

NetEase Cloud 음악 리뷰 크롤링
# coding=gbk
import requests
import json
c='网易云爬虫实战一'
print(c)
music_url = 'https://music.163.com/#/song?id=28815250'
id = music_url.split('=')[1]
# print(id)
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_%s?csrf_token=7e19029fe28aa3e09cfe87e89d2e4eeb' %(id)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Referer': 'https://music.163.com/song?id=%s' %(id),
'Origin': 'https://music.163.com',
}
formdata = {
'params': 'AoF/ZXuccqvtaCMCPHecFGVPfrbtDj4JFPJsaZ3tYn9J+r0NcnKPhZdVECDz/jM+1CpA+ByvAO2J9d44B/MG97WhjmxWkfo4Tm++AfyBgK11NnSbKsuQ5bxJR6yE0MyFhU8sPq7wb9DiUPFKs2ulw0GxwU/il1NS/eLrq+bbYikK/cyne90S/yGs6ldxpbcNd1yQTuOL176aBZXTJEcGkfbxY+mLKCwScAcCK1s3STo=',
'encSecKey': '365b4c31a9c7e2ddc002e9c42942281d7e450e5048b57992146633181efe83c1e26acbc8d84b988d746370d788b6ae087547bace402565cca3ad59ccccf7566b07d364aa1d5b2bbe8ccf2bc33e0f03182206e29c66ae4ad6c18cb032d23f1793420ceda05e796401f170dbdb825c20356d27f07870598b2798f8d344807ad6f2',
}
response = requests.post(url, headers = headers, data = formdata)
messages = json.loads(response.text)
data_list=[]
data={}
for message in messages['hotComments']:
data['nickname']=message['user']['nickname']
data['content']=message['content']
data_list.append(data)
data={}
#print(data_list)
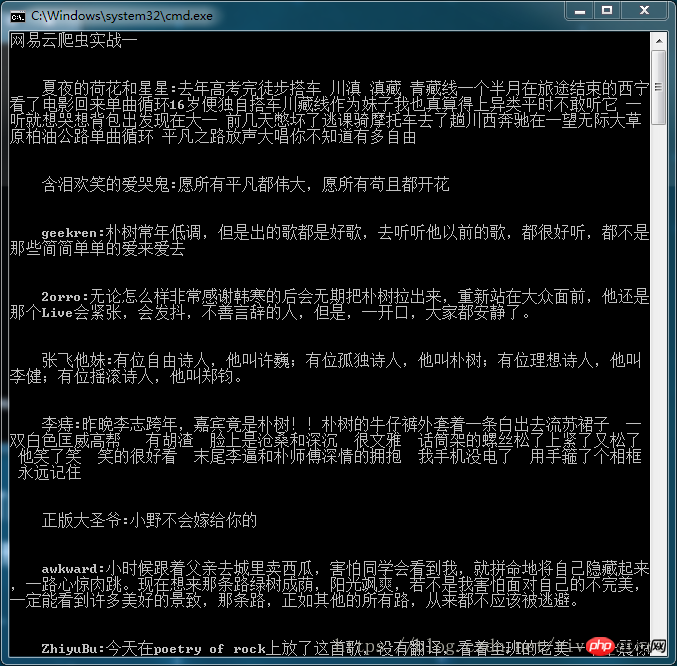
for i in data_list:
c = ' '+i['nickname']+':'+i['content']
print('\n\n'+c.replace('\n',''))
요약:
1. 첫 번째 줄의 "#coding=gbk"는 텍스트 편집기에 텍스트 문자열을 입력할 수 있다는 의미입니다.
2. "id = music_url.split('=')[1]"의 Split() 함수는 요소를 그룹화하는 것을 의미합니다. 예에서는 "https://music.163.com/#/입니다. song?id =", "28815250"
3. 요청 모듈에서 얻은 HTML 텍스트는 json.loads() 메서드를 사용하여 Python에서 읽을 수 있는 텍스트로 변환해야 합니다. 그렇지 않으면 오류가 보고됩니다. 주피터 노트북에서는 이런 일이 발생하지 않습니다.
4.replace() 함수는 문자열에서 요소를 제거할 수 있습니다. 이 예에서는 개행 문자가 빈 문자로 변경됩니다.
최종 표시 결과는 다음과 같습니다.
본 글에서는 NetEase Cloud 음악 리뷰 크롤링 관련 내용을 소개하고 있으니 PHP 중국어 웹사이트를 주목해주세요.
