

Redis의 5가지 주요 데이터 유형과 애플리케이션 시나리오를 이해하는 기사 1개

1. 문자열형
데이터 추가/수정: 키 값 설정set key value
获取数据:get key
删除数据:del key
키 가져오기🎜🎜🎜🎜데이터 삭제 style="box-sizing: border-box; 글꼴-가족: "Source Code Pro", "DejaVu Sans Mono", "Ubuntu Mono", "Anonymous Pro", "Droid Sans Mono", Menlo, Monaco, Consolas, Inconsolata , Courier, 고정 폭, "PingFang SC", "Microsoft YaHei", 글꼴 크기: 14px; 배경색: rgb(249, 242, 244); 테두리 반경: 2px 4px; -높이: 22px; 색상: rgb(199, 37, 78);">del 키🎜🎜여러 데이터 추가/수정: mset 키 값 key1 value1mset key value key1 value1
获取多个数据:mget key key1
追加信息到原始数据后边(不存在时则添加):append key value
지정된 범위에서 값을 늘리도록 값을 설정합니다: incrby 키 값은 매번 값을 추가합니다 <br style="box-sizing: border-box;">지정된 범위를 줄이도록 데이터 설정:<code style="box-sizing: border-box;font-family: " source code pro sans mono menlo monaco consolas inconsolata courier monospace sc yahei sans-serif rgb decrby><code style="box-sizing: border-box; font-family: " source code pro sans mono menlo monaco consolas inconsolata courier monospace sc yahei sans-serif font-size: background-color: rgb border-radius: padding: line-height: color:>incr key 默认每次加1 | incrby key value 每次新增value
设置数据减少指定范围:decr key | decrby key value 跟新增是一回事
应用场景
控制数据库表主键id,为数据库表提供主键生成策略,保证数据表主键的一致性。
设置过期时间:setex key seconds value
1-3 문자열 유형 에이징 작업
🎜 🎜🎜만료 시간 설정:setex 키 초 값🎜🎜응용 시나리오
시간 제한 투표 기능 실현: 예를 들어 WeChat 계정은 한 시간에 한 번 투표할 수 있습니다.
핫 정보 실현: 전자상거래 업계의 인기 제품, 뉴스 웹사이트의 인기 뉴스
Weibo big V 홈페이지는 자주 방문하며 팬 수, 팔로워 수, Weibo 번호는 수시로 업데이트되어야 합니다. 이는 빈도가 높은 정보인데, redis의 문자열 형태를 이용하면 해결할 수 있습니다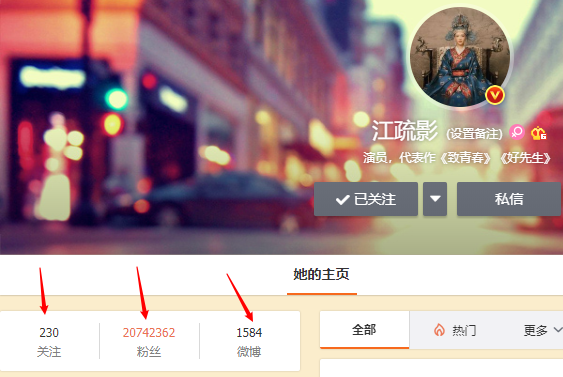
Redis에서 Big V에 대한 사용자 정보를 설정하고, 사용자의 기본 키와 속성을 키 값으로 사용하여 구현한 사례입니다. 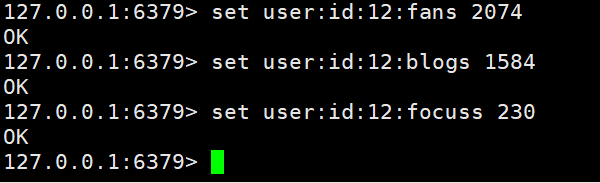
여기서는 키의 명명 규칙(테이블 이름 + 기본 키 + 기본 키 값 + 필드: 필드 값)에 대해 간략하게 설명해야 합니다. 이러한 규칙에 따라 이름을 지정하면 우리의 핵심 가치를 매우 잘 관리할 수 있습니다.
다른 방법을 사용하여 구현할 수도 있습니다. 예를 들어 구조를 사용하여 키를 직접 따르는 것입니다. 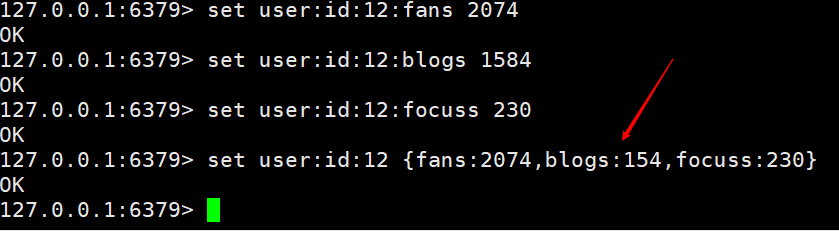
위의 두 가지 방법을 구현할 수 있지만 첫 번째 방법은 모든 값에 대해 매우 편리할 수 있습니다. 두 번째 방법은 비즈니스 시나리오에 따라 모든 것을 한 번만 변경하는 것입니다.
