

Python 인코딩 형식 변경 문제

오늘 Python 크롤러를 작성 중인데 갑자기 크롤링된 웹 페이지가 비정상이고 오류가 보고되었습니다. UnicodeEncodeError: 'latin-1' 코덱이 41-50 위치의 문자를 인코딩할 수 없습니다: 서수 범위(256)에 없음 UnicodeEncodeError: 'ascii' 코덱은 문자를 서수로 인코딩할 수 없습니다. 이는 명백한 인코딩 형식 문제입니다. 실제로 Python2나 3뿐만 아니라 Java, C와 같은 다른 프로그래밍 언어도 인코딩 형식에 문제가 자주 발생하는데, 이는 매우 골치 아픈 일이며, 특히 ASCII, gbk, utf-8 및 기타 인코딩 간의 변환은 더욱 그렇습니다. . 그래서 정보를 찾아보고, 실습도 해보고, 이런저런 방법을 몇 가지 발견했습니다.
먼저, Python의 시스템 인코딩 형식과 입출력 형식을 어떻게 확인하나요?
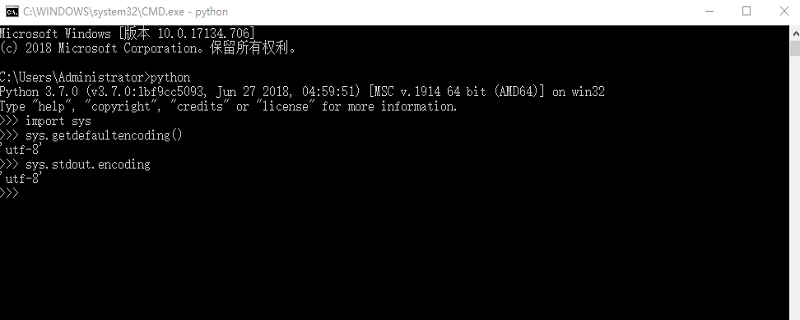
>>> import sys >>> sys.getdefaultencoding()# 系统默认编码格式 'UTF-8' >>> sys.stdout.encoding# 输入输出格式 'US-ASCII'
이 경우 현재 명령줄의 입력 및 출력 인코딩이 ASCII라는 의미이므로 수동으로 인코딩해야 합니다. 환경 변수 LANG을 utf-8로 설정하도록 변경하세요.
export LANG="en_US.UTF-8"
우분투 환경에 있다면 위의 명령 줄을 ~/.bashrc에 추가하여 문제를 한 번에 해결할 수 있습니다. 모두 추가한 후 다음 명령을 실행하여 적용하거나 다시 시작하여 적용하세요.
source ~/.bashrc
또는 또 다른 방법은 Python에 대해서만 해당 인코딩을 설정하는 것입니다(위와 동일, 명령줄을 실행하거나 bashrc 파일을 추가):
PYTHONIOENCODING='utf_8' export PYTHONIOENCODING
gbk 인코딩 예시 사진 : # 🎜🎜#

# -*- coding: utf-8 -*-
>>>sys.getdefaultencoding()查看当前编码(若报错,先执行>>>import sys >>>reload(sys)); >>>sys.setdefaultencoding('utf8')设置编码
import sys reload(sys) sys.setdefaultencoding('utf8') 重启Python解释器,发现编码已被设置为utf8; 这是因为系统在Python启动的时候,自行调用该文件,设置系统的默认编码,而不需要每次都手动加上解决代码,属于一劳永逸的解决方法。
Decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。 Encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
>>> 'ABC'.encode('ascii') b'ABC' >>> '中文'.encode('utf-8') b'\xe4\xb8\xad\xe6\x96\x87' >>> '中文'.encode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
UTF-8 인코딩 변환 도구
】【python3 비디오 튜토리얼
】#🎜🎜 #처음에는 몇 가지 인코딩 형식밖에 없었습니다. 컴퓨터의 대중화와 많은 국가나 조직의 사용으로 인해 점점 더 많은 인코딩 형식이 있지만, 여전히 국제적으로 허용되는 형식은 UTF-8입니다. 따라서 좋은 프로그래밍 습관이 있어야 하며 주로 UTF-8 인코딩 형식을 사용합니다. 인코딩 문제가 발생하면 인코딩 형식을 일관되게 유지하십시오.
위 내용은 Python 인코딩 형식 변경 문제의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7502
7502
 15
1377
52
78
11
52
19
19
54
15
1377
52
78
11
52
19
19
54

 hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
hadidb : 파이썬의 가볍고 수평 확장 가능한 데이터베이스
Apr 08, 2025 pm 06:12 PM
HADIDB : 가볍고 높은 수준의 확장 가능한 Python 데이터베이스 HadIDB (HADIDB)는 파이썬으로 작성된 경량 데이터베이스이며 확장 수준이 높습니다. PIP 설치를 사용하여 HADIDB 설치 : PIPINSTALLHADIDB 사용자 관리 사용자 만들기 사용자 : createUser () 메소드를 작성하여 새 사용자를 만듭니다. Authentication () 메소드는 사용자의 신원을 인증합니다. Fromhadidb.operationimportuseruser_obj = user ( "admin", "admin") user_obj.
 MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
MongoDB 데이터베이스 비밀번호를 보는 Navicat의 방법
Apr 08, 2025 pm 09:39 PM
해시 값으로 저장되기 때문에 MongoDB 비밀번호를 Navicat을 통해 직접 보는 것은 불가능합니다. 분실 된 비밀번호 검색 방법 : 1. 비밀번호 재설정; 2. 구성 파일 확인 (해시 값이 포함될 수 있음); 3. 코드를 점검하십시오 (암호 하드 코드 메일).
 2 시간의 파이썬 계획 : 현실적인 접근
Apr 11, 2025 am 12:04 AM
2 시간의 파이썬 계획 : 현실적인 접근
Apr 11, 2025 am 12:04 AM
2 시간 이내에 Python의 기본 프로그래밍 개념과 기술을 배울 수 있습니다. 1. 변수 및 데이터 유형을 배우기, 2. 마스터 제어 흐름 (조건부 명세서 및 루프), 3. 기능의 정의 및 사용을 이해하십시오. 4. 간단한 예제 및 코드 스 니펫을 통해 Python 프로그래밍을 신속하게 시작하십시오.
 고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
고로드 애플리케이션의 MySQL 성능을 최적화하는 방법은 무엇입니까?
Apr 08, 2025 pm 06:03 PM
MySQL 데이터베이스 성능 최적화 안내서 리소스 집약적 응용 프로그램에서 MySQL 데이터베이스는 중요한 역할을 수행하며 대규모 트랜잭션 관리를 담당합니다. 그러나 응용 프로그램 규모가 확장됨에 따라 데이터베이스 성능 병목 현상은 종종 제약이됩니다. 이 기사는 일련의 효과적인 MySQL 성능 최적화 전략을 탐색하여 응용 프로그램이 고 부하에서 효율적이고 반응이 유지되도록합니다. 실제 사례를 결합하여 인덱싱, 쿼리 최적화, 데이터베이스 설계 및 캐싱과 같은 심층적 인 주요 기술을 설명합니다. 1. 데이터베이스 아키텍처 설계 및 최적화 된 데이터베이스 아키텍처는 MySQL 성능 최적화의 초석입니다. 몇 가지 핵심 원칙은 다음과 같습니다. 올바른 데이터 유형을 선택하고 요구 사항을 충족하는 가장 작은 데이터 유형을 선택하면 저장 공간을 절약 할 수있을뿐만 아니라 데이터 처리 속도를 향상시킬 수 있습니다.
 파이썬 : 기본 응용 프로그램 탐색
Apr 10, 2025 am 09:41 AM
파이썬 : 기본 응용 프로그램 탐색
Apr 10, 2025 am 09:41 AM
Python은 웹 개발, 데이터 과학, 기계 학습, 자동화 및 스크립팅 분야에서 널리 사용됩니다. 1) 웹 개발에서 Django 및 Flask 프레임 워크는 개발 프로세스를 단순화합니다. 2) 데이터 과학 및 기계 학습 분야에서 Numpy, Pandas, Scikit-Learn 및 Tensorflow 라이브러리는 강력한 지원을 제공합니다. 3) 자동화 및 스크립팅 측면에서 Python은 자동화 된 테스트 및 시스템 관리와 같은 작업에 적합합니다.
 Amazon Athena와 함께 AWS Glue Crawler를 사용하는 방법
Apr 09, 2025 pm 03:09 PM
Amazon Athena와 함께 AWS Glue Crawler를 사용하는 방법
Apr 09, 2025 pm 03:09 PM
데이터 전문가는 다양한 소스에서 많은 양의 데이터를 처리해야합니다. 이것은 데이터 관리 및 분석에 어려움을 겪을 수 있습니다. 다행히도 AWS Glue와 Amazon Athena의 두 가지 AWS 서비스가 도움이 될 수 있습니다.
 MySQL이 SQL 서버에 연결할 수 있습니다
Apr 08, 2025 pm 05:54 PM
MySQL이 SQL 서버에 연결할 수 있습니다
Apr 08, 2025 pm 05:54 PM
아니요, MySQL은 SQL Server에 직접 연결할 수 없습니다. 그러나 다음 방법을 사용하여 데이터 상호 작용을 구현할 수 있습니다. 미들웨어 사용 : MySQL에서 중간 형식으로 데이터를 내보낸 다음 미들웨어를 통해 SQL Server로 가져옵니다. 데이터베이스 링커 사용 : 비즈니스 도구는 본질적으로 미들웨어를 통해 여전히 구현되는보다 우호적 인 인터페이스와 고급 기능을 제공합니다.
 Redis로 서버를 시작하는 방법
Apr 10, 2025 pm 08:12 PM
Redis로 서버를 시작하는 방법
Apr 10, 2025 pm 08:12 PM
Redis 서버를 시작하는 단계에는 다음이 포함됩니다. 운영 체제에 따라 Redis 설치. Redis-Server (Linux/MacOS) 또는 Redis-Server.exe (Windows)를 통해 Redis 서비스를 시작하십시오. Redis-Cli Ping (Linux/MacOS) 또는 Redis-Cli.exe Ping (Windows) 명령을 사용하여 서비스 상태를 확인하십시오. Redis-Cli, Python 또는 Node.js와 같은 Redis 클라이언트를 사용하여 서버에 액세스하십시오.
