

단일 테이블 쿼리란 무엇입니까?

단일 테이블 쿼리는 하나의 테이블에 있는 데이터를 쿼리하는 것을 말합니다. 실행 순서는 "from->where->group by->having->distinct->order by->limit->select"입니다. .

데이터베이스 작업에서 단일 테이블 쿼리는 테이블의 데이터를 쿼리하는 것입니다. 자세한 구문은 다음과 같습니다.
select distinct 字段1,字段2... from 表名 where 分组之前的过滤条件 group by 分组字段 having 分组之后的过滤条件 order by 排序字段 limit 显示的条数;
구문 순서는 동일하지만 실행 순서는 다릅니다. 문법 순서에 따라 실행되지만 이 순서대로 실행됩니다.
from--->where--->group by--->having-->distinct--->order by--->limit--->select
왜 이런 실행 순서가 구현되는지에 대해서는 말하지 않을 것이며 명확하게 설명할 자신도 없습니다. 초보자라면 이 실행 순서만 기억하면 됩니다. 더 알고 싶다면 구글에 접속해 보세요.
단일 테이블 쿼리를 이해하기 전에 먼저 직원 테이블을 생성해 보겠습니다:
emp表: 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职日期 hire_date date 岗位 post varchar 职位描述 post_comment varchar 薪水 salary double 办公室 office int 部门编号 depart_id int
테이블 생성:
create table emp( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, depart_id int );
데이터 삽입:
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values ('niange','male',23,'20170301','manager',15000,401,1), ('monicx','male',23,'20150302','teacher',16000,401,1), ('wupeiqi','male',25,'20130305','teacher',8300,401,1), ('yuanhao','male',34,'20140701','teacher',3500,401,1), ('anny','female',48,'20150311','sale',3000.13,402,2), ('monke','female',38,'20101101','sale',2000.35,402,2), ('sandy','female',18,'20110312','sale',1000.37,402,2), ('chermy','female',18,'20130311','operation',19000,403,3), ('bailes','male',18,'20150411','operation',18000,403,3), ('omg','female',18,'20140512','operation',17000,403,3);
where 조건 필터링
은 where 절에서 사용할 수 있습니다:
1. 비교 연산자: >, <, >=, <=, <>, !=.
2. 1~5 사이 값은 1~5입니다.
3. in(1,3,8) 값은 1, 3 또는 8입니다.
4. 'monicx%'와 마찬가지로
%는 임의의 문자 수를 나타냅니다.
_는 하나의 문자를 나타냅니다.
5. 논리 연산자 and, or, not은 여러 조건에서 직접 사용할 수 있습니다.
6, 정규식
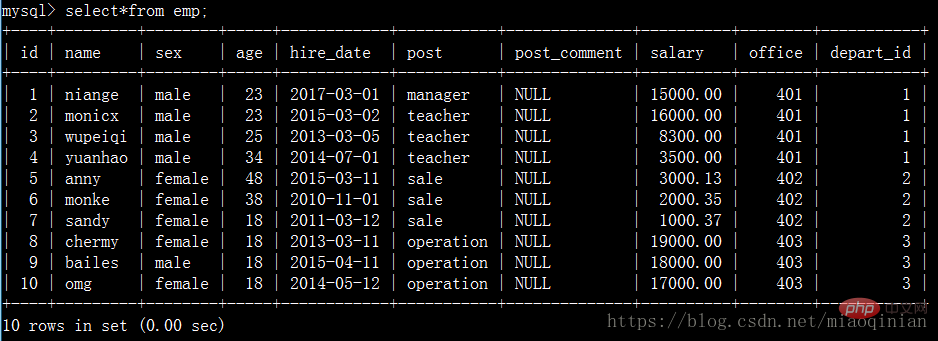
2에서 5 사이의 직원 ID 이름 찾기:
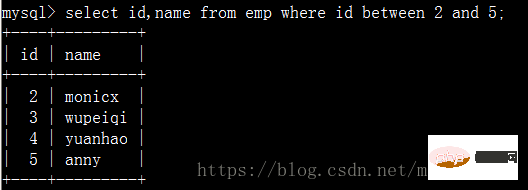
이름에 문자 y가 포함된 직원 이름과 급여 쿼리:
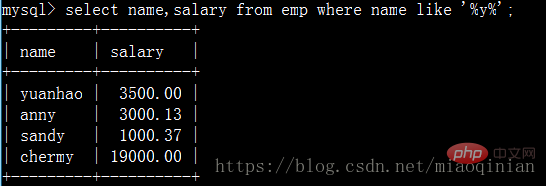
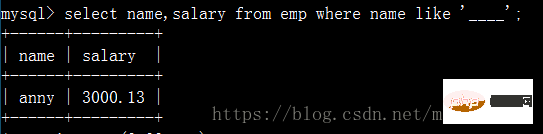
쿼리 직원 이름은 4글자와 급여로 구성됩니다.
