
의미: 배치문으로 이해될 수 있는 미리 컴파일된 SQL 문 집합
Function:
코드 재사용성 향상
작업 단순화
컴파일 횟수 감소 그리고 데이터베이스 서버에 대한 연결 수를 줄이고 효율성을 향상시킵니다.
과 저장 프로시저의 차이점:
저장 프로시저: 반환이 0개이거나 여러 개일 수 있으며 일괄 삽입 및 일괄 삽입에 적합합니다. 업데이트
함수: 데이터 처리 및 결과 반환에 적합한 반환은 1개뿐입니다.
DELIMITER $ CREATE FUNCTION 函数名(参数列表) RETURNS 返回类型 BEGIN 函数体 END$ DELIMITER ;
참고:
매개변수 목록에는 두 부분이 포함됩니다. 값 유형은 매개변수 이름 매개변수 유형
시작 부분에 선언되어야 합니다.
함수 본문에 return 문이 있어야 하며, 오류가 보고되지 않습니다.
끝 표시를 설정하려면 구분 기호 문을 사용하세요
------------
SELECT 函数名(参数列表)
함수를 호출합니다. 함수에는 반환 값이 있으므로 이 값은 select를 사용하여 인쇄할 수 있습니다.
==========
Case: 총 학생 수 테이블 반환
1.1 함수 만들기
DELIMITER $ CREATE FUNCTION myFun1() RETURNS INT BEGIN DECLARE num INT DEFAULT 0; #定义一个变量 SELECT COUNT(*) INTO num #赋值 FROM student; RETURN num; #返回值 END $ DELIMITER ;
정의됨 컴파일하려면 다음을 실행해야 합니다
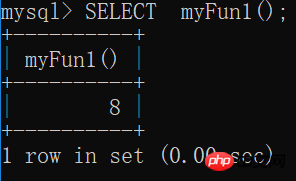
1.2 호출 함수
SELECT myFun1();
----------
케이스: 반환 학생 이름 기준 점수
2.1 기능 만들기
DELIMITER $ CREATE FUNCTION myFun2(stuName VARCHAR(20)) RETURNS INT BEGIN DECLARE grade INT DEFAULT 0; #定义变量 SELECT s.grade INTO grade #赋值 FROM student s WHERE s.name = stuName; RETURN grade; #返回 END $ DELIMITER ;
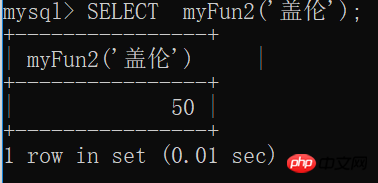
2.2 전화
SELECT myFun2('盖伦');
=========
SHOW CREATE FUNCTION myFun1;
DROP FUNCTION myFun2;
이 글에서는 MySQL 기능 관련 내용을 설명하고 있습니다. 더 많은 관련 권장사항을 보려면 PHP 중국어 웹사이트를 참고하세요.
관련 권장 사항:
Spark SQL은 로그 오프라인 일괄 처리를 구현합니다.
위 내용은 MySQL 함수 관련 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



