
예를 들어 Northwind 데이터베이스에는
SELECT c.CustomerId,CompanyName FROM Customers c
WHERE EXISTS(
SELECT OrderID FROM Orders o WHERE o.CustomerID=c.CustomerID)
EXISTS가 어떻게 작동하나요? 하위 쿼리는 OrderId 필드를 반환하지만 외부 쿼리는 CustomerID 및 CompanyName 필드를 찾고 있습니다. 이 두 필드는 확실히 OrderID에 없습니다.
EXISTS는 하위 쿼리가 하나 이상의 데이터 행을 반환하는지 확인하는 데 사용됩니다. 하위 쿼리는 실제로 데이터를 반환하지 않지만 True 또는 False를 반환합니다.
EXISTS는 행의 존재를 감지하는 하위 쿼리를 지정합니다.
구문: EXISTS 하위 쿼리
매개변수: 하위 쿼리는 제한된 SELECT 문입니다(COMPUTE 절 및 INTO 키워드는 허용되지 않음).
결과 유형: Boolean 하위 쿼리에 행이 포함되어 있으면 TRUE를 반환하고, 그렇지 않으면 FLASE를 반환합니다.
| 예제 테이블 A: TableIn | 예제 테이블 B: TableEx |
|
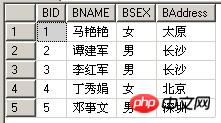 |
(1) 하위 쿼리에 NULL을 사용하면 결과 집합
select * from TableIn where exists(select null) 等同于: select * from TableIn

(2)이 반환됩니다. 두 쿼리 모두 동일한 결과를 반환합니다.
select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME) select * from TableIn where ANAME in(select BNAME from TableEx)
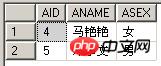
(3) EXISTS 및 = ANY를 사용하여 쿼리를 비교합니다. 두 쿼리 모두 동일한 결과를 반환합니다.
select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME) select * from TableIn where ANAME=ANY(select BNAME from TableEx)
NOT EXISTS는 EXISTS와 정반대입니다. 하위 쿼리가 행을 반환하지 않으면 NOT EXISTS의 WHERE 절이 충족됩니다.
결론:
EXISTS(NOT EXISTS 포함) 절의 반환 값은 BOOL 값입니다. EXISTS 내부에는 하위 쿼리 문(SELECT ... FROM...)이 있는데, 이를 EXIST의 내부 쿼리 문이라고 합니다. 그 안에 있는 쿼리 문은 결과 집합을 반환합니다. EXISTS 절은 쿼리 문의 결과 집합이 비어 있는지 또는 비어 있지 않은지 여부에 따라 부울 값을 반환합니다.
이를 이해하는 가장 일반적인 방법은 테스트로서 외부 쿼리 테이블의 각 행을 내부 쿼리로 대체하는 것입니다. 내부 쿼리에서 반환된 결과가 null이 아닌 값을 취하는 경우 EXISTS 절은 TRUE를 반환하고 이 행은 외부 쿼리 결과 줄로 사용할 수 있습니다. 그렇지 않으면 결과로 사용할 수 없습니다.
분석기는 먼저 문의 첫 번째 단어를 살펴보고 첫 번째 단어가 SELECT 키워드인 것을 발견하면 FROM 키워드로 점프한 다음 FROM 키워드를 통해 테이블 이름을 찾아 테이블을 메모리에 로드합니다. . 다음 단계는 WHERE 키워드를 찾는 것입니다. 찾을 수 없으면 SELECT로 돌아가서 필드 분석을 찾습니다. WHERE가 발견되면 해당 조건을 분석하고 SELECT로 돌아갑니다. 분야를 분석합니다. 마지막으로 가상 테이블이 형성됩니다.
WHERE 키워드 뒤에 오는 것은 조건식입니다. 조건식을 계산한 후 반환 값은 0이 아니거나 0입니다. 0이 아닌 경우 참(true)을 의미하고 0은 거짓(false)을 의미합니다. 마찬가지로 WHERE 뒤의 조건에도 다음에 SELECT를 실행할지 여부를 결정하는 true 또는 false 반환 값이 있습니다.
