

Node.js의 스레드 및 프로세스에 대한 자세한 분석

이 글은 Node.js의 스레드와 프로세스에 대한 자세한 분석을 제공합니다. 도움이 필요한 친구들이 참고할 수 있기를 바랍니다.
Jani Hartikainen이 작성한 유명한 기사 "PHP가 Node.js보다 나은 5가지 이유"에는 Node.js에 대한 초기 논쟁이 많이 있었습니다. 심지어 직접적인 관점도 있습니다. Node.js의 단일 스레드 취약점 문제를 지적합니다.
PHP 코드가 손상되어도 전체 서버가 다운되지는 않습니다. PHP 코드는 자체 프로세스 범위에서만 실행됩니다. 요청에 오류가 표시되면 특정 요청에만 영향을 미칩니다. Node.js 환경에서는 모든 요청이 단일 프로세스로 처리됩니다. 요청으로 인해 알 수 없는 오류가 발생하면 전체 서버가 영향을 받습니다.
Node.js와 Apache+PHP의 또 다른 매우 다른 점은 프로세스의 실행 시간입니다. 물론 이 기사에서도 PHP가 Node.js보다 나은 이유를 설명합니다.
PHP 프로세스는 수명이 짧습니다. PHP에서는 각 프로세스가 요청에 대해 짧은 시간만 지속되므로 리소스 할당 및 메모리에 대해 걱정할 필요가 없습니다. Node.js 프로세스는 오랜 시간 동안 실행되어야 하며, 메모리 관리에 주의하고 적절하게 관리해야 합니다. 예를 들어 전역 데이터에서 항목을 삭제하는 것을 잊어버린 경우 메모리 누수가 쉽게 발생할 수 있습니다.
여기서 PHP와 Node.js의 우월성을 두고 말싸움을 일으키고 싶지 않습니다. 마치 스포츠카 사이에서 누가 더 나은지를 논하는 것처럼 PHP와 Node.js는 각각 인터넷 시대의 개발 언어를 대표합니다. 오프로드 차량에는 모두 고유한 전문성과 적용 가능한 시나리오가 있습니다. 다음 두 그림을 사용하여 HTTP 요청 처리 시 PHP와 Node.js의 차이점을 더 깊이 이해할 수 있습니다.
PHP 모델:
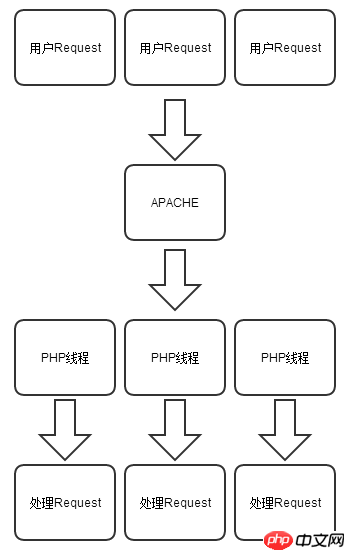
Node.js 모델:
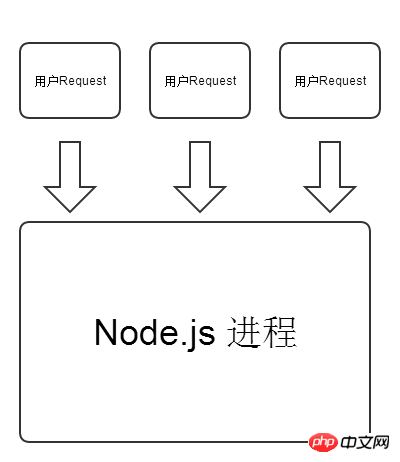
따라서 Node.js 코드를 작성할 때 숨겨진 예외가 트리거된 후에는 전체 Node.js를 염두에 두어야 합니다. 프로세스가 충돌합니다. 하지만 이 기능은 코드를 작성할 때에도 편리함을 제공합니다. 예를 들어 간단한 웹 사이트 방문 횟수를 구현하려면 Node.js는 메모리에 변수 var count=0을 정의하고 사용자가 요청할 때마다 count++를 실행하면 됩니다. .
var http = require('http');
var count = 0;
http.createServer(function (request, response) {
response.writeHead(200, {'Content-Type': 'text/plain'});
response.end((++count).toString())
}).listen(8124);
console.log('Server running at http://127.0.0.1:8124/');하지만 PHP의 경우 웹사이트 방문 횟수를 저장하려면 count.txt 파일을 만드는 등 제3자 매체를 사용하여 카운트 값을 저장해야 합니다.
$counter_file = ("count.txt");
$visits = file($counter_file);
$visits[0]++;
$fp = fopen($counter_file,"w");
fputs($fp,"$visits[0]");
fclose($fp);
echo "$visits[0]";
?>단일 스레드 js
Google의 V8 Javascript 엔진은 Chrome 브라우저에서 성능이 입증되었으므로 Node.js의 작성자인 Ryan Dahl은 v8이 Node.js 효율성을 강화하는 Node.js 실행 엔진으로 v8을 선택했습니다. 성능은 또한 유명한 Nginx와 마찬가지로 Node.js가 단일 스레드를 기반으로 한다는 것을 나타냅니다. 물론 이것은 저자 Ryan Dahl이 Node.js를 디자인한 원래 의도입니다.
