

MySql의 트랜잭션 격리 수준에 대한 자세한 소개(코드 포함)

이 기사는 MySql의 트랜잭션 격리 수준(코드 포함)에 대해 자세히 소개합니다. 필요한 친구가 참고할 수 있기를 바랍니다.
1. 트랜잭션의 4가지 특성(ACID)
트랜잭션 격리 수준을 이해하기 전에 먼저 이해해야 할 트랜잭션의 4가지 특성입니다.
1. 원자성
트랜잭션이 시작된 후 모든 작업이 완료되거나 완료되지 않습니다. 거래는 분할할 수 없는 전체입니다. 트랜잭션 실행 중 오류가 발생하면 트랜잭션의 무결성을 보장하기 위해 트랜잭션이 시작되기 전 상태로 롤백됩니다. 원자에 대한 물리적인 설명과 유사합니다. 화학 반응에서 더 이상 쪼개질 수 없는 기본 입자를 말합니다.
2. 일관성
트랜잭션이 시작되고 끝난 후에는 데이터베이스 무결성 제약 조건의 정확성, 즉 데이터의 무결성을 보장할 수 있습니다. 예를 들어, 고전적인 이체 사례에서 A가 B에게 돈을 이체할 때 A가 돈을 공제하고 B가 확실히 돈을 받도록 해야 합니다. 내 개인적인 이해는 물리학의 에너지 보존과 유사합니다.
3. 격리
트랜잭션 간의 완전한 격리. 예를 들어, A는 동시에 너무 많은 작업을 수행하여 계정 금액의 손실을 방지하기 위해 은행 카드로 자금을 이체합니다. 따라서 A의 이체가 완료되기 전에는 이 카드에 대한 다른 작업이 허용되지 않습니다.
4. 내구성
트랜잭션이 데이터에 미치는 영향은 영구적입니다. 널리 알려진 설명은 트랜잭션이 완료된 후 데이터 작업을 디스크에 저장해야 한다는 것입니다(지속성). 트랜잭션이 완료되면 되돌릴 수 없습니다. 데이터베이스 작업 측면에서 트랜잭션이 완료되면 롤백할 수 없습니다.
2. 트랜잭션 동시성 문제
인터넷의 물결 속에서 프로그램의 가치는 더 이상 전통 산업의 복잡한 비즈니스 로직을 해결하는 데 도움이 되지 않습니다. 사용자 경험이 가장 중요한 인터넷 시대에 코드는 Xierqi 지하철역의 코더의 발걸음, 속도, 속도, 속도와 같습니다. 물론, 잘못된 방향으로 앉을 수는 없습니다. 원래 Xizhimen에 가고 싶었고 결국 Dongzhimen에 도착했습니다. 전통적인 산업의 복잡한 비즈니스 로직에 비해 인터넷은 동시성이 프로그램에 가져오는 속도와 열정에 더 많은 관심을 기울입니다. 물론 과속에는 대가가 따른다. 동시 트랜잭션에서, 가난한 코더는 조심하지 않으면 도망갈 것입니다.
1. 더티 읽기
를 잘못된 데이터 읽기라고도 합니다. 다른 트랜잭션에 의해 아직 커밋되지 않은 데이터를 읽는 트랜잭션을 더티 읽기(dirty read)라고 합니다.
예: 트랜잭션 T1이 데이터 행을 수정했지만 아직 제출되지 않았습니다. 이때 트랜잭션 T2는 트랜잭션 T1이 수정한 데이터를 읽었습니다. 그런 다음 트랜잭션 T1이 어떤 이유로 롤백되었으므로 트랜잭션 T2는 더티 데이터를 읽었습니다. .
2. 반복되지 않는 읽기
동일한 트랜잭션에서 동일한 데이터를 여러 번 읽어도 일관성이 없습니다.
예를 들어 트랜잭션 T1은 특정 데이터를 읽고, 트랜잭션 T2는 데이터를 읽고 수정하며, T1은 읽은 값을 확인하기 위해 데이터를 다시 읽고 다른 결과를 얻습니다.
3. 판타지 읽기
설명하기 어렵지만 예를 들어보겠습니다.
창고 관리에서는 관리자가 창고 관리에 방금 도착한 상품을 입력해야 합니다. 창고에 넣을 경우 이전 항목을 확인해야 하며 정확성을 보장하기 위한 보관 기록이 없습니다. 관리자 A는 창고에 해당 상품이 없는지 확인한 후 해당 상품을 보관소에 넣습니다. 만약 관리자 B가 빠른 손길로 이미 해당 상품을 보관소에 넣었을 경우. 이때 관리자 A는 해당 상품이 이미 인벤토리에 있다는 사실을 발견했습니다. 마치 환상의 독서가 방금 일어난 것 같았습니다. 이전에는 존재하지 않았던 일이 갑자기 그는 그것을 갖게 되었습니다.
