

http 성능에 영향을 미치는 공통 요소 분석

이 글의 주요 내용은 HTTP 성능에 영향을 미치는 공통 요소를 소개하는 것입니다. 관심 있는 친구들이 이에 대해 배울 수 있습니다.
여기에서 논의하는 HTTP 성능은 단일 서버의 HTTP 성능인 가장 간단한 모델을 기반으로 합니다. 물론 대규모 로드 밸런싱 클러스터에도 적용 가능합니다. HTTP 서버. 또한 클라이언트나 서버 자체의 부하가 너무 높다거나 HTTP 프로토콜을 구현하는 소프트웨어가 다른 IO 모델을 사용한다는 점 또한 배제합니다. 또한 DNS 확인 프로세스 및 웹 애플리케이션 개발 자체의 결함도 무시합니다.
TCP/IP 모델의 관점에서 보면 HTTP의 하위 계층은 TCP 계층이므로 HTTP의 성능은 TCP의 성능에 크게 좌우됩니다. 물론 HTTPS라면 TLS/SSL 계층이 있어야 합니다. 추가했지만 확실히 HTTPS입니다. 성능은 확실히 HTTP보다 나쁘고 여기서는 통신 프로세스를 논의하지 않습니다. 즉, 레이어가 많을수록 성능 손실이 더 심각해집니다.
위 조건에서 HTTP 성능에 영향을 미치는 가장 일반적인 요소는 다음과 같습니다.
3방향 핸드셰이크 단계인 TCP 연결 설정
TCP 느린 시작
TCP 지연 확인
-
Nagle 알고리즘
TIME_WAIT 누적 및 포트 소진
서버 포트 소진
서버 HTTP 프로세스의 열린 파일 수가 최대치에 도달
TCP 연결 설정
일반적으로 네트워크가 안정적이면 TCP 연결 설정이 소모되지 않습니다. 시간이 많이 걸리며 합리적인 시간이 소요되는 범위 내에서 3방향 핸드셰이크 프로세스가 완료됩니다. 그러나 HTTP는 Stateless이고 짧은 연결이므로 TCP 연결은 완료됩니다. HTTP 세션이 승인된 후 연결이 끊어집니다. 웹 페이지에는 일반적으로 많은 리소스가 있습니다. 이는 HTTP 세션과 비교할 때 연결을 설정하는 데 TCP 3방향 핸드셰이크가 너무 오래 걸린다는 것을 의미합니다. 물론 기존 연결을 재사용하여 TCP 연결 설정 수를 줄일 수 있습니다.
TCP Slow Start
TCP 혼잡 제어 방법1, TCP가 설정된 후 초기 전송 단계에서는 연결의 최대 전송 속도가 제한되며, 데이터 전송이 성공하면 전송 속도가 점차 증가됩니다. 미래에는 TCP Slow Start 입니다. 느린 시작은 한 번에 전송할 수 있는 IP 패킷 수2를 제한합니다. 그렇다면 왜 느린 시작이 있습니까? 주된 목적은 대규모 데이터 전송으로 인해 네트워크가 마비되는 것을 방지하는 것입니다. 인터넷에서 데이터 전송에 있어서 매우 중요한 링크는 라우터이며, 또한 라우터 자체의 트래픽이 많지 않습니다. 인터넷이 전송될 수 있으며 특정 기간 동안 라우터에 도착하는 데이터의 양이 보내는 양보다 훨씬 많으면 라우터는 로컬 캐시가 소진되면 데이터 패킷을 삭제합니다. 폐기 동작을 정체라고 합니다. 라우터가 이러한 상황에 직면하면 이는 많은 링크에 영향을 미치고 심각한 경우 광범위한 마비로 이어질 수 있습니다. 따라서 TCP 통신의 모든 당사자는 혼잡 제어를 수행해야 하며 느린 시작은 혼잡 제어의 알고리즘 또는 메커니즘 중 하나입니다.
예를 들어 TCP에 재전송 메커니즘이 있다는 것을 알고 있습니다. 네트워크의 라우터가 정체로 인해 대규모 패킷 손실을 경험한다고 가정하면 해당 TCP 프로토콜 스택이 이 상황을 확실히 감지할 것입니다. TCP 재전송 메커니즘이 시작되고 이 라우터의 영향을 받는 발신자는 귀하뿐만 아니라 많은 수의 발신자 TCP 프로토콜 스택이 재전송을 시작합니다. 이는 원래 혼잡한 네트워크에서 더 많은 데이터 패킷을 보내는 것과 같습니다. 불에 연료를 추가합니다.
위 설명을 통해 일반적인 네트워크 환경에서도 HTTP 메시지의 송신자로서 각 요청에 대한 TCP 연결 설정은 느린 시작의 영향을 받는다는 결론을 내릴 수 있습니다. 그러면 HTTP에 따르면 연결이 짧고 연결이 짧습니다. 세션이 끝나면 연결이 끊어집니다. 열려 있으면 클라이언트가 HTTP 요청을 시작하고 웹 페이지에서 리소스를 얻으며 TCP 연결이 끊어지기 전에 TCP 연결이 끊어질 수 있습니다. 프로세스가 완료되고 웹 페이지의 다른 후속 리소스를 계속 사용할 수 있습니다. TCP 연결을 계속 설정하려면 각 TCP 연결의 시작 단계가 느려질 수 있으므로 성능을 향상시키기 위해 HTTP를 활성화할 수 있습니다. 나중에 keepalive라고 불리는 지속적인 연결.
