

회귀 및 분류를 구현하기 위해 PyTorch에 간단한 신경망을 구축하는 예

이 기사에서는 회귀 및 분류를 구현하기 위해 PyTorch에서 간단한 신경망을 구축하는 예를 주로 소개하고 참고용으로 제공합니다. 함께 살펴보세요
이 글에서는 PyTorch에서 회귀와 분류를 구현하기 위한 간단한 신경망 구축 사례를 소개합니다. 자세한 내용은 다음과 같습니다.

1 . PyTorch 시작하기
1. 설치 방법
PyTorch 공식 웹사이트(http://pytorch.org)에 로그인하면 다음 인터페이스를 볼 수 있습니다:
옵션을 클릭하세요. 위 그림에서 Linux에서 conda 명령을 얻으려면:
conda install pytorch torchvision -c soumith
현재 PyTorch는 아직 Windows가 아닌 MacOS와 Linux만 지원합니다. PyTorch를 설치하면 두 개의 모듈이 설치됩니다. 하나는 torch이고 다른 하나는 torchvision입니다. Torch는 신경망을 구축하는 데 사용되는 기본 모듈입니다. torchvision은 데이터베이스와 직접 사용할 수 있도록 이미 훈련된 신경망이 있는 보조 모듈입니다. 예를 들어 (VGG, AlexNet, ResNet)입니다.
2. Numpy 및 Torch
torch_data = torch.from_numpy(np_data)는 numpy(배열) 형식을 토치(텐서) 형식으로 변환할 수 있습니다. torch_data.numpy()는 토치의 텐서 형식을 numpy의 배열 형식으로 변환할 수 있습니다. Torch의 Tensor와 numpy의 배열은 저장 공간을 공유하므로 하나를 수정하면 다른 것도 수정됩니다.
1차원(1-D) 데이터의 경우 numpy는 행 벡터 형식으로 출력을 인쇄하고, torch는 열 벡터 형식으로 출력을 인쇄합니다.
sin, cos,abs,mean 등과 같은 numpy의 다른 기능은 torch에서도 같은 방식으로 사용될 수 있습니다. numpy에서 np.matmul(data, data)와 data.dot(data)의 행렬 곱셈은 동일한 결과를 산출한다는 점에 유의해야 합니다. torch.mm(tensor, tensor)는 행렬 곱셈 방법이므로 결과는 다음과 같습니다. 행렬, tensor.dot(tensor)는 텐서를 1차원 텐서로 변환한 다음 요소별로 곱하고 합산하여 실수를 얻습니다.
관련 코드:
import torch import numpy as np np_data = np.arange(6).reshape((2, 3)) torch_data = torch.from_numpy(np_data) # 将numpy(array)格式转换为torch(tensor)格式 tensor2array = torch_data.numpy() print( '\nnumpy array:\n', np_data, '\ntorch tensor:', torch_data, '\ntensor to array:\n', tensor2array, ) # torch数据格式在print的时候前后自动添加换行符 # abs data = [-1, -2, 2, 2] tensor = torch.FloatTensor(data) print( '\nabs', '\nnumpy: \n', np.abs(data), '\ntorch: ', torch.abs(tensor) ) # 1维的数据,numpy是行向量形式显示,torch是列向量形式显示 # sin print( '\nsin', '\nnumpy: \n', np.sin(data), '\ntorch: ', torch.sin(tensor) ) # mean print( '\nmean', '\nnumpy: ', np.mean(data), '\ntorch: ', torch.mean(tensor) ) # 矩阵相乘 data = [[1,2], [3,4]] tensor = torch.FloatTensor(data) print( '\nmatrix multiplication (matmul)', '\nnumpy: \n', np.matmul(data, data), '\ntorch: ', torch.mm(tensor, tensor) ) data = np.array(data) print( '\nmatrix multiplication (dot)', '\nnumpy: \n', data.dot(data), '\ntorch: ', tensor.dot(tensor) )
3. Variable
PyTorch의 신경망은 Tensor의 모든 작업에 대한 자동 파생 방법을 제공하는 autograd 패키지에서 제공됩니다.
autograd.Variable 이는 이 패키지의 핵심 클래스입니다. 변수는 Tensor를 포함하고 Tensor에 정의된 거의 모든 작업을 지원하는 컨테이너로 이해될 수 있습니다. 작업이 완료되면 .backward()를 호출하여 모든 그래디언트를 자동으로 계산할 수 있습니다. 즉, Variable에 텐서를 배치해야만 역전송, 자동 도출 등의 연산을 신경망에서 구현할 수 있습니다.