관련 권장 사항:
HTML을 Excel로 변환하고 인쇄 및 다운로드 기능을 실현
위 내용은 NetEase Cloud 음악 리뷰 크롤링의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7655
7655
 15
1393
52
91
11
73
19
37
110
15
1393
52
91
11
73
19
37
110

 New York Times API를 사용한 메타데이터 스크래핑
Sep 02, 2023 pm 10:13 PM
New York Times API를 사용한 메타데이터 스크래핑
Sep 02, 2023 pm 10:13 PM
소개 지난주에 메타데이터 수집을 위해 웹페이지를 스크래핑하는 방법에 대한 소개를 썼고, 뉴욕타임즈 웹사이트는 스크래핑이 불가능하다고 언급했습니다. New York Times 페이월은 기본 메타데이터 수집 시도를 차단합니다. 하지만 New York Times API를 사용하면 이 문제를 해결할 수 있는 방법이 있습니다. 최근 저는 Yii 플랫폼에 커뮤니티 웹사이트를 구축하기 시작했습니다. 이는 향후 튜토리얼에서 게시할 예정입니다. 사이트 콘텐츠와 관련된 링크를 쉽게 추가하고 싶습니다. 사람들은 양식에 URL을 쉽게 붙여넣을 수 있지만 제목과 출처 정보를 제공하는 데는 시간이 많이 걸립니다. 그래서 오늘의 튜토리얼에서는 New York Times API를 활용하여 New York Times에 링크를 추가할 때 헤드라인을 수집하도록 최근에 작성한 스크래핑 코드를 확장하겠습니다. 기억해, 나도 관련돼 있어
 PHP 프로젝트에서 API 인터페이스를 호출하여 데이터를 크롤링하고 처리하는 방법은 무엇입니까?
Sep 05, 2023 am 08:41 AM
PHP 프로젝트에서 API 인터페이스를 호출하여 데이터를 크롤링하고 처리하는 방법은 무엇입니까?
Sep 05, 2023 am 08:41 AM
PHP 프로젝트에서 API 인터페이스를 호출하여 데이터를 크롤링하고 처리하는 방법은 무엇입니까? 1. 소개 PHP 프로젝트에서는 종종 다른 웹사이트에서 데이터를 크롤링하고 이러한 데이터를 처리해야 합니다. 많은 웹사이트에서는 API 인터페이스를 제공하며, 우리는 이러한 인터페이스를 호출하여 데이터를 얻을 수 있습니다. 이 기사에서는 PHP를 사용하여 API 인터페이스를 호출하여 데이터를 크롤링하고 처리하는 방법을 소개합니다. 2. API 인터페이스의 URL과 매개변수를 얻으십시오. 시작하기 전에 대상 API 인터페이스의 URL과 필수 매개변수를 얻어야 합니다.
 Vue 개발 경험 요약: SEO 및 검색 엔진 크롤링 최적화를 위한 팁
Nov 22, 2023 am 10:56 AM
Vue 개발 경험 요약: SEO 및 검색 엔진 크롤링 최적화를 위한 팁
Nov 22, 2023 am 10:56 AM
Vue 개발 경험 요약: SEO 최적화 및 검색 엔진 크롤링을 위한 팁 인터넷의 급속한 발전으로 인해 웹사이트 SEO(SearchEngineOptimization, 검색 엔진 최적화)가 점점 더 중요해지고 있습니다. Vue를 사용하여 개발된 웹사이트의 경우 SEO 및 검색 엔진 크롤링을 최적화하는 것이 중요합니다. 이 기사에서는 일부 Vue 개발 경험을 요약하고 SEO 및 검색 엔진 크롤링 최적화를 위한 몇 가지 팁을 공유합니다. 사전 렌더링 기술 Vue 사용
 Scrapy를 사용하여 Douban 도서와 평점 및 댓글을 크롤링하는 방법은 무엇입니까?
Jun 22, 2023 am 10:21 AM
Scrapy를 사용하여 Douban 도서와 평점 및 댓글을 크롤링하는 방법은 무엇입니까?
Jun 22, 2023 am 10:21 AM
인터넷의 발달로 사람들은 정보를 얻기 위해 인터넷에 점점 더 의존하고 있습니다. 책을 좋아하는 사람들에게 Douban Books는 없어서는 안 될 플랫폼이 되었습니다. 또한, Douban Books는 풍부한 도서 평점과 리뷰를 제공하여 독자들이 책을 보다 포괄적으로 이해할 수 있도록 해줍니다. 그러나 이 정보를 수동으로 얻는 것은 건초 더미에서 바늘을 찾는 것과 같습니다. 이때 Scrapy 도구를 사용하여 데이터를 크롤링할 수 있습니다. Scrapy는 Python 기반의 오픈 소스 웹 크롤러 프레임워크로 효율적으로 도움을 줄 수 있습니다.
