

Node 정적 자원 서버 운영 방법
이번에는 Node 정적 리소스 서버 운영 방법과 Node 정적 리소스 서버 운영 시 주의사항은 무엇인지 알려드리겠습니다. 다음은 실제 사례로 살펴보겠습니다.
http 서버는 tcp 서버에서 상속됩니다. http 프로토콜은 TCP를 기반으로 하는 애플리케이션 계층 프로토콜입니다.
http의 원리는 클라이언트가 연결되면 연결 이벤트가 먼저 발생하는 것입니다. 그런 다음 요청을 여러 번 보낼 수 있습니다. 각 요청은 요청 이벤트를 트리거합니다.
let server = http.createServer();
let url = require('url');
server.on('connection', function (socket) {
console.log('客户端连接 ');
});
server.on('request', function (req, res) {
let { pathname, query } = url.parse(req.url, true);
let result = [];
req.on('data', function (data) {
result.push(data);
});
req.on('end', function () {
let r = Buffer.concat(result);
res.end(r);
})
});
server.on('close', function (req, res) {
console.log('服务器关闭 ');
});
server.on('error', function (err) {
console.log('服务器错误 ');
});
server.listen(8080, function () {
console.log('server started at http://localhost:8080');
});req는 클라이언트의 연결을 나타내고 서버는 클라이언트의 요청 정보를 구문 분석한 다음 이를 req
res에 넣습니다. 응답을 클라이언트에 보내려면 메시지에 응답하려면 res
req와 res를 모두 소켓에서 먼저 전달해야 하며, 그런 다음 이벤트가 발생하면 수신해야 합니다. 요청 객체를 생성한 다음 요청 객체를 기반으로 응답 객체를 생성합니다
req.url 요청 경로 가져오기
req.headers 요청 헤더 객체
다음으로 몇 가지 핵심 기능에 대해 설명하겠습니다.
압축과 압축 풀기를 깊이 이해하고 구현합니다.
왜 압축해야 할까요?
압축 및 압축 해제에 zlib 모듈을 사용할 수 있습니다. 파일을 압축한 후 크기를 줄이고 전송 속도를 높이며 대역폭 코드를 절약할 수 있습니다.
압축 및 압축 해제 개체는 모두 변환 변환 스트림입니다. , 이중 이중 스트림에서 상속됩니다. 즉, 읽고 쓸 수 있는 스트림
zlib.createGzip: Gzip 스트림 객체를 반환하고 Gzip 알고리즘을 사용하여 데이터를 압축합니다.
zlib.createGunzip: Gzip 스트림 객체를 반환합니다. Gzip 알고리즘을 사용하여 압축된 데이터의 압축을 풉니다. 데이터 압축 해제 알고리즘
- 구현 압축 및 압축 해제
-
압축된 파일은 크거나 작을 수 있으므로 처리 속도를 향상시키기 위해 스트림을 사용하여 달성합니다
let fs = require("fs"); let path = require("path"); let zlib = require("zlib"); function gzip(src) { fs .createReadStream(src) .pipe(zlib.createGzip()) .pipe(fs.createWriteStream(src + ".gz")); } gzip(path.join(dirname,'msg.txt')); function gunzip(src) { fs .createReadStream(src) .pipe(zlib.createGunzip()) .pipe( fs.createWriteStream(path.join(dirname, path.basename(src, ".gz"))) ); } gunzip(path.join(dirname, "msg.txt.gz"));로그인 후 복사
gzip 방법은 압축을 구현하는 데 사용
gunzip 방법은 압축 해제를 구현하는 데 사용됩니다
msg.txt 파일은 형제 디렉터리입니다
왜 이렇게 작성해야 합니까: gzip(path.join(dirname,') msg.txt'));
console.log(process.cwd ()); 때문에 현재 작업 디렉터리는 파일이 있는 디렉터리가 아니라 루트 디렉터리임을 출력합니다. gzip(' msg.txt'); 파일을 찾을 수 없으면 오류가 보고됩니다
basename 확장자를 포함하여 경로에서 파일 이름을 가져오세요. 확장자 매개변수를 전달하여 확장자
extname을 제거할 수 있습니다. 확장자를 얻으려면
압축 형식과 압축 해제 형식이 일치해야 합니다. 그렇지 않으면 오류가 보고됩니다
-
가끔 얻은 문자열이 스트림이 아니므로 해결 방법
let zlib=require('zlib'); let str='hello'; zlib.gzip(str,(err,buffer)=>{ console.log(buffer.length); zlib.unzip(buffer,(err,data)=>{ console.log(data.toString()); }) });로그인 후 복사가능합니다 압축된 내용이 원본보다 크면 압축이 의미가 없습니다 규칙이 있기 때문에 텍스트 압축의 효과가 더 좋습니다.