또한, 우리는 TCP에 창이라는 개념이 있다는 것을 알고 있습니다. 이 창은 송신자와 수신자 모두에게 존재하며, 한편으로는 송신자와 수신자가 패킷을 관리할 수 있도록 보장합니다. 반면에 순서에 따라 여러 패킷을 보내 처리량을 향상시킬 수 있습니다. 또 다른 점은 창 크기를 조정할 수 있다는 것입니다. 목적은 송신자가 수신할 수 있는 것보다 더 빠르게 데이터를 보내는 것을 방지하는 것입니다. 창은 이중 전송 통신 속도 문제를 해결하지만 다른 네트워크 장치는 네트워크를 통과합니다. 발신자는 라우터의 수신 기능을 어떻게 알 수 있습니까? 위에서 소개한 혼잡 제어가 있습니다.
TCP 지연 확인
먼저 확인이 무엇인지 알아야 합니다. 이는 송신자가 수신자에게 TCP 세그먼트를 보낸 후 수신자가 수신했음을 알리기 위해 확인을 다시 보낸다는 의미입니다. 일정 시간 내에 메시지를 보내는데, 승인을 받지 못한 경우 TCP 세그먼트를 다시 보내야 합니다.
확인 메시지는 일반적으로 상대적으로 작습니다. 즉, 하나의 IP 그룹이 여러 개의 확인 메시지를 전달할 수 있으므로 작은 메시지를 너무 많이 보내는 것을 피하기 위해 수신자는 다시 보낼 때 확인 메시지가 있는지 확인하기 위해 기다립니다. 전송된 다른 데이터에 대해 수신자에게 확인 메시지와 데이터가 있으면 TCP 세그먼트에 함께 넣어서 특정 시간(보통 100~200밀리초) 내에 전송해야 할 다른 데이터가 없으면 전송합니다. 그런 다음 확인 메시지를 보냅니다. 확인 메시지는 별도의 패킷으로 전송됩니다. 사실 이렇게 하는 목적은 네트워크 부담을 최대한 줄이는 것입니다.
잘 알려진 예는 물류입니다. 예를 들어, A 도시에서 B 도시까지의 적재 용량이 10톤이라면 확실히 트럭이 가득 차기를 원할 것입니다. 작은 소포가 당신에게 옵니다. 그는 즉시 일어나서 B 도시로 운전했습니다.
그래서 TCP는 데이터 패킷이 오면 즉시 ACK 확인을 반환하도록 설계되지 않았습니다. 일반적으로 일정 기간 동안 캐시에 데이터가 남아 있으면 이전 ACK 확인을 다시 보냅니다. 그러나 시간이 너무 길면 상대방은 패킷이 손실되었다고 생각하고 재전송을 시작합니다.
지연된 확인을 사용할지 여부와 방법에 대해 운영 체제마다 의견이 다릅니다. 예를 들어 Linux를 사용하지 않도록 설정하면 각 항목을 확인하는 것도 빠른 확인 모드입니다.
활성화 여부 또는 설정할 밀리초는 시나리오에 따라 다릅니다. 예를 들어 온라인 게임 시나리오에서는 확인이 가능한 한 빨리 이루어져야 하며 SSH 세션에는 지연된 확인을 사용할 수 있습니다.
HTTP의 경우 TCP 지연 확인을 끄거나 조정할 수 있습니다.
Nagle 알고리즘
이 알고리즘은 실제로 IP 패킷 활용도를 향상하고 네트워크 부담을 줄이기 위해 설계되었습니다. 여기에는 여전히 작은 패킷과 전체 크기 패킷이 포함됩니다(이더넷 표준 MTU 패킷당 1500바이트에 따라 계산됨). 전체 크기가 아닌 패킷으로 간주됨), IP 헤더와 TCP 헤더가 각각 20바이트를 차지하므로 작은 패킷이 아무리 작더라도 40바이트보다 작지는 않습니다. 50바이트의 작은 메시지를 보낸다는 것은 실제로 유효한 데이터가 너무 적다는 것을 의미합니다.지연된 승인과 마찬가지로 작은 크기의 패킷은 LAN에서는 큰 문제가 되지 않지만 주로 WAN에 영향을 미칩니다.
실제로 이 알고리즘은 발신자가 현재 TCP 연결에서 메시지를 보냈지만 아직 확인을 받지 못한 경우, 이때 발신자에게 아직 보낼 작은 메시지가 있으면 보낼 수 없지만 배치해야 한다는 것입니다. 버퍼는 이전에 보낸 메시지의 확인을 기다립니다. 확인을 받은 후 보낸 사람은 버퍼에서 동일한 방향의 작은 메시지를 수집하여 전송을 위해 하나의 메시지로 조립합니다. 실제로 이는 수신자가 ACK 확인을 더 빨리 반환할수록 발신자가 데이터를 더 빨리 보낼 수 있음을 의미합니다.
