

대기업 Java 면접 질문 정리 및 정리(전체)
ThreadLocal(스레드 변수 복사본)
Synchronized는 메모리 공유를 구현하고 ThreadLocal은 각 스레드에 대한 로컬 변수를 유지합니다.
스레드 간 데이터 격리에 사용되는 공간을 사용하여 이 변수를 사용하는 각 스레드에 복사본을 제공합니다. 각 스레드는 다른 스레드의 복사본 충돌을 방해하지 않고 독립적으로 자체 복사본을 변경할 수 있습니다.
ThreadLocal 클래스는 각 스레드의 변수 복사본을 저장하는 Map을 유지 관리합니다. Map에 있는 요소의 키는 스레드 개체이고 값은 해당 스레드의 변수 복사본입니다.
ThreadLocal은 Spring에서 큰 역할을 하며 Bean 관리, 트랜잭션 관리, 작업 스케줄링, AOP 및 요청 범위의 기타 모듈에 나타납니다.
Spring의 대부분의 빈은 싱글톤 범위로 선언되고 ThreadLocal을 사용하여 캡슐화될 수 있으므로 상태 저장 빈은 싱글톤 방식으로 멀티 스레드에서 정상적으로 작동할 수 있습니다.
Java Virtual Machine 사양에서는 Java 런타임 데이터를 6가지 유형으로 나눕니다.
1. 프로그램 카운터: 현재 실행 중인 프로그램의 메모리 주소를 저장하는 데 사용되는 데이터 구조입니다. 자바 가상 머신의 멀티스레딩은 스레드를 차례로 전환하고 프로세서 시간을 할당함으로써 이루어진다. 스레드 전환 후 올바른 위치로 돌아가기 위해서는 각 스레드가 서로 영향을 주지 않는 독립적인 프로그램 카운터가 필요하다. 스레드 비공개".
2. Java 가상 머신 스택: 스레드 전용이며 스레드 수명 주기와 동일하며 지역 변수 테이블, 작업 스택 및 메서드 반환 값을 저장하는 데 사용됩니다. 지역 변수 테이블에는 기본 데이터 유형과 개체 참조가 포함됩니다.
3. 로컬 메서드 스택: 가상 머신 스택과 매우 유사하지만 가상 머신에서 사용하는 기본 메서드를 제공합니다.
4.Java 힙: 거의 모든 객체 인스턴스가 메모리를 할당하는 모든 스레드가 공유하는 메모리 영역입니다.
5. 메소드 영역: 각 스레드가 공유하는 영역으로 가상 머신에서 로드한 클래스 정보, 상수, 정적 변수, 컴파일된 코드가 저장됩니다.
6. 런타임 상수 풀: 런타임 시 각 클래스 파일의 상수 테이블을 나타냅니다. 컴파일 시간 숫자 상수, 메소드 또는 필드 참조 등 여러 유형의 상수가 포함됩니다.
"Java GC는 언제, 무엇을, 무엇을 했는지 말씀해 주실 수 있나요?
When:
1. 신세대 에덴 영역이 하나 있고, 서바이벌 영역이 두 개 있습니다." 먼저 개체를 Eden 영역에 배치합니다. 공간이 부족하면 생존 영역 중 하나에 배치합니다. 여전히 배치할 수 없는 경우 새 세대에서 마이너 GC가 트리거되고 살아남은 객체는 해당 영역에 배치됩니다. 에덴 지역에서 다른 생존자 지역으로 이동한 후 에덴과 이전 생존자 지역의 기억을 지웁니다. 특정 GC 프로세스 중에 내려놓을 수 없는 개체가 발견되면 이러한 개체는 이전 세대 메모리에 저장됩니다.
2. 대형 물체와 장기 생존 물체가 노인 구역으로 직접 들어갑니다.
3. 마이너 GC가 실행될 때마다 Old 영역으로 승격될 객체의 크기가 Old 영역의 남은 크기를 초과하는지 분석해야 합니다. 그런 다음 노인 영역에서 최대한 많은 공간을 확보하기 위해 Full GC를 실행합니다.
이란: GC Roots에서는 검색이 안되고, 마크 정리 후에도 아직 부활 개체가 없습니다.
해야 할 일: 젊은 세대: 복사 및 정리; 이전 세대: 마크 스윕 및 마크 압축 알고리즘: 클래스를 Java에 저장하고 클래스를 로드하는 클래스 로더 자체.
GC 루트란 무엇입니까? 1. 가상 머신 스택에서 참조되는 개체 2. 메서드 영역의 정적 속성에서 참조되는 개체, 상수에서 참조되는 개체 3. 로컬 메서드 스택의 JNI(일반적으로 네이티브 메서드) 참조된 객체.
Synchronized와 Lock은 모두 재진입 잠금입니다. 동일한 스레드가 동기화 코드를 다시 입력하면 획득한 잠금을 사용할 수 있습니다.
Synchronized는 비관적인 잠금 메커니즘이자 배타적 잠금입니다. Locks.ReentrantLock은 매번 잠그지는 않지만 충돌이 없다고 가정하고 작업을 완료합니다. 충돌로 인해 실패하면 성공할 때까지 재시도합니다. ReentrantLock 적용 시나리오
잠금 제어를 기다리는 동안 스레드가 중단되어야 함
- #🎜🎜 #잠시 기다려주세요 -notify는 별도로 처리되어야 합니다. ReentrantLock의 조건 애플리케이션은 알릴 스레드를 제어할 수 있으며 잠금은 여러 조건에 바인딩될 수 있습니다.
- 공정한 잠금 기능을 사용하면 들어오는 모든 스레드가 대기열에 대기하게 됩니다.
fail-fast: 메커니즘은 Java 컬렉션(Collection)의 오류 메커니즘입니다. 여러 스레드가 동일한 컬렉션의 콘텐츠에 대해 작동하는 경우 빠른 실패 이벤트가 발생할 수 있습니다.
예: 스레드 A가 반복자를 통해 컬렉션을 순회할 때 컬렉션의 내용이 다른 스레드에 의해 변경된 경우 스레드 A가 컬렉션에 액세스하면 ConcurrentModificationException 예외가 발생하여 실패가 발생합니다. 빠른이벤트happens-before: 두 작업 사이에 before before 관계가 있는 경우 이전 작업의 결과가 이후 작업에 표시됩니다.
1. 프로그램 순서 규칙: 스레드의 각 작업은 스레드의 후속 작업 전에 발생합니다.
2. 모니터 잠금 규칙: 모니터 잠금 해제는 모니터 잠금이 잠기기 전에 발생합니다.
3. 휘발성 변수 규칙: 휘발성 필드에 대한 쓰기는 이 휘발성 필드를 읽기 전에 발생합니다.
4. 전이성: A가 B보다 먼저 발생하고 B가 C보다 먼저 발생하면 A가 C보다 먼저 발생합니다.
5. 스레드 시작 규칙: 이 스레드의 모든 작업 전에 Thread 개체의 start() 메서드가 발생합니다.
휘발성과 동기화에는 네 가지 차이점이 있습니다.
1 세분성이 다릅니다. 전자는 변수를 대상으로 하고 후자는 개체와 클래스를 잠급니다.
2 syn 블록, 휘발성 스레드는 차단하지 않습니다.