http에서 압축 및 압축 해제를 적용합니다
다음은 이러한 것을 구현합니다.
클라이언트가 서버에 요청을 시작하면 accept-encoding을 전달합니다(예: Accept-Encoding: gzip, 기본값). 내가 지원하는 압축 해제 형식을 서버에 알려줍니다서버는 Accept-Encoding으로 표시되는 형식에 따라 압축해야 합니다. 형식이 없으면 브라우저에서 압축을 풀 수 없으므로 압축할 수 없습니다.
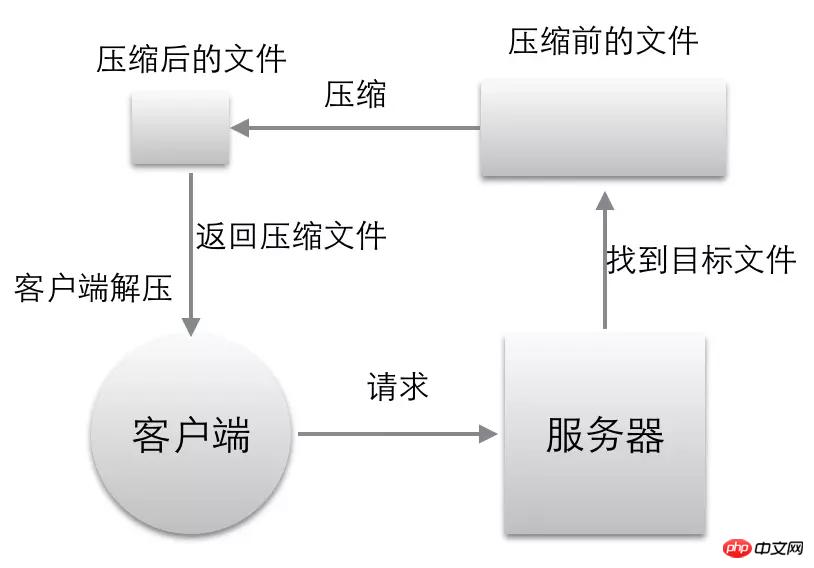
클라이언트에서 Accept-Encoding이 필요한 경우 형식 서버에는 없습니다. 압축을 구현할 수 없습니다
-
let http = require("http"); let path = require("path"); let url = require("url"); let zlib = require("zlib"); let fs = require("fs"); let { promisify } = require("util"); let mime = require("mime"); //把一个异步方法转成一个返回promise的方法 let stat = promisify(fs.stat); http.createServer(request).listen(8080); async function request(req, res) { let { pathname } = url.parse(req.url); let filepath = path.join(dirname, pathname); // fs.stat(filepath,(err,stat)=>{});现在不这么写了,异步的处理起来比较麻烦 try { let statObj = await stat(filepath); res.setHeader("Content-Type", mime.getType(pathname)); let acceptEncoding = req.headers["accept-encoding"]; if (acceptEncoding) { if (acceptEncoding.match(/\bgzip\b/)) { res.setHeader("Content-Encoding", "gzip"); fs .createReadStream(filepath) .pipe(zlib.createGzip()) .pipe(res); } else if (acceptEncoding.match(/\bdeflate\b/)) { res.setHeader("Content-Encoding", "deflate"); fs .createReadStream(filepath) .pipe(zlib.createDeflate()) .pipe(res); } else { fs.createReadStream(filepath).pipe(res); } } else { fs.createReadStream(filepath).pipe(res); } } catch (e) { res.statusCode = 404; res.end("Not Found"); } }로그인 후 복사mime: 파일 이름과 경로를 통해 파일의 콘텐츠 유형을 가져오고 다양한 파일 콘텐츠 유형에 따라 다양한 콘텐츠 유형을 반환할 수 있습니다 acceptEncoding:全部写成小写是为了兼容不同的浏览器,node把所有的请求头全转成了小写
filepath:得到文件的绝对路径
启动服务后,访问http://localhost:8080/msg.txt 可看到结果
深刻理解并实现缓存
为什么要缓存呢,缓存有什么好处?