단일 스레딩의 장점과 단점
Node.js의 단일 스레딩은 장점이 있지만 완벽하지는 않습니다. 단일 스레드 모델을 유지하면서 어떻게 비차단을 보장합니까?
고성능
우선 싱글 스레드는 기존 PHP처럼 스레드를 자주 생성하고 전환하는 오버헤드를 피하여 실행 속도가 빨라집니다. 둘째, 리소스 사용량이 적습니다. Node.js 웹 서버에서 스트레스 테스트를 수행한 친구는 Node.js의 메모리 사용량이 과부하 상태에서도 여전히 매우 낮다는 것을 알 수 있습니다. 요청당 하나의 스레드는 많은 양의 물리적 메모리를 차지하므로 서버가 물리적 메모리 고갈로 인해 자주 교체되고 응답이 손실될 수 있습니다.
스레드 안전성
단일 스레드 js는 또한 여러 스레드가 동시에 읽고 쓰는 동일한 변수로 인해 발생하는 프로그램 충돌에 대해 걱정할 필요가 없습니다. 예를 들어 이전에 수행했던 웹 액세스 통계는 단일 스레드의 절대적인 스레드 안전성으로 인해 동시에 count 변수를 읽고 쓰는 것이 불가능합니다. 우리의 통계 코드는 수백 개의 동시가 있어도 문제를 일으키지 않습니다. 사용자 요청을 기록하기 위해 파일을 저장하는 PHP의 방법과 비교하면 동시에 파일을 쓰는 문제에 직면하게 됩니다. 스레드 안전은 또한 멀티스레드 프로그래밍에서 변수를 잠그거나 잠금 해제하는 것을 잊어버려서 발생하는 비극으로부터 개발자를 해방시킵니다.
단일 스레드 비동기 및 비차단
Node.js는 단일 스레드이지만 I/O를 비동기 및 비차단으로 만드는 방법은 무엇입니까? 실제로 Node.js는 여전히 멀티스레딩을 사용하여 하위 수준의 I/O에 액세스합니다. 관심 있는 친구들은 libuv를 사용하여 I/O를 처리하는 Node.js의 fs 모듈 소스 코드를 살펴볼 수 있습니다. 의견 Node.js 코드는 비차단형이며 비동기식입니다.
차단/비차단과 비동기/동기화는 서로 다른 개념입니다. 동기화는 차단을 의미하지 않지만 차단은 확실히 동기화를 의미합니다.
举个现实生活中的例子,我去食堂打饭,我选择了A套餐,然后工作人员帮我去配餐,如果我就站在旁边,等待工作人员给我配餐,这种情况就称之为同步;若工作人员帮我配餐的同时,排在我后面的人就开始点餐,这样整个食堂的点餐服务并没有因为我在等待A套餐而停止,这种情况就称之为非阻塞。这个例子就简单说明了同步但非阻塞的情况。
再如果我在等待配餐的时候去买饮料,等听到叫号再回去拿套餐,此时我的饮料也已经买好,这样我在等待配餐的同时还执行了买饮料的任务,叫号就等于执行了回调,就是异步非阻塞了。
阻塞的单线程
既然Node.js是单线程异步非阻塞的,是不是我们就可以高枕无忧了呢?
还是拿上面那个买套餐的例子,如果我在买饮料的时候,已经叫我的号让我去拿套餐,可是我等了好久才拿到饮料,所以我可能在大厅叫我的餐号之后很久才拿到A套餐,这也就是单线程的阻塞情况。
在浏览器中,js都是以单线程的方式运行的,所以我们不用担心js同时执行带来的冲突问题,这对于我们编码带来很多的便利。
但是对于在服务端执行的Node.js,它可能每秒有上百个请求需要处理,对于在浏览器端工作良好的单线程js是否也能同样在服务端表现良好呢?
