
이 글은 주로 Python을 사용하여 MS Word를 처리하는 예제를 소개합니다. 이제 특정 참고 가치가 있습니다. 필요한 친구들이 참고할 수 있습니다.
MS Word 파일(docx 및 doc)을 읽고 쓸 수 있습니다. 파일), 주로 python-docx 패키지를 사용합니다. 이 문서에서는 일반적으로 사용되는 몇 가지 작업을 제공하고 빠르게 시작하는 데 도움이 되는 예제를 완성합니다.
Installation
pyhton은 pip 도구를 사용하여 쉽게 설치할 수 있는 docx 파일을 처리하기 위해 python-docx 패키지를 사용해야 합니다. pip 도구는 python 설치 경로
pip install python-docx
물론 easy_install 또는 수동 설치를 선택할 수도 있습니다
파일 내용 쓰기
여기에서는 필요에 따라 유용한 콘텐츠를 추출하기 위해 직접 샘플을 제공합니다
#coding=utf-8 from docx import Document from docx.shared import Pt from docx.shared import Inches from docx.oxml.ns import qn #打开文档 document = Document() #加入不同等级的标题 document.add_heading(u'MS WORD写入测试',0) document.add_heading(u'一级标题',1) document.add_heading(u'二级标题',2) #添加文本 paragraph = document.add_paragraph(u'我们在做文本测试!') #设置字号 run = paragraph.add_run(u'设置字号、') run.font.size = Pt(24) #设置字体 run = paragraph.add_run('Set Font,') run.font.name = 'Consolas' #设置中文字体 run = paragraph.add_run(u'设置中文字体、') run.font.name=u'宋体' r = run._element r.rPr.rFonts.set(qn('w:eastAsia'), u'宋体') #设置斜体 run = paragraph.add_run(u'斜体、') run.italic = True #设置粗体 run = paragraph.add_run(u'粗体').bold = True #增加引用 document.add_paragraph('Intense quote', style='Intense Quote') #增加无序列表 document.add_paragraph( u'无序列表元素1', style='List Bullet' ) document.add_paragraph( u'无序列表元素2', style='List Bullet' ) #增加有序列表 document.add_paragraph( u'有序列表元素1', style='List Number' ) document.add_paragraph( u'有序列表元素2', style='List Number' ) #增加图像(此处用到图像image.bmp,请自行添加脚本所在目录中) document.add_picture('image.bmp', width=Inches(1.25)) #增加表格 table = document.add_table(rows=1, cols=3) hdr_cells = table.rows[0].cells hdr_cells[0].text = 'Name' hdr_cells[1].text = 'Id' hdr_cells[2].text = 'Desc' #再增加3行表格元素 for i in xrange(3): row_cells = table.add_row().cells row_cells[0].text = 'test'+str(i) row_cells[1].text = str(i) row_cells[2].text = 'desc'+str(i) #增加分页 document.add_page_break() #保存文件 document.save(u'测试.docx')
코드 조각에 의해 생성된 문서 스타일은 다음과 같습니다

Note: 테이블의 경계선 설정 방법에 대한 해결책을 찾지 못한 문제가 있습니다. 아시는 분 조언 좀 부탁드리겠습니다.
파일 내용 읽기
#coding=utf-8 from docx import Document #打开文档 document = Document(u'测试.docx') #读取每段资料 l = [ paragraph.text.encode('gb2312') for paragraph in document.paragraphs]; #输出并观察结果,也可以通过其他手段处理文本即可 for i in l: print i #读取表格材料,并输出结果 tables = [table for table in document.tables]; for table in tables: for row in table.rows: for cell in row.cells: print cell.text.encode('gb2312'),'\t', print print '\n'
방금 생성한 파일을 계속 사용하고 있습니다. 출력 결과는
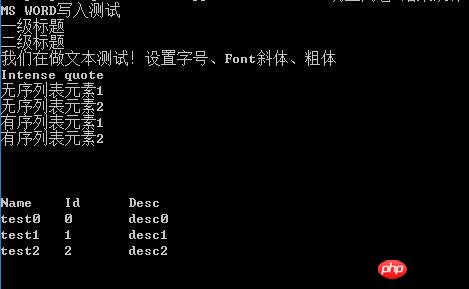
참고: 여기서는 gb2312를 사용합니다. 독서 인코딩 모드의 주요 목적은 중국어의 올바른 읽기 및 쓰기를 보장하는 것입니다. 일반적으로 UTF-8 인코딩이 사용됩니다. 또한 python-docx는 주로 docx 파일을 처리하므로 doc 파일을 로드할 때 문제가 발생할 수 있습니다. doc 파일이 많은 경우 doc2doc
도구를 사용하는 등 먼저 doc 파일을 docx 파일로 일괄 변환하는 것이 좋습니다.관련 추천 :
Python 처리 csv 파일 예제에 대한 자세한 설명
위 내용은 Python을 사용하여 MS Word를 처리하는 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