직무 설명이 비어 있는 직원 이름과 직위 이름을 쿼리합니다.
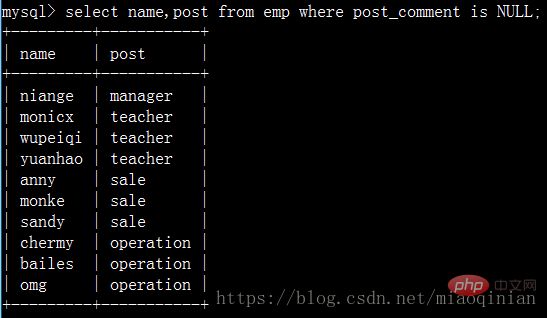
문자 m으로 시작하고 the로 시작하는 이름을 쿼리합니다. e 또는 x로 끝나는 편지 직원! 이때 정규식을 사용할 수 있습니다. MySQL은 정규식을 표현하기 위한 regexp를 제공합니다.

group by group
먼저 mysq의 sql_mode를 only_full_group_by로 설정합니다. 이는 앞으로는 그룹화를 위한 기반만 얻을 수 있다는 의미입니다.
set global sql_mode="strict_trans_tables,only_full_group_by";
where 이후에 그룹화가 발생합니다. 즉, where 이후에 얻은 기록을 기반으로 그룹화가 이루어집니다.
그룹핑이란 직원 정보 테이블에 따라 직위를 그룹화하거나 성별에 따라 그룹화하는 등 모든 기록을 동일한 특정 분야에 따라 분류하는 것을 의미합니다.
그룹화하는 방법은 무엇인가요?
예를 들어, 각 부서의 최고 급여를 가져옵니다.
예: 각 부서의 직원 수를 가져옵니다.
"every""라는 단어 뒤의 필드는 그룹화의 기초입니다.
참고: 어떤 필드로든 그룹화할 수 있지만 게시물별로 그룹화한 후에는 게시물 필드만 볼 수 있습니다.
그러나 그룹 내 정보를 보려면 aggregation(함께 모아서 하나의 콘텐츠로 합성) 기능
每个部门的最高工资 select post,max(salary) from emp group by post; 每个部门的最底工资 select post,min(salary) from emp group by post; 每个部门的平均工资 select post,avg(salary) from emp group by post; 每个部门的工资总合 select post,sum(salary) from emp group by post; 每个部门的总人数 select post,count(id) from emp group by post;
group_concat(그룹화한 후 해당 콘텐츠를 가져오기 위해 사용)을 사용해야 합니다. 필드.)
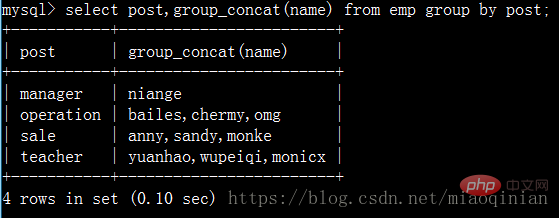
다음과 같이 사용할 수 있습니다.
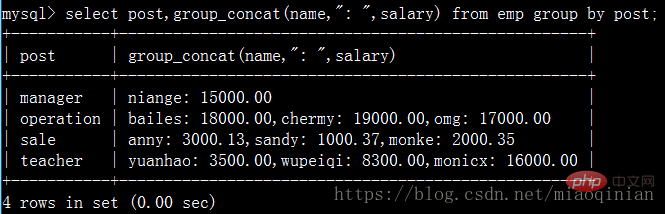
다음 코드로 직접 시도해 볼 수 있습니다.
select post,group_concat(name) from emp group by post; select post,group_concat(name,"_NB") from emp group by post; select post,group_concat(name,": ",salary) from emp group by post; select post,group_concat(salary) from emp group by post;
현명한 반 친구들은 없이도 사용할 수 있다고 말할 것입니다. 그룹화? 아니요! 그러나 mysql은 또 다른 작동 방법을 제공합니다. 연결되어 있습니다.