我们看如下代码:
var start = Date.now();//获取当前时间戳
setTimeout(function () {
console.log(Date.now() - start);
for (var i = 0; i < 1000000000; i++){//执行长循环
}
}, 1000);
setTimeout(function () {
console.log(Date.now() - start);
}, 2000);最终我们的打印结果是:(结果可能因为你的机器而不同)
1000
3738
对于我们期望2秒后执行的setTimeout函数其实经过了3738毫秒之后才执行,换而言之,因为执行了一个很长的for循环,所以我们整个Node.js主线程被阻塞了,如果在我们处理100个用户请求中,其中第一个有需要这样大量的计算,那么其余99个就都会被延迟执行。
其实虽然Node.js可以处理数以千记的并发,但是一个Node.js进程在某一时刻其实只是在处理一个请求。
单线程和多核
线程是cpu调度的一个基本单位,一个cpu同时只能执行一个线程的任务,同样一个线程任务也只能在一个cpu上执行,所以如果你运行Node.js的机器是像i5,i7这样多核cpu,那么将无法充分利用多核cpu的性能来为Node.js服务。
多线程
在C++、C#、python等其他语言都有与之对应的多线程编程,有些时候这很有趣,带给我们灵活的编程方式;但是也可能带给我们一堆麻烦,需要学习更多的Api知识,在编写更多代码的同时也存在着更多的风险,线程的切换和锁也会造成系统资源的开销。
就像上面的那个例子,如果我们的Node.js有创建子线程的能力,那问题就迎刃而解了:
var start = Date.now();
createThread(function () { //创建一个子线程执行这10亿次循环
console.log(Date.now() - start);
for (var i = 0; i < 1000000000; i++){}
});
setTimeout(function () { //因为10亿次循环是在子线程中执行的,所以主线程不受影响
console.log(Date.now() - start);
}, 2000);可惜也可以说可喜的是,Node.js的核心模块并没有提供这样的api给我们,我们真的不想多线程又回归回来。不过或许多线程真的能够解决我们某方面的问题。
tagg2模块
Jorge Chamorro Bieling是tagg(Threads a gogo for Node.js)包的作者,他硬是利用phread库和C语言让Node.js支持了多线程的开发,我们看一下tagg模块的简单示例:
var Threads = require('threads_a_gogo');//加载tagg包
function fibo(n) {//定义斐波那契数组计算函数
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
var t = Threads.create().eval(fibo);
t.eval('fibo(35)', function(err, result) {//将fibo(35)丢入子线程运行
if (err) throw err; //线程创建失败
console.log('fibo(35)=' + result);//打印fibo执行35次的结果
});
console.log('not block');//打印信息了,表示没有阻塞上面这段代码利用tagg包将fibo(35)这个计算丢入了子线程中进行,保证了Node.js主线程的舒畅,当子线程任务执行完毕将会执行主线程的回调函数,把结果打印到屏幕上,执行结果如下:
not block
fibo(35)=14930352
斐波那契数列,又称黄金分割数列,这个数列从第三项开始,每一项都等于前两项之和:0、1、1、2、3、5、8、13、21、……。
注意我们上面代码的斐波那契数组算法并不是最优算法,只是为了模拟cpu密集型计算任务。
由于tagg包目前只能在linux下安装运行,所以我fork了一个分支,修改了部分tagg包的代码,发布了tagg2包。tagg2包同样具有tagg包的多线程功能,采用新的node-gyp命令进行编译,同时它跨平台支持,mac,linux,windows下都可以使用,对开发人员的api也更加友好。安装方法很简单,直接npm install tagg2。
一个利用tagg2计算斐波那契数组的http服务器代码:
var express = require('express');
var tagg2 = require("tagg2");
var app = express();
var th_func = function(){//线程执行函数,以下内容会在线程中执行
var fibo =function fibo (n) {//在子线程中定义fibo函数
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
var n = fibo(~~thread.buffer);//执行fibo递归
thread.end(n);//当线程执行完毕,执行thread.end带上计算结果回调主线程
};
app.get('/', function(req, res){
var n = ~~req.query.n || 1;//获取用户请求参数
var buf = new Buffer(n.toString());
tagg2.create(th_func, {buffer:buf}, function(err,result){
//创建一个js线程,传入工作函数,buffer参数以及回调函数
if(err) return res.end(err);//如果线程创建失败
res.end(result.toString());//响应线程执行计算的结果
})
});
app.listen(8124);
console.log('listen on 8124');其中~~req.query.n表示将用户传递的参数n取整,功能类似Math.floor函数。
我们用express框架搭建了一个web服务器,根据用户发送的参数n的值来创建子线程计算斐波那契数组,当子线程计算完毕之后将结果响应给客户端。由于计算是丢入子线程中运行的,所以整个主线程不会被阻塞,还是能够继续处理新请求的。
我们利用apache的http压力测试工具ab来进行一次简单的压力测试,看看执行斐波那契数组35次,100客户端并发100个请求,我们的QPS (Query Per Second)每秒查询率在多少。
ab的全称是ApacheBench,是Apache附带的一个小工具,用于进行HTTP服务器的性能测试,可以同时模拟多个并发请求。
我们的测试硬件:linux 2.6.4 4cpu 8G 64bit,网络环境则是内网。
ab压力测试命令:
ab -c 100 -n 100 http://192.168.28.5:8124/?n=35
压力测试结果:
Server Software:
Server Hostname: 192.168.28.5
Server Port: 8124
Document Path: /?n=35
Document Length: 8 bytes
Concurrency Level: 100
Time taken for tests: 5.606 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 10600 bytes
HTML transferred: 800 bytes
Requests per second: 17.84 [#/sec](mean)
Time per request: 5605.769 [ms](mean)
Time per request: 56.058 [ms](mean, across all concurrent requests)
