
이 기사는 Java의 JVM 바이트 코드에 대한 자세한 소개를 제공합니다. 이는 특정 참조 가치가 있으므로 도움이 될 수 있습니다.
JVM(Java Basics)에 대한 기사입니다. 원래는 Java 클래스 로딩 메커니즘에 대해 먼저 이야기하고 싶었지만, JVM의 역할은 컴파일러에서 컴파일된 바이트코드를 로드하고 해석하는 것입니다. 따라서 먼저 바이트코드를 이해한 다음 바이트코드를 로드하기 위한 클래스 로딩 메커니즘에 대해 이야기하는 것이 더 좋을 것 같아서 이 기사에서는 바이트코드에 대한 자세한 설명으로 변경합니다.
Java의 순수한 객체 지향 특성으로 인해 바이트코드가 클래스의 정보를 나타낼 수 있는 한 JVM이 한 클래스의 정보를 로드할 수 있는 한 전체 Java 프로그램을 나타낼 수 있습니다. 전체 프로그램. 따라서 바이트코드이든 JVM 로딩 메커니즘이든 클래스에 중점을 둡니다. 내 주요 관심사는 다음과 같습니다.
1 바이트코드가 메모리에 한꺼번에 로드되지 않기 때문에 JVM은 로드하려는 클래스 정보가 .class 파일에 있는 위치를 어떻게 알 수 있습니까?
2. 바이트코드는 클래스 정보를 어떻게 표현하나요?
3. 바이트코드가 프로그램을 최적화하나요?
첫 번째 질문은 매우 간단합니다. 소스 파일에 클래스가 많더라도(공용 클래스는 하나만) 컴파일러는 각 클래스에 대해 .class 파일을 생성하고 JVM은 필요한 클래스 이름에 따라 이를 로드하기 때문입니다. 로드하면 됩니다.
다음 문제를 해결하기 위해 먼저 바이트코드 구성을 살펴보겠습니다(Mac에서 Hex Fiend로 열기).
이 코드의 경우:
package com.test.main1;
public class ByteCodeTest {
int num1 = 1;
int num2 = 2;
public int getAdd() {
return num1 + num2;
}
}
class Extend extends ByteCodeTest {
public int getSubstract() {
return num1 - num2;
}
}안의 Extend 클래스를 분석해 보겠습니다.
Hex Fiend를 사용하여 다음과 같이 컴파일된 .class 파일을 엽니다(16진수 코드):
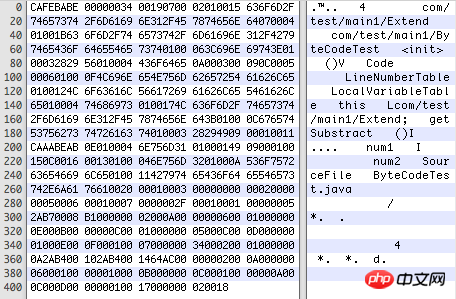
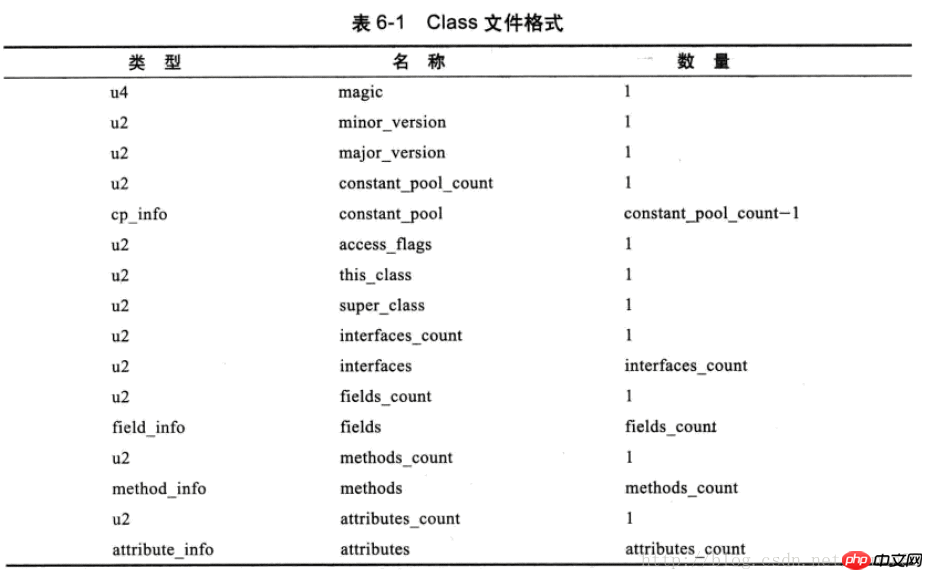
클래스 파일에는 구분 기호가 없으므로 각 위치가 나타내는 형식, 각 부분의 길이 등은 strict 규정 은 사라졌습니다. 아래 표를 참조하세요.
