

pytorch + visdom 자체 구축 이미지 데이터 세트를 처리하는 CNN 방법

이 글은 자체 구축한 이미지 데이터 세트를 처리하기 위한 pytorch + visdom CNN 방법을 주로 소개합니다. 이제 특정 참조 가치가 있으므로 필요한 친구들이 참조할 수 있습니다.
Environment
시스템: win10
cpu: i7-6700HQ
gpu: gtx965m
python: 3.6
pytorch: 0.3
데이터 다운로드
Sasank Chilamkurthy의 튜토리얼에서 출처 : 다운로드 링크;
다운로드하여 압축을 풀고 프로젝트 루트 디렉터리에 넣으세요:

데이터 세트는 개미와 벌을 분류하는 데 사용됩니다. 각 클래스에는 약 120개의 훈련 이미지와 75개의 검증 이미지가 있습니다.
데이터 가져오기
torchvision.datasets.ImageFolder(root,transforms) 모듈을 사용하여 이미지를 텐서로 변환할 수 있습니다.
첫 번째 변환 정의:
ata_transforms = {
'train': transforms.Compose([
# 随机切成224x224 大小图片 统一图片格式
transforms.RandomResizedCrop(224),
# 图像翻转
transforms.RandomHorizontalFlip(),
# totensor 归一化(0,255) >> (0,1) normalize channel=(channel-mean)/std
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
"val" : transforms.Compose([
# 图片大小缩放 统一图片格式
transforms.Resize(256),
# 以中心裁剪
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
}데이터 가져오기 및 로드:
data_dir = './hymenoptera_data'
# trans data
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
# load data
data_loaders = {x: DataLoader(image_datasets[x], batch_size=BATCH_SIZE, shuffle=True) for x in ['train', 'val']}
data_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
print(data_sizes, class_names){'train': 244, 'val': 153} ['ants', 'bees']훈련 세트 244개, 테스트 세트 153개.
visdom은 텐서 입력을 지원하므로 numpy로 변경할 필요가 없습니다. 텐서 계산을 직접 사용할 수 있습니다. 이전 기사의 cifar10 사양 변경:
inputs, classes = next(iter(data_loaders['val'])) out = torchvision.utils.make_grid(inputs) inp = torch.transpose(out, 0, 2) mean = torch.FloatTensor([0.485, 0.456, 0.406]) std = torch.FloatTensor([0.229, 0.224, 0.225]) inp = std * inp + mean inp = torch.transpose(inp, 0, 2) viz.images(inp)
