

Python을 사용하여 Zhihu에서 지정된 답변으로 비디오를 캡처하는 방법을 알아보세요.


서문
이제 Zhihu는 동영상 업로드를 허용하지만 너무 화가 나서 필사적으로 좀 조사한 다음 쉽게 다운로드할 수 있도록 코딩했습니다. 비디오를 저장합니다.
다음으로, 고양이는 왜 뱀을 전혀 무서워하지 않나요? 예를 들어 대답하고 전체 다운로드 과정을 공유하세요.
관련 학습 권장사항: python 비디오 튜토리얼
디버그
F12를 열고 아래와 같이 커서를 찾습니다.
그런 다음 커서를 비디오로 이동합니다. 아래와 같이:
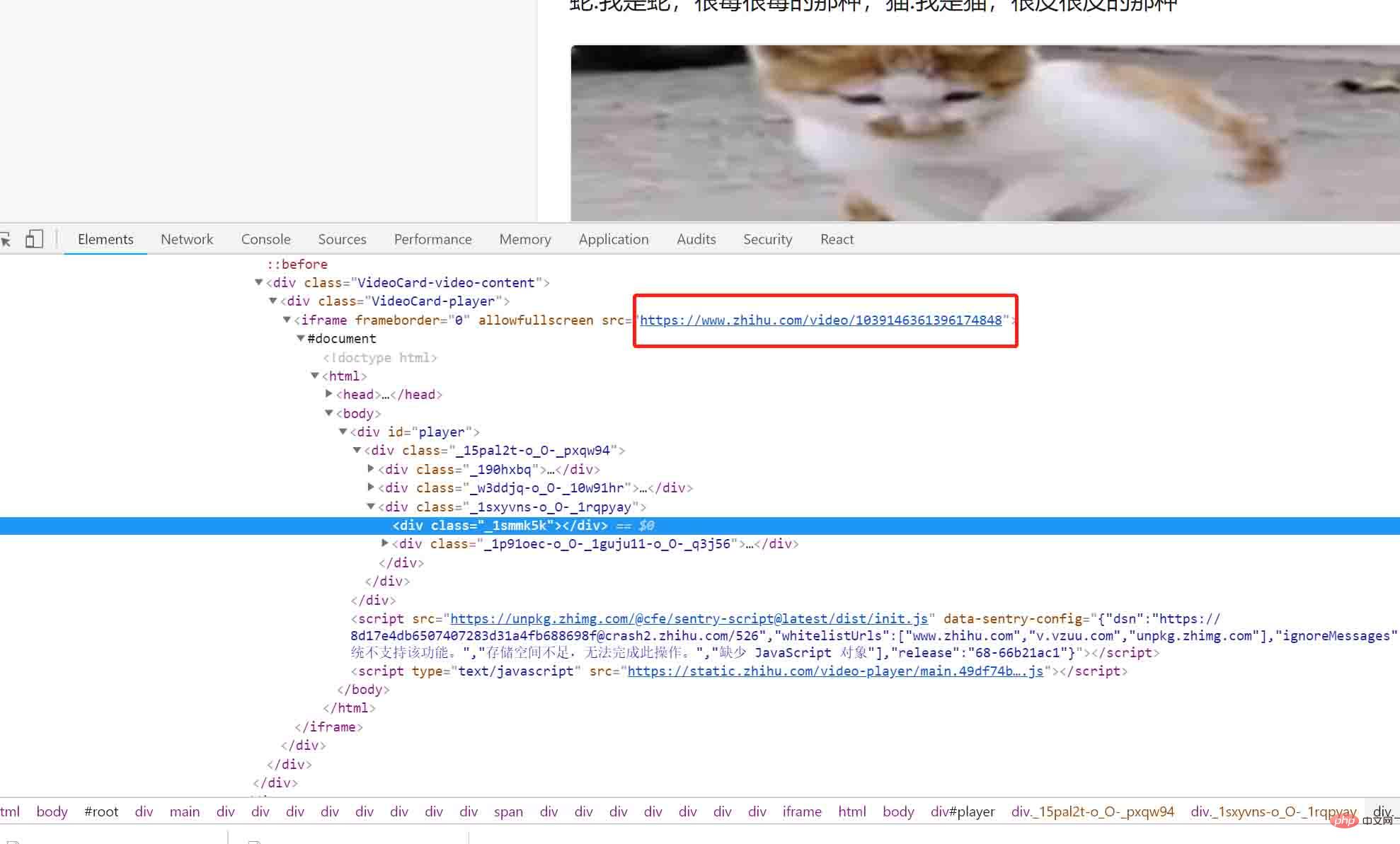
야 이게 뭐야? 시야에 신비한 링크가 나타났습니다: https://www.zhihu.com/video/xxxxx, 이 링크를 브라우저에 복사한 다음 열어 보겠습니다:
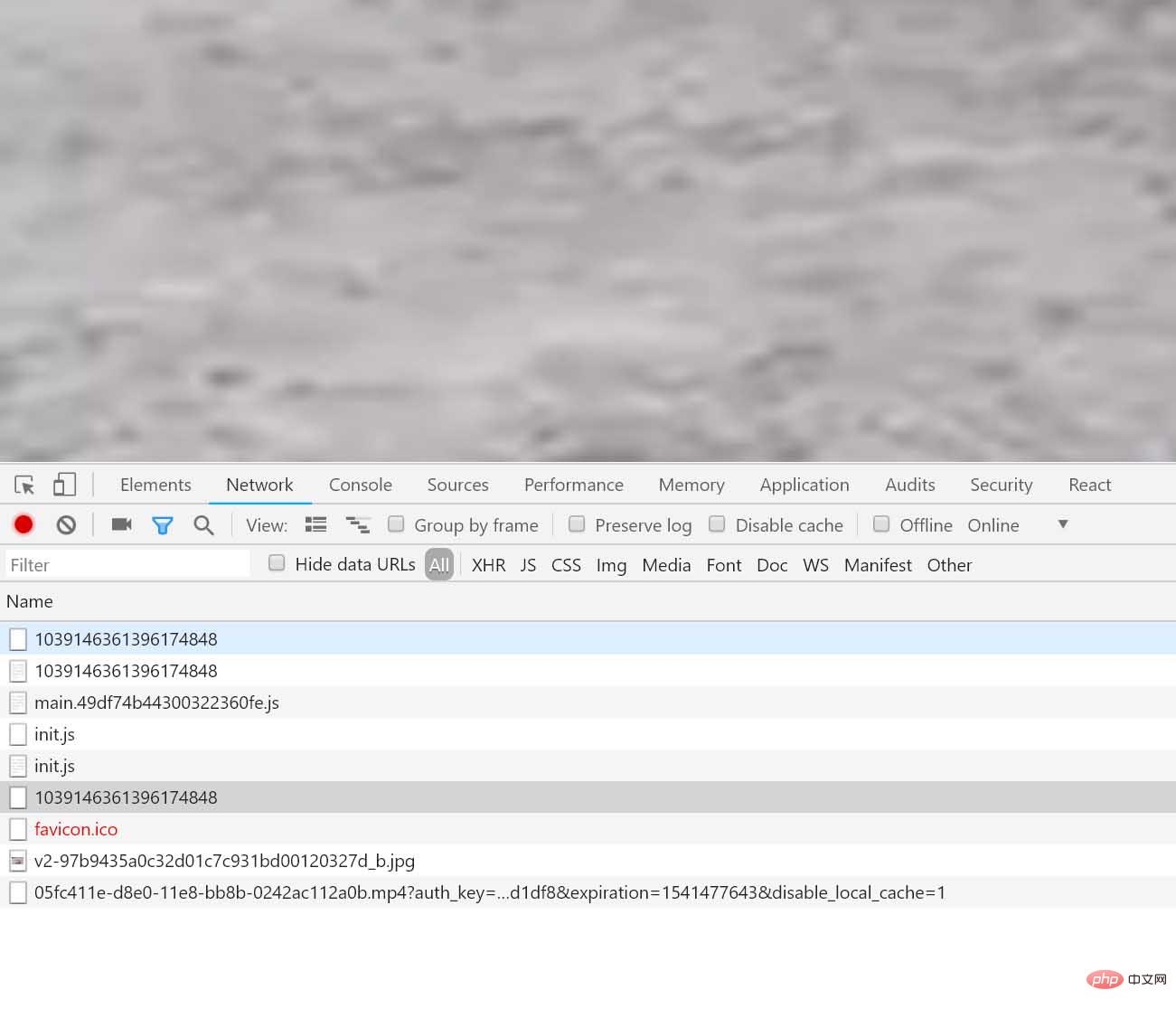
이것이 우리가 하는 것 같습니다 비디오를 찾고 계시다면 걱정하지 마십시오. 웹 페이지의 요청을 살펴보겠습니다. 그러면 매우 흥미로운 요청을 찾을 수 있습니다(요점은 다음과 같습니다).
