

MySQL 데이터베이스 SQL 문 최적화


문제 SQL 판단
SQL에 문제가 있는지 여부를 두 가지 증상으로 판단할 수 있습니다.
- 시스템 수준 증상
- CPU 소모가 심함
- IO 대기가 심함
- 페이지 응답 시간 만료됨 긴
- 애플리케이션의 로그에 시간 초과 및 기타 오류
가 있는 경우 sar 명령과 top 명령을 사용하여 현재 로그를 볼 수 있습니다. 시스템 상태. sar命令,top命令查看当前系统状态。

也可以通过Prometheus、Grafana等监控工具观察系统状态。
- SQL语句表象
- 冗长
- 执行时间过长
- 从全表扫描获取数据
- 执行计划中的rows、cost很大
冗长的SQL都好理解,一段SQL太长阅读性肯定会差,而且出现问题的频率肯定会更高。更进一步判断SQL问题就得从执行计划入手,如下所示:

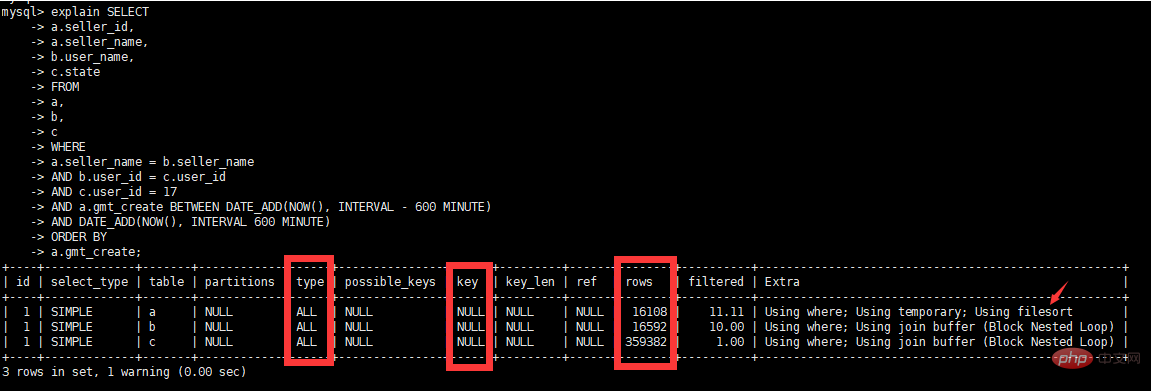
执行计划告诉我们本次查询走了全表扫描Type=ALL
Prometheus를 사용할 수도 있습니다 , Grafana와 같은 모니터링 도구는 시스템 상태를 관찰합니다.
- SQL 문 표현
- 긴
- 실행 시간이 너무 깁니다
- 전체 테이블 스캔에서 데이터 가져오기
- 실행 계획의 행과 비용이 매우 큽니다
- 긴 SQL은 이해하기 쉽지만 SQL이 너무 길면 가독성이 떨어집니다. 확실히 가난하고 문제가 발생할 수 있습니다. 빈도는 확실히 더 높을 것입니다. SQL 문제를 더 자세히 파악하려면 아래와 같이 실행 계획부터 시작해야 합니다.

- 실행 계획에 따르면 이 쿼리는 전체 테이블 스캔
Type=ALL을 거쳤으며 행이 매우 큽니다(9950400). 기본적으로 다음을 수행할 수 있습니다. 이것이 "맛있는" SQL이라고 판단하십시오. - SQL 문제 해결
- 데이터베이스마다 이를 얻는 방법이 다릅니다. 다음은 현재 주류 데이터베이스를 위한 느린 쿼리 SQL 획득 도구입니다.
- MySQL
- 느린 쿼리 로그
- 테스트 도구 loadrunner
- Percona 회사의 ptquery 및 기타 도구
OracleAWR 보고서
테스트 도구 loadrunner 등
v$sql, v$session_wait 등과 같은 관련 내부 뷰
GRID Control 모니터링 도구Dameng 데이터베이스
AWR 보고서
Dameng 성능 모니터링 도구(dem)v$sql, v$session_wait 등 관련 내부 뷰테스트 도구 로드러너 등
SQL 작성 능력
있습니다. SQL 작성을 위한 몇 가지 일반적인 기술은 다음과 같습니다.
• 인덱스의 합리적인 사용
인덱스 수가 너무 적으면 쿼리 속도가 느려지고 인덱스가 너무 많아 공간을 많이 차지하며 추가를 실행할 때 인덱스를 동적으로 유지 관리해야 합니다. , 삭제 및 수정이 성능에 영향을 미칩니다.