데이터 추가/수정: hset 키 필드 값hset key field value
获取数据:hget key field | hgetall key
删除数据:hdel key field field1
hget 키 필드 | 상자 크기: 테두리 상자; 글꼴 계열: "소스 코드 Pro", "DejaVu Sans Mono", "Ubuntu Mono", "Anonymous Pro", "Droid Sans Mono", Menlo, Monaco, Consolas, Inconsolata, Courier, 고정 폭, "PingFang SC", "Microsoft YaHei", 글꼴 크기: 14px, 테두리 반경: 2px, 줄 높이: 22px; 색상: rgb(199, 37, 78);">hgetall 키🎜🎜🎜🎜 데이터 삭제: 🎜🎜<div class="cl-preview-section" style="box-sizing: border-box; color: rgba(0, 0, 0, 0.75); font-family: -apple-system, " sf ui text arial sc sans gb yahei micro hei sans-serif font-size: font-variant-ligatures: common-ligatures white-space: normal background-color: rgb><p style="box-sizing: border-box; margin-top: 0px; margin-bottom: 16px; color: rgb(77, 77, 77); line-height: 26px;">여러 데이터 추가/수정: <code style="box-sizing: border-box; 글꼴-가족: " source code pro sans mono menlo monaco consolas inconsolata courier monospace sc yahei sans-serif rgb radius: padding: line-height: color:>hmset 키 필드 값 field1 value1hmset key field value field1 value1获取多个数据:hmget key field field1
获取表中字段数量:hlen key
获取表中是否存在某个字段:hexists key field
🎜🎜🎜🎜🎜🎜2-2 해시 유형 데이터에 대한 확장 작업🎜🎜<div class="cl-preview-section" style="box-sizing: border-box; color: rgba(0, 0, 0, 0.75); font-family: -apple-system, " sf ui text arial sc sans gb yahei micro hei sans-serif font-size: font-variant-ligatures: common-ligatures white-space: normal background-color: rgb><p style="box-sizing: border-box; margin-top: 0px; margin-bottom: 16px; color: rgb(77, 77, 77); line-height: 26px;">해시 테이블의 모든 필드 값 가져오기: <code style="box-sizing: border-box;font-family: " source code pro sans mono menlo monaco consolas inconsolata courier sc yahei sans-serif rgb border-radius: line-height: color:>hkeys 키hkeys key获取hash表中所有的字段值:hvals key