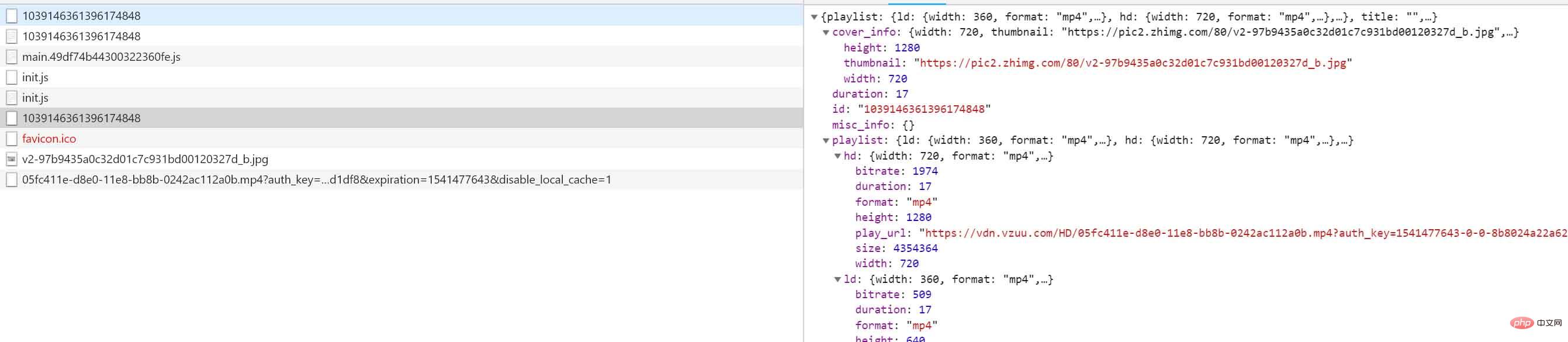
데이터를 직접 살펴보겠습니다. :
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-987c2c504d14ab1165ce2ed47759d927&expiration=1541477643&disable_local_cache=1",
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-8b8024a22a62f097ca31b8b06b7233a1&expiration=1541477643&disable_local_cache=1",
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-5948c2562d817218c9a9fc41abad1df8&expiration=1541477643&disable_local_cache=1",
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-97b9435a0c32d01c7c931bd00120327d_b.jpg",
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}맞습니다. 다운로드하려는 동영상은 여기에 있습니다. 여기서 ld는 일반 화질, sd는 표준 화질, hd는 고화질을 의미합니다. 브라우저에서 해당 링크를 다시 연 다음 마우스 오른쪽 버튼을 클릭하고 비디오를 다운로드하려면 저장하세요.
Code
전체 프로세스가 어떻게 생겼는지 알면 다음 코딩 프로세스는 간단합니다. 여기서는 너무 많이 설명하지 않고 코드로 이동합니다.
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())결론
코드도 다음과 같습니다. 최적화된 공간, 여기서는 답변의 첫 번째 동영상을 다운로드했습니다. 이론적으로는 하나의 답변 아래에 여러 동영상이 있어야 합니다. 여전히 질문이나 제안 사항이 있으면 우리와 소통할 수 있습니다.
관련 학습 권장사항: python 비디오 튜토리얼
위 내용은 Python을 사용하여 Zhihu에서 지정된 답변으로 비디오를 캡처하는 방법을 알아보세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7518
7518
 15
1378
52
80
11
53
19
21
67
15
1378
52
80
11
53
19
21
67

 웹 사이트 성과를 향상시키기 위해 Debian Apache Logs를 사용하는 방법
Apr 12, 2025 pm 11:36 PM
웹 사이트 성과를 향상시키기 위해 Debian Apache Logs를 사용하는 방법
Apr 12, 2025 pm 11:36 PM
이 기사는 데비안 시스템에서 Apache Logs를 분석하여 웹 사이트 성능을 향상시키는 방법을 설명합니다. 1. 로그 분석 기본 사항 Apache Log는 IP 주소, 타임 스탬프, 요청 URL, HTTP 메소드 및 응답 코드를 포함한 모든 HTTP 요청의 자세한 정보를 기록합니다. 데비안 시스템 에서이 로그는 일반적으로 /var/log/apache2/access.log 및 /var/log/apache2/error.log 디렉토리에 있습니다. 로그 구조를 이해하는 것은 효과적인 분석의 첫 번째 단계입니다. 2. 로그 분석 도구 다양한 도구를 사용하여 Apache 로그를 분석 할 수 있습니다.
 파이썬 : 게임, Guis 등
Apr 13, 2025 am 12:14 AM
파이썬 : 게임, Guis 등
Apr 13, 2025 am 12:14 AM
Python은 게임 및 GUI 개발에서 탁월합니다. 1) 게임 개발은 Pygame을 사용하여 드로잉, 오디오 및 기타 기능을 제공하며 2D 게임을 만드는 데 적합합니다. 2) GUI 개발은 Tkinter 또는 PYQT를 선택할 수 있습니다. Tkinter는 간단하고 사용하기 쉽고 PYQT는 풍부한 기능을 가지고 있으며 전문 개발에 적합합니다.
