

Python 코드 예제를 사용하여 kNN 알고리즘의 실제 적용 시연_기본 지식

이웃 알고리즘 또는 K-최근접 이웃(kNN, k-NearestNeighbor) 분류 알고리즘은 데이터 마이닝 분류 기술에서 가장 간단한 방법 중 하나입니다. 소위 K 최근접 이웃은 k 최근접 이웃을 의미합니다. 이는 각 샘플이 k 최근접 이웃으로 표현될 수 있음을 의미합니다.
kNN 알고리즘의 핵심 아이디어는 특징 공간에서 샘플의 가장 가까운 인접 샘플 k개 대부분이 특정 카테고리에 속하면 샘플도 이 카테고리에 속하며 이 카테고리에 있는 샘플의 특성을 갖는다는 것입니다. 이 방법은 분류 결정에 있어서 가장 가까운 하나 또는 여러 개의 샘플의 범주를 기준으로 분류할 샘플의 범주만 결정합니다. kNN 방법은 카테고리 결정을 내릴 때 매우 적은 수의 인접 샘플에만 관련됩니다. kNN 방법은 카테고리를 결정하기 위해 클래스 도메인을 구별하는 방법보다는 제한된 주변 샘플에 주로 의존하기 때문에, 교차점이나 중복되는 부분이 많은 샘플 세트를 분할하는 데에는 kNN 방법이 다른 방법보다 효율적입니다. 적합성을 위한 클래스 도메인.
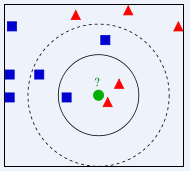
위 사진에서 녹색 원은 어느 반에 배정되어야 할까요? 빨간색 삼각형인가요, 아니면 파란색 사각형인가요? K=3이면 빨간색 삼각형의 비율이 2/3이므로 녹색 원에 빨간색 삼각형의 클래스가 할당됩니다. K=5이면 파란색 사각형의 비율이 3/5이므로 녹색 원에 할당됩니다. 파란색 사각형 유형의 클래스가 지정됩니다.
KNN(K-Nearest Neighbor) 분류 알고리즘은 이론적으로 성숙한 방법이며 가장 간단한 기계 학습 알고리즘 중 하나입니다. 이 방법의 아이디어는: 샘플이 특징 공간에서 가장 유사한(즉, 특징 공간에서 가장 가까운) k개의 샘플 중 특정 범주에 속하면 샘플도 이 범주에 속한다는 것입니다. KNN 알고리즘에서 선택된 이웃은 모두 올바르게 분류된 객체입니다. 이 방법은 분류 의사결정에서 가장 가까운 하나 또는 여러 개의 샘플의 범주를 기반으로 분류할 샘플의 범주만 결정합니다. KNN 방법도 원칙적으로 극한 정리에 의존하지만 카테고리 결정을 내릴 때 매우 적은 수의 인접 샘플에만 관련됩니다. KNN 방법은 카테고리를 결정하기 위해 클래스 도메인을 판별하는 방법보다는 제한된 주변 샘플에 주로 의존하기 때문에 샘플 세트를 많은 수의 교차 또는 중첩으로 분할하는 데에는 KNN 방법이 다른 방법보다 효율적입니다. 적합성을 위한 클래스 도메인.
KNN 알고리즘은 분류뿐만 아니라 회귀에도 사용할 수 있습니다. 샘플의 가장 가까운 이웃 k개를 찾아 이들 이웃의 속성 평균을 샘플에 할당함으로써 샘플의 속성을 얻을 수 있습니다. 더 유용한 방법은 샘플에서 서로 다른 거리에 있는 이웃의 영향에 서로 다른 가중치를 부여하는 것입니다. 예를 들어 가중치는 거리에 반비례합니다.
kNN 알고리즘을 사용하여 Douban 영화 사용자의 성별 예측
요약
본 글에서는 성별에 따라 선호하는 영화의 종류가 다를 것이라고 판단하여 이 실험을 진행하게 되었습니다. 활성 Douban 사용자 274명이 최근 관람한 100편의 영화를 이용하여 유형에 대한 통계를 작성하였고, 획득된 37개의 영화 유형을 속성 특징으로 사용하였고, 사용자의 성별을 라벨로 사용하여 샘플 세트를 구성하였다. kNN 알고리즘을 사용하여 샘플의 90%를 훈련 샘플로 사용하고 10%를 테스트 샘플로 사용하여 Douban 영화 사용자 성별 분류기를 구성하며 정확도는 81.48%에 도달할 수 있습니다.
실험 데이터
본 실험에 사용된 데이터는 Douban 사용자가 표시한 영화로, Douban 사용자 274명이 최근 시청한 영화 100편을 선정했습니다. 각 사용자에 대한 영화 유형 통계입니다. 본 실험에 사용된 데이터에는 총 37개의 영화 유형이 있으므로 이 37가지 유형을 사용자의 속성특징으로 사용하고, 각 특징의 값은 사용자의 영화 100개 중 해당 유형의 영화 개수이다. 사용자는 성별에 따라 라벨이 지정됩니다. Douban에는 사용자 성별 정보가 없으므로 모두 수동으로 라벨이 지정됩니다.
데이터 형식은 다음과 같습니다.
X1,1,X1,2,X1,3,X1,4……X1,36,X1,37,Y1 X2,1,X2,2,X2,3,X2,4……X2,36,X2,37,Y2 ………… X274,1,X274,2,X274,3,X274,4……X274,36,X274,37,Y274
예:
0,0,0,3,1,34,5,0,0,0,11,31,0,0,38,40,0,0,15,8,3,9,14,2,3,0,4,1,1,15,0,0,1,13,0,0,1,1 0,1,0,2,2,24,8,0,0,0,10,37,0,0,44,34,0,0,3,0,4,10,15,5,3,0,0,7,2,13,0,0,2,12,0,0,0,0
像这样的数据一共有274行,表示274个样本。每一个的前37个数据是该样本的37个特征值,最后一个数据为标签,即性别:0表示男性,1表示女性。
在此次试验中取样本的前10%作为测试样本,其余作为训练样本。
首先对所有数据归一化。对矩阵中的每一列求取最大值(max_j)、最小值(min_j),对矩阵中的数据X_j,
X_j=(X_j-min_j)/(max_j-min_j) 。
然后对于每一条测试样本,计算其与所有训练样本的欧氏距离。测试样本i与训练样本j之间的距离为:
distance_i_j=sqrt((Xi,1-Xj,1)^2+(Xi,2-Xj,2)^2+……+(Xi,37-Xj,37)^2) ,
对样本i的所有距离从小到大排序,在前k个中选择出现次数最多的标签,即为样本i的预测值。
实验结果
首先选择一个合适的k值。 对于k=1,3,5,7,均使用同一个测试样本和训练样本,测试其正确率,结果如下表所示。
选取不同k值的正确率表
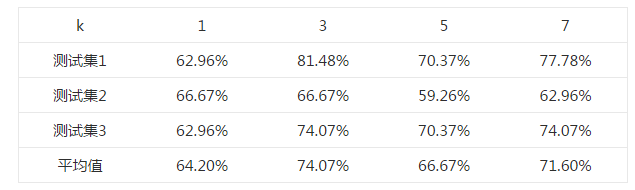
由上述结果可知,在k=3时,测试的平均正确率最高,为74.07%,最高可以达到81.48%。
上述不同的测试集均来自同一样本集中,为随机选取所得。
Python代码
这段代码并非原创,来自《机器学习实战》(Peter Harrington,2013),并有所改动。
#coding:utf-8
from numpy import *
import operator
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,37)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split(',')
returnMat[index,:] = listFromLine[0:37]
classLabelVector.append(int(listFromLine[-1]))
index += 1
fr.close()
return returnMat,classLabelVector
def genderClassTest():
hoRatio = 0.10 #hold out 10%
datingDataMat,datingLabels = file2matrix('doubanMovieDataSet.txt') #load data setfrom file
normMat,ranges,minVals=autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
testMat=normMat[0:numTestVecs,:]
trainMat=normMat[numTestVecs:m,:]
trainLabels=datingLabels[numTestVecs:m]
k=3
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(testMat[i,:],trainMat,trainLabels,k)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]):
errorCount += 1.0
print "Total errors:%d" %errorCount
print "The total accuracy rate is %f" %(1.0-errorCount/float(numTestVecs))