참고: 세 가지 유형의 문제는 이해하기 어려워 보입니다. 더티 리딩은 데이터의 정확성에 중점을 둡니다. 반복 불가능성은 데이터 수정에 중점을 두고, 팬텀 판독은 데이터 추가 및 삭제에 중점을 둡니다.
3. MySql의 4가지 트랜잭션 격리 수준
이전 장에서는 높은 동시성이 트랜잭션에 미치는 영향에 대해 배웠습니다. 네 가지 트랜잭션 격리 수준은 위의 세 가지 문제에 대한 솔루션입니다.
| 격리 수준 | 더티 읽기 | 반복 불가 | 팬텀 읽기 ) |
| 은 | 예 | 비- 반복 읽기(읽기-커밋) | |
| Yes | Yes | Repeatable-read | No|
|
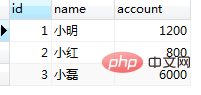
4. 4가지 격리 수준의 SQL 시연 mysql 버전: 5.6 스토리지 엔진: InnoDB Tool: navicat 테이블 생성 명령문: CREATE TABLE `tb_bank` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(16) COLLATE utf8_bin DEFAULT NULL, `account` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin; INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (1, '小明', 1000); 로그인 후 복사 1 sql을 통한 시연------read-uncommitted Dirty read (2) read-uncommit으로 인한 더티 읽기 소위 더티 읽기(dirty read)는 두 트랜잭션 중 하나가 다른 트랜잭션의 커밋되지 않은 데이터를 읽을 수 있음을 의미합니다. 데모 단계: select @@tx_isolation;//查询当前事务隔离级别 set session transaction isolation level read uncommitted;//将事务隔离级别设置为 读未提交 로그인 후 복사 ② 두 세션 모두 트랜잭션을 엽니다 start transaction;//开启事务 로그인 후 복사 ③ Session1 및 session2: 두 작업이 수행되기 전 계정 잔고가 1000 select * from tb_bank where id=1;//查询结果为1000 로그인 후 복사 4임을 증명합니다. session2: 이때, session2의 업데이트가 먼저 수행되는 것으로 가정합니다. update tb_bank set account = account + 100 where id=1; 로그인 후 복사 ⑤ session1: session2가 커밋되기 전에 session1이 실행을 시작합니다. select * from tb_bank where id=1;//查询结果:1100 로그인 후 복사 ⑥ session2: 어떤 이유로 인해 전송이 실패하고 트랜잭션이 롤백되었습니다. rollback;//事务回滚 commit;//提交事务 로그인 후 복사 7 이때 session1은 외부로 전송이 시작되고 session1은 ⑤의 쿼리 결과 1100이 올바른 데이터라고 생각합니다. update tb_bank set account=1100-200 where id=1; commit; 로그인 후 복사 8Session1과 session2 쿼리 결과 select * from tb_bank where id=1;//查询结果:900 로그인 후 복사 이때 session1의 dirty reading으로 인해 최종 데이터가 일치하지 않는 것을 발견했습니다. 올바른 결과는 800이어야 합니다. (2) 읽기-커밋은 더티 읽기를 해결합니다. 데이터를 재설정하고 데이터를 복원합니다. to account=1000 ① 두 개의 새로운 세션을 생성하고 각각 set session transaction isolation level read committed;//将隔离级别设置为 不可重复读 로그인 후 복사 (1)의 ② ③ ④ ⑤ 단계를 반복합니다. 두 트랜잭션은 효과적으로 격리되므로 session1의 트랜잭션은 in의 트랜잭션으로 인해 발생한 데이터 변경 사항을 쿼리할 수 없습니다. 세션2. 더티 읽기(Dirty Read)는 효과적으로 방지됩니다. 2. SQL을 통해 시연 ----- 읽기-커밋 비반복 읽기 (1) 읽기-커밋 비반복 읽기 데이터를 재설정하고 계정=1000으로 데이터 복원 소위 비 -반복 읽기는 트랜잭션이 커밋되지 않은 다른 트랜잭션의 데이터를 읽을 수 없지만 제출된 데이터는 읽을 수 있음을 의미합니다. 이때 두 판독 결과가 일치하지 않습니다. 