선택률이 높고(중복 값이 적음) 트리 인덱스 일반 조인 열을 색인화해야 하는 위치와 B가 자주 참조됩니다. 복잡한 문서 유형 쿼리가 더 많습니다. 전체 텍스트 인덱스를 사용하면 효율적입니다. 인덱스 설정은 쿼리와 DML 성능 간의 균형을 유지해야 합니다. 복합 인덱스를 생성할 때 선행 열이 아닌 쿼리에 주의하세요
• UNION
UNION 대신 UNION ALL을 사용하세요. ALL은 UNION보다 실행 효율성이 높습니다. UNION은 실행 시 중복 제거가 필요합니다. UNION은 데이터 정렬이 필요합니다. 쿼리는 테이블로 반환되어야 하며 포함 인덱스는 사용할 수 없습니다.• JOIN 필드는 인덱싱하는 것이 좋습니다.
일반적으로 JOIN 필드는 미리 인덱싱됩니다.
• 복잡한 SQL 문 방지
| Field | Explanation |
|---|---|
| id | 각각의 독립적으로 실행되는 작업 식별은 id 값이 클수록 먼저 실행되는 개체를 식별합니다. 실행 순서는 위에서 아래로 아래 |
| select_type | 쿼리의 각 select 절 유형 |
| table | 작업 중인 개체의 이름, 일반적으로 테이블 이름이지만 다른 이름도 있습니다. format |
| partitions | 일치하는 파티션 정보(파티셔닝되지 않은 테이블의 경우 값은 NULL) |
| type | 조인 작업 유형 |
| possible_keys | 사용 가능한 인덱스 |
| 키 | 옵티마이저가 실제로 사용하는 인덱스(가장 중요한 열 ) 연결 유형 중 가장 좋은 것부터 나쁜 것까지 const, eq_reg, ref, 범위, 색인 및 모두. ALL가 나타나면 현재 SQL에 "악취"가 있다는 의미 const、eq_reg、ref、range、index和ALL。当出现ALL时表示当前SQL出现了“坏味道” |
| key_len | 被优化器选定的索引键长度,单位是字节 |
| ref | 表示本行被操作对象的参照对象,无参照对象为NULL |
| rows | 查询执行所扫描的元组个数(对于innodb,此值为估计值) |
| filtered | 条件表上数据被过滤的元组个数百分比 |
| extra | 执行计划的重要补充信息,当此列出现Using MySQL 데이터베이스 SQL 문 최적화sort , Using temporary 字样时就要小心了,很可能SQL语句需要优化 |
接下来我们用一段实际优化案例来说明SQL优化的过程及优化技巧。
优化案例
表结构
CREATE TABLE `a` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_id` bigint(20) DEFAULT NULL, `seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `b` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_name` varchar(100) DEFAULT NULL, `user_id` varchar(50) DEFAULT NULL, `user_name` varchar(100) DEFAULT NULL, `sales` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `c` ( `id` int(11) NOT NULLAUTO_INCREMENT, `user_id` varchar(50) DEFAULT NULL, `order_id` varchar(100) DEFAULT NULL, `state` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) );
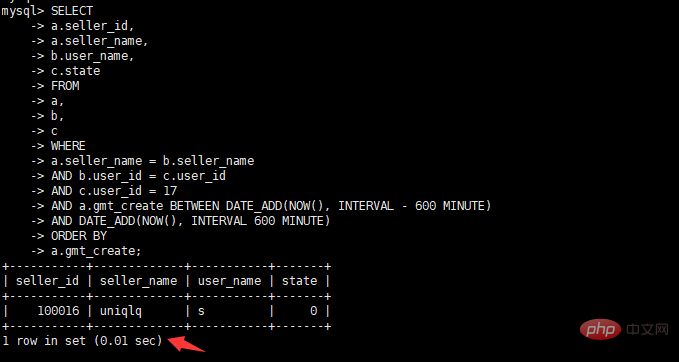
로그인 후 복사三张表关联,查询当前用户在当前时间前后10个小时的订单情况,并根据订单创建时间升序排列,具体SQL如下
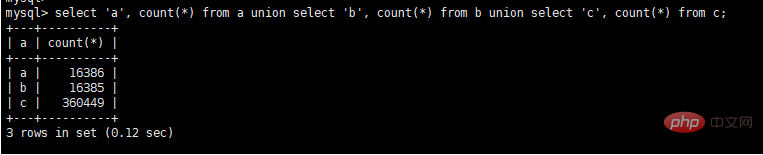
select a.seller_id, a.seller_name, b.user_name, c.state from a, b, c where a.seller_name = b.seller_name and b.user_id = c.user_id and c.user_id = 17 and a.gmt_create BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE) AND DATE_ADD(NOW(), INTERVAL 600 MINUTE) order by a.gmt_create
로그인 후 복사查看数据量
原执行时间
原执行计划
初步优化思路
SQL中 where条件字段类型要跟表结构一致,表中
user_id为varchar(50)类型,实际SQL用的int类型,存在隐式转换,也未添加索引。将b和c表user_id字段改成int类型。因存在b表和c表关联,将b和c表
user_id创建索引因存在a表和b表关联,将a和b表
seller_name- key_len옵티마이저가 선택한 인덱스 키의 길이, 단위는 바이트
ref 는 이것을 연산 중인 행의 참조 객체입니다. 비참조 객체는 NULLrows
쿼리 실행으로 스캔된 튜플 수(innodb의 경우 이 값은 추정치입니다)
- filtered조건 테이블의 데이터 필터링된 튜플의 비율extra
실행 계획의 중요한 보충 정보입니다.