원본 텐서는 .data 속성을 통해 접근할 수 있으며, 이 변수의 기울기는 .grad 속성을 통해 볼 수 있습니다.
관련 코드:
import torch from torch.autograd import Variable tensor = torch.FloatTensor([[1,2],[3,4]]) variable = Variable(tensor, requires_grad=True) # 打印展示Variable类型 print(tensor) print(variable) t_out = torch.mean(tensor*tensor) # 每个元素的^ 2 v_out = torch.mean(variable*variable) print(t_out) print(v_out) v_out.backward() # Variable的误差反向传递 # 比较Variable的原型和grad属性、data属性及相应的numpy形式 print('variable:\n', variable) # v_out = 1/4 * sum(variable*variable) 这是计算图中的 v_out 计算步骤 # 针对于 v_out 的梯度就是, d(v_out)/d(variable) = 1/4*2*variable = variable/2 print('variable.grad:\n', variable.grad) # Variable的梯度 print('variable.data:\n', variable.data) # Variable的数据 print(variable.data.numpy()) #Variable的数据的numpy形式
부분 출력 결과:
변수:
변수 포함:
1 2
3 4
[torch.FloatTensor 크기 2x 2]
variable.grad:
다음을 포함하는 변수:
0.5000 1.0000
1.5000 2.0000
[torch.FloatTensor 크기 2x2]
variable.data:
1 2
3 4
[torch.FloatTensor 크기 2x2]
[[ 1. 2.]
[ 3. 4.]]
4. 여기 기능 활성화 기능
Torch의 활성화 기능은 모두 torch.nn.function에 있으며, relu, sigmoid, tanh, softplus는 모두 일반적으로 사용되는 활성화 기능입니다. 관련 코드:
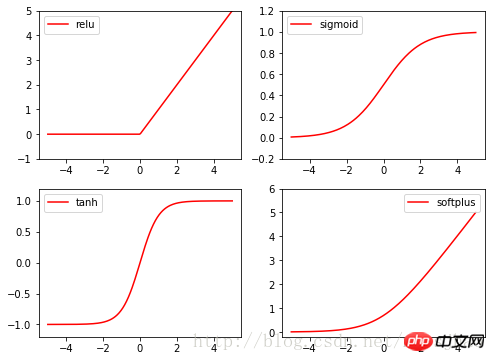
import torch import torch.nn.functional as F from torch.autograd import Variable import matplotlib.pyplot as plt x = torch.linspace(-5, 5, 200) x_variable = Variable(x) #将x放入Variable x_np = x_variable.data.numpy() # 经过4种不同的激励函数得到的numpy形式的数据结果 y_relu = F.relu(x_variable).data.numpy() y_sigmoid = F.sigmoid(x_variable).data.numpy() y_tanh = F.tanh(x_variable).data.numpy() y_softplus = F.softplus(x_variable).data.numpy() plt.figure(1, figsize=(8, 6)) plt.subplot(221) plt.plot(x_np, y_relu, c='red', label='relu') plt.ylim((-1, 5)) plt.legend(loc='best') plt.subplot(222) plt.plot(x_np, y_sigmoid, c='red', label='sigmoid') plt.ylim((-0.2, 1.2)) plt.legend(loc='best') plt.subplot(223) plt.plot(x_np, y_tanh, c='red', label='tanh') plt.ylim((-1.2, 1.2)) plt.legend(loc='best') plt.subplot(224) plt.plot(x_np, y_softplus, c='red', label='softplus') plt.ylim((-0.2, 6)) plt.legend(loc='best') plt.show()
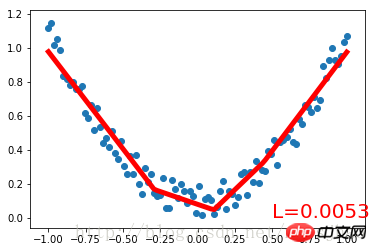
먼저 노이즈 집합을 만듭니다. 데이터를 2차 함수로 피팅하고 변수에 넣습니다. 신경망 구축을 위해 Net 클래스를 정의하고 torch.nn.Module 클래스를 상속합니다. 입력 뉴런, 은닉층 뉴런, 출력 뉴런의 수에 대한 매개변수는 Net 클래스의 구성 메소드에서 정의되며, Net 상위 클래스의 구성 메소드는 super() 메소드를 통해 얻어지며, 각각의 구조 형태는 다음과 같습니다. Net의 계층은 속성의 형태로 정의됩니다. 정의 Net의 전달() 메소드는 각 계층의 뉴런을 완전한 신경망 전달 경로로 구축합니다.