따라서 반복해서 읽을 수 없습니다. READ COMMITTED 격리 수준에서는 각 읽기에 대해 스냅샷이 다시 생성되므로 각 스냅샷이 최신입니다. 따라서 트랜잭션의 각 SELECT는 다른 커밋된 트랜잭션에 의해 변경된 내용도 볼 수 있습니다.시나리오: 세션1은 쿼리용 계정을 수행합니다. , 세션2는 100을 계정으로 이체합니다. select * from tb_bank where id=1;//查询结果为1000,这说明 不可重复读 隔离级别有效的隔离了两个会话的事务。 로그인 후 복사 ② session1과 session2를 각각 트랜잭션을 열도록 설정합니다. set session transaction isolation level read committed; 로그인 후 복사 ③ session1 첫 번째 쿼리: start transaction; 로그인 후 복사 ④ session2 업데이트: select * from tb_bank where id=1;//查询结果:1000 로그인 후 복사 ⑤ session1 두 번째 쿼리: update tb_bank set account = account+100 where id=1; select * from tb_bank where id=1;//查询结果:1100 로그인 후 복사 쿼리를 살펴보는 중 결과를 보면, 트랜잭션 개시 시 session1의 반복 읽기 결과가 일치하지 않음을 알 수 있어, 읽기 커밋 트랜잭션 격리 수준이 반복 불가능 읽기임을 알 수 있습니다. 분명히 이 결과는 우리가 원하는 결과가 아닙니다. (2) 반복 읽기 데이터를 재설정하여 데이터를 계정=1000으로 복원① 두 개의 새 세션을 생성하고 각각 select * from tb_bank where id=1;//查询结果:1100。和③中查询结果对比,session1两次查询结果不一致。 로그인 후 복사 (1)의 ② ③ ④ ⑤ session1을 두 번째로 반복합니다. 쿼리:
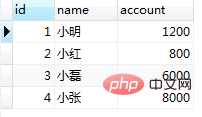
set session transaction isolation level repeatable read; 로그인 후 복사 반복 읽기 격리 수준에서는 다중 읽기 결과가 다른 트랜잭션의 영향을 받지 않는 것을 결과에서 알 수 있습니다. 반복해서 읽을 수 있습니다. 여기서 의문이 생깁니다. session1에서 읽은 결과는 여전히 session2의 업데이트 전 결과입니다. session1에서 100을 계속 전송하면 올바른 결과인 1200을 얻을 수 있습니까? 계속 작업: ⑥ 세션 1을 100으로 전송: select * from tb_bank where id=1;//查询结果为:1000 로그인 후 복사 여기서 속인 것 같아요, 잠금, 잠금, 잠금. session1의 업데이트 문이 차단되었습니다. session2의 업데이트 문이 커밋된 후에만 session1의 실행이 계속될 수 있습니다. 세션의 실행 결과는 1200입니다. 이때 MVCC 메커니즘은 반복 읽기의 격리 수준에서 사용되며 선택 작업은 버전 번호를 업데이트하지 않기 때문에 세션 1은 1000+100을 사용하여 계산되지 않는 것으로 확인되었습니다. 이지만 스냅샷 읽기(기록 버전)입니다. 삽입, 업데이트 및 삭제는 현재 읽은 버전(현재 버전)인 버전 번호를 업데이트합니다. 3. SQL을 통해 시연----반복 읽기의 팬텀 읽기 在业务逻辑中,通常我们先获取数据库中的数据,然后在业务中判断该条件是否符合自己的业务逻辑,如果是的话,那么就可以插入一部分数据。但是mysql的快照读可能在这个过程中会产生意想不到的结果。 准备工作:插入两条数据 INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (2, '小红', 800); INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (3, '小磊', 6000); 로그인 후 복사 (1)repeatable-read的幻读 ① 新建两个session都执行 set session transaction isolation level repeatable read; start transaction; select * from tb_bank;//查询结果:(这一步很重要,直接决定了快照生成的时间) 로그인 후 복사 结果都是:
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000); select * from tb_bank; 로그인 후 복사
结果数据插入成功。此时session2提交事务 commit; 로그인 후 복사 ③ session1进行插入 select * from tb_bank; 로그인 후 복사