设置指定字段的数值增加指定范围的值:hincrby key field increment | hincrbyfloat key field increment
이 사진은 인터넷에서 직접 찍은 것이 아니라 장바구니 장면을 시뮬레이션한 것입니다.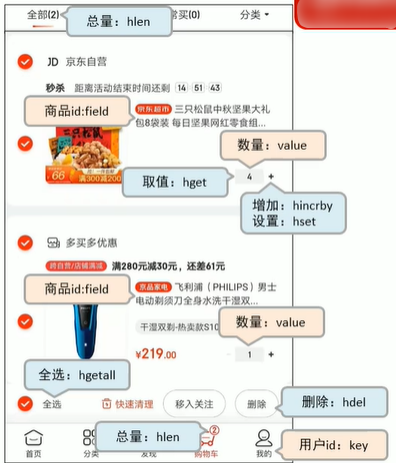
위 그림에서 장바구니에 담긴 정보를 볼 수 있습니다. 다음으로 Redis를 사용하여 장바구니를 구현합니다.
여기에서는 장바구니 추가 및 장바구니 가져오기를 구현합니다. 키 이름은 테이블 이름 + 기본 키 + 기본 키 값입니다. 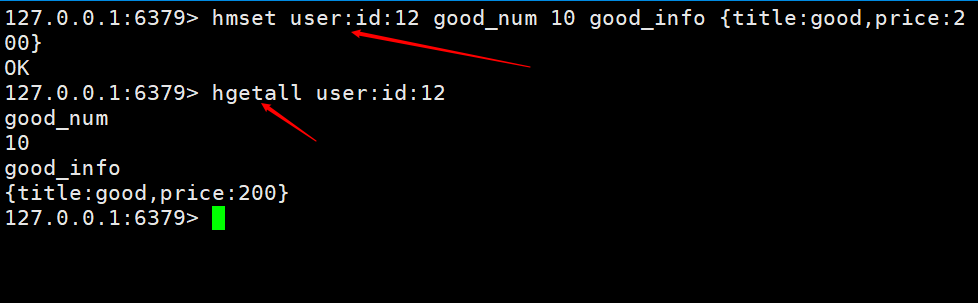
위 그림에서는 제품 정보 저장이 문제가 됩니다. 많이 반복하면 모든 제품을 개별적으로 해시해야 합니다. 아래 사진처럼 상품ID만 저장됩니다
설정 방법은 2가지가 있는데, 하나는 여러 필드를 설정하는 것이고, 또 하나는 json으로 직접 저장하는 것입니다. 정보가 자주 변경되지 않으면 json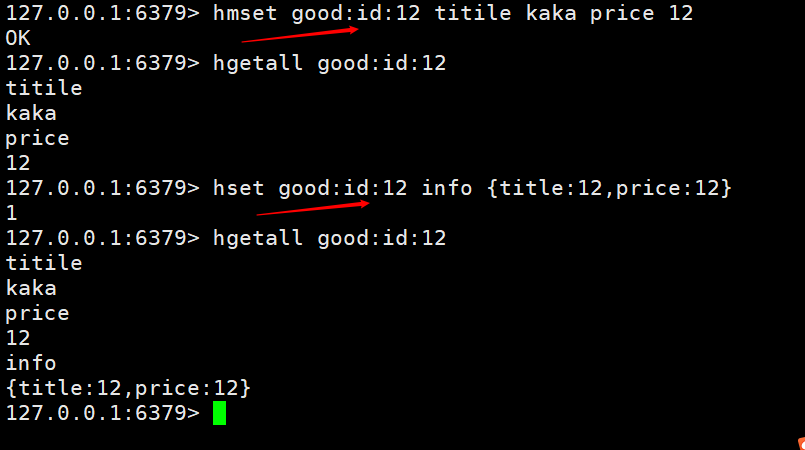
을 사용하여 메소드hsetnx key field value를 제공할 수 있습니다. 존재하면 추가되지 않고, 없으면 추가됩니다. 이 기능은 다른 사용자가 동일한 제품을 추가할 때 덮어쓰기 및 불필요한 작업을 방지하는 데 사용됩니다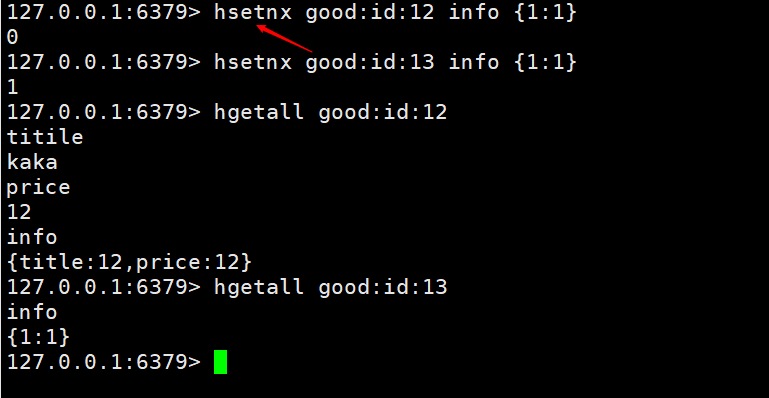
3.데이터 저장 요구 사항: 여러 데이터를 저장하고, 데이터 저장 공간의 순서를 구분합니다.
필수 데이터 구조: 하나의 저장 공간에 여러 데이터를 저장하며, 입력 순서는 데이터를 통해 반영될 수 있습니다.
목록 유형: 여러 데이터 저장, 하위 계층은 이중 연결 목록 저장 구조를 사용하여
데이터 추가/수정: lpush key value value1 | rpush key value value1
获取数据:범위 키 시작 끝 | lindex 키 인덱스 | llen 키lrange key start end | lindex key index | llen key
删除数据:rpop key | lpop key
删除数据:rpop 키 | lpop 키
🎜3-2 목록지정된 시간 내에 데이터 가져오기 및 삭제: blpop key1 key2 timeout | brpop key1 key2 timeout
이 기능은 케이스 작성이 간단하고 이해하기 쉽습니다.
왼쪽 터미널 명령이 실행된 후 30초 동안 대기하여 반환됩니다. 삭제된 데이터
오른쪽의 add 명령을 실행하면 왼쪽에서 삭제된 데이터가 바로 반환됩니다
위에서 우리는 목록의 기본 동작은 lpop 키나 rpop 키를 실행할 수 있으며 do 또는 오른쪽에서 삭제가 가능하지만 Redis의 5가지 주요 데이터 유형과 애플리케이션 시나리오를 이해하는 기사 1개은 친구의 서클을 사용하고 중간부터 데이터가 삭제되는 경우가 있습니다. 케이스는 아래와 같습니다
먼저 list5에 a b c d
를 추가한 다음 c를 제거합니다
보고 나면 a b d만 남습니다
새로운 저장 요구 사항: 쿼리 중에 많은 양의 데이터를 저장합니다. 더 높은 효율성을 편리하게 제공
필요한 저장 구조: 대용량 데이터 저장 가능, 효율적인 내부 저장 메커니즘, 쿼리 용이
설정 유형: 해시 저장 구조와 정확히 동일, 값(nil)이 아닌 키만 저장하고, 값 중복은 허용되지 않습니다
데이터 추가/수정:sadd key member member1
获取数据:멤버 키smembers key
删除数据:srem key member1
获取集合数据总量:scard key