Net 클래스를 정의한 후 신경망 인스턴스를 정의합니다. Net 클래스 인스턴스는 신경망의 구조 정보를 직접 출력할 수 있습니다. 그런 다음 신경망의 최적화 프로그램과 손실 함수를 정의합니다. 이러한 사항이 정의되면 교육을 시작할 수 있습니다. Optimizer.zero_grad(), loss.backward(), Optimizer.step()은 각각 이전 단계의 업데이트 매개변수 값을 삭제하고, 오류의 역전파를 수행하여 새로운 업데이트 매개변수 값을 계산하고, 계산된 업데이트 값을 net.parameters(). 반복적인 훈련 과정을 반복합니다.실행 결과:
Net((숨김): 선형(1 -> 10)
(predict): Linear (10 -> 1)
)
三、PyTorch实现简单分类
完整代码:
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
# 生成数据
# 分别生成2组各100个数据点,增加正态噪声,后标记以y0=0 y1=1两类标签,最后cat连接到一起
n_data = torch.ones(100,2)
# torch.normal(means, std=1.0, out=None)
x0 = torch.normal(2*n_data, 1) # 以tensor的形式给出输出tensor各元素的均值,共享标准差
y0 = torch.zeros(100)
x1 = torch.normal(-2*n_data, 1)
y1 = torch.ones(100)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # 组装(连接)
y = torch.cat((y0, y1), 0).type(torch.LongTensor)
# 置入Variable中
x, y = Variable(x), Variable(y)
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.out = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.out(x)
return x
net = Net(n_feature=2, n_hidden=10, n_output=2)
print(net)
optimizer = torch.optim.SGD(net.parameters(), lr=0.012)
loss_func = torch.nn.CrossEntropyLoss()
plt.ion()
plt.show()
for t in range(100):
out = net(x)
loss = loss_func(out, y) # loss是定义为神经网络的输出与样本标签y的差别,故取softmax前的值
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 2 == 0:
plt.cla()
# 过了一道 softmax 的激励函数后的最大概率才是预测值
# torch.max既返回某个维度上的最大值,同时返回该最大值的索引值
prediction = torch.max(F.softmax(out), 1)[1] # 在第1维度取最大值并返回索引值
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
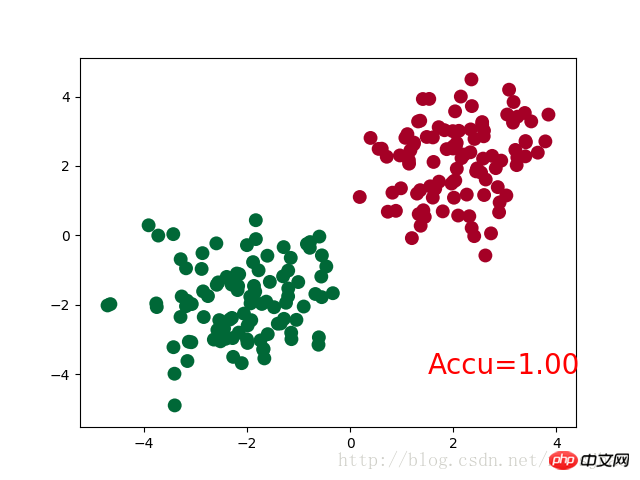
accuracy = sum(pred_y == target_y)/200 # 预测中有多少和真实值一样
plt.text(1.5, -4, 'Accu=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()神经网络结构部分的Net类与前文的回归部分的结构相同。
需要注意的是,在循环迭代训练部分,out定义为神经网络的输出结果,计算误差loss时不是使用one-hot形式的,loss是定义在out与y上的torch.nn.CrossEntropyLoss(),而预测值prediction定义为out经过Softmax后(将结果转化为概率值)的结果。
运行结果:
Net (
(hidden): Linear (2 -> 10)
(out):Linear (10 -> 2)
