
1. 파이프라인 출현 배경:
Redis에는 명령 전송, 명령 대기열, 명령 실행, 결과 반환의 네 가지 프로세스가 있습니다.
이 프로세스를 왕복 시간(줄여서 RTT)이라고 합니다. ) ), mget mset는 RTT를 효과적으로 절약하지만 대부분의 명령(예: mhgetall은 제외)은 일괄 작업을 지원하지 않으며 N번의 RTT를 소비해야 합니다. 이때 이 문제를 해결하려면 파이프라인이 필요합니다.
2. 파이프라인 성능
1. 파이프라인을 사용하지 않고 N 명령 실행
2. 파이프라인으로 N 명령 실행
3. 둘 사이의 성능 비교
Pipeline을 사용하면 하나씩 실행하는 것보다 실행 속도가 빠릅니다. 특히 클라이언트와 서버 사이의 네트워크 지연이 클수록 성능이 더 확실해집니다.
둘 사이의 성능 차이를 분석하기 위해 테스트 코드가 아래에 게시되었습니다.
@Test
public void pipeCompare() {
Jedis redis = new Jedis("192.168.1.111", 6379);
redis.auth("12345678");//授权密码 对应redis.conf的requirepass密码
Map<String, String> data = new HashMap<String, String>();
redis.select(8);//使用第8个库
redis.flushDB();//清空第8个库所有数据
// hmset
long start = System.currentTimeMillis();
// 直接hmset
for (int i = 0; i < 10000; i++) {
data.clear(); //清空map
data.put("k_" + i, "v_" + i);
redis.hmset("key_" + i, data); //循环执行10000条数据插入redis
}
long end = System.currentTimeMillis();
System.out.println(" 共插入:[" + redis.dbSize() + "]条 .. ");
System.out.println("1,未使用PIPE批量设值耗时" + (end - start) / 1000 + "秒..");
redis.select(8);
redis.flushDB();
// 使用pipeline hmset
Pipeline pipe = redis.pipelined();
start = System.currentTimeMillis();
//
for (int i = 0; i < 10000; i++) {
data.clear();
data.put("k_" + i, "v_" + i);
pipe.hmset("key_" + i, data); //将值封装到PIPE对象,此时并未执行,还停留在客户端
}
pipe.sync(); //将封装后的PIPE一次性发给redis
end = System.currentTimeMillis();
System.out.println(" PIPE共插入:[" + redis.dbSize() + "]条 .. ");
System.out.println("2,使用PIPE批量设值耗时" + (end - start) / 1000 + "秒 ..");
//--------------------------------------------------------------------------------------------------
// hmget
Set<String> keys = redis.keys("key_*"); //将上面设值所有结果键查询出来
// 直接使用Jedis hgetall
start = System.currentTimeMillis();
Map<String, Map<String, String>> result = new HashMap<String, Map<String, String>>();
for (String key : keys) {
//此处keys根据以上的设值结果,共有10000个,循环10000次
result.put(key, redis.hgetAll(key)); //使用redis对象根据键值去取值,将结果放入result对象
}
end = System.currentTimeMillis();
System.out.println(" 共取值:[" + redis.dbSize() + "]条 .. ");
System.out.println("3,未使用PIPE批量取值耗时 " + (end - start) / 1000 + "秒 ..");
// 使用pipeline hgetall
result.clear();
start = System.currentTimeMillis();
for (String key : keys) {
pipe.hgetAll(key); //使用PIPE封装需要取值的key,此时还停留在客户端,并未真正执行查询请求
}
pipe.sync(); //提交到redis进行查询
end = System.currentTimeMillis();
System.out.println(" PIPE共取值:[" + redis.dbSize() + "]条 .. ");
System.out.println("4,使用PIPE批量取值耗时" + (end - start) / 1000 + "秒 ..");
redis.disconnect();
}
3 기본 배치 명령(mset, mget)과 Pipeline
1 간의 비교는 원자적이지만 파이프라인은 있습니다. 비원자성
(원자성 개념: 트랜잭션은 모두 성공하거나 모두 실패하는 분할할 수 없는 최소 작업 단위입니다. 원자적 작업은 비즈니스 논리 중 하나가 분할할 수 없어야 함을 의미합니다. 한 가지를 처리할 때 모두 성공하거나 둘 다 성공합니다. , 원자를 분할할 수 없음)
2. 기본 배치 명령에는 하나의 명령에 여러 개의 키가 있지만 파이프라인은 여러 명령(트랜잭션 있음)을 지원하며 기본 배치 명령은 다음에서 구현됩니다. 파이프라인은 서버측을 필요로 하고 클라이언트가 함께 완성합니다
4. 파이프라인을 사용하는 올바른 방법
파이프라인을 사용하여 조립하는 명령의 수는 너무 많아지면 안 됩니다. 그렇지 않으면 데이터의 양이 너무 많아질 것입니다. 이로 인해 클라이언트의 대기 시간이 늘어나고 네트워크 정체가 발생할 수도 있습니다. 많은 수의 명령이 분할될 수 있습니다. 여러 개의 작은 파이프라인 명령이 완료됩니다.