判断集合中是否包含指定数据:sismember key member
删除数据:srem 키 멤버1
获取集합数据总weight:스카드 키🎜🎜🎜🎜判断集合中是否包含指정数据:sismember 핵심 멤버🎜🎜🎜🎜🎜🎜🎜
세트에서 지정된 양의 데이터를 무작위로 획득: srandmember 키 수 code><code style="box-sizing: border-box; font-family: " source code pro sans mono menlo monaco consolas inconsolata courier monospace sc yahei sans-serif font-size: background-color: rgb border-radius: padding: line-height: color:>srandmember key count
随机获取集合中某个数据并将改数据集移除集合:spop key
컬렉션에서 특정 데이터를 무작위로 얻고 컬렉션에서 새 데이터 세트를 제거합니다. <h2 style="box-sizing: border-box; margin: 8px 0px 16px; line-height: 32px; color: rgb(79, 79, 79); font-size: 24px;"><a id="43_set_137" style="box-sizing: border-box; background-color: transparent; color: rgb(78, 161, 219);"> </a></h2>
4-3세트형 비즈니스 시나리오 추천정보
핫정보, 핫뉴스, 핫셀 여행, 어플앱추천, 추천팔로우 등 랜덤푸시
🎜카카가 최근에 discuz를 쓰고 있어서 이번 사건은 주목추천을 받기 위해서입니다. 🎜🎜Case 1: 특정 추천 메커니즘에 따라 해당 사용자를 세트에 저장하고, 매번 추천이 필요한 사용자 2명을 무작위로 획득
Case 2: 해당 사용자를 세트에 저장 특정 추천 메커니즘에 따라 설정 해당 사용자를 저장하면 날짜를 기준으로 매일 추천된 사용자는 반복될 수 없습니다
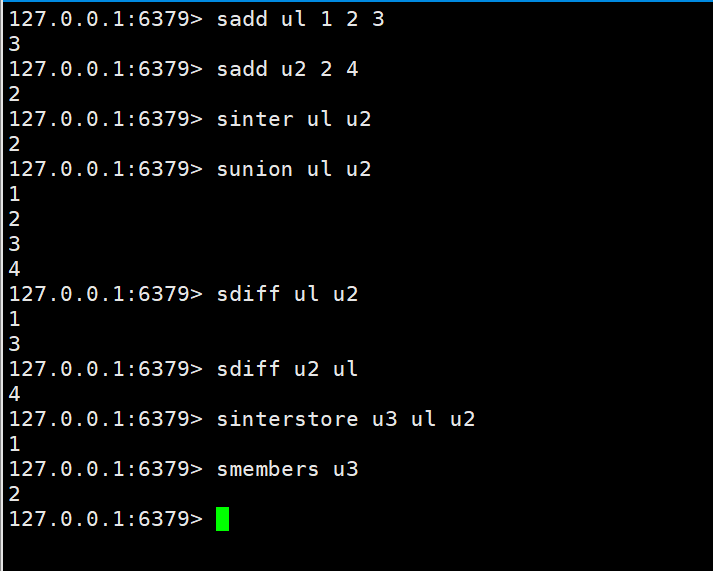
두 집합의 교집합, 합집합, 차이
sinter key key1
sunion key key1
sdiff key key1
로그인 후 복사
두 집합의 교집합, 합집합, 차이가 지정된 집합에 저장됩니다
sinterstore destination key1 key2
sunionstore destination key1 key2
sdiffstore destination key1 key2
로그인 후 복사
案例:我们需要挖掘一个信息的共同好友。例如微信公众号的共同关注好友数量、QQ添加新好友的推荐机制、深度挖掘用户直接的联系
就根据上述案例,我们可以使用差集来实现qq的有可能认识的好友。
PV直接使用string类型的incr统计即可
UV和IP都是独立不重复的,使用set来操作。
在上边我们知道set有一个特性就是不能重复,我们就可以根据这一点来轻松实现这个功能。然后使用scard key 来统计数量。
UV가 독립적인 방문자인 경우 로컬 쿠키를 사용하여 동일한 방법으로 기록을 위해 쿠키를 redis에 전달할 수 있습니다
이 그 중 하나입니다. 이전 4가지 유형 중 정렬을 지원하지 않습니다. 아래에서 살펴볼 sorted_set 유형은 빅 데이터 저장과 정렬 기능을 모두 지원합니다
