
onDestroy: startService 메소드를 통해 시작된 서비스는 Context의 StopService가 호출되거나 서비스 내에서 stopSelf 메소드가 호출되는 경우에만 서비스가 중지되고 파기됩니다. 서비스 콜백 기능이 실행됩니다.
2.3.BindService 생명주기
bindService를 통해 서비스를 시작하는 것은 주로 다음과 같은 생명주기 기능을 가지고 있습니다:
onCreate():
서비스가 처음 생성될 때 시스템은 이 메소드를 호출합니다. 서비스가 이미 실행 중인 경우 이 메서드는 호출되지 않고 한 번만 호출됩니다.
onStartCommand():
이 메서드는 다른 구성 요소가 startService()를 호출하여 서비스 시작을 요청할 때 시스템에서 호출됩니다.
onDestroy():
이 메소드는 서비스가 더 이상 사용되지 않을 때 시스템에 의해 호출되어 폐기됩니다.
onBind():
bindService()를 호출하여 다른 구성 요소가 서비스에 바인딩될 때 시스템에서 이 메서드를 호출합니다.
onUnbind():
🎜unbindService()를 호출하여 다른 구성 요소가 서비스에서 바인딩을 해제할 때 시스템이 이 메서드를 호출합니다. 🎜🎜onRebind(): 🎜🎜이전 구성 요소가 서비스에서 바인딩 해제되고 또 다른 새 구성 요소가 서비스에 바인딩되고 onUnbind()가 true를 반환하면 시스템이 이 메서드를 호출합니다. 🎜3、fragemnt
3.1、创建方式
(1)静态创建" >START_STICKYSTART_STICKY가 반환되면 서비스를 실행하는 프로세스가 Android 시스템에 의해 강제로 종료된 후에도 Android 시스템이 서비스를 계속 시작된 상태로 설정한다는 의미입니다(예: onStartCommand 메소드에 의해 전달된 인텐트 객체를 저장하면 Android 시스템은 서비스를 다시 생성하고 onStartCommand 콜백 메소드를 실행하려고 시도하지만 onStartCommand 콜백 메소드의 Intent 매개변수는 null입니다. 즉, onStartCommand 메소드가 실행되더라도 인텐트 정보를 얻을 수 없습니다. 서비스가 언제든지 문제 없이 실행되거나 종료될 수 있고 인텐트 정보가 필요하지 않은 경우 onStartCommand 메소드에서 START_STICKY를 반환할 수 있습니다. 예를 들어 배경 음악을 재생하는 데 사용되는 서비스는 이 값을 반환하는 데 적합합니다.
START_REDELIVER_INTENTSTART_REDELIVER_INTENT가 반환되면 서비스를 실행하는 프로세스가 Android 시스템에 의해 강제로 종료된 후 START_STICKY를 반환하는 경우와 유사하게 Android 시스템이 다시 서비스하고 onStartCommand 콜백 메소드를 실행합니다. 그러나 차이점은 Android 시스템이 서비스가 종료되기 전에 onStartCommand 메소드에 전달된 마지막 인텐트를 유지하고 이를 다시 생성된 서비스의 onStartCommand 메소드에 전달하므로 인텐트 매개변수 읽을 수 있습니다. START_REDELIVER_INTENT가 반환되는 한 onStartCommand의 인텐트는 null이 아니어야 합니다. 서비스가 실행하기 위해 특정 인텐트에 의존해야 하고(인텐트 등에서 관련 데이터 정보를 읽어야 함) 강제 삭제 후 이를 다시 생성해야 하는 경우 해당 서비스는 START_REDELIVER_INTENT를 반환하는 데 적합합니다.
onBind
Service의 onBind 메소드는 추상 메소드이므로 Service 클래스 자체도 추상 클래스입니다. 즉, onBind 메소드를 사용하지 않더라도 다시 작성해야 합니다. startService를 통해 Service를 사용하는 경우 onBind 메서드를 재정의할 때 null만 반환하면 됩니다. onBind 메소드는 주로 BindService 메소드에 대해 Service를 호출할 때 사용됩니다.
onDestroy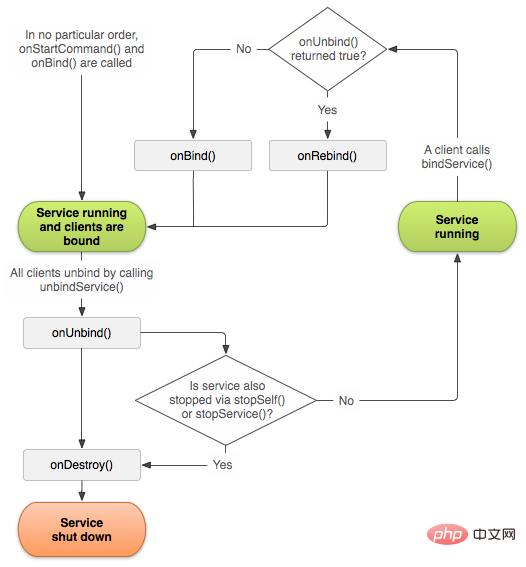
onDestroy: startService 메소드를 통해 시작된 서비스는 Context의 StopService가 호출되거나 서비스 내에서 stopSelf 메소드가 호출되는 경우에만 서비스가 중지되고 파기됩니다. 서비스 콜백 기능이 실행됩니다.
2.3.BindService 생명주기
bindService를 통해 서비스를 시작하는 것은 주로 다음과 같은 생명주기 기능을 가지고 있습니다:
onCreate():
서비스가 처음 생성될 때 시스템은 이 메소드를 호출합니다. 서비스가 이미 실행 중인 경우 이 메서드는 호출되지 않고 한 번만 호출됩니다.
onStartCommand():
이 메서드는 다른 구성 요소가 startService()를 호출하여 서비스 시작을 요청할 때 시스템에서 호출됩니다.
onDestroy():
이 메소드는 서비스가 더 이상 사용되지 않을 때 시스템에 의해 호출되어 폐기됩니다.
onBind():
bindService()를 호출하여 다른 구성 요소가 서비스에 바인딩될 때 시스템에서 이 메서드를 호출합니다.
onUnbind():
🎜unbindService()를 호출하여 다른 구성 요소가 서비스에서 바인딩을 해제할 때 시스템이 이 메서드를 호출합니다. 🎜🎜onRebind(): 🎜🎜이전 구성 요소가 서비스에서 바인딩 해제되고 또 다른 새 구성 요소가 서비스에 바인딩되고 onUnbind()가 true를 반환하면 시스템이 이 메서드를 호출합니다. 🎜3、fragemnt
3.1、创建方式
(1)静态创建

안드로이드 면접 질문의 가장 상세한 공유

기본 Android 지식 포인트
1. Android 클래스 로더
Android 개발에서 플러그인 기반이든 컴포넌트 기반이든 안드로이드 시스템의 ClassLoader를 기반으로 설계되었습니다. 단지 안드로이드 플랫폼의 가상머신이 클래스 파일을 최적화한 결과물인 Dex 바이트코드를 실행한다는 점일 뿐입니다. 기존 클래스 파일은 .class 파일을 생성하는 Java 소스 코드 파일인 반면, 안드로이드는 모든 클래스 파일을 병합하고 최적화합니다. 최종 class.dex를 생성합니다. 목적은 서로 다른 클래스 파일에 중복된 항목을 하나만 유지하는 것입니다. 초기 Android 애플리케이션 개발에서 Android 애플리케이션이 dex로 분할되지 않은 경우 마지막 애플리케이션의 apk는 dex 파일이 있을 겁니다.
Android에는 DexClassLoader와 PathClassLoader라는 두 가지 일반적으로 사용되는 클래스 로더가 있으며 둘 다 BaseDexClassLoader에서 상속됩니다. 차이점은 상위 클래스 생성자를 호출할 때 DexClassLoader가 추가로optimizedDirectory 매개변수를 전달한다는 것입니다. 이 디렉터리는 내부 저장소 경로여야 하며 시스템에서 생성된 Dex 파일을 캐시하는 데 사용됩니다. PathClassLoader의 매개변수는 null이며 내부 저장소 디렉터리의 Dex 파일만 로드할 수 있습니다. 따라서 DexClassLoader를 사용하여 많은 플러그인 기술의 기초이기도 한 외부 apk 파일을 로드할 수 있습니다.
 2. 서비스
2. 서비스
Android 서비스를 이해하는 것은 다음과 같은 측면에서 이해할 수 있습니다.
서비스는 메인 스레드에서 실행되며 시간이 많이 걸리는 작업(네트워크 요청, 데이터베이스 복사, 대용량 파일)은 수행할 수 없습니다. 서비스 ).- 서비스가 다른 프로세스에서 실행될 수 있도록 서비스가 xml에 있는 프로세스를 설정할 수 있습니다.
- Service에서 수행하는 작업은 최대 20초, BroadcastReceiver는 10초, Activity는 5초입니다.
- Activity는 BindService(Intent, ServiceConnection, 플래그)를 통해 Service에 바인딩됩니다.
- Activity는 startService 및 BindService를 통해 서비스를 시작할 수 있습니다.
- IntentService
IntentService는 ServiceHandler(Handler) 및 HandlerThread(Thread)가 내부에 포함된 Service에서 상속된 추상 클래스입니다. IntentService는 비동기 요청을 처리하는 클래스입니다. IntentService에는 시간이 많이 걸리는 작업을 처리하기 위한 작업자 스레드(HandlerThread)가 있습니다. IntentService를 시작하는 방법은 일반적인 것과 동일하지만 작업이 완료되면 IntentService가 자동으로 중지됩니다. 또한 IntentService는 여러 번 시작될 수 있습니다. 시간이 많이 걸리는 각 작업은 작업 대기열 형태로 IntentService의 onHandleIntent 콜백에서 실행되며 매번 하나의 작업자 스레드가 실행됩니다. IntentService의 핵심은 HandlerThread 및 Handler를 캡슐화하는 비동기 프레임워크입니다.
2.1. 수명주기 다이어그램
서비스는 Android의 4가지 주요 구성 요소 중 하나이며 널리 사용됩니다. Activity와 마찬가지로 Service에도 아래 그림과 같이 일련의 수명 주기 콜백 함수가 있습니다.
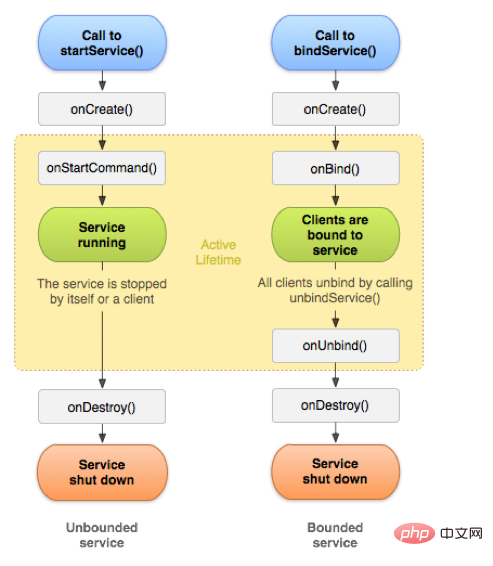 보통 서비스를 시작하는 방법에는 startService와bindService의 두 가지 방법이 있습니다.
보통 서비스를 시작하는 방법에는 startService와bindService의 두 가지 방법이 있습니다.