Transfer rate: 1.85 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 3 4 0.8 4 6
Processing: 455 5367 599.7 5526 5598
Waiting: 454 5367 599.7 5526 5598
Total: 461 5372 599.3 5531 5602
Percentage of the requests served within a certain time (ms)
50% 5531
66% 5565
75% 5577
80% 5581
90% 5592
95% 5597
98% 5600
99% 5602
100% 5602 (longest request)我们看到Requests per second表示每秒我们服务器处理的任务数量,这里是17.84。第二个我们比较关心的是两个Time per request结果,上面一行Time per request:5605.769 [ms](mean)表示当前这个并发量下处理每组请求的时间,而下面这个Time per request:56.058 [ms](mean, across all concurrent requests)表示每个用户平均处理时间,因为我们本次测试并发是100,所以结果正好是上一行的100分之1。得出本次测试平均每个用户请求的平均等待时间为56.058 [ms]。
另外我们看下最后带有百分比的列表,可以看到50%的用户是在5531 ms以内返回的,最慢的也不过5602 ms,响应延迟非常的平均。
我们如果用cluster来启动4个进程,是否可以充分利用cpu达到tagg2那样的QPS呢?我们在同样的网络环境和测试机上运行如下代码:
var cluster = require('cluster');//加载clustr模块
var numCPUs = require('os').cpus().length;//设定启动进程数为cpu个数
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork();//启动子进程
}
} else {
var express = require('express');
var app = express();
var fibo = function fibo (n) {//定义斐波那契数组算法
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
app.get('/', function(req, res){
var n = fibo(~~req.query.n || 1);//接收参数
res.send(n.toString());
});
app.listen(8124);
console.log('listen on 8124');
}在终端屏幕上打印了4行信息:
listen on 8124
listen on 8124
listen on 8124
listen on 8124
我们成功启动了4个cluster之后,用同样的ab压力测试命令对8124端口进行测试,结果如下:
Server Software:
Server Hostname: 192.168.28.5
Server Port: 8124
Document Path: /?n=35
Document Length: 8 bytes
Concurrency Level: 100
Time taken for tests: 10.509 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 16500 bytes
HTML transferred: 800 bytes
Requests per second: 9.52 [#/sec](mean)
Time per request: 10508.755 [ms](mean)
Time per request: 105.088 [ms](mean, across all concurrent requests)
Transfer rate: 1.53 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 4 5 0.4 5 6
Processing: 336 3539 2639.8 2929 10499
Waiting: 335 3539 2639.9 2929 10499
Total: 340 3544 2640.0 2934 10504
Percentage of the requests served within a certain time (ms)
50% 2934
66% 3763
75% 4527
80% 5153
90% 8261
95% 9719
98% 10308
99% 10504
100% 10504 (longest request)通过和上面tagg2包的测试结果对比,我们发现区别很大。首先每秒处理的任务数从17.84 [#/sec]下降到了9.52 [#/sec],这说明我们web服务器整体的吞吐率下降了;然后每个用户请求的平均等待时间也从56.058 [ms]提高到了105.088 [ms],用户等待的时间也更长了。
最后我们发现用户请求处理的时长非常的不均匀,50%的用户在2934 ms内返回了,最慢的等待达到了10504 ms。虽然我们使用了cluster启动了4个Node.js进程处理用户请求,但是对于每个Node.js进程来说还是单线程的,所以当有4个用户跑满了4个Node.js的cluster进程之后,新来的用户请求就只能等待了,最后造成了先到的用户处理时间短,后到的用户请求处理时间比较长,就造成了用户等待时间非常的不平均。
v8引擎
大家看到这里是不是开始心潮澎湃,感觉js一统江湖的时代来临了,单线程异步非阻塞的模型可以胜任大并发,同时开发也非常高效,多线程下的js可以承担cpu密集型任务,不会有主线程阻塞而引起的性能问题。
但是,不论tagg还是tagg2包都是利用phtread库和v8的v8::Isolate Class类来实现js多线程功能的。
Isolate代表着一个独立的v8引擎实例,v8的Isolate拥有完全分开的状态,在一个Isolate实例中的对象不能够在另外一个Isolate实例中使用。嵌入式开发者可以在其他线程创建一些额外的Isolate实例并行运行。在任何时刻,一个Isolate实例只能够被一个线程进行访问,可以利用加锁/解锁进行同步操作。
换而言之,我们在进行v8的嵌入式开发时,无法在多线程中访问js变量,这条规则将直接导致我们之前的tagg2里面线程执行的函数无法使用Node.js的核心api,比如fs,crypto等模块。如此看来,tagg2包还是有它使用的局限性,针对一些可以使用js原生的大量计算或循环可以使用tagg2,Node.js核心api因为无法从主线程共享对象的关系,也就不能跨线程使用了。
libuv
最后,如果我们非要让Node.js支持多线程,还是提倡使用官方的做法,利用libuv库来实现。
libuv是一个跨平台的异步I/O库,它主要用于Node.js的开发,同时他也被Mozilla's Rust language, Luvit, Julia, pyuv等使用。它主要包括了Event loops事件循环,Filesystem文件系统,Networking网络支持,Threads线程,Processes进程,Utilities其他工具。
在Node.js核心api中的异步多线程大多是使用libuv来实现的,下一章将带领大家开发一个让Node.js支持多线程并基于libuv的Node.js包。
多进程
在支持html5的浏览器里,我们可以使用webworker来将一些耗时的计算丢入worker进程中执行,这样主进程就不会阻塞,用户也就不会有卡顿的感觉了。在Node.js中是否也可以使用这类技术,保证主线程的通畅呢?