Using MySQL 데이터베이스 SQL 문 최적화sort,Using temporary라는 단어를 사용할 때는 주의하세요. code>가 이 열에 나타납니다. 예, SQL 문을 최적화해야 할 가능성이 매우 높습니다 다음으로 실제 최적화 사례를 사용하여 SQL 최적화 프로세스와 최적화 기술을 설명합니다. - 최적화 사례
- 테이블 구조
alter table b modify `user_id` int(10) DEFAULT NULL; alter table c modify `user_id` int(10) DEFAULT NULL; alter table c add index `idx_user_id`(`user_id`); alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`); alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);
로그인 후 복사
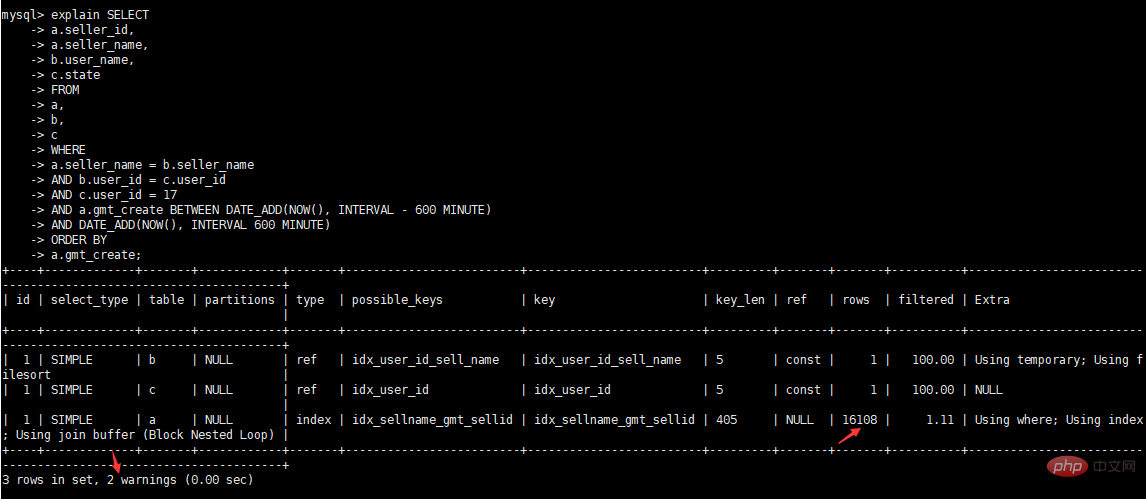
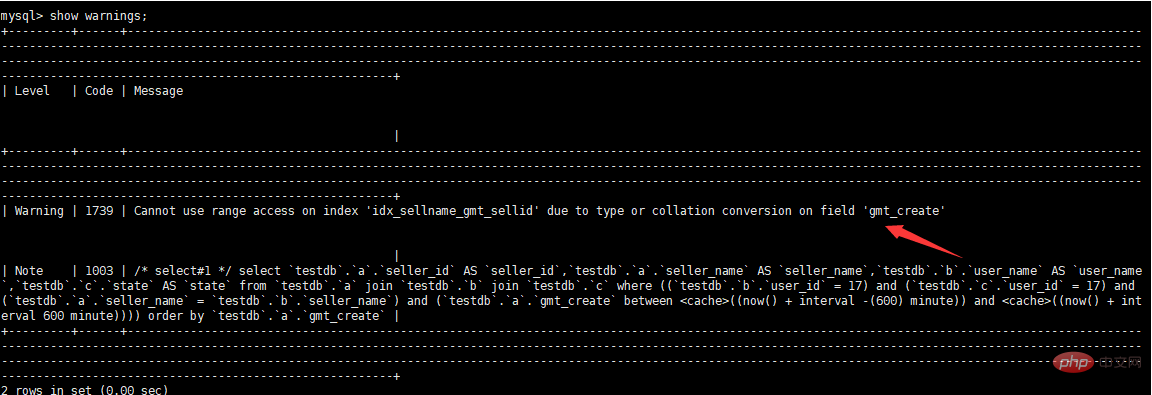 다음으로 실제 최적화 사례를 사용하여 SQL 최적화 프로세스와 최적화 기술을 설명합니다.
