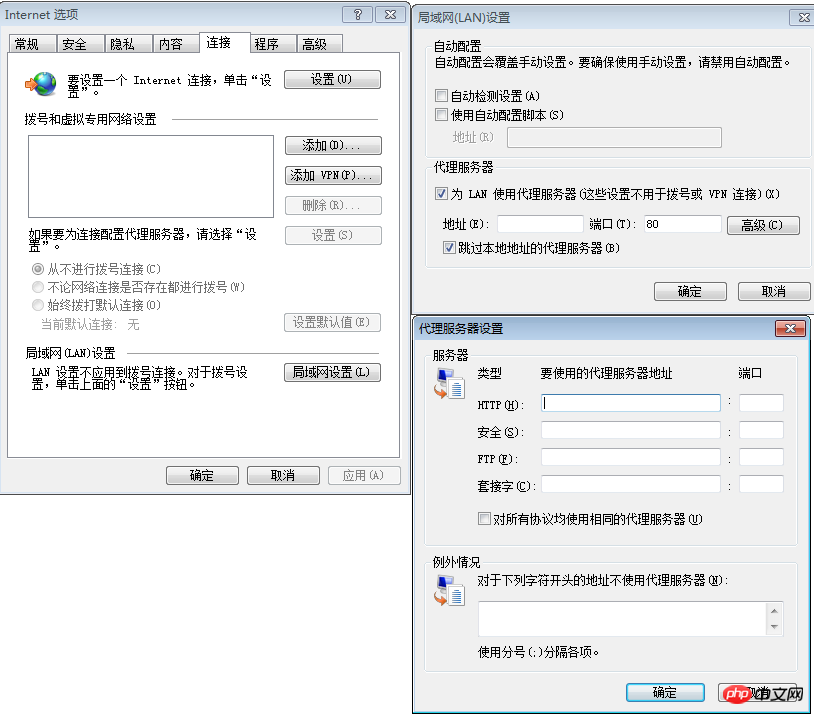

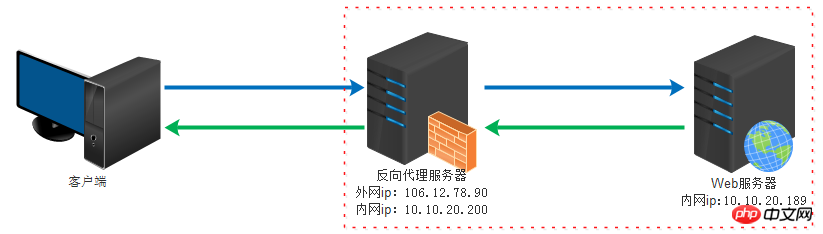
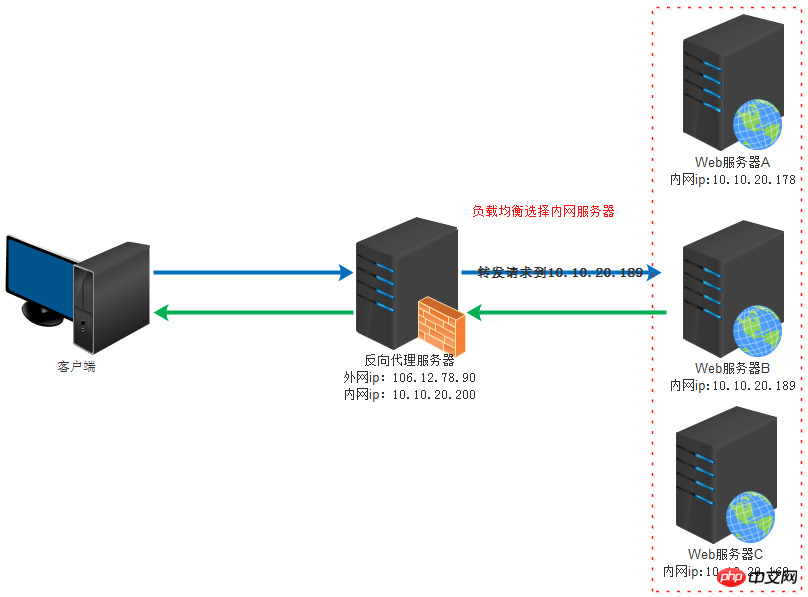
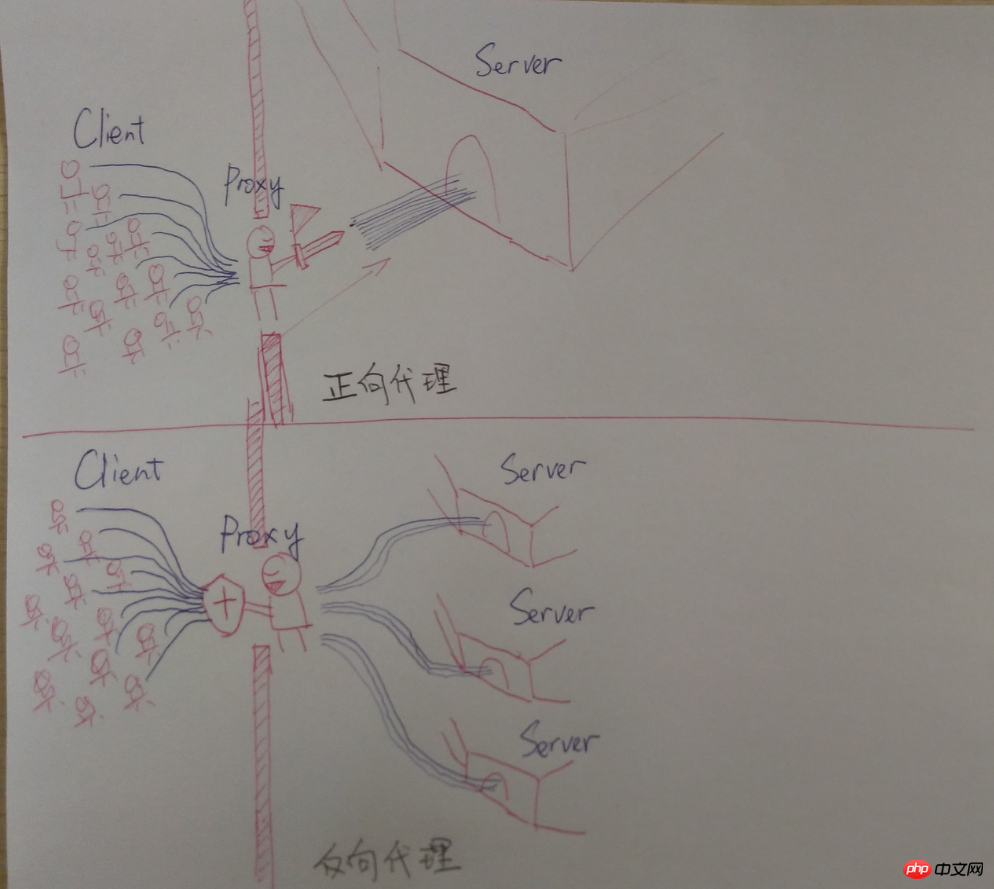
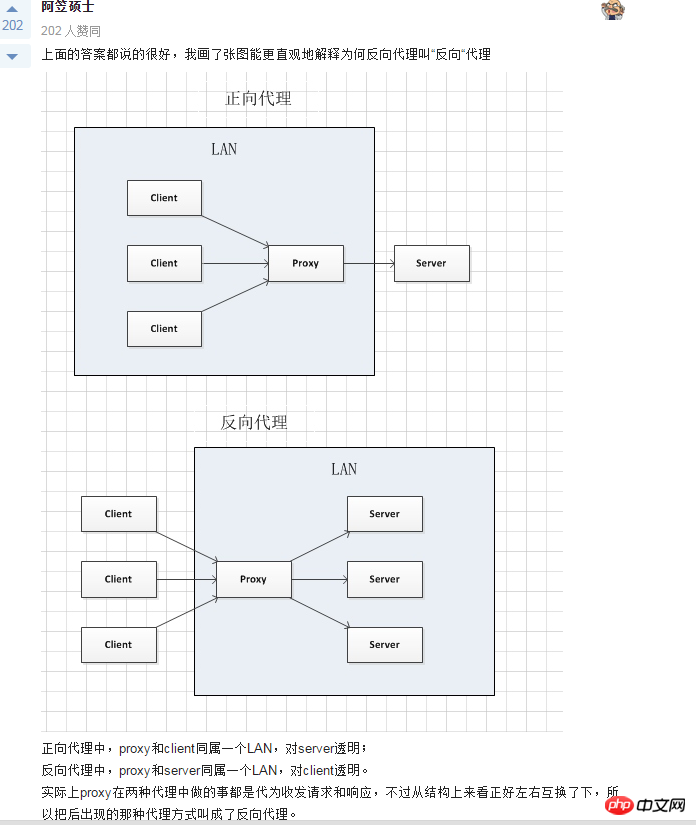
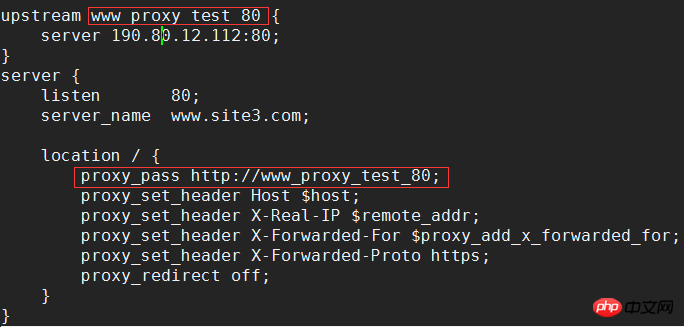 참조:
참조: 정방향 프록시
역방향 프록시역방향 프록시는 클라이언트에게 원래 서버처럼 작동합니다.
