

PHP에서 cURL을 사용하는 방법

이 글에서는 주로 PHP 컬렉션 아티팩트 cURL을 사용하는 방법을 자세히 소개합니다. file_get_contents 함수는 원격 링크에서 데이터를 얻는 데 더 많은 이점이 있습니다. 관심 있는 친구는 이를 참조할 수 있습니다.
추천 매뉴얼: php 자율 학습 매뉴얼
데이터 수집을 해본 분들이라면 cURL이 익숙하실 겁니다. PHP에는 원격 링크 데이터를 얻을 수 있는 file_get_contents 함수가 있지만 그 제어성은 너무 열악합니다. 다양한 복잡한 수집 시나리오에서는 file_get_contents가 약간 무력해 보입니다. 따라서 이 기사에서는 컬렉션 아티팩트 cURL의 사용 방법을 소개합니다.
먼저 file_get_contents 함수가 원격 링크 데이터를 얻는 방법을 추가하겠습니다.
<?php $url = "http://git.oschina.net/yunluo/API/raw/master/notice.txt"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); $notice = curl_exec($ch); echo $notice; ?>
이 코드는 컬을 직접 사용하여 파일 내용을 표시하지만 문제가 있습니다. 컬은 PHP의 확장이기 때문에 일부 호스트는 보안상의 이유로 컬을 사용하고 Ningwai는 PHP를 로컬에서 디버깅할 때 컬을 닫습니다. 오류가 발생해서 이 코드는 바람직하지 않아서 Yunluo가 다시 작성했습니다
<?php
if (function_exists('curl_init')) {
$url = "http://git.oschina.net/yunluo/API/raw/master/notice.txt";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
$dxycontent = curl_exec($ch);
echo $dxycontent;
} else {
echo '汗!貌似您的服务器尚未开启curl扩展,无法收到来自云落的通知,请联系您的主机商开启,本地调试请无视';
}
?>수정된 버전은 서버에서 컬 확장 기능이 켜져 있는지 확인하기 위해 컬 확장 기능을 판단하는 것입니다. 파일을 직접 표시하거나 열려 있지 않은 경우 프롬프트 텍스트를 표시합니다.
문제는 해결됐지만 또 다른 문제가 발생합니다. 텍스트만 표시하고 중요한 작업에는 사용하지 않는데 왜 이렇게 많은 코드를 작성합니까? ?
몇 가지 블라인드 테스트를 거친 후 원격 파일 내용을 얻는 데 file_get_contents가 컬보다 느리지 않다는 사실을 발견했습니다. 어떤 경우에는 파일 수가 적을 경우 컬 확장보다 훨씬 빠를 수 있으므로 코드를 다시 작성했습니다.
<?php echo file_get_contents( "http://git.oschina.net/yunluo/API/raw/master/notice.txt" ); ?>
Tool
FireFox + Firebug
"일을 잘하려면 먼저 도구를 갈고 닦아야 합니다." 사건을 분석하기 전에 먼저 Firebug 아티팩트를 사용하여 필요한 정보를 얻는 방법을 알아보겠습니다.
F12를 사용하여 Firebug를 열면 그림 (1)과 같은 인터페이스를 얻을 수 있습니다.
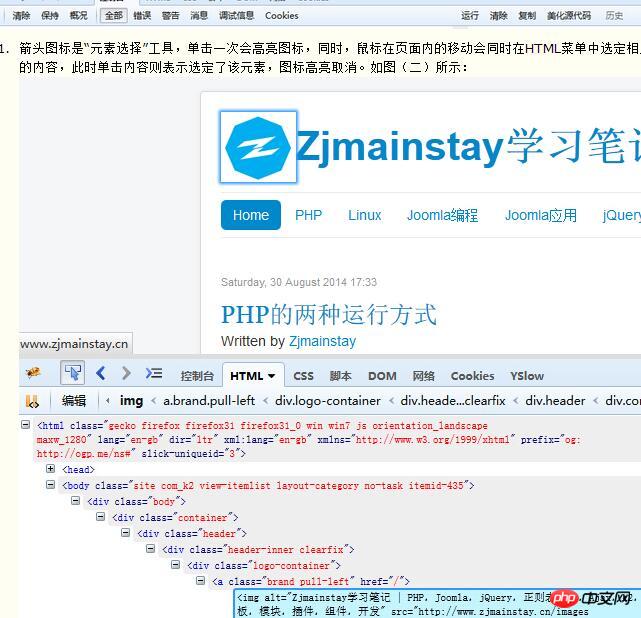
1. 화살표 아이콘은 "요소 선택" 도구입니다. 동시에 아이콘이 강조 표시됩니다. 페이지 내에서 마우스를 움직이면 HTML 메뉴에서 해당 콘텐츠가 선택됩니다. 콘텐츠를 클릭하면 해당 요소가 선택되고 아이콘이 강조 표시됩니다. 그림 (2)와 같이:
Firebug 뷰 요소
2. Console
JS의 console.log 시리즈 기능 인쇄가 여기에 출력됩니다.