cluster
cluster可以用来让Node.js充分利用多核cpu的性能,同时也可以让Node.js程序更加健壮,官网上的cluster示例已经告诉我们如何重新启动一个因为异常而奔溃的子进程。
webworker
想要像在浏览器端那样启动worker进程,我们需要利用Node.js核心api里的child_process模块。child_process模块提供了fork的方法,可以启动一个Node.js文件,将它作为worker进程,当worker进程工作完毕,把结果通过send方法传递给主进程,然后自动退出,这样我们就利用了多进程来解决主线程阻塞的问题。
我们先启动一个web服务,还是接收参数计算斐波那契数组:
var express = require('express');
var fork = require('child_process').fork;
var app = express();
app.get('/', function(req, res){
var worker = fork('./work_fibo.js') //创建一个工作进程
worker.on('message', function(m) {//接收工作进程计算结果
if('object' === typeof m && m.type === 'fibo'){
worker.kill();//发送杀死进程的信号
res.send(m.result.toString());//将结果返回客户端
}
});
worker.send({type:'fibo',num:~~req.query.n || 1});
//发送给工作进程计算fibo的数量
});
app.listen(8124);我们通过express监听8124端口,对每个用户的请求都会去fork一个子进程,通过调用worker.send方法将参数n传递给子进程,同时监听子进程发送消息的message事件,将结果响应给客户端。
下面是被fork的work_fibo.js文件内容:
var fibo = function fibo (n) {//定义算法
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
process.on('message', function(m) {
//接收主进程发送过来的消息
if(typeof m === 'object' && m.type === 'fibo'){
var num = fibo(~~m.num);
//计算jibo
process.send({type: 'fibo',result:num})
//计算完毕返回结果
}
});
process.on('SIGHUP', function() {
process.exit();//收到kill信息,进程退出
});我们先定义函数fibo用来计算斐波那契数组,然后监听了主线程发来的消息,计算完毕之后将结果send到主线程。同时还监听process的SIGHUP事件,触发此事件就进程退出。
这里我们有一点需要注意,主线程的kill方法并不是真的使子进程退出,而是会触发子进程的SIGHUP事件,真正的退出还是依靠process.exit();。
下面我们用ab 命令测试一下多进程方案的处理性能和用户请求延迟,测试环境不变,还是100个并发100次请求,计算斐波那切数组第35位:
Server Software:
Server Hostname: 192.168.28.5
Server Port: 8124
Document Path: /?n=35
Document Length: 8 bytes
Concurrency Level: 100
Time taken for tests: 7.036 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 16500 bytes
HTML transferred: 800 bytes
Requests per second: 14.21 [#/sec](mean)
Time per request: 7035.775 [ms](mean)
Time per request: 70.358 [ms](mean, across all concurrent requests)
Transfer rate: 2.29 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 4 4 0.2 4 5
Processing: 4269 5855 970.3 6132 7027
Waiting: 4269 5855 970.3 6132 7027
Total: 4273 5860 970.3 6136 7032
Percentage of the requests served within a certain time (ms)
50% 6136
66% 6561
75% 6781
80% 6857
90% 6968
95% 7003
98% 7017
99% 7032
100% 7032 (longest request)压力测试结果QPS约为14.21,相比cluster来说,还是快了很多,每个用户请求的延迟都很平均,因为进程的创建和销毁的开销要大于线程,所以在性能方面略低于tagg2,不过相对于cluster方案,这样的提升还是令我们满意的。
换一种思路
使用child_process模块的fork方法确实可以让我们很好的解决单线程对cpu密集型任务的阻塞问题,同时又没有tagg2包那样无法使用Node.js核心api的限制。
但是如果我的worker具有多样性,每次在利用child_process模块解决问题时都需要去创建一个worker.js的工作函数文件,有点麻烦。我们是不是可以更加简单一些呢?
在我们启动Node.js程序时,node命令可以带上-e这个参数,它将直接执行-e后面的字符串,如下代码就将打印出hello world。
node -e "console.log('hello world')"
合理的利用这个特性,我们就可以免去每次都创建一个文件的麻烦。
var express = require('express');
var spawn = require('child_process').spawn;
var app = express();
var spawn_worker = function(n,end){//定义工作函数
var fibo = function fibo (n) {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
