
다음은 Python을 사용하여 pdf를 txt로 출력하는 방법에 대한 예입니다. 좋은 참조 값이 있으며 모든 사람에게 도움이 되기를 바랍니다. 와서 살펴보자
일주일 전에 한 반 친구가 저에게 이것에 대해 물었습니다. 예전에 Huawei 대회에 참가했기 때문에 대회를 살펴보았더니 pdfminer 패키지를 사용해야 한다고 했습니다. 그래서 설치했는데, 설치 과정은 아주 간단했습니다.
sudo pip install pdfminer;
과정 중 오류는 없었습니다. 어떻게 부르는지는 pdfminer 라이브러리를 잘 공부하지 않아서 바이두를 시작하게 됐는데...
공식 문서: http://www.unixuser.org/~euske/python/pdfminer/ index.html
은 전적으로 Python으로 작성되었습니다. (버전 2.4 이상에 적용 가능)
PDF 문서를 구문 분석, 분석 및 변환합니다.
PDF-1.7 사양을 지원합니다. (거의)
CJK 언어 및 세로쓰기 스크립트를 지원합니다.
다양한 글꼴 유형(Type1, TrueType, Type3 및 CID)을 지원합니다.
기본 암호화(RC4) 지원.
PDF를 HTML로 변환합니다.
개요 추출(TOC).
태그 콘텐츠 추출.
텍스트 블록을 그룹화하여 원본 레이아웃을 재구성하세요.
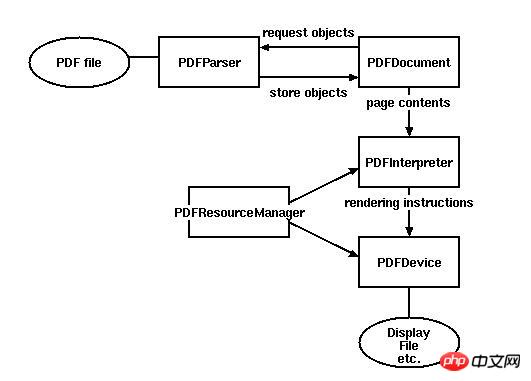
일부 기본 클래스
PDFParser: 파일에서 데이터 가져오기
PDFDocument: 얻은 데이터를 저장하고 PDFParser는 서로 관련됩니다.
PDFPageInterpreter가 페이지 콘텐츠를 처리합니다.
PDFDevice가 이를 필요한 것으로 변환합니다.
PDFResourceManager 형식은 글꼴이나 이미지와 같은 공유 리소스를 저장하는 데 사용됩니다.
간단한 구현
test.pdf를 읽고 output.txt로 출력합니다.
# -*- coding: utf-8 -*-
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import *
from pdfminer.converter import PDFPageAggregator
import os
fp = open('test.pdf', 'rb')
#来创建一个pdf文档分析器
parser = PDFParser(fp)
#创建一个PDF文档对象存储文档结构
document = PDFDocument(parser)
# 检查文件是否允许文本提取
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建一个PDF资源管理器对象来存储共赏资源
rsrcmgr=PDFResourceManager()
# 设定参数进行分析
laparams=LAParams()
# 创建一个PDF设备对象
# device=PDFDevice(rsrcmgr)
device=PDFPageAggregator(rsrcmgr,laparams=laparams)
# 创建一个PDF解释器对象
interpreter=PDFPageInterpreter(rsrcmgr,device)
# 处理每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout=device.get_result()
for x in layout:
if(isinstance(x,LTTextBoxHorizontal)):
with open('output.txt','a') as f:
f.write(x.get_text().encode('utf-8')+'\n')관련 권장 사항:
위 내용은 Python을 사용하여 PDF를 TXT로 출력하는 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