2.2.startService 수명주기
Context의 startService 메소드를 호출하면 서비스가 시작됩니다. startService 메소드에 의해 시작된 서비스는 외부 또는 서비스 내부에서 계속 실행됩니다. 서비스의 stopSelf 메소드가 호출되면 서비스 실행이 중지되고 폐기됩니다.
onCreate
onCreate: startService 메소드 실행 시 서비스가 실행 중이 아닌 경우 서비스가 생성되고 서비스가 이미 실행 중인 경우 서비스의 onCreate 콜백 메소드가 실행되며 startService 메소드 실행은 실행되지 않습니다. 서비스의 onCreate 메소드. 즉, Service를 시작하기 위해 Context의 startService 메소드를 여러 번 실행하면 Service 메소드의 onCreate 메소드는 Service가 처음 생성될 때 한 번만 호출되고 이후에는 다시 호출되지 않습니다. 미래. onCreate 메소드에서 일부 서비스 초기화 관련 작업을 완료할 수 있습니다.
onStartCommand
onStartCommand: startService 메소드를 실행한 후 서비스의 onCreate 메소드가 호출될 수 있으며, 그 후에는 서비스의 onStartCommand 콜백 메소드가 반드시 실행됩니다. 즉, Context의 startService 메소드가 여러 번 실행되면 그에 따라 Service의 onStartCommand 메소드도 여러 번 호출됩니다. onStartCommand 메소드는 매우 중요합니다. 이 메소드에서는 들어오는 Intent 매개변수를 기반으로 실제 작업을 수행합니다. 예를 들어 데이터를 다운로드하거나 음악을 재생하는 등의 스레드가 생성됩니다.
public @StartResult int onStartCommand(Intent intent, @StartArgFlags int flags, int startId) {
}Android에서 메모리 부족이 발생하면 현재 실행 중인 서비스가 파괴될 수 있으며, 메모리가 충분할 때 서비스가 다시 생성될 수 있습니다. 서비스가 강제로 파괴되고 다시 생성되는 동작은 Android 시스템에 따라 다릅니다. 서비스 값에 onStartCommand 메소드가 반환될 때. 일반적으로 사용되는 세 가지 반환 값은 START_NOT_STICKY, START_STICKY 및 START_REDELIVER_INTENT입니다. 이 세 가지 값은 서비스의 정적 상수입니다. START_NOT_STICKY、START_STICKY和START_REDELIVER_INTENT,这三个值都是Service中的静态常量。
START_NOT_STICKY
如果返回START_NOT_STICKY,表示当Service运行的进程被Android系统强制杀掉之后,不会重新创建该Service,当然如果在其被杀掉之后一段时间又调用了startService,那么该Service又将被实例化。那什么情境下返回该值比较恰当呢?如果我们某个Service执行的工作被中断几次无关紧要或者对Android内存紧张的情况下需要被杀掉且不会立即重新创建这种行为也可接受,那么我们便可将 onStartCommand的返回值设置为START_NOT_STICKY。举个例子,某个Service需要定时从服务器获取最新数据:通过一个定时器每隔指定的N分钟让定时器启动Service去获取服务端的最新数据。当执行到Service的onStartCommand时,在该方法内再规划一个N分钟后的定时器用于再次启动该Service并开辟一个新的线程去执行网络操作。假设Service在从服务器获取最新数据的过程中被Android系统强制杀掉,Service不会再重新创建,这也没关系,因为再过N分钟定时器就会再次启动该Service并重新获取数据。
START_STICKY
如果返回START_STICKY,表示Service运行的进程被Android系统强制杀掉之后,Android系统会将该Service依然设置为started状态(即运行状态),但是不再保存onStartCommand方法传入的intent对象,然后Android系统会尝试再次重新创建该Service,并执行onStartCommand回调方法,但是onStartCommand回调方法的Intent参数为null,也就是onStartCommand方法虽然会执行但是获取不到intent信息。如果你的Service可以在任意时刻运行或结束都没什么问题,而且不需要intent信息,那么就可以在onStartCommand方法中返回START_STICKY,比如一个用来播放背景音乐功能的Service就适合返回该值。
START_REDELIVER_INTENTSTART_NOT_STICKY
START_NOT_STICKYSTART_NOT_STICKY가 반환되면 서비스를 실행하는 프로세스가 Android 시스템에 의해 강제로 종료되면 서비스가 다시 생성되지 않는다는 의미입니다. 일정 시간이 지나면 다시 종료됩니다. startService가 호출되면 서비스가 인스턴스화됩니다. 그렇다면 어떤 상황에서 이 값을 반환하는 것이 적절한가요? 서비스 중 하나가 수행한 작업이 몇 번이나 중단되었는지 또는 Android 메모리가 부족할 때 서비스를 종료하고 즉시 다시 생성하지 않아야 하는지가 중요하지 않은 경우 이 동작은 허용되며 다음의 반환 값을 설정할 수 있습니다. onStartCommand를 START_NOT_STICKY로 설정합니다. 예를 들어 서비스는 정기적으로 서버에서 최신 데이터를 가져와야 합니다. 서버에서 최신 데이터를 얻으려면 타이머를 사용하여 지정된 N분마다 서비스를 시작해야 합니다. 서비스의 onStartCommand가 실행되면 이 메소드에서는 서비스를 다시 시작하고 새 스레드를 열어 네트워크 작업을 수행하기 위해 N분 동안 타이머가 계획됩니다. 서버에서 최신 데이터를 가져오는 과정에서 Android 시스템에 의해 서비스가 강제로 종료된다고 가정하면 타이머가 서비스를 다시 시작하고 다시 가져오기 때문에 서비스가 다시 생성되지 않습니다. N분 후 데이터입니다.
START_STICKYSTART_STICKY가 반환되면 서비스를 실행하는 프로세스가 Android 시스템에 의해 강제로 종료된 후에도 Android 시스템이 서비스를 계속 시작된 상태로 설정한다는 의미입니다(예: onStartCommand 메소드에 의해 전달된 인텐트 객체를 저장하면 Android 시스템은 서비스를 다시 생성하고 onStartCommand 콜백 메소드를 실행하려고 시도하지만 onStartCommand 콜백 메소드의 Intent 매개변수는 null입니다. 즉, onStartCommand 메소드가 실행되더라도 인텐트 정보를 얻을 수 없습니다. 서비스가 언제든지 문제 없이 실행되거나 종료될 수 있고 인텐트 정보가 필요하지 않은 경우 onStartCommand 메소드에서 START_STICKY를 반환할 수 있습니다. 예를 들어 배경 음악을 재생하는 데 사용되는 서비스는 이 값을 반환하는 데 적합합니다.
START_REDELIVER_INTENTSTART_REDELIVER_INTENT가 반환되면 서비스를 실행하는 프로세스가 Android 시스템에 의해 강제로 종료된 후 START_STICKY를 반환하는 경우와 유사하게 Android 시스템이 다시 서비스하고 onStartCommand 콜백 메소드를 실행합니다. 그러나 차이점은 Android 시스템이 서비스가 종료되기 전에 onStartCommand 메소드에 전달된 마지막 인텐트를 유지하고 이를 다시 생성된 서비스의 onStartCommand 메소드에 전달하므로 인텐트 매개변수 읽을 수 있습니다. START_REDELIVER_INTENT가 반환되는 한 onStartCommand의 인텐트는 null이 아니어야 합니다. 서비스가 실행하기 위해 특정 인텐트에 의존해야 하고(인텐트 등에서 관련 데이터 정보를 읽어야 함) 강제 삭제 후 이를 다시 생성해야 하는 경우 해당 서비스는 START_REDELIVER_INTENT를 반환하는 데 적합합니다.
onBind
Service의 onBind 메소드는 추상 메소드이므로 Service 클래스 자체도 추상 클래스입니다. 즉, onBind 메소드를 사용하지 않더라도 다시 작성해야 합니다. startService를 통해 Service를 사용하는 경우 onBind 메서드를 재정의할 때 null만 반환하면 됩니다. onBind 메소드는 주로 BindService 메소드에 대해 Service를 호출할 때 사용됩니다.
onDestroy
onDestroy: startService 메소드를 통해 시작된 서비스는 Context의 StopService가 호출되거나 서비스 내에서 stopSelf 메소드가 호출되는 경우에만 서비스가 중지되고 파기됩니다. 서비스 콜백 기능이 실행됩니다.
2.3.BindService 생명주기
bindService를 통해 서비스를 시작하는 것은 주로 다음과 같은 생명주기 기능을 가지고 있습니다:
onCreate():
서비스가 처음 생성될 때 시스템은 이 메소드를 호출합니다. 서비스가 이미 실행 중인 경우 이 메서드는 호출되지 않고 한 번만 호출됩니다.
onStartCommand():
이 메서드는 다른 구성 요소가 startService()를 호출하여 서비스 시작을 요청할 때 시스템에서 호출됩니다.
onDestroy():
이 메소드는 서비스가 더 이상 사용되지 않을 때 시스템에 의해 호출되어 폐기됩니다.
onBind():
bindService()를 호출하여 다른 구성 요소가 서비스에 바인딩될 때 시스템에서 이 메서드를 호출합니다.
