돔 DOM은 Document Object Model의 약자입니다. 문서 객체 모델은 XML이나 HTML을 트리 노드 형태로 표현한 문서이다. DOM 메서드와 속성을 사용하면 페이지의 모든 요소에 액세스하고 수정하고 삭제할 수 있으며 요소를 추가할 수도 있습니다. DOM은 Javascript를 포함한 모든 언어로 구현될 수 있는 언어 독립적인 API입니다
아래 텍스트 중 하나를 살펴보십시오.
P태그임을 알 수 있습니다. body 태그에 포함되어 있습니다. 따라서 body는 p의 부모 노드이고 p는 자식 노드입니다. 첫 번째와 세 번째 단락도 본문의 하위 노드입니다. 이들은 모두 두 번째 단락의 형제 노드입니다. 이 em 태그는 두 번째 세그먼트 p의 하위 노드입니다. 따라서 p는 상위 노드입니다. 부모-자식 노드 관계는 나무와 같은 관계를 묘사할 수 있습니다. 그래서 DOM 트리라고 부릅니다.
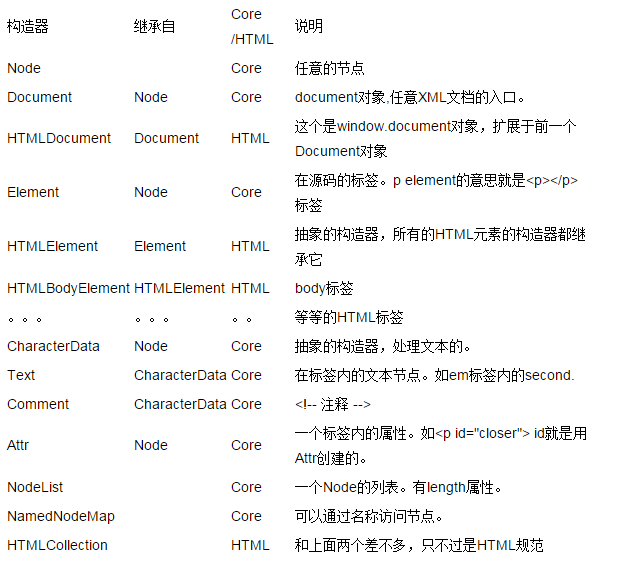
핵심 DOM과 HTML DOM 우리는 DOM이 HTML 및 XML 문서를 묘사할 수 있다는 것을 이미 알고 있습니다. 실제로 HTML 문서는 XML 문서이지만 더 표준화되어 있습니다. 따라서 DOM 레벨 1의 일부로 Core DOM 사양은 모든 XML 문서에 적용되고 HTML DOM 사양은 Core DOM을 확장합니다. 물론 HTML DOM은 HTML 문서에만 적용됩니다. Core DOM과 HTML DOM의 생성자를 살펴보겠습니다.
시공자 관계
DOM 노드 액세스 양식의 유효성을 검사하거나 이미지를 변경하기 전에 요소(element.)에 액세스하는 방법을 알아야 합니다. 요소를 얻는 방법에는 여러 가지가 있습니다.
문서 노드 문서를 통해 현재 문서에 접근할 수 있습니다. Firebug(Firefox 플러그인)를 사용하여 문서의 속성과 메서드를 볼 수 있습니다.
모든 노드에는 nodeType, nodeName, nodeValue 속성이 있습니다. 문서의 nodeType을 살펴보겠습니다
document.nodeType;//9
로그인 후 복사
총 12가지 노드 유형이 있습니다. 문서는 9입니다. 일반적으로 사용되는 것은 요소(element: 1), 속성(attribute: 2), 텍스트(text: 3)입니다.
노드에도 이름이 있습니다. HTML 태그의 경우. 노드 이름은 레이블 이름입니다. 텍스트 노드(text)의 이름은 #text입니다. 문서 노드(document)의 이름은 #document입니다.
노드에도 값이 있습니다. 텍스트 노드의 경우 값은 텍스트입니다. 문서 값이 null입니다
문서 요소 XML에는 문서를 래핑하기 위한 ROOT 노드가 있습니다. HTML 문서의 경우. ROOT 노드는 html 태그입니다. 루트 노드에 액세스합니다. documentElement의 속성을 사용할 수 있습니다.
WebSocket 및 JavaScript를 사용하여 온라인 음성 인식 시스템을 구현하는 방법 소개: 지속적인 기술 개발로 음성 인식 기술은 인공 지능 분야의 중요한 부분이 되었습니다. WebSocket과 JavaScript를 기반으로 한 온라인 음성 인식 시스템은 낮은 대기 시간, 실시간, 크로스 플랫폼이라는 특징을 갖고 있으며 널리 사용되는 솔루션이 되었습니다. 이 기사에서는 WebSocket과 JavaScript를 사용하여 온라인 음성 인식 시스템을 구현하는 방법을 소개합니다.