loss, 최적화 기능: 
class CNN(nn.Module):
def __init__(self, in_dim, n_class):
super(CNN, self).__init__()
self.cnn = nn.Sequential(
nn.BatchNorm2d(in_dim),
nn.ReLU(True),
nn.Conv2d(in_dim, 16, 7), # 224 >> 218
nn.BatchNorm2d(16),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2), # 218 >> 109
nn.ReLU(True),
nn.Conv2d(16, 32, 5), # 105
nn.BatchNorm2d(32),
nn.ReLU(True),
nn.Conv2d(32, 64, 5), # 101
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.Conv2d(64, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(2, 2), # 101 >> 50
nn.Conv2d(64, 128, 3, 1, 1), #
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(3), # 50 >> 16
)
self.fc = nn.Sequential(
nn.Linear(128*16*16, 120),
nn.BatchNorm1d(120),
nn.ReLU(True),
nn.Linear(120, n_class))
def forward(self, x):
out = self.cnn(x)
out = self.fc(out.view(-1, 128*16*16))
return out
# 输入3层rgb ,输出 分类 2
model = CNN(3, 2)line = viz.line(Y=np.arange(10)) loss_f = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=LR, momentum=0.9) scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
rreee
Run 20 살펴보기:
BATCH_SIZE = 4 LR = 0.001 EPOCHS = 10
[9/10] train_loss:0.650|train_acc:0.639|test_loss:0.621|test_acc0.706 [10/10] train_loss:0.645|train_acc:0.627|test_loss:0.654|test_acc0.686 Training complete in 1m 16s Best val Acc: 0.712418
[19/20] train_loss:0.592|train_acc:0.701|test_loss:0.563|test_acc0.712 [20/20] train_loss:0.564|train_acc:0.721|test_loss:0.571|test_acc0.706 Training complete in 2m 30s Best val Acc: 0.745098
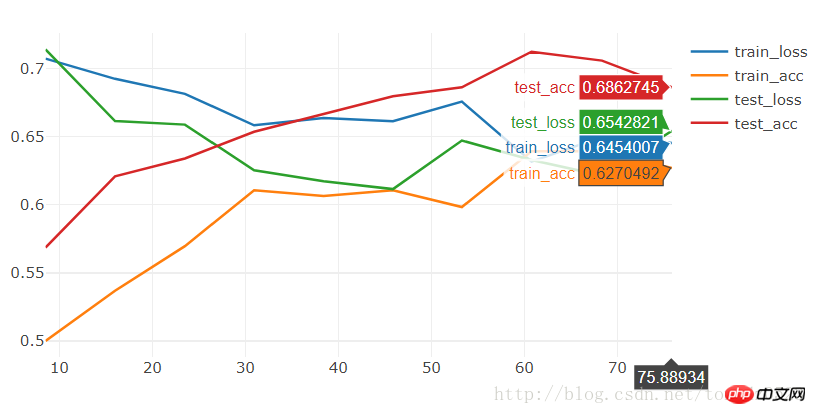 원하는 경우 효과도 매우 평균입니다. 짧은 시간에 훈련시키면 효과가 매우 좋을 것입니다. 좋은 모델의 경우 훈련된 상태를 다운로드하여 다음을 기준으로 훈련할 수 있습니다.