onUnbind():
🎜unbindService()를 호출하여 다른 구성 요소가 서비스에서 바인딩을 해제할 때 시스템이 이 메서드를 호출합니다. 🎜🎜onRebind(): 🎜🎜이전 구성 요소가 서비스에서 바인딩 해제되고 또 다른 새 구성 요소가 서비스에 바인딩되고 onUnbind()가 true를 반환하면 시스템이 이 메서드를 호출합니다. 🎜3、fragemnt
3.1、创建方式
(1)静态创建
首先我们需要创建一个xml文件,然后创建与之对应的java文件,通过onCreatView()的返回方法进行关联,最后我们需要在Activity中进行配置相关参数即在Activity的xml文件中放上fragment的位置。
<fragment
android:name="xxx.BlankFragment"
android:layout_width="match_parent"
android:layout_height="match_parent">
</fragment>(2)动态创建
动态创建Fragment主要有以下几个步骤:
- 创建待添加的fragment实例。
- 获取FragmentManager,在Activity中可以直接通过调用 getSupportFragmentManager()方法得到。
- 开启一个事务,通过调用beginTransaction()方法开启。
- 向容器内添加或替换fragment,一般使用repalce()方法实现,需要传入容器的id和待添加的fragment实例。
- 提交事务,调用commit()方法来完成。
3.2、Adapter对比
FragmnetPageAdapter在每次切换页面时,只是将Fragment进行分离,适合页面较少的Fragment使用以保存一些内存,对系统内存不会多大影响。
FragmentPageStateAdapter在每次切换页面的时候,是将Fragment进行回收,适合页面较多的Fragment使用,这样就不会消耗更多的内存
3.3、Activity生命周期
Activity的生命周期如下图: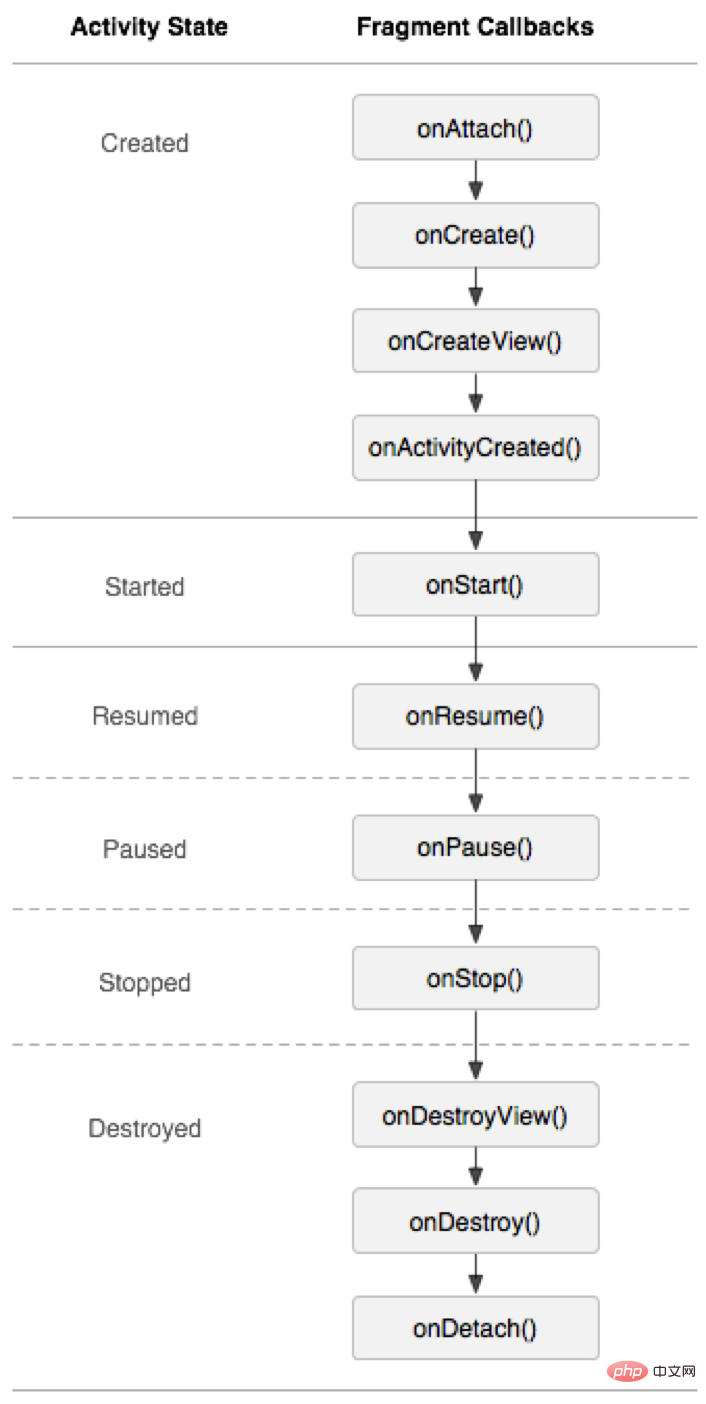
(1)动态加载:
动态加载时,Activity的onCreate()调用完,才开始加载fragment并调用其生命周期方法,所以在第一个生命周期方法onAttach()中便能获取Activity以及Activity的布局的组件;
(2)静态加载:
1.静态加载时,Activity的onCreate()调用过程中,fragment也在加载,所以fragment无法获取到Activity的布局中的组件,但为什么能获取到Activity呢?
2.原来在fragment调用onAttach()之前其实还调用了一个方法onInflate(),该方法被调用时fragment已经是和Activity相互结合了,所以可以获取到对方,但是Activity的onCreate()调用还未完成,故无法获取Activity的组件;
3.Activity的onCreate()调用完成是,fragment会调用onActivityCreated()生命周期方法,因此在这儿开始便能获取到Activity的布局的组件;
3.4、与Activity通信
fragment不通过构造函数进行传值的原因是因为横屏切换的时候获取不到值。
Activity向Fragment传值:
Activity向Fragment传值,要传的值放到bundle对象里;
在Activity中创建该Fragment的对象fragment,通过调用setArguments()传递到fragment中;
在该Fragment中通过调用getArguments()得到bundle对象,就能得到里面的值。
Fragment向Activity传值:
第一种:
在Activity中调用getFragmentManager()得到fragmentManager,,调用findFragmentByTag(tag)或者通过findFragmentById(id),例如:
FragmentManager fragmentManager = getFragmentManager(); Fragment fragment = fragmentManager.findFragmentByTag(tag);
第二种:
通过回调的方式,定义一个接口(可以在Fragment类中定义),接口中有一个空的方法,在fragment中需要的时候调用接口的方法,值可以作为参数放在这个方法中,然后让Activity实现这个接口,必然会重写这个方法,这样值就传到了Activity中
Fragment与Fragment之间是如何传值的:
第一种:
通过findFragmentByTag得到另一个的Fragment的对象,这样就可以调用另一个的方法了。
第二种:
通过接口回调的方式。
第三种:
通过setArguments,getArguments的方式。
3.5、api区别
add
一种是add方式来进行show和add,这种方式你切换fragment不会让fragment重新刷新,只会调用onHiddenChanged(boolean isHidden)。
replace
而用replace方式会使fragment重新刷新,因为add方式是将fragment隐藏了而不是销毁再创建,replace方式每次都是重新创建。
commit/commitAllowingStateLoss
两者都可以提交fragment的操作,唯一的不同是第二种方法,允许丢失一些界面的状态和信息,几乎所有的开发者都遇到过这样的错误:无法在activity调用了onSaveInstanceState之后再执行commit(),这种异常时可以理解的,界面被系统回收(界面已经不存在),为了在下次打开的时候恢复原来的样子,系统为我们保存界面的所有状态,这个时候我们再去修改界面理论上肯定是不允许的,所以为了避免这种异常,要使用第二种方法。
3. 지연 로딩
프래그먼트를 자주 사용하면 뷰페이저와 함께 사용하는 경우가 많습니다. 그러면 프래그먼트를 초기화할 때 우리가 작성한 네트워크 요청과 함께 실행되는 문제가 발생합니다. 매우 많은 성능을 소모하므로 가장 이상적인 방법은 사용자가 현재 조각을 클릭하거나 슬라이드할 때만 네트워크를 요청하는 것입니다. 그래서 우리는 게으른 로딩이라는 용어를 생각해 냈습니다.
Viewpager는 조각과 함께 사용되며 처음 두 조각은 기본적으로 로드됩니다. 네트워크 패킷 손실, 혼잡 등의 문제가 발생하기 쉽습니다.
Fragment에는 setUserVisibleHint 메소드가 있는데, 이 메소드는 onCreate() 메소드보다 낫습니다. isVisibleToUser를 통해 현재 Fragment가 표시되는지 여부를 알려주고, 표시되면 네트워크를 다시 로드할 수 있습니다.
onCreateView보다 먼저 setUserVisibleHint()가 호출된 것을 로그에서 볼 수 있으므로, setUserVisibleHint()에서 지연 로딩을 구현하려면 null 포인터를 방지하기 위해 View 및 기타 변수가 초기화되었는지 확인해야 합니다.
사용 단계:
현재 페이지가 생성되었는지 여부를 나타내는 변수 isPrepare=false, isVisible=false를 선언합니다.
onViewCreated 주기 중에 isPrepare=true를 설정합니다.
setUserVisibleHint(부울 isVisible)를 사용하여 표시 여부를 결정하고 isVisible을 설정합니다. =true
isPrepare 및 isVisible을 모두 true로 판단하여 데이터 로드를 시작한 다음, isPrepare 및 isVisible을 false로 복원하여 반복 로드를 방지합니다.
Android Fragment의 지연 로딩에 대해서는 다음 링크를 참조할 수 있습니다: Lazy loading of Fragment
4, Activity
4.1, Activity start process
사용자는 Launcher 프로그램에서 애플리케이션 아이콘을 클릭하여 애플리케이션을 시작합니다. 항목 활동. 활동이 시작되면 여러 프로세스 간의 상호 작용이 필요합니다. Android 시스템에는 Android 프레임워크 계층 및 애플리케이션 계층 프로그램의 프로세스를 인큐베이션하는 전용 프로세스가 있습니다. 많은 바인더 서비스를 실행하는 system_server 프로세스도 있습니다. 예를 들어 ActivityManagerService, PackageManagerService, WindowManagerService와 같은 바인더 서비스는 각각 다른 스레드에서 실행되며, 그중 ActivityManagerService는 활동 스택, 애플리케이션 프로세스 및 작업을 관리하는 역할을 담당합니다.
런처 아이콘을 클릭하여 액티비티를 시작하세요
사용자가 런처 프로그램에서 애플리케이션 아이콘을 클릭하면 ActivityManagerService가 애플리케이션의 항목 활동을 시작하라는 알림을 받게 됩니다. Zygote 프로세스에 응용 프로그램 프로세스를 부화하도록 알리고 ActivityThread의 기본 메서드는 dalvik 응용 프로그램 프로세스에서 실행됩니다. 다음으로 애플리케이션 프로세스는 애플리케이션 프로세스가 시작되었음을 ActivityManagerService에 알립니다. ActivityManagerService는 이 프록시 개체를 통해 애플리케이션 프로세스를 제어할 수 있도록 애플리케이션 프로세스에 항목 Activity의 인스턴스를 생성하도록 알립니다. 라이프 사이클 방법을 실행합니다.
안드로이드 그리기 프로세스 창 시작 프로세스 분석
4.2, Activity lifecycle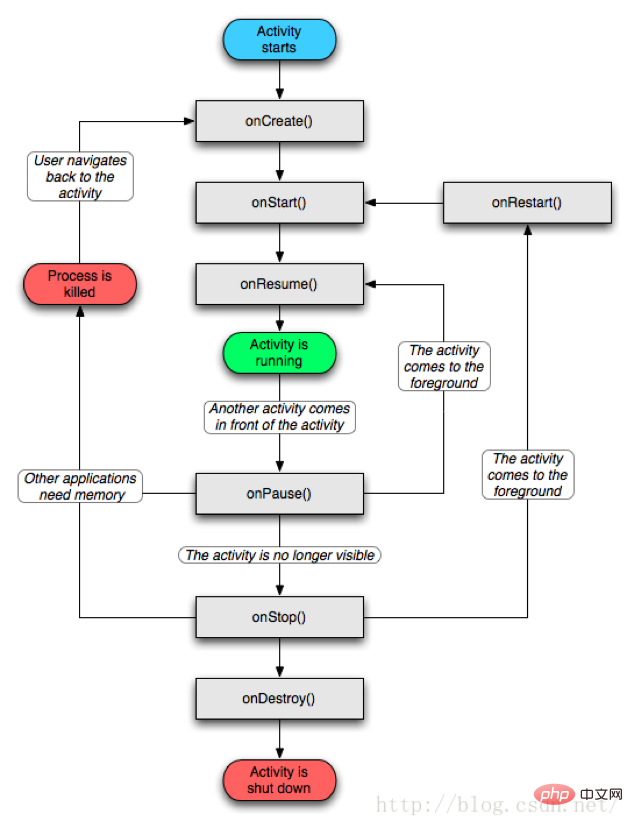
(1) Activity form
Active/Running:
Activity는 활성 상태입니다. 스택에 표시되며 사용자와 상호 작용할 수 있습니다.
일시 중지됨:
활동이 포커스를 잃거나 전체 화면이 아닌 새로운 활동 또는 투명한 활동에 의해 스택 맨 위에 배치되면 해당 활동은 일시 중지됨 상태로 변환됩니다. 그러나 현재 Activity는 사용자와 상호 작용하는 기능만 상실했으며 모든 상태 정보와 멤버 변수는 여전히 존재한다는 점을 이해해야 합니다. 시스템 메모리가 부족할 때만 시스템에서 재활용할 수 있습니다.