减少了冗余的数据传输,节省了网费。
减少了服务器的负担, 大大提高了网站的性能
加快了客户端加载网页的速度
缓存的分类
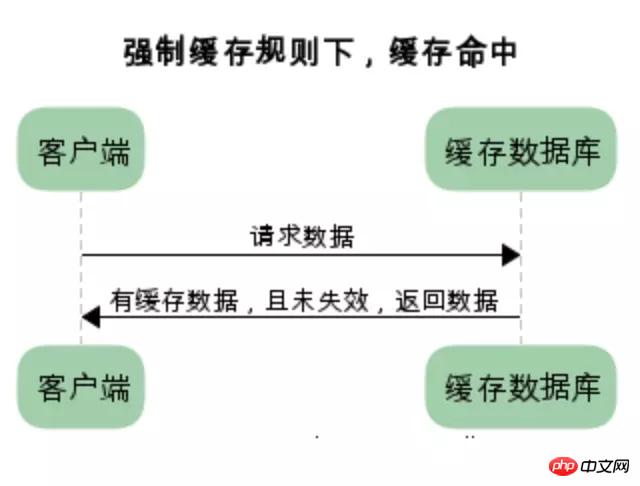
强制缓存:
强制缓存,在缓存数据未失效的情况下,可以直接使用缓存数据
在没有缓存数据的时候,浏览器向服务器请求数据时,服务器会将数据和缓存规则一并返回,缓存规则信息包含在响应header中
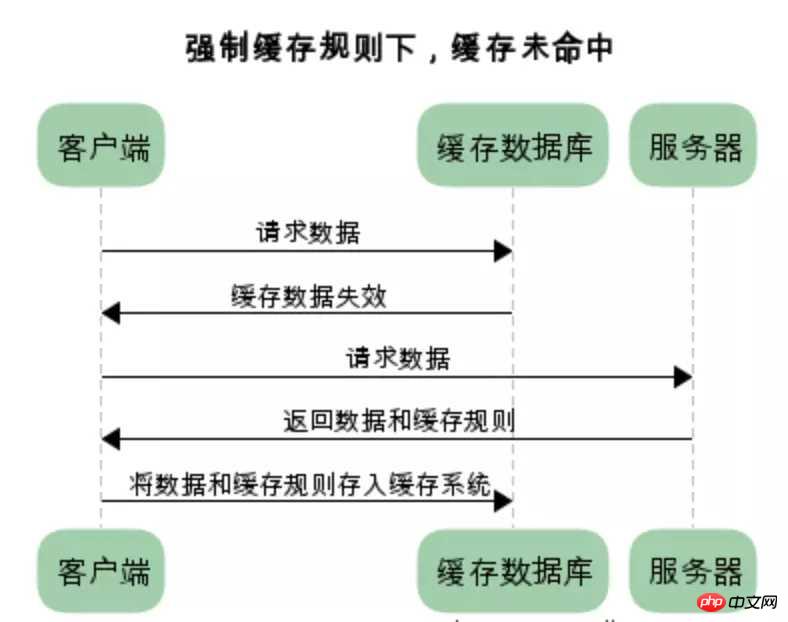
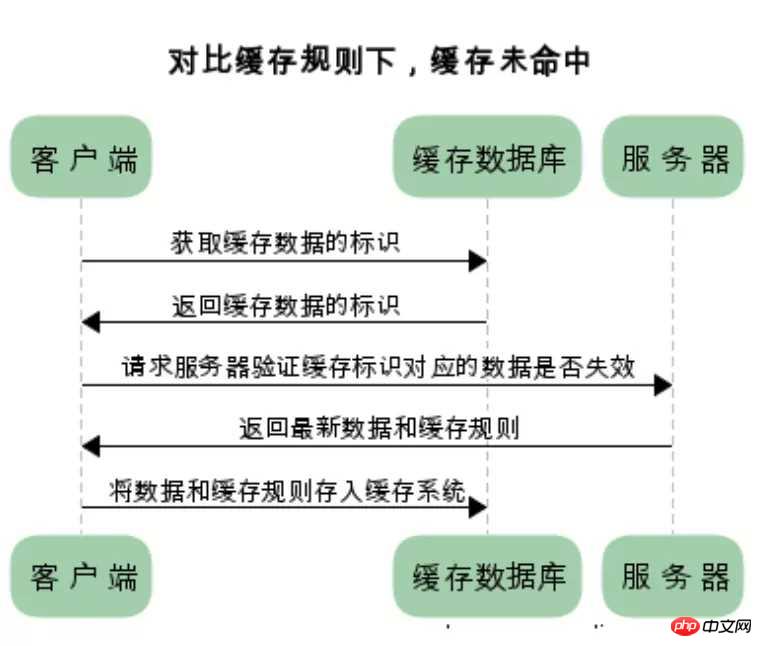
对比缓存:
浏览器第一次请求数据时,服务器会将缓存标识与数据一起返回给客户端,客户端将二者备份至缓存数据库中
再次请求数据时,客户端将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回304状态码,通知客户端比较成功,可以使用缓存数据
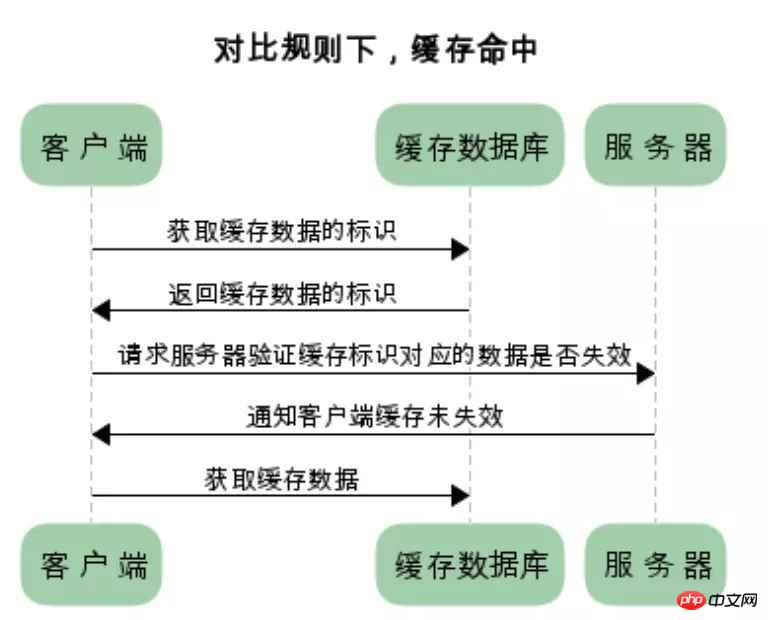
两类缓存的区别和联系
强制缓存如果生效,不需要再和服务器发生交互,而对比缓存不管是否生效,都需要与服务端发生交互
两类缓存规则可以同时存在,强制缓存优先级高于对比缓存,也就是说,当执行强制缓存的规则时,如果缓存生效,直接使用缓存,不再执行对比缓存规则
实现对比缓存
实现对比缓存一般是按照以下步骤:
第一次访问服务器的时候,服务器返回资源和缓存的标识,客户端则会把此资源缓存在本地的缓存数据库中。
第二次客户端需要此数据的时候,要取得缓存的标识,然后去问一下服务器我的资源是否是最新的。
如果是最新的则直接使用缓存数据,如果不是最新的则服务器返回新的资源和缓存规则,客户端根据缓存规则缓存新的数据
实现对比缓存一般有两种方式
通过最后修改时间来判断缓存是否可用
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
// http://localhost:8080/index.html
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
//D:\vipcode\201801\20.cache\index.html
let filepath = path.join(dirname, pathname);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
let ifModifiedSince = req.headers['if-modified-since'];
let LastModified = stat.ctime.toGMTString();
if (ifModifiedSince == LastModified) {
res.writeHead(304);
res.end('');
} else {
return send(req, res, filepath, stat);
}
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath, stat) {
res.setHeader('Content-Type', mime.getType(filepath));
//发给客户端之后,客户端会把此时间保存起来,下次再获取此资源的时候会把这个时间再发回服务器
res.setHeader('Last-Modified', stat.ctime.toGMTString());
fs.createReadStream(filepath).pipe(res);
}这种方式有很多缺陷
某些服务器不能精确得到文件的最后修改时间, 这样就无法通过最后修改时间来判断文件是否更新了
某些文件的修改非常频繁,在秒以下的时间内进行修改.Last-Modified只能精确到秒。
一些文件的最后修改时间改变了,但是内容并未改变。 我们不希望客户端认为这个文件修改了
如果同样的一个文件位于多个CDN服务器上的时候内容虽然一样,修改时间不一样
ETag
ETag是根据实体内容生成的一段hash字符串,可以标识资源的状态