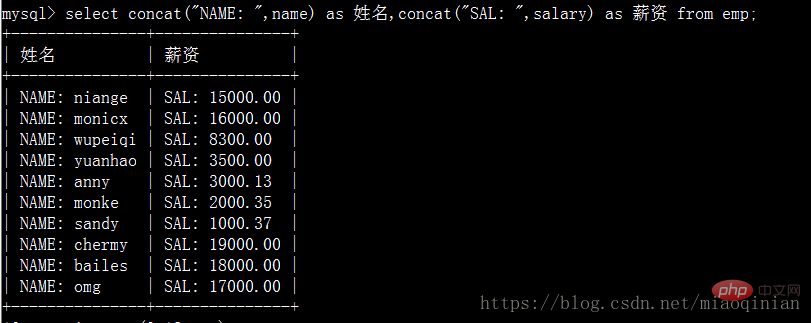
# 补充as语法
mysql> select emp.id,emp.name from emp as t1; # 报错
mysql> select t1.id,t1.name from emp as t1;group by 그게 전부입니다. 그래도 이해가 되지 않는다면 다음과 같은 간단한 연습을 해보세요.
1. 查询岗位名以及岗位包含的所有员工名字
select post,group_concat(name) from emp group by post;
2. 查询岗位名以及各岗位内包含的员工个数
select post,count(id) from emp group by post;
3. 查询公司内男员工和女员工的个数
select sex,count(id) from emp group by sex;
4. 查询岗位名以及各岗位的平均薪资
select post,avg(salary) from emp group by post;
5. 查询岗位名以及各岗位的最高薪资
select post,max(salary) from emp group by post;
6. 查询岗位名以及各岗位的最低薪资
select post,min(salary) from emp group by post;
7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
select sex,avg(salary) from emp group by sex;
8、统计各部门年龄在30岁以上的员工平均工资
select post,avg(salary) from emp where age >= 30 group by post;having 필터
having은 그룹화 후 추가로 필터링된다는 점을 제외하면 where와 동일한 구문 형식을 갖습니다.
where不能用聚合函数,但having是可以用聚合函数,这也是它们最大的区别。
统计各部门年龄在24岁以上的员工平均工资,并且保留平均工资大于4000的部门。
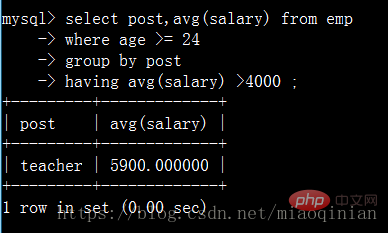
注意:having只能与 select 语句一起使用。
having通常在 group by 子句中使用。
如果不使用 group by子句,不会报错,但会出现以下的情况。

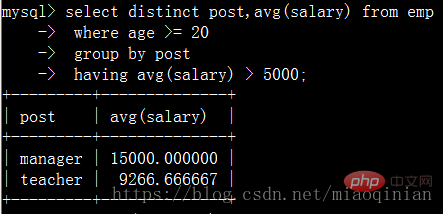
distinct去重
order by 排序
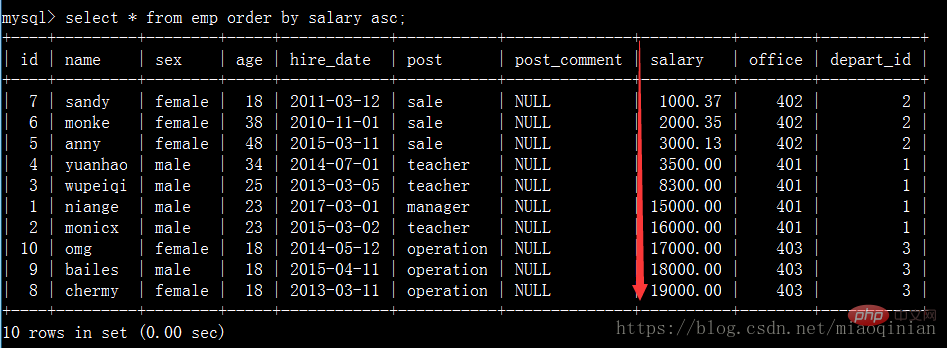
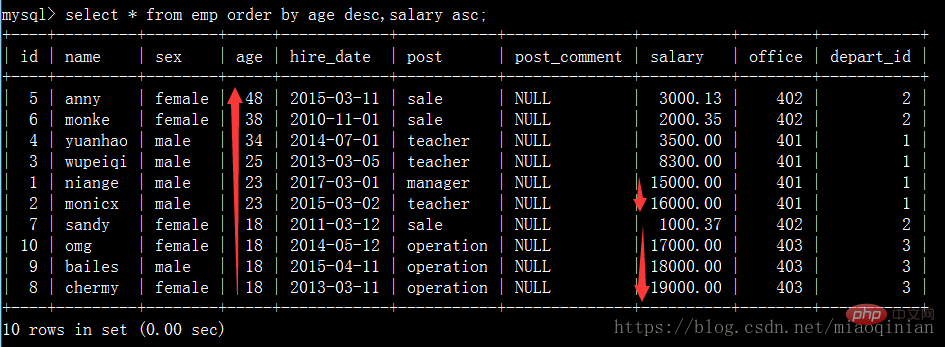
select * from emp order by salary asc; #默认升序排 select * from emp order by salary desc; #降序排 select * from emp order by age desc; #降序排 select * from emp order by age desc,salary asc; #先按照age降序排,再按照薪资升序排