1. Jedis에서 파이프라인을 사용하는 방법
redis가 mset 및 mget 메소드를 제공하지만 mdel 메소드를 제공하지 않는다는 것은 누구나 알고 있습니다.
2. Jedis에서 파이프라인을 사용하는 단계:
@Test
public void testCommond() {
// 工具类初始化
JedisUtils jedis = new JedisUtils("192.168.1.111", 6379, "12345678");
for (int i = 0; i < 100; i++) {
// 设值
jedis.set("n" + i, String.valueOf(i));
}
System.out.println("keys from redis return =======" + jedis.keys("*"));
}
// 使用pipeline批量删除
@Test
public void testPipelineMdel() {
// 工具类初始化
JedisUtils jedis = new JedisUtils("192.168.1.111", 6379, "12345678");
List<String> keys = new ArrayList<String>();
for (int i = 0; i < 100; i++) {
keys.add("n" + i);
}
jedis.mdel(keys);
System.out.println("after mdel the redis return ---------" + jedis.keys("*"));
}JedisUtils의 mdel 방법:
/**
* 删除多个字符串key 并释放连接
*
* @param keys*
* @return 成功返回value 失败返回null
*/
public boolean mdel(List<String> keys) {
Jedis jedis = null;
boolean flag = false;
try {
jedis = pool.getResource();//从连接借用Jedis对象
Pipeline pipe = jedis.pipelined();//获取jedis对象的pipeline对象
for(String key:keys){
pipe.del(key); //将多个key放入pipe删除指令中
}
pipe.sync(); //执行命令,完全此时pipeline对象的远程调用
flag = true;
} catch (Exception e) {
pool.returnBrokenResource(jedis);
e.printStackTrace();
} finally {
returnResource(pool, jedis);
}
return flag;
}파이프라인을 사용하여 모든 작업을 제출하고 실행 결과를 반환:
@Test
public void testPipelineSyncAll() {
// 工具类初始化
Jedis jedis = new Jedis("192.168.1.111", 6379);
jedis.auth("12345678");
// 获取pipeline对象
Pipeline pipe = jedis.pipelined();
pipe.multi();
pipe.set("name", "james"); // 调值
pipe.incr("age");// 自增
pipe.get("name");
pipe.discard();
// 将不同类型的操作命令合并提交,并将操作操作以list返回
List<Object> list = pipe.syncAndReturnAll();
for (Object obj : list) {
// 将操作结果打印出来
System.out.println(obj);
}
// 断开连接,释放资源
jedis.disconnect();
}5. redis 트랜잭션
파이프라인은 여러 명령의 조합입니다. 원자성을 보장하기 위해 redis는 간단한 트랜잭션을 제공합니다.
1. Redis의 간단한 트랜잭션,
함께 실행해야 하는 명령 그룹은 multi와 exec 명령 사이에 위치하며, 여기서 multi는 트랜잭션의 시작을 나타내고 exec는 트랜잭션의 끝을 나타냅니다.
2. 트랜잭션 중지 폐기
3. 명령이 잘못되고 구문이 잘못되어 트랜잭션이 정상적으로 종료되지 않습니다.
4. 실행 오류, 구문이 정확합니다. 하지만 유형이 잘못되면 트랜잭션이 정상적으로 종료될 수 있습니다.
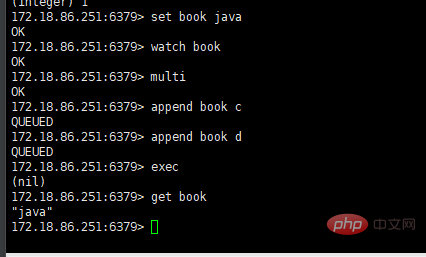
5. watch 명령:
watch 사용 후 다중 실패 및 트랜잭션 실패
WATCH의 메커니즘은 다음과 같습니다. 이 실행되면 Redis는 WATCH라는 키를 확인하고 WATCH 시작 이후 키가 변경되지 않은 경우에만 WATCH EXEC라는 키만 실행합니다. WATCH 명령과 EXEC 명령 사이에서 WATCH 키가 변경되면 EXEC 명령은 실패를 반환합니다.
더 많은 Redis 지식을 알고 싶다면
redis 입문 튜토리얼위 내용은 Redis의 파이프라인에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