资源发生改变时,ETag也随之发生变化。 ETag是Web服务端产生的,然后发给浏览器客户端
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
let crypto = require('crypto');
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
let filepath = path.join(dirname, pathname);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
let ifNoneMatch = req.headers['if-none-match'];
let out = fs.createReadStream(filepath);
let md5 = crypto.createHash('md5');
out.on('data', function (data) {
md5.update(data);
});
out.on('end', function () {
let etag = md5.digest('hex');
let etag = `${stat.size}`;
if (ifNoneMatch == etag) {
res.writeHead(304);
res.end('');
} else {
return send(req, res, filepath, etag);
}
});
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath, etag) {
res.setHeader('Content-Type', mime.getType(filepath));
res.setHeader('ETag', etag);
fs.createReadStream(filepath).pipe(res);
}客户端想判断缓存是否可用可以先获取缓存中文档的ETag,然后通过If-None-Match发送请求给Web服务器询问此缓存是否可用。
服务器收到请求,将服务器的中此文件的ETag,跟请求头中的If-None-Match相比较,如果值是一样的,说明缓存还是最新的,Web服务器将发送304 Not Modified响应码给客户端表示缓存未修改过,可以使用。
如果不一样则Web服务器将发送该文档的最新版本给浏览器客户端
实现强制缓存
把资源缓存在客户端,如果客户端再次需要此资源的时候,先获取到缓存中的数据,看是否过期,如果过期了。再请求服务器
如果没过期,则根本不需要向服务器确认,直接使用本地缓存即可
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
let crypto = require('crypto');
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
let filepath = path.join(dirname, pathname);
console.log(filepath);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
send(req, res, filepath);
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath) {
res.setHeader('Content-Type', mime.getType(filepath));
res.setHeader('Expires', new Date(Date.now() + 30 * 1000).toUTCString());
res.setHeader('Cache-Control', 'max-age=30');
fs.createReadStream(filepath).pipe(res);
}浏览器会将文件缓存到Cache目录,第二次请求时浏览器会先检查Cache目录下是否含有该文件,如果有,并且还没到Expires设置的时间,即文件还没有过期,那么此时浏览器将直接从Cache目录中读取文件,而不再发送请求