정방향 프록시와 역방향 프록시의 차이점버퍼링 기능을 사용하여 네트워크 사용량을 줄이세요.
역방향 프록시
Security
는 외부 세계가 투명하여 방문자는 자신이 프록시를 방문하고 있다는 사실을 알 수 없습니다.
역방향 프록시와 CDN의 차이점간단히 말하면 CDN은 네트워크 가속
솔루션입니다. 역방향 프록시는 사용자 요청을 백엔드 서버로 전달하는 기술입니다.
CDN은 역방향 프록시의 기술적 원리를 사용하며 가장 중요한 핵심 기술은 스마트 DNS 등입니다. 17. mysql 마스터-슬레이브, 최적화
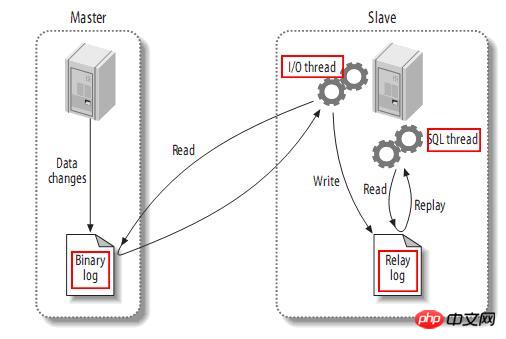
18 웹 보안
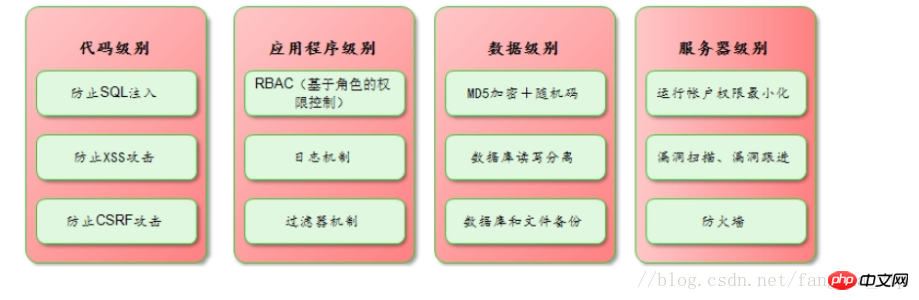 <br/>
<br/>20. memcached와 redis의 차이점
21. apache와 nginx의 차이점
1. 정의: 1. Apache HTTP 서버는 거의 모든 환경에서 널리 실행될 수 있는 모듈형 서버입니다. http
둘 다
Apache
2. Nginx와 Apache의 비교
1) nginx apache
2) apache nginx에 비해 장점
둘의 장단점 비교l
23. 性能优化
分布式缓存
缓存的基本原理
缓存是指将数据存储在相对较高访问速度的存储介质中。
(1)访问速度快,减少数据访问时间;
(2)如果缓存的数据进过计算处理得到的,那么被缓存的数据无需重复计算即可直接使用。
缓存的本质是一个内存Hash表,以一对Key、Value的形式存储在内存Hash表中,读写时间复杂度为O(1)。
合理使用缓存
不合理使用缓存非但不能提高系统的性能,还会成为系统的累赘,甚至风险。
频繁修改的数据
如果缓存中保存的是频繁修改的数据,就会出现数据写入缓存后,应用还来不及读取缓存,数据就已经失效,徒增系统负担。一般来说,数据的读写比在2:1以上,缓存才有意义。
没有热点的访问
如果应用系统访问数据没有热点,不遵循二八定律,那么缓存就没有意义。
数据不一致与脏读
一般会对缓存的数据设置失效时间,一旦超过失效时间,就要从数据库中重新加载。因此要容忍一定时间的数据不一致,如卖家已经编辑了商品属性,但是需要过一段时间才能被买家看到。还有一种策略是数据更新立即更新缓存,不过这也会带来更多系统开销和事务一致性问题。
缓存可用性
缓存会承担大部分数据库访问压力,数据库已经习惯了有缓存的日子,所以当缓存服务崩溃时,数据库会因为完全不能承受如此大压力而宕机,导致网站不可用。
这种情况被称作缓存雪崩,发生这种故障,甚至不能简单地重启缓存服务器和数据库服务器来恢复。
实践中,有的网站通过缓存热备份等手段提高缓存可用性:当某台缓存服务器宕机时,将缓存访问切换到热备服务器上。
但这种设计有违缓存的初衷,**缓存根本就不应该当做一个可靠的数据源来使用**。
通过分布式缓存服务器集群,将缓存数据分布到集群多台服务器上可在一定程度上改善缓存的可用性。
当一台缓存服务器宕机时,只有部分缓存数据丢失,重新从数据库加载这部分数据不会产生很大的影响。
缓存预热
缓存中的热点数据利用LRU(最近最久未用算法)对不断访问的数据筛选淘汰出来,这个过程需要花费较长的时间。
那么最好在缓存系统启动时就把热点数据加载好,这个缓存预加载手段叫缓存预热。
缓存穿透
如果因为不恰当的业务、或者恶意攻击持续高并发地请求某个不存在的数据,由于缓存没有保存该数据,所有的请求都会落到数据库上,会对数据库造成压力,甚至崩溃。
**一个简单的对策是将不存在的数据也缓存起来(其value为null)** 。分布式缓存架构
分布式缓存指缓存部署在多个服务器组成的集群中,以集群方式提供缓存服务,其架构方式有两种,一种是以JBoss Cache为代表的需要更新同步的分布式缓存,一种是以Memcached为代表的不互相通信的分布式缓存。 JBoss Cache在集群中所有服务器中保存相同的缓存数据,当某台服务器有缓存数据更新,就会通知其他机器更新或清除缓存数据。 它通常将应用程序和缓存部署在同一台服务器上,但受限于单一服务器的内存空间;当集群规模较大的时候,缓存更新需要同步到所有机器,代价惊人。因此这种方案多见于企业应用系统中。 Memcached采用一种集中式的缓存集群管理(互不通信的分布式架构方式)。缓存与应用分离部署,缓存系统部署在一组专门的服务器上,应用程序通过一致性Hash等路由算法选择缓存服务器远程访问数据,缓存服务器之间不通信,集群规模可以很容易地实现扩容,具有良好的伸缩性。 (1)简单的通信协议。Memcached使用TCP协议(UDP也支持)通信; (2)丰富的客户端程序。 (3)高性能的网络通信。Memcached服务端通信模块基于Libevent,一个支持事件触发的网络通信程序库,具有稳定的长连接。 (4)高效的内存管理。 (5)互不通信的服务器集群架构。
异步操作
使用消息队列将调用异步化(生产者--消费者模式),可改善网站的扩展性,还可以改善系统的性能。
在不使用消息队列的情况下,用户的请求数据直接写入数据库,在高并发的情况下,会对数据库造成巨大压力,使得响应延迟加剧。
在使用消息队列后,用户请求的数据发送给消息队列后立即返回,再由消息队列的消费者进程(通常情况下,该进程独立部署在专门的服务器集群上)从消息队列中获取数据,
异步写入数据库。由于消息队列服务器处理速度远快于服务器(消息队列服务器也比数据库具有更好的伸缩性)。
消息队列具有很好的削峰作用--通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。
需要注意的是,由于数据写入消息队列后立即返回给用户,数据在后续的业务校验、写数据库等操作可能失败,因此在使用消息队列进行业务异步处理后,
需要适当修改业务流程进行配合,如订单提交后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完后,
甚至商品出库后,再通过电子邮件或SMS消息通知用户订单成功,以免交易纠纷。
使用集群
在网站高并发访问的场景下,使用负载均衡技术为一个应用构建一个由多台服务器组成的服务器集群,将并发访问请求分发到多台服务器上处理。
代码优化
多线程
从资源利用的角度看,使用多线程的原因主要有两个:IO阻塞与多CPU。
当前线程进行IO处理的时候,会被阻塞释放CPU以等待IO操作完成,由于IO操作(不管是磁盘IO还是网络IO)通常都需要较长的时间,这时CPU可以调度其他的线程进行处理。
理想的系统Load是既没有进程(线程)等待也没有CPU空闲,利用多线程IO阻塞与执行交替进行,可最大限度利用CPU资源。
使用多线程的另一个原因是服务器有多个CPU。
简化启动线程估算公式:
启动线程数 = [任务执行时间 / (任务执行时间 - IO等待时间)]*CPU内核数 多线程编程一个需要注意的问题是线程安全问题,即多线程并发对某个资源进行修改,导致数据混乱。
所有的资源---对象、内存、文件、数据库,乃至另一个线程都可能被多线程并发访问。
编程上,解决线程安全的主要手段有:
(1)将对象设计为无状态对象。
所谓无状态对象是指对象本身不存储状态信息(对象无成员变量,或者成员变量也是无状态对象),不过从面向对象设计的角度看,无状态对象是一种不良设计。
(2)使用局部对象。
即在方法内部创建对象,这些对象会被每个进入该方法的线程创建,除非程序有意识地将这些对象传递给其他线程,否则不会出现对象被多线程并发访问的情形。
(3)并发访问资源时使用锁。
即多线程访问资源的时候,通过锁的方式使多线程并发操作转化为顺序操作,从而避免资源被并发修改。
资源复用
1系统运行时,要尽量减少那些开销很大的系统资源的创建和销毁,比如数据库连接、网络通信连接、线程、复杂对象等。
2从编程角度,资源复用主要有两种模式:单例(Singleton)和对象池(Object Pool)。
3单例虽然是GoF经典设计模式中较多被诟病的一个模式,但由于目前Web开发中主要使用贫血模式,从Service到Dao都是些无状态对象,无需重复创建,使用单例模式也就自然而然了。
4对象池模式通过复用对象实例,减少对象创建和资源消耗。
5对于数据库连接对象,每次创建连接,数据库服务端都需要创建专门的资源以应对,因此频繁创建关闭数据库连接,对数据库服务器是灾难性的,
同时频繁创建关闭连接也需要花费较长的时间。