이제 확인 지연과 Nagle 알고리즘의 결합이 가져올 문제에 대해 이야기해 보겠습니다. 실제로 확인 지연으로 인해 수신자는 일정 시간 동안 ACK 확인을 누적하고, 이 기간 동안 ACK를 수신하지 않으면 발신자는 전체 크기가 아닌 나머지 데이터를 계속 보내지 않는다는 것을 쉽게 알 수 있습니다. 패킷(데이터는 여러 개의 IP 패킷으로 나누어집니다. 송신자가 보내는 응답 데이터 패킷의 수는 1500의 정수배가 될 수 없습니다. 데이터 끝에 있는 일부 데이터는 작을 가능성이 높습니다. 크기의 IP 패킷), 여기서 모순은 이런 종류의 문제가 TCP 전송의 전송 성능에 영향을 미친다는 것입니다. 그러면 HTTP는 TCP에 의존하므로 일반적으로 서버에서 알고리즘을 비활성화합니다. 운영 체제에서 이를 비활성화하거나 프로그램에서 TCP_NODELAY를 설정하여 이 알고리즘을 비활성화할 수 있습니다. 예를 들어 Nginx에서는 tcp_nodelay on;를 사용하여 비활성화할 수 있습니다.
TIME_WAIT 누적 및 포트 소진3
클라이언트인 당사자 또는 TCP 연결을 적극적으로 종료하는 당사자를 의미합니다. 서버도 적극적으로 폐쇄를 시작할 수 있지만 여기서 논의하는 것은 HTTP 성능입니다. HTTP 연결의 특성상 클라이언트는 일반적으로 활성 폐쇄를 시작합니다. 여기서는 소위 홈페이지를 여는 것이 아니라 특정 리소스에 대한 요청입니다. 홈페이지에는 많은 리소스가 있으므로 N개의 HTTP 요청이 발생합니다. 시작됩니다.) 이 요청이 끝나면 TCP 연결이 끊어집니다. 그러면 클라이언트의 연결 TCP 상태가 TIME_WAIT라는 상태로 표시됩니다. 이 상태에서 최종 종료까지 일반적으로 2MSL이 소요됩니다.
4, 우리는 클라이언트가 서버의 HTTP 서비스에 액세스할 때 자체 임의의 높은 비트 포트를 사용하여 서버의 포트 80 또는 443에 연결하여 HTTP 통신을 설정한다는 것을 알고 있습니다(핵심은 TCP 통신입니다). 클라이언트에서 사용 가능한 포트 수 클라이언트가 연결을 끊을 때 이 무작위 포트를 해제하지만 클라이언트가 적극적으로 연결을 끊은 후에는 TIME_WAIT에서 실제까지의 TCP 상태 사이의 2MSL 기간 동안 무작위 포트가 사용되지 않습니다. CLOSED(클라이언트가 동일한 서버에 대한 또 다른 HTTP 액세스를 시작하는 경우) 그 목적 중 하나는 동일한 TCP 소켓의 더티 데이터를 방지하는 것입니다. 위의 결론을 통해 우리는 클라이언트의 서버에 대한 HTTP 액세스가 너무 집중적일 경우 포트 사용 속도가 포트 해제 속도보다 높아질 수 있으며, 이는 결국 사용 가능한 무작위가 없기 때문에 연결 설정에 실패하게 된다는 것을 알고 있습니다. 포트. 우리는 일반적으로 클라이언트가 적극적으로 연결을 종료한다고 위에서 말했습니다.
TCP/IP 상세 설명 1권 제2판, P442 마지막 단락에서는 대화형 응용 프로그램의 경우 클라이언트는 일반적으로 활성 종료 작업을 수행하고 TIME_WAIT 상태에 들어가며, 서버는 일반적으로 수동 종료 작업을 수행하고 TIME_WAIT 상태에 들어가지 않는다고 나와 있습니다. 직접 TIME_WAIT 상태.
그러나 웹 서버가 연결 유지를 활성화한 경우 시간 초과에 도달하면 서버가 자동으로 종료됩니다. (여기서 TCP/IP에 대한 자세한 설명이 틀렸다는 것은 아니지만 해당 섹션에서는 주로 TCP에 대한 것이며 HTTP를 소개하지 않으며 반드시 그런 것은 아니고 일반적으로 말합니다.)