code style=" box-sizing: border-box; 글꼴 계열: "Source Code Pro", "DejaVu Sans Mono", "Ubuntu Mono", "Anonymous Pro", "Droid Sans Mono", Menlo, Monaco, Consolas, Inconsolata, Courier, 고정폭, "PingFang SC", "Microsoft YaHei", 글꼴 크기: 14px; 배경색: rgb(249, 242, 244); 테두리 반경: 2px 4px; line-height: 22px; color: rgb(199, 37, 78);">zadd 주요 점수 멤버zadd key score member
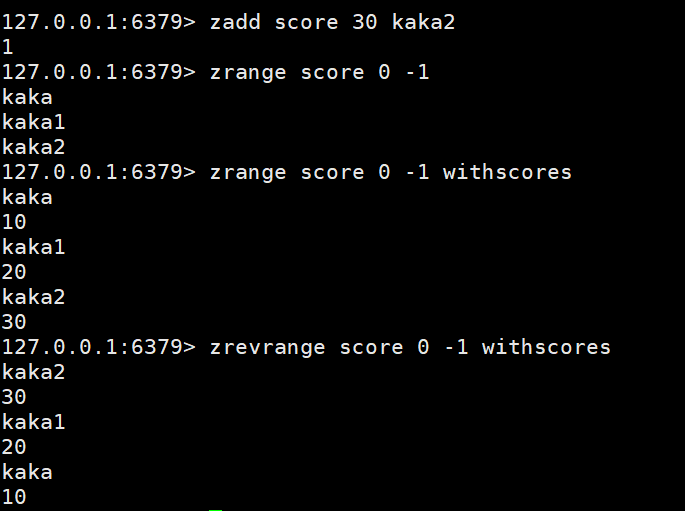
获取数据:zrange key start stop | zrevrange key start stop
🎜데이터 가져오기: zrange 키 시작 중지 | zrevrange 키 시작 중지🎜🎜删除数据:zrem 핵심 멤버zrem key member
按条件获取数据:zrangebyscore key min max limit | zrevrangescore key max min
条件删除数据:zremrangebyrank key start stop | zremrangebyscore key min max
获取集合数据总量:zcard key | zcount key min max
🎜
按条件获取数据:zrangebyscore 키 최소 최대 제한 | zrevrangescore 키 최대 최소값🎜🎜🎜🎜条件删除数据:zremrangebyrank 키 시작 중지 | zremrangebyscore 키 최소 최대🎜🎜🎜🎜获取集合数据总weight:zcard 키 | zcount 키 최소 최대🎜🎜수집 및 운영: zinterstore 대상 numkeys 키 | zunionstore 대상 numkeys 키(이 명령은 설명되지 않습니다. 확인할 수 있습니다. 모든 교차점의 합을 합산한다는 점만 제외하면 numkeys라는 매개변수가 있다는 점만 빼면 설정과 유사합니다. 다음 키를 계산하려면 몇 개의 키가 필요한가요?)zinterstore destination numkeys key | zunionstore destination numkeys key(这个指令就不做演示了,可以自己查看文档。跟set有点类似,只不过会把所有交集的和给加起来。然后这里边有个numkeys这个参数是一共几个key进行计算 后边的key就需要几个)
获取数据对应的索引:zrank key member | zrevrank key member
socre值获取与修改:zscore key member | zincrby key increment member
🎜Summary🎜🎜🎜🎜위는 Redis 데이터 유형에 대한 간략한 소개와 구체적인 적용입니다. 이는 다음 문서의 특정 요구 사항에 따라 구현됩니다. 🎜🎜
데이터 저장 요구 사항: 여러 데이터를 저장하고, 데이터 저장 공간의 순서를 구분합니다.
필수 데이터 구조: 하나의 저장 공간에 여러 데이터를 저장하며, 입력 순서는 데이터를 통해 반영될 수 있습니다.
목록 유형: 여러 데이터 저장, 하위 계층은 이중 연결 목록 저장 구조를 사용하여
데이터 추가/수정: lpush key value value1 | rpush key value value1
获取数据:범위 키 시작 끝 | lindex 키 인덱스 | llen 키lrange key start end | lindex key index | llen key
删除数据:rpop key | lpop key
rpop 키 | lpop 키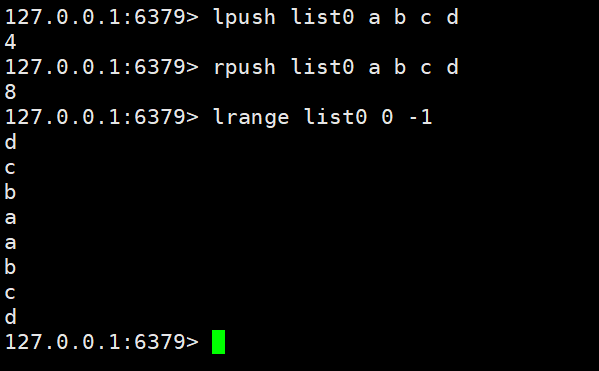
지정된 시간 내에 데이터 가져오기 및 삭제: blpop key1 key2 timeout | brpop key1 key2 timeout
이 기능은 케이스 작성이 간단하고 이해하기 쉽습니다.