6因此实践中,应用程序的数据库连接基本都使用连接池(Connection Pool)的方式,数据库连接对象创建好以后,
将连接对象放入对象池容器中,应用程序要连接的时候,就从对象池中获取一个空闲的连接使用,使用完毕再将该对象归还到对象池中即可,不需要创建新的连接。
数据结构
早期关于程序的一个定义是,程序就是数据结构+算法,数据结构对于编程的重要性不言而喻。
在不同场景中合理使用数据结构,灵活组合各种数据结构改善数据读写和计算特性可极大优化程序的性能。
垃圾回收
理解垃圾回收机制有助于程序优化和参数调优,以及编写内存安全的代码。
24. 支付
手机网站支付接口
产品简介
申请条件
配置
查看PID

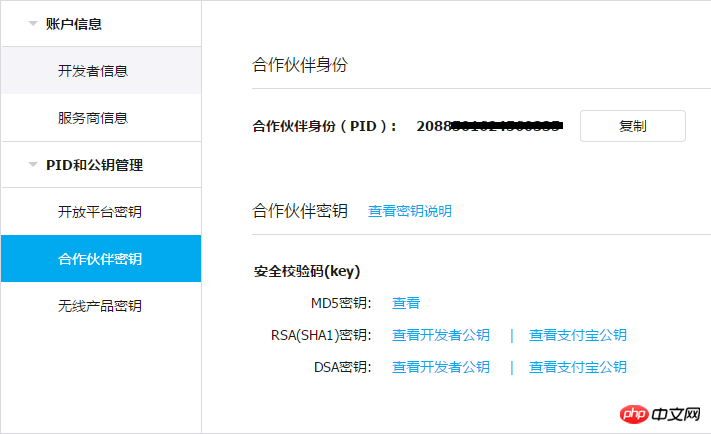
配置密钥
应用环境
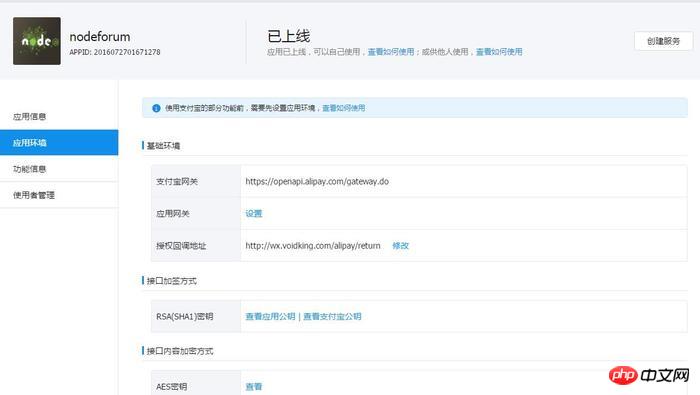 <br/>
<br/>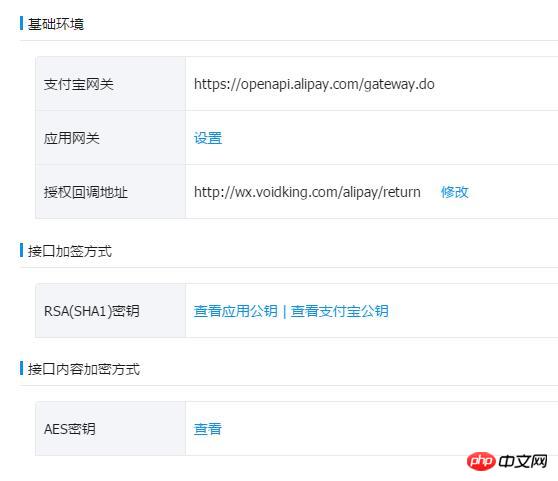 <br/>上图是我的应用配置选项,公司账号也许会有所不同。具体哪些参数需要配置?请参照接口参数说明,需要什么就配置什么。
<br/>上图是我的应用配置选项,公司账号也许会有所不同。具体哪些参数需要配置?请参照接口参数说明,需要什么就配置什么。交互
Node端发起支付请求
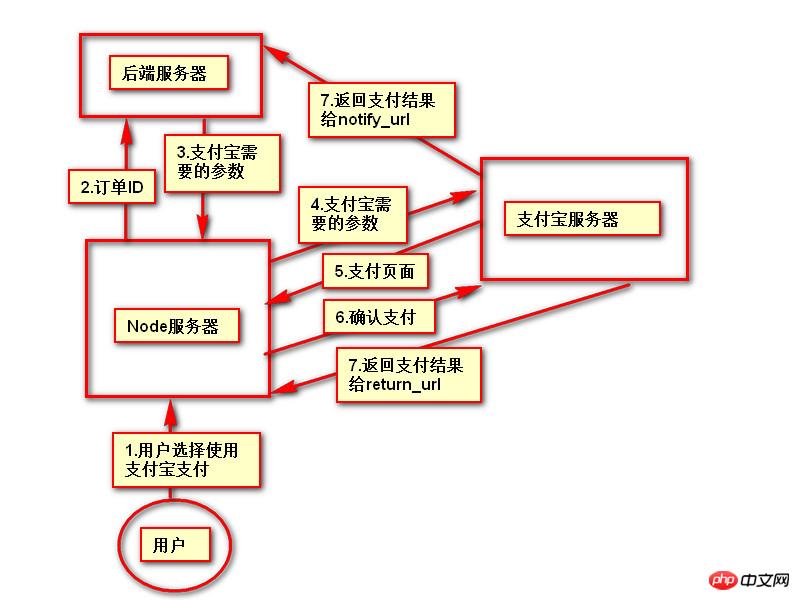 <br/>我们公司采用的,就是这种方式,步骤3中Node端获取到的支付宝参数,包括sign。其实,sign的计算工作也可以放在Node端,只不过支付宝没有给出Node的demo,实现起来需要耗费多一点时间。
<br/>我们公司采用的,就是这种方式,步骤3中Node端获取到的支付宝参数,包括sign。其实,sign的计算工作也可以放在Node端,只不过支付宝没有给出Node的demo,实现起来需要耗费多一点时间。后端发起支付请求
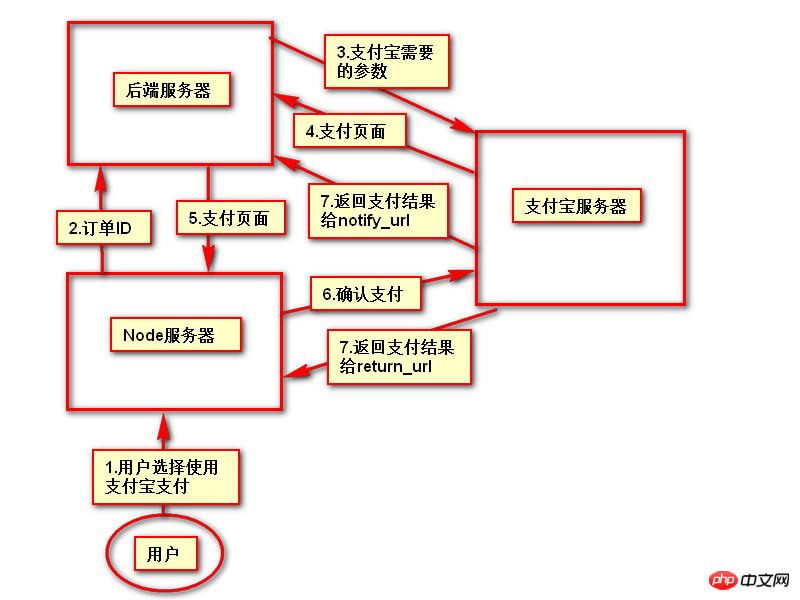 <br/>这种方式也很好,而且,步骤4中后端获取到支付页面,也可以不传给Node端,自己显示出来。这样,整个流程就更加简单。
<br/>这种方式也很好,而且,步骤4中后端获取到支付页面,也可以不传给Node端,自己显示出来。这样,整个流程就更加简单。return_url和notify_url
Node端详解
request发起请求
// 通过orderId向后端请求获取支付宝支付参数alidata var alipayUrl = 'https://mapi.alipay.com/gateway.do?'+ alidata; request.get({url: alipayUrl},function(error, response, body){ res.send(response.body); });
request.get({url: alipayUrl},function(error, response, body){
var str = response2.body;
str = str.replace(/gb2312/, "utf-8");
res.setHeader('content-type', 'text/html;charset=utf-8');
res.send(str);
});表单提交请求
Node端
// node端 // 通过orderId向后端请求获取支付宝支付参数alidata function getArg(str,arg) { var reg = new RegExp('(^|&)' + arg + '=([^&]*)(&|$)', 'i'); var r = str.match(reg); if (r != null) { return unescape(r[2]); } return null; } var alipayParam = { _input_charset: getArg(alidata,'_input_charset'), body: getArg(alidata,'body'), it_b_pay: getArg(alidata, 'it_b_pay'), notify_url: getArg(alidata, 'notify_url'), out_trade_no: getArg(alidata, 'out_trade_no'), partner: getArg(alidata, 'partner'), payment_type: getArg(alidata, 'payment_type'), return_url: getArg(alidata, 'return_url'), seller_id: getArg(alidata, 'seller_id'), service: getArg(alidata, 'service'), show_url: getArg(alidata, 'show_url'), subject: getArg(alidata, 'subject'), total_fee: getArg(alidata, 'total_fee'), sign_type: getArg(alidata, 'sign_type'), sign: getArg(alidata, 'sign'), app_pay: getArg(alidata, 'app_pay') }; res.render('artist/alipay',{ // 其他参数 alipayParam: alipayParam });html
<!--alipay.html-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>支付宝支付</title> </head> <body>
<form id="ali-form" action="https://mapi.alipay.com/gateway.do" method="get">
<input type="hidden" name="_input_charset" value="<%= alipayParam._input_charset%>">
<input type="hidden" name="body" value="<%= alipayParam.body%>">
<input type="hidden" name="it_b_pay" value="<%= alipayParam.it_b_pay%>">
<input type="hidden" name="notify_url" value="<%= alipayParam.notify_url%>">
<input type="hidden" name="out_trade_no" value="<%= alipayParam.out_trade_no%>">
<input type="hidden" name="partner" value="<%= alipayParam.partner%>">
<input type="hidden" name="payment_type" value="<%= alipayParam.payment_type%>">
<input type="hidden" name="return_url" value="<%= alipayParam.return_url%>">
<input type="hidden" name="seller_id" value="<%= alipayParam.seller_id%>">
<input type="hidden" name="service" value="<%= alipayParam.service%>">
<input type="hidden" name="show_url" value="<%= alipayParam.show_url%>">
<input type="hidden" name="subject" value="<%= alipayParam.subject%>">
<input type="hidden" name="total_fee" value="<%= alipayParam.total_fee%>">
<input type="hidden" name="sign_type" value="<%= alipayParam.sign_type%>">