Expires是服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据
Cache-Control与Expires的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据,如果同时设置的话,其优先级高于Expires
下面开始写静态服务器
首先创建一个http服务,配置监听端口
let http = require('http');
let server = http.createServer();
server.on('request', this.request.bind(this));
server.listen(this.config.port, () => {
let url = `http://${this.config.host}:${this.config.port}`;
debug(`server started at ${chalk.green(url)}`);
});下面写个静态文件服务器
先取到客户端想说的文件或文件夹路径,如果是目录的话,应该显示目录下面的文件列表
async request(req, res) {
let { pathname } = url.parse(req.url);
if (pathname == '/favicon.ico') {
return this.sendError('not found', req, res);
}
let filepath = path.join(this.config.root, pathname);
try {
let statObj = await stat(filepath);
if (statObj.isDirectory()) {
let files = await readdir(filepath);
files = files.map(file => ({
name: file,
url: path.join(pathname, file)
}));
let html = this.list({
title: pathname,
files
});
res.setHeader('Content-Type', 'text/html');
res.end(html);
} else {
this.sendFile(req, res, filepath, statObj);
}
} catch (e) {
debug(inspect(e));
this.sendError(e, req, res);
}
}
sendFile(req, res, filepath, statObj) {
if (this.handleCache(req, res, filepath, statObj)) return;
res.setHeader('Content-Type', mime.getType(filepath) + ';charset=utf-8');
let encoding = this.getEncoding(req, res);
let rs = this.getStream(req, res, filepath, statObj);
if (encoding) {
rs.pipe(encoding).pipe(res);
} else {
rs.pipe(res);
}
}支持断点续传
getStream(req, res, filepath, statObj) {
let start = 0;
let end = statObj.size - 1;
let range = req.headers['range'];
if (range) {
res.setHeader('Accept-Range', 'bytes');
res.statusCode = 206;
let result = range.match(/bytes=(\d*)-(\d*)/);
if (result) {
start = isNaN(result[1]) ? start : parseInt(result[1]);
