

SQL Server의 Partition By 및 row_number 함수 사용에 대한 자세한 설명


키워드별 파티션은 분석 함수의 일부로, 그룹 내 여러 레코드를 반환할 수 있다는 점에서 집계 함수와 다릅니다. 반면 집계 함수에는 일반적으로 파티션별 통계 값을 반영하는 레코드가 하나만 있습니다. 결과 집합을 그룹화합니다. 지정하지 않으면 전체 결과 집합을 그룹으로 처리합니다.
오늘 그룹에서 질문을 봤는데 여기에 요약하겠습니다. 다양한 카테고리에서 최신 기록을 쿼리하세요. 얼핏 보기에는 매우 간단하지 않나요? 분류를 원할 경우 Group By를 사용하고, 최신 기록을 원할 경우 Order By를 사용하세요. 그런 다음 자신의 테이블에 만들어 보세요:
관련 학습 권장 사항: mysql 비디오 튜토리얼
우선 제출 시간에 따라 데이터를 역순으로 테이블에 배치합니다.
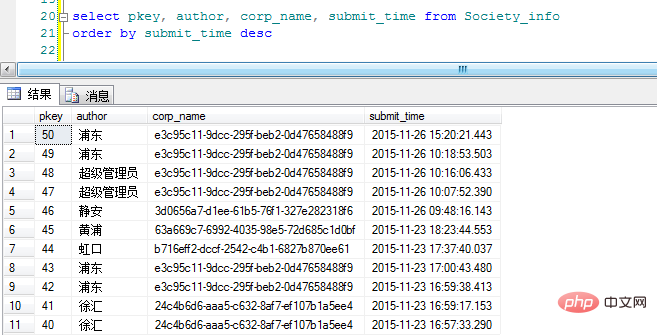
"corp_name"은 분류 GUID입니다(제 이름이 임의로 지정되었음을 양해해 주시기 바랍니다). 좋습니다. 표시 효과를 보기 위해 Group By를 추가하는 원래 아이디어는 다음과 같습니다.
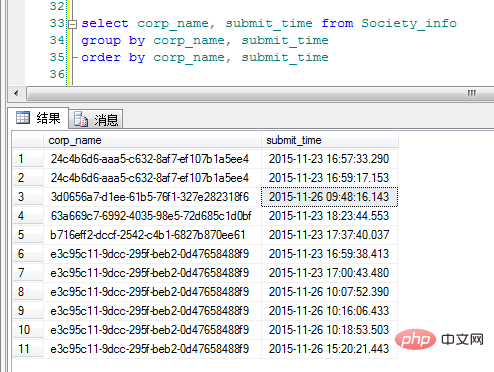
어, 음. 이 결과는 제가 상상했던 것과 다릅니다. 코드를 작성할 때 여전히 문제를 합리적으로 분석해야 하는 것 같습니다. 마음이 결과를 제어할 수는 없습니다.
요구사항이 데이터 카테고리가 다르기 때문에 Group By 외에 다른 기능을 사용할 수 있나요? 조사를 해보니 실제로 over(partition by) 기능이 있다는 것을 알았습니다. 그러면 일반적으로 사용되는 Group By 기능과의 차이점은 무엇입니까? Group By는 단순히 결과를 그룹화하는 것 외에도 일반적으로 집계 기능과 함께 사용됩니다. Partition By에는 그룹화 기능도 있으며 여기서는 자세히 설명하지 않겠습니다.
코드를 보세요:
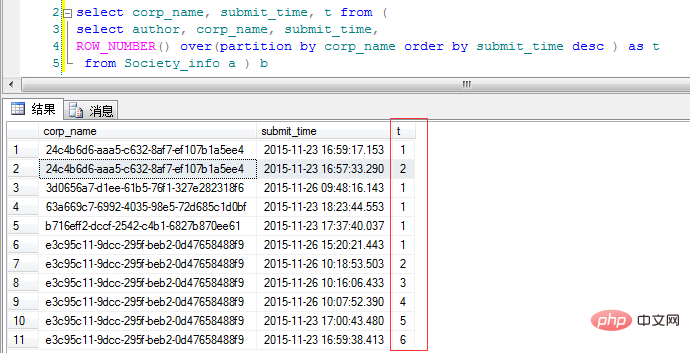
over(partition by corp_name order by submit_time desc ) as t . corp_name에 따라 분류되고 시간의 역순으로 정렬됩니다. "t" 여기의 열은 다양한 corp_name 클래스의 발생 횟수입니다. 요구 사항은 다양한 카테고리의 최신 제출 데이터만 쿼리하면 됩니다. "t"로 다시 필터링하세요.
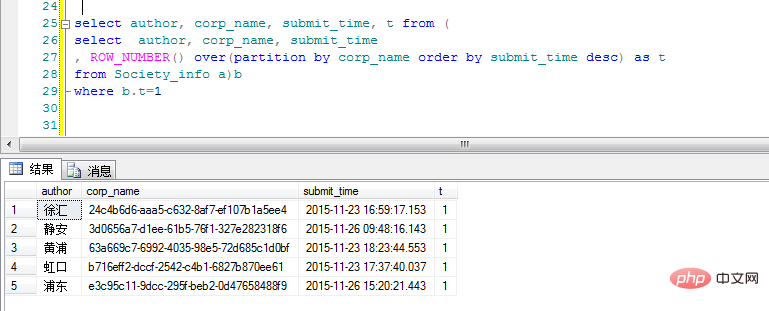
좋아요, 결과가 나왔습니다. 좋아요를 눌러달라는 게 아니라 제 아바타의 가슴을 좋아해 주시길 바랍니다. ! ! !
ps: SQL Server 데이터베이스 파티션별 및 ROW_NUMBER() 함수 사용에 대한 자세한 설명
필드별 SQL 파티션 사용 경험
먼저 예제를 살펴보세요.