왼쪽 터미널 명령이 실행된 후 30초 동안 대기하여 반환됩니다. 삭제된 데이터
오른쪽의 add 명령을 실행하면 왼쪽에서 삭제된 데이터가 바로 반환됩니다
위에서 우리는 목록의 기본 동작은 lpop 키나 rpop 키를 실행할 수 있으며 do 또는 오른쪽에서 삭제가 가능하지만 Redis의 5가지 주요 데이터 유형과 애플리케이션 시나리오를 이해하는 기사 1개은 친구의 서클을 사용하고 중간부터 데이터가 삭제되는 경우가 있습니다. 케이스는 아래와 같습니다
먼저 list5에 a b c d
를 추가한 다음 c를 제거합니다
보고 나면 a b d만 남습니다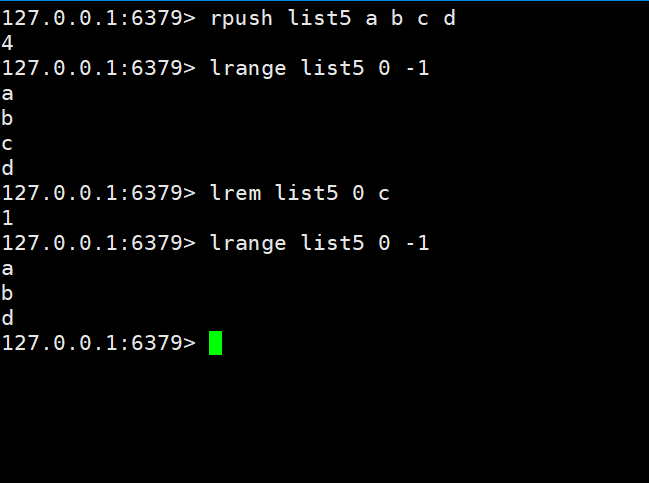
새로운 저장 요구 사항: 쿼리 중에 많은 양의 데이터를 저장합니다. 더 높은 효율성을 편리하게 제공
필요한 저장 구조: 대용량 데이터 저장 가능, 효율적인 내부 저장 메커니즘, 쿼리 용이
설정 유형: 해시 저장 구조와 정확히 동일, 값(nil)이 아닌 키만 저장하고, 값 중복은 허용되지 않습니다
데이터 추가/수정:sadd key member member1
获取数据:멤버 키smembers key
删除数据:srem key member1
获取集合数据总量:scard key
判断集合中是否包含指定数据:sismember key member
srem 키 멤버1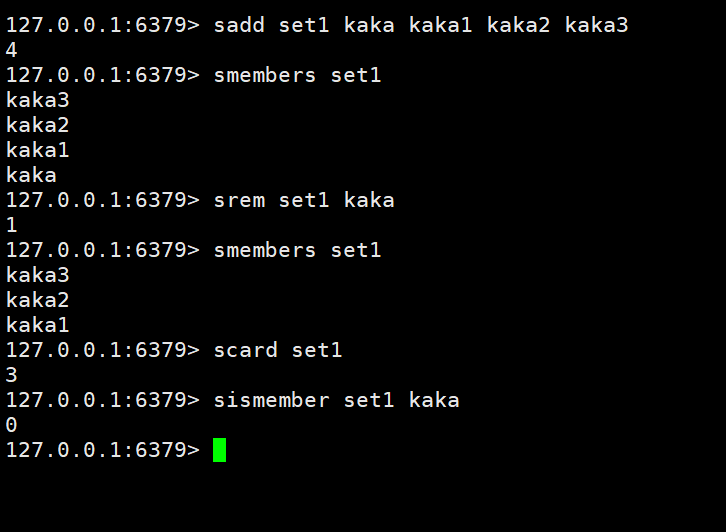
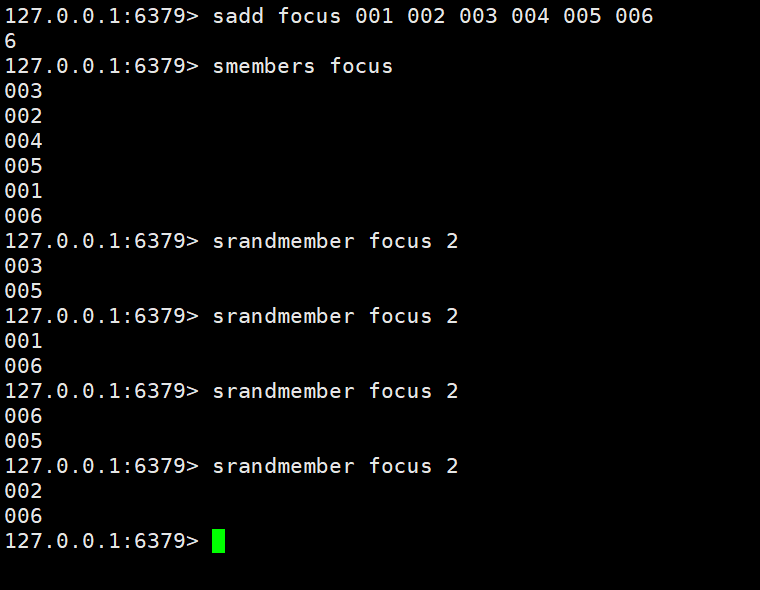
세트에서 지정된 양의 데이터를 무작위로 획득: srandmember 키 수 code><code style="box-sizing: border-box; font-family: " source code pro sans mono menlo monaco consolas inconsolata courier monospace sc yahei sans-serif font-size: background-color: rgb border-radius: padding: line-height: color:>srandmember key count
随机获取集合中某个数据并将改数据集移除集合:spop key
<h2 style="box-sizing: border-box; margin: 8px 0px 16px; line-height: 32px; color: rgb(79, 79, 79); font-size: 24px;"><a id="43_set_137" style="box-sizing: border-box; background-color: transparent; color: rgb(78, 161, 219);"> </a></h2>
Case 1: 특정 추천 메커니즘에 따라 해당 사용자를 세트에 저장하고, 매번 추천이 필요한 사용자 2명을 무작위로 획득
Case 2: 해당 사용자를 세트에 저장 특정 추천 메커니즘에 따라 설정 해당 사용자를 저장하면 날짜를 기준으로 매일 추천된 사용자는 반복될 수 없습니다

두 집합의 교집합, 합집합, 차이
sinter key key1 sunion key key1 sdiff key key1
두 집합의 교집합, 합집합, 차이가 지정된 집합에 저장됩니다
sinterstore destination key1 key2 sunionstore destination key1 key2 sdiffstore destination key1 key2
案例:我们需要挖掘一个信息的共同好友。例如微信公众号的共同关注好友数量、QQ添加新好友的推荐机制、深度挖掘用户直接的联系
就根据上述案例,我们可以使用差集来实现qq的有可能认识的好友。
PV直接使用string类型的incr统计即可
UV和IP都是独立不重复的,使用set来操作。
在上边我们知道set有一个特性就是不能重复,我们就可以根据这一点来轻松实现这个功能。然后使用scard key 来统计数量。
UV가 독립적인 방문자인 경우 로컬 쿠키를 사용하여 동일한 방법으로 기록을 위해 쿠키를 redis에 전달할 수 있습니다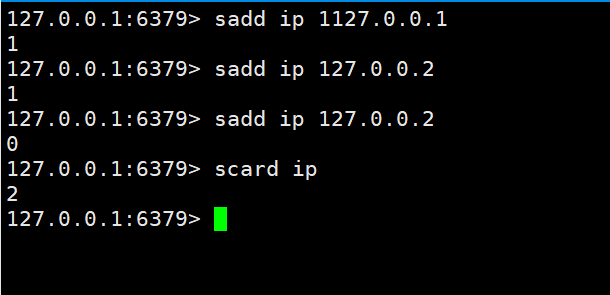