3 syn은 세 가지 주요 기능을 보장하고 휘발성은 원자성을 보장하지 않습니다.
4 syn 컴파일러 최적화, 휘발성은 최적화되지 않았습니다. Volatile에는 두 가지 특성이 있습니다:
1. 이 변수의 가시성을 모든 스레드에 보장합니다. 즉, 스레드가 이 변수의 값을 수정하면 새 값이 표시됩니다. 다른 스레드에서는 안전하지 않지만 다중 스레드에서는 안전하지 않습니다.
2. 명령어 재정렬 최적화를 비활성화합니다.
Volatile이 메모리 가시성을 보장하는 방법:
1. 휘발성 변수를 작성할 때 JMM은 스레드에 해당하는 로컬 메모리의 공유 변수를 기본 메모리로 새로 고칩니다.
2. 휘발성 변수를 읽을 때 JMM은 스레드에 해당하는 로컬 메모리를 무효화합니다. 스레드는 다음으로 주 메모리에서 공유 변수를 읽습니다.
동기화: 한 작업의 완료는 다른 작업에 따라 달라집니다. 종속 작업은 종속 작업이 완료될 때까지 기다린 후에만 완료할 수 있습니다.
비동기: 종속 작업이 완료될 때까지 기다릴 필요가 없으며, 완료해야 할 작업을 종속 작업에 알리기만 하면 됩니다. 자체 작업이 완료되면 종속 작업에 다시 알림이 전송됩니다. 완료되었는지. (비동기의 특징은 알림입니다.) 전화 걸기와 문자 메시지 보내기는 동기식 작업과 비동기식 작업에 대한 비유입니다.
Blocking: CPU는 다른 작업을 완료하기 전에 느린 작업이 완료될 때까지 멈추고 기다립니다.
비 차단: 비 차단은 느린 실행 중에 CPU가 다른 작업을 수행하는 것을 의미합니다. 느린 실행이 완료된 후 CPU는 후속 작업을 완료합니다.
비차단을 사용하면 스레드 전환이 증가합니다. 증가된 CPU 사용 시간이 시스템 전환 비용을 보상할 수 있는지 여부를 고려해야 합니다.
CAS(Compare And Swap) 잠금 없는 알고리즘: CAS는 낙관적 잠금 기술입니다. 여러 스레드가 CAS를 사용하여 동일한 변수를 동시에 업데이트하려고 하면 스레드 중 하나만 변수 값을 업데이트할 수 있습니다. , 다른 스레드는 실패합니다. 스레드는 일시 중단되지 않지만 경쟁이 실패했다는 알림을 받고 다시 시도할 수 있습니다. CAS에는 3개의 피연산자, 메모리 값 V, 이전 예상 값 A, 수정될 새 값 B가 있습니다. 예상 값 A와 메모리 값 V가 동일한 경우에만 메모리 값 V를 B로 수정하고, 그렇지 않으면 아무 작업도 수행하지 않습니다.
스레드 풀의 역할: 프로그램이 시작되면 처리에 응답하기 위해 여러 개의 스레드가 생성되며, 이를 스레드 풀이라고 하며, 내부 스레드를 작업 스레드라고 합니다.
첫 번째: 리소스 소비를 줄입니다. 생성된 스레드를 재사용하여 스레드 생성 및 소멸 비용을 줄입니다.
두 번째: 응답 속도를 향상시킵니다. 작업이 도착하면 스레드가 생성될 때까지 기다리지 않고 즉시 작업을 실행할 수 있습니다.
세 번째: 스레드 관리 효율성을 향상시킵니다.
일반적으로 사용되는 스레드 풀: ExecutorService는 주요 구현 클래스이며, 그 중 일반적으로 사용되는 클래스는 Executors.newSingleThreadPool(), newFixedThreadPool(), newcachedTheadPool(), newScheduledThreadPool()입니다.
클래스 로더의 작동 메커니즘:
1. 로딩: Java 바이너리 코드를 jvm으로 가져오고 클래스 파일을 생성합니다.
2. 연결: a) 확인: 로드된 클래스 파일 데이터의 정확성 확인 b) 준비: 클래스의 정적 변수에 대한 저장 공간 할당 c) 구문 분석: 기호 참조를 직접 참조로 변환
3: 초기화: Static 클래스의 경우 변수, 정적 메서드 및 정적 코드 블록은 초기화 작업을 수행합니다.
상위 위임 모델: 클래스 로더가 클래스 로딩 요청을 받으면 먼저 해당 요청을 상위 클래스 로더에 위임하여 사용자 정의 로더->애플리케이션 로더->확장 클래스 로더->클래스 로더 시작을 완료합니다.
일관적 해싱:
Memcahed 캐시:
데이터 구조: 키, 값 쌍
사용 방법: get, put 및 기타 방법
Redis 데이터 구조: 문자열—문자열(키-값 유형)
Hash—사전(해시맵) ) Redis의 해시 구조를 사용하면 데이터베이스에서 속성을 업데이트하는 것처럼 특정 속성 값만 수정할 수 있습니다.
List—목록은 메시지 대기열을 구현합니다.
Set—세트는 고유성을 활용합니다.
Sorted Set—순서가 지정된 세트를 정렬할 수 있습니다. 지속성을 얻을 수 있습니다
Java 자동 박싱 및 언박싱에 대한 심층 분석
Java 반사 메커니즘에 대해 이야기
불변 클래스를 작성하는 방법은 무엇입니까?
인덱스: B+, B-, 전체 텍스트 인덱스
Mysql의 인덱스는 데이터베이스가 데이터를 효율적으로 찾을 수 있도록 설계된 데이터 구조입니다.
일반적으로 사용되는 데이터 구조는 B+Tree입니다. 각 리프 노드는 인덱스 키의 관련 정보를 저장할 뿐만 아니라 인접한 리프 노드에 포인터를 추가하여 순차 액세스 포인터를 사용합니다. 목적은 다양한 간격으로 액세스 성능을 향상시키는 것입니다.
인덱스를 사용하는 경우:
group by, order by 및 고유 키워드 뒤에 자주 나타나는 필드
다른 테이블과 자주 연결되는 테이블은 연결된 필드에 인덱스를 생성해야 합니다.
자주 Where 절에 나타남
쿼리 선택에 사용되는 필드로 자주 나타남
Spring IOC(Inversion of Control, 종속성 주입)
Spring은 속성(Setter 메서드) 주입, 생성자 주입 및 생성자 주입이라는 세 가지 종속성 주입 방법을 지원합니다. 인터페이스 주입.
Spring에서는 애플리케이션을 구성하고 Spring IOC 컨테이너에 의해 관리되는 객체를 빈이라고 합니다.
Spring의 IOC 컨테이너는 Bean을 인스턴스화하고 리플렉션 메커니즘을 통해 Bean 간의 종속성을 설정합니다.
간단히 말하면 Bean은 Spring IOC 컨테이너에 의해 초기화되고, 조립되고, 관리되는 객체입니다.
Bean 객체를 얻는 과정은 먼저 Resource를 통해 구성 파일을 로드하고 IOC 컨테이너를 시작한 다음 getBean 메소드를 통해 Bean 객체를 얻은 다음 해당 메소드를 호출하는 것입니다.