다음으로 실제 최적화 사례를 사용하여 SQL 최적화 프로세스와 최적화 기술을 설명합니다. 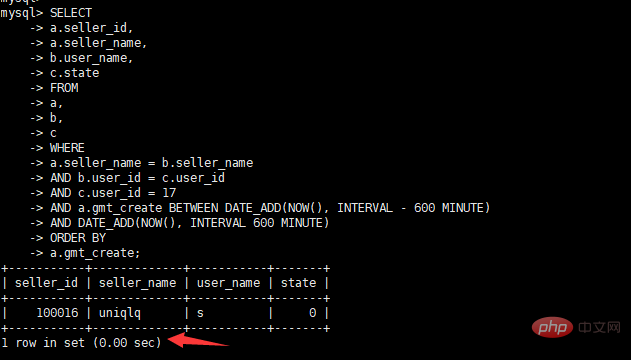
alter table a modify "gmt_create" datetime DEFAULT NULL
데이터량 보기
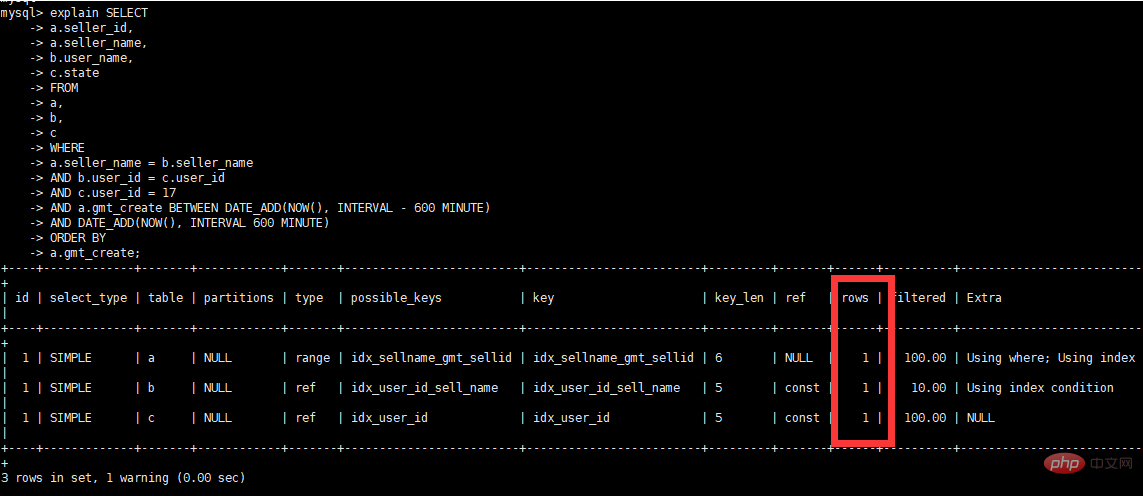
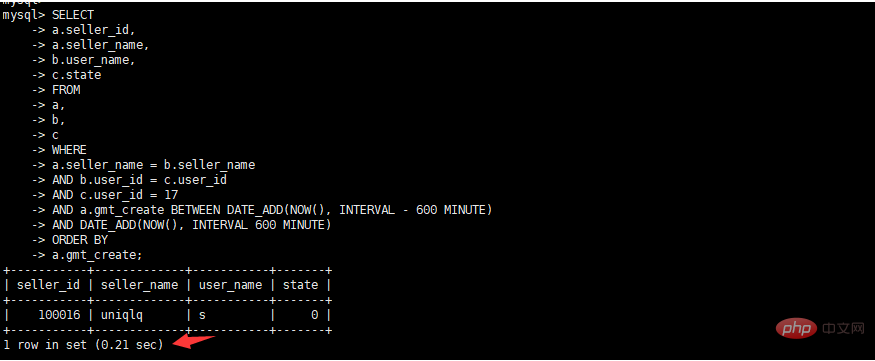
- 원래 실행 계획
- 초기 최적화 아이디어
- SQL의 where 조건 필드 유형은 테이블 구조와 일치해야 합니다. 테이블의
user_id는 varchar(50) 유형입니다. SQL에 사용되는 실제 int 유형에는 암시적 변환이 있으며 인덱스가 추가되지 않습니다. 테이블 b와 c의user_id필드를 int 유형으로 변경합니다.