여기서 u1, u2, u4, u8은 여러 바이트의 부호 없는 숫자를 나타냅니다. 디컴파일된 16진수 파일에서 두 숫자는 1바이트, 즉 u1을 나타냅니다.
처음부터 끝까지 하나씩 살펴보세요:
(1) Magic: u4, 매직 넘버는 이 파일이 .class 파일이라는 뜻입니다. .jpg 등에도 이 매직 넘버가 있기 때문에 *.jpg가 *.123으로 변경되어도 평소대로 열 수 있습니다.
(2) 마이너 버전, 메이저 버전: 각 u2, 버전 번호, 이전 버전과 호환 가능, 즉 상위 버전 JDK는 하위 버전 .class 파일을 사용할 수 있지만 그 반대는 불가능합니다.
(3) Constant_pool_count: u2, 상수 풀에 있는 상수의 개수, 0019는 24를 나타냅니다.
(4) 다음은 총 상수_풀_카운트-1인 특정 상수입니다.
상수 풀은 일반적으로 두 가지 유형의 데이터를 저장합니다.
리터럴: 문자열, 최종 수정된 상수 등
기호 참조: 클래스/인터페이스의 정규화된 이름, 메서드 이름 및 설명, 필드 이름 및 설명 등
디컴파일된 숫자를 바탕으로 먼저 아래 표를 확인하여 상수의 유형과 길이를 확인하세요. 찾은 길이와 같은 다음 숫자는 상수의 구체적인 값을 나타냅니다.
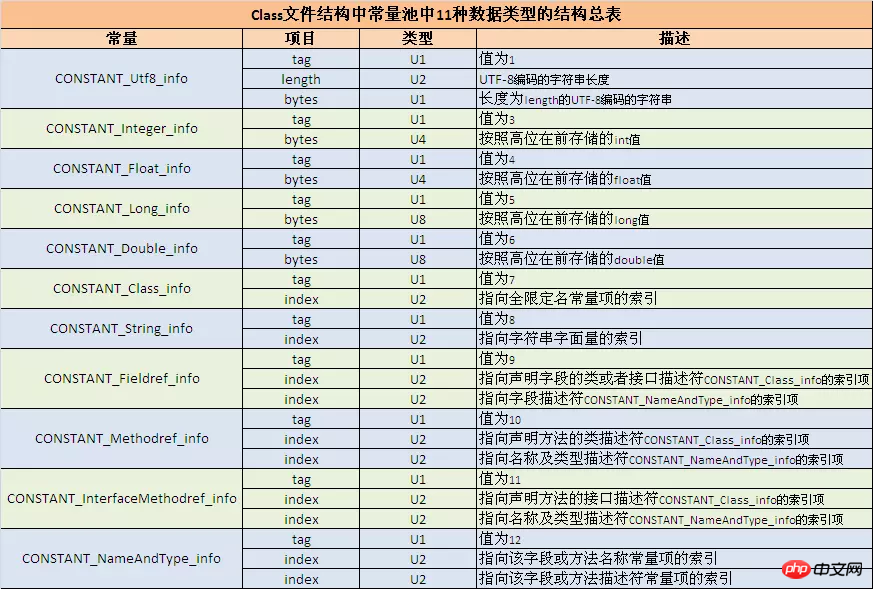
예를 들어 070002는 유형이 CONSTANT_Class_info이고 해당 태그가 u1이며 u2의 길이가 정규화된 이름 상수 항목을 가리키는 인덱스임을 의미합니다. 이 인덱스는 javap -verbose로 연 클래스 파일과 함께 보아야 합니다. 상수 풀의 내용과 순서는 여기에 명확하게 나열되어 있습니다.
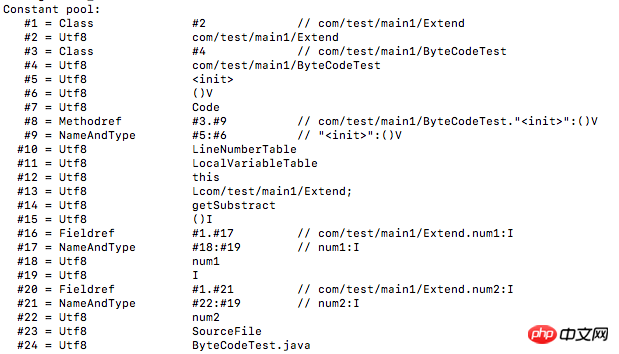
여기에서 0002 인덱스 항목의 상수는 다음과 같습니다. /test/main1/Extend는 클래스의 정규화된 이름입니다. 값이 문자열인 경우 값을 십진수로 변환하고 ASCII 코드 테이블을 확인하여 특정 문자를 가져와야 합니다. 다음 상수는 다음과 같이 분석됩니다.
