

Python 시뮬레이션 로그인의 다양한 방법

이 글에서는 주로 다양한 Python 시뮬레이션 로그인 방법을 소개합니다. 각 방법에 대해 자세히 소개합니다. 관심 있는 친구들은 함께 살펴보세요
Text
방법 1: 알려진 쿠키를 직접 사용하여
에 액세스합니다. 기능:
간단하지만 먼저 브라우저에 로그인해야 합니다.
원리:
간단히 말하면, 쿠키는 요청을 시작하는 클라이언트에 저장됩니다. 서버는 쿠키를 사용하여 다양한 클라이언트를 구별합니다. HTTP는 상태 비저장 연결이기 때문에 서버가 한 번에 여러 요청을 받으면 동일한 클라이언트가 어떤 요청을 시작했는지 확인할 수 없습니다. "로그인해야만 볼 수 있는 페이지에 접근하는 것"의 행위는 클라이언트가 서버에 "나는 방금 로그인한 클라이언트입니다."라는 것을 증명해야 합니다. 따라서 클라이언트를 식별하고 해당 정보(예: 로그인 상태)를 저장하려면 쿠키가 필요합니다.
물론 이는 다른 클라이언트의 쿠키를 얻는 한 서버와 대화하기 위해 그 쿠키를 가장할 수 있다는 의미이기도 합니다. 이것은 우리 프로그램에 기회를 제공합니다.
먼저 브라우저로 로그인한 후 개발자 도구를 사용하여 쿠키를 확인합니다. 그런 다음 프로그램에 쿠키를 담아 웹사이트에 요청을 보내면 귀하의 프로그램이 방금 로그인한 브라우저인 것처럼 가장하여 로그인한 후에만 볼 수 있는 페이지를 가져올 수 있습니다.
구체적인 단계:
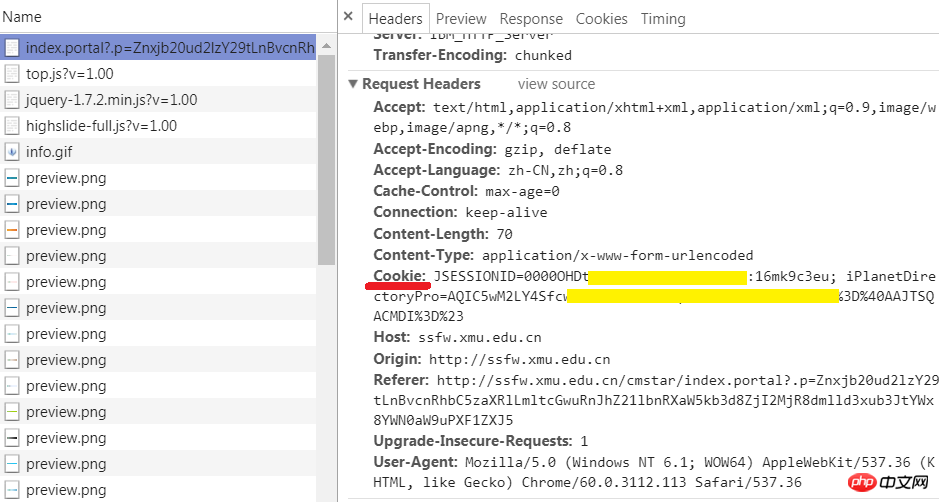
1. 브라우저로 로그인하고 브라우저에서 쿠키 문자열을 가져옵니다.
먼저 브라우저를 사용하여 로그인하세요. 개발자 도구를 다시 열고 네트워크 탭으로 이동합니다. 왼쪽의 이름 열에서 현재 URL을 찾고 오른쪽의 헤더 탭을 선택한 다음 웹사이트에서 브라우저에 발행한 쿠키가 포함된 요청 헤더를 확인하세요. 예, 그 뒤에 있는 문자열입니다. 복사해두세요. 나중에 코드에서 사용하겠습니다.
참고로, 프로그램을 실행하기 전에 로그인하는 것이 가장 좋습니다. 너무 일찍 로그인하거나 브라우저를 닫으면 복사된 쿠키가 만료될 가능성이 높습니다.