주식 분석을 위한 필수 도구: PHP 및 JS에서 캔들 차트를 그리는 단계를 배우십시오. 인터넷과 기술의 급속한 발전으로 주식 거래는 많은 투자자에게 중요한 방법 중 하나가 되었습니다. 주식분석은 투자자의 의사결정에 있어 중요한 부분이며 캔들차트는 기술적 분석에 널리 사용됩니다. PHP와 JS를 사용하여 캔들 차트를 그리는 방법을 배우면 투자자가 더 나은 결정을 내리는 데 도움이 되는 보다 직관적인 정보를 얻을 수 있습니다. 캔들스틱 차트는 주가를 캔들스틱 형태로 표시하는 기술 차트입니다. 주가를 보여주네요
얼굴 검출 및 인식 기술은 이미 상대적으로 성숙하고 널리 사용되는 기술입니다. 현재 가장 널리 사용되는 인터넷 응용 언어는 JS입니다. 웹 프런트엔드에서 얼굴 감지 및 인식을 구현하는 것은 백엔드 얼굴 인식에 비해 장점과 단점이 있습니다. 장점에는 네트워크 상호 작용 및 실시간 인식이 줄어 사용자 대기 시간이 크게 단축되고 사용자 경험이 향상된다는 단점이 있습니다. 모델 크기에 따라 제한되고 정확도도 제한됩니다. js를 사용하여 웹에서 얼굴 인식을 구현하는 방법은 무엇입니까? 웹에서 얼굴 인식을 구현하려면 JavaScript, HTML, CSS, WebRTC 등 관련 프로그래밍 언어 및 기술에 익숙해야 합니다. 동시에 관련 컴퓨터 비전 및 인공지능 기술도 마스터해야 합니다. 웹 측면의 디자인으로 인해 주목할 가치가 있습니다.
WebSocket과 JavaScript: 실시간 모니터링 시스템 구현을 위한 핵심 기술 서론: 인터넷 기술의 급속한 발전과 함께 실시간 모니터링 시스템이 다양한 분야에서 널리 활용되고 있다. 실시간 모니터링을 구현하는 핵심 기술 중 하나는 WebSocket과 JavaScript의 조합입니다. 이 기사에서는 실시간 모니터링 시스템에서 WebSocket 및 JavaScript의 적용을 소개하고 코드 예제를 제공하며 구현 원칙을 자세히 설명합니다. 1. 웹소켓 기술
인터넷 금융의 급속한 발전으로 인해 주식 투자는 점점 더 많은 사람들의 선택이 되었습니다. 주식 거래에서 캔들 차트는 주가의 변화 추세를 보여주고 투자자가 보다 정확한 결정을 내리는 데 도움이 되는 일반적으로 사용되는 기술적 분석 방법입니다. 이 기사에서는 PHP와 JS의 개발 기술을 소개하고 독자가 주식 캔들 차트를 그리는 방법을 이해하도록 유도하며 구체적인 코드 예제를 제공합니다. 1. 주식 캔들 차트의 이해 주식 캔들 차트를 그리는 방법을 소개하기 전에 먼저 캔들 차트가 무엇인지부터 이해해야 합니다. 캔들스틱 차트는 일본인이 개발했습니다.
JavaScript 및 WebSocket을 사용하여 실시간 온라인 주문 시스템을 구현하는 방법 소개: 인터넷의 대중화와 기술의 발전으로 점점 더 많은 레스토랑에서 온라인 주문 서비스를 제공하기 시작했습니다. 실시간 온라인 주문 시스템을 구현하기 위해 JavaScript 및 WebSocket 기술을 사용할 수 있습니다. WebSocket은 TCP 프로토콜을 기반으로 하는 전이중 통신 프로토콜로 클라이언트와 서버 간의 실시간 양방향 통신을 실현할 수 있습니다. 실시간 온라인 주문 시스템에서는 사용자가 요리를 선택하고 주문을 하면
JavaScript 튜토리얼: HTTP 상태 코드를 얻는 방법, 특정 코드 예제가 필요합니다. 서문: 웹 개발에서는 서버와의 데이터 상호 작용이 종종 포함됩니다. 서버와 통신할 때 반환된 HTTP 상태 코드를 가져와서 작업의 성공 여부를 확인하고 다양한 상태 코드에 따라 해당 처리를 수행해야 하는 경우가 많습니다. 이 기사에서는 JavaScript를 사용하여 HTTP 상태 코드를 얻는 방법과 몇 가지 실용적인 코드 예제를 제공합니다. XMLHttpRequest 사용
JavaScript 및 WebSocket: 효율적인 실시간 일기 예보 시스템 구축 소개: 오늘날 일기 예보의 정확성은 일상 생활과 의사 결정에 매우 중요합니다. 기술이 발전함에 따라 우리는 날씨 데이터를 실시간으로 획득함으로써 보다 정확하고 신뢰할 수 있는 일기예보를 제공할 수 있습니다. 이 기사에서는 JavaScript 및 WebSocket 기술을 사용하여 효율적인 실시간 일기 예보 시스템을 구축하는 방법을 알아봅니다. 이 문서에서는 특정 코드 예제를 통해 구현 프로세스를 보여줍니다. 우리