원하는 경우 효과도 매우 평균입니다. 짧은 시간에 훈련시키면 효과가 매우 좋을 것입니다. 좋은 모델의 경우 훈련된 상태를 다운로드하여 다음을 기준으로 훈련할 수 있습니다. model = torchvision.models.resnet18(True) num_ftrs = model.fc.in_features model.fc = nn.Linear(num_ftrs, 2)
[9/10] train_loss:0.621|train_acc:0.652|test_loss:0.588|test_acc0.667 [10/10] train_loss:0.610|train_acc:0.680|test_loss:0.561|test_acc0.667 Training complete in 1m 24s Best val Acc: 0.686275
10 에포크는 95% 정확도에 직접 도달할 수 있습니다. 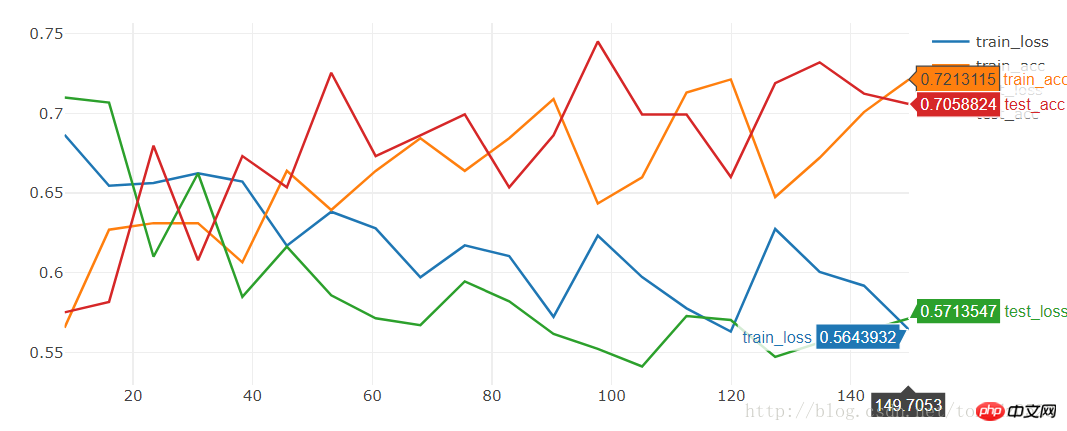
관련 추천:
pytorch + visdom은 간단한 분류 문제를 처리합니다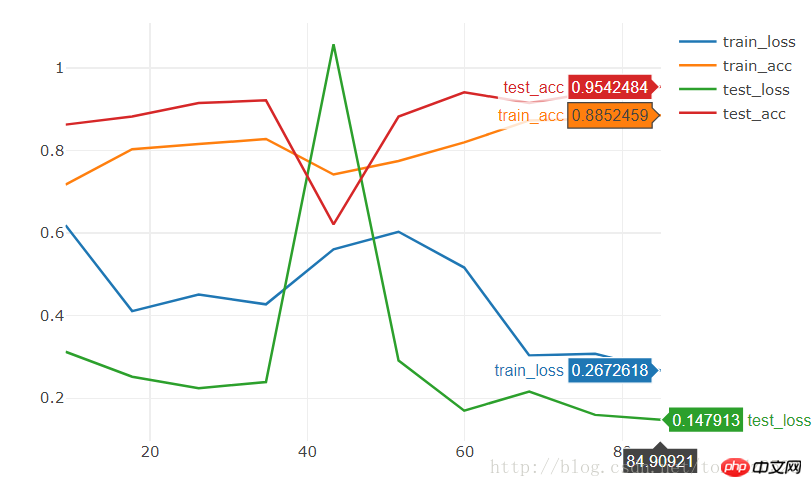
위 내용은 pytorch + visdom 자체 구축 이미지 데이터 세트를 처리하는 CNN 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7680
7680
 15
1393
52
1209
24
91
11
73
19
15
1393
52
1209
24
91
11
73
19

 Xiaohongshu에 게시할 때 사진이 자동으로 저장되는 문제를 해결하는 방법은 무엇입니까? 포스팅 시 자동으로 저장되는 이미지는 어디에 있나요?
Mar 22, 2024 am 08:06 AM
Xiaohongshu에 게시할 때 사진이 자동으로 저장되는 문제를 해결하는 방법은 무엇입니까? 포스팅 시 자동으로 저장되는 이미지는 어디에 있나요?
Mar 22, 2024 am 08:06 AM
소셜 미디어의 지속적인 발전으로 Xiaohongshu는 점점 더 많은 젊은이들이 자신의 삶을 공유하고 아름다운 것을 발견할 수 있는 플랫폼이 되었습니다. 많은 사용자들이 이미지 게시 시 자동 저장 문제로 고민하고 있습니다. 그렇다면 이 문제를 해결하는 방법은 무엇입니까? 1. Xiaohongshu에 게시할 때 사진이 자동으로 저장되는 문제를 해결하는 방법은 무엇입니까? 1. 캐시 지우기 먼저 Xiaohongshu의 캐시 데이터를 지워볼 수 있습니다. 단계는 다음과 같습니다. (1) Xiaohongshu를 열고 오른쪽 하단에 있는 "내" 버튼을 클릭합니다. (2) 개인 센터 페이지에서 "설정"을 찾아 클릭합니다. 캐시 지우기' 옵션을 선택하고 확인을 클릭하세요. 캐시를 삭제한 후 샤오홍슈에 다시 진입하여 사진을 올려 자동 저장 문제가 해결되었는지 확인해 보세요. 2. Xiaohongshu 버전을 업데이트하여 Xiaohongshu를 확인하세요.
 TikTok 댓글에 사진을 게시하는 방법은 무엇입니까? 댓글란에 있는 사진의 입구는 어디인가요?
Mar 21, 2024 pm 09:12 PM
TikTok 댓글에 사진을 게시하는 방법은 무엇입니까? 댓글란에 있는 사진의 입구는 어디인가요?