분석기는 먼저 SELECT 키워드를 찾은 다음 FROM 키워드로 점프하여 STUDENT 테이블을 메모리로 가져오고 포인터를 통해 첫 번째 레코드를 찾은 다음 WHERE 키워드를 찾아 조건식을 계산합니다. 그런 다음 이 레코드를 넣습니다. 가상 테이블에 로드되고 포인터는 다음 레코드를 가리킵니다. false인 경우 포인터는 다른 작업을 수행하지 않고 다음 레코드를 직접 가리킵니다. 항상 전체 테이블을 검색하고 검색된 가상 테이블을 사용자에게 반환합니다. EXISTS는 반환 값(true 또는 false)을 갖는 조건식의 일부입니다.
레코드를 삽입하기 전에 레코드가 이미 존재하는지 확인해야 합니다. 레코드가 존재하지 않는 경우에만 삽입 작업이 수행됩니다. EXISTS 조건문을 사용하면 중복 레코드 삽입을 방지할 수 있습니다.
INSERT INTO TableIn (ANAME,ASEX)
SELECT top 1 'Zhang San', 'Mr' FROM TableIn
WHERE가 존재하지 않습니다(TableIn.AID = 7인 TableIn에서 * 선택)
EXISTS 및 IN 사용 효율성 문제, 정상 하에서 IN은 인덱스를 사용하지 않지만 구체적인 용도는 실제 상황에 따라 다르기 때문에 기존을 사용하는 것이 in보다 더 효율적입니다.
IN은 외부 표면이 크고 내부 테이블이 작은 상황에 적합합니다. 외부 표면은 작고 내부 테이블은 큰 상황.
in, not in, 존재함과 존재하지 않음의 차이점:
먼저 in과 존재함의 차이점에 대해 이야기해 보겠습니다.
exists: 존재함, 그 뒤에 하위 쿼리가 옵니다. 하위 쿼리가 숫자를 반환하는 경우 행 중 존재하면 true를 반환합니다.
select * from class where presents (select'x"form stu where stu.cid=class.cid)
In과 Exists를 쿼리 효율성 측면에서 비교할 때 in 쿼리의 효율성이 Exists의 쿼리 효율성보다 빠릅니다
exists (xxxxx) 후속 하위 쿼리를 상관 하위 쿼리라고 합니다. 목록의 값을 반환하지 않습니다.
단지 true 또는 false 결과를 반환합니다(이것이 하위 쿼리가 'x'를 선택하는 이유입니다. 물론 사용할 수도 있습니다 ).
아무거나 선택) 즉, 괄호 안의 데이터를 찾을 수 있는지, 그러한 레코드가 존재하는지에만 관심이 있습니다.
메인 쿼리를 한 번 실행한 후 해당 결과를 서브 쿼리에서 쿼리하는 방식입니다. 존재하면 true를 반환하면 출력
, 그렇지 않으면 false를 반환합니다. 출력되지 않고 메인 쿼리의 각 행에 따라 쿼리할 하위 쿼리로 이동합니다.
실행 순서는 다음과 같습니다.
1. 먼저 외부 쿼리를 한 번 실행합니다. 외부 쿼리의 각 행은 하위 쿼리가 실행될 때마다 참조됩니다. 외부 쿼리에서
할 때 앞으로 이동할 값입니다. 3. 하위 쿼리의 결과를 사용하여 외부 쿼리의 결과 집합을 결정합니다.
외부 쿼리가 100개의 행을 반환하는 경우 SQL은 쿼리를 101번 실행합니다. 외부 쿼리에 대해 한 번, 그런 다음 외부 쿼리에서 반환된 각 행에 대해 한 번씩
.
in: 모든 여자와 같은 나이인 남자에 대한 쿼리를 포함합니다
select * from stu where sex='male' 및 age in(stu에서 sex='female'인 나이 선택)
in( ) 서브 쿼리는 결과 세트를 반환합니다. 즉, 서브 쿼리는 먼저 결과 세트를 생성한 다음, 메인 쿼리는 요구 사항을 충족하는 필드 목록을 찾기 위해 실행 순서가 다릅니다. . 요구 사항을 충족하는 출력, 그렇지 않으면 출력되지 않습니다.
not in과 존재하지 않음의 차이점:
not in은 하위 쿼리에서 select 키워드 뒤의 필드에 not null 제약 조건이 있거나 그런 힌트가 있습니다. 또한, 메인 쿼리의 테이블이 크고 서브 쿼리의 테이블이 작지만 레코드가 많은 경우에는 not in을 사용해야 합니다.예: 학생이 없는 수업을 쿼리합니다.
select * from class where cid not in(stu와 다른 cid 선택)
테이블에 cid에 대한 null 값이 있는 경우 not in은 null 값을 처리하지 않습니다.