end = isNaN(result[2]) ? end : parseInt(result[2]) - 1;
}
}
return fs.createReadStream(filepath, {
start, end
});
}支持对比缓存,通过etag的方式
handleCache(req, res, filepath, statObj) {
let ifModifiedSince = req.headers['if-modified-since'];
let isNoneMatch = req.headers['is-none-match'];
res.setHeader('Cache-Control', 'private,max-age=30');
res.setHeader('Expires', new Date(Date.now() + 30 * 1000).toGMTString());
let etag = statObj.size;
let lastModified = statObj.ctime.toGMTString();
res.setHeader('ETag', etag);
res.setHeader('Last-Modified', lastModified);
if (isNoneMatch && isNoneMatch != etag) {
return fasle;
}
if (ifModifiedSince && ifModifiedSince != lastModified) {
return fasle;
}
if (isNoneMatch || ifModifiedSince) {
res.writeHead(304);
res.end();
return true;
} else {
return false;
}
}支持文件压缩
getEncoding(req, res) {
let acceptEncoding = req.headers['accept-encoding'];
if (/\bgzip\b/.test(acceptEncoding)) {
res.setHeader('Content-Encoding', 'gzip');
return zlib.createGzip();
} else if (/\bdeflate\b/.test(acceptEncoding)) {
res.setHeader('Content-Encoding', 'deflate');
return zlib.createDeflate();
} else {
return null;
}
}编译模板,得到一个渲染的方法,然后传入实际数据数据就可以得到渲染后的HTML了
function list() {
let tmpl = fs.readFileSync(path.resolve(dirname, 'template', 'list.html'), 'utf8');
return handlebars.compile(tmpl);
}这样一个简单的静态服务器就完成了,其中包含了静态文件服务,实现缓存,实现断点续传,分块获取,实现压缩的功能
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
위 내용은 Node 정적 자원 서버 운영 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7569
7569
 15
1386
52
87
11
61
19
28
107
15
1386
52
87
11
61
19
28
107

 nvm에서 노드를 삭제하는 방법
Dec 29, 2022 am 10:07 AM
nvm에서 노드를 삭제하는 방법
Dec 29, 2022 am 10:07 AM
nvm을 사용하여 노드를 삭제하는 방법: 1. "nvm-setup.zip"을 다운로드하여 C 드라이브에 설치합니다. 2. "nvm -v" 명령을 통해 환경 변수를 구성하고 버전 번호를 확인합니다. install" 명령 노드 설치; 4. "nvm uninstall" 명령을 통해 설치된 노드를 삭제합니다.