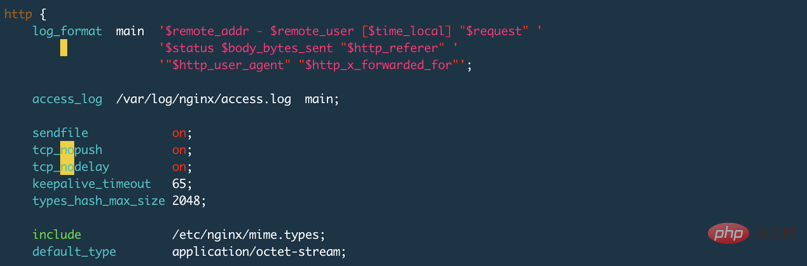
테스트에는 Nginx를 사용합니다. code>keepalive_timeout 65s;는 구성 파일에 설정되어 있습니다. Nginx의 기본 설정은 75s입니다. 0으로 설정하면 아래와 같이 keepalive가 비활성화됩니다. keepalive_timeout 65s;,Nginx的默认设置是75s,设置为0表示禁用keepalive,如下图:
下面我使用Chrom浏览器访问这个Nginx默认提供的主页,并通过抓包程序来监控整个通信过程,如下图:
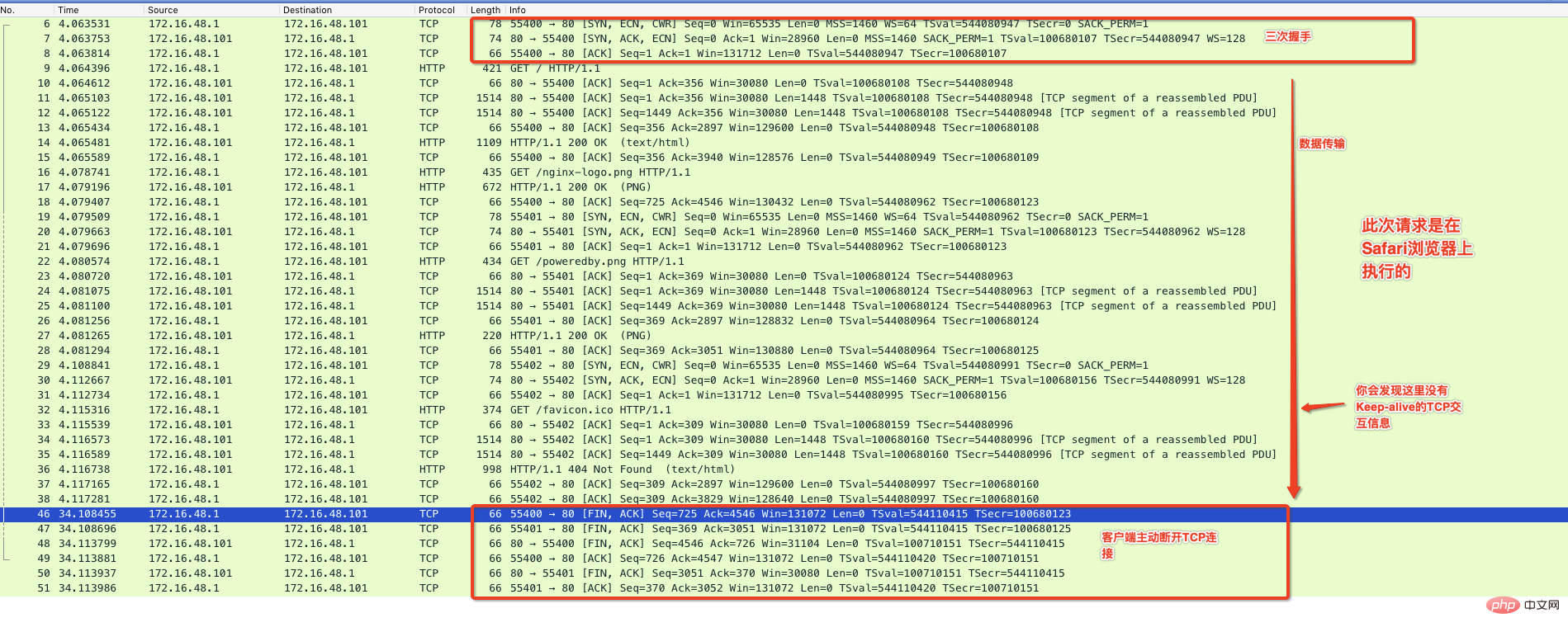
从上图可以看出来在有效数据传送完毕后,中间出现了Keep-Alive标记的通信,并且在65秒内没有请求后服务器主动断开连接,这种情况你在Nginx的服务器上就会看到TIME_WAIT的状态。
服务端端口耗尽
有人说Nginx监听80或者443,客户端都是连接这个端口,服务端怎么会端口耗尽呢?就像下图一样(忽略图中的TIME_WAIT,产生这个的原因上面已经说过了是因为Nginx的keepalive_timeout设置导致的)
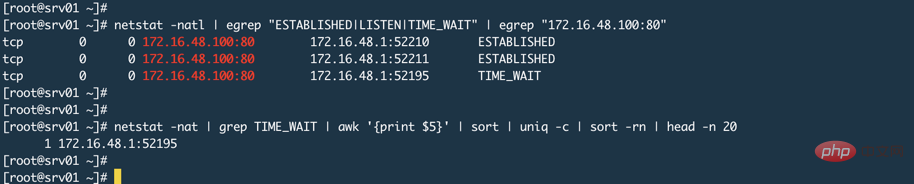
其实,这取决于Nginx工作模式,我们使用Nginx通常都是让其工作在代理模式,这就意味着真正的资源或者数据在后端Web应用程序上,比如Tomcat。代理模式的特点是代理服务器代替用户去后端获取数据,那么此时相对于后端服务器来说,Nginx就是一个客户端,这时候Nginx就会使用随机端口来向后端发起请求,而系统可用随机端口范围是一定的,可以使用sysctl net.ipv4.ip_local_port_range命令来查看服务器上的随机端口范围。
通过我们之前介绍的延迟确认、Nagle算法以及代理模式下Nginx充当后端的客户端角色并使用随机端口连接后端,这就意味着服务端的端口耗尽风险是存在的。随机端口释放速度如果比与后端建立连接的速度慢就有可能出现。不过一般不会出现这个情况,至少我们公司的Nginx我没有发现有这种现象产生。因为首先是静态资源都在CDN上;其次后端大部分都是REST接口提供用户认证或者数据库操作,这些操作其实后端如果没有瓶颈的话基本都很快。不过话说回来如果后端真的有瓶颈且扩容或者改架构成本比较高的话,那么当面对大量并发的时候你应该做的是限流防止后端被打死。
服务端HTTP进程打开文件数量达到最大
我们说过HTTP通信依赖TCP连接,一个TCP连接就是一个套接字,对于类Unix系统来说,打开一个套接字就是打开一个文件,如果有100个请求连接服务端,那么一旦连接建立成功服务端就会打开100个文件,而Linux系统中一个进程可以打开的文件数量是有限的ulimit -f
 다음으로 Chrom 브라우저를 이용하여 Nginx에서 기본적으로 제공하는 홈페이지에 접속하고, 패킷 캡쳐를 통해 전체 통신 과정을 모니터링합니다. 프로그램, 아래와 같이:
다음으로 Chrom 브라우저를 이용하여 Nginx에서 기본적으로 제공하는 홈페이지에 접속하고, 패킷 캡쳐를 통해 전체 통신 과정을 모니터링합니다. 프로그램, 아래와 같이:
서버 포트가 소진되었습니다
어떤 사람들은 Nginx가 80 또는 443을 수신한다고 말합니다. 클라이언트는 항상 이 포트에 연결합니다. 어떻게 서버에 포트가 부족할 수 있습니까? 아래 그림과 같습니다(그림에서 TIME_WAIT 무시, 그 이유는 위에서 언급했으며 Nginx의 keepalive_timeout 설정으로 인해 발생합니다)