이 그 중 하나입니다. 이전 4가지 유형 중 정렬을 지원하지 않습니다. 아래에서 살펴볼 sorted_set 유형은 빅 데이터 저장과 정렬 기능을 모두 지원합니다
code style=" box-sizing: border-box; 글꼴 계열: "Source Code Pro", "DejaVu Sans Mono", "Ubuntu Mono", "Anonymous Pro", "Droid Sans Mono", Menlo, Monaco, Consolas, Inconsolata, Courier, 고정폭, "PingFang SC", "Microsoft YaHei", 글꼴 크기: 14px; 배경색: rgb(249, 242, 244); 테두리 반경: 2px 4px; line-height: 22px; color: rgb(199, 37, 78);">zadd 주요 점수 멤버zadd key score member
获取数据:zrange key start stop | zrevrange key start stop
删除数据:zrem 핵심 멤버zrem key member
按条件获取数据:zrangebyscore key min max limit | zrevrangescore key max min
条件删除数据:zremrangebyrank key start stop | zremrangebyscore key min max
获取集合数据总量:zcard key | zcount key min max
수집 및 운영: zinterstore 대상 numkeys 키 | zunionstore 대상 numkeys 키(이 명령은 설명되지 않습니다. 확인할 수 있습니다. 모든 교차점의 합을 합산한다는 점만 제외하면 numkeys라는 매개변수가 있다는 점만 빼면 설정과 유사합니다. 다음 키를 계산하려면 몇 개의 키가 필요한가요?)zinterstore destination numkeys key | zunionstore destination numkeys key(这个指令就不做演示了,可以自己查看文档。跟set有点类似,只不过会把所有交集的和给加起来。然后这里边有个numkeys这个参数是一共几个key进行计算 后边的key就需要几个)
获取数据对应的索引:zrank key member | zrevrank key member
socre值获取与修改:zscore key member | zincrby key increment member
위 내용은 Redis의 5가지 주요 데이터 유형과 애플리케이션 시나리오를 이해하는 기사 1개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7450
7450
 15
1374
52
77
11
40
19
14
8
15
1374
52
77
11
40
19
14
8

 Redis 메모리 사용이 너무 높으면 어떻게해야합니까?
Apr 10, 2025 pm 02:21 PM
Redis 메모리 사용이 너무 높으면 어떻게해야합니까?
Apr 10, 2025 pm 02:21 PM
Redis 메모리 급등에는 너무 큰 데이터 볼륨, 부적절한 데이터 구조 선택, 구성 문제 (예 : MaxMemory 설정이 너무 작은) 및 메모리 누출이 포함됩니다. 솔루션에는 만료 된 데이터 삭제, 압축 기술 사용, 적절한 구조 선택, 구성 매개 변수 조정, 코드의 메모리 누출 확인 및 메모리 사용을 정기적으로 모니터링합니다.
 Redis 메모리 조각화를 처리하는 방법?
Apr 10, 2025 pm 02:24 PM
Redis 메모리 조각화를 처리하는 방법?
Apr 10, 2025 pm 02:24 PM
Redis 메모리 조각화는 할당 된 메모리에 재 할당 할 수없는 작은 자유 영역의 존재를 말합니다. 대처 전략에는 다음이 포함됩니다. REDIS를 다시 시작하십시오 : 메모리를 완전히 지우지 만 인터럽트 서비스. 데이터 구조 최적화 : Redis에 더 적합한 구조를 사용하여 메모리 할당 및 릴리스 수를 줄입니다. 구성 매개 변수 조정 : 정책을 사용하여 최근에 가장 적게 사용 된 키 값 쌍을 제거하십시오. 지속 메커니즘 사용 : 데이터를 정기적으로 백업하고 Redis를 다시 시작하여 조각을 정리하십시오. 메모리 사용 모니터링 : 적시에 문제를 발견하고 조치를 취하십시오.