3. HTML
HTML 콘텐츠, 여기에 표시되는 내용이 반드시 수집 중에 파싱되는 콘텐츠는 아니라는 점에 유의하세요. 수집 중 콘텐츠 분석은 항상 소스 코드 보기(Ctrl+U)를 기반으로 합니다. 그런 다음 보다 특별한 참조를 선택하고 소스 코드에서 해당 위치를 찾습니다.
예를 들어 HTML에서
Demo
라는 태그를 볼 수 있지만 소스 코드를 볼 때 표시되는 콘텐츠는4. CSS
CSS 파일 내용은 다음과 같습니다
5.Script
Javascript 파일 내용은 다음과 같습니다.
6.DOM
Dom 노드 내용
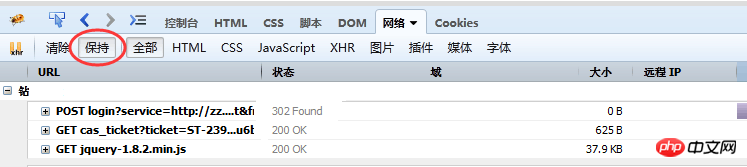
7. 각 요청 링크의 데이터는 여기에서 수집하고 분석합니다. 각 요청의 매개변수, 요청 헤더, 쿠키 데이터 등을 표시할 수 있습니다. 페이지 제출이 새로 고쳐지면 그림 (3)과 같이 새로 고친 후에도 페이지 요청 콘텐츠가 콘솔에 계속 남아 있도록 지속성을 사용해야 합니다.
8. 쿠키
쿠키 데이터
요약 수집 요청을 분석할 때 주로 "네트워크" 메뉴의 요청 데이터를 중요하게 생각합니다. 필요한 경우 "보류"를 사용하여 페이지 새로 고침을 위해 요청 데이터를 볼 수 있습니다. 콘텐츠를 요청하기 전에 다음을 삭제하세요.
사례 분석
1. 단순 수집
여기서 언급하는 단순 수집은 단일 페이지 GET 요청의 수집을 의미합니다. file_get_contents를 통해서도 페이지 반환 결과를 쉽게 얻을 수 있을 정도로 간단합니다. 기능.