end(fibo(n));
}
var spawn_end = function(result){//定义工作函数结束的回调函数参数
console.log(result);
process.exit();
}
app.get('/', function(req, res){
var n = ~~req.query.n || 1;
//拼接-e后面的参数
var spawn_cmd = '('+spawn_worker.toString()+'('+n+','+spawn_end.toString()+'));'
console.log(spawn_cmd);//注意这个打印结果
var worker = spawn('node',['-e',spawn_cmd]);//执行node -e "xxx"命令
var fibo_res = '';
worker.stdout.on('data', function (data) { //接收工作函数的返回
fibo_res += data.toString();
});
worker.on('close', function (code) {//将结果响应给客户端
res.send(fibo_res);
});
});
app.listen(8124);代码很简单,我们主要关注3个地方。
第一、我们定义了spawn_worker函数,他其实就是将会在-e后面执行的工作函数,所以我们把计算斐波那契数组的算法定义在内,spawn_worker函数接收2个参数,第一个参数n表示客户请求要计算的斐波那契数组的位数,第二个end参数是一个函数,如果计算完毕则执行end,将结果传回主线程;
第二、真正当Node.js脚步执行的字符串其实就是spawn_cmd里的内容,它的内容我们通过运行之后的打印信息,很容易就能明白;
第三、我们利用child_process的spawn方法,类似在命令行里执行了node -e "js code",启动Node.js工作进程,同时监听子进程的标准输出,将数据保存起来,当子进程退出之后把结果响应给用户。
现在主要的焦点就是变量spawn_cmd到底保存了什么,我们打开浏览器在地址栏里输入:
http://127.0.0.1:8124/?n=35
下面就是程序运行之后的打印信息,
(function (n,end){
var fibo = function fibo (n) {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1;
}
end(fibo(n));
}(35,function (result){
console.log(result);
process.exit();
}));对于在子进程执行的工作函数的两个参数n和end现在一目了然,n代表着用户请求的参数,期望获得的斐波那契数组的位数,而end参数则是一个匿名函数,在标准输出中打印计算结果然后退出进程。
node -e命令虽然可以减少创建文件的麻烦,但同时它也有命令行长度的限制,这个值各个系统都不相同,我们通过命令getconf ARG_MAX来获得最大命令长度,例如:MAC OSX下是262,144 byte,而我的linux虚拟机则是131072 byte。
多进程和多线程
大部分多线程解决cpu密集型任务的方案都可以用我们之前讨论的多进程方案来替代,但是有一些比较特殊的场景多线程的优势就发挥出来了,下面就拿我们最常见的http web服务器响应一个小的静态文件作为例子。
以express处理小型静态文件为例,大致的处理流程如下: 1、首先获取文件状态,判断文件的修改时间或者判断etag来确定是否响应304给客户端,让客户端继续使用本地缓存。 2、如果缓存已经失效或者客户端没有缓存,就需要获取文件的内容到buffer中,为响应作准备。 3、然后判断文件的MIME类型,如果是类似html,js,css等静态资源,还需要gzip压缩之后传输给客户端 4、最后将gzip压缩完成的静态文件响应给客户端。
下面是一个正常成功的Node.js处理静态资源无缓存流程图:

这个流程中的(2),(3),(4)步都经历了从js到C++ ,打开和释放文件,还有调用了zlib库的gzip算法,其中每个异步的算法都会有创建和销毁线程的开销,所以这样也是大家诟病Node.js处理静态文件不给力的原因之一。
为了改善这个问题,我之前有利用libuv库开发了一个改善Node.js的http/https处理静态文件的包,名为ifile,ifile包,之所以可以加速Node.js的静态文件处理性能,主要是减少了js和C++的互相调用,以及频繁的创建和销毁线程的开销,下图是ifile包处理一个静态无缓存资源的流程图:
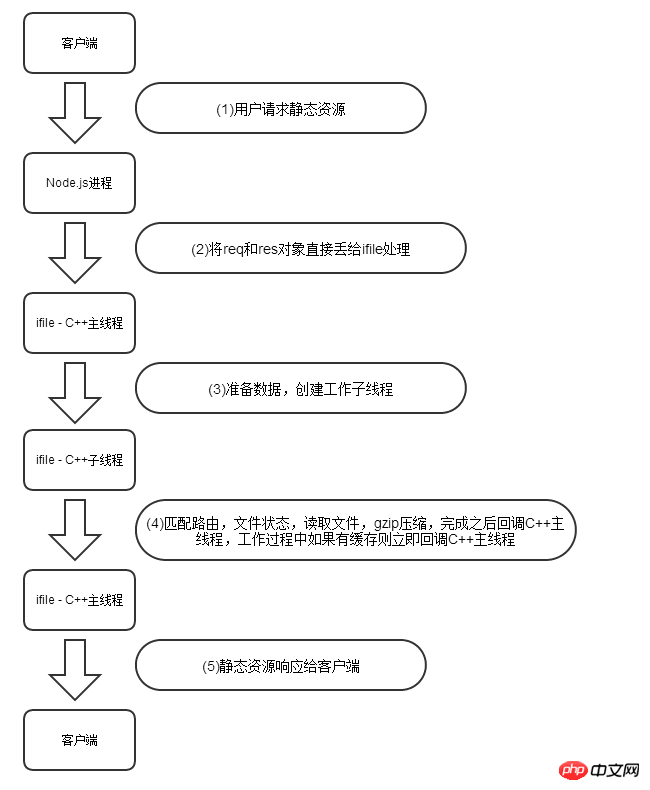
由于全部工作都是在libuv的子线程中执行的,所以Node.js主线程不会阻塞,当然性能也会大幅提升了,使用ifile包非常简单,它能够和express无缝的对接。
var express = require('express');
var ifile = require("ifile");
var app = express();
app.use(ifile.connect()); //默认值是 [['/static',__dirname]];
app.listen(8124);上面这4行代码就可以让express把静态资源交给ifile包来处理了,我们在这里对它进行了一个简单的压力测试,测试用例为响应一个大小为92kb的jquery.1.7.1.min.js文件,测试命令:
ab -c 500 -n 5000 -H "Accept-Encoding: gzip"
http://192.168.28.5:8124/static/jquery.1.7.1.min.js
由于在ab命令中我们加入了-H "Accept-Encoding: gzip",表示响应的静态文件希望是gzip压缩之后的,所以ifile将会把压缩之后的jquery.1.7.1.min.js文件响应给客户端。结果如下:
Server Software:
Server Hostname: 192.168.28.5
Server Port: 8124
Document Path: /static/jquery.1.7.1.min.js
Document Length: 33016 bytes
Concurrency Level: 500
Time taken for tests: 9.222 seconds
Complete requests: 5000
Failed requests: 0
Write errors: 0