Spring Bean 범위:
싱글톤: Spring IOC 컨테이너에는 공유 Bean 인스턴스가 하나만 있으며 일반적으로 싱글톤 범위입니다.
프로토타입: 각 요청은 새로운 Bean 인스턴스를 생성합니다.
요청: 각 http 요청은 새로운 Bean 인스턴스를 생성합니다.
에이전트의 일반적인 장점: 비즈니스 클래스는 비즈니스 로직 자체에만 집중하면 비즈니스 클래스의 재사용이 보장됩니다.
Java 정적 프록시:
프록시 객체와 대상 객체는 동일한 인터페이스를 구현합니다. 대상 객체는 특정 인터페이스 구현에서 프록시 객체가 해당 호출 전후에 다른 비즈니스 처리 논리를 추가할 수 있습니다. 대상 객체의 메소드.
단점: 하나의 프록시 클래스는 하나의 비즈니스 클래스만 프록시할 수 있습니다. 비즈니스 클래스가 메서드를 추가하는 경우 해당 프록시 클래스도 메서드를 추가해야 합니다.
Java 동적 프록시:
Java 동적 프록시는 InvocationHandler 인터페이스를 구현하고 Invoke 메서드를 재정의하는 클래스를 작성하는 것입니다. Invoke 메서드에서 이 공용 프록시 클래스는 프록시하려는 개체만 명확히 할 수 있습니다. 실행 중일 때 프록시된 클래스의 메소드를 구현할 수 있으며, 클래스 메소드 구현 시 개선 처리를 수행할 수 있습니다.
실제: 프록시 객체 방법 = 향상된 처리 + 프록시 객체 방법
동적 프록시 클래스를 생성하는 JDK와 CGLIB의 차이점:
JDK 동적 프록시는 인터페이스를 구현하는 클래스에 대해서만 프록시(클래스 인스턴스화)를 생성할 수 있습니다. 이때, 프록시 객체와 대상 객체는 동일한 인터페이스를 구현하며, 대상 객체는 프록시 객체의 속성으로 사용되며, 특정 인터페이스 구현에서는 해당 메소드 호출 전후에 다른 비즈니스 처리 로직을 추가할 수 있다. CGLIB는 클래스에 대한 프록시를 구현하며 주로 지정된 클래스의 하위 클래스를 생성하고(클래스를 인스턴스화하지 않고) 그 안에 있는 메서드를 재정의합니다.
Spring AOP 애플리케이션 시나리오
성능 테스트, 접근 제어, 로그 관리, 트랜잭션 등
기본 전략은 대상 클래스가 인터페이스를 구현하는 경우 JDK 동적 프록시 기술을 사용하는 것입니다. 대상 객체가 인터페이스를 구현하지 않으면 기본적으로 CGLIB 프록시가 사용됩니다.
- 클라이언트 요청이 제출됩니다. to DispatcherServlet
- DispatcherServlet 컨트롤러는 HandlerMapping을 쿼리하고 이를 찾아 지정된 컨트롤러에 배포합니다.
- 컨트롤러는 비즈니스 로직 처리를 호출한 후 ModelAndView로 반환됩니다.
- DispatcherServlet은 하나 이상의 ViewResoler 뷰 파서를 쿼리하여 ModelAndView가 지정한 뷰를 찾습니다
- 뷰는 결과를 클라이언트에 표시하는 역할을 담당합니다
DNS 도메인 이름 확인 –> TCP 3방향 핸드셰이크 시작 –> TCP 연결 설정 후 http 요청 시작 –> 서버가 http 요청에 응답하고 브라우저가 html 코드를 받습니다. html 코드를 구문 분석하고 html 코드 리소스(예: javascript, css, 그림 등)를 요청합니다. –> 브라우저가 페이지를 렌더링하여 사용자에게 표시합니다.
세션 및 쿠키: 쿠키를 사용하면 서버가 각 클라이언트의 방문을 추적할 수 있지만, 이러한 쿠키는 각 클라이언트 방문마다 반환되어야 합니다. 쿠키가 많으면 클라이언트와 서버 간의 데이터 전송량이 눈에 띄게 증가합니다.
그리고 Session은 이 문제를 매우 잘 해결합니다. 동일한 클라이언트가 서버와 상호 작용할 때마다 Session을 통해 서버에 데이터를 저장합니다. 매번 모든 쿠키 값을 반환할 필요는 없지만 처음에는 ID를 반환합니다. 클라이언트는 서버에서 생성된 고유 ID에 액세스하므로 클라이언트는 이 ID만 반환하면 됩니다. 이 ID는 일반적으로 이름이 JSESSIONID인 쿠키입니다. 이러한 방식으로 서버는 이 ID를 사용하여 서버에 저장된 KV 값을 검색할 수 있습니다.
세션 및 쿠키 시간 초과 문제, 쿠키 보안 문제
분산 세션 프레임워크
구성 서버, Zookeeper 클러스터 관리 서버는 모든 서버의 구성 파일을 균일하게 관리할 수 있습니다.
이러한 세션 공유는 분산 캐시에 저장되며, 언제든지 쓰고 읽을 수 있으며 Memcache나 Tair처럼 성능이 매우 좋아야 합니다.
HttpSession에서 상속되는 클래스를 캡슐화하고 이 클래스에 세션을 저장한 다음 분산 캐시에 저장합니다.
쿠키는 도메인 간에 액세스할 수 없으므로 세션 동기화를 위해서는 SessionID를 동기화하고 작성해야 합니다. 다른 도메인 이름으로 아래로.
Adapter 모드: 하나의 인터페이스를 다른 인터페이스에 적용합니다. Java I/O의 InputStreamReader는 Reader 클래스를 InputStream에 적용하여 바이트 스트림에서 문자 스트림으로 정확하게 변환합니다.
데코레이터 모드: 원래 인터페이스를 유지하고 원래 기능을 향상시킵니다.
FileInputStream은 InputStream의 모든 인터페이스를 구현합니다. BufferedInputStreams는 FileInputStream에서 상속되며 특정 데코레이터 구현자로서 읽기 성능을 향상시키기 위해 InputStream이 읽은 콘텐츠를 메모리에 저장합니다.
Spring 트랜잭션 구성 방법:
1. 트랜잭션 측면을 구현하는 비즈니스 클래스 메서드를 찾는 데 사용되는 포인트컷 정보
2. 트랜잭션 동작을 제어하는 트랜잭션 속성에는 트랜잭션 격리 수준, 트랜잭션 전파 동작, 타임아웃 기간, 롤백 규칙이 포함됩니다.
Spring은 선언적 트랜잭션 구성을 위해 aop/tx 스키마 네임스페이스와 @Transaction 주석 기술을 사용합니다.
Mybatis
모든 Mybatis 애플리케이션은 SqlSessionFactory 객체의 인스턴스를 중심으로 이루어집니다. 먼저 바이트 스트림을 사용하여 Resource를 통해 구성 파일을 읽은 다음 SqlSessionFactoryBuilder().build 메서드를 통해 SqlSessionFactory를 생성하고 SqlSessionFactory.openSession() 메서드를 통해 각 데이터베이스 트랜잭션을 제공하는 SqlSession을 생성합니다.