01001563 6F6D2F74 6573742F 6D61696E 312F4578 74656E64:com/test/main1/Extend
070004:com/test/main1/ByteCodeTest
01001B 63 6F6D2F74 6573742F 6D61696E 312F4279 7465436F 64655465 7374: com/test /main1/ByteCodeTest
0100063C 696E6974 3E:
01000328 2956: ()V
01000443 6F6465: Code
0A000300 09: com/test/main 1/Byte CodeTest、"<초기화>":( ) V
0C000500 06:
01000F4C 696E654E 756D6265 72546162 6C65: LineNumberTable
0100124C 6F63616C 56617269 61626C65 5461626C 65: LocalVariableTable
01000474 686973: this
0100174C 636F6D2F 74657374 2F6D6169 6E312F45 7874656E 643B: Lcom /test/main1/Extend;
01000C67 65745375 62737472 616374: getSubstract
01000328 2949: ()I
09000100 11: com/test/main1/Extend、num1:I
0C001200 13:num1、I
0100046E 756D31: num1
01000149: I
09000100 15: com/test/main1/Extend, num2: I
0C001600 13: num2, I
0100046E 756D32: 2
01 000A53 6F757263 6546696C 65: 소스파일
01001142 79746543 6F646554 6573742E 6A617661: ByteCodeTest.java
이 시점에서 상수 풀의 모든 상수가 구문 분석되었습니다.
(5) 다음은 u2의 access_flags입니다. access_flags 액세스 플래그의 주요 목적은 클래스인지 인터페이스인지, 액세스 권한이 공개인지, 추상인지를 표시하는 것입니다. , 최종으로 표시되었는지 여부 등은 아래 표를 참조하세요.
| Flag_name | Value | 해석 |
| ACC_PUBLIC | 0x0001 | 은 액세스 권한이 공개되어 다음에서 액세스할 수 있음을 의미합니다. 이 패키지 외부 |
| ACC_FINAL | 0x0010 | 은 final에 의해 수정되었으며 하위 클래스가 허용되지 않음을 의미합니다 |
| ACC_SUPER | 0x0020 | 은 특별해요, 동적 바인딩이 직접 상위 클래스임을 나타냅니다. 아래 설명을 참조하세요. |
| ACC_INTERFACE | 0x0200 | 은 클래스가 아닌 인터페이스를 나타냅니다. |
| ACC_ABSTRACT | 0x0400 | 추상 클래스를 나타내며 인스턴스화할 수 없습니다. 변경 |
| ACC_SYNTHETIC | 0x1000 | 은 합성에 의해 수정되었으며 소스 코드에 표시되지 않음을 의미합니다. 부록 [2] |
| ACC_ANNOTATION | 0x2000 | 은 주석 유형 |
| ACC_ENUM | 0x4000 | 열거형이라는 뜻입니다 |
所以,本类中的access_flags是0020,表示这个Extend类调用父类的方法时,并非是编译时绑定,而是在运行时搜索类层次,找到最近的父类进行调用。这样可以保证调用的结果是一定是调用最近的父类,而不是编译时绑定的父类,保证结果的正确性。
(6)this_class:u2的类索引,用于确定类的全限定名。本类的this_class是0001,表示在常量池中#1索引,是com/test/main1/Extend
(7)super_class:u2的父类索引,用于确定直接父类的全限定名。本类是0003,#3是com/test/main1/ByteCodeTest
(8)interfaces_count:u2,表示当前类实现的接口数量,注意是直接实现的接口数量。本类中是0000,表示没有实现接口。
(9)Interfaces:表示接口的全限定名索引。每个接口u2,共interfaces_count个。本类为空。
(10)fields_count:u2,表示类变量和实例变量总的个数。本类中是0000,无。
(11)fields:fileds的长度为filed_info,filed_info是一个复合结构,组成如下:
filed_info: {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}由于本类无类变量和实例变量,故本字段为空。
(12)methods_count:u2,表示方法个数。本类中是0002,表示有2个。
(13)methods:methods的长度为一个method_info结构:
method_info {
u2 access_flags; 0000 ?