if object_id('TESTDB') is not null drop table TESTDB create table TESTDB(A varchar(8), B varchar(8)) insert into TESTDB select 'A1', 'B1' union all select 'A1', 'B2' union all select 'A1', 'B3' union all select 'A2', 'B4' union all select 'A2', 'B5' union all select 'A2', 'B6' union all select 'A3', 'B7' union all select 'A3', 'B3' union all select 'A3', 'B4'
-- 모든 정보
SELECT * FROM TESTDB A B ------- A1 B1 A1 B2 A1 B3 A2 B4 A2 B5 A2 B6 A3 B7 A3 B3 A3 B4
-- 사용 PARTITION BY 함수 뒤에
SELECT *,ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) NUM FROM TESTDB A B NUM ------------- A1 B1 1 A1 B2 2 A1 B3 3 A2 B4 1 A2 B5 2 A2 B6 3 A3 B7 1 A3 B3 2 A3 B4 3
는 결과에 추가 열 NUM이 있음을 확인할 수 있습니다. 이 NUM은 동일한 행의 수를 나타냅니다. 예를 들어 A1이 3개 있는 경우 해당 행의 수를 표시합니다. 각 A1.
-- ROW_NUMBER() OVER
SELECT *,ROW_NUMBER() OVER(ORDER BY A DESC)NUM FROM TESTDB A B NUM ------------------------ A3 B7 1 A3 B3 2 A3 B4 3 A2 B4 4 A2 B5 5 A2 B6 6 A1 B1 7 A1 B2 8 A1 B3 9
의 결과만 사용하면 행 번호만 표시하는 것을 볼 수 있습니다.
-- 애플리케이션에 대해 더 자세히 살펴보겠습니다
SELECT A = CASE WHEN NUM = 1 THEN A ELSE '' END,B FROM (SELECT A,NUM = ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) FROM TESTDB) T A B --------- A1 B1 B2 B3 A2 B4 B5 B6 A3 B7 B3 B4
다음으로 몇 가지 예제를 통해 ROW_NUMBER() 함수의 사용법을 소개하겠습니다.
예는 다음과 같습니다.
1.
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
와 같이 번호 매기기에는 row_number() 함수를 사용합니다. 원칙: 먼저 psd로 정렬하고, 정렬한 후 각 데이터에 번호를 매깁니다.
2. 주문을 가격 오름차순으로 정렬하고, 각 레코드를 다음 코드로 정렬합니다.
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3. 각 가구의 모든 주문을 계산하고 각 고객의 주문을 오름차순으로 정렬합니다. 금액별로 주문하고 동시에 각 고객의 주문에 번호를 매깁니다. 이렇게 하면 각 고객이 주문한 수를 알 수 있습니다.
그림에 표시된 대로:

코드는 다음과 같습니다.
select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order
4. 각 고객이 최근에 주문한 수를 계산합니다.

코드는 다음과 같습니다.
with tabs as ( select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order ) select MAX(rows) as '下单次数',customerID from tabs group by customerID
5. 각 고객의 모든 주문 중 최소 구매 금액을 계산하고, 해당 주문 중 고객이 구매한 횟수도 계산합니다.
如图:

上图:rows表示客户是第几次购买。
思路:利用临时表来执行这一操作。
1.先按客户进行分组,然后按客户的下单的时间进行排序,并进行编号。
2.然后利用子查询查找出每一个客户购买时的最小价格。
3.根据查找出每一个客户的最小价格来查找相应的记录。
代码如下:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by insDT) as rows,customerID,totalPrice, DID from OP_Order ) select * from tabs where totalPrice in ( select MIN(totalPrice)from tabs group by customerID )
6.筛选出客户第一次下的订单。

思路。利用rows=1来查询客户第一次下的订单记录。
代码如下:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order ) select * from tabs where rows = 1 select * from OP_Order
7.rows_number()可用于分页
思路:先把所有的产品筛选出来,然后对这些产品进行编号。然后在where子句中进行过滤。
8.注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行。
如下代码:
select ROW_NUMBER() over(partition by customerID order by insDT) as rows, customerID,totalPrice, DID from OP_Order where insDT>'2011-07-22'
以上代码是先执行where子句,执行完后,再给每一条记录进行编号。
위 내용은 SQL Server의 Partition By 및 row_number 함수 사용에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7555
7555
 15
1384
52
83
11
59
19
28
96
15
1384
52
83
11
59
19
28
96