Total transferred: 166495000 bytes
HTML transferred: 165080000 bytes
Requests per second: 542.16 [#/sec](mean)
Time per request: 922.232 [ms](mean)
Time per request: 1.844 [ms](mean, across all concurrent requests)
Transfer rate: 17630.35 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 49 210.2 1 1003
Processing: 191 829 128.6 870 1367
Waiting: 150 824 128.5 869 1091
Total: 221 878 230.7 873 1921
Percentage of the requests served within a certain time (ms)
50% 873
66% 878
75% 881
80% 885
90% 918
95% 1109
98% 1815
99% 1875
100% 1921 (longest request)我们首先看到Document Length一项结果为33016 bytes说明我们的jquery文件已经被成功的gzip压缩,因为源文件大小是92kb;其次,我们最关心的Requests per second:542.16 [#/sec](mean),说明我们每秒能处理542个任务;最后,我们看到,在这样的压力情况下,平均每个用户的延迟在1.844 [ms]。
我们看下使用express框架处理这样的压力会是什么样的结果,express测试代码如下:
var express = require('express'); var app = express(); app.use(express.compress());//支持gzip app.use('/static', express.static(__dirname + '/static')); app.listen(8124);
代码同样非常简单,注意这里我们使用:
app.use('/static', express.static(__dirname + '/static'));
而不是:
app.use(express.static(__dirname));
后者每个请求都会去匹配一次文件是否存在,而前者只有请求url是/static开头的才会去匹配静态资源,所以前者效率更高一些。然后我们执行相同的ab压力测试命令看下结果:
Server Software:
Server Hostname: 192.168.28.5
Server Port: 8124
Document Path: /static/jquery.1.7.1.min.js
Document Length: 33064 bytes
Concurrency Level: 500
Time taken for tests: 16.665 seconds
Complete requests: 5000
Failed requests: 0
Write errors: 0
Total transferred: 166890000 bytes
HTML transferred: 165320000 bytes
Requests per second: 300.03 [#/sec](mean)
Time per request: 1666.517 [ms](mean)
Time per request: 3.333 [ms](mean, across all concurrent requests)
Transfer rate: 9779.59 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 173 539.8 1 7003
Processing: 509 886 350.5 809 9366
Waiting: 238 476 277.9 426 9361
Total: 510 1059 632.9 825 9367
Percentage of the requests served within a certain time (ms)
50% 825
66% 908
75% 1201
80% 1446
90% 1820
95% 1952
98% 2560
99% 3737
100% 9367 (longest request)同样分析一下结果,Document Length:33064 bytes表示文档大小为33064 bytes,说明我们的gzip起作用了,每秒处理任务数从ifile包的542下降到了300,最长用户等待时间也延长到了9367 ms,可见我们的努力起到了立竿见影的作用,js和C++互相调用以及线程的创建和释放并不是没有损耗的。
但是当我在express的谷歌论坛里贴上这些测试结果,并宣传ifile包的时候,express的作者TJ,给出了不一样的评价,他在回复中说道:
请牢记你可能不需要这么高等级吞吐率的系统,就算是每月百万级别下载量的npm网站,也仅仅每秒处理17个请求而已,这样的压力甚至于PHP也可以处理掉(又黑了一把php)。
确实如TJ所说,性能只是我们项目的指标之一而非全部,一味的去追求高性能并不是很理智。
ifile包开源项目地址:https://github.com/DoubleSpout/ifile
总结
单线程的Node.js给我们编码带来了太多的便利和乐趣,我们应该时刻保持清醒的头脑,在写Node.js代码中切不可与PHP混淆,任何一个隐藏的问题都可能击溃整个线上正在运行的Node.js程序。
单线程异步的Node.js不代表不会阻塞,在主线程做过多的任务可能会导致主线程的卡死,影响整个程序的性能,所以我们要非常小心的处理大量的循环,字符串拼接和浮点运算等cpu密集型任务,合理的利用各种技术把任务丢给子线程或子进程去完成,保持Node.js主线程的畅通。
스레드/프로세스의 사용에는 오버헤드가 없습니다. 생성되고 파괴되는 스레드/프로세스 수를 최대한 줄이는 것은 시스템의 전반적인 성능과 오류 확률을 향상시킬 수 있습니다.
마지막으로, 높은 처리량 비율을 갖는 시스템이 필요하지 않을 수도 있으므로 맹목적으로 고성능과 높은 동시성을 추구하지 마십시오. 효율적이고 민첩하며 저렴한 개발은 프로젝트에 필요한 것이며, 이는 Node.js가 많은 개발 언어 중에서 돋보일 수 있는 핵심이기도 합니다.
