
텍스트 정보
여기에서는 대신 특정 학교의 수업 일정을 사용합니다.

다음 코드로 이동합니다.
a .php
<?php header( "Content-type:text/html;Charset=utf-8" );
$ch = curl_init(); $url ="表的链接";
curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" );
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch);
preg_match_all("/<td rowspan=\"\d\">(.*?)<\/td>\n<td rowspan=\"\d\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td rowspan=\"\d\" align=\"\w+\">(.*?)<\/td><td>(.*?)<\/td>\n<td>(.*?)<\/td><td>(.*?)<\/td>/",$content,$matchs,PREG_SET_ORDER);//匹配该表所用的正则
var_dump($matchs);그런 다음 실행해 보겠습니다.

수업 일정을 성공적으로 가져왔습니다.
사진 획득
절대 링크
바이두 갤러리 홈페이지를 예로 들어보겠습니다
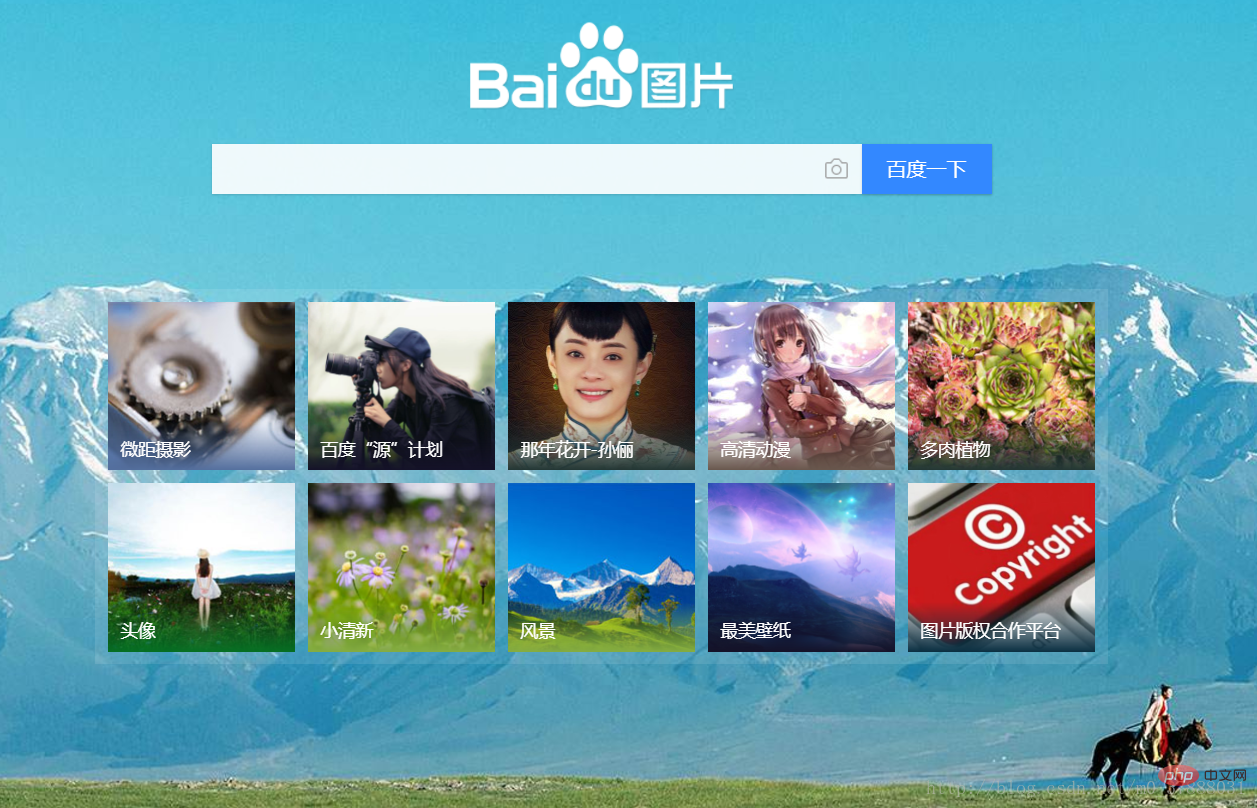
b .php
<?php header( "Content-type:text/html;Charset=utf-8" );
$ch = curl_init(); $url="http://image.baidu.com/";
curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.113 Safari/537.36" );
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch); $string=file_get_contents($url);
preg_match_all("/<img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/image/301/164/948/1594878376637006.png" class="lazy" ([^ alt="PHP에서 크롤러를 구현하는 프로세스를 이해하는 데 10분 정도 소요됩니다." >]*)\s*src=('|\")([^'\"]+)('|\")/",
$string,$matches); $new_arr=array_unique($matches[3]); foreach($new_arr as $key){
echo "<img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/image/301/164/948/1594878376637006.png" class="lazy" src=$key alt="PHP에서 크롤러를 구현하는 프로세스를 이해하는 데 10분 정도 소요됩니다." >";
}그러면 다음 페이지가 표시됩니다. 
상대 링크
바이두 갤러리의 사진 링크는 대부분 절대 링크이므로 상대 링크인 웹페이지 사진을 만나면 우리는 어떻게 처리해야 할까요? 사실 매우 간단합니다. 루프 부분을 
로 변경하면 브라우저에서 이미지를 출력할 수도 있습니다.
읽어주셔서 감사합니다. 도움이 되셨으면 좋겠습니다.
추천 튜토리얼: "php 튜토리얼"
위 내용은 PHP에서 크롤러를 구현하는 프로세스를 이해하는 데 10분 정도 소요됩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