 InnoDB 전체 텍스트 검색 기능을 설명하십시오.
Apr 02, 2025 pm 06:09 PM
InnoDB 전체 텍스트 검색 기능을 설명하십시오.
Apr 02, 2025 pm 06:09 PM
InnoDB의 전체 텍스트 검색 기능은 매우 강력하여 데이터베이스 쿼리 효율성과 대량의 텍스트 데이터를 처리 할 수있는 능력을 크게 향상시킬 수 있습니다. 1) InnoDB는 기본 및 고급 검색 쿼리를 지원하는 역 색인화를 통해 전체 텍스트 검색을 구현합니다. 2) 매치 및 키워드를 사용하여 검색, 부울 모드 및 문구 검색을 지원합니다. 3) 최적화 방법에는 워드 세분화 기술 사용, 인덱스의 주기적 재건 및 캐시 크기 조정, 성능과 정확도를 향상시키는 것이 포함됩니다.
 Alter Table 문을 사용하여 MySQL에서 테이블을 어떻게 변경합니까?
Mar 19, 2025 pm 03:51 PM
Alter Table 문을 사용하여 MySQL에서 테이블을 어떻게 변경합니까?
Mar 19, 2025 pm 03:51 PM
이 기사는 MySQL의 Alter Table 문을 사용하여 열 추가/드롭 테이블/열 변경 및 열 데이터 유형 변경을 포함하여 테이블을 수정하는 것에 대해 설명합니다.
 MySQL에서 인덱스를 사용하는 것보다 전체 테이블 스캔이 더 빠를 수 있습니까?
Apr 09, 2025 am 12:05 AM
MySQL에서 인덱스를 사용하는 것보다 전체 테이블 스캔이 더 빠를 수 있습니까?
Apr 09, 2025 am 12:05 AM
전체 테이블 스캔은 MySQL에서 인덱스를 사용하는 것보다 빠를 수 있습니다. 특정 사례는 다음과 같습니다. 1) 데이터 볼륨은 작습니다. 2) 쿼리가 많은 양의 데이터를 반환 할 때; 3) 인덱스 열이 매우 선택적이지 않은 경우; 4) 복잡한 쿼리시. 쿼리 계획을 분석하고 인덱스 최적화, 과도한 인덱스를 피하고 정기적으로 테이블을 유지 관리하면 실제 응용 프로그램에서 최상의 선택을 할 수 있습니다.
 Windows 7에 MySQL을 설치할 수 있습니까?
Apr 08, 2025 pm 03:21 PM
Windows 7에 MySQL을 설치할 수 있습니까?
Apr 08, 2025 pm 03:21 PM
예, MySQL은 Windows 7에 설치 될 수 있으며 Microsoft는 Windows 7 지원을 중단했지만 MySQL은 여전히 호환됩니다. 그러나 설치 프로세스 중에 다음 지점이 표시되어야합니다. Windows 용 MySQL 설치 프로그램을 다운로드하십시오. MySQL의 적절한 버전 (커뮤니티 또는 기업)을 선택하십시오. 설치 프로세스 중에 적절한 설치 디렉토리 및 문자를 선택하십시오. 루트 사용자 비밀번호를 설정하고 올바르게 유지하십시오. 테스트를 위해 데이터베이스에 연결하십시오. Windows 7의 호환성 및 보안 문제에 주목하고 지원되는 운영 체제로 업그레이드하는 것이 좋습니다.
 MySQL 연결에 대한 SSL/TLS 암호화를 어떻게 구성합니까?
Mar 18, 2025 pm 12:01 PM
MySQL 연결에 대한 SSL/TLS 암호화를 어떻게 구성합니까?
Mar 18, 2025 pm 12:01 PM
기사는 인증서 생성 및 확인을 포함하여 MySQL에 대한 SSL/TLS 암호화 구성에 대해 설명합니다. 주요 문제는 자체 서명 인증서의 보안 영향을 사용하는 것입니다. [문자 수 : 159]
 인기있는 MySQL GUI 도구는 무엇입니까 (예 : MySQL Workbench, Phpmyadmin)?
Mar 21, 2025 pm 06:28 PM
인기있는 MySQL GUI 도구는 무엇입니까 (예 : MySQL Workbench, Phpmyadmin)?
Mar 21, 2025 pm 06:28 PM
기사는 MySQL Workbench 및 Phpmyadmin과 같은 인기있는 MySQL GUI 도구에 대해 논의하여 초보자 및 고급 사용자를위한 기능과 적합성을 비교합니다. [159 자].
 InnoDB에서 클러스터 된 인덱스와 비 클러스터 된 인덱스 (2 차 지수)의 차이.
Apr 02, 2025 pm 06:25 PM
InnoDB에서 클러스터 된 인덱스와 비 클러스터 된 인덱스 (2 차 지수)의 차이.
Apr 02, 2025 pm 06:25 PM
클러스터 인덱스와 비 클러스터 인덱스의 차이점은 1. 클러스터 된 인덱스는 인덱스 구조에 데이터 행을 저장하며, 이는 기본 키 및 범위별로 쿼리에 적합합니다. 2. 클러스터되지 않은 인덱스는 인덱스 키 값과 포인터를 데이터 행으로 저장하며 비 예산 키 열 쿼리에 적합합니다.
 MySQL에서 큰 데이터 세트를 어떻게 처리합니까?
Mar 21, 2025 pm 12:15 PM
MySQL에서 큰 데이터 세트를 어떻게 처리합니까?
Mar 21, 2025 pm 12:15 PM
기사는 MySQL에서 파티셔닝, 샤딩, 인덱싱 및 쿼리 최적화를 포함하여 대규모 데이터 세트를 처리하기위한 전략에 대해 설명합니다.