해결책: select * from class
(cid가 null이 아닌 stu에서 고유한 cid 선택)
not in의 실행 순서는 다음과 같습니다. (각 레코드 조회) 요구 사항이 충족되면 결과 집합이 반환됩니다. 요구 사항을 충족하지 않으면 테이블의 레코드가 조회가 완료될 때까지 다음 레코드를 계속 쿼리합니다. 즉, 찾을 수 없다는 것을 증명하기 위해서는 모든 기록을 조회해야만 증명할 수 있다. 인덱스는 사용되지 않습니다.
존재하지 않음: 메인 쿼리 테이블에 레코드가 적고 서브 쿼리 테이블에 레코드가 많으며, 인덱스가 있는 경우입니다. 예: 학생이 없는 수업을 쿼리하려면
select * from class2
(select * from stu1 where stu1.cid =class2.cid)
实例: exists,not exists的使用方法示例,需要的朋友可以参考下。 本文介绍了SQL中EXISTS的用法 ,更多相关内容请关注php中文网。 相关推荐: Sql 四大排名函数(ROW_NUMBER、RANK、DENSE_RANK、NTILE)简介 위 내용은 SQL에서 EXISTS 사용법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
not exists的执行顺序是:在表中查询,是根据索引查询的,如果存在就返回true,如果不存在就返回false,不会每条记录都去查询。
之所以要多用not exists,而不用not in,也就是not exists查询的效率远远高与not in查询的效率。学生表:create table student
(
id number(8) primary key,
name varchar2(10),deptment number(8)
)
选课表:create table select_course
(
ID NUMBER(8) primary key,
STUDENT_ID NUMBER(8) foreign key (COURSE_ID) references course(ID),
COURSE_ID NUMBER(8) foreign key (STUDENT_ID) references student(ID)
)
课程表:create table COURSE
(
ID NUMBER(8) not null,
C_NAME VARCHAR2(20),
C_NO VARCHAR2(10)
)
student表的数据:
ID NAME DEPTMENT_ID
---------- --------------- -----------
1 echo 1000
2 spring 2000
3 smith 1000
4 liter 2000course表的数据:
ID C_NAME C_NO
---------- -------------------- --------
1 数据库 data1
2 数学 month1
3 英语 english1select_course表的数据:
ID STUDENT_ID COURSE_ID
---------- ---------- ----------
1 1 1
2 1 2
3 1 3
4 2 1
5 2 2
6 3 21.查询选修了所有课程的学生id、name:(即这一个学生没有一门课程他没有选的。)
分析:如果有一门课没有选,则此时(1)select * from select_course sc where sc.student_id=ts.id
and sc.course_id=c.id存在null,
这说明(2)select * from course c 的查询结果中确实有记录不存在(1查询中),查询结果返回没有选的课程,
此时select * from t_student ts 后的not exists 判断结果为false,不执行查询。
SQL> select * from t_student ts where not exists
(select * from course c where not exists
(select * from select_course sc where sc.student_id=ts.id and sc.course_id=c.id));
ID NAME DEPTMENT_ID
---------- --------------- -----------
1 echo 10002.查询没有选择所有课程的学生,即没有全选的学生。(存在这样的一个学生,他至少有一门课没有选),
分析:只要有一个门没有选,即select * from select_course sc where student_id=t_student.id and course_id
=course.id 有一条为空,即not exists null 为true,此时select * from course有查询结果(id为子查询中的course.id ),
因此select id,name from t_student 将执行查询(id为子查询中t_student.id )。
SQL> select id,name from t_student where exists
(select * from course where not exists
(select * from select_course sc where student_id=t_student.id and course_id=course.id));
ID NAME
---------- ---------------
2 spring
3 smith
4 liter
3.查询一门课也没有选的学生。(不存这样的一个学生,他至少选修一门课程),
分析:如果他选修了一门select * from course结果集不为空,not exists 判断结果为false;
select id,name from t_student 不执行查询。
SQL> select id,name from t_student where not exists
(select * from course where exists
(select * from select_course sc where student_id=t_student.id and course_id=course.id));
ID NAME
---------- ---------------
4 liter
4.查询至少选修了一门课程的学生。
SQL> select id,name from t_student where exists
(select * from course where exists
(select * from select_course sc where student_id=t_student.id and course_id=course.id));
ID NAME
---------- ---------------
1 echo
2 spring
3 smith
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