 Express를 사용하여 노드 프로젝트에서 파일 업로드를 처리하는 방법
Mar 28, 2023 pm 07:28 PM
Express를 사용하여 노드 프로젝트에서 파일 업로드를 처리하는 방법
Mar 28, 2023 pm 07:28 PM
파일 업로드를 처리하는 방법은 무엇입니까? 다음 글에서는 Express를 사용하여 노드 프로젝트에서 파일 업로드를 처리하는 방법을 소개하겠습니다. 도움이 되길 바랍니다.
 115 네트워크 디스크에서 리소스를 찾는 방법
Feb 23, 2024 pm 05:10 PM
115 네트워크 디스크에서 리소스를 찾는 방법
Feb 23, 2024 pm 05:10 PM
115 네트워크 디스크에는 많은 리소스가 있을 것인데 리소스를 찾는 방법은 무엇입니까? 사용자는 소프트웨어에서 필요한 리소스를 검색한 다음 다운로드 인터페이스로 들어간 다음 네트워크 디스크에 저장하도록 선택할 수 있습니다. 115 네트워크 디스크에서 리소스를 찾는 방법에 대한 이 소개는 구체적인 내용을 알려줄 수 있습니다. 다음은 자세한 소개입니다. 와서 살펴보세요. 115 네트워크 디스크에서 리소스를 찾는 방법 답변: 소프트웨어에서 콘텐츠를 검색한 다음 클릭하여 네트워크 디스크에 저장합니다. 자세한 소개: 1. 먼저 앱에서 원하는 리소스를 입력하세요. 2. 그러면 나타나는 키워드 링크를 클릭하세요. 3. 그런 다음 다운로드 인터페이스로 들어갑니다. 4. 내부 네트워크 디스크에 저장을 클릭합니다.
 Node의 프로세스 관리 도구 'pm2”에 대한 심층 분석
Apr 03, 2023 pm 06:02 PM
Node의 프로세스 관리 도구 'pm2”에 대한 심층 분석
Apr 03, 2023 pm 06:02 PM
이 기사에서는 Node의 프로세스 관리 도구인 "pm2"를 공유하고 pm2가 필요한 이유, pm2 설치 및 사용 방법에 대해 설명합니다. 모두에게 도움이 되기를 바랍니다!
 PI 노드 교육 : PI 노드 란 무엇입니까? Pi 노드를 설치하고 설정하는 방법은 무엇입니까?
Mar 05, 2025 pm 05:57 PM
PI 노드 교육 : PI 노드 란 무엇입니까? Pi 노드를 설치하고 설정하는 방법은 무엇입니까?