2. 코드 작성
urllib 라이브러리 버전:
import sys import io from urllib import request sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码 #登录后才能访问的网站 url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal' #浏览器登录后得到的cookie,也就是刚才复制的字符串 cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx' #登录后才能访问的网页 url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal' req = request.Request(url) #设置cookie req.add_header('cookie', raw_cookies) #设置请求头 req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36') resp = request.urlopen(req) print(resp.read().decode('utf-8'))
요청 라이브러리 버전:
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx'
#把cookie字符串处理成字典,以便接下来使用
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value방법 2: 로그인을 시뮬레이션한 후 수행 쿠키 액세스 권한 받기
원칙:
먼저 프로그램의 웹사이트에 로그인 요청을 보냅니다. 즉, 로그인 정보(사용자 이름, 비밀번호 등)가 포함된 양식을 제출합니다. 응답에서 쿠키를 얻고, 나중에 다른 페이지를 방문할 때 이 쿠키를 가져가면 로그인해야만 볼 수 있는 페이지를 얻을 수 있습니다.
구체적인 단계:
1. 양식이 제출된 페이지를 찾습니다.
여전히 브라우저의 개발자 도구를 사용해야 합니다. 네트워크 탭으로 이동하여 로그 보존을 확인하세요(중요!). 브라우저에서 웹사이트에 로그인하세요. 그런 다음 왼쪽의 이름 열에서 양식이 제출된 페이지를 찾으세요. 그것을 찾는 방법? 오른쪽을 보고 헤더 탭으로 이동합니다. 우선 General 섹션에서 Request Method가 POST여야 합니다. 둘째, 하단에 Form Data라는 섹션이 있어야 하며, 여기서 방금 입력한 사용자 이름과 비밀번호를 볼 수 있습니다. 왼쪽에 있는 이름을 보면 로그인이라는 단어가 포함되어 있는 경우 양식이 제출된 페이지일 수 있습니다(반드시 그런 것은 아닙니다!).

여기서 강조할 점은 "양식이 제출되는 페이지"는 일반적으로 사용자 이름과 비밀번호를 입력하는 페이지가 아니라는 점입니다! 따라서 도구를 사용하여 찾으십시오.
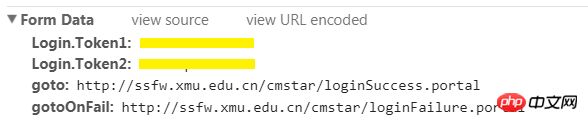
2. 제출할 데이터를 알아보세요
브라우저에 로그인할 때 사용자 이름과 비밀번호만 입력했지만 양식에는 그보다 더 많은 데이터가 포함되어 있습니다. Form Data에서 제출해야 하는 모든 데이터를 확인할 수 있습니다.
3. 코드 작성
urllib 라이브러리 버전 :
import sys
import io
import urllib.request
import http.cookiejar
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录时需要POST的数据
data = {'Login.Token1':'学号',
'Login.Token2':'密码',
'goto:http':'//ssfw.xmu.edu.cn/cmstar/loginSuccess.portal',
'gotoOnFail:http':'//ssfw.xmu.edu.cn/cmstar/loginFailure.portal'}
post_data = urllib.parse.urlencode(data).encode('utf-8')
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#登录时表单提交到的地址(用开发者工具可以看到)
login_url = ' http://ssfw.xmu.edu.cn/cmstar/userPasswordValidate.portal
#构造登录请求
req = urllib.request.Request(login_url, headers = headers, data = post_data)
#构造cookie
cookie = http.cookiejar.CookieJar()
#由cookie构造opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
#发送登录请求,此后这个opener就携带了cookie,以证明自己登录过
resp = opener.open(req)
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#构造访问请求
req = urllib.request.Request(url, headers = headers)
resp = opener.open(req)
print(resp.read().decode('utf-8'))요청 라이브러리 버전 :
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx'
#把cookie字符串处理成字典,以便接下来使用
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#在发送get请求时带上请求头和cookies
resp = requests.get(url, headers = headers, cookies = cookies)
print(resp.content.decode('utf-8'))요청 라이브러리가 사용하기 더 편리한 것은 당연합니다~~ ~
방법 3: 로그인을 시뮬레이션한 후 세션을 사용하여 로그인 상태를 유지합니다.