관련 권장사항:
URL이 매개변수를 전달할 때 변수(코드)를 작성하는 방법
JS 튜토리얼 - 동적 프로그래밍 알고리즘 배낭 용량 문제
javaScript의 범위 및 클로저에 대한 지식 설명
위 내용은 Node.js의 스레드 및 프로세스에 대한 자세한 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7509
7509
 15
1378
52
78
11
52
19
19
63
15
1378
52
78
11
52
19
19
63

 Node의 메모리 제어에 관한 기사
Apr 26, 2023 pm 05:37 PM
Node의 메모리 제어에 관한 기사
Apr 26, 2023 pm 05:37 PM
Non-Blocking, Event-Driven 기반으로 구축된 Node 서비스는 메모리 소모가 적다는 장점이 있으며, 대규모 네트워크 요청을 처리하는데 매우 적합합니다. 대규모 요청을 전제로 '메모리 제어'와 관련된 문제를 고려해야 합니다. 1. V8의 가비지 수집 메커니즘과 메모리 제한 Js는 가비지 수집 기계에 의해 제어됩니다.
 Node V8 엔진의 메모리와 GC에 대한 자세한 그래픽 설명
Mar 29, 2023 pm 06:02 PM
Node V8 엔진의 메모리와 GC에 대한 자세한 그래픽 설명
Mar 29, 2023 pm 06:02 PM
이 기사는 NodeJS V8 엔진의 메모리 및 가비지 수집기(GC)에 대한 심층적인 이해를 제공할 것입니다. 도움이 되기를 바랍니다.
 최고의 Node.js Docker 이미지를 선택하는 방법에 대해 이야기해 볼까요?
Dec 13, 2022 pm 08:00 PM
최고의 Node.js Docker 이미지를 선택하는 방법에 대해 이야기해 볼까요?
Dec 13, 2022 pm 08:00 PM
Node용 Docker 이미지를 선택하는 것은 사소한 문제처럼 보일 수 있지만 이미지의 크기와 잠재적인 취약점은 CI/CD 프로세스와 보안에 상당한 영향을 미칠 수 있습니다. 그렇다면 최고의 Node.js Docker 이미지를 어떻게 선택합니까?
 Node의 파일 모듈에 대해 자세히 이야기해 보겠습니다.
Apr 24, 2023 pm 05:49 PM
Node의 파일 모듈에 대해 자세히 이야기해 보겠습니다.
Apr 24, 2023 pm 05:49 PM
파일 모듈은 파일 읽기/쓰기/열기/닫기/삭제 추가 등과 같은 기본 파일 작업을 캡슐화한 것입니다. 파일 모듈의 가장 큰 특징은 모든 메소드가 **동기** 및 ** 두 가지 버전을 제공한다는 것입니다. 비동기**, sync 접미사가 있는 메서드는 모두 동기화 메서드이고, 없는 메서드는 모두 이기종 메서드입니다.
 Node.js 19가 공식적으로 출시되었습니다. Node.js의 6가지 주요 기능에 대해 이야기해 보겠습니다!
Nov 16, 2022 pm 08:34 PM
Node.js 19가 공식적으로 출시되었습니다. Node.js의 6가지 주요 기능에 대해 이야기해 보겠습니다!
Nov 16, 2022 pm 08:34 PM
Node 19가 정식 출시되었습니다. 이 글에서는 Node.js 19의 6가지 주요 기능에 대해 자세히 설명하겠습니다. 도움이 되셨으면 좋겠습니다!
 Node.js의 GC(가비지 수집) 메커니즘에 대해 이야기해 보겠습니다.
Nov 29, 2022 pm 08:44 PM
Node.js의 GC(가비지 수집) 메커니즘에 대해 이야기해 보겠습니다.
Nov 29, 2022 pm 08:44 PM
Node.js는 GC(가비지 수집)를 어떻게 수행하나요? 다음 기사에서는 이에 대해 설명합니다.
 Node의 이벤트 루프에 대해 이야기해 봅시다.
Apr 11, 2023 pm 07:08 PM
Node의 이벤트 루프에 대해 이야기해 봅시다.
Apr 11, 2023 pm 07:08 PM
이벤트 루프는 Node.js의 기본 부분이며 메인 스레드가 차단되지 않도록 하여 비동기 프로그래밍을 가능하게 합니다. 이벤트 루프를 이해하는 것은 효율적인 애플리케이션을 구축하는 데 중요합니다. 다음 기사는 Node.js의 이벤트 루프에 대한 심층적인 이해를 제공할 것입니다. 도움이 되기를 바랍니다!
 노드가 npm 명령을 사용할 수 없으면 어떻게 해야 합니까?
Feb 08, 2023 am 10:09 AM
노드가 npm 명령을 사용할 수 없으면 어떻게 해야 합니까?
Feb 08, 2023 am 10:09 AM
노드가 npm 명령을 사용할 수 없는 이유는 환경 변수가 올바르게 구성되지 않았기 때문입니다. 해결 방법은 다음과 같습니다. 1. "시스템 속성"을 엽니다. 2. "환경 변수" -> "시스템 변수"를 찾은 다음 환경을 편집합니다. 3. nodejs 폴더의 위치를 찾습니다. 4. "확인"을 클릭합니다.