<input type="hidden" name="sign" value="<%= alipayParam.sign%>">
<input type="hidden" name="app_pay" value="<%= alipayParam.app_pay%>">
</form> <% include ../bootstrap.html %> <script type="text/javascript" src="<%= dist %>/js/business-modules/artist/alipay.js?v=2016052401"></script>
</body>
</html>
js
// alipay.js seajs.use(['zepto'],function($){
var index = {
init:function(){
var self = this;
this.bindEvent();
},
bindEvent:function(){
var self = this;
$('#ali-form').submit();
}
}
index.init();
});小结
 <br/>选择支付宝支付后,成功跳转到了支付宝支付页面,nice!看来这种方案很靠谱。
<br/>选择支付宝支付后,成功跳转到了支付宝支付页面,nice!看来这种方案很靠谱。错误排查
 <br/>值得点赞的是,支付宝给的错误代码很明确,一看就懂。上面这个错误,签名不对。因为我给alipayParam私自加了个app_pay属性,没有经过签名。
<br/>值得点赞的是,支付宝给的错误代码很明确,一看就懂。上面这个错误,签名不对。因为我给alipayParam私自加了个app_pay属性,没有经过签名。微信屏蔽支付宝
问题描述

完美解决办法
Node端
res.render('artist/alipay',{ alipayParam: alipayParam, param: urlencode(alidata) });html
<input type="hidden" id="param" value="<%= param%>"> <iframe id="payFrame" name="mainIframe" src="" frameborder="0" scrolling="auto" ></iframe>
js
var iframe = document.getElementById('payFrame'); var param = $('#param').val(); iframe.src='https://mapi.alipay.com/gateway.do?'+param;
报错
官方解决办法
html
<!--alipay.html--> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>支付宝支付</title> </head> <body> <form id="ali-form" action="https://mapi.alipay.com/gateway.do" method="get"> <input type="hidden" name="_input_charset" value="<%= alipayParam._input_charset%>"> <input type="hidden" name="body" value="<%= alipayParam.body%>"> <input type="hidden" name="it_b_pay" value="<%= alipayParam.it_b_pay%>"> <input type="hidden" name="notify_url" value="<%= alipayParam.notify_url%>"> <input type="hidden" name="out_trade_no" value="<%= alipayParam.out_trade_no%>"> <input type="hidden" name="partner" value="<%= alipayParam.partner%>"> <input type="hidden" name="payment_type" value="<%= alipayParam.payment_type%>"> <input type="hidden" name="return_url" value="<%= alipayParam.return_url%>"> <input type="hidden" name="seller_id" value="<%= alipayParam.seller_id%>"> <input type="hidden" name="service" value="<%= alipayParam.service%>"> <input type="hidden" name="show_url" value="<%= alipayParam.show_url%>"> <input type="hidden" name="subject" value="<%= alipayParam.subject%>"> <input type="hidden" name="total_fee" value="<%= alipayParam.total_fee%>"> <input type="hidden" name="sign_type" value="<%= alipayParam.sign_type%>"> <input type="hidden" name="sign" value="<%= alipayParam.sign%>"> <p class="wrapper buy-wrapper" style="max-width:90%"> <a href="javascript:void(0);" class="J-btn-submit btn mj-submit btn-strong btn-larger btn-block">确认支付</a> </p> </form> <input type="hidden" id="param" value="<%= param%>"> <% include ../bootstrap.html %> <script type="text/javascript" src="<%= dist %>/js/business-modules/artist/ap.js"></script> <script> var btn = document.querySelector(".J-btn-submit"); btn.addEventListener("click", function (e) { e.preventDefault(); e.stopPropagation(); e.stopImmediatePropagation(); var queryParam = ''; Array.prototype.slice.call(document.querySelectorAll("input[type=hidden]")).forEach(function (ele) { queryParam += ele.name + "=" + encodeURIComponent(ele.value) + '&'; }); var gotoUrl = document.querySelector("#ali-form").getAttribute('action') + '?' + queryParam; _AP.pay(gotoUrl); return false; }, false); btn.click(); </script> </body> </html>
后记
북마크
25 높은 동시성, 대규모 트래픽
<br/>
26. mysql과 nosql의 차이점
NoSQL 또는 관계형 데이터베이스
백엔드 구조 서비스화Overview
구조화된 데이터(즉, 데이터베이스에 저장된 행 데이터)에 비해 구현된 데이터는 2차원 테이블 구조를 사용하여 논리적으로 표현할 수 있습니다. , 데이터베이스에서 2차원 논리적 테이블로 표현할 수 없는 데이터를 비정형 데이터라고 하며, 사무문서, 텍스트, 그림, XML, HTML, 각종 보고서, 이미지, 오디오/비디오 정보 등 모든 형식을 포함합니다.