원칙:
세션은 세션을 의미합니다. 쿠키와 마찬가지로 서버가 클라이언트를 "인식"할 수도 있습니다. 간단히 이해하면 클라이언트와 서버 간의 모든 상호 작용을 "세션"으로 처리하는 것입니다. 동일한 "세션"에 있기 때문에 서버는 클라이언트가 로그인했는지 여부를 자연스럽게 알 수 있습니다.
구체적인 단계:
1. 양식이 제출된 페이지를 알아보세요
2. 제출할 데이터를 알아보세요.
这两步和方法二的前两步是一样的
3.写代码
requests库的版本
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录时需要POST的数据
data = {'Login.Token1':'学号',
'Login.Token2':'密码',
'goto:http':'//ssfw.xmu.edu.cn/cmstar/loginSuccess.portal',
'gotoOnFail:http':'//ssfw.xmu.edu.cn/cmstar/loginFailure.portal'}
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#登录时表单提交到的地址(用开发者工具可以看到)
login_url = 'http://ssfw.xmu.edu.cn/cmstar/userPasswordValidate.portal'
#构造Session
session = requests.Session()
#在session中发送登录请求,此后这个session里就存储了cookie
#可以用print(session.cookies.get_dict())查看
resp = session.post(login_url, data)
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#发送访问请求
resp = session.get(url)
print(resp.content.decode('utf-8'))方法四:使用无头浏览器访问
特点:
功能强大,几乎可以对付任何网页,但会导致代码效率低
原理:
如果能在程序里调用一个浏览器来访问网站,那么像登录这样的操作就轻而易举了。在Python中可以使用Selenium库来调用浏览器,写在代码里的操作(打开网页、点击……)会变成浏览器忠实地执行。这个被控制的浏览器可以是Firefox,Chrome等,但最常用的还是PhantomJS这个无头(没有界面)浏览器。也就是说,只要把填写用户名密码、点击“登录”按钮、打开另一个网页等操作写到程序中,PhamtomJS就能确确实实地让你登录上去,并把响应返回给你。
具体步骤:
1.安装selenium库、PhantomJS浏览器
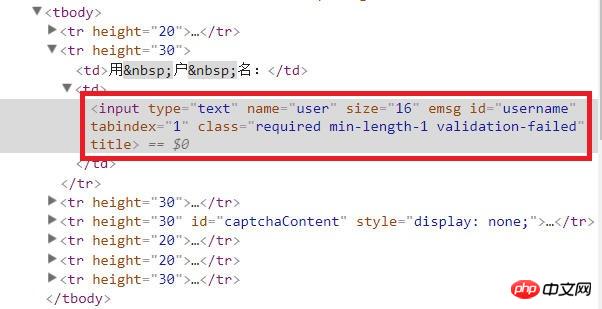
2.在源代码中找到登录时的输入文本框、按钮这些元素
因为要在无头浏览器中进行操作,所以就要先找到输入框,才能输入信息。找到登录按钮,才能点击它。
在浏览器中打开填写用户名密码的页面,将光标移动到输入用户名的文本框,右键,选择“审查元素”,就可以在右边的网页源代码中看到文本框是哪个元素。同理,可以在源代码中找到输入密码的文本框、登录按钮。
3.考虑如何在程序中找到上述元素
Selenium库提供了find_element(s)_by_xxx的方法来找到网页中的输入框、按钮等元素。其中xxx可以是id、name、tag_name(标签名)、class_name(class),也可以是xpath(xpath表达式)等等。当然还是要具体分析网页源代码。
4.写代码
import requests import sys import io from selenium import webdriver sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf8') #改变标准输出的默认编码 #建立Phantomjs浏览器对象,括号里是phantomjs.exe在你的电脑上的路径 browser = webdriver.PhantomJS('d:/tool/07-net/phantomjs-windows/phantomjs-2.1.1-windows/bin/phantomjs.exe') #登录页面 url = r'http://ssfw.xmu.edu.cn/cmstar/index.portal' # 访问登录页面 browser.get(url) # 