Stopped:
Activity가 다른 Activity에 의해 완전히 덮이면 해당 Activity는 Stopped 상태가 됩니다. 이때 더 이상 표시되지 않지만 Paused 상태와 같은 모든 상태 정보 및 멤버 변수가 유지됩니다.
Killed:
활동이 시스템에 의해 재활용되면 활동은 Killed 상태가 됩니다.
활동은 위의 네 가지 형태 간에 전환됩니다. 전환 방법은 사용자의 작업에 따라 다릅니다. Activity의 네 가지 형태를 이해한 후 Activity의 수명주기에 대해 이야기해 보겠습니다.
Activity 생명주기
소위 전형적인 생명주기는 사용자 참여로 Activity가 생성, 실행, 중지, 소멸의 정상적인 생명주기 과정을 겪는다는 것입니다.
onCreate
이 메서드는 활동이 생성될 때 다시 호출됩니다. 이는 일반적으로 활동을 생성할 때 이 메서드를 재정의한 다음 이 메서드에서 몇 가지 초기화 작업을 수행해야 합니다. 예를 들어, setContentView를 통해 인터페이스 레이아웃 리소스를 설정하고, 필요한 컴포넌트 정보를 초기화하는 등의 작업을 수행합니다.
onStart
이 메서드가 다시 호출되면 Activity가 이미 시작되고 있지만 아직 포그라운드에 표시되지 않았으므로 사용자와 상호 작용할 수 없다는 의미입니다. 활동이 표시되었지만 볼 수 없다는 것을 간단히 이해할 수 있습니다.
onResume
이 메서드가 다시 호출되면 활동이 포그라운드에 표시되고 사용자와 상호 작용할 수 있음을 의미합니다(앞에서 언급한 활성/실행 중 상태). onResume 메서드와 onStart 사이의 동일한 점은 둘 다입니다. 그러나 onStart가 콜백되면 Activity는 여전히 백그라운드에 있으므로 사용자와 상호 작용할 수 없지만 onResume은 이미 포그라운드에 표시되어 사용자와 상호 작용할 수 있습니다. 물론, 흐름도를 보면 Activity가 중지되면(onPause 메서드 및 onStop 메서드 호출) 전경으로 돌아갈 때 onResume 메서드도 호출되므로 onResume에서 일부 리소스를 초기화할 수도 있음을 알 수 있습니다. onPause 또는 onStop 메서드에서 해제된 리소스를 다시 초기화하는 등의 메서드입니다.
onPause
이 메서드가 다시 호출되면 활동이 중지 중(일시 중지된 상태)임을 의미합니다. 일반적인 상황에서는 onStop 메서드가 즉시 다시 호출됩니다. 하지만 흐름도를 보면 onPause 메서드가 실행된 후 바로 onResume 메서드가 실행되는 상황도 볼 수 있습니다. 이는 상대적으로 극단적인 현상으로 현재 Activity가 후퇴하게 된 것일 수 있습니다. 현재 활동의 경우 이 시점에서 onResume 메소드가 다시 호출됩니다. 물론 onPause 메서드에서는 일부 데이터 저장이나 애니메이션 중지 또는 리소스 재활용 작업을 수행할 수 있지만 시간이 너무 많이 걸려서는 안 됩니다. 왜냐하면 이것이 새 Activity의 표시에 영향을 미칠 수 있기 때문입니다. onPause 메서드가 실행된 후 새로운 Activity 메소드의 onResume이 실행됩니다.
onStop
은 일반적으로 onPause 메서드가 완료된 직후에 실행되며, 이는 활동이 곧 중지되거나 완전히 덮였음을 나타냅니다(중지된 형식). 이때 활동은 보이지 않으며 백그라운드에서만 실행됩니다. 마찬가지로 일부 리소스 해제 작업은 onStop 메서드에서 수행할 수 있습니다(시간이 많이 걸리지 않음).
onRestart
는 활동이 다시 시작되고 있음을 나타냅니다. 활동이 표시되지 않음에서 표시로 변경되면 이 메서드가 다시 호출됩니다. 이 상황은 일반적으로 사용자가 새 활동을 열 때 현재 활동이 일시 중지되고(onPause 및 onStop이 실행됨) 사용자가 현재 활동 페이지로 돌아갈 때 onRestart 메서드가 다시 호출되는 경우입니다.
onDestroy
이때 Activity가 소멸되고 있으며, Life Cycle에서 실행되는 마지막 메서드이기도 합니다. 일반적으로 이 방법으로 일부 재활용 작업과 최종 리소스 방출을 수행할 수 있습니다.
Summary
여기서 요약을 살펴보겠습니다. Activity가 시작되면 onCreate(), onStart(), onResume()이 차례로 호출되고 Activity가 백그라운드로 물러날 때(보이지 않거나 Home을 클릭하거나 교체됨) 새로운 Activity Complete Coverage에 의해) onPause() 및 onStop()이 순차적으로 호출됩니다. Activity가 포그라운드로 돌아가면(데스크톱에서 원래 Activity로 돌아가거나 덮어쓴 후 원래 Activity로 돌아가는 경우) onRestart(), onStart(), onResume()이 차례로 호출됩니다. Activity가 종료되어 소멸되면(뒤로 버튼 클릭) onPause(), onStop(), onDestroy()가 차례로 호출됩니다. 이 시점에서 Activity의 전체 수명 주기 메서드 콜백이 완료됩니다. 이제 이전 흐름도를 다시 살펴보면 매우 명확해집니다. 글쎄, 이것은 활동의 전체 일반적인 수명주기 프로세스입니다.
2. View 지식 포인트
Android의 Activity, PhoneWindow 및 DecorView 간의 관계는 다음 다이어그램으로 나타낼 수 있습니다. 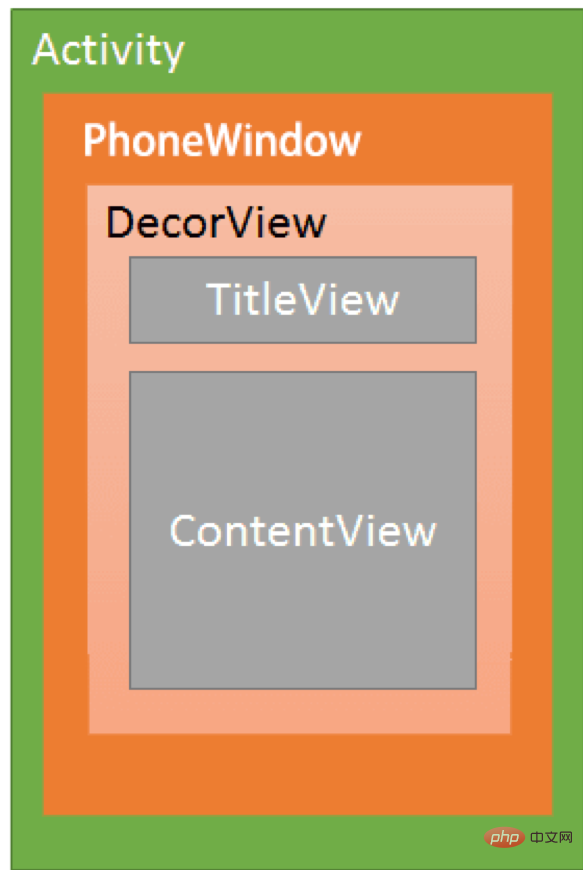
2.1 DecorView에 대한 간략한 분석
예를 들어 다음과 같은 뷰가 있습니다. 전체 Window 인터페이스입니다. 최상위 뷰에는 LinearLayout이라는 하나의 하위 요소만 있습니다. 알림 표시줄, 제목 표시줄, 콘텐츠 표시 표시줄을 포함한 전체 Window 인터페이스를 나타냅니다. LinearLayout에는 두 개의 FrameLayout 하위 요소가 있습니다. 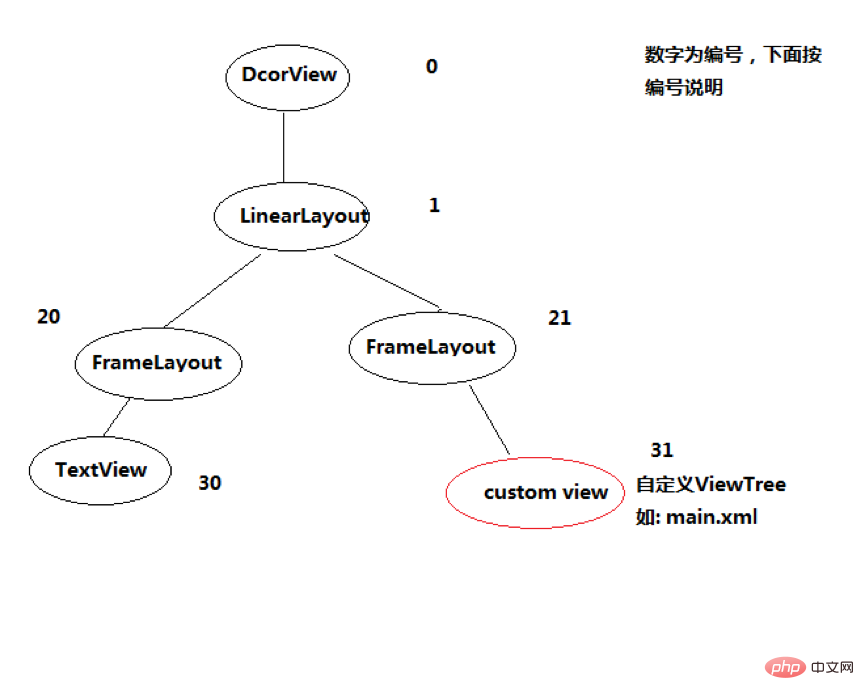
DecorView의 역할
DecorView는 기본적으로 FrameLayout인 최상위 뷰입니다. 여기에는 제목 표시줄과 콘텐츠 표시줄의 두 부분이 포함되어 있으며 둘 다 FrameLayout입니다. 콘텐츠 열 ID는 setContentView가 설정된 활동의 일부인 콘텐츠입니다. 마지막으로 레이아웃은 콘텐츠 ID로 FrameLayout에 추가됩니다.
콘텐츠 가져오기: ViewGroup 콘텐츠=findViewById(android.id.content)
뷰 설정 가져오기: getChildAt(0).
사용 요약
각 활동에는 Window 개체가 포함되어 있으며 Window 개체는 일반적으로 PhoneWindow에 의해 구현됩니다.
PhoneWindow: Window의 구현 클래스인 전체 애플리케이션 창의 루트 뷰로 DecorView를 설정합니다. Android의 가장 기본적인 윈도우 시스템입니다. 각 활동은 활동과 전체 뷰 시스템 간의 상호 작용을 위한 인터페이스인 PhoneWindow 개체를 생성합니다.
DecorView: PhoneWindow에 표시될 특정 콘텐츠를 표시하는 최상위 뷰입니다. DecorView는 현재 활동에 있는 모든 뷰의 조상입니다.