 Scrapy 실행: Baidu 뉴스 데이터 크롤링
Jun 23, 2023 am 08:50 AM
Scrapy 실행: Baidu 뉴스 데이터 크롤링
Jun 23, 2023 am 08:50 AM
Scrapy 실행: Baidu 뉴스 데이터 크롤링 인터넷이 발전하면서 사람들이 정보를 얻는 주요 방법이 전통적인 미디어에서 인터넷으로 바뀌었고 사람들은 뉴스 정보를 얻기 위해 점점 더 인터넷에 의존하고 있습니다. 연구원이나 분석가의 경우 분석 및 연구를 위해 많은 양의 데이터가 필요합니다. 따라서 이 글에서는 Scrapy를 사용하여 Baidu 뉴스 데이터를 크롤링하는 방법을 소개합니다. Scrapy는 웹사이트 데이터를 빠르고 효율적으로 크롤링할 수 있는 오픈 소스 Python 크롤러 프레임워크입니다. Scrapy는 강력한 웹페이지 구문 분석 및 크롤링 기능을 제공합니다.
 웹 크롤링 및 데이터 추출을 위해 PHP Goutte 클래스 라이브러리를 사용하는 방법은 무엇입니까?
Aug 09, 2023 pm 02:16 PM
웹 크롤링 및 데이터 추출을 위해 PHP Goutte 클래스 라이브러리를 사용하는 방법은 무엇입니까?
Aug 09, 2023 pm 02:16 PM
웹 크롤링 및 데이터 추출을 위해 PHPGoutte 클래스 라이브러리를 사용하는 방법은 무엇입니까? 개요: 일상적인 개발 과정에서 영화 순위, 일기 예보 등과 같은 다양한 데이터를 인터넷에서 얻어야 하는 경우가 많습니다. 웹 크롤링은 이 데이터를 얻는 일반적인 방법 중 하나입니다. PHP 개발에서는 Goutte 클래스 라이브러리를 사용하여 웹 크롤링 및 데이터 추출 기능을 구현할 수 있습니다. 이 기사에서는 PHPGoutte 클래스 라이브러리를 사용하여 웹 페이지를 크롤링하고 데이터를 추출하고 코드 예제를 첨부하는 방법을 소개합니다. 통풍이란 무엇입니까?
 Scrapy 실행: Douban 영화 데이터 크롤링 및 인기 순위 평가
Jun 22, 2023 pm 01:49 PM
Scrapy 실행: Douban 영화 데이터 크롤링 및 인기 순위 평가
Jun 22, 2023 pm 01:49 PM
Scrapy는 데이터를 빠르고 효율적으로 스크랩하기 위한 오픈 소스 Python 프레임워크입니다. 이 기사에서는 Scrapy를 사용하여 Douban 영화의 데이터를 크롤링하고 인기도를 평가할 것입니다. 준비 먼저 Scrapy를 설치해야 합니다. 명령줄에 다음 명령을 입력하여 Scrapy를 설치할 수 있습니다. pipinstallscrapy 다음으로 Scrapy 프로젝트를 생성하겠습니다. 명령줄에 다음 명령을 입력합니다: scrapystartproject
 Scrapy를 사용하여 Kugou Music 노래를 크롤링하는 방법은 무엇입니까?
Jun 22, 2023 pm 10:59 PM
Scrapy를 사용하여 Kugou Music 노래를 크롤링하는 방법은 무엇입니까?
Jun 22, 2023 pm 10:59 PM
인터넷의 발달로 인해 인터넷에 존재하는 정보의 양이 증가하고 있으며, 사람들은 다양한 분석과 마이닝을 수행하기 위해 다양한 웹사이트에서 정보를 크롤링해야 합니다. Scrapy는 웹사이트 데이터를 자동으로 크롤링하고 구조화된 형식으로 출력할 수 있는 완전한 기능을 갖춘 Python 크롤러 프레임워크입니다. Kugou Music은 가장 인기 있는 온라인 음악 플랫폼 중 하나입니다. 아래에서는 Kugou Music의 노래 정보를 크롤링하기 위해 Scrapy를 사용하는 방법을 소개하겠습니다. 1. Scrapy 설치Scrapy는 Python 언어 기반의 프레임워크이므로