 Redis는 지정된 구성 파일을 사용하여 다시 시작합니다
Apr 10, 2025 pm 02:42 PM
Redis는 지정된 구성 파일을 사용하여 다시 시작합니다
Apr 10, 2025 pm 02:42 PM
구성 파일을 지정하여 Redis를 다시 시작하십시오. 1. 구성 파일을 찾으십시오 (일반적으로 Conf 서브 디렉토리에있는 redis.conf); 2. 필요한 구성을 수정합니다 (예 : 포트 변경); 3. Redis-server/path/to/redis.conf 명령을 사용하여 구성 파일을 통해 redis를 다시 시작하십시오 (여기서 /path/to/redis.conf는 수정 된 구성 파일의 경로); 4. Redis-Cli를 사용하여 성공적으로 다시 시작되었는지 확인하십시오.
 Redis 재시작 데이터가 여전히 있습니다
Apr 10, 2025 pm 02:45 PM
Redis 재시작 데이터가 여전히 있습니다
Apr 10, 2025 pm 02:45 PM
Redis가 다시 시작된 후에도 데이터가 여전히 존재합니다. Redis는 메모리에 데이터를 저장하고 다시 시작하면 메모리 데이터가 삭제되지 않습니다. Redis는 또한 RDB 또는 AOF 파일을 통해 하드 디스크에 데이터를 저장하는 지속성을 제공하여 다시 시작한 후 지속적인 파일에서 데이터를 복구 할 수 있도록합니다.
 메모리에 대한 Redis 지속성의 영향은 무엇입니까?
Apr 10, 2025 pm 02:15 PM
메모리에 대한 Redis 지속성의 영향은 무엇입니까?
Apr 10, 2025 pm 02:15 PM
Redis Persistence는 추가 메모리를 차지하고 RDB는 스냅 샷을 생성 할 때 메모리 사용량을 일시적으로 증가시키고 AOF는 로그를 추가 할 때 계속 메모리를 차지합니다. 영향 요인에는 데이터 볼륨, 지속성 정책 및 Redis 구성이 포함됩니다. 영향을 완화하려면 RDB 스냅 샷 정책을 합리적으로 구성하고 구성 최적화, 하드웨어 업그레이드 및 메모리 사용을 모니터링 할 수 있습니다. 또한 성능과 데이터 보안 사이의 균형을 찾는 것이 중요합니다.
 비즈니스 요구에 따라 Redis 메모리 크기를 설정하는 방법은 무엇입니까?
Apr 10, 2025 pm 02:18 PM
비즈니스 요구에 따라 Redis 메모리 크기를 설정하는 방법은 무엇입니까?
Apr 10, 2025 pm 02:18 PM
Redis 메모리 크기 설정은 다음 요소를 고려해야합니다. 데이터 볼륨 및 성장 추세 : 저장된 데이터의 크기 및 성장 속도를 추정하십시오. 데이터 유형 : 다른 유형 (예 : 목록, 해시)은 다른 메모리를 차지합니다. 캐싱 정책 : 전체 캐시, 부분 캐시 및 단계 정책은 메모리 사용에 영향을 미칩니다. 비즈니스 피크 : 트래픽 피크를 처리하기에 충분한 메모리를 남겨 두십시오.
 Redis Restart 서비스는 어디에 있습니까?
Apr 10, 2025 pm 02:36 PM
Redis Restart 서비스는 어디에 있습니까?
Apr 10, 2025 pm 02:36 PM
다른 운영 체제에서 REDIS 서비스를 다시 시작하는 방법 : Linux/MacOS : SystemCTL 명령 (SystemCTL REDIS-SERVER 재시작) 또는 서비스 명령 (Service Redis-Server Restart)을 사용하십시오. Windows : Services.msc 도구를 사용하고 (실행 대화 상자에서 "services.msc"를 입력하고 Enter를 누르십시오) "redis"서비스를 마우스 오른쪽 단추로 클릭하고 "다시 시작"을 선택하십시오.
 Redis Restart 명령은 무엇입니까?
Apr 10, 2025 pm 02:39 PM
Redis Restart 명령은 무엇입니까?
Apr 10, 2025 pm 02:39 PM
Redis Restart 명령은 Redis-Server입니다. 이 명령은 구성 파일을로드하고, 데이터 구조를 만들고, Redis 서버를 시작하고, 클라이언트 연결을 듣는 데 사용됩니다. 사용자는 터미널에서 "redis-server [옵션]"명령을 실행하여 Redis 서버를 다시 시작할 수 있습니다. 일반적인 옵션에는 배경 작동, 구성 파일 경로 지정, 청취 포트 지정 및 데이터 손실 된 경우에만 스냅 샷을 다시로드하는 것이 포함됩니다. 서버를 다시 시작하면 모든 클라이언트 연결을 분리하여 다시 시작하기 전에 필요한 데이터를 저장해야합니다.