2.2. View의 이벤트 배포
View의 이벤트 배포 메커니즘은 다음 그림으로 표현할 수 있습니다. 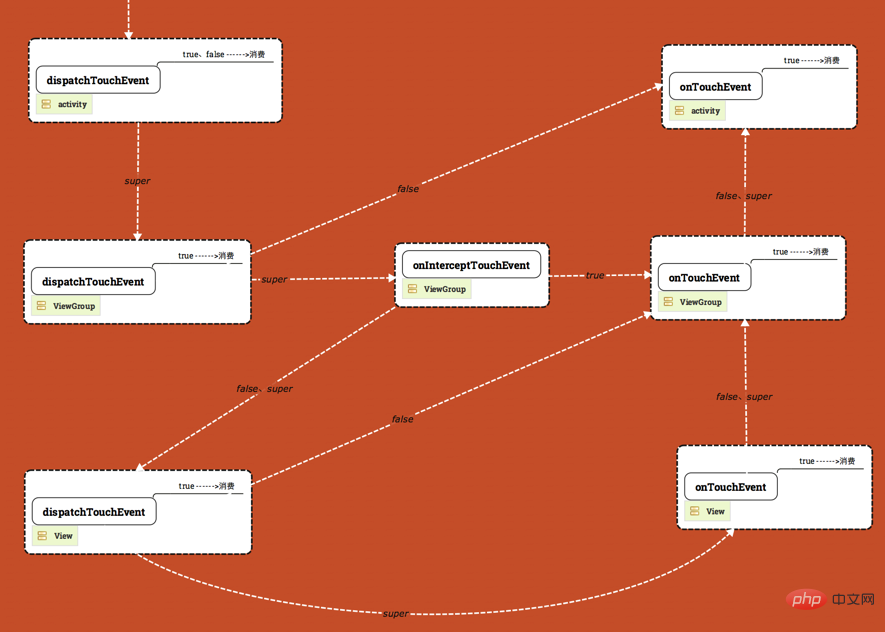
위 그림과 같이 그림은 위에서 아래로 Activity, ViewGroup, View의 3개 레이어로 구분됩니다. .
- 이벤트는 왼쪽 상단의 흰색 화살표에서 시작하여 Activity의 dispatchTouchEvent에 의해 배포됩니다.
- 화살표 위의 단어는 메소드 반환 값을 나타냅니다. (return true, return false, return super.xxxxx(), super
는 - dispatchTouchEvent 및 onTouchEvent 상자에 [true---->Consumption]이라는 단어가 있는데, 이는 메서드가 true를 반환하면 해당 이벤트가 소비되고 소비되지 않는다는 의미입니다.
- 현재 그래프의 모든 이벤트는 ACTION_MOVE 및 ACTION_UP에 대한 최종 분석을 수행합니다. 수정됨), return super.dispatchTouchEvent(ev).)만 내려가면 true 또는 false를 반환하고 이벤트가 소비됩니다(전송 종료).
생성되면 전달 프로세스는 다음 순서를 따릅니다.
Activity -> Window -> View
이벤트는 항상 Activity로 전달된 다음 Activity는 Window로 전달되고 마지막으로 Window는 최상위 뷰로 전달됩니다. 이벤트를 수신한 후 최상위 뷰는 이벤트 배포 메커니즘에 따라 이벤트를 배포합니다. 뷰의 onTouchEvent가 FALSE를 반환하면 해당 상위 컨테이너의 onTouchEvent가 호출되고, 그 중 어느 것도 이 이벤트를 처리하지 않습니다.
ViewGroup의 이벤트 배포 프로세스는 아마도 다음과 같을 것입니다. 최상위 ViewGroup 차단 이벤트, 즉 onInterceptTouchEvent가 true를 반환하면 이벤트가 ViewGroup으로 전달됩니다. ViewGroup의 onTouchListener가 설정되면 onTouch가 호출되고 그렇지 않으면 onTouchEvent가 호출됩니다. 즉, 둘 다 설정되면 onTouch가 onTouchEvent를 차단하고 onClickerListener가 설정되면 onClick이 호출됩니다. 최상위 ViewGroup이 이를 가로채지 않으면 이벤트가 있는 클릭으로 이벤트가 전달됩니다. 이때 하위 뷰의 dispatchTouchEvent가 호출됩니다.
View의 이벤트 배포
dispatchTouchEvent -> ; onTouch(setOnTouchListener) -> onTouchEvent -> onClick
onTouch와 onTouchEvent
의 차이점은 모두 dispatchTouchEvent에서 호출됩니다. onTouch가 true를 반환하면 onTouchEvent가 실행되지 않습니다. 처형되지 않습니다.
2.3. 도면 보기
xml 레이아웃 파일에서 레이아웃_너비 및 레이아웃_높이 매개변수는 특정 크기를 쓸 필요가 없지만, 랩_콘텐츠 또는 일치_부모는 작성해야 합니다. 이 두 가지 설정은 실제 크기를 지정하지 않지만 화면에 그리는 뷰는 특정 너비와 높이를 가져야 합니다. 그렇기 때문에 크기를 직접 처리하고 설정해야 합니다. 물론 View 클래스는 기본 처리를 제공하지만 View 클래스의 기본 처리가 우리의 요구 사항을 충족하지 않으면 onMeasure 함수를 다시 작성해야 합니다~.
onMeasure 함수는 측정 모드와 크기를 포함하는 int 정수입니다. Int 유형 데이터는 32비트를 차지하며 Google이 구현하는 것은 int 데이터의 처음 2비트가 다양한 레이아웃 모드를 구별하는 데 사용되고 다음 30비트는 크기 데이터를 저장하는 것입니다.
onMeasure 함수의 사용법은 아래와 같습니다.
MeasureSpec에는 세 가지 측정 모드가 있습니다. 
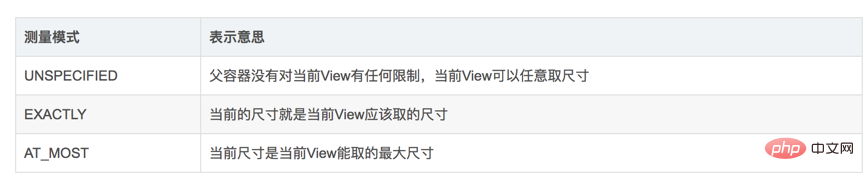 match_parent—>EXACTLY. 그것을 이해하는 방법? match_parent는 상위 View에서 제공하는 남은 공간을 모두 사용하는 것이며, 상위 View의 남은 공간을 결정하는데, 이 크기가 이 측정 모드의 정수에 저장됩니다.
match_parent—>EXACTLY. 그것을 이해하는 방법? match_parent는 상위 View에서 제공하는 남은 공간을 모두 사용하는 것이며, 상위 View의 남은 공간을 결정하는데, 이 크기가 이 측정 모드의 정수에 저장됩니다.
wrap_content—>AT_MOST. 이해하는 방법: 뷰 콘텐츠를 감싸기 위해 크기를 설정하고 싶습니다. 그러면 크기는 상위 뷰에서 참조로 제공한 크기입니다. 이 크기를 초과하지 않는 한 특정 크기는 그에 따라 설정됩니다. 우리의 필요에.
고정 크기(예: 100dp) —>정확히. 사용자가 크기를 지정하면 더 이상 간섭할 필요가 없습니다. 물론 지정된 크기가 기본 크기가 됩니다.

 2.4.ViewGroup 그리기
2.4.ViewGroup 그리기
ViewGroup을 사용자 정의하는 것은 그리 간단하지 않습니다~ 왜냐하면 ViewGroup 자체를 관리해야 할 뿐만 아니라 하위 뷰도 관리해야 하기 때문입니다. 우리 모두는 ViewGroup이 하위 뷰를 보유하고 지정된 위치에 하위 뷰를 배치하는 역할을 하는 뷰 컨테이너라는 것을 알고 있습니다.
- 우선, 각 하위 뷰의 크기를 알아야 합니다. 먼저 하위 뷰의 크기를 알아야만 현재 ViewGroup이 이를 수용할 수 있는 크기를 알 수 있습니다.
- 하위 뷰의 크기와 뷰그룹이 구현하려는 기능을 기반으로 뷰그룹의 크기를 결정하세요
ViewGroup和子View的大小算出来了之后,接下来就是去摆放了吧,具体怎么去摆放呢?这得根据你定制的需求去摆放了,比如,你想让子View按照垂直顺序一个挨着一个放,或者是按照先后顺序一个叠一个去放,这是你自己决定的。
已经知道怎么去摆放还不行啊,决定了怎么摆放就是相当于把已有的空间”分割”成大大小小的空间,每个空间对应一个子View,我们接下来就是把子View对号入座了,把它们放进它们该放的地方去。

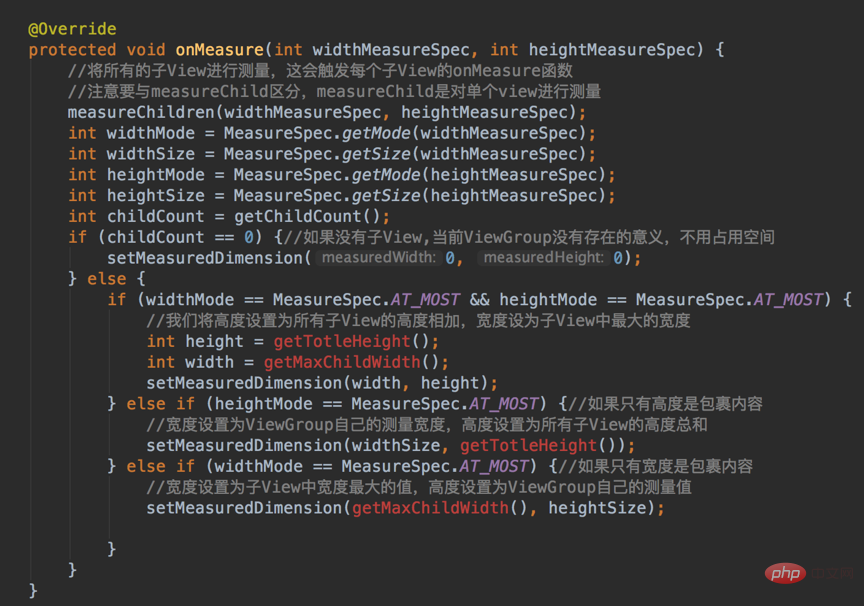

自定义ViewGroup可以参考:Android自定义ViewGroup
3、系统原理
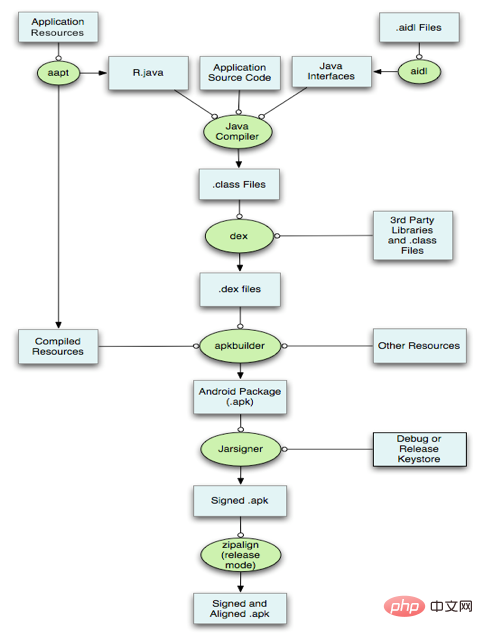
3.1、打包原理
Android的包文件APK分为两个部分:代码和资源,所以打包方面也分为资源打包和代码打包两个方面,这篇文章就来分析资源和代码的编译打包原理。
具体说来:
- 通过AAPT工具进行资源文件(包括AndroidManifest.xml、布局文件、各种xml资源等)的打包,生成R.java文件。
- 通过AIDL工具处理AIDL文件,生成相应的Java文件。
- 通过Javac工具编译项目源码,生成Class文件。
- 通过DX工具将所有的Class文件转换成DEX文件,该过程主要完成Java字节码转换成Dalvik字节码,压缩常量池以及清除冗余信息等工作。
- 通过ApkBuilder工具将资源文件、DEX文件打包生成APK文件。
- 利用KeyStore对生成的APK文件进行签名。
- 如果是正式版的APK,还会利用ZipAlign工具进行对齐处理,对齐的过程就是将APK文件中所有的资源文件举例文件的起始距离都偏移4字节的整数倍,这样通过内存映射访问APK文件的速度会更快。
3.2、安装流程
Android apk的安装过程主要氛围以下几步:
- 复制APK到/data/app目录下,解压并扫描安装包。
- 资源管理器解析APK里的资源文件。
- 解析AndroidManifest文件,并在/data/data/目录下创建对应的应用数据目录。
- 然后对dex文件进行优化,并保存在dalvik-cache目录下。
- 将AndroidManifest文件解析出的四大组件信息注册到PackageManagerService中。
- 安装完成后,发送广播。
可以使用下面的图表示: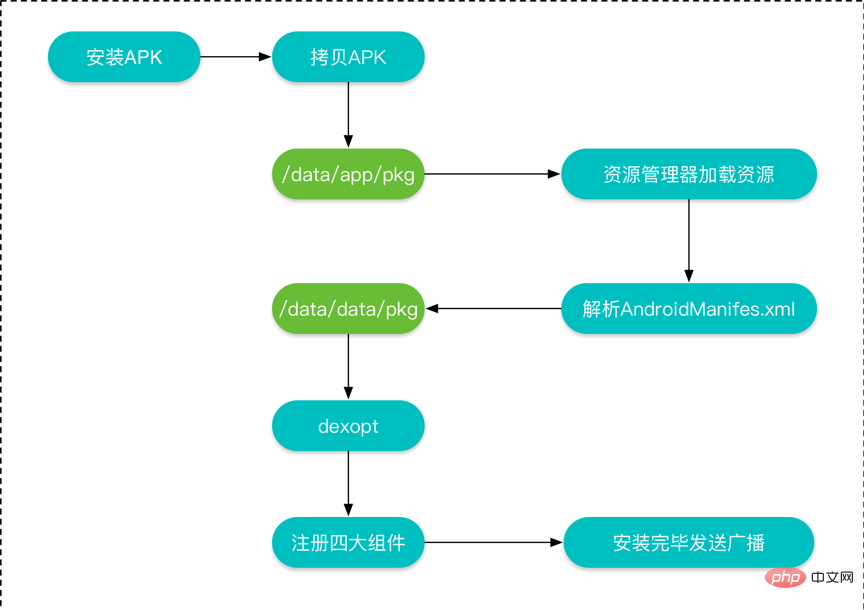
4、 第三方库解析
4.1、Retrofit网络请求框架
概念:Retrofit是一个基于RESTful的HTTP网络请求框架的封装,其中网络请求的本质是由OKHttp完成的,而Retrofit仅仅负责网络请求接口的封装。
原理:App应用程序通过Retrofit请求网络,实际上是使用Retrofit接口层封装请求参数,Header、URL等信息,之后由OKHttp完成后续的请求,在服务器返回数据之后,OKHttp将原始的结果交给Retrofit,最后根据用户的需求对结果进行解析。
retrofit使用
1.在retrofit中通过一个接口作为http请求的api接口
public interface NetApi {
@GET("repos/{owner}/{repo}/contributors")
Call<ResponseBody> contributorsBySimpleGetCall(@Path("owner") String owner, @Path("repo") String repo);
}2.创建一个Retrofit实例
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("https://api.github.com/")
.build();3.调用api接口
NetApi repo = retrofit.create(NetApi.class);
//第三步:调用网络请求的接口获取网络请求
