이 글은 nodejs 크롤러의 초기 시험을 위한 superagent와 Cherio에 관련된 지식을 주로 소개하고 있습니다. 매우 훌륭하고 참고할만한 가치가 있습니다. 도움이 필요한 친구들이 참고할 수 있습니다.
서문
크롤러에 대해 들어본 적이 있습니다. 지난 며칠간부터 오랫동안 nodejs를 배우고 크롤러 https://github.com/leichangchun/node-crawlers/tree/master/superagent_cheerio_demo를 작성하여 기사 제목, 사용자 이름, 읽은 횟수, 숫자를 크롤링합니다. 블로그 파크 홈페이지의 추천 및 사용자 아바타에 대한 간략한 요약이 완료되었습니다.
다음 사항을 사용하세요.
1. 노드의 핵심 모듈 - 파일 시스템
2. http 요청을 위한 타사 모듈 - superagent
3. DOM 구문 분석을 위한 타사 모듈 -cherio
가세요 여러 모듈에 대한 자세한 설명과 API를 보려면 각 링크를 참조하세요. 데모에는 간단한 사용법만 나와 있습니다.
준비
npm을 사용하여 종속성을 관리하면 종속성 정보가 package.json
//安装用到的第三方模块 cnpm install --save superagent cheerio
//引入第三方模块,superagent用于http请求,cheerio用于解析DOM const request = require('superagent'); const cheerio = require('cheerio'); const fs = require('fs');
request.get(url)
.end(error,res){
//do something
}//目标链接 博客园首页
let targetUrl = 'https://www.cnblogs.com/';
//用来暂时保存解析到的内容和图片地址数据
let content = '';
let imgs = [];
//发起请求
request.get(targetUrl)
.end( (error,res) => {
if(error){ //请求出错,打印错误,返回
console.log(error)
return;
}
// cheerio需要先load html
let $ = cheerio.load(res.text);
//抓取需要的数据,each为cheerio提供的方法用来遍历
$('#post_list .post_item').each( (index,element) => {
//分析所需要的数据的DOM结构
//通过选择器定位到目标元素,再获取到数据
let temp = {
'标题' : $(element).find('h3 a').text(),
'作者' : $(element).find('.post_item_foot > a').text(),
'阅读数' : +$(element).find('.article_view a').text().slice(3,-2),
'推荐数' : +$(element).find('.diggnum').text()
}
//拼接数据
content += JSON.stringify(temp) + '\n';
//同样的方式获取图片地址
if($(element).find('img.pfs').length > 0){
imgs.push($(element).find('img.pfs').attr('src'));
}
});
//存放数据
mkdir('./content',saveContent);
mkdir('./imgs',downloadImg);
})//创建目录
function mkdir(_path,callback){
if(fs.existsSync(_path)){
console.log(`${_path}目录已存在`)
}else{
fs.mkdir(_path,(error)=>{
if(error){
return console.log(`创建${_path}目录失败`);
}
console.log(`创建${_path}目录成功`)
})
}
callback(); //没有生成指定目录不会执行
}//将文字内容存入txt文件中
function saveContent() {
fs.writeFile('./content/content.txt',content.toString());
}//下载爬到的图片
function downloadImg() {
imgs.forEach((imgUrl,index) => {
//获取图片名
let imgName = imgUrl.split('/').pop();
//下载图片存放到指定目录
let stream = fs.createWriteStream(`./imgs/${imgName}`);
let req = request.get('https:' + imgUrl); //响应流
req.pipe(stream);
console.log(`开始下载图片 https:${imgUrl} --> ./imgs/${imgName}`);
} )
}rrreee
Effect에 직접 쓸 수 있습니다. 데모를 실행하고 효과를 확인하면 데이터가 정상적으로 내려갔습니다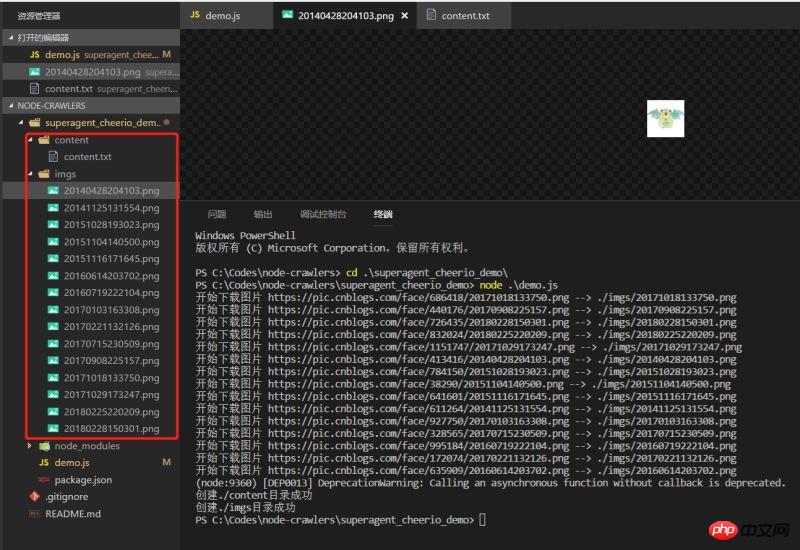
Vue는 이미지를 데이터베이스에 업로드하고 페이지에 표시하는 기능 예제
🎜위 내용은 nodejs 크롤러를 사용하여 superagent 및 Cherio를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