🎜 🎜🎜사실 이는 Nginx의 작업 모드에 따라 다릅니다. Nginx를 사용할 때 일반적으로 프록시 모드에서 작동하도록 설정하는데, 이는 실제 리소스나 데이터가 Tomcat과 같은 온엔드 웹 애플리케이션 뒤에 있습니다. 프록시 모드의 특징은 프록시 서버가 사용자를 대신하여 데이터를 가져오는 것입니다. 이때 Nginx는 클라이언트입니다. 백엔드에 대한 요청을 시작하면 시스템을 사용할 수 있습니다. 임의 포트 범위는 확실합니다.
🎜🎜사실 이는 Nginx의 작업 모드에 따라 다릅니다. Nginx를 사용할 때 일반적으로 프록시 모드에서 작동하도록 설정하는데, 이는 실제 리소스나 데이터가 Tomcat과 같은 온엔드 웹 애플리케이션 뒤에 있습니다. 프록시 모드의 특징은 프록시 서버가 사용자를 대신하여 데이터를 가져오는 것입니다. 이때 Nginx는 클라이언트입니다. 백엔드에 대한 요청을 시작하면 시스템을 사용할 수 있습니다. 임의 포트 범위는 확실합니다. sysctl net.ipv4.ip_local_port_range 명령을 사용하면 서버의 임의 포트 범위를 볼 수 있습니다. 🎜🎜앞서 소개한 지연 확인, Nagle 알고리즘 및 프록시 모드를 통해 Nginx는 백엔드의 클라이언트 역할을 하며 임의의 포트를 사용하여 백엔드에 연결하므로 서버 측에서 포트가 고갈될 위험이 존재합니다. 백엔드와의 연결 속도보다 느릴 경우 임의의 포트 해제 속도가 발생할 수 있습니다. 하지만 일반적으로 이런 상황은 발생하지 않습니다. 적어도 저희 회사 Nginx에서는 이런 현상을 발견하지 못했습니다. 우선 정적 리소스가 CDN에 있기 때문에 둘째, 대부분의 백엔드는 REST 인터페이스를 사용하여 사용자 인증 또는 데이터베이스 작업을 제공합니다. 실제로 백엔드에 병목 현상이 없으면 이러한 작업은 기본적으로 매우 빠릅니다. 그러나 백엔드에 실제로 병목 현상이 있고 확장 또는 아키텍처 변경 비용이 상대적으로 높다면 동시성이 많이 발생할 때 해야 할 일은 백엔드가 종료되는 것을 방지하기 위해 흐름을 제한하는 것입니다. 🎜서버측 HTTP 프로세스에서 연 파일 수가 최대값에 도달했습니다🎜🎜HTTP 통신은 다음을 사용한다고 말했습니다. TCP 연결. TCP 연결은 소켓입니다. 즉, 소켓을 여는 것은 서버에 연결하라는 요청이 100개 있으면 연결이 성공적으로 이루어지면 서버가 100개의 파일을 여는 것을 의미합니다. 그러나 Linux 시스템에서는 프로세스가 열 수 있는 파일 수가 제한되어 있으므로 이 값을 너무 작게 설정하면 HTTP 연결에도 영향을 미칩니다. 프록시 모드에서 실행되는 Nginx 또는 기타 HTTP 프로그램의 경우 일반적으로 하나의 연결이 두 개의 소켓을 열고 두 개의 파일을 차지합니다(Nginx 로컬 캐시에 도달하거나 Nginx가 데이터를 직접 반환하는 경우 제외). 따라서 프록시 서버 프로세스에서 열 수 있는 파일 수도 크게 설정해야 합니다. 🎜🎜지속적인 연결 Keepalive🎜🎜먼저 Keepalive는 두 가지 수준으로 설정할 수 있으며 두 수준은 서로 다른 의미를 갖는다는 것을 알아야 합니다. TCP의 keepalive는 감지 메커니즘입니다. 예를 들어, 하트비트 정보는 상대방이 아직 온라인 상태임을 나타냅니다. 이 하트비트 정보는 서로 간의 TCP 연결이 항상 열려 있어야 함을 의미합니다. HTTP의 -alive는 TCP 연결의 빈번한 설정을 피하기 위해 TCP 연결을 재사용하는 메커니즘입니다. 🎜그러므로 TCP의 Keepalive와 HTTP의 Keep-alive가 같은 것이 아니라는 점을 이해해야 합니다🎜. 🎜🎜HTTP의 연결 유지 메커니즘🎜🎜비지속적 연결은 각 HTTP 트랜잭션이 완료된 후 TCP 연결을 끊고 다음 HTTP 트랜잭션에서 TCP 연결을 다시 설정합니다. 이는 분명히 효율적인 메커니즘이 아니므로 HTTP/ 1.1 및 HTTP/1.0의 향상된 버전에서는 HTTP가 트랜잭션이 끝난 후에도 TCP 연결을 열린 상태로 유지할 수 있으므로 클라이언트나 서버가 적극적으로 연결을 닫을 때까지 후속 HTTP 트랜잭션이 연결을 재사용할 수 있습니다. 영구 연결은 TCP 연결 설정 수를 줄이고 TCP 느린 시작으로 인한 트래픽 제한도 최소화합니다. 🎜
