
bootstrap 및 부스팅은 기계 학습에서 일반적으로 사용되는 몇 가지 리샘플링 방법입니다. 그 중 통계 추정에는 부트스트랩 리샘플링(Bootstrap Resampling) 방식이 주로 사용되고, 여러 하위 분류기의 조합에는 부스팅(Boosting) 방식이 주로 사용된다.

bootstrap: 통계 추정을 위한 리샘플링 방법 (권장 학습: Python 비디오 튜토리얼 )
부트스트랩 방법은 크기가 n인 원래 훈련 데이터 세트 DD에서 n개의 샘플 포인트를 무작위로 선택하여 새로운 훈련 세트를 형성하는 것입니다. 그런 다음 이 선택 과정을 독립적으로 B번 반복합니다. 이 B 데이터 세트를 사용하여 모델 통계(예: 평균, 분산 등)를 추정합니다. 원래 데이터 세트의 크기가 n이므로 이러한 B개의 새로운 훈련 세트에는 필연적으로 중복 샘플이 있을 것입니다.
통계의 추정값은 독립적인 B 훈련 세트에 대한 추정값 θbθb의 평균으로 정의됩니다.
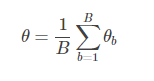 #🎜 🎜## 🎜🎜#
#🎜 🎜## 🎜🎜#
boosting은 k개의 하위 분류자를 순차적으로 훈련시키고, 최종 분류 결과는 이러한 하위 분류자의 투표에 의해 결정됩니다.
먼저 n1n1 샘플을 크기 n의 원래 훈련 데이터 세트에서 무작위로 선택하여 C1C1로 표시된 첫 번째 분류기를 훈련시킨 다음 두 번째 분류기 C2C2의 훈련 세트 D2D2를 구성합니다. D2D2의 샘플 중 절반은 C1C1에 의해 올바르게 분류될 수 있는 반면, 샘플의 나머지 절반은 C1C1에 의해 잘못 분류되었습니다.
그런 다음 세 번째 분류기 C3C3의 훈련 세트 D3D3을 계속 구성합니다. 요구 사항은 다음과 같습니다. C1C1과 C2C2는 D3D3의 샘플에 대해 서로 다른 분류 결과를 갖습니다. 나머지 하위 분류기는 유사한 라인을 따라 훈련됩니다.
Boosting 새로운 훈련 세트를 구성하는 주요 원칙은 가장 유용한 샘플을 사용하는 것입니다.
더 많은 Python 관련 기술 기사를 보려면
위 내용은 부스팅과 부트스트랩의 차이점의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