)
四、补充知识
1. super()函数
在定义Net类的构造方法的时候,使用了super(Net,self).__init__()语句,当前的类和对象作为super函数的参数使用,这条语句的功能是使Net类的构造方法获得其超类(父类)的构造方法,不影响对Net类单独定义构造方法,且不必关注Net类的父类到底是什么,若需要修改Net类的父类时只需修改class语句中的内容即可。
2. torch.normal()
torch.normal()可分为三种情况:(1)torch.normal(means,std, out=None)中means和std都是Tensor,两者的形状可以不必相同,但Tensor内的元素数量必须相同,一一对应的元素作为输出的各元素的均值和标准差;(2)torch.normal(mean=0.0, std, out=None)中mean是一个可定义的float,各个元素共享该均值;(3)torch.normal(means,std=1.0, out=None)中std是一个可定义的float,各个元素共享该标准差。
3. torch.cat(seq, dim=0)
torch.cat可以将若干个Tensor组装连接起来,dim指定在哪个维度上进行组装。
4. torch.max()
(1)torch.max(input)→ float
input是tensor,返回input中的最大值float。
(2)torch.max(input,dim, keepdim=True, max=None, max_indices=None) -> (Tensor, LongTensor)
同时返回指定维度=dim上的最大值和该最大值在该维度上的索引值。
相关推荐:
위 내용은 회귀 및 분류를 구현하기 위해 PyTorch에 간단한 신경망을 구축하는 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7454
7454
 15
1375
52
77
11
40
19
14
9
15
1375
52
77
11
40
19
14
9

 PyCharm과 PyTorch의 완벽한 조합: 자세한 설치 및 구성 단계
Feb 21, 2024 pm 12:00 PM
PyCharm과 PyTorch의 완벽한 조합: 자세한 설치 및 구성 단계
Feb 21, 2024 pm 12:00 PM
PyCharm은 강력한 통합 개발 환경(IDE)이고, PyTorch는 딥 러닝 분야에서 인기 있는 오픈 소스 프레임워크입니다. 머신러닝과 딥러닝 분야에서 PyCharm과 PyTorch를 개발에 활용하면 개발 효율성과 코드 품질을 크게 향상시킬 수 있습니다. 이 기사에서는 PyCharm에서 PyTorch를 설치 및 구성하는 방법을 자세히 소개하고 독자가 이 두 가지의 강력한 기능을 더 잘 활용할 수 있도록 특정 코드 예제를 첨부합니다. 1단계: PyCharm 및 Python 설치
 YOLO는 불멸이다! YOLOv9 출시: 성능과 속도 SOTA~
Feb 26, 2024 am 11:31 AM
YOLO는 불멸이다! YOLOv9 출시: 성능과 속도 SOTA~
Feb 26, 2024 am 11:31 AM
오늘날의 딥러닝 방법은 모델의 예측 결과가 실제 상황에 가장 가깝도록 가장 적합한 목적 함수를 설계하는 데 중점을 두고 있습니다. 동시에 예측을 위한 충분한 정보를 얻을 수 있도록 적합한 아키텍처를 설계해야 합니다. 기존 방법은 입력 데이터가 레이어별 특징 추출 및 공간 변환을 거치면 많은 양의 정보가 손실된다는 사실을 무시합니다. 이 글에서는 딥 네트워크를 통해 데이터를 전송할 때 중요한 문제, 즉 정보 병목 현상과 가역 기능을 살펴보겠습니다. 이를 바탕으로 다중 목표를 달성하기 위해 심층 네트워크에서 요구되는 다양한 변화에 대처하기 위해 PGI(Programmable Gradient Information) 개념을 제안합니다. PGI는 목적 함수를 계산하기 위해 대상 작업에 대한 완전한 입력 정보를 제공할 수 있으므로 네트워크 가중치를 업데이트하기 위한 신뢰할 수 있는 기울기 정보를 얻을 수 있습니다. 또한 새로운 경량 네트워크 프레임워크가 설계되었습니다.