user_id에 인덱스를 생성합니다. 테이블 a와 테이블 b가 연관되어 있으므로 테이블 a와 테이블 b >seller_name 필드 생성 인덱스🎜🎜🎜🎜복합 인덱스를 사용하여 임시 테이블 및 정렬 제거🎜🎜🎜🎜SQL의 초기 최적화🎜🎜🎜🎜rrreee🎜🎜🎜최적화 후 실행 시간 보기🎜🎜🎜🎜🎜🎜 🎜 최적화 계획 후 실행 보기🎜🎜🎜🎜🎜🎜🎜경고 정보 보기🎜🎜🎜🎜🎜🎜🎜계속 최적화🎜🎜🎜🎜rrreee🎜🎜🎜실행 시간 보기🎜🎜🎜🎜 🎜 🎜🎜🎜🎜실행 계획 보기🎜🎜 🎜🎜🎜🎜🎜 🎜최적화 요약🎜🎜🎜🎜실행 계획 보기 설명🎜🎜경고 정보가 있으면 알람 정보를 확인하여 경고 표시🎜🎜SQL에 관련된 테이블 구조 및 인덱스 정보 보기🎜🎜최적화 가능성 생각해보기 실행 계획에 따른 포인트🎜🎜가능한 최적화 시점에서 테이블 구조 변경, 인덱스 추가, SQL 재작성 등의 작업을 수행🎜🎜최적화된 실행 시간 및 실행 계획 보기🎜🎜🎜최적화 효과가 확실하지 않은 경우 네번째 단계🎜🎜"🎜mysql 동영상 튜토리얼🎜" 추천🎜
위 내용은 MySQL 데이터베이스 SQL 문 최적화의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7698
7698
 15
1640
14
1393
52
1287
25
1229
29
15
1640
14
1393
52
1287
25
1229
29

 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache는 데이터베이스에 연결하여 다음 단계가 필요합니다. 데이터베이스 드라이버 설치. 연결 풀을 만들려면 Web.xml 파일을 구성하십시오. JDBC 데이터 소스를 작성하고 연결 설정을 지정하십시오. JDBC API를 사용하여 Connections, 명세서 작성, 매개 변수 바인딩, 쿼리 또는 업데이트 실행 및 처리를 포함하여 Java 코드의 데이터베이스에 액세스하십시오.
 Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker의 MySQL을 시작하는 방법
Apr 15, 2025 pm 12:09 PM
Docker에서 MySQL을 시작하는 프로세스는 다음 단계로 구성됩니다. MySQL 이미지를 가져와 컨테이너를 작성하고 시작하고 루트 사용자 암호를 설정하고 포트 확인 연결을 매핑하고 데이터베이스를 작성하고 사용자는 데이터베이스에 모든 권한을 부여합니다.
 MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
MySQL의 역할 : 웹 응용 프로그램의 데이터베이스
Apr 17, 2025 am 12:23 AM
웹 응용 프로그램에서 MySQL의 주요 역할은 데이터를 저장하고 관리하는 것입니다. 1. MySQL은 사용자 정보, 제품 카탈로그, 트랜잭션 레코드 및 기타 데이터를 효율적으로 처리합니다. 2. SQL 쿼리를 통해 개발자는 데이터베이스에서 정보를 추출하여 동적 컨텐츠를 생성 할 수 있습니다. 3.mysql은 클라이언트-서버 모델을 기반으로 작동하여 허용 가능한 쿼리 속도를 보장합니다.
 Centos 설치 MySQL
Apr 14, 2025 pm 08:09 PM
Centos 설치 MySQL
Apr 14, 2025 pm 08:09 PM
Centos에 MySQL을 설치하려면 다음 단계가 필요합니다. 적절한 MySQL Yum 소스 추가. mysql 서버를 설치하려면 yum install mysql-server 명령을 실행하십시오. mysql_secure_installation 명령을 사용하여 루트 사용자 비밀번호 설정과 같은 보안 설정을 작성하십시오. 필요에 따라 MySQL 구성 파일을 사용자 정의하십시오. MySQL 매개 변수를 조정하고 성능을 위해 데이터베이스를 최적화하십시오.