Mybatis 초기화의 세 가지 과정 –> SqlSession 생성 –> SQL 문 실행 및 결과 반환
서블릿과 필터의 차이점:
전체 프로세스는 다음과 같습니다. 필터는 사용자 요청을 전처리한 다음 요청을 서블릿에 전달합니다. 응답을 처리 및 생성하고 마지막으로 서버 응답을 필터링하여 사후 처리합니다.
Filter의 용도는 다음과 같습니다.
Filter는 특정 URL 요청 및 응답을 사전 처리하고 사후 처리할 수 있습니다.
HttpServletRequest가 서블릿에 도달하기 전에 클라이언트의 HttpServletRequest를 가로채세요.
필요에 따라 HttpServletRequest를 확인하고 HttpServletRequest 헤더 및 데이터를 수정할 수도 있습니다.
클라이언트에 도달하기 전에 HttpServletResponse를 가로채세요.
필요에 따라 HttpServletResponse를 확인하고 HttpServletResponse 헤더 및 데이터를 수정할 수도 있습니다.
사실 Filter와 Servlet은 매우 유사하지만 유일한 차이점은 Filter가 사용자에게 직접 응답을 생성할 수 없다는 것입니다. 실제로 Filter의 doFilter() 메소드에 있는 코드는 여러 서블릿의 service() 메소드에서 추출된 공통 코드입니다. Filter를 사용하면 더 나은 재사용이 가능합니다.
필터와 서블릿의 수명주기:
1.필터는 웹 서버가 시작될 때 초기화됩니다.
2. 서블릿을 1로 구성하면 Tomcat(서블릿 컨테이너)이 시작될 때 서블릿도 초기화됩니다.
3. 서블릿이 구성되지 않은 경우 1. Tomcat이 시작될 때 서블릿이 초기화되지 않지만 요청이 오면 초기화됩니다.
4. 요청이 이루어질 때마다 요청이 초기화되며, 요청에 응답한 후 해당 요청은 파기됩니다.
5.서블릿이 초기화된 후에는 요청이 종료되어도 로그아웃되지 않습니다.
6. Tomcat이 종료되면 Servlet과 Filter가 차례로 로그아웃됩니다.
HashMap과 HashTable의 차이점.
1. HashMap은 스레드로부터 안전하지 않으며 HashTable은 스레드로부터 안전합니다.
2. HashMap의 키와 값 모두 null 값을 허용하지만 HashTable은 허용하지 않습니다.
3. 스레드 안전 문제로 인해 HashMap이 HashTable보다 더 효율적입니다.
HashMap 구현 메커니즘:
은 각 요소가 연결된 목록이고 연결된 목록의 각 노드가 Entry[] 키-값 쌍의 데이터 구조인 배열을 유지합니다.
배열+연결리스트의 특성, 빠른 검색, 빠른 삽입 및 삭제 기능을 구현합니다.
각 키에 해당하는 배열 인덱스 첨자는 int i = hash(key.hashcode)&(len-1);
새로 추가된 각 노드가 연결 목록의 시작 부분에 배치되고, 그런 다음 새로 추가된 노드는 원래 연결 리스트의 헤드를 가리킵니다
HashMap과 TreeMap의 차이점
HashMap conflict
HashMap, ConcurrentHashMap 및 LinkedHashMap의 차이점
ConcurrentHashMap은 스레드 안전을 보장하기 위해 잠금 분할 기술을 사용합니다. 잠금 분할 기술: 먼저 데이터를 저장하기 위해 세그먼트로 나눈 다음 스레드가 잠금을 점유하면 분할할 때 중 하나에 액세스합니다. 데이터, 다른 세그먼트의 데이터는 다른 스레드에서도 액세스할 수 있습니다
ConcurrentHashMap은 각 세그먼트에서 스레드로부터 안전합니다
LinkedHashMap은 이중 연결 목록을 유지하며 그 안의 데이터를 쓸 수 있습니다. 순차 읽기
ConcurrentHashMap 응용 시나리오
1: ConcurrentHashMap의 응용 시나리오는 동시성이 높지만 스레드 안전성을 보장하지 않습니다. 해당 세그먼트만 잠그면 높은 동시 동기 액세스를 보장하고 효율성을 향상시킬 수 있습니다.
2: 여러 스레드로 작성할 수 있습니다.
ConcurrentHashMap은 HashMap을 여러 세그먼트로 나눕니다
1. 가져올 때 먼저 세그먼트를 찾은 다음 읽기 작업을 위한 헤드 노드를 찾습니다. 값은 휘발성 변수이므로 경쟁 조건이 발생할 경우 최신 값을 읽는 것이 보장됩니다. 읽은 값이 null인 경우 수정 중일 수 있으며 ReadValueUnderLock 함수가 호출되고 잠금이 적용됩니다. 읽은 데이터가 정확합니다.
2. 넣을 때 잠기고 해시 체인의 머리에 추가됩니다.
3. 제거 시에도 잠깁니다. 다음은 최종 유형이므로 변경할 수 없으므로 삭제된 노드 이전의 모든 노드를 복사해야 합니다.
4.ConcurrentHashMap을 사용하면 여러 수정 작업을 동시에 수행할 수 있습니다. 핵심은 잠금 분리 기술을 사용하는 데 있습니다. 여러 잠금을 사용하여 해시 테이블의 다른 세그먼트에 대한 수정을 제어합니다.
ConcurrentHashMap의 적용 시나리오는 동시성이 높지만 스레드 안전성을 보장하지 않습니다. 동기화된 HashMap 및 HashTable은 잠금 후 전체 컨테이너를 잠글 필요가 없으며 해당 세그먼트만 잠그면 됩니다. 좋아요, 그러면 우리는 높은 동시 동기 액세스를 보장하고 효율성을 향상시킬 수 있습니다.
ConcurrentHashMap은 각 호출이 원자적 작업임을 보장하지만 여러 호출이 원자적 작업임을 보장하지는 않습니다.
Vector와 ArrayList의 차이점
ExecutorService 서비스 = Executors.... ExecutorService 서비스 = new ThreadPoolExecutor() ExecutorService 서비스 = new ScheduledThreadPoolExecutor();
ThreadPoolExecutor 소스 코드 분석
스레드 풀 자체의 상태 :
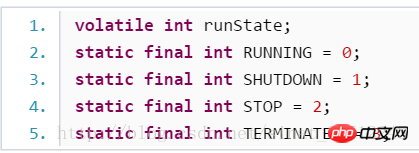
대기 중인 작업 대기열 및 작업 세트:

스레드 풀의 기본 상태 잠금:

스레드 풀 생존 시간 및 크기:

1.2 ThreadPoolExecutor의 내부 작동 원리
함께 위의 Data 정의를 내부적으로 어떻게 구현하는지 살펴보겠습니다. Doug Lea의 전체 아이디어는 5개의 문장으로 요약됩니다.
현재 풀 크기 poolSize가 corePoolSize보다 작은 경우 새 스레드를 만들어 작업을 수행합니다.
현재 풀 크기 poolSize가 corePoolSize보다 크고 대기 대기열이 가득 차지 않은 경우 대기 대기열에 들어갑니다.
현재 풀 크기 poolSize가 corePoolSize보다 크고 maximumPoolSize보다 작은 경우 및 대기 대기열 가득 차면 작업을 실행하기 위해 새 스레드가 생성됩니다.