retrofit2.Call<ResponseBody> call = repo.contributorsBySimpleGetCall("username", "path");
call.enqueue(new Callback<ResponseBody>() { //进行异步请求
@Override
public void onResponse(Call<ResponseBody> call, Response<ResponseBody> response) {
//进行异步操作
}
@Override
public void onFailure(Call<ResponseBody> call, Throwable t) {
//执行错误回调方法
}
});retrofit动态代理
retrofit执行的原理如下:
1.首先,通过method把它转换成ServiceMethod。
2.然后,通过serviceMethod,args获取到okHttpCall对象。
3.最后,再把okHttpCall进一步封装并返回Call对象。
首先,创建retrofit对象的方法如下:
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("https://api.github.com/")
.build();在创建retrofit对象的时候用到了build()方法,该方法的实现如下:
public Retrofit build() {
if (baseUrl == null) {
throw new IllegalStateException("Base URL required.");
}
okhttp3.Call.Factory callFactory = this.callFactory;
if (callFactory == null) {
callFactory = new OkHttpClient(); //设置kHttpClient
}
Executor callbackExecutor = this.callbackExecutor;
if (callbackExecutor == null) {
callbackExecutor = platform.defaultCallbackExecutor(); //设置默认回调执行器
}
// Make a defensive copy of the adapters and add the default Call adapter.
List<CallAdapter.Factory> adapterFactories = new ArrayList<>(this.adapterFactories);
adapterFactories.add(platform.defaultCallAdapterFactory(callbackExecutor));
// Make a defensive copy of the converters.
List<Converter.Factory> converterFactories = new ArrayList<>(this.converterFactories);
return new Retrofit(callFactory, baseUrl, converterFactories, adapterFactories,
callbackExecutor, validateEagerly); //返回新建的Retrofit对象
}该方法返回了一个Retrofit对象,通过retrofit对象创建网络请求的接口的方式如下:
NetApi repo = retrofit.create(NetApi.class);
retrofit对象的create()方法的实现如下:‘
public <T> T create(final Class<T> service) {
Utils.validateServiceInterface(service);
if (validateEagerly) {
eagerlyValidateMethods(service);
}
return (T) Proxy.newProxyInstance(service.getClassLoader(), new Class<?>[] { service },
new InvocationHandler() {
private final Platform platform = Platform.get();
@Override public Object invoke(Object proxy, Method method, Object... args)
throws Throwable {
// If the method is a method from Object then defer to normal invocation.
if (method.getDeclaringClass() == Object.class) {
return method.invoke(this, args); //直接调用该方法
}
if (platform.isDefaultMethod(method)) {
return platform.invokeDefaultMethod(method, service, proxy, args); //通过平台对象调用该方法
}
ServiceMethod serviceMethod = loadServiceMethod(method); //获取ServiceMethod对象
OkHttpCall okHttpCall = new OkHttpCall<>(serviceMethod, args); //传入参数生成okHttpCall对象
return serviceMethod.callAdapter.adapt(okHttpCall); //执行okHttpCall
}
});
}4.2、图片加载库对比
Picasso:120K
Glide:475K
Fresco:3.4M
Android-Universal-Image-Loader:162K
图片函数库的选择需要根据APP的具体情况而定,对于严重依赖图片缓存的APP,例如壁纸类,图片社交类APP来说,可以选择最专业的Fresco。对于一般的APP,选择Fresco会显得比较重,毕竟Fresco3.4M的体量摆在这。根据APP对图片的显示和缓存的需求从低到高,我们可以对以上函数库做一个排序。
Picasso < Android-Universal-Image-Loader < Glide < Fresco
2. 소개:
Picasso: Picasso는 네트워크 요청의 캐싱 부분을 okhttp 구현에 넘겨줄 수 있기 때문에 Square의 네트워크 라이브러리와 함께 가장 잘 작동할 수 있습니다.
Glide: Picasso의 API를 모방하고 많은 확장(예: gif 및 기타 지원)을 추가합니다. Glide의 기본 비트맵 형식은 Picasso의 기본 ARGB_8888 형식의 메모리 오버헤드의 절반입니다. 한 가지 유형이 캐시됨), Glide 캐시는 ImageView와 크기가 동일합니다(즉, 5656 및 128128은 두 개의 캐시입니다).
FB의 이미지 로딩 프레임워크 Fresco: 가장 큰 장점은 5.0(최소 2.3) 미만의 비트맵 로딩입니다. 5.0 미만의 시스템에서 Fresco는 이미지를 특수 메모리 영역(Ashmem 영역)에 배치합니다. 물론, 사진이 표시되지 않을 때는 점유된 메모리가 자동으로 해제됩니다. 이렇게 하면 앱이 더 부드러워지고 이미지 메모리 사용으로 인한 OOM이 줄어듭니다. 5.0 이하라고 하는 이유는 5.0 이후에는 시스템이 기본적으로 Ashmem 영역에 저장하기 때문입니다.
3. 요약:
Glide는 Picasso가 구현할 수 있는 모든 기능을 수행할 수 있지만 필요한 설정은 다릅니다. 그러나 Picasso의 크기는 Glide의 크기보다 훨씬 작습니다. 프로젝트 자체의 네트워크 요청이 okhttp 또는 개조를 사용하는 경우(본질은 여전히 okhttp입니다) Picasso를 사용하는 것이 좋습니다. Square 제품군 버킷). Glide의 장점은 GIF, Video 등 대용량 사진 스트림을 제공한다는 점입니다. Meipai, Aipai 등의 동영상 애플리케이션을 제작하는 경우에는 사용을 권장합니다.
Fresco의 메모리 최적화는 5.0 이하로 아주 좋은데, 가격이 너무 커서 볼륨도 엄청 큽니다. Fresco>Glide>Picasso
하지만 사용하기가 조금 불편하기도 합니다. (작은 제안: 내장형만 사용할 수 있습니다. ImageView에서) 이러한 기능을 구현하는 것이 더 번거롭습니다. 우리는 일반적으로 Fresco에 따라 수정하고 Bitmap 레이어를 직접 사용합니다.)
4.3 다양한 json 파싱 라이브러리 사용
참조 링크: https://www.cnblogs.com / kunpengit/p/4001680.html
(1) Google의 Gson
Gson은 현재 가장 다재다능한 Json 구문 분석 아티팩트입니다. Gson은 원래 Google의 내부 요구에 부응하여 Google에서 개발했지만 2008년 이후 첫 번째 버전이 공개되었습니다. 5월에는 많은 기업이나 사용자들이 이용하게 되었습니다. Gson의 애플리케이션은 주로 toJson과 fromJson의 두 가지 변환 기능으로 구성됩니다. 이는 종속성이 없으며 JDK에서 직접 실행할 수 있습니다. 이러한 종류의 개체 변환을 사용하기 전에 먼저 개체 유형과 해당 멤버를 생성해야 JSON 문자열을 해당 개체로 성공적으로 변환할 수 있습니다. 클래스에 get 및 set 메소드가 있는 한 Gson은 복잡한 유형의 json을 bean으로 또는 bean을 json으로 완전히 변환할 수 있습니다. Gson은 기능면에서는 완벽하지만 성능은 FastJson에 비해 뒤떨어집니다.
(2) Alibaba의 FastJson
Fastjson은 Alibaba에서 개발한 Java 언어로 작성된 고성능 JSON 프로세서입니다.
