

파이썬에서 재귀란 무엇인가요? 두 가지 우선순위 검색 알고리즘 구현(코드 예)

本篇文章给大家带来的内容是介绍python什么是递归?两种优先搜索算法的实现 (代码示例)。有一定的参考价值,有需要的朋友可以参考一下,希望对你们有所帮助。

一、递归原理小案例分析
(1)# 概述
递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到!
(2)# 写递归的过程
1、写出临界条件
2、找出这一次和上一次关系
3、假设当前函数已经能用,调用自身计算上一次的结果,再求出本次的结果
(3)案例分析:求1+2+3+...+n的数和
# 概述
'''
递归:即一个函数调用了自身,即实现了递归
凡是循环能做到的事,递归一般都能做到!
'''
# 写递归的过程
'''
1、写出临界条件
2、找出这一次和上一次关系
3、假设当前函数已经能用,调用自身计算上一次的结果,再求出本次的结果
'''
# 问题:输入一个大于1 的数,求1+2+3+....
def sum(n):
if n==1:
return 1
else:
return n+sum(n-1)
n=input("请输入:")
print("输出的和是:",sum(int(n)))
'''
输出:
请输入:4
输出的和是: 10
'''
#__author:"吉*佳"
#date: 2018/10/21 0021
#function:
import os
def getAllDir(path):
fileList = os.listdir(path)
print(fileList)
for fileName in fileList:
fileAbsPath = os.path.join(path,fileName)
if os.path.isdir(fileAbsPath):
print("$$目录$$:",fileName)
getAllDir(fileAbsPath)
else:
print("**普通文件!**",fileName)
# print(fileList)
pass
getAllDir("G:\\")输出结果如下:


二、深度遍历与广度遍历
(一)、深度优先搜索
说明:深度优先搜索借助栈结构来进行模拟
深度遍历示意图:

说明:
先把A压栈进去,在A出栈的同时把B C压栈进去,此时让B出栈的同时把DE压栈(C留着先不处理) 同理,在D出栈的时候,H I压栈,最后再从上往下
取出栈内还未出栈的元素,即达到深度优先遍历。
案例实践:利用栈来深度搜索打印出目录结构

程序代码:
#__author:"吉**"
#date: 2018/10/21 0021
#function:
# 深度优先遍历目录层级结构
import os
def getAllDirDP(path):
stack = []
# 压栈操作,相当于图中的A压入
stack.append(path)
# 处理栈,当栈为空的时候结束循环
while len(stack) != 0:
#从栈里取数据,相当于取出A,取出A的同时把BC压入
dirPath = stack.pop()
firstList = os.listdir(dirPath)
#判断:是目录压栈,把该目录地址压栈,不是目录即是普通文件,打印
for filename in firstList:
fileAbsPath=os.path.join(dirPath,filename)
if os.path.isdir(fileAbsPath):
#是目录就压栈
print("目录:",filename)
stack.append(fileAbsPath)
else:
#是普通文件就打印即可,不压栈
print("普通文件:",filename)
getAllDirDP(r'E:\[AAA](千)全栈学习python\18-10-21\day7\temp\dir')结果:
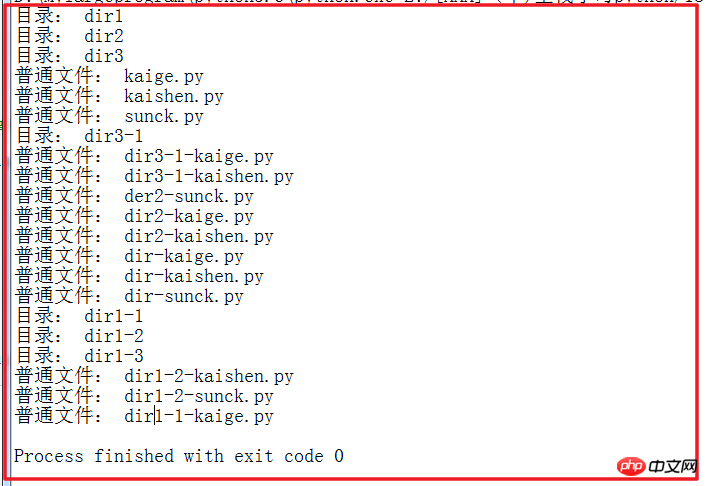
该过程示意图解释:(s-05-1部分)