Mar 05, 2025 pm 05:57 PM
Pinetwork 노드에 대한 자세한 설명 및 설치 안내서이 기사에서는 Pinetwork Ecosystem을 자세히 소개합니다. Pi 노드, Pinetwork 생태계의 주요 역할을 수행하고 설치 및 구성을위한 전체 단계를 제공합니다. Pinetwork 블록 체인 테스트 네트워크가 출시 된 후, PI 노드는 다가오는 주요 네트워크 릴리스를 준비하여 테스트에 적극적으로 참여하는 많은 개척자들의 중요한 부분이되었습니다. 아직 Pinetwork를 모른다면 Picoin이 무엇인지 참조하십시오. 리스팅 가격은 얼마입니까? PI 사용, 광업 및 보안 분석. Pinetwork 란 무엇입니까? Pinetwork 프로젝트는 2019 년에 시작되었으며 독점적 인 Cryptocurrency Pi Coin을 소유하고 있습니다. 이 프로젝트는 모든 사람이 참여할 수있는 사람을 만드는 것을 목표로합니다.
 Han Xiaoquan은 왜 갑자기 자원이 없습니까?
Feb 24, 2024 pm 03:22 PM
Han Xiaoquan은 왜 갑자기 자원이 없습니까?
Feb 24, 2024 pm 03:22 PM
한샤오취안은 한국 드라마를 많이 볼 수 있는 소프트웨어인데 왜 갑자기 리소스가 없나요? 이 소프트웨어는 네트워크 문제, 버전 문제 또는 저작권 문제로 인해 리소스가 없을 수 있습니다. Han Xiaoquan이 갑자기 자원이 없는 이유에 대한 이 기사는 구체적인 내용을 알려줄 수 있습니다. 다음은 자세한 소개입니다. 와서 살펴보세요. Han Xiaoquan에 갑자기 리소스가 없는 이유는 무엇입니까? 답변: 네트워크 문제, 버전 문제 및 저작권 문제로 인해 자세한 소개: 1. 네트워크 문제 해결 방법: 다른 네트워크를 선택한 다음 소프트웨어에 다시 로그인하여 시도해 볼 수 있습니다. . 2. 버전 문제 해결: 사용자는 공식 웹사이트에서 이 소프트웨어의 최신 버전을 다운로드할 수 있습니다. 3. 저작권 문제 해결: 저작권 문제로 인해 일부 한국 드라마가 목록에서 제거되었습니다. 다른 한국 드라마를 선택하여 시청할 수 있습니다.
 npm node gyp가 실패하는 경우 수행할 작업
Dec 29, 2022 pm 02:42 PM
npm node gyp가 실패하는 경우 수행할 작업
Dec 29, 2022 pm 02:42 PM
"node-gyp.js"와 "Node.js"의 버전이 일치하지 않아 npm node gyp가 실패했습니다. 해결 방법: 1. "npm 캐시 clean -f"를 통해 노드 캐시를 지웁니다. 2. "npm install - g n" n 모듈을 설치합니다. 3. "n v12.21.0" 명령을 통해 "node v12.21.0" 버전을 설치합니다.
 Angular 및 Node를 사용한 토큰 기반 인증
Sep 01, 2023 pm 02:01 PM
Angular 및 Node를 사용한 토큰 기반 인증
Sep 01, 2023 pm 02:01 PM
인증은 모든 웹 애플리케이션에서 가장 중요한 부분 중 하나입니다. 이 튜토리얼에서는 토큰 기반 인증 시스템과 기존 로그인 시스템과의 차이점에 대해 설명합니다. 이 튜토리얼이 끝나면 Angular와 Node.js로 작성된 완벽하게 작동하는 데모를 볼 수 있습니다. 기존 인증 시스템 토큰 기반 인증 시스템으로 넘어가기 전에 기존 인증 시스템을 살펴보겠습니다. 사용자는 로그인 양식에 사용자 이름과 비밀번호를 입력하고 로그인을 클릭합니다. 요청한 후 데이터베이스를 쿼리하여 백엔드에서 사용자를 인증합니다. 요청이 유효하면 데이터베이스에서 얻은 사용자 정보를 이용하여 세션을 생성하고, 세션 정보를 응답 헤더에 반환하여 브라우저에 세션 ID를 저장한다. 다음과 같은 애플리케이션에 대한 액세스를 제공합니다.