 PHP 및 Python : 두 가지 인기있는 프로그래밍 언어를 비교합니다
Apr 14, 2025 am 12:13 AM
PHP 및 Python : 두 가지 인기있는 프로그래밍 언어를 비교합니다
Apr 14, 2025 am 12:13 AM
PHP와 Python은 각각 고유 한 장점이 있으며 프로젝트 요구 사항에 따라 선택합니다. 1.PHP는 웹 개발, 특히 웹 사이트의 빠른 개발 및 유지 보수에 적합합니다. 2. Python은 간결한 구문을 가진 데이터 과학, 기계 학습 및 인공 지능에 적합하며 초보자에게 적합합니다.
 DDOS 공격 탐지에서 데비안 스나이퍼의 역할
Apr 12, 2025 pm 10:42 PM
DDOS 공격 탐지에서 데비안 스나이퍼의 역할
Apr 12, 2025 pm 10:42 PM
이 기사에서는 DDOS 공격 탐지 방법에 대해 설명합니다. "Debiansniffer"의 직접적인 적용 사례는 발견되지 않았지만 DDOS 공격 탐지에 다음과 같은 방법을 사용할 수 있습니다. 효과적인 DDOS 공격 탐지 기술 : 트래픽 분석을 기반으로 한 탐지 : 갑작스런 트래픽 성장, 특정 포트에서의 연결 감지 등의 비정상적인 네트워크 트래픽 패턴을 모니터링하여 DDOS 공격을 식별합니다. 예를 들어, Pyshark 및 Colorama 라이브러리와 결합 된 Python 스크립트는 실시간으로 네트워크 트래픽을 모니터링하고 경고를 발행 할 수 있습니다. 통계 분석에 기반한 탐지 : 데이터와 같은 네트워크 트래픽의 통계적 특성을 분석하여
 Debian Readdir가 다른 도구와 통합하는 방법
Apr 13, 2025 am 09:42 AM
Debian Readdir가 다른 도구와 통합하는 방법
Apr 13, 2025 am 09:42 AM
데비안 시스템의 readdir 함수는 디렉토리 컨텐츠를 읽는 데 사용되는 시스템 호출이며 종종 C 프로그래밍에 사용됩니다. 이 기사에서는 ReadDir를 다른 도구와 통합하여 기능을 향상시키는 방법을 설명합니다. 방법 1 : C 언어 프로그램을 파이프 라인과 결합하고 먼저 C 프로그램을 작성하여 readDir 함수를 호출하고 결과를 출력하십시오.#포함#포함#포함#포함#includinTmain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 NGINX SSL 인증서 업데이트 Debian Tutorial
Apr 13, 2025 am 07:21 AM
NGINX SSL 인증서 업데이트 Debian Tutorial
Apr 13, 2025 am 07:21 AM
이 기사에서는 Debian 시스템에서 NginxSSL 인증서를 업데이트하는 방법에 대해 안내합니다. 1 단계 : CertBot을 먼저 설치하십시오. 시스템에 CERTBOT 및 PYTHON3-CERTBOT-NGINX 패키지가 설치되어 있는지 확인하십시오. 설치되지 않은 경우 다음 명령을 실행하십시오. sudoapt-getupdatesudoapt-getinstallcertbotpython3-certbot-nginx 2 단계 : 인증서 획득 및 구성 rectbot 명령을 사용하여 nginx를 획득하고 nginx를 구성하십시오.
 파이썬과 시간 : 공부 시간을 최대한 활용
Apr 14, 2025 am 12:02 AM
파이썬과 시간 : 공부 시간을 최대한 활용
Apr 14, 2025 am 12:02 AM
제한된 시간에 Python 학습 효율을 극대화하려면 Python의 DateTime, Time 및 Schedule 모듈을 사용할 수 있습니다. 1. DateTime 모듈은 학습 시간을 기록하고 계획하는 데 사용됩니다. 2. 시간 모듈은 학습과 휴식 시간을 설정하는 데 도움이됩니다. 3. 일정 모듈은 주간 학습 작업을 자동으로 배열합니다.
 Debian OpenSSL에서 HTTPS 서버를 구성하는 방법
Apr 13, 2025 am 11:03 AM
Debian OpenSSL에서 HTTPS 서버를 구성하는 방법
Apr 13, 2025 am 11:03 AM
데비안 시스템에서 HTTPS 서버를 구성하려면 필요한 소프트웨어 설치, SSL 인증서 생성 및 SSL 인증서를 사용하기 위해 웹 서버 (예 : Apache 또는 Nginx)를 구성하는 등 여러 단계가 포함됩니다. 다음은 Apacheweb 서버를 사용하고 있다고 가정하는 기본 안내서입니다. 1. 필요한 소프트웨어를 먼저 설치하고 시스템이 최신 상태인지 확인하고 Apache 및 OpenSSL을 설치하십시오 : Sudoaptupdatesudoaptupgradesudoaptinsta