현재 풀 크기 poolSize가 corePoolSize 및 maximumPoolSize보다 크고 대기 대기열이 가득 찬 경우 거부 정책이 호출되어 작업을 처리합니다.
스레드 풀의 각 스레드는 작업 실행 후 즉시 종료되지 않습니다. 대신, keepAliveTime에서 대기할 수 있는 새 작업이 없는 경우 대기 대기열에 실행해야 하는 스레드 작업이 있는지 확인합니다. , 그러면 스레드가 종료됩니다.
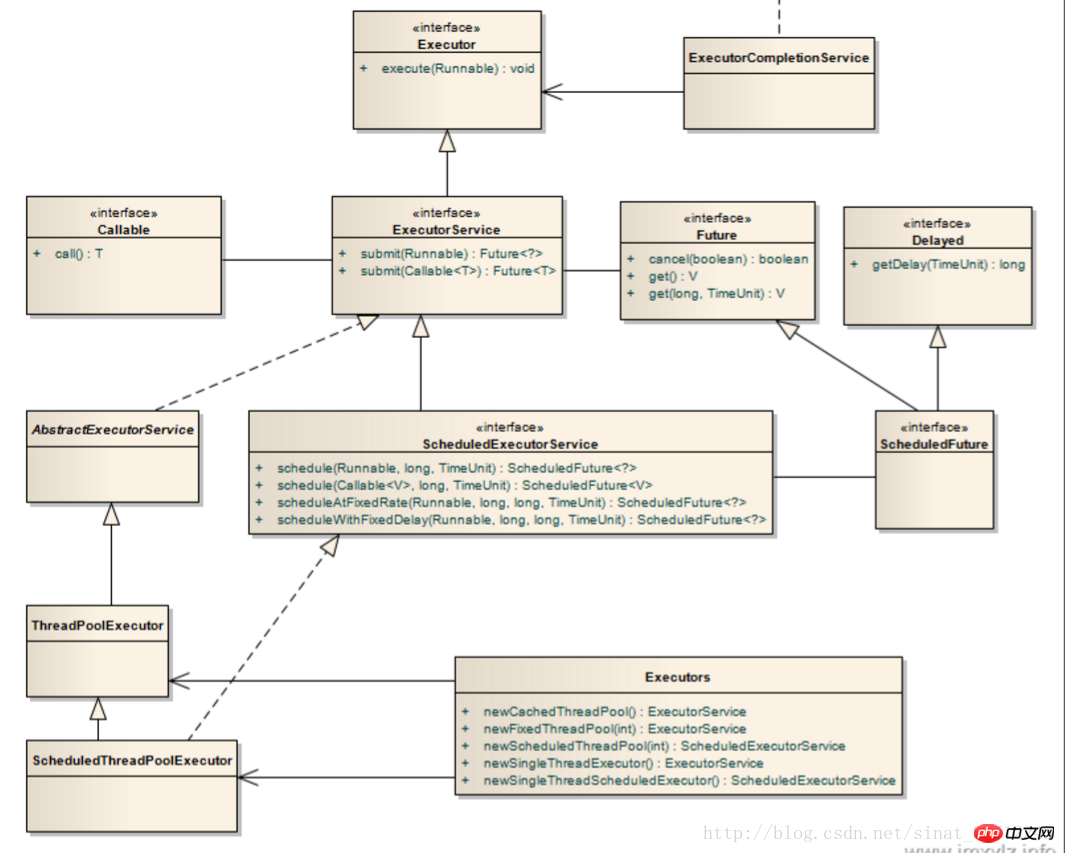
Executor 패키지 구조
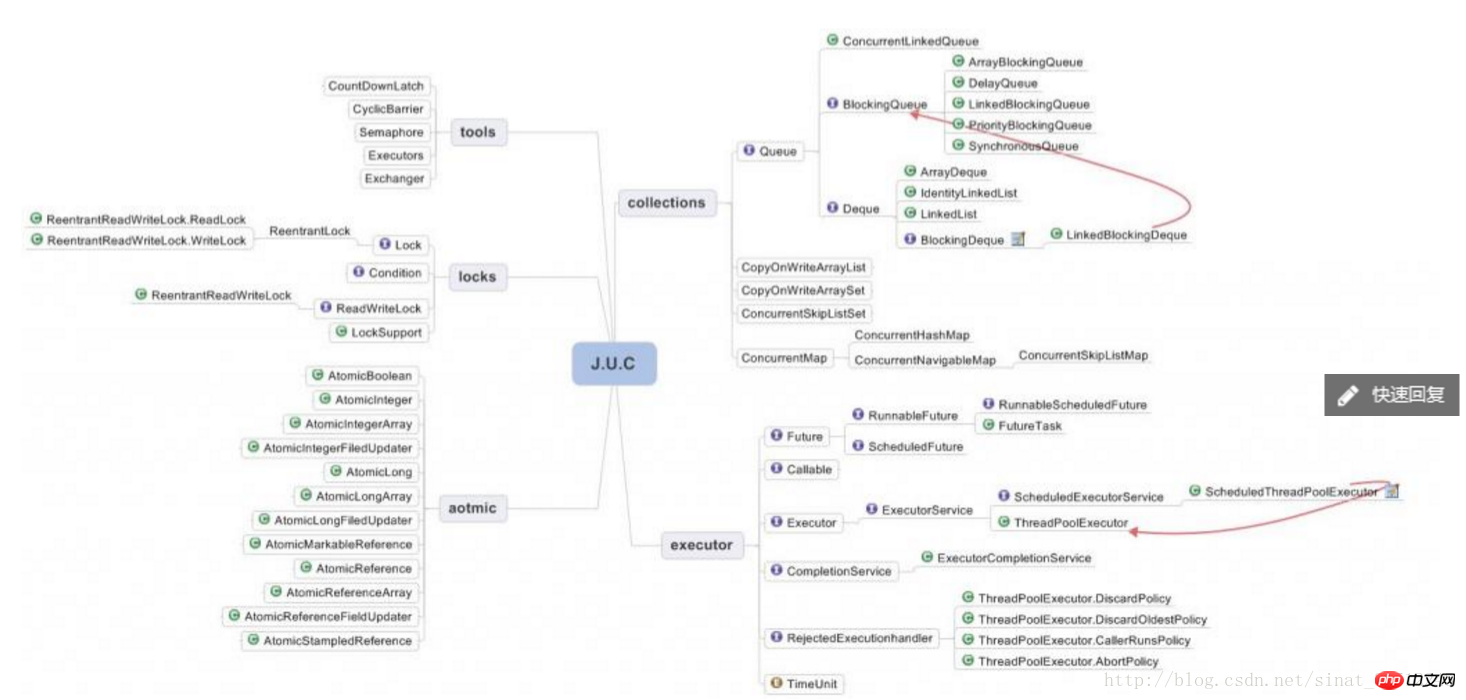
CopyOnWriteArrayList: 요소를 추가할 때 원래 컨테이너를 복사하여 새 컨테이너에 복사한 다음 새 컨테이너에 추가합니다. 컨테이너에 쓰고, 쓴 후 원래 컨테이너의 참조를 새 컨테이너로 지정합니다. 읽을 때는 이전 컨테이너의 데이터를 읽으므로 동시 읽기가 수행될 수 있지만 이는 약한 일관성 전략입니다.