limit 限制显示条数

如查要获取工资最高的员工的信息,我们可以用order by和limit也可以做到。

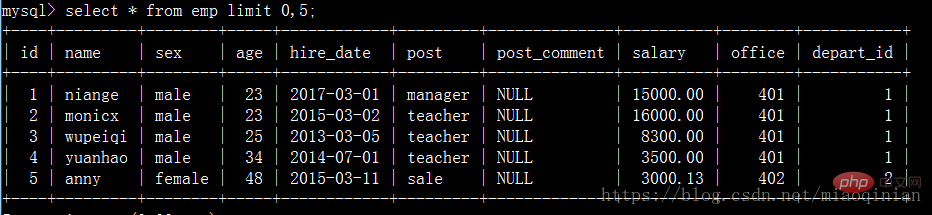
如果查一个表数据量大的话可以用limit分页显示。
select * from emp limit 0,5;
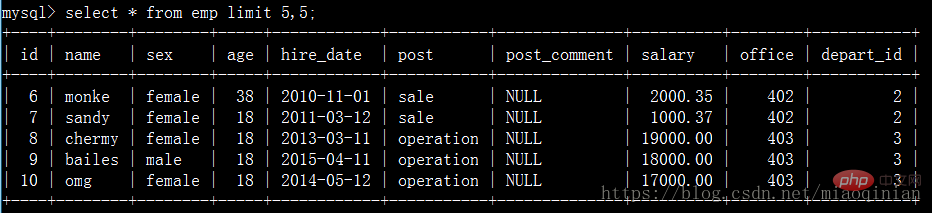
select * from emp limit 5,5;
ps:看到这里如果上面的东西你都明白的话,单表查询你基本上已经熟悉它了。
위 내용은 단일 테이블 쿼리란 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7691
7691
 15
1639
14
1393
52
1287
25
1229
29
15
1639
14
1393
52
1287
25
1229
29

 MySQL에서 인덱스를 사용하는 것보다 전체 테이블 스캔이 더 빠를 수 있습니까?
Apr 09, 2025 am 12:05 AM
MySQL에서 인덱스를 사용하는 것보다 전체 테이블 스캔이 더 빠를 수 있습니까?
Apr 09, 2025 am 12:05 AM
전체 테이블 스캔은 MySQL에서 인덱스를 사용하는 것보다 빠를 수 있습니다. 특정 사례는 다음과 같습니다. 1) 데이터 볼륨은 작습니다. 2) 쿼리가 많은 양의 데이터를 반환 할 때; 3) 인덱스 열이 매우 선택적이지 않은 경우; 4) 복잡한 쿼리시. 쿼리 계획을 분석하고 인덱스 최적화, 과도한 인덱스를 피하고 정기적으로 테이블을 유지 관리하면 실제 응용 프로그램에서 최상의 선택을 할 수 있습니다.
 InnoDB 전체 텍스트 검색 기능을 설명하십시오.
Apr 02, 2025 pm 06:09 PM
InnoDB 전체 텍스트 검색 기능을 설명하십시오.
Apr 02, 2025 pm 06:09 PM
InnoDB의 전체 텍스트 검색 기능은 매우 강력하여 데이터베이스 쿼리 효율성과 대량의 텍스트 데이터를 처리 할 수있는 능력을 크게 향상시킬 수 있습니다. 1) InnoDB는 기본 및 고급 검색 쿼리를 지원하는 역 색인화를 통해 전체 텍스트 검색을 구현합니다. 2) 매치 및 키워드를 사용하여 검색, 부울 모드 및 문구 검색을 지원합니다. 3) 최적화 방법에는 워드 세분화 기술 사용, 인덱스의 주기적 재건 및 캐시 크기 조정, 성능과 정확도를 향상시키는 것이 포함됩니다.
 Windows 7에 MySQL을 설치할 수 있습니까?
Apr 08, 2025 pm 03:21 PM
Windows 7에 MySQL을 설치할 수 있습니까?