<?php $url = 'http://demo.zjmainstay.cn/php/curl/simple.html'; $content = file_get_contents($url); echo $content;
<?php $url = 'http://demo.zjmainstay.cn/php/curl/simple.html'; $ch = curl_init($url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出 $content = curl_exec($ch); //执行并存储结果 curl_close($ch); echo $content;
相关文章推荐:
1.PHP的curl函数的详细介绍(总结)
2.PHP中使用CURL之php curl详细解析和常见大坑
相关视频推荐:
1.独孤九贱(4)_PHP视频教程
二、需要参数的采集
这种情况,页面请求需要传入一些参数,可以是GET请求,也可以是POST请求。这种情况的采集,使用file_get_contents外带一些参数还是可以实现的,但是这里我们将不再展示。
代码片段之cURL GET
这种请求,我们可以选择搜索引擎作为演示,比如我百度搜索一个词语“PHP cURL”,在输入回车后,我们会得到一个类似http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&ch=&tn=baidu&bar=&wd=PHP%20cURL的链接,注意这里的链接可能不同浏览器、不同入口方式访问得到不一样结果,因此不必介意链接是否一样。通过输入多个关键词并观察链接,我们可以确定 wd 参数就是我们要传入的动态参数,而其他参数则可以不变,因此得到我们下面的采集代码。
<?php $keyword = 'PHP cURL'; $url = 'http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&ch=&tn=baidu&bar=&wd=' . urlencode($keyword); $ch = curl_init($url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出 $content = curl_exec($ch); //执行并存储结果 curl_close($ch); echo $content;
有些时候,一些参数并不是必须的,这时候我们可以删掉它,比如上面的链接可以只保留http://www.baidu.com/s?ie=utf-8&wd=PHP%20cURL,ie=utf-8 这个参数可能影响结果的编码,所以暂且留着它。就这样简单的代码,我们就可以采集到百度搜索的结果了。
代码片段之cURL POST
对于POST类型的请求,我们平时并不少见,比如有些搜索就是使用POST方式提交,这时候我们就需要使用POST类型来提交参数了。这个在PHP cURL里面有相应的参数:CURLOPT_POST 和 CURLOPT_POSTFIELDS , CURLOPT_POST 的设置可以指定当前提交是否为POST方式,CURLOPT_POSTFIELDS则用于设定提交的参数,可以是参数串,也可以是参数数组,比如:
curl_setopt($ch, CURLOPT_POSTFIELDS, 'ie=utf-8&wd=PHP%20cURL'); 或 curl_setopt($ch, CURLOPT_POSTFIELDS, array( 'ie' => 'utf-8', 'wd' => 'PHP%20cURL', ));
下面是我做的一个POST模拟搜索PHP POST 搜索,后端是使用了前面的百度关键词搜索,基本原理就是,客户端提交一个关键词到我服务器,我服务器使用该关键词请求百度的搜索,然后得到结果,返回到客户端。
如图(四)是利用Firebug对请求数据的分析,得到我们需要提交的请求链接和请求参数:
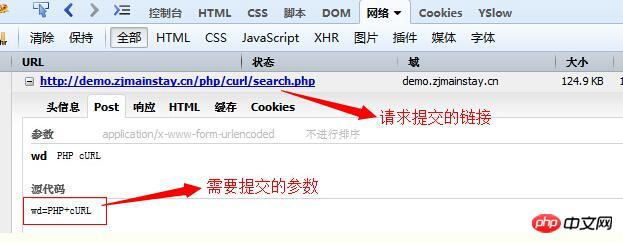
然后下面是我们的代码:
<?php
$keyword = 'PHP cURL';
//参数方法一
// $post = 'wd=' . urlencode($keyword);
//参数方法二
$post = array(
'wd' => urlencode($keyword),
);
$url = 'http://demo.zjmainstay.cn/php/curl/search.php';
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
curl_setopt($ch, CURLOPT_POST, 1); //发送POST类型数据
curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //POST数据,$post可以是数组,也可以是拼接
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
var_dump($content);三、需要Referer的采集
对于一些程序,它可能判断来源网址,如果发现referer不是自己的网站,则拒绝访问,这时候,我们就需要添加CURLOPT_REFERER参数,模拟来路,使得程序能够正常采集。
<?php
$keyword = 'PHP cURL';
//参数方法一
// $post = 'wd=' . urlencode($keyword);
//参数方法二
$post = array(
'wd' => urlencode($keyword),
);
$url = 'http://demo.zjmainstay.cn/php/curl/search_refer.php';
$refer = 'http://demo.zjmainstay.cn/'; //来路地址