사용 시나리오: CopyOnWriteArrayList는 캐싱과 같이 읽기 작업이 쓰기 작업보다 훨씬 큰 시나리오에 사용하기에 적합합니다.
일반적인 Linux 명령: cd, cp, mv, rm, ps(프로세스), tar, cat(내용 보기), chmod, vim, find, ls
교착 상태에 필요한 조건
상호 배제에는 비공유 상태의 리소스가 하나 이상 있습니다.
점유 및 대기
비선점
루프 대기
교착 상태를 해결하려면 첫 번째가 교착 상태입니다. 위의 4가지 조건이 동시에 유지되도록 하세요. 두 번째는 자원을 합리적으로 배분하는 것입니다.
세 번째는 뱅커 알고리즘을 사용하는 것입니다. 프로세스에서 요청한 남은 리소스 양이 운영 체제에서 충족될 수 있으면 이를 할당합니다.
프로세스 간 통신 방식
파이프(pipe): 파이프는 반이중 통신 방식으로 데이터가 한 방향으로만 흐를 수 있으며, 연관된 프로세스 간에만 사용할 수 있습니다. 프로세스 선호도는 일반적으로 상위-하위 프로세스 관계를 나타냅니다.
Named Pipe: Named Pipe도 반이중 통신 방식이지만 관련 없는 프로세스 간의 통신을 허용합니다.
세마포어: 세마포어는 여러 프로세스에서 공유 리소스에 대한 액세스를 제어하는 데 사용할 수 있는 카운터입니다. 이는 프로세스가 리소스에 액세스할 때 다른 프로세스가 공유 리소스에 액세스하지 못하도록 방지하기 위한 잠금 메커니즘으로 자주 사용됩니다. 따라서 주로 프로세스 간 및 동일한 프로세스 내의 다른 스레드 간 동기화 수단으로 사용됩니다.
메시지 큐(메시지 큐): 메시지 큐는 연결된 메시지 목록으로, 커널에 저장되고 메시지 큐 식별자로 식별됩니다. 메시지 큐는 신호 전송 정보가 적다는 단점, 파이프는 형식화되지 않은 바이트 스트림만 전달할 수 있고 버퍼 크기가 제한된다는 단점을 극복합니다.
신호(sinal): 신호는 이벤트가 발생했음을 수신 프로세스에 알리는 데 사용되는 비교적 복잡한 통신 방법입니다.
공유 메모리: 공유 메모리는 다른 프로세스에서 액세스할 수 있는 메모리 섹션을 매핑하는 것입니다. 이 공유 메모리는 하나의 프로세스에서 생성되지만 여러 프로세스에서 액세스할 수 있습니다. 공유 메모리는 가장 빠른 IPC 방법이며 다른 프로세스 간 통신 방법의 비효율성을 해결하도록 특별히 설계되었습니다. 프로세스 간 동기화 및 통신을 달성하기 위해 세마포어와 같은 다른 통신 메커니즘과 함께 사용되는 경우가 많습니다.
소켓: 소켓은 프로세스 간 통신 메커니즘이기도 하며 다른 통신 메커니즘과 달리 서로 다른 시스템 간의 프로세스 통신에 사용할 수 있습니다.
프로세스와 스레드의 차이점과 연결
운영 체제의 프로세스 스케줄링 알고리즘
컴퓨터 시스템의 계층적 저장 구조에 대한 자세한 설명
데이터베이스 트랜잭션은 하나의 논리적 단위로 수행되는 일련의 작업을 의미합니다. 일의.

MySQL 데이터베이스 최적화 요약
MYSQL 최적화를 위한 일반적인 방법
MySQL 스토리지 엔진 - MyISAM과 InnoDB의 차이점
SQL 데이터베이스의 패러다임에 대하여
Hibernate의 첫 번째 레벨 캐시는 Session에서 제공되므로 Session의 Life Cycle에서 프로그램이 save(), update(), saveOrUpdate() 및 기타 메소드를 호출하고 쿼리 인터페이스를 호출할 때 list, filter, iterate, 해당 객체가 Session 캐시에 없으면 Hibernate 첫 번째 수준 캐시에 추가되며 세션이 닫히면 캐시가 사라집니다.
Hibernate의 첫 번째 수준 캐시는 세션에 내장되어 있으며 어떤 방식으로도 제거하거나 구성할 수 없습니다. 첫 번째 수준 캐시는 엔터티 개체를 캐싱할 때 개체의 기본 키 ID입니다. Map의 Key이며, 해당 값이 엔터티 객체입니다.
Hibernate 2차 캐시: 획득한 모든 데이터 객체를 ID에 따라 2차 캐시에 넣습니다. Hibernate의 2차 캐시 전략은 ID 쿼리에 대한 캐시 전략으로, 데이터가 삭제되거나 업데이트되거나 추가될 때 동시에 캐시가 업데이트됩니다.
프로세스와 스레드의 차이점:
프로세스: 각 프로세스에는 독립적인 코드와 데이터 공간(프로세스 컨텍스트)이 있습니다. 프로세스 간 전환에는 큰 오버헤드가 있습니다.
스레드: 동일한 유형의 스레드는 코드와 데이터 공간을 공유합니다. 각 스레드에는 독립적인 실행 스택과 프로그램 카운터(PC)가 있으며 스레드 전환 오버헤드가 작습니다.
스레드와 프로세스는 생성, 준비, 실행, 차단, 종료의 5단계로 구분됩니다.
다중 프로세스는 운영 체제가 동시에 여러 작업(프로그램)을 실행할 수 있음을 의미합니다.
멀티스레딩은 동일한 프로그램에서 여러 시퀀스 흐름을 실행하는 것을 의미합니다.
Java에서 멀티스레딩을 구현하는 방법에는 세 가지가 있습니다. 하나는 Thread 클래스를 계속 구현하는 것이고, 다른 하나는 Runable 인터페이스를 구현하는 것이고, 세 번째는 Callable 인터페이스를 구현하는 것입니다.
Switch에서 문자열을 매개변수로 사용할 수 있나요?
a. Java 7 이전에는 스위치가 byte, short, char, int 또는 해당 캡슐화 클래스 및 Enum 유형만 지원할 수 있었습니다. Java 7에서는 문자열 지원이 추가되었습니다.