데이터 분류
반구조적 데이터(semi-structured data)
구조화된 데이터
구조화되지 않은 데이터
반구조화된 데이터
储存方式
化解为结构化数据
用XML格式来组织并保存到CLOB字段中
28. 单链表翻转
单链表反转总结篇
1 定义
class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
next = null;
}
}2 方法1:就地反转法
2.1 思路
2.2 解释
1初始状态
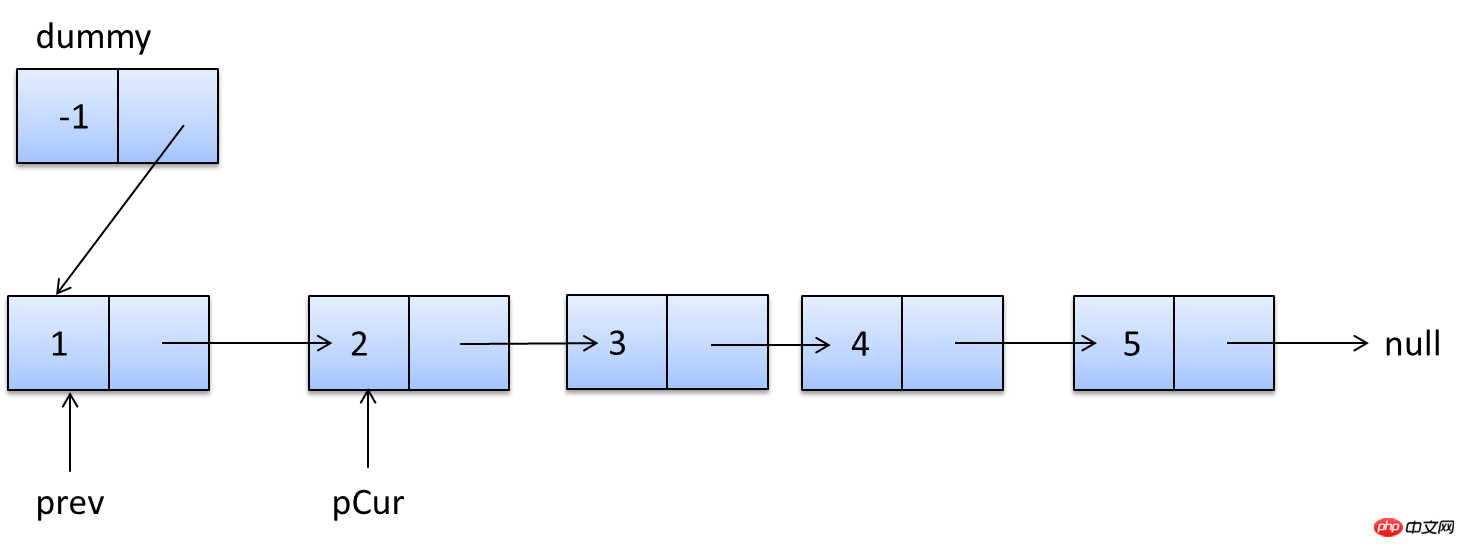
2 过程
1 prev.next = pCur.next;
2 pCur.next = dummy.next;
3 dummy.next = pCur;
4 pCur = prev.next;
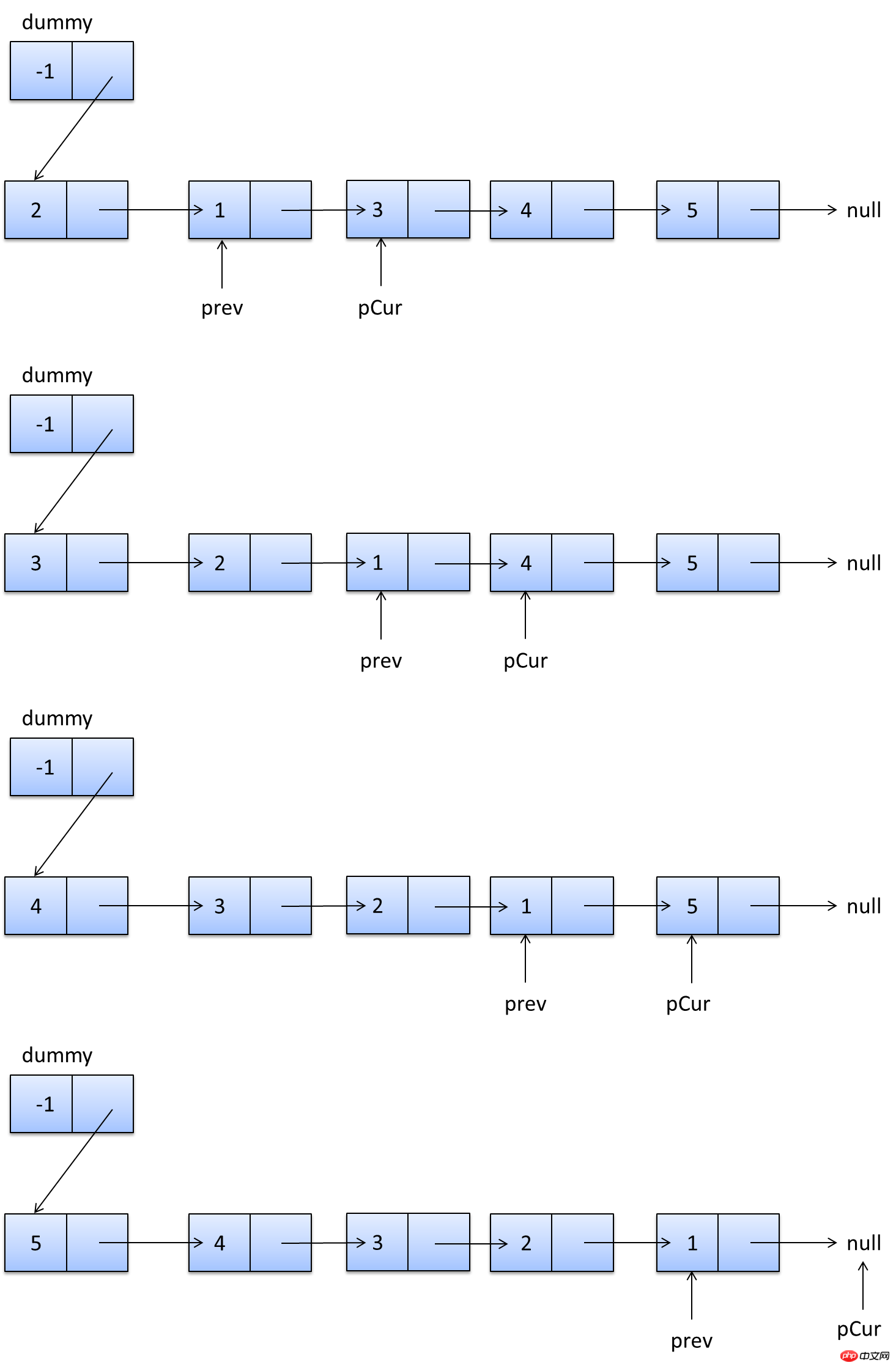
3 循环条件
pCur is not null
2.3 代码
1 // 1.就地反转法
2 public ListNode reverseList1(ListNode head) {
3 if (head == null)
4 return head;
5 ListNode dummy = new ListNode(-1);
6 dummy.next = head;
7 ListNode prev = dummy.next;
8 ListNode pCur = prev.next;
9 while (pCur != null) {
10 prev.next = pCur.next;
11 pCur.next = dummy.next;
12 dummy.next = pCur;
13 pCur = prev.next;
14 }
15 return dummy.next;
16 }2.4 总结
3 方法2:新建链表,头节点插入法
3.1 思路
3.2 解释
1 初始状态
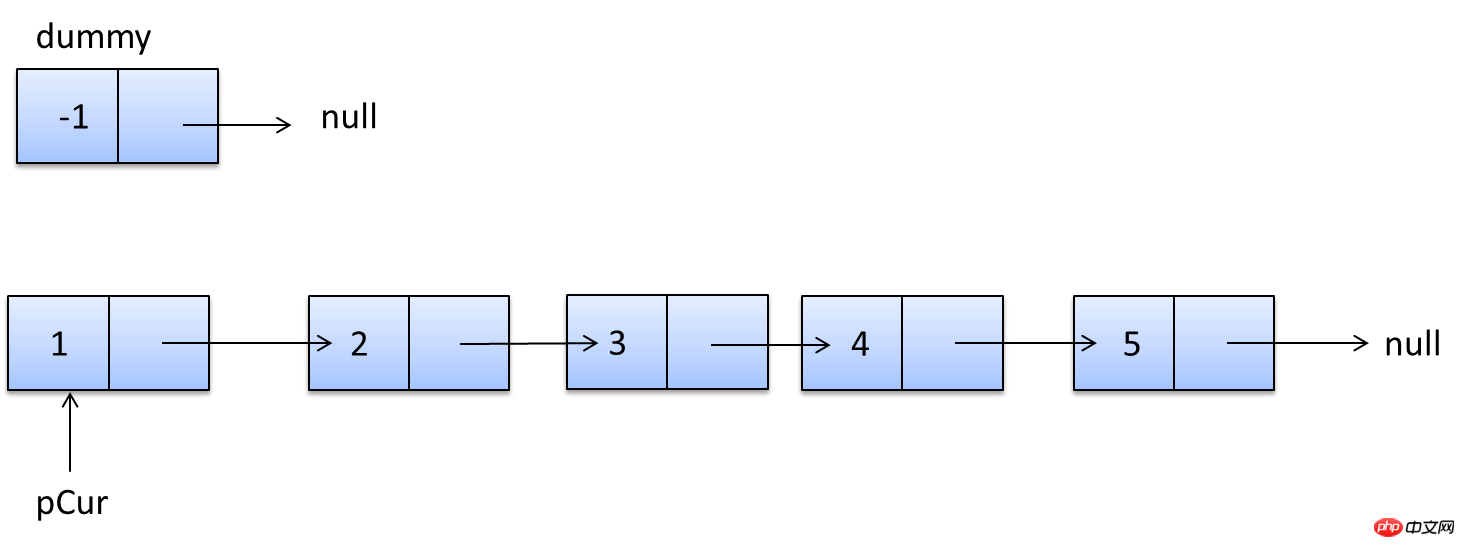
2 过程
1 pNex = pCur.next
2 pCur.next = dummy.next
3 dummy.next = pCur
4 pCur = pNex
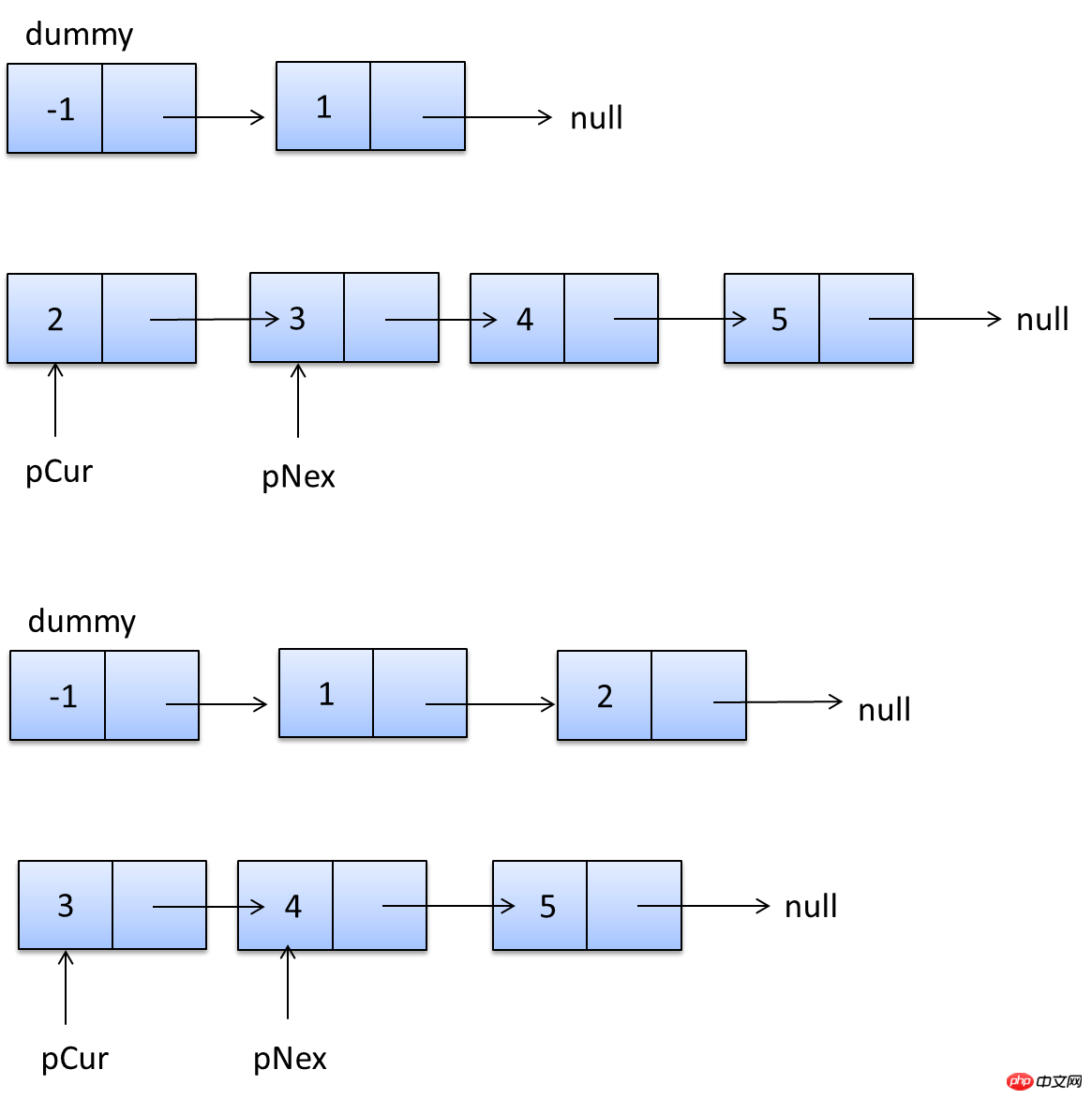
3 循环条件
pCur is not null
3.3 代码
1 // 2.新建链表,头节点插入法
2 public ListNode reverseList2(ListNode head) {
3 ListNode dummy = new ListNode(-1);
4 ListNode pCur = head;
5 while (pCur != null) {
6 ListNode pNex = pCur.next;
7 pCur.next = dummy.next;
8 dummy.next = pCur;
9 pCur = pNex;
10 }
11 return dummy.next;
12 }<br/>29. 最擅长的php
30. 索引
MySQL索引优化
一、索引类型
CREATE TABLE index_table (
id BIGINT NOT NULL auto_increment COMMENT '主键',
NAME VARCHAR (10) COMMENT '姓名',
age INT COMMENT '年龄',
phoneNum CHAR (11) COMMENT '手机号',
PRIMARY KEY (id) ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
下图是Col2为索引列,记录与B树结构的对应图,仅供参考:
1、普通索引
------直接创建索引 create index index_name on index_table(name);
2、唯一索引
---------直接创建唯一索引 create UNIQUE index index_phoneNum on index_table(phoneNum);
3、主键
4、多列索引
-------直接创建组合索引 create index index_union on index_table(name,age,phoneNum);
二、索引优化
1、选择索引列
SELECT age----不使用索引 FROM index_union WHERE NAME = 'xiaoming'---考虑使用索引 AND phoneNum = '18668247687';---考虑使用索引
2、最左前缀原则
3、like的使用
4、不能使用索引说明
5、order by
1 select test_index where id = 3 order by id desc;1 select test_index where id = 3 order by name desc;31. 몰 구조
1 전자상거래 사례의 이유
대형 포털은 일반적으로 CDN, 정적화 등을 사용하여 최적화할 수 있는 뉴스 정보입니다. Kaixin.com 및 기타 웹사이트는 더욱 대화형이며 더 많은 NOSQL, 분산 캐시를 도입하고 사용량이 많을 수 있습니다. -speed 성능 커뮤니케이션 프레임워크 등. 전자상거래 웹사이트는 위 두 가지 범주의 특징을 가지고 있습니다. 예를 들어, 제품 세부정보는 CDN을 사용하여 정적으로 만들 수 있지만, 상호작용성이 높은 웹사이트는 NOSQL과 같은 기술을 사용해야 합니다. 따라서 우리는 전자상거래 웹사이트를 분석 사례로 활용한다. 大型门户一般是新闻类信息,可以使用CDN,静态化等方式优化,开心网等交互性比较多,可能会引入更多的NOSQL,分布式缓存,使用高性能的通信框架等。电商网站具备以上两类的特点,比如产品详情可以采用CDN,静态化,交互性高的需要采用NOSQL等技术。因此,我们采用电商网站作为案例,进行分析。2 电商网站需求