종속성도 없고 추가 jar도 필요 없으며 JDK에서 직접 실행할 수 있습니다. FastJson은 복잡한 유형의 Bean을 Json으로 변환할 때 몇 가지 문제가 있습니다. 참조 유형이 나타날 수 있으며 이로 인해 Json 변환 오류가 발생하고 참조를 지정해야 합니다. FastJson은 독창적인 알고리즘을 사용하여 모든 json 라이브러리를 능가하는 구문 분석 속도를 극도로 높입니다.
Json 기술 비교를 요약하자면, 프로젝트를 선택할 때 Google의 Gson과 Alibaba의 FastJson을 병행하여 사용할 수 있으며, 성능 요구 사항이 없으면 Google의 Gson을 사용할 수 있습니다. 데이터의 정확성을 보장하려면 Gson을 사용하여 Bean을 json으로 변환하고 FastJson을 사용하여 Json을 Bean으로 변환해야 합니다
5. 최신 기술
참조 링크 - Android 구성 요소화 솔루션
5.1. 개념:
구성 요소 수정: APP를 여러 모듈로 나누는 것입니다. 각 모듈은 구성 요소가 의존할 수 있는 기본 라이브러리일 수 있습니다. 서로 의존해야 하지만 서로 호출할 수 있게 되어 최종적으로 릴리즈됩니다. 이때 모든 컴포넌트는 메인 APP 프로젝트 의존성에 의해 lib 형태로 apk로 패키징됩니다.
(2) 출처:
- APP 버전이 반복되고, 새로운 기능이 지속적으로 추가되고, 비즈니스가 복잡해지고, 유지 관리 비용이 높습니다.
- 비즈니스 결합도가 높고, 코드가 비대하며, 팀 내 여러 사람이 공동 개발하기 어려움
- Android 컴파일 코드 지연, 단일 프로젝트의 코드 결합이 심각하고 한 부분을 수정하려면 다시 컴파일하고 패키징해야 하므로 시간이 많이 걸리고 노동 집약적입니다.
- 단위 테스트에 편리하며 다른 모듈에 집중하지 않고 하나의 비즈니스 모듈만 변경할 수 있습니다.
(3) 장점:
- 구성 요소화는 재사용을 개선하기 위해 공통 모듈을 분리하고 균일하게 관리하며, 구성 요소는 UI 구현을 포함하고 레이어 및 논리 레이어
- 각각을 포함할 수도 있습니다. 구성 요소를 독립적으로 컴파일하여 컴파일 속도를 높이고 독립적으로 패키지할 수 있습니다.
- 각 프로젝트 내의 수정 사항은 다른 프로젝트에 영향을 미치지 않습니다.
- 비즈니스 라이브러리 프로젝트를 빠르게 분리하고 다른 앱에 통합할 수 있습니다.
- 자주 반복되는 비즈니스 모듈은 구성 요소 접근 방식을 채택하여 비즈니스 라인 연구 및 개발이 서로 간섭할 수 없으며 협업 효율성을 향상하고 제품 품질을 제어하며 안정성을 향상시킵니다.
- 병렬 개발을 통해 팀원은 스스로 개발한 소형 모듈에만 집중하므로 결합이 줄어들고 향후 유지 관리가 더 쉬워집니다.
(4) 고려사항:
모드 전환: APP가 개별 디버깅과 전체 디버깅 사이를 자유롭게 전환하도록 하는 방법
컴포넌트화 후 각 비즈니스 모듈은 별도의 APP(isModuleRun=false)가 될 수 있으며, 릴리스 패키징할 때 각 비즈니스 모듈은 루트 프로젝트 gradle.properties에서 isModuleRun=true로 완전히 제어되는 lib 종속성으로 사용됩니다. isModuleRun 상태가 다르고, 로딩하는 애플리케이션과 AndroidManifest가 달라서 독립 APK인지 lib인지 구별이 가능합니다.
build.grade에서 구성:

리소스 충돌
여러 모듈을 생성할 때 동일한 리소스 파일 이름을 병합할 때 발생하는 충돌을 해결하는 방법 중복된 비즈니스 모듈 및 BaseModule 리소스 파일 이름으로 인해 충돌이 발생합니다.
각 모듈에는 app_name이 있습니다. 리소스 이름이 중복되는 것을 방지하려면 각 컴포넌트의 build.gradle에서 리소스 이름 접두사를 강제로 확인하기 위해 ResourcePrefix "xxx_"를 추가합니다. 각 컴포넌트의 리소스 접두사를 수정합니다. 그러나 값은
종속성
여러 모듈 간 공통 라이브러리 및 도구 클래스를 참조하는 방법
구성 요소 통신
구성 요소화 후 모듈 간은 각각 격리됩니다. 기타 UI 점프 및 메서드 호출을 수행하는 방법은 Alibaba ARouter 또는 Meituan의 WMRouter와 같은 라우팅 프레임워크를 사용하여 수행할 수 있습니다.
각 비즈니스 모듈은 이전에 종속성이 필요하지 않으며 라우팅을 통해 점프할 수 있으므로 비즈니스 간의 문제를 완벽하게 해결합니다.
입력 매개변수
우리는 구성요소가 연결되어 있다는 것을 알고 있으므로 단독으로 디버깅할 때 다른 모듈에서 전달된 매개변수를 가져오는 방법
Application
구성요소가 단독으로 실행될 때 각 모듈이 자동으로 APK에 들어갑니다. 여러 개의 애플리케이션이 있을 것입니다. 분명히 너무 많은 코드를 반복적으로 작성하고 싶지 않으므로 하나의 BaseApplication만 정의하면 됩니다. 다른 애플리케이션이 이 BaseApplication을 직접 상속해도 됩니다.
For 컴포넌트화 구현 방법에 대한 자세한 내용은 다음을 참조하세요. Anjuke Android Project Architecture Evolution
5.2, 플러그인
참조 링크 - 플러그인 소개
(1) 개요
플러그인에 관해서는 I 65535개를 초과하는 메서드 수 문제는 Dex 하도급을 통해 해결할 수 있으며 플러그인 개발을 사용하여 해결할 수도 있습니다. 플러그인의 개념은 플러그인 APP를 로드하고 실행하는 것입니다
(2가지 장점. )
대규모 프로젝트에서는 명확한 업무 분담을 위해 여러 팀이 서로 다른 플러그인 앱을 담당하는 경우가 많으므로 각 모듈이 서로 더 명확하게 캡슐화됩니다. 플러그인 APK 및 다양한 모듈을 별도로 컴파일할 수 있으므로 개발 효율성이 향상됩니다.
한도를 초과하는 위의 문제를 해결하려면 새로운 플러그인을 출시하여 "핫" 효과를 얻을 수 있습니다.
의미: 휴대폰 대각선 단위의 물리적 크기: 인치(inch), 1인치 = 2.54cmAndroid 휴대폰의 일반적인 크기는 5인치, 5.5인치, 6인치, 6.5인치 등입니다.화면 해상도 의미: 휴대폰의 가로 및 세로 방향의 총 픽셀 수일반 화면의 "가로 픽셀로 설명되며 높이 방향으로 1920픽셀이 있습니다. 단위: px(픽셀), 1px=1 픽셀
UI 디자이너의 디자인 도면은 px를 통합 측정 단위로 사용합니다.Android 휴대폰의 일반적인 해상도 비율: 320x480, 480x800, 720x1280, 1080x1920
화면 픽셀 밀도
의미: 인치당 픽셀 도트 단위: dpi(dots per ich)
기기에 인치당 160픽셀이 있다고 가정하면 기기의 화면 픽셀 밀도 = 160dpi
6.2, 적응 방법
1. 다양한 화면 크기 지원: Wrap_content, match_parent, Weight를 사용하세요. 레이아웃의 유연성을 보장하고 다양한 화면 크기에 적응하려면 "wrap_content" 및 "match_parent"를 사용하여 특정 뷰 구성 요소의 너비와 높이를 제어해야 합니다.
2. 상대 레이아웃을 사용하고 절대 레이아웃을 비활성화합니다.
3. LinearLayout의 가중치 속성을 사용하세요
너비가 0dp가 아니고(wrap_content와 0dp가 동일한 효과를 가짐) match_parent라면 어떻게 될까요?
android:layout_weight의 진정한 의미는 다음과 같습니다. View가 이 속성을 설정하고 이것이 유효한 경우 View의 너비는 원래 너비(android:layout_width)에 남은 공간의 비율을 더한 것과 같습니다.
이런 관점에서 위의 현상을 설명해 보겠습니다. 위 코드에서는 각 Button의 너비를 match_parent로 설정했습니다. 화면 너비가 L이라고 가정하면 각 Button의 너비도 L이어야 하며 나머지 너비는 L-(L+L) = -L과 같습니다. .
Button1의 무게는 1이고 나머지 너비 비율은 1/(1+2)= 1/3이므로 최종 너비는 L+1/3*(-L)=2/3L입니다. 유사하며 최종적으로 너비는 L+2/3(-L)=1/3L입니다.
4. .9개 사진 사용
6.3. Toutiao 화면 적응
참조 링크: Toutiao 화면 적응 솔루션 최종 버전
7. 성능 최적화
참조 링크: Android 성능 모니터링 도구, 메모리 및 카드 최적화 방법,
안드로이드 성능 최적화는 주로 다음과 같은 측면에서 최적화됩니다:
안정성(메모리 오버플로, 충돌)
원활(멈춤)
소비(전력 소비, 트래픽)
설치 패키지(APK 슬리밍)
많이 있습니다. 불합리한 메모리 사용, 코드 예외 시나리오에 대한 부적절한 고려, 불합리한 코드 로직 등과 같이 안정성에 영향을 미치는 이유는 모두 응용 프로그램의 안정성에 영향을 미칩니다. 가장 일반적인 두 가지 시나리오는 충돌과 ANR입니다. 이 두 가지 오류는 프로그램을 사용할 수 없게 만듭니다. 따라서 충돌에 대한 전역 모니터링을 잘 수행하고, 충돌을 처리하고, 후속 분석을 위해 충돌 정보 및 예외 정보를 수집 및 기록하여 비즈니스를 적절하게 처리하고, 메인 스레드에서 시간이 많이 걸리는 작업을 수행하지 마십시오. ANR 프로그램이 응답하지 않는 것을 방지합니다.
(1) 안정성 - 메모리 최적화
(1) 메모리 모니터 도구:
Android Studio와 함께 제공되는 메모리 모니터링 도구로 실시간 메모리 분석을 매우 잘 수행하는 데 도움이 될 수 있습니다. Android Studio의 오른쪽 하단에 있는 Memory Monitor 탭을 클릭하고 도구를 열면 밝은 파란색이 사용 가능한 메모리를 나타내고, 어두운 부분이 사용된 메모리를 나타내는 것을 확인할 수 있습니다. 메모리 변환 추세 차트에서 확인할 수 있습니다. 메모리 사용량 상태, 예를 들어 메모리가 계속해서 늘어나면 아래 그림과 같이 메모리가 갑자기 줄어들면 메모리 누수가 발생할 수 있으며, GC 등이 발생할 수 있습니다.
LeakCanary 도구:
LeakCanary는 Android 메모리 누수를 모니터링하기 위해 MAT를 기반으로 Square에서 개발한 오픈 소스 프레임워크입니다. 작동 원리는 다음과 같습니다.
모니터링 메커니즘은 활동을 WeakReference로 패키징하여 WeakReference로 래핑된 활동 객체가 재활용되면 WeakReference 참조가 ReferenceQueue에 배치됩니다. Activity가 재활용될 수 있는지 확인하는 데 사용됩니다. (ReferenceQueue에 재활용이 가능하다고 명시되어 있고 누수는 없습니다. 그렇지 않으면 누수가 있을 수 있습니다. LeakCanary는 GC를 한 번 실행하고 ReferenceQueue에 없으면 GC를 실행합니다. , 누출로 간주됩니다).