 Huawei 휴대폰에서 이중 WeChat 로그인을 구현하는 방법은 무엇입니까?
Mar 24, 2024 am 11:27 AM
Huawei 휴대폰에서 이중 WeChat 로그인을 구현하는 방법은 무엇입니까?
Mar 24, 2024 am 11:27 AM
Huawei 휴대폰에서 이중 WeChat 로그인을 구현하는 방법은 무엇입니까? 소셜 미디어의 등장으로 WeChat은 사람들의 일상 생활에 없어서는 안될 커뮤니케이션 도구 중 하나가 되었습니다. 그러나 많은 사람들이 동일한 휴대폰에서 동시에 여러 WeChat 계정에 로그인하는 문제에 직면할 수 있습니다. Huawei 휴대폰 사용자의 경우 듀얼 WeChat 로그인을 달성하는 것은 어렵지 않습니다. 이 기사에서는 Huawei 휴대폰에서 듀얼 WeChat 로그인을 달성하는 방법을 소개합니다. 우선, 화웨이 휴대폰과 함께 제공되는 EMUI 시스템은 듀얼 애플리케이션 열기라는 매우 편리한 기능을 제공합니다. 앱 듀얼 오픈 기능을 통해 사용자는 동시에
 자연어 생성 작업의 5가지 샘플링 방법 및 Pytorch 코드 구현 소개
Feb 20, 2024 am 08:50 AM
자연어 생성 작업의 5가지 샘플링 방법 및 Pytorch 코드 구현 소개
Feb 20, 2024 am 08:50 AM
자연어 생성 작업에서 샘플링 방법은 생성 모델에서 텍스트 출력을 얻는 기술입니다. 이 기사에서는 5가지 일반적인 방법을 논의하고 PyTorch를 사용하여 구현합니다. 1. GreedyDecoding 그리디 디코딩에서는 생성 모델이 시간 단위로 입력 시퀀스를 기반으로 출력 시퀀스의 단어를 예측합니다. 각 시간 단계에서 모델은 각 단어의 조건부 확률 분포를 계산한 다음, 현재 시간 단계의 출력으로 조건부 확률이 가장 높은 단어를 선택합니다. 이 단어는 다음 시간 단계의 입력이 되며 지정된 길이의 시퀀스 또는 특수 종료 표시와 같은 일부 종료 조건이 충족될 때까지 생성 프로세스가 계속됩니다. GreedyDecoding의 특징은 매번 현재 조건부 확률이 가장 좋다는 것입니다.
 PyTorch와 함께 PyCharm을 설치하는 방법에 대한 튜토리얼
Feb 24, 2024 am 10:09 AM
PyTorch와 함께 PyCharm을 설치하는 방법에 대한 튜토리얼
Feb 24, 2024 am 10:09 AM
강력한 딥 러닝 프레임워크인 PyTorch는 다양한 머신 러닝 프로젝트에서 널리 사용됩니다. 강력한 Python 통합 개발 환경인 PyCharm은 딥 러닝 작업을 구현할 때에도 훌륭한 지원을 제공할 수 있습니다. 이 기사에서는 PyCharm에 PyTorch를 설치하는 방법을 자세히 소개하고 독자가 딥 러닝 작업에 PyTorch를 사용하여 빠르게 시작할 수 있도록 구체적인 코드 예제를 제공합니다. 1단계: PyCharm 설치 먼저 다음 사항을 확인해야 합니다.