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
curl_setopt($ch, CURLOPT_REFERER, $refer); //来路模拟
curl_setopt($ch, CURLOPT_POST, 1); //发送POST类型数据
curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //POST数据,$post可以是数组,也可以是拼接
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
var_dump($content);search_refer.php的源码如下,做了简单的Referer判断拦截:
<?php
if(empty($_POST['wd'])) {
exit('Deny empty params.');
}
//Referer判断
if(stripos($_SERVER['HTTP_REFERER'], $_SERVER['HTTP_HOST']) === false) {
exit('Deny');
}
$keyword = addslashes(trim(strip_tags($_POST['wd'])));
$url = 'http://www.baidu.com/s?ie=utf-8&wd=' . urlencode($keyword);
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
echo $content;四、需要cookie支持的采集
对于模拟登录的应用,单单提交参数和模拟来路并不能解决问题,这时候我们就需要保存或者提交相应的Cookie参数,这个在PHP cURL里面也提供了相应的参数:
CURLOPT_COOKIE: 直接使用字符串方式提交cookie参数
CURLOPT_COOKIEFILE: 使用文件方式提交cookie参数
CURLOPT_COOKIEJAR: 保存提交后反馈的cookie数据
下面是PHP100的模拟登录示例:
<?php
header("content-Type: text/html; charset=UTF-8");
$cookie_file = tempnam('./temp', 'cookie');
$login_url="http://bbs.php100.com/login.php";
$post_fields="cktime=36000&step=2&pwuser=username&pwpwd=password";
//提交登录表单请求
$ch=curl_init($login_url);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_POST,1);
curl_setopt($ch,CURLOPT_POSTFIELDS,$post_fields);
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file); //存储提交后得到的cookie数据
curl_exec($ch);
curl_close($ch);
//登录成功后,获取bbs首页数据
$url="http://bbs.php100.com/index.php";
$ch=curl_init($url);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_COOKIEFILE,$cookie_file); //使用提交后得到的cookie数据做参数
$contents=curl_exec($ch);
curl_close($ch);
//转码显示
echo iconv('gbk', 'UTF-8', $contents);五、压缩网页采集(gzip)
有些没有接触过压缩页面的朋友估计会在这里被坑死,因为他们会发现采集回来的内容是乱码,并且无论使用iconv还是强大的mb_convert_encoding都无法还原数据,然后又没有概念,各种抓狂却找不到方法,哈哈,我曾经也是这样~
如图(五)是乱码表现形式:
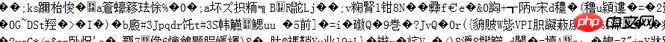
还好最后功夫不负有心人,还是找到了,它就是CURLOPT_ENCODING参数。
比如,采集搜狐的新闻时候就遇到gzip压缩问题,下面是示例:
<?php $url = 'http://news.sohu.com/'; $ch = curl_init($url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出 curl_setopt($ch, CURLOPT_ENCODING, "gzip"); //指定gzip压缩 $content = curl_exec($ch); //执行并存储结果 curl_close($ch); echo $content;
手册说明:支持的编码有"identity","deflate"和"gzip"。如果为空字符串"",请求头会发送所有支持的编码类型。
后面一句表明,使用curl_setopt($ch, CURLOPT_ENCODING, "");也是可以的,但是不能不加这个参数。
六、SSL链接的采集
有些请求链接是https类型的,这时候使用cURL采集可能会失败,这时候,我们可以使用 var_dump(curl_error($ch));的方法打印错误提示,然后根据错误提示查找相应的解决方案。比如SSL错误常见提示:SSL certificate problem: unable to get local issuer certificate,这时候,我们就需要利用参数:CURLOPT_SSL_VERIFYPEER 和 CURLOPT_SSL_VERIFYHOST 来禁用SSL证书的验证,我尝试过只使用CURLOPT_SSL_VERIFYPEER参数禁用失败,所以大家最好同时使用两个参数。
下面是代码示例:
<?php $searchStr = 'RC376981638HK'; $post = 'accion=LocalizaUno&numero='.$searchStr.'&ecorreo=&numeros='; $url = 'https://aplicacionesweb.correos.es/localizadorenvios/track.asp'; $ch = curl_init($url); //初始化curl curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出 curl_setopt($ch, CURLOPT_POST, 1); //发送POST类型数据 curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //POST数据,$post可以是数组,也可以是拼接参数串 curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); //SSL 报错时使用 curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); //SSL 报错时使用 $contents = curl_exec($ch); //执行并存储结果 // var_dump(curl_error($ch)); //获取失败是使用(采集错误提示) curl_close($ch); echo $contents;
七、代理采集
大家都知道,国内存在万恶的墙,所以,假如我们需要获取某些被墙数据时,就需要用到国外代理服务器;又或者我们需要采集大量数据时,需要不断切换IP,也会用到代理。
使用代理在PHP cURL里面有几个相对应的参数:CURLOPT_PROXY、CURLOPT_PROXYPORT 和 CURLOPT_PROXYUSERPWD,还有另外几个,这里不列举。
CURLOPT_PROXY 指定代理IP参数
CURLOPT_PROXYPORT 指定代理端口参数
CURLOPT_PROXYUSERPWD 指定需要验证的代理的账号密码,"[username]:[password]"格式的字符串
关于代理账号获取,大家自己发挥,我这里提供网上搜索到的一个列表:cURL 高匿代理
下面是代理采集示例:
<?php
$url = 'http://demo.zjmainstay.cn/php/curl/dump_ip.php?t=' . time();
echo "本地IP:" . file_get_contents($url) . "\n伪造IP:";
$ip = '183.224.1.116';
$port = '80';
//伪造请求头参数,如果是高匿代理这里不需要提供
$header = array(
'X-FORWARDED-FOR: ' . $ip,
'CLIENT-IP: ' . $ip,
);
$ch = curl_init($url); //初始化curl
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
curl_setopt($ch, CURLOPT_PROXY, $ip);
curl_setopt($ch, CURLOPT_PROXYPORT, $port);
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
echo $content;八、 多线程采集
对于大量采集工作,为了提高采集效率,使用PHP cURL提供的多线程采集是必不可少的。手册上提供的多线程采集例子好像都不太好用,我刚开始也从里面测试了几个例子,但是发现都是执行卡死,根本无法执行完成,前几天突然又测试了一下,然后发现curl_multi_info_read函数下面的Example #1是可以执行的,它的内容在$res上,但是没有打印出来,而且雅虎的请求比较慢,会卡住,前面两个链接都能正常返回。
不过,还好当时的例子不好用,然后我经过搜索找到了一个很厉害的项目,CurlMulti ,它对PHP cURL Multi 进行了一个良性扩展的封装,能够很好地提供采集支持。
关于CurlMulti的使用我就不多介绍,官网上面提供了demo,使用过程有技术难题可以直接加入Q群讨论,作者@Ares 和其他的采集大牛都会提供技术解答帮助。
下面是PHP cURL Multi的一个简单示例:
<?php
$urls = array(
"http://demo.zjmainstay.cn/php/curl/curl_multi_1.php",
"http://demo.zjmainstay.cn/php/curl/curl_multi_2.php",
);
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_RETURNTRANSFER, 1); //不直接输出结果
curl_multi_add_handle($mh, $conn[$i]);
}
$active = null;
$res = array();
do {
$status = curl_multi_exec($mh, $active);
$info = curl_multi_info_read($mh);
if (false !== $info) {
//采集信息处理
$res[] = array(
'content' => curl_multi_getcontent($info['handle']),
'info' => $info,
);
curl_close($info['handle']);
}
} while ($status === CURLM_CALL_MULTI_PERFORM || $active);
curl_multi_close($mh);
var_dump($res);九、302跳转(301跳转)
对于一些应用,比如模拟登录,如果遇上302跳转,会导致cookie丢失而使得模拟登录失败,请求现象如图(六)所示:
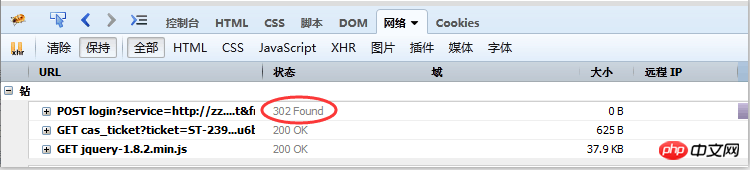
这个时候,可以使用:
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
关于CURLOPT_FOLLOWLOCATION,手册说明是:
启用时会将服务器服务器返回的"Location: "放在header中递归的返回给服务器,使用CURLOPT_MAXREDIRS可以限定递归返回的数量。
我个人理解,通俗点讲就是后面的跳转会继续跟踪访问,而且cookie在header里面被保留了下来。
十、模拟上传文件
在PHP手册的curl_setopt函数中,关于CURLOPT_POSTFIELDS有如下描述:
全部数据使用HTTP协议中的"POST"操作来发送。要发送文件,在文件名前面加上@前缀并使用完整路径。这个参数可以通过urlencoded后的字符串类似'para1=val1¶2=val2&...'或使用一个以字段名为键值,字段数据为值的数组。如果value是一个数组,Content-Type头将会被设置成multipart/form-data。
对于上传文件,这句话包含两个信息:
1. 要上传文件,post的数据参数必须使用数组,使得Content-Type头将会被设置成multipart/form-data。
2. 要上传文件,在文件名前面加上@前缀并使用完整路径。
因此,模拟文件上传可以按照如下实现:
//上传D盘下的test.jpg文件,文件必须存在,否则curl处理失败且没有任何提示 $data = array('name' => 'Foo', 'file' => '@d:/test.jpg'); $ch = curl_init('http://localhost/upload.php'); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $data); curl_exec($ch);
本地测试的时候,在upload.php文件中打印出\\(_POST和\$_FILES即可验证是否上传成功,如下: " print_r($_FILES);
输出结果类似:
Array ( [name] => Foo ) Array ( [file] => Array ( [name] => test.jpg [type] => application/octet-stream [tmp_name] => D:\xampp\tmp\php2EA0.tmp [error] => 0 [size] => 139999 ) )
关于CURLOPT_POSTFIELDS的赋值,另外补充一句描述:
传递一个数组到CURLOPT_POSTFIELDS,cURL会把数据编码成 multipart/form-data,而然传递一个URL-encoded字符串时,数据会被编码成 application/x-www-form-urlencoded。
即:
curl_setopt(\(ch, CURLOPT_POSTFIELDS, 'param1=val1¶m2=val2&...'); 和 curl_setopt(\)ch, CURLOPT_POSTFIELDS, array('param1' => 'val1', 'param2' => 'val2', ...));
这样一个功能强大的采集神器cURL的使用方法为大家介绍到这,希望对大家的学习有所帮助。
以上就是本文的全部内容,希望对大家的学习有所帮助,更多相关内容请关注PHP中文网!
相关推荐:
위 내용은 PHP에서 cURL을 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7711
7711
 15
1640
14
1394
52
1288
25
1232
29
15
1640
14
1394
52
1288
25
1232
29

 Ubuntu 및 Debian용 PHP 8.4 설치 및 업그레이드 가이드
Dec 24, 2024 pm 04:42 PM
Ubuntu 및 Debian용 PHP 8.4 설치 및 업그레이드 가이드
Dec 24, 2024 pm 04:42 PM
PHP 8.4는 상당한 양의 기능 중단 및 제거를 통해 몇 가지 새로운 기능, 보안 개선 및 성능 개선을 제공합니다. 이 가이드에서는 Ubuntu, Debian 또는 해당 파생 제품에서 PHP 8.4를 설치하거나 PHP 8.4로 업그레이드하는 방법을 설명합니다.
 이전에 몰랐던 후회되는 PHP 함수 7가지
Nov 13, 2024 am 09:42 AM
이전에 몰랐던 후회되는 PHP 함수 7가지
Nov 13, 2024 am 09:42 AM
숙련된 PHP 개발자라면 이미 그런 일을 해왔다는 느낌을 받을 것입니다. 귀하는 상당한 수의 애플리케이션을 개발하고, 수백만 줄의 코드를 디버깅하고, 여러 스크립트를 수정하여 작업을 수행했습니다.
 PHP 개발을 위해 Visual Studio Code(VS Code)를 설정하는 방법
Dec 20, 2024 am 11:31 AM
PHP 개발을 위해 Visual Studio Code(VS Code)를 설정하는 방법
Dec 20, 2024 am 11:31 AM
VS Code라고도 알려진 Visual Studio Code는 모든 주요 운영 체제에서 사용할 수 있는 무료 소스 코드 편집기 또는 통합 개발 환경(IDE)입니다. 다양한 프로그래밍 언어에 대한 대규모 확장 모음을 통해 VS Code는
 JWT (JSON Web Tokens) 및 PHP API의 사용 사례를 설명하십시오.
Apr 05, 2025 am 12:04 AM
JWT (JSON Web Tokens) 및 PHP API의 사용 사례를 설명하십시오.