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7642
7642
 15
1392
52
90
11
72
19
33
150
15
1392
52
90
11
72
19
33
150

 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
Windows 8에서 코드를 실행할 수 있습니다
Apr 15, 2025 pm 07:24 PM
VS 코드는 Windows 8에서 실행될 수 있지만 경험은 크지 않을 수 있습니다. 먼저 시스템이 최신 패치로 업데이트되었는지 확인한 다음 시스템 아키텍처와 일치하는 VS 코드 설치 패키지를 다운로드하여 프롬프트대로 설치하십시오. 설치 후 일부 확장은 Windows 8과 호환되지 않을 수 있으며 대체 확장을 찾거나 가상 시스템에서 새로운 Windows 시스템을 사용해야합니다. 필요한 연장을 설치하여 제대로 작동하는지 확인하십시오. Windows 8에서는 VS 코드가 가능하지만 더 나은 개발 경험과 보안을 위해 새로운 Windows 시스템으로 업그레이드하는 것이 좋습니다.
 VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VScode 확장자가 악의적입니까?
Apr 15, 2025 pm 07:57 PM
VS 코드 확장은 악의적 인 코드 숨기기, 취약성 악용 및 합법적 인 확장으로 자위하는 등 악성 위험을 초래합니다. 악의적 인 확장을 식별하는 방법에는 게시자 확인, 주석 읽기, 코드 확인 및주의해서 설치가 포함됩니다. 보안 조치에는 보안 인식, 좋은 습관, 정기적 인 업데이트 및 바이러스 백신 소프트웨어도 포함됩니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
터미널 VSCODE에서 프로그램을 실행하는 방법
Apr 15, 2025 pm 06:42 PM
vs 코드에서는 다음 단계를 통해 터미널에서 프로그램을 실행할 수 있습니다. 코드를 준비하고 통합 터미널을 열어 코드 디렉토리가 터미널 작업 디렉토리와 일치하는지 확인하십시오. 프로그래밍 언어 (예 : Python의 Python Your_file_name.py)에 따라 실행 명령을 선택하여 성공적으로 실행되는지 여부를 확인하고 오류를 해결하십시오. 디버거를 사용하여 디버깅 효율을 향상시킵니다.
 vScode를 Mac에 사용할 수 있습니다
Apr 15, 2025 pm 07:36 PM
vScode를 Mac에 사용할 수 있습니다
Apr 15, 2025 pm 07:36 PM
VS 코드는 Mac에서 사용할 수 있습니다. 강력한 확장, GIT 통합, 터미널 및 디버거가 있으며 풍부한 설정 옵션도 제공합니다. 그러나 특히 대규모 프로젝트 또는 고도로 전문적인 개발의 경우 VS 코드는 성능 또는 기능 제한을 가질 수 있습니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