관련 튜토리얼: HTTP 비디오 튜토리얼
이 사진을 다시 보세요, 사진 속 keepalive_timeout 65s는 http를 켜는 연결 유지 기능을 설정하고 시간 초과를 65초로 설정합니다. 실제로 더 중요한 옵션이 하나 더 있습니다: keepalive_requests 100; TCP 연결에는 시작할 수 있는 HTTP 요청 수가 가장 많습니다. 기본값은 100입니다. keepalive_timeout 65s设置了开启http的keep-alive特性并且设置了超时时长为65秒,其实还有比较重要的选项是keepalive_requests 100;它表示同一个TCP连接最多可以发起多少个HTTP请求,默认是100个。
在HTTP/1.0中keep-alive并不是默认使用的,客户端发送HTTP请求时必须带有Connection: Keep-alive的首部来试图激活keep-alive,如果服务器不支持那么将无法使用,所有请求将以常规形式进行,如果服务器支持那么在响应头中也会包括Connection: Keep-alive的信息。
在HTTP/1.1中默认就使用Keep-alive,除非特别说明,否则所有连接都是持久的。如果要在一个事务结束后关闭连接,那么HTTP的响应头中必须包含Connection: CLose首部,否则该连接会始终保持打开状态,当然也不能总是打开,也必须关闭空闲连接,就像上面Nginx的设置一样最多保持65秒的空闲连接,超过后服务端将会主动断开该连接。
TCP的keepalive
在Linux上没有一个统一的开关去开启或者关闭TCP的Keepalive功能,查看系统keepalive的设置sysctl -a | grep tcp_keepalive,如果你没有修改过,那么在Centos系统上它会显示:
net.ipv4.tcp_keepalive_intvl = 75 # 两次探测直接间隔多少秒 net.ipv4.tcp_keepalive_probes = 9 # 探测频率 net.ipv4.tcp_keepalive_time = 7200 # 表示多长时间进行一次探测,单位秒,这里也就是2小时
按照默认设置,那么上面的整体含义就是2小时探测一次,如果第一次探测失败,那么过75秒再探测一次,如果9次都失败就主动断开连接。
如何开启Nginx上的TCP层面的Keepalive,在Nginx中有一个语句叫做listen
Connection: Keep-alive 헤더를 포함해야 합니다. Keep-alive를 활성화하기 위해 서버가 지원하지 않으면 모든 요청이 일반 형식으로 이루어집니다. 서버가 지원하는 경우 Connection: Keep-alive 정보. 응답 헤더에도 포함됩니다.
HTTP/1.1에서는 기본적으로 연결 유지가 사용됩니다. 달리 지정하지 않는 한 모든 연결은 지속됩니다. 트랜잭션이 끝난 후 연결을 닫으려면 HTTP 응답 헤더에 Connection: CLose 헤더가 포함되어야 합니다. 그렇지 않으면 연결이 항상 열려 있을 것입니다. 물론 항상 열려 있을 수는 없습니다. 연결은 위의 Nginx 설정과 마찬가지로 최대 65초 동안 유휴 연결을 유지할 수 있으며 그 이후에는 서버가 적극적으로 연결을 끊습니다.