推荐大家使用需求功能矩阵,进行需求描述。

3 网站初级架构

一般都会采用集群的方式,进行高可用设计
고객 요구 사항:
제품을 받은 후 사용자는 제품을 평가하고 평가할 수 있습니다.
요구사항을 설명하기 위해 요구사항 함수 매트릭스를 사용하는 것이 좋습니다. 🎜🎜이 전자상거래 웹사이트의 수요 매트릭스는 다음과 같습니다: 🎜🎜🎜🎜🎜🎜위는 전자상거래 웹사이트 요구 사항에 대한 간단한 예입니다. 목적은 (1) 요구 사항을 분석할 때 포괄적이어야 하며, 대규모 분산 시스템은 비기능적 요구 사항에 초점을 맞춰야 합니다. (2) 모든 사람이 다음 단계의 분석 및 설계를 위한 기초를 가질 수 있도록 간단한 전자 상거래 수요 시나리오를 설명해야 합니다. 🎜🎜3 기본 웹 사이트 구조 🎜🎜일반 웹 사이트의 초기 접근 방식은 3개의 서버를 사용하는 것입니다. 하나는 애플리케이션 배포, 하나는 데이터베이스 배포, 다른 하나는 NFS 파일 시스템 배포입니다. 이것은 지난 몇 년간 10만 명 이상의 회원이 있는 웹사이트, 수직 의류 디자인 포털, 수많은 사진을 본 적이 있는 비교적 전통적인 접근 방식입니다. 서버는 애플리케이션, 데이터베이스 및 이미지 스토리지를 배포하는 데 사용됩니다. 성능상의 문제가 많았습니다. 아래와 같이: 🎜🎜🎜🎜그러나 현재의 주류 웹사이트 아키텍처는 엄청난 변화를 겪었습니다. 일반적으로 클러스터는 고가용성 설계에 사용됩니다. 적어도 이것이 아래의 모습입니다. 🎜🎜🎜🎜🎜🎜🎜 (1) 고가용성을 달성하기 위해 클러스터를 중복 애플리케이션 서버에 사용합니다. (로드 밸런싱 장비는 애플리케이션과 함께 배포할 수 있습니다.) 🎜🎜🎜🎜 (2) 데이터베이스 마스터 대기 모드를 사용하여 데이터 백업 및 고가용성; 🎜🎜🎜🎜4 시스템 용량 추정🎜🎜🎜🎜추정 단계: 🎜🎜🎜🎜🎜🎜등록된 사용자 수 - 일일 평균 UV 볼륨 - 일일 동시성 볼륨 🎜
예상 용량: 70/90 원칙
위의 추정에 따르면 몇 가지 문제가 있습니다. 일반적으로 약 70% 수준을 유지하며 피크 기간에는 90% 수준에 도달하며 자원을 낭비하지 않으며 비교적 안정적입니다. 메모리와 IO는 비슷합니다. 5 웹사이트 아키텍처 분석
系统CPU一般维持在70%左右的水平,高峰期达到90%的水平,是不浪费资源,并比较稳定的。内存,IO类似。5 网站架构分析
6 网站架构优化
6.1 业务拆分
根据业务属性进行垂直切分,划分为产品子系统,购物子系统,支付子系统,评论子系统,客服子系统,接口子系统(对接如进销存,短信等外部系统)。根据业务子系统进行等级定义,可分为核心系统和非核心系统。核心系统:产品子系统,购物子系统,支付子系统;非核心:评论子系统,客服子系统,接口子系统。业务拆分作用:提升为子系统可由专门的团队和部门负责,专业的人做专业的事,解决模块之间耦合以及扩展性问题;每个子系统单独部署,避免集中部署导致一个应用挂了,全部应用不可用的问题。等级定义作用:用于流量突发时,对关键应用进行保护,实现优雅降级;保护关键应用不受到影响。

6.2 应用集群部署(分布式,集群,负载均衡)
分布式部署:将业务拆分后的应用单独部署,应用直接通过RPC进行远程通信;集群部署:电商网站的高可用要求,每个应用至少部署两台服务器进行集群部署;负载均衡:6 웹사이트 아키텍처 최적화
6.1 사업 분할
🎜비즈니스 속성에 따른 수직적 세분화, 제품 하위 시스템, 쇼핑 하위 시스템, 결제 하위 시스템으로 구분 , 서브시스템 시스템, 고객 서비스 서브시스템, 인터페이스 서브시스템(구매, 판매, 재고, SMS 등 외부 시스템과 연결)을 검토합니다. 🎜🎜비즈니스 하위 시스템을 기반으로 한 수준 정의는 핵심 시스템과 비핵심 시스템으로 나눌 수 있습니다. 핵심 시스템: 제품 하위 시스템, 쇼핑 하위 시스템, 결제 하위 시스템, 비핵심: 검토 하위 시스템, 고객 서비스 하위 시스템, 인터페이스 하위 시스템. 🎜🎜비즈니스 분할의 역할: 전문 팀과 부서에서 하위 시스템으로의 업그레이드를 처리할 수 있습니다. 이를 통해 각 하위 시스템이 별도로 배포되는 것을 방지할 수 있습니다. 하나의 애플리케이션이 중단되고 모든 애플리케이션을 사용할 수 없게 만드는 중앙 집중식 배포 문제입니다. 🎜🎜레벨 정의 기능: 트래픽 버스트 중에 주요 애플리케이션을 보호하고 정상적인 성능 저하를 달성하는 데 사용됩니다. 🎜🎜분할 후 아키텍처 다이어그램: 🎜🎜🎜🎜참조 배포 계획 2:🎜🎜🎜🎜(1) 각 애플리케이션은 위와 같이 개별적으로 배포됩니다. 🎜🎜(2) 핵심 시스템과 비핵심 시스템이 조합하여 배포됩니다. 🎜< /blockquote >
6.2 애플리케이션 클러스터 배포(분산, 클러스터링, 로드 밸런싱)
🎜분산 배포: 업무 분할 후 애플리케이션을 별도로 배포하고, RPC 원격 통신을 통해 직접 애플리케이션을 수행한다. ; 🎜🎜클러스터 배포:전자 상거래 웹사이트에 대한 고가용성 요구 사항, 각 애플리케이션은 클러스터 배포를 위해 최소 2개의 서버를 배포해야 합니다.🎜🎜로드 밸런싱:은 가용성이 높습니다. 시스템은 로드 밸런싱을 통해 일반 애플리케이션에 대한 고가용성을 달성하고, 내장된 로드 밸런싱을 통해 고가용성을 달성하려면 분산 서비스를, 활성 및 백업 방식을 통해 고가용성을 달성하려면 관계형 데이터베이스에 필요합니다. 🎜🎜클러스터 배포 후 아키텍처 다이어그램:🎜