结果session1中没有该条记录,这时按照我们通常的业务逻辑,此时应该是能成功插入id=4的数据。继续执行: INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000); 로그인 후 복사
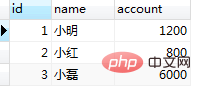
结果插入失败,提示该条已经存在,但是我们查询里面并没有这一条数据啊。为什么会插入失败呢? 因为①中的select语句生成了快照,之后的读操作(未加读锁)都是进行的快照读,即在当前事务结束前,所有的读操作的结果都是第一次快照读产生的快照版本。疑问又来了,为什么②步骤中的select语句读到的不是快照版本呢?因为update语句会更新当前事务的快照版本。具体参阅第五章节。 (2)repeatable-read利用当前读解决幻读重复(1)中的①② select * from tb_bank; 로그인 후 복사 结果session1中没有该条记录,这时按照我们通常的业务逻辑,此时应该是能成功插入id=4的数据。 select * from tb_bank lock in share mode;//采用当前读 로그인 후 복사 结果:发现当前结果中已经有小张的账户信息了,按照业务逻辑,我们就不在继续执行插入操作了。 4、serializable隔离级别 在此级别下我们就不再做serializable的避免幻读的sql演示了,毕竟是给整张表都加锁的。 五、当前读和快照读 本想把当前读和快照读单开一片博客,但是为了把幻读总结明白,暂且在本章节先简单解释下快照读和当前读。后期再追加一篇MVCC,next-key的博客吧。。。 1、快照读:即一致非锁定读。 ① InnoDB存储引擎下,查询语句默认执行快照读。 ② RR隔离级别下一个事务中的第一次读操作会产生数据的快照。 ③ update,insert,delete操作会更新快照。 四种事务隔离级别下的快照读区别: ① read-uncommitted和read-committed级别:每次读都会产生一个新的快照,每次读取的都是最新的,因此RC级别下select结果能看到其他事务对当前数据的修改,RU级别甚至能读取到其他未提交事务的数据。也因此这两个级别下数据是不可重复读的。 ② repeatable-read级别:基于MVCC的并发控制,并发性能极高。第一次读会产生读数据快照,之后在当前事务中未发生快照更新的情况下,读操作都会和第一次读结果保持一致。快照产生于事务中,不同事务中的快照是完全隔离的。 ③ serializable级别:从MVCC并发控制退化为基于锁的并发控制。不区别快照读与当前读,所有的读操作均为当前读,读加读锁 (S锁),写加写锁 (X锁)。Serializable隔离级别下,读写冲突,因此并发度急剧下降。(锁表,不建议使用) 2、当前读:即一致锁定读。如何产生当前读 ① select ... lock in share mode ② select ... for update ③ update,insert,delete操作都是当前读。 读取之后,还需要保证当前记录不能被其他并发事务修改,需要对当前记录加锁。①中对读取记录加S锁 (共享锁),②③X锁 (排它锁)。 3、疑问总结① update,insert,delete操作为什么都是当前读? 简单来说,不执行当前读,数据的完整性约束就有可能遭到破坏。尤其在高并发的环境下。 分析update语句的执行步骤:update table set ... where ...; InnoDB 엔진은 먼저 where 쿼리를 수행하고 쿼리된 결과 세트는 첫 번째 항목에서 시작하여 현재 읽기를 실행한 다음 업데이트 작업을 수행하고 두 번째 데이터 조각을 읽고 업데이트 작업을 수행합니다. 업데이트가 실행되면 현재 읽기가 수반됩니다. 삭제도 마찬가지입니다. 결국 데이터를 삭제하기 전에 먼저 찾아야 합니다. 삽입은 약간 다릅니다. 삽입 작업을 실행하기 전에 고유 키 확인을 수행해야 합니다. [관련 권장 사항: MySQL 튜토리얼]
|

위 내용은 MySql의 트랜잭션 격리 수준에 대한 자세한 소개(코드 포함)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
웹 응용 프로그램에서 MySQL의 주요 역할은 데이터를 저장하고 관리하는 것입니다. 1. MySQL은 사용자 정보, 제품 카탈로그, 트랜잭션 레코드 및 기타 데이터를 효율적으로 처리합니다. 2. SQL 쿼리를 통해 개발자는 데이터베이스에서 정보를 추출하여 동적 컨텐츠를 생성 할 수 있습니다. 3.mysql은 클라이언트-서버 모델을 기반으로 작동하여 허용 가능한 쿼리 속도를 보장합니다.
 Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker에서 MySQL을 시작하는 프로세스는 다음 단계로 구성됩니다. MySQL 이미지를 가져와 컨테이너를 작성하고 시작하고 루트 사용자 암호를 설정하고 포트 확인 연결을 매핑하고 데이터베이스를 작성하고 사용자는 데이터베이스에 모든 권한을 부여합니다.
 LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
LARAVEL 소개 예
Apr 18, 2025 pm 12:45 PM
Laravel은 웹 응용 프로그램을 쉽게 구축하기위한 PHP 프레임 워크입니다. 설치 : Composer를 사용하여 전 세계적으로 Laravel CLI를 설치하고 프로젝트 디렉토리에서 응용 프로그램을 작성하는 등 다양한 기능을 제공합니다. 라우팅 : Routes/Web.php에서 URL과 핸들러 간의 관계를 정의하십시오. 보기 : 리소스/뷰에서보기를 작성하여 응용 프로그램의 인터페이스를 렌더링합니다. 데이터베이스 통합 : MySQL과 같은 데이터베이스와 상자 외 통합을 제공하고 마이그레이션을 사용하여 테이블을 작성하고 수정합니다. 모델 및 컨트롤러 : 모델은 데이터베이스 엔티티를 나타내고 컨트롤러는 HTTP 요청을 처리합니다.
 데이터베이스 연결 문제 해결 : Minii/DB 라이브러리 사용 실질적인 사례
Apr 18, 2025 am 07:09 AM
데이터베이스 연결 문제 해결 : Minii/DB 라이브러리 사용 실질적인 사례
Apr 18, 2025 am 07:09 AM
작은 응용 프로그램을 개발할 때 까다로운 문제가 발생했습니다. 가벼운 데이터베이스 운영 라이브러리를 신속하게 통합해야합니다. 여러 라이브러리를 시도한 후에는 기능이 너무 많거나 호환되지 않는다는 것을 알았습니다. 결국, 나는 내 문제를 완벽하게 해결하는 YII2를 기반으로 단순화 된 버전 인 Minii/DB를 발견했습니다.
 MySQL 및 Phpmyadmin : 핵심 기능 및 기능
Apr 22, 2025 am 12:12 AM
MySQL 및 Phpmyadmin : 핵심 기능 및 기능
Apr 22, 2025 am 12:12 AM
MySQL 및 Phpmyadmin은 강력한 데이터베이스 관리 도구입니다. 1) MySQL은 데이터베이스 및 테이블을 작성하고 DML 및 SQL 쿼리를 실행하는 데 사용됩니다. 2) PHPMYADMIN은 데이터베이스 관리, 테이블 구조 관리, 데이터 운영 및 사용자 권한 관리에 직관적 인 인터페이스를 제공합니다.
 MySQL 대 기타 프로그래밍 언어 : 비교
Apr 19, 2025 am 12:22 AM
MySQL 대 기타 프로그래밍 언어 : 비교
Apr 19, 2025 am 12:22 AM
다른 프로그래밍 언어와 비교할 때 MySQL은 주로 데이터를 저장하고 관리하는 데 사용되는 반면 Python, Java 및 C와 같은 다른 언어는 논리적 처리 및 응용 프로그램 개발에 사용됩니다. MySQL은 데이터 관리 요구에 적합한 고성능, 확장 성 및 크로스 플랫폼 지원으로 유명하며 다른 언어는 데이터 분석, 엔터프라이즈 애플리케이션 및 시스템 프로그래밍과 같은 해당 분야에서 이점이 있습니다.
 Laravel 프레임 워크 설치 방법
Apr 18, 2025 pm 12:54 PM
Laravel 프레임 워크 설치 방법
Apr 18, 2025 pm 12:54 PM
기사 요약 :이 기사는 Laravel 프레임 워크를 쉽게 설치하는 방법에 대한 독자들을 안내하기위한 자세한 단계별 지침을 제공합니다. Laravel은 웹 애플리케이션의 개발 프로세스를 가속화하는 강력한 PHP 프레임 워크입니다. 이 자습서는 시스템 요구 사항에서 데이터베이스 구성 및 라우팅 설정에 이르기까지 설치 프로세스를 다룹니다. 이러한 단계를 수행함으로써 독자들은 라벨 프로젝트를위한 탄탄한 토대를 빠르고 효율적으로 놓을 수 있습니다.
 MySQL 대 기타 데이터베이스 : 옵션 비교
Apr 15, 2025 am 12:08 AM
MySQL 대 기타 데이터베이스 : 옵션 비교
Apr 15, 2025 am 12:08 AM
MySQL은 웹 응용 프로그램 및 컨텐츠 관리 시스템에 적합하며 오픈 소스, 고성능 및 사용 편의성에 인기가 있습니다. 1) PostgreSQL과 비교하여 MySQL은 간단한 쿼리 및 높은 동시 읽기 작업에서 더 잘 수행합니다. 2) Oracle과 비교할 때 MySQL은 오픈 소스와 저렴한 비용으로 인해 중소 기업에서 더 인기가 있습니다. 3) Microsoft SQL Server와 비교하여 MySQL은 크로스 플랫폼 응용 프로그램에 더 적합합니다. 4) MongoDB와 달리 MySQL은 구조화 된 데이터 및 트랜잭션 처리에 더 적합합니다.