 너무 빨라요! 10줄 미만의 코드로 단 몇 분 만에 비디오 음성을 텍스트로 인식합니다.
Feb 27, 2024 pm 01:55 PM
너무 빨라요! 10줄 미만의 코드로 단 몇 분 만에 비디오 음성을 텍스트로 인식합니다.
Feb 27, 2024 pm 01:55 PM
안녕하세요 여러분, 저는 Kite입니다. 2년 전에는 오디오 및 비디오 파일을 텍스트 콘텐츠로 변환하는 작업이 어려웠지만 이제는 단 몇 분만에 쉽게 해결할 수 있습니다. 훈련 데이터를 얻기 위해 일부 회사에서는 Douyin, Kuaishou 등 짧은 비디오 플랫폼에서 비디오를 완전히 크롤링한 다음 비디오에서 오디오를 추출하고 이를 텍스트 형식으로 변환하여 빅데이터 모델의 훈련 코퍼스로 사용했다고 합니다. . 비디오 또는 오디오 파일을 텍스트로 변환해야 하는 경우 현재 제공되는 이 오픈 소스 솔루션을 사용해 볼 수 있습니다. 예를 들어, 영화나 TV 프로그램의 대화가 나오는 특정 시점을 검색할 수 있습니다. 더 이상 고민하지 않고 요점을 살펴보겠습니다. Whisper는 OpenAI의 오픈 소스 Whisper입니다. 물론 Python으로 작성되었습니다. 몇 가지 간단한 설치 패키지만 있으면 됩니다.
 PHP 프로그래밍 가이드: 피보나치 수열을 구현하는 방법
Mar 20, 2024 pm 04:54 PM
PHP 프로그래밍 가이드: 피보나치 수열을 구현하는 방법
Mar 20, 2024 pm 04:54 PM
프로그래밍 언어 PHP는 다양한 프로그래밍 논리와 알고리즘을 지원할 수 있는 강력한 웹 개발 도구입니다. 그중 피보나치 수열을 구현하는 것은 일반적이고 고전적인 프로그래밍 문제입니다. 이 기사에서는 PHP 프로그래밍 언어를 사용하여 피보나치 수열을 구현하는 방법을 소개하고 구체적인 코드 예제를 첨부합니다. 피보나치 수열은 다음과 같이 정의되는 수학적 수열입니다. 수열의 첫 번째와 두 번째 요소는 1이고 세 번째 요소부터 시작하여 각 요소의 값은 이전 두 요소의 합과 같습니다. 시퀀스의 처음 몇 가지 요소
 1.3ms는 1.3ms가 걸립니다! Tsinghua의 최신 오픈 소스 모바일 신경망 아키텍처 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms는 1.3ms가 걸립니다! Tsinghua의 최신 오픈 소스 모바일 신경망 아키텍처 RepViT
Mar 11, 2024 pm 12:07 PM
논문 주소: https://arxiv.org/abs/2307.09283 코드 주소: https://github.com/THU-MIG/RepViTRepViT는 모바일 ViT 아키텍처에서 잘 작동하며 상당한 이점을 보여줍니다. 다음으로, 본 연구의 기여를 살펴보겠습니다. 기사에서는 경량 ViT가 일반적으로 시각적 작업에서 경량 CNN보다 더 나은 성능을 발휘한다고 언급했는데, 그 이유는 주로 모델이 전역 표현을 학습할 수 있는 MSHA(Multi-Head Self-Attention 모듈) 때문입니다. 그러나 경량 ViT와 경량 CNN 간의 아키텍처 차이점은 완전히 연구되지 않았습니다. 본 연구에서 저자는 경량 ViT를 효과적인