6.3 다단계 캐시
에 따라 로컬 캐시와 분산 캐시의 두 가지 유형으로 나눌 수 있습니다. 이 경우에는 두 번째 수준 캐시 방법을 사용하여 캐시를 설계합니다. 첫 번째 수준 캐시는 로컬 캐시이고 두 번째 수준 캐시는 분산 캐시입니다. (보다 세분화된 페이지 캐싱, 프래그먼트 캐싱 등도 있습니다) 一般可分为两类本地缓存和分布式缓存。本案例采用二级缓存的方式,进行缓存的设计。一级缓存为本地缓存,二级缓存为分布式缓存。(还有页面缓存,片段缓存等,那是更细粒度的划分)一级缓存,缓存数据字典,和常用热点数据等基本不可变/有规则变化的信息,二级缓存缓存需要的所有缓存。当一级缓存过期或不可用时,访问二级缓存的数据。如果二级缓存也没有,则访问数据库。
6.4 单点登录(分布式Session)
一般可采用Session同步,Cookies,分布式Session方式。电商网站一般采用分布式Session实现。
6.5 数据库集群(读写分离,分库分表)
高可用,高性能一般采用冗余的方式进行系统设计。一般有两种方式读写分离和分库分表。读写分离:一般解决读比例远大于写比例的场景,可采用一主一备,一主多备或多主多备方式。
6.6 服务化
将多个子系统公用的功能/模块,进行抽取,作为公用服务使用。比如本案例的会员子系统就可以抽取为公用的服务。
6.7 消息队列
消息队列可以解决子系统/模块之间的耦合,实现异步,高可用,高性能的系统레벨 1 캐시, 캐시 데이터 사전, 일반적으로 사용되는 핫스팟 데이터 및 기타 기본적으로 불변/정기적으로 변경되는 정보, 레벨 2 캐시 캐시 모든 캐싱이 필요합니다. 첫 번째 수준 캐시가 만료되거나 사용할 수 없게 되면 두 번째 수준 캐시의 데이터에 액세스됩니다. 두 번째 수준 캐시가 없으면 데이터베이스에 액세스됩니다. 
일반적으로 세션 동기화, 쿠키, 분산 세션 방법을 사용할 수 있습니다. 전자상거래 웹사이트는 일반적으로 분산 세션을 사용하여 구현됩니다. 🎜🎜한 단계 더 나아가 분산 세션을 기반으로 완전한 Single Sign-On 또는 계정 관리 시스템을 구축할 수 있습니다. 🎜🎜🎜 🎜프로세스 설명: 🎜🎜🎜(1) 사용자가 처음 로그인하면 사용자 ID를 키로 사용하는 등의 세션 정보(사용자 ID 및 사용자 정보)가 분산 세션에 기록됩니다. (2) 사용자가 다시 로그인하면 분산된 Session을 가져와서 세션 정보가 있는지 확인합니다. 그렇지 않은 경우 로그인 페이지로 이동합니다. 🎜🎜 (3) 일반적으로 Cache 미들웨어를 사용하여 구현하는 것이 좋습니다. Redis를 사용하므로 분산 세션의 다운타임을 용이하게 하는 지속성 기능이 있습니다. 그 후 영구 저장소에서 세션 정보를 로드할 수 있습니다. 🎜🎜 (4) 세션을 저장할 때 세션 보존 시간을 설정할 수 있습니다. 예를 들어 15분 정도이며 초과하면 자동으로 시간 초과됩니다. 🎜🎜🎜 캐시 미들웨어와 결합하면 분산 세션이 세션 세션을 매우 잘 시뮬레이션할 수 있습니다. 🎜🎜6.5 데이터베이스 클러스터(읽기 및 쓰기 분리, 하위 데이터베이스 및 하위 테이블)🎜🎜대규모 웹사이트에서는 대용량 데이터 저장, 고가용성 및 고성능을 달성하기 위해 대용량 데이터를 저장해야 합니다. 일반적으로 중복 시스템 설계 코드>를 사용합니다. 일반적으로 읽기와 쓰기, 하위 데이터베이스와 테이블을 분리하는 방법에는 두 가지가 있습니다. 🎜🎜읽기와 쓰기의 분리: 일반적으로 읽기 비율이 쓰기 비율보다 훨씬 큰 시나리오를 해결하기 위해 하나의 기본과 하나의 대기, 하나의 기본과 다중 대기, 또는 다중 기본과 다중 대기를 사용할 수 있습니다. . 🎜🎜이 사례는 데이터베이스 하위 테이블 및 읽기-쓰기 분리와 결합된 비즈니스 분할을 기반으로 합니다. 아래와 같이: 🎜🎜🎜🎜🎜 (1) 업무 분할 후: 각 하위 시스템에는 별도의 라이브러리가 필요합니다. 🎜🎜 (2) 별도의 라이브러리가 너무 큰 경우 제품 분류 라이브러리 등 업무 특성에 따라 다시 라이브러리로 분할될 수 있습니다. , 제품 라이브러리 🎜🎜 (3) 데이터베이스가 분할된 후 테이블에 많은 양의 데이터가 있는 경우 테이블은 일반적으로 ID, 시간 등에 따라 분할될 수 있습니다. 고급 사용법은 일관됨 Hash) 🎜🎜( 4) 하위 라이브러리와 하위 테이블을 기준으로 읽기 및 쓰기를 분리합니다. 🎜🎜🎜관련 미들웨어는 Cobar(Alibaba, 현재 더 이상 유지되지 않음), TDDL(Alibaba), Atlas(Qihoo 360), MyCat(Cobar를 기반으로 하여 중국에는 인재가 많으며, 중국 최초의 오픈소스 프로젝트로 알려져 있음). 🎜🎜샤딩 데이터베이스 및 테이블의 테마 공유에서는 데이터베이스 및 테이블 샤딩 이후의 시퀀스 문제, JOIN 및 트랜잭션 문제가 소개됩니다. 🎜🎜6.6 Servitization🎜🎜여러 하위 시스템에 공통적인 기능/모듈을 추출하여 공용 서비스로 사용합니다. 예를 들어 이 경우 멤버십 하위 시스템은 공용 서비스로 추출될 수 있습니다. 🎜🎜🎜 🎜6.7 메시지 큐🎜🎜메시지 큐는 하위 시스템/모듈 간의 결합을 해결하고 비동기식, 고가용성, 고성능 시스템을 실현할 수 있습니다. 이는 분산 시스템의 표준 구성입니다. 이 경우 메시지 큐는 주로 쇼핑 및 배송 링크에 사용됩니다. 🎜🎜🎜(1) 사용자가 주문한 후 메시지 대기열에 기록된 다음 클라이언트에 직접 반환됩니다. 🎜🎜(2) 재고 하위 시스템: 메시지 대기열 정보를 읽고 재고 감소를 완료합니다. ) 배포 하위 시스템: 메시지 대기열 정보를 읽고 전달합니다. 🎜🎜🎜🎜🎜建议可以研究下Rabbit MQ。6.8 其他架构(技术)