u2 name_index; 0005 <init>
u2 descriptor_index; 0006 ()V
u2 attributes_count; 0001 1个
attribute_info attributes[attributes_count]; 0007 Code
}其中attribute_info结构如下:
attribute_info {
u2 attribute_name_index; 0007 Code
u1 attribute_length;
u1 info[attribute_length];
}上面是通用的attribute_info的定义,另外,JVM里预定义了几种attribute,Code即是其中一种(注意,如果使用的是JVM预定义的attribute,则attribute_info的结构就按照预定义的来),其结构如下:
Code_attribute { //Code_attribute包含某个方法、实例初始化方法、类或接口初始化方法的Java虚拟机指令及相关辅助信息
u2 attribute_name_index; 0007 Code
u4 attribute_length; 0000002F 47
u2 max_stack; 0001 1 //用来给出当前方法的操作数栈在方法执行的任何时间点的最大深度
u2 max_locals; 0001 1 //用来给出分配在当前方法引用的局部变量表中的局部变量个数
u4 code_length; 00000005 5 //给出当前方法code[]数组的字节数
u1 code[code_length]; 2AB70008 B1 42、183、0、8、177
//给出了实现当前方法的Java虚拟机代码的实际字节内容 (这些数字代码实际对应一些Java虚拟机的指令)
u2 exception_table_lentgh; 0000 0 //异常的信息
{
u2 start_pc; //这两项的值表明了异常处理器在code[]中的有效范围,即异常处理器x应满足:start_pc≤x≤end_pc
u2 end_pc; //start_pc必须在code[]中取值,end_pc要么在code[]中取值,要么等于code_length的值
u2 handler_pc; //表示一个异常处理器的起点
u2 catch_type; //表示当前异常处理器需要捕捉的异常类型。为0,则都调用该异常处理器,可用来实现finally。
} exception_table[exception_table_lentgh]; 在本类中大括号里的结构为空
u2 attribute_count; 0002 2 表示该方法的其它附加属性,本类有1个
attribute_info attributes[attributes_count]; 000A、000B LineNumberTable、LocalVariableTable
}LineNumberTable和LocalVariableTable又是两个预定义的attribute,其结构如下:
LineNumberTable_attribute { //被调试器用来确定源文件中由给定的行号所表示的内容,对应于Java虚拟机code[]数组的哪部分
u2 attribute_name_index; 000A
u4 attribute_length; 00000006
u2 line_number_table_length; 0001
{ u2 start_pc; 0000
u2 line_number; 000E //该值必须与源文件中对应的行号相匹配
} line_number_table[line_number_table_length];
}以及:
LocalVariableTable_attribute {
u2 attribute_name_index; 000B
u4 attribute_length; 0000000C
u2 local_variable_table_length; 0001
{ u2 start_pc; 0000
u2 length; 0005
u2 name_index; 000C
u2 descriptor_index; 000D //用来表示源程序中局部变量类型的字段描述符
u2 index; 0000
} local_variable_table[local_variable_table_length];然后就是第二个方法,具体略过。
(14)attributes_count:u2,这里的attribute表示整个class文件的附加属性,和前面方法的attribute结构相同。本类中为0001。
(15)attributes:class文件附加属性,本类中为0017,指向常量池#17,为SourceFile,SourceFile的结构如下:
SourceFile_attribute {
u2 attribute_name_index; 0017 SourceFile
u4 attribute_length; 00000002 2
u2 sourcefile_index; 0018 ByteCodeTest.java //表示本class文件是由ByteCodeTest.java编译来的
}嗯,字节码的内容大概就写这么多。可以看到通篇文章基本都是在分析字节码文件的16进制代码,所以可以这么说,字节码的核心在于其16进制代码,利用规范中的规则去解析这些代码,可以得出关于这个类的全部信息,包括:
1. 这个类的版本号;
2. 这个类的常量池大小,以及常量池中的常量;
3. 这个类的访问权限;
4. 这个类的全限定名、直接父类全限定名、类的直接实现的接口信息;
5. 这个类的类变量和实例变量的信息;
6. 这个类的方法信息;
7. 其它的这个类的附加信息,如来自哪个源文件等。
解析完字节码,回头再来看开始提出的问题,也就迎刃而解了。由于字节码文件格式严格按照规定,可以用来表示类的全部信息;字节码只是用来表示类信息的,不会进行程序的优化。
那么在编译期间,编译器会对程序进行优化吗?运行期间JVM会吗?什么时候进行的,按照什么原则呢?这个留作以后再表。
最后,值得注意的是,字节码不仅是平台无关的(任何平台生成的字节码都可以在任何的JRE环境运行),还是语言无关的,不仅Java可以生成字节码,其它语言如Groovy、Jython、Scala等也能生成字节码,运行在JRE环境中。
위 내용은 Java의 JVM 바이트코드에 대한 자세한 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!





















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