객체의 공개 메서드는 무엇인가요?
a. 메소드는 두 객체가 동일한지 테스트합니다.
b. 메소드 clone은 객체를 복사합니다.
c. getClass 메소드는 inform, informall 및 메소드를 반환합니다. wait는 모두 주어진 객체에 대해 스레드 동기화를 수행하는 데 사용됩니다
Java의 네 가지 참조, 강점과 약점, 사용 시나리오
a. OOM 문제를 해결하려면 소프트 참조와 약한 참조를 사용하세요. 메모리가 부족하면 JVM이 자동으로 이미지 경로와 해당 이미지 객체와 관련된 소프트 참조 간의 매핑 관계를 저장합니다. 이러한 캐시된 이미지 공간을 재활용하여 OOM 문제를 효과적으로 방지합니다.
b. 소프트 액세스 가능한 객체 검색 방법을 통해 Java 객체 캐싱을 구현합니다. 예를 들어 Employee 클래스를 생성하는 경우 매번 직원의 정보를 쿼리해야 하는 경우입니다. 불과 몇 초 전에 쿼리를 했다고 해도 인스턴스를 재구축해야 하기 때문에 시간이 많이 걸린다. 소프트 참조와 HashMap을 결합할 수 있습니다. 먼저 참조를 저장합니다. 소프트 참조 형식으로 Employee 개체의 인스턴스를 참조하고 HashMap에 대한 참조를 저장합니다. 키는 직원의 ID이고 값은 소프트 참조입니다. 반면에 이 개체는 참조를 꺼내어 캐시에 Employee 인스턴스에 대한 소프트 참조가 있는지 확인하는 것입니다. 소프트 참조가 없거나 소프트 참조에서 얻은 인스턴스가 null인 경우 인스턴스를 다시 빌드하고 새로 생성된 인스턴스에 소프트 참조를 저장합니다.
c. 강력한 참조: 개체에 강력한 참조가 있는 경우 가비지 수집기에 의해 재활용되지 않습니다. 현재 메모리 공간이 부족하더라도 JVM은 이를 회수하지 않고 OutOfMemoryError 오류를 발생시켜 프로그램이 비정상적으로 종료됩니다. 강력한 참조와 객체 사이의 연결을 끊으려면 JVM이 적절한 시간에 객체를 재활용하도록 명시적으로 참조를 null에 할당할 수 있습니다.
d. 소프트 참조: 소프트 참조를 사용할 때 메모리 공간이 충분하면 가비지 수집기에 의해 재활용되지 않고 소프트 참조를 계속 사용할 수 있습니다. 메모리가 부족한 경우에만 소프트 참조가 가비지 수집됩니다. 재활용.
e. 약한 참조: 약한 참조가 있는 객체는 수명 주기가 더 짧습니다. JVM이 가비지 수집을 수행할 때 약한 참조 객체가 발견되면 현재 메모리 공간이 충분한지 여부에 관계없이 약한 참조가 재활용되기 때문입니다. 그러나 가비지 수집기는 우선 순위가 낮은 스레드이므로 약한 참조 개체를 빠르게 찾지 못할 수도 있습니다.
f. 가상 참조: 이름에서 알 수 있듯이 객체가 가상 참조만 보유하는 경우 참조가 없는 것과 동일하며 언제든지 가비지 수집기에 의해 재활용될 수 있습니다.
해시코드와 같음의 차이점은 무엇인가요?
a. 두 객체가 동일한지 확인하는 데에도 사용됩니다. Java 컬렉션에는 두 가지 유형이 있습니다. 그 중 set은 요소의 반복 구현을 허용하지 않습니다. 1,000개의 요소가 있는 경우에는 Equal을 사용하여 동일한 개체인지 확인하기 위해 Equal을 1,000번 호출해야 합니다. 이렇게 하면 효율성이 크게 떨어집니다. 해시코드는 실제로 객체의 저장 주소를 반환합니다. 이 위치에 요소가 없으면 바로 위에 요소가 저장됩니다. 이 위치에 요소가 이미 존재하는 경우 이 시점에서 새 항목과 비교하기 위해 동일한 메서드가 호출됩니다. 요소가 동일하면 저장하지 않고 다른 주소로 해시합니다.
Override와 Overload의 의미와 차이점
a. Overload는 이름에서 알 수 있듯이 reloading입니다. 함수 이름은 같지만 매개변수 이름을 가질 수 있다는 뜻입니다. , 반환값, 유형은 동일할 수 없습니다. 즉, 매개변수, 유형, 반환값은 변경될 수 있지만 함수 이름은 변경되지 않습니다.
b. 하위 클래스가 상위 클래스를 상속하면 하위 클래스가 이 함수를 호출할 때 하위 클래스가 자동으로 호출되는 메서드를 정의할 수 있습니다. 상위 클래스는 재정의(재정의)되는 것과 동일합니다.
자세한 내용은 C++의 오버로딩과 다시 쓰기(덮어쓰기)의 차이점에 대한 분석 예제로 이동하여
추상 클래스와 인터페이스의 차이점
a을 볼 수 있습니다. 클래스는 단일 클래스만 상속할 수 있지만 구현할 수 있습니다. 다중 인터페이스
b. 추상화 클래스에는 생성자가 있을 수 있지만 인터페이스에는 생성자가 있을 수 없습니다.
c. 추상 클래스의 모든 메서드는 추상 클래스에서 일부 기본 메서드를 구현하도록 선택할 수 있습니다. 인터페이스에서는 모든 메서드가 추상이어야 합니다
d. 추상 클래스는 정적 메서드를 포함할 수 있지만 인터페이스는 그럴 수 없습니다
e. 추상 클래스는 일반 멤버 변수를 가질 수 있지만 인터페이스는 그럴 수 없습니다.
XML을 구문 분석하는 방법 방법: DOM, SAX, PULL
a.DOM: 메모리 소비: 먼저 xml 문서를 메모리로 읽은 다음 DOM API를 사용하여 트리 구조에 액세스하고 데이터를 얻습니다. 작성하기는 매우 간단하지만 메모리를 많이 소모합니다. 데이터가 너무 크고 휴대폰 성능이 충분하지 않으면 휴대폰이 직접 충돌할 수 있습니다
b.SAX: 높은 구문 분석 효율성, 적은 메모리 사용량, 이벤트 중심: 더 쉽게 말하면 문서를 순차적으로 스캔합니다. 스캔됨), 요소의 시작과 끝, 문서의 끝 등을 이벤트 처리 기능에 알리고 이벤트 처리 기능이 해당 조치를 취한 후 문서가 끝날 때까지 동일한 스캔을 계속합니다.
c.PULL: SAX와 유사하며, next() 메서드를 호출하여 다음 구문 분석 이벤트(즉, 시작 문서, 끝 문서, 시작 태그, 끝 태그)를 가져올 수 있습니다. 요소의 경우 XmlPullParser의 getAttributte() 메서드를 호출하여 속성 값을 가져오거나 해당 nextText()를 호출하여 이 노드의 값을 가져올 수 있습니다.
wait()와 sleep()의 차이점
sleep은 Thread 클래스에서 오고 wait는 Object 클래스에서 옵니다
The process sleep() 메소드를 호출하면 스레드는 객체 잠금을 해제하지 않습니다. 대기 메소드를 호출하는 스레드는 객체 잠금을 해제합니다
sleep은 절전 모드 후에 시스템 리소스를 포기하지 않습니다. 대기는 시스템 리소스를 포기하고 다른 스레드가 CPU를 차지할 수 있습니다
sleep(밀리초)은 절전 시간을 지정해야 하며 시간이 되면 자동으로 깨어납니다
JAVA의 힙과 스택의 차이점, Java의 메모리 메커니즘에 대해 이야기해 보겠습니다
#🎜 🎜#a. 기본 데이터 유형은 변수 및 객체 참조보다 우수합니다. 이들은 모두 스택 b에 할당됩니다. 힙 메모리는 새로운#🎜🎜에 의해 생성된 객체와 배열을 저장하는 데 사용됩니다. #c. 클래스 변수(정적으로 수정된 변수), 프로그램은 로드 시 힙에 클래스 변수에 대한 메모리가 할당되고 힙의 메모리 주소가 스택
d에 저장됩니다. 인스턴스 변수: java 키워드 new를 사용하면 시스템이 이를 힙에 엽니다. 반드시 변수에 할당된 연속적인 공간은 아니며 해시 알고리즘을 통해 분산된 힙 메모리 주소를 기반으로 긴 일련의 숫자로 변환됩니다. 힙에 있는 변수의 "물리적 위치"를 나타냅니다. 인스턴스 변수의 수명 주기 - 인스턴스가 변수 참조가 손실된 후 GC(가비지 수집기)에 의해 재활용 가능한 "목록"에 포함됩니다. ), 그러나 힙에 있는 메모리는 즉시 해제되지 않습니다
e. 지역 변수: 실행 시 메소드 또는 특정 코드 세그먼트(예: for 루프)에서 선언됩니다. 메모리는 스택에 할당됩니다. 지역 변수가 범위를 벗어나면 메모리가 즉시 해제됩니다.