Mar 21, 2024 pm 09:12 PM
Douyin 짧은 동영상의 인기로 인해 댓글 영역의 사용자 상호 작용이 더욱 다채로워졌습니다. 일부 사용자는 자신의 의견이나 감정을 더 잘 표현하기 위해 댓글로 이미지를 공유하기를 원합니다. 그렇다면 TikTok 댓글에 사진을 게시하는 방법은 무엇입니까? 이 기사에서는 이 질문에 대해 자세히 답변하고 몇 가지 관련 팁과 예방 조치를 제공합니다. 1. Douyin 댓글에 사진을 어떻게 게시하나요? 1. Douyin 열기: 먼저 Douyin 앱을 열고 계정에 로그인해야 합니다. 2. 댓글 영역 찾기: 짧은 동영상을 탐색하거나 게시할 때 댓글을 달고 싶은 위치를 찾아 "댓글" 버튼을 클릭하세요. 3. 댓글 내용 입력: 댓글 영역에 댓글 내용을 입력합니다. 4. 사진 전송 선택: 댓글 내용 입력 인터페이스에 "사진" 버튼 또는 "+" 버튼이 표시됩니다.
 PyCharm과 PyTorch의 완벽한 조합: 자세한 설치 및 구성 단계
Feb 21, 2024 pm 12:00 PM
PyCharm과 PyTorch의 완벽한 조합: 자세한 설치 및 구성 단계
Feb 21, 2024 pm 12:00 PM
PyCharm은 강력한 통합 개발 환경(IDE)이고, PyTorch는 딥 러닝 분야에서 인기 있는 오픈 소스 프레임워크입니다. 머신러닝과 딥러닝 분야에서 PyCharm과 PyTorch를 개발에 활용하면 개발 효율성과 코드 품질을 크게 향상시킬 수 있습니다. 이 기사에서는 PyCharm에서 PyTorch를 설치 및 구성하는 방법을 자세히 소개하고 독자가 이 두 가지의 강력한 기능을 더 잘 활용할 수 있도록 특정 코드 예제를 첨부합니다. 1단계: PyCharm 및 Python 설치
 iPhone에서 사진을 더 선명하게 만드는 6가지 방법
Mar 04, 2024 pm 06:25 PM
iPhone에서 사진을 더 선명하게 만드는 6가지 방법
Mar 04, 2024 pm 06:25 PM
Apple의 최근 iPhone은 선명한 디테일, 채도 및 밝기로 추억을 포착합니다. 그러나 때로는 이미지가 덜 선명하게 보일 수 있는 몇 가지 문제가 발생할 수 있습니다. iPhone 카메라의 자동 초점 기능이 크게 발전하여 사진을 빠르게 촬영할 수 있게 되었지만, 특정 상황에서는 카메라가 실수로 잘못된 피사체에 초점을 맞춰 원치 않는 영역에서 사진이 흐릿해질 수 있습니다. iPhone의 사진이 일반적으로 초점이 맞지 않거나 선명도가 부족한 경우 다음 게시물을 통해 사진을 더 선명하게 만드는 데 도움이 될 것입니다. iPhone에서 사진을 더 선명하게 만드는 방법 [6가지 방법] 기본 사진 앱을 사용하여 사진을 정리할 수 있습니다. 더 많은 기능과 옵션을 원하신다면
 PPT 사진을 하나씩 나타나게 하는 방법
Mar 25, 2024 pm 04:00 PM
PPT 사진을 하나씩 나타나게 하는 방법
Mar 25, 2024 pm 04:00 PM
파워포인트에서는 그림을 하나씩 표시하는 것이 일반적인 기술인데, 이는 애니메이션 효과를 설정하면 가능하다. 이 가이드에서는 기본 설정, 이미지 삽입, 애니메이션 추가, 애니메이션 순서 및 타이밍 조정 등 이 기술을 구현하는 단계를 자세히 설명합니다. 또한 트리거 사용, 애니메이션 속도 및 순서 조정, 애니메이션 효과 미리보기 등의 고급 설정 및 조정이 제공됩니다. 이러한 단계와 팁을 따르면 사용자는 PowerPoint에서 그림이 차례로 표시되도록 쉽게 설정할 수 있으므로 프레젠테이션의 시각적 효과가 향상되고 청중의 관심을 끌 수 있습니다.