TCP keepalive
sysctl - a | grep tcp_keepalive, 수정하지 않은 경우 Centos 시스템에 다음이 표시됩니다. # 表示开启,TCP的keepalive参数使用系统默认的 listen 80 default_server so_keepalive=on; # 表示显式关闭TCP的keepalive listen 80 default_server so_keepalive=off; # 表示开启,设置30分钟探测一次,探测间隔使用系统默认设置,总共探测10次,这里的设 # 置将会覆盖上面系统默认设置 listen 80 default_server so_keepalive=30m::10;
- 기본 설정에 따르면 위의 전반적인 의미는 한 번 감지한다는 것입니다. 2시간마다 첫 번째 감지에 실패하면 75초 후에 다시 감지됩니다. 9번 실패하면 적극적으로 연결이 끊어집니다.
-
Nginx의 TCP 수준에서 Keepalive를 활성화하는 방법 Nginx에는
rrreeelisten이라는 명령문이 있습니다. 이는 Nginx가 수신 대기하는 포트를 설정하는 데 사용되는 서버 섹션의 명령문입니다. 실제로 소켓 속성을 설정하는 데 사용되는 다른 매개변수가 있습니다. 따라서 Nginx에서 이 so_keepalive를 설정할지 여부는 특정 항목에 따라 다릅니다. Nginx는 so_keepalive를 활성화하지 않고 HTTP 요청의 연결 유지 기능 사용에 영향을 미치지 않기 때문에 TCP의 연결 유지는 HTTP의 연결 유지와 혼동되지 않습니다. 클라이언트와 Nginx 사이에 직접 또는 Nginx와 백엔드 서버 사이에 로드 밸런싱 장치가 있고 응답과 요청이 이 로드 밸런싱 장치를 통과하는 경우 이 so_keepalive에 주의해야 합니다. 예를 들어, LVS의 다이렉트 라우팅 모드에서는 응답이 - LVS를 거치지 않기 때문에 영향을 받지 않습니다. 그러나 NAT 모드인 경우에는 LVS에도
LVS가 있으므로 주의해야 합니다. 지속 시간이 백엔드에서 데이터를 반환하는 지속 시간보다 짧은 경우, LVS는 클라이언트가 데이터를 수신하기 전에 TCP 연결을 끊습니다.
- TCP 혼잡 제어에는 TCP 느린 시작, 혼잡 회피 및 기타 알고리즘을 포함한 일부 알고리즘이 있습니다 ↩
- #🎜🎜 # 어떤 곳에서는 이를 IP 단편화라고도 부르지만 모두 같은 의미입니다. 단편화가 단순히 데이터 링크 계층으로 제한되는 이유는 데이터 링크마다 MTU가 다르며 이더넷의 경우 1500바이트입니다. , 일부 시나리오에서는 FDDI의 MTU가 다른 크기일 수 있습니다. 단순히 IP 계층을 고려하면 최대 IP 데이터 패킷은 65535바이트↩
위 내용은 http 성능에 영향을 미치는 공통 요소 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7662
7662
 15
1393
52
1205
24
91
11
73
19
15
1393
52
1205
24
91
11
73
19

 http 상태 코드 520은 무엇을 의미합니까?
Oct 13, 2023 pm 03:11 PM
http 상태 코드 520은 무엇을 의미합니까?
Oct 13, 2023 pm 03:11 PM
HTTP 상태 코드 520은 서버가 요청을 처리하는 동안 알 수 없는 오류가 발생하여 더 구체적인 정보를 제공할 수 없음을 의미합니다. 서버가 요청을 처리하는 동안 알 수 없는 오류가 발생했음을 나타내는 데 사용됩니다. 이는 서버 구성 문제, 네트워크 문제 또는 기타 알 수 없는 이유로 인해 발생할 수 있습니다. 이는 일반적으로 서버 구성 문제, 네트워크 문제, 서버 과부하 또는 코딩 오류로 인해 발생합니다. 상태 코드 520 오류가 발생하면 웹사이트 관리자나 기술 지원팀에 문의하여 자세한 정보와 지원을 받는 것이 가장 좋습니다.
 Kirin 8000 및 Snapdragon 프로세서의 성능 분석: 강점과 약점의 세부 비교
Mar 24, 2024 pm 06:09 PM
Kirin 8000 및 Snapdragon 프로세서의 성능 분석: 강점과 약점의 세부 비교
Mar 24, 2024 pm 06:09 PM
Kirin 8000과 Snapdragon 프로세서 성능 분석: 장단점 상세 비교 스마트폰의 인기와 기능성이 높아지면서 휴대폰의 핵심 부품인 프로세서도 많은 주목을 받고 있습니다. 현재 시장에 나와 있는 가장 일반적이고 우수한 프로세서 브랜드 중 하나는 Huawei의 Kirin 시리즈와 Qualcomm의 Snapdragon 시리즈입니다. 이 기사에서는 Kirin 8000과 Snapdragon 프로세서의 성능 분석에 중점을 두고 두 프로세서의 장단점을 다양한 측면에서 비교해 보겠습니다. 먼저 Kirin 8000 프로세서를 살펴보겠습니다. 화웨이의 최신 플래그십 프로세서인 Kirin 8000
 성능 비교: Go 언어와 C 언어의 속도 및 효율성
Mar 10, 2024 pm 02:30 PM
성능 비교: Go 언어와 C 언어의 속도 및 효율성
Mar 10, 2024 pm 02:30 PM
성능 비교: Go 언어와 C 언어의 속도와 효율성 컴퓨터 프로그래밍 분야에서 성능은 항상 개발자가 주목하는 중요한 지표였습니다. 프로그래밍 언어를 선택할 때 개발자는 일반적으로 속도와 효율성에 중점을 둡니다. 널리 사용되는 프로그래밍 언어인 Go 언어와 C 언어는 시스템 수준 프로그래밍과 고성능 애플리케이션에 널리 사용됩니다. 이 글에서는 속도와 효율성 측면에서 Go 언어와 C 언어의 성능을 비교하고 구체적인 코드 예제를 통해 차이점을 보여줍니다. 먼저 Go 언어와 C 언어의 개요를 살펴보겠습니다. Go 언어는 G가 개발했습니다.