原理分析:

说明:
队列是 先进先出的模型。A先进队,在A出队的时候,C B入队,按图示,C出队,FG 入队,B出队,DE入队,
F出队,JK入队,G出队,无入队,D出队,H I入队,最后E J K H I出队,均无入队了,即每一层一层处理、
故:先进先出的队列结构实现了广度优先遍历。 先进后出的栈结构实现的是深度优先遍历。
代码实现:
其实深度优先和广度优先在代码书写上是差别不大的,基本相同,只是一个是使用栈结构(用列表进行模拟)
另一个(广度优先遍历)是使用了队列的数据结构来达到先进先出的目的。
#__author:"吉**"
#date: 2018/10/21 0021
#function:
# 广度优先搜索模拟
# 利用队列来模拟广度优先搜索
import os
import collections
def getAllDirIT(path):
queue=collections.deque()
#进队
queue.append(path)
#循环,当队列为空,停止循环
while len(queue) != 0:
#出队数据 这里相当于找到A元素的绝对路径
dirPath = queue.popleft()
# 找出跟目录下的所有的子目录信息,或者是跟目录下的文件信息
dirList = os.listdir(dirPath)
#遍历该文件夹下的其他信息
for filename in dirList:
#绝对路径
dirAbsPath = os.path.join(dirPath,filename)
# 判断:如果是目录dir入队操作,如果不是dir打印出即可
if os.path.isdir(dirAbsPath):
print("目录:"+filename)
queue.append(dirAbsPath)
else:
print("普通文件:"+filename)
# 函数的调用
getAllDirIT(r'E:\[AAA](千)全栈学习python\18-10-21\day7\temp\dir')广度优先运行输出结构:

先图解:按照每一层从左到右遍历即可实现。

结束!
위 내용은 파이썬에서 재귀란 무엇인가요? 두 가지 우선순위 검색 알고리즘 구현(코드 예)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7442
7442
 15
1371
52
76
11
37
19
9
6
15
1371
52
76
11
37
19
9
6