Apr 08, 2025 pm 03:21 PM
예, MySQL은 Windows 7에 설치 될 수 있으며 Microsoft는 Windows 7 지원을 중단했지만 MySQL은 여전히 호환됩니다. 그러나 설치 프로세스 중에 다음 지점이 표시되어야합니다. Windows 용 MySQL 설치 프로그램을 다운로드하십시오. MySQL의 적절한 버전 (커뮤니티 또는 기업)을 선택하십시오. 설치 프로세스 중에 적절한 설치 디렉토리 및 문자를 선택하십시오. 루트 사용자 비밀번호를 설정하고 올바르게 유지하십시오. 테스트를 위해 데이터베이스에 연결하십시오. Windows 7의 호환성 및 보안 문제에 주목하고 지원되는 운영 체제로 업그레이드하는 것이 좋습니다.
 MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL : 쉽게 학습하기위한 간단한 개념
Apr 10, 2025 am 09:29 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) 데이터베이스 및 테이블 작성 : CreateAbase 및 CreateTable 명령을 사용하십시오. 2) 기본 작업 : 삽입, 업데이트, 삭제 및 선택. 3) 고급 운영 : 가입, 하위 쿼리 및 거래 처리. 4) 디버깅 기술 : 확인, 데이터 유형 및 권한을 확인하십시오. 5) 최적화 제안 : 인덱스 사용, 선택을 피하고 거래를 사용하십시오.
 InnoDB에서 클러스터 된 인덱스와 비 클러스터 된 인덱스 (2 차 지수)의 차이.
Apr 02, 2025 pm 06:25 PM
InnoDB에서 클러스터 된 인덱스와 비 클러스터 된 인덱스 (2 차 지수)의 차이.
Apr 02, 2025 pm 06:25 PM
클러스터 인덱스와 비 클러스터 인덱스의 차이점은 1. 클러스터 된 인덱스는 인덱스 구조에 데이터 행을 저장하며, 이는 기본 키 및 범위별로 쿼리에 적합합니다. 2. 클러스터되지 않은 인덱스는 인덱스 키 값과 포인터를 데이터 행으로 저장하며 비 예산 키 열 쿼리에 적합합니다.
 MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 사용자와 데이터베이스의 관계
Apr 08, 2025 pm 07:15 PM
MySQL 데이터베이스에서 사용자와 데이터베이스 간의 관계는 권한과 테이블로 정의됩니다. 사용자는 데이터베이스에 액세스 할 수있는 사용자 이름과 비밀번호가 있습니다. 권한은 보조금 명령을 통해 부여되며 테이블은 Create Table 명령에 의해 생성됩니다. 사용자와 데이터베이스 간의 관계를 설정하려면 데이터베이스를 작성하고 사용자를 생성 한 다음 권한을 부여해야합니다.
 MySQL과 Mariadb가 공존 할 수 있습니다
Apr 08, 2025 pm 02:27 PM
MySQL과 Mariadb가 공존 할 수 있습니다
Apr 08, 2025 pm 02:27 PM
MySQL 및 MariaDB는 공존 할 수 있지만주의해서 구성해야합니다. 열쇠는 각 데이터베이스에 다른 포트 번호와 데이터 디렉토리를 할당하고 메모리 할당 및 캐시 크기와 같은 매개 변수를 조정하는 것입니다. 연결 풀링, 애플리케이션 구성 및 버전 차이도 고려해야하며 함정을 피하기 위해 신중하게 테스트하고 계획해야합니다. 두 개의 데이터베이스를 동시에 실행하면 리소스가 제한되는 상황에서 성능 문제가 발생할 수 있습니다.
 다양한 유형의 MySQL 인덱스 (B-Tree, Hash, Full-Text, Spatial)를 설명하십시오.
Apr 02, 2025 pm 07:05 PM
다양한 유형의 MySQL 인덱스 (B-Tree, Hash, Full-Text, Spatial)를 설명하십시오.
Apr 02, 2025 pm 07:05 PM
MySQL은 B-Tree, Hash, Full-Text 및 Spatial의 4 가지 인덱스 유형을 지원합니다. 1.B- 트리 색인은 동일한 값 검색, 범위 쿼리 및 정렬에 적합합니다. 2. 해시 인덱스는 동일한 값 검색에 적합하지만 범위 쿼리 및 정렬을 지원하지 않습니다. 3. 전체 텍스트 색인은 전체 텍스트 검색에 사용되며 다량의 텍스트 데이터를 처리하는 데 적합합니다. 4. 공간 지수는 지리 공간 데이터 쿼리에 사용되며 GIS 응용 프로그램에 적합합니다.