 웹 페이지 리디렉션의 일반적인 애플리케이션 시나리오를 이해하고 HTTP 301 상태 코드를 이해합니다.
Feb 18, 2024 pm 08:41 PM
웹 페이지 리디렉션의 일반적인 애플리케이션 시나리오를 이해하고 HTTP 301 상태 코드를 이해합니다.
Feb 18, 2024 pm 08:41 PM
HTTP 301 상태 코드의 의미 이해: 웹 페이지 리디렉션의 일반적인 응용 시나리오 인터넷의 급속한 발전으로 인해 사람들은 웹 페이지 상호 작용에 대한 요구 사항이 점점 더 높아지고 있습니다. 웹 디자인 분야에서 웹 페이지 리디렉션은 HTTP 301 상태 코드를 통해 구현되는 일반적이고 중요한 기술입니다. 이 기사에서는 HTTP 301 상태 코드의 의미와 웹 페이지 리디렉션의 일반적인 응용 프로그램 시나리오를 살펴봅니다. HTTP301 상태 코드는 영구 리디렉션(PermanentRedirect)을 나타냅니다. 서버가 클라이언트의 정보를 받을 때
 C#의 일반적인 네트워크 통신 및 보안 문제와 솔루션
Oct 09, 2023 pm 09:21 PM
C#의 일반적인 네트워크 통신 및 보안 문제와 솔루션
Oct 09, 2023 pm 09:21 PM
C#의 일반적인 네트워크 통신 및 보안 문제와 해결 방법 오늘날 인터넷 시대에 네트워크 통신은 소프트웨어 개발에 없어서는 안 될 부분이 되었습니다. C#에서는 일반적으로 데이터 전송 보안, 네트워크 연결 안정성 등과 같은 일부 네트워크 통신 문제가 발생합니다. 이 문서에서는 C#의 일반적인 네트워크 통신 및 보안 문제에 대해 자세히 설명하고 해당 솔루션과 코드 예제를 제공합니다. 1. 네트워크 통신 문제 네트워크 연결 중단: 네트워크 통신 과정에서 네트워크 연결이 중단될 수 있으며, 이로 인해
 HTTP 200 OK: 성공적인 응답의 의미와 목적을 이해합니다.
Dec 26, 2023 am 10:25 AM
HTTP 200 OK: 성공적인 응답의 의미와 목적을 이해합니다.
Dec 26, 2023 am 10:25 AM
HTTP 상태 코드 200: 성공적인 응답의 의미와 목적 탐색 HTTP 상태 코드는 서버 응답 상태를 나타내는 데 사용되는 숫자 코드입니다. 그 중 상태 코드 200은 요청이 서버에 의해 성공적으로 처리되었음을 나타냅니다. 이 기사에서는 HTTP 상태 코드 200의 구체적인 의미와 사용법을 살펴보겠습니다. 먼저 HTTP 상태 코드의 분류를 이해해 보겠습니다. 상태 코드는 1xx, 2xx, 3xx, 4xx 및 5xx의 다섯 가지 범주로 나뉩니다. 그 중 2xx는 성공적인 응답을 나타냅니다. 그리고 200은 2xx에서 가장 일반적인 상태 코드입니다.
 C++ 코드의 성능 분석을 수행하는 방법은 무엇입니까?
Nov 02, 2023 pm 02:36 PM
C++ 코드의 성능 분석을 수행하는 방법은 무엇입니까?
Nov 02, 2023 pm 02:36 PM
C++ 코드의 성능 분석을 수행하는 방법 C++ 프로그램을 개발할 때 성능은 중요한 고려 사항입니다. 코드 성능을 최적화하면 프로그램의 속도와 효율성이 향상될 수 있습니다. 그러나 코드를 최적화하려면 먼저 성능 병목 현상이 발생하는 위치를 이해해야 합니다. 성능 병목 현상을 찾으려면 먼저 코드 성능 분석을 수행해야 합니다. 이 기사에서는 개발자가 최적화를 위해 코드에서 성능 병목 현상을 찾는 데 도움이 되는 몇 가지 일반적으로 사용되는 C++ 코드 성능 분석 도구 및 기술을 소개합니다. 프로파일링 도구를 사용한 프로파일링 도구
 http 요청 415 오류 해결 방법
Nov 14, 2023 am 10:49 AM
http 요청 415 오류 해결 방법
Nov 14, 2023 am 10:49 AM
해결 방법: 1. 요청 헤더에서 Content-Type을 확인합니다. 2. 요청 본문에서 데이터 형식을 확인합니다. 3. 적절한 인코딩 형식을 사용합니다. 4. 적절한 요청 방법을 사용합니다. 5. 서버측 지원을 확인합니다.