应用集群,多级缓存,单点登录,数据库集群,服务化,消息队列外。还有CDN,反向代理,分布式文件系统,大数据处理等系统。7 架构总结

32. app
34. AB
前沿
--PV(访问量):Page View, 即页面浏览量或点击量,用户每次刷新即被计算一次。 --UV(独立访客):Unique Visitor,访问您网站的一台电脑客户端为一个访客。00:00-24:00内相同的客户端只会被计算一次。 --IP(独立IP):指独立IP数。00:00-24:00内相同IP地址之被计算一次。
安装
ab的基本参数
-c 并发的请求数 -n 要执行的请求总数 -k 启用keep-alive功能(开启的话,请求会快一些) -H 一个使用冒号分隔的head报文头的附加信息 -t 执行这次测试所用的时间
ab基本语法
ab -c 5 -n 60 -H "Referer: http://baidu.com" -H "Connection: close" http://blog.csdn.net /XXXXXX/article/details/XXXXXXX
ab -c 100 -n 100 -H "User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:3 8.0) Gecko/20100101 Firefox/38.0" -e "E:\ab.csv" http://blog.csdn.net/uxxxxx/artic le/details/xxxx
ab执行结果分析

总结
linux 下ab压力测试
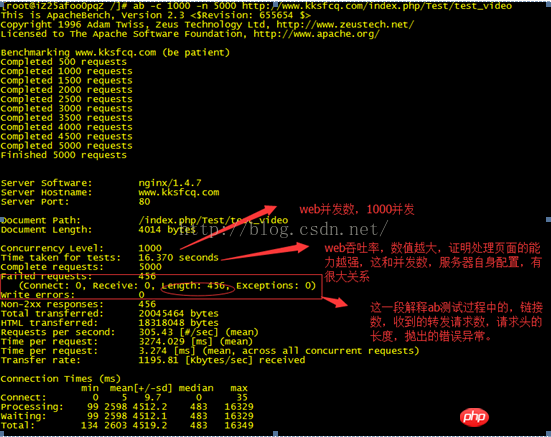
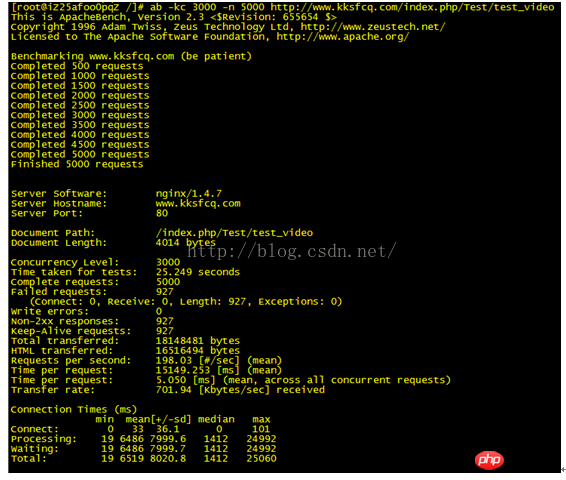 <br/>
<br/>35. 느린 쿼리
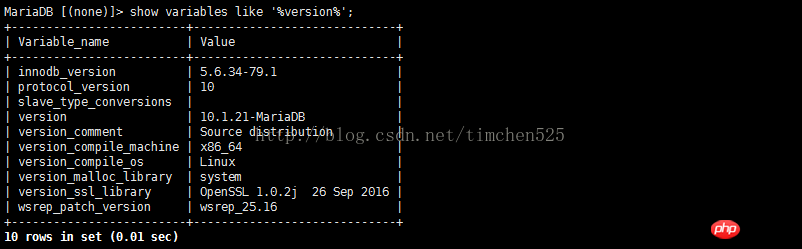 <br/>
<br/> <br/>
<br/> <br/>
<br/> <br/>
<br/> 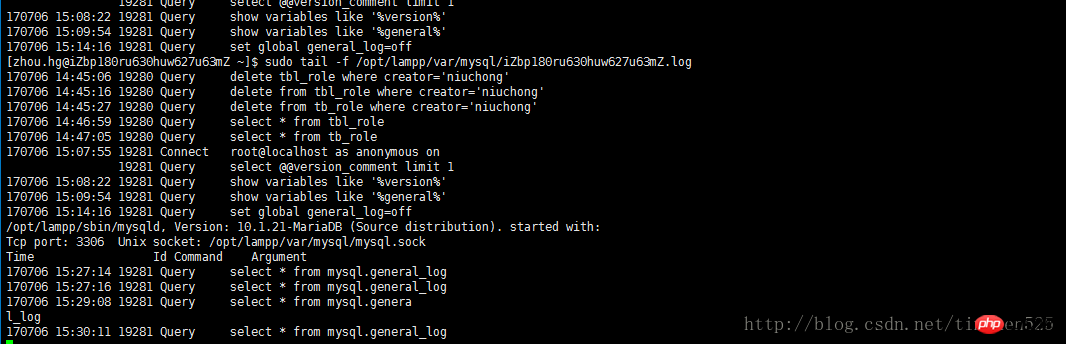 <br/>
<br/>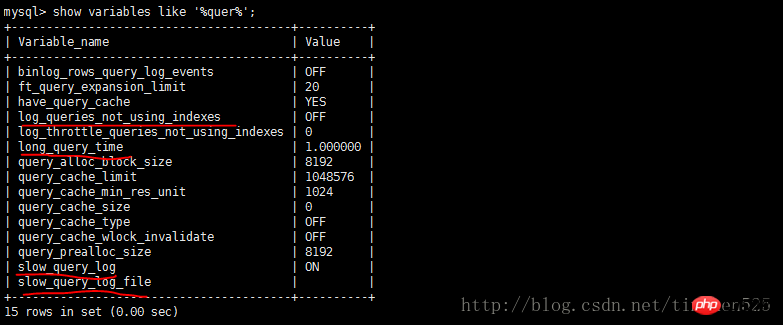 의 값은 파일에 기록된 느린 쿼리 로그입니다. (<br/>참고:
의 값은 파일에 기록된 느린 쿼리 로그입니다. (<br/>참고:  <br/>
<br/> <br/>
<br/>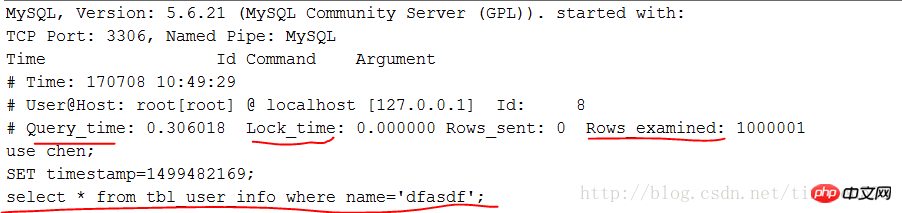 <br/>
<br/>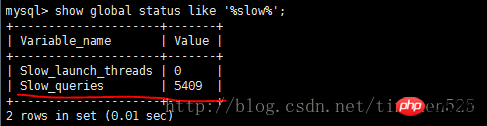 <br/>
<br/> <br/>
<br/>36. Framework
오픈 소스 프레임워크(TP, CI, Laravel, Yii)
37. 命名空间
PHP命名空间 namespace 及导入 use 的用法
<?php
echo 111;
//由于namespace前有代码而报错
namespace Teacher;
class Person{
function __construct(){
echo 'Please study!';
}
}<?php
namespace Newer;
require_once './1.php';
new Person();
//报错,找不到Person;
new \Person();
//输出 I am tow!;
<?php
namespace New;
require_once './2.php';
new Person();
//报错,(当前空间)找不到
Person; new \Person();
//报错,(公共空间)找不到
Person; new \Two\Person();
//输出 I am tow!;
namespace School\Parents;
class Man{
function __construct(){
echo 'Listen to teachers!<br/>';
}
}
namespace School\Teacher;
class Person{
function __construct(){
echo 'Please study!<br/>';
}
}
namespace School\Student;
class Person{
function __construct(){
echo 'I want to play!<br/>';
}
}
new Person();
//输出I want to play!
new \School\Teacher\Person();
//输出Please study!
new Teacher\Person();
//报错 ----------
use School\Teacher;
new Teacher\Person();
//输出Please study! ----------
use School\Teacher as Tc;
new Tc\Person();
//输出Please study! ----------
use \School\Teacher\Person;
new Person();
//报错 ----------
use \School\Parent\Man;
new Man();
//报错

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