 C 언어 합계의 기능은 무엇입니까?
Apr 03, 2025 pm 02:21 PM
C 언어 합계의 기능은 무엇입니까?
Apr 03, 2025 pm 02:21 PM
C 언어에는 내장 합계 기능이 없으므로 직접 작성해야합니다. 합계는 배열 및 축적 요소를 가로 질러 달성 할 수 있습니다. 루프 버전 : 루프 및 배열 길이를 사용하여 계산됩니다. 포인터 버전 : 포인터를 사용하여 배열 요소를 가리키며 효율적인 합계는 자체 증가 포인터를 통해 달성됩니다. 동적으로 배열 버전을 할당 : 배열을 동적으로 할당하고 메모리를 직접 관리하여 메모리 누출을 방지하기 위해 할당 된 메모리가 해제되도록합니다.
 누가 더 많은 파이썬이나 자바 스크립트를 지불합니까?
Apr 04, 2025 am 12:09 AM
누가 더 많은 파이썬이나 자바 스크립트를 지불합니까?
Apr 04, 2025 am 12:09 AM
기술 및 산업 요구에 따라 Python 및 JavaScript 개발자에 대한 절대 급여는 없습니다. 1. 파이썬은 데이터 과학 및 기계 학습에서 더 많은 비용을 지불 할 수 있습니다. 2. JavaScript는 프론트 엔드 및 풀 스택 개발에 큰 수요가 있으며 급여도 상당합니다. 3. 영향 요인에는 경험, 지리적 위치, 회사 규모 및 특정 기술이 포함됩니다.
 별개의 구별이 관련되어 있습니까?
Apr 03, 2025 pm 10:30 PM
별개의 구별이 관련되어 있습니까?
Apr 03, 2025 pm 10:30 PM
구별되고 구별되는 것은 구별과 관련이 있지만, 다르게 사용됩니다. 뚜렷한 (형용사)는 사물 자체의 독창성을 묘사하고 사물 사이의 차이를 강조하는 데 사용됩니다. 뚜렷한 (동사)는 구별 행동이나 능력을 나타내며 차별 과정을 설명하는 데 사용됩니다. 프로그래밍에서 구별은 종종 중복 제거 작업과 같은 컬렉션에서 요소의 독창성을 나타내는 데 사용됩니다. 홀수 및 짝수 숫자를 구별하는 것과 같은 알고리즘이나 함수의 설계에 별개가 반영됩니다. 최적화 할 때 별도의 작업은 적절한 알고리즘 및 데이터 구조를 선택해야하며, 고유 한 작업은 논리 효율성의 구별을 최적화하고 명확하고 읽을 수있는 코드 작성에주의를 기울여야합니다.
 H5 페이지 생산에는 지속적인 유지 보수가 필요합니까?
Apr 05, 2025 pm 11:27 PM
H5 페이지 생산에는 지속적인 유지 보수가 필요합니까?
Apr 05, 2025 pm 11:27 PM
코드 취약점, 브라우저 호환성, 성능 최적화, 보안 업데이트 및 사용자 경험 개선과 같은 요소로 인해 H5 페이지를 지속적으로 유지해야합니다. 효과적인 유지 관리 방법에는 완전한 테스트 시스템 설정, 버전 제어 도구 사용, 페이지 성능을 정기적으로 모니터링하고 사용자 피드백 수집 및 유지 관리 계획을 수립하는 것이 포함됩니다.
 이해하는 방법! x는?
Apr 03, 2025 pm 02:33 PM
이해하는 방법! x는?
Apr 03, 2025 pm 02:33 PM
! x 이해! x는 C 언어로 된 논리적 비 운영자입니다. 그것은 x의 값, 즉 실제 변경, 거짓, 잘못된 변경 사항을 부수합니다. 그러나 C의 진실과 거짓은 부울 유형보다는 숫자 값으로 표시되며, 0이 아닌 것은 참으로 간주되며 0만이 거짓으로 간주됩니다. 따라서! x는 음수를 양수와 동일하게 처리하며 사실로 간주됩니다.
 C 언어에서 합계는 무엇을 의미합니까?
Apr 03, 2025 pm 02:36 PM
C 언어에서 합계는 무엇을 의미합니까?
Apr 03, 2025 pm 02:36 PM
합에 대한 C에는 내장 합계 기능이 없지만 다음과 같이 구현할 수 있습니다. 루프를 사용하여 요소를 하나씩 축적합니다. 포인터를 사용하여 요소를 하나씩 액세스하고 축적합니다. 큰 데이터 볼륨의 경우 병렬 계산을 고려하십시오.
 58.com 작업 페이지에서 실시간 응용 프로그램 및 뷰어 데이터를 얻는 방법은 무엇입니까?
Apr 05, 2025 am 08:06 AM
58.com 작업 페이지에서 실시간 응용 프로그램 및 뷰어 데이터를 얻는 방법은 무엇입니까?
Apr 05, 2025 am 08:06 AM
크롤링하는 동안 58.com 작업 페이지의 동적 데이터를 얻는 방법은 무엇입니까? Crawler 도구를 사용하여 58.com의 작업 페이지를 크롤링 할 때는이 문제가 발생할 수 있습니다.
 사랑 코드 복사 및 붙여 넣기 복사하여 사랑 코드를 무료로 붙여 넣으십시오.
Apr 04, 2025 am 06:48 AM
사랑 코드 복사 및 붙여 넣기 복사하여 사랑 코드를 무료로 붙여 넣으십시오.
Apr 04, 2025 am 06:48 AM
코드 복사 및 붙여 넣기는 불가능하지는 않지만주의해서 처리해야합니다. 코드의 환경, 라이브러리, 버전 등과 같은 종속성은 현재 프로젝트와 일치하지 않으므로 오류 또는 예측할 수없는 결과를 초래할 수 있습니다. 파일 경로, 종속 라이브러리 및 Python 버전을 포함하여 컨텍스트가 일관되게 유지하십시오. 또한 특정 라이브러리의 코드를 복사 및 붙여 넣을 때 라이브러리 및 해당 종속성을 설치해야 할 수도 있습니다. 일반적인 오류에는 경로 오류, 버전 충돌 및 일관되지 않은 코드 스타일이 포함됩니다. 성능 최적화는 코드의 원래 목적 및 제약에 따라 재 설계 또는 리팩토링되어야합니다. 복사 코드를 이해하고 디버그하고 맹목적으로 복사하여 붙여 넣지 않는 것이 중요합니다.