 웹페이지의 이미지를 로드할 수 없으면 어떻게 해야 합니까? 6가지 솔루션
Mar 15, 2024 am 10:30 AM
웹페이지의 이미지를 로드할 수 없으면 어떻게 해야 합니까? 6가지 솔루션
Mar 15, 2024 am 10:30 AM
일부 네티즌들은 브라우저 웹페이지를 열었을 때 웹페이지의 사진이 오랫동안 로드되지 않는다는 사실을 발견했습니다. 네트워크가 정상인지 확인했는데 무엇이 문제인가요? 아래 편집기에서는 웹 페이지 이미지를 로드할 수 없는 문제에 대한 6가지 해결 방법을 소개합니다. 웹페이지 이미지를 로드할 수 없습니다: 1. 인터넷 속도 문제 웹페이지에 이미지가 표시되지 않습니다. 이는 컴퓨터의 인터넷 속도가 상대적으로 느리고 컴퓨터에 열려 있는 소프트웨어가 더 많기 때문일 수 있습니다. 로딩 시간 초과로 인해 사진이 표시되지 않을 수 있습니다. 네트워크 속도를 차지하는 소프트웨어를 끄고 작업 관리자에서 확인할 수 있습니다. 2. 방문자가 너무 많으면 웹페이지에 사진이 표시되지 않는 경우, 우리가 방문한 웹페이지가 동시에 방문되었기 때문일 수 있습니다.
 HTML, CSS 및 jQuery를 사용하여 이미지 병합 및 표시의 고급 기능을 구현하는 방법
Oct 27, 2023 pm 04:36 PM
HTML, CSS 및 jQuery를 사용하여 이미지 병합 및 표시의 고급 기능을 구현하는 방법
Oct 27, 2023 pm 04:36 PM
HTML, CSS 및 jQuery를 사용하여 이미지 병합 표시를 구현하는 방법에 대한 고급 기능 개요: 웹 디자인에서 이미지 표시는 중요한 링크이며, 이미지 병합 표시는 페이지 로딩 속도와 사용자 경험을 향상시키는 일반적인 기술 중 하나입니다. 이 기사에서는 HTML, CSS 및 jQuery를 사용하여 이미지 병합 및 표시의 고급 기능을 구현하는 방법을 소개하고 구체적인 코드 예제를 제공합니다. 1. HTML 레이아웃: 먼저 병합된 이미지를 표시하기 위해 HTML로 컨테이너를 만들어야 합니다. 당신은 디를 사용할 수 있습니다
 Foxit PDF Reader를 사용하여 PDF 문서를 jpg 이미지로 변환하는 방법 - Foxit PDF Reader를 사용하여 PDF 문서를 jpg 이미지로 변환하는 방법
Mar 04, 2024 pm 05:49 PM
Foxit PDF Reader를 사용하여 PDF 문서를 jpg 이미지로 변환하는 방법 - Foxit PDF Reader를 사용하여 PDF 문서를 jpg 이미지로 변환하는 방법
Mar 04, 2024 pm 05:49 PM
Foxit PDF Reader 소프트웨어도 사용하고 계십니까? 그렇다면 Foxit PDF Reader가 PDF 문서를 jpg 이미지로 변환하는 방법을 알고 계십니까? 다음 기사에서는 변환 방법에 관심이 있는 사람들을 위해 Foxit PDF Reader가 PDF 문서를 jpg 이미지로 변환하는 방법을 설명합니다. jpg 이미지를 보려면 아래를 방문하여 살펴보시기 바랍니다. 먼저 Foxit PDF Reader를 시작한 다음 상단 도구 모음에서 "기능"을 찾은 다음 "PDF를 다른 사람에게 보내기" 기능을 선택하십시오. 다음으로 "Foxit PDF 온라인 변환"이라는 웹 페이지를 엽니다. 페이지 오른쪽 상단의 "로그인" 버튼을 클릭하여 로그인한 후 "PDF를 이미지로" 기능을 활성화하세요. 그런 다음 업로드 버튼을 클릭하고 이미지로 변환하려는 PDF 파일을 추가한 후 "변환 시작"을 클릭하세요.