Apr 05, 2025 am 12:04 AM
JWT는 주로 신분증 인증 및 정보 교환을 위해 당사자간에 정보를 안전하게 전송하는 데 사용되는 JSON을 기반으로 한 개방형 표준입니다. 1. JWT는 헤더, 페이로드 및 서명의 세 부분으로 구성됩니다. 2. JWT의 작업 원칙에는 세 가지 단계가 포함됩니다. JWT 생성, JWT 확인 및 Parsing Payload. 3. PHP에서 인증에 JWT를 사용하면 JWT를 생성하고 확인할 수 있으며 사용자 역할 및 권한 정보가 고급 사용에 포함될 수 있습니다. 4. 일반적인 오류에는 서명 검증 실패, 토큰 만료 및 대형 페이로드가 포함됩니다. 디버깅 기술에는 디버깅 도구 및 로깅 사용이 포함됩니다. 5. 성능 최적화 및 모범 사례에는 적절한 시그니처 알고리즘 사용, 타당성 기간 설정 합리적,
 문자열로 모음을 계산하는 PHP 프로그램
Feb 07, 2025 pm 12:12 PM
문자열로 모음을 계산하는 PHP 프로그램
Feb 07, 2025 pm 12:12 PM
문자열은 문자, 숫자 및 기호를 포함하여 일련의 문자입니다. 이 튜토리얼은 다른 방법을 사용하여 PHP의 주어진 문자열의 모음 수를 계산하는 방법을 배웁니다. 영어의 모음은 A, E, I, O, U이며 대문자 또는 소문자 일 수 있습니다. 모음이란 무엇입니까? 모음은 특정 발음을 나타내는 알파벳 문자입니다. 대문자와 소문자를 포함하여 영어에는 5 개의 모음이 있습니다. a, e, i, o, u 예 1 입력 : String = "Tutorialspoint" 출력 : 6 설명하다 문자열의 "Tutorialspoint"의 모음은 u, o, i, a, o, i입니다. 총 6 개의 위안이 있습니다
 PHP에서 HTML/XML을 어떻게 구문 분석하고 처리합니까?
Feb 07, 2025 am 11:57 AM
PHP에서 HTML/XML을 어떻게 구문 분석하고 처리합니까?
Feb 07, 2025 am 11:57 AM
이 튜토리얼은 PHP를 사용하여 XML 문서를 효율적으로 처리하는 방법을 보여줍니다. XML (Extensible Markup Language)은 인간의 가독성과 기계 구문 분석을 위해 설계된 다목적 텍스트 기반 마크 업 언어입니다. 일반적으로 데이터 저장 AN에 사용됩니다
 PHP에서 늦은 정적 결합을 설명하십시오 (정적 : :).
Apr 03, 2025 am 12:04 AM
PHP에서 늦은 정적 결합을 설명하십시오 (정적 : :).
Apr 03, 2025 am 12:04 AM
정적 바인딩 (정적 : :)는 PHP에서 늦은 정적 바인딩 (LSB)을 구현하여 클래스를 정의하는 대신 정적 컨텍스트에서 호출 클래스를 참조 할 수 있습니다. 1) 구문 분석 프로세스는 런타임에 수행됩니다. 2) 상속 관계에서 통화 클래스를 찾아보십시오. 3) 성능 오버 헤드를 가져올 수 있습니다.
 php magic 방법 (__construct, __destruct, __call, __get, __set 등)이란 무엇이며 사용 사례를 제공합니까?
Apr 03, 2025 am 12:03 AM
php magic 방법 (__construct, __destruct, __call, __get, __set 등)이란 무엇이며 사용 사례를 제공합니까?
Apr 03, 2025 am 12:03 AM
PHP의 마법 방법은 무엇입니까? PHP의 마법 방법은 다음과 같습니다. 1. \ _ \ _ Construct, 객체를 초기화하는 데 사용됩니다. 2. \ _ \ _ 파괴, 자원을 정리하는 데 사용됩니다. 3. \ _ \ _ 호출, 존재하지 않는 메소드 호출을 처리하십시오. 4. \ _ \ _ get, 동적 속성 액세스를 구현하십시오. 5. \ _ \ _ Set, 동적 속성 설정을 구현하십시오. 이러한 방법은 특정 상황에서 자동으로 호출되어 코드 유연성과 효율성을 향상시킵니다.