JAVA 다형성 구현 원리# 🎜🎜#
a 추상적인 용어로 다형성은 다음을 의미합니다. 동일한 메시지는 보낸 사람에 따라 다양한 동작을 채택할 수 있습니다. (메시지 전송은 함수 호출입니다) b. 구현 원칙은 동적 바인딩입니다. 프로그램이 호출하는 메서드는 런타임 중에 소스 코드를 추적하면 JVM이 찾을 수 있습니다. 매개변수의 자동 변환을 통해 적절한 방법을 사용합니다. 관련 추천:Java 컬렉션 인터뷰 질문 및 답변 요약
Java 컬렉션 로딩 순서 분석 (면접 질문에 흔히 사용됨)
위 내용은 대기업 Java 면접 질문 정리 및 정리(전체)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7548
7548
 15
1382
52
83
11
57
19
22
90
15
1382
52
83
11
57
19
22
90

 다섯 가지 일반적인 Go 언어 면접 질문과 답변
Jun 01, 2023 pm 08:10 PM
다섯 가지 일반적인 Go 언어 면접 질문과 답변
Jun 01, 2023 pm 08:10 PM
최근 몇 년간 큰 인기를 얻은 프로그래밍 언어로 Go 언어는 많은 기업과 기업에서 인터뷰의 핫스팟이 되었습니다. Go 언어 초보자의 경우 인터뷰 과정에서 관련 질문에 어떻게 대답할지가 탐구해 볼 만한 질문입니다. 초보자가 참고할 수 있는 일반적인 Go 언어 인터뷰 질문 5가지와 답변은 다음과 같습니다. Go 언어의 가비지 수집 메커니즘이 어떻게 작동하는지 소개해주세요. Go 언어의 가비지 수집 메커니즘은 마크 스윕 알고리즘과 3색 표시 알고리즘을 기반으로 합니다. Go 프로그램의 메모리 공간이 충분하지 않으면 Go 가비지 수집기가
 2023년 프론트엔드 React 면접 질문 요약(컬렉션)
Aug 04, 2020 pm 05:33 PM
2023년 프론트엔드 React 면접 질문 요약(컬렉션)
Aug 04, 2020 pm 05:33 PM
잘 알려진 프로그래밍 학습 웹사이트인 PHP 중국어 웹사이트는 프런트 엔드 개발자가 React 인터뷰 장애물을 준비하고 해결하는 데 도움이 되는 몇 가지 React 인터뷰 질문을 편집했습니다.
 2023년 엄선된 웹 프런트엔드 면접 질문과 답변 전체 모음(컬렉션)
Apr 08, 2021 am 10:11 AM
2023년 엄선된 웹 프런트엔드 면접 질문과 답변 전체 모음(컬렉션)
Apr 08, 2021 am 10:11 AM
이 기사에서는 수집할 가치가 있는 몇 가지 선택된 웹 프런트엔드 인터뷰 질문을 요약합니다(답변 포함). 도움이 필요한 친구들이 모두 참고할 수 있기를 바랍니다.
 꼭 마스터해야 할 Angular 면접 질문 50개(컬렉션)
Jul 23, 2021 am 10:12 AM
꼭 마스터해야 할 Angular 면접 질문 50개(컬렉션)
Jul 23, 2021 am 10:12 AM
이 글에서는 반드시 마스터해야 할 Angular 면접 질문 50개를 초급, 중급, 고급의 세 부분으로 분석하여 철저하게 이해하도록 도와줄 것입니다!
 Alibaba 터미널: 하루에 100만 건의 로그인 요청, 8G 메모리, JVM 매개변수를 설정하는 방법은 무엇입니까?
Aug 15, 2023 pm 04:31 PM
Alibaba 터미널: 하루에 100만 건의 로그인 요청, 8G 메모리, JVM 매개변수를 설정하는 방법은 무엇입니까?
Aug 15, 2023 pm 04:31 PM
지난 주 Alibaba Cloud와의 기술 인터뷰에서 동급생이 다음과 같은 질문을 받았습니다. 하루에 100만 건의 로그인 요청이 있는 플랫폼과 8G 메모리를 갖춘 서비스 노드를 가정할 때 JVM 매개변수를 어떻게 설정합니까? 답변이 이상적이지 않다고 생각되면 저에게 와서 검토를 요청하세요.
 면접관: 높은 동시성에 대해 얼마나 알고 있나요? 나: 음...
Jul 26, 2023 pm 04:07 PM
면접관: 높은 동시성에 대해 얼마나 알고 있나요? 나: 음...
Jul 26, 2023 pm 04:07 PM
높은 동시성은 거의 모든 프로그래머가 갖고 싶어하는 경험입니다. 그 이유는 간단합니다. 트래픽이 증가하면 인터페이스 응답 시간 초과, CPU 로드 증가, 잦은 GC, 교착 상태, 대용량 데이터 저장 등과 같은 다양한 기술 문제가 발생하게 됩니다. 이러한 문제는 기술 수준의 지속적인 개선을 촉진할 수 있습니다.
 2023년 Vue 고빈도 면접 질문 공유(답변 분석 포함)
Aug 01, 2022 pm 08:08 PM
2023년 Vue 고빈도 면접 질문 공유(답변 분석 포함)
Aug 01, 2022 pm 08:08 PM
이 기사에서는 수집할 가치가 있는 2023년에 선정된 Vue 고주파 인터뷰 질문(답변 포함)을 요약합니다. 도움이 필요한 친구들이 모두 참고할 수 있기를 바랍니다.
 자주 발생하는 지식 포인트를 익히는 데 도움이 되는 프런트엔드 인터뷰 질문을 살펴보세요. (4)
Feb 20, 2023 pm 07:19 PM
자주 발생하는 지식 포인트를 익히는 데 도움이 되는 프런트엔드 인터뷰 질문을 살펴보세요. (4)
Feb 20, 2023 pm 07:19 PM
매일 10개의 질문이 나옵니다. 100일 후에는 프론트 엔드 인터뷰의 모든 고주파 지식 포인트를 마스터하게 됩니다. ! ! , 기사를 읽으시면서 답변을 직접적으로 보지 않으셨으면 좋겠고, 먼저 자신이 알고 있는지 생각해보시고, 그렇다면 당신의 답변은 무엇입니까? 생각해보시고 답변과 비교해보세요. 물론 제 것보다 더 나은 답변이 있으시면 댓글란에 메시지를 남겨주시고 함께 기술의 아름다움에 대해 토론해 보세요.