等待一定时间,让js脚本加载完毕 browser.implicitly_wait(3) #输入用户名 username = browser.find_element_by_name('user') username.send_keys('学号') #输入密码 password = browser.find_element_by_name('pwd') password.send_keys('密码') #选择“学生”单选按钮 student = browser.find_element_by_xpath('//input[@value="student"]') student.click() #点击“登录”按钮 login_button = browser.find_element_by_name('btn') login_button.submit() #网页截图 browser.save_screenshot('picture1.png') #打印网页源代码 print(browser.page_source.encode('utf-8').decode()) browser.quit()
相关推荐:
위 내용은 Python 시뮬레이션 로그인의 다양한 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7478
7478
 15
1377
52
77
11
50
19
19
33
15
1377
52
77
11
50
19
19
33

 MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL은 지불해야합니다
Apr 08, 2025 pm 05:36 PM
MySQL에는 무료 커뮤니티 버전과 유료 엔터프라이즈 버전이 있습니다. 커뮤니티 버전은 무료로 사용 및 수정할 수 있지만 지원은 제한되어 있으며 안정성이 낮은 응용 프로그램에 적합하며 기술 기능이 강합니다. Enterprise Edition은 안정적이고 신뢰할 수있는 고성능 데이터베이스가 필요하고 지원 비용을 기꺼이 지불하는 응용 프로그램에 대한 포괄적 인 상업적 지원을 제공합니다. 버전을 선택할 때 고려 된 요소에는 응용 프로그램 중요도, 예산 책정 및 기술 기술이 포함됩니다. 완벽한 옵션은없고 가장 적합한 옵션 만 있으므로 특정 상황에 따라 신중하게 선택해야합니다.
 설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
설치 후 MySQL을 사용하는 방법
Apr 08, 2025 am 11:48 AM
이 기사는 MySQL 데이터베이스의 작동을 소개합니다. 먼저 MySQLworkBench 또는 명령 줄 클라이언트와 같은 MySQL 클라이언트를 설치해야합니다. 1. MySQL-Uroot-P 명령을 사용하여 서버에 연결하고 루트 계정 암호로 로그인하십시오. 2. CreateABase를 사용하여 데이터베이스를 작성하고 데이터베이스를 선택하십시오. 3. CreateTable을 사용하여 테이블을 만들고 필드 및 데이터 유형을 정의하십시오. 4. InsertInto를 사용하여 데이터를 삽입하고 데이터를 쿼리하고 업데이트를 통해 데이터를 업데이트하고 DELETE를 통해 데이터를 삭제하십시오. 이러한 단계를 마스터하고 일반적인 문제를 처리하는 법을 배우고 데이터베이스 성능을 최적화하면 MySQL을 효율적으로 사용할 수 있습니다.
 다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
다운로드 후 MySQL을 설치할 수 없습니다
Apr 08, 2025 am 11:24 AM
MySQL 설치 실패의 주된 이유는 다음과 같습니다. 1. 권한 문제, 관리자로 실행하거나 Sudo 명령을 사용해야합니다. 2. 종속성이 누락되었으며 관련 개발 패키지를 설치해야합니다. 3. 포트 충돌, 포트 3306을 차지하는 프로그램을 닫거나 구성 파일을 수정해야합니다. 4. 설치 패키지가 손상되어 무결성을 다운로드하여 확인해야합니다. 5. 환경 변수가 잘못 구성되었으며 운영 체제에 따라 환경 변수를 올바르게 구성해야합니다. 이러한 문제를 해결하고 각 단계를 신중하게 확인하여 MySQL을 성공적으로 설치하십시오.
 MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일이 손상되어 설치할 수 없습니다. 수리 솔루션
Apr 08, 2025 am 11:21 AM
MySQL 다운로드 파일은 손상되었습니다. 어떻게해야합니까? 아아, mySQL을 다운로드하면 파일 손상을 만날 수 있습니다. 요즘 정말 쉽지 않습니다! 이 기사는 모든 사람이 우회를 피할 수 있도록이 문제를 해결하는 방법에 대해 이야기합니다. 읽은 후 손상된 MySQL 설치 패키지를 복구 할 수있을뿐만 아니라 향후에 갇히지 않도록 다운로드 및 설치 프로세스에 대해 더 깊이 이해할 수 있습니다. 파일 다운로드가 손상된 이유에 대해 먼저 이야기합시다. 이에 대한 많은 이유가 있습니다. 네트워크 문제는 범인입니다. 네트워크의 다운로드 프로세스 및 불안정성의 중단으로 인해 파일 손상이 발생할 수 있습니다. 다운로드 소스 자체에도 문제가 있습니다. 서버 파일 자체가 고장 났으며 물론 다운로드하면 고장됩니다. 또한 일부 안티 바이러스 소프트웨어의 과도한 "열정적 인"스캔으로 인해 파일 손상이 발생할 수 있습니다. 진단 문제 : 파일이 실제로 손상되었는지 확인하십시오
 MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 인터넷이 필요합니까?
Apr 08, 2025 pm 02:18 PM
MySQL은 기본 데이터 저장 및 관리를위한 네트워크 연결없이 실행할 수 있습니다. 그러나 다른 시스템과의 상호 작용, 원격 액세스 또는 복제 및 클러스터링과 같은 고급 기능을 사용하려면 네트워크 연결이 필요합니다. 또한 보안 측정 (예 : 방화벽), 성능 최적화 (올바른 네트워크 연결 선택) 및 데이터 백업은 인터넷에 연결하는 데 중요합니다.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL 설치 후 시작할 수없는 서비스에 대한 솔루션
Apr 08, 2025 am 11:18 AM
MySQL이 시작을 거부 했습니까? 당황하지 말고 확인합시다! 많은 친구들이 MySQL을 설치 한 후 서비스를 시작할 수 없다는 것을 알았으며 너무 불안했습니다! 걱정하지 마십시오.이 기사는 침착하게 다루고 그 뒤에있는 마스터 마인드를 찾을 수 있습니다! 그것을 읽은 후에는이 문제를 해결할뿐만 아니라 MySQL 서비스에 대한 이해와 문제 해결 문제에 대한 아이디어를 향상시키고보다 강력한 데이터베이스 관리자가 될 수 있습니다! MySQL 서비스는 시작되지 않았으며 간단한 구성 오류에서 복잡한 시스템 문제에 이르기까지 여러 가지 이유가 있습니다. 가장 일반적인 측면부터 시작하겠습니다. 기본 지식 : 서비스 시작 프로세스 MySQL 서비스 시작에 대한 간단한 설명. 간단히 말해서 운영 체제는 MySQL 관련 파일을로드 한 다음 MySQL 데몬을 시작합니다. 여기에는 구성이 포함됩니다
 MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 설치 후 데이터베이스 성능을 최적화하는 방법
Apr 08, 2025 am 11:36 AM
MySQL 성능 최적화는 설치 구성, 인덱싱 및 쿼리 최적화, 모니터링 및 튜닝의 세 가지 측면에서 시작해야합니다. 1. 설치 후 innodb_buffer_pool_size 매개 변수와 같은 서버 구성에 따라 my.cnf 파일을 조정해야합니다. 2. 과도한 인덱스를 피하기 위해 적절한 색인을 작성하고 Execution 명령을 사용하여 실행 계획을 분석하는 것과 같은 쿼리 문을 최적화합니다. 3. MySQL의 자체 모니터링 도구 (showprocesslist, showstatus)를 사용하여 데이터베이스 건강을 모니터링하고 정기적으로 백업 및 데이터베이스를 구성하십시오. 이러한 단계를 지속적으로 최적화함으로써 MySQL 데이터베이스의 성능을 향상시킬 수 있습니다.