활동이 누출된 것으로 확인되면 메모리 덤프 파일(Debug.dumpHprofData)을 가져온 다음 HeapAnalyzerService.runAnalytic을 통해 메모리 파일을 분석한 다음 HeapAnalyzer(checkForLeak—findLeakingReference—findLeakTrace)를 통해 메모리 누출 분석을 수행합니다. 마지막으로 DisplayLeakService를 통해 메모리 누수가 표시됩니다.
(3) Android Lint 도구:
Android Lint 도구는 Android Sutido와 통합된 Android 코드 프롬프트 도구로 레이아웃과 코드에 매우 강력한 도움을 제공할 수 있습니다. 하드 코딩하면 레벨 경고가 표시됩니다. 예를 들어 레이아웃 파일에 중복된 LinearLayout 레이아웃을 작성하고, TextView에 직접 표시할 텍스트를 작성하고, 글꼴 크기 단위로 sp 대신 dp를 사용하면 오른쪽에 표시됩니다. 편집자의 프롬프트를 참조하세요.
(2) 부드러움 - 말더듬 최적화
말더듬 시나리오는 일반적으로 사용자 상호 작용 경험의 가장 직접적인 측면에서 발생합니다. 지연에 영향을 미치는 두 가지 주요 요인은 인터페이스 그리기와 데이터 처리입니다.
인터페이스 그리기: 주된 이유는 그리기 수준이 깊고, 페이지가 복잡하며, 새로 고침이 불합리하기 때문입니다. 이러한 이유로 인해 UI, 시작 후 초기 인터페이스, 그리기에서 지연 장면이 더 자주 발생합니다. 페이지로 이동합니다.
데이터 처리: 이 지연 시나리오의 이유는 데이터 처리량이 너무 많기 때문입니다. 이는 일반적으로 세 가지 상황으로 나누어집니다. 하나는 데이터가 UI 스레드에서 처리되는 것이고, 다른 하나는 데이터 처리가 이루어지기 때문입니다. CPU를 많이 차지하여 메인 스레드가 시간을 얻지 못합니다. 셋째, 메모리 증가로 인해 GC가 자주 발생하여 지연이 발생합니다.
(1) 레이아웃 최적화
안드로이드 시스템은 View를 측정하고 레이아웃하고 그릴 때 View 개수를 순회하면서 동작합니다. 뷰 번호의 높이가 너무 높으면 측정 속도, 레이아웃 및 그리기 속도에 심각한 영향을 미칩니다. Google은 또한 API 문서에서 뷰 높이가 10개 레이어를 초과하지 않아야 한다고 권장합니다. 현재 버전에서 Google은 LineraLayout 대신 RelativeLayout을 기본 루트 레이아웃으로 사용합니다. 그 목적은 LineraLayout 중첩으로 생성된 레이아웃 트리의 높이를 줄여 UI 렌더링 효율성을 높이는 것입니다.
레이아웃 재사용, 레이아웃 재사용을 위한 레이블 사용
레벨 감소, 상위 레이아웃 대체를 위한 레이블 사용
컨트롤에서 불필요한 속성 삭제;
(2) 그리기 최적화
오버드로잉은 화면의 특정 픽셀을 동일한 프레임에 여러 번 그리는 것을 의미합니다. 다단계 중첩 UI 구조에서 보이지 않는 UI가 그리기 작업도 수행하는 경우 특정 픽셀 영역을 여러 번 그려서 CPU 및 GPU 리소스가 중복되게 낭비됩니다. 과잉 그리기를 방지하는 방법은 무엇입니까?
레이아웃 최적화. XML에서 불필요한 배경을 제거하고, Window의 기본 배경을 제거하고, 필요에 따라 자리 표시자 배경 이미지를 표시합니다
사용자 정의 보기 최적화. 시스템이 눈에 보이는 영역을 식별하는 데 도움이 되도록 canvas.clipRect()를 사용하면 이 영역 내에서만 그려집니다.
(3) 시작 최적화
앱에는 일반적으로 스플래시 페이지의 UI 레이아웃을 최적화하고 프로필 GPU 렌더링을 통해 프레임 손실을 감지하는 SplashActivity가 있습니다.
(3) 절약 - 전력 소비 최적화
Android 5.0 이전에는 애플리케이션의 전력 소비를 테스트하는 것이 번거롭고 부정확했습니다. 5.0 이후 Google은 기기의 전력 소비 정보를 얻기 위한 API인 Battery Historian을 특별히 도입했습니다. Battery Historian은 Google에서 제공하는 Android 시스템 전력 분석 도구로, 휴대폰의 전력 소비 과정을 시각적으로 표시하고 전력 분석 파일을 입력하여 소비 상황을 표시합니다.
마지막으로 전력 소비 최적화를 위한 몇 가지 참조 방법이 제공됩니다.
(1) 계산 최적화. 루프 최적화를 위한 알고리즘, if...else 대신 Switch...case, 부동 소수점 연산 방지.
부동소수점 연산: 컴퓨터에서는 정수와 소수가 1024, 3.1415926 등과 같은 일반적인 형식으로 저장됩니다. 이는 특성이 없지만 그러한 숫자의 정확도가 높지 않으며 표현이 충분히 포괄적이지 않습니다. 보편적인 숫자 표기법을 갖기 위해 부동 소수점 숫자가 발명되었습니다. 부동 소수점 숫자의 표현은 과학 표기법(
.×10***)과 약간 유사하며 표현은 0.*****×10이며 컴퓨터의 형식은 입니다. *** e ±**), 여기서 앞의 별표는 고정 소수점 소수점, 즉 정수 부분이 0인 순수 소수를 나타내고, 다음 지수 부분은 고정 소수점 정수를 나타냅니다. 모든 정수 또는 소수는 이 형식을 사용하여 표현될 수 있습니다. 예를 들어 1024는 0.1024×10^4(.1024e+004)로 표현될 수 있고 3.1415926은 0.31415926×10^1(.31415926e+001)로 표현될 수 있습니다. , 이것은 부동 소수점 숫자입니다. 부동 소수점 숫자에 대해 수행되는 연산은 부동 소수점 연산입니다. 부동 소수점 연산은 일반 연산보다 더 복잡하므로 컴퓨터는 일반 연산보다 부동 소수점 연산을 훨씬 느리게 수행합니다. (2) Wake Lock을 부적절하게 사용하지 마세요.
Wake Lock은 주로 시스템의 절전 모드와 관련된 잠금 메커니즘입니다. 누군가 이 잠금 장치를 보유하고 있는 한 시스템은 절전 모드로 들어갈 수 없습니다. 즉, 내 프로그램이 이 잠금 장치를 CPU에 추가하면 시스템이 절전 모드로 전환되지 않습니다. . Hibernate, 이것의 목적은 우리 프로그램의 운영에 전적으로 협력하는 것입니다. 경우에 따라 이 작업을 수행하지 않으면 몇 가지 문제가 발생합니다. 예를 들어 WeChat과 같은 인스턴트 메시징의 하트비트 패킷은 화면이 꺼진 직후 네트워크 액세스를 중지합니다. 따라서 Wake_Lock은 WeChat에서 광범위하게 사용됩니다. 전력을 절약하기 위해 CPU가 작업을 수행하지 않을 때 시스템은 자동으로 절전 모드로 전환됩니다. 효율적인 실행을 위해 CPU를 깨워야 하는 작업이 있는 경우 CPU에 Wake_Lock이 추가됩니다. 누구나 저지르는 흔한 실수는 CPU를 깨워 작동하게 하는 것은 쉽지만 Wake_Lock을 해제하는 것은 잊어버리기 쉽다는 것입니다.
(3) Job Scheduler를 사용하여 백그라운드 작업을 관리합니다.
Android 5.0 API 21에서 Google은 사용자가 밤에 휴식을 취하거나 기기를 사용할 때와 같이 특정 시점이나 특정 조건이 충족될 때 작업이 실행되는 시나리오를 처리하기 위해 JobScheduler API라는 구성 요소를 제공합니다. 전원 어댑터를 켜고 Wi-Fi에 연결하여 업데이트 다운로드 작업을 시작하세요. 이를 통해 리소스 소비를 줄이면서 애플리케이션 효율성을 높일 수 있습니다.
(4) 설치 패키지 - APK 슬리밍
(1) 설치 패키지
assets 폴더의 구조. 일부 구성 파일과 리소스 파일을 저장하기 위해 자산은 해당 ID를 자동으로 생성하지 않지만 AssetManager 클래스의 인터페이스를 통해 이를 얻습니다.
res. res는 리소스의 약어입니다. 이 디렉터리에는 리소스 파일이 저장됩니다. 해당 ID는 자동으로 생성되어 .R 파일에 매핑됩니다.
메타-INF. APK 파일의 무결성을 확인할 수 있는 애플리케이션의 서명 정보를 저장합니다.
AndroidManifest.xml. 이 파일은 Android 애플리케이션의 구성 정보, 일부 구성 요소의 등록 정보, 사용 가능한 권한 등을 설명하는 데 사용됩니다.
classes.dex. Dalvik 바이트코드 프로그램은 Dalvik 가상 머신을 실행 가능하게 만듭니다. 일반적으로 Android 애플리케이션은 패키징할 때 Android SDK의 dx 도구를 사용하여 Java 바이트코드를 Dalvik 바이트코드로 변환합니다.
resources.arsc. 리소스 파일과 리소스 ID 간의 매핑 관계를 기록하며, 리소스 ID를 기준으로 리소스를 찾는 데 사용됩니다.
(2) 설치 패키지 크기를 줄입니다
코드 난독화. 압축, 최적화, 난독화 및 기타 기능이 포함된 IDE와 함께 제공되는 proGuard 코드 난독화 도구를 사용하세요.
리소스 최적화. 예를 들어 Android Lint를 사용하여 중복 리소스 삭제, 리소스 파일 최소화 등을 수행할 수 있습니다.
이미지 최적화. 예를 들어 PNG 최적화 도구를 사용하여 이미지를 압축합니다. 가장 진보된 압축 도구인 Googlek 오픈 소스 라이브러리 zopfli를 추천합니다. 애플리케이션 버전이 0 이상인 경우 WebP 이미지 형식을 사용하는 것이 좋습니다.
중복되거나 쓸모없는 기능이 있는 타사 라이브러리를 피하세요. 예를 들어 Baidu Maps는 기본 지도에 연결할 수 있고, iFlytek Voice는 오프라인으로 연결할 필요가 없으며 사진 라이브러리 GlidePicasso 등에 연결할 수 있습니다.
플러그인 개발. 예를 들어 기능 모듈은 서버에 배치되고 요청 시 다운로드되므로 설치 패키지의 크기를 줄일 수 있습니다.
WeChat의 오픈 소스 파일 난독화 도구인 AndResGuard를 사용할 수 있습니다. 일반적으로 압축할 수 있는 APK 크기는 1M 정도입니다.
7.1.콜드 스타트와 핫 스타트
참조 링크: https://www.jianshu.com/p/03c0fd3fc245
콜드 스타트
애플리케이션을 시작할 때 시스템에는 애플리케이션에 대한 프로세스가 없습니다. 이때 시스템에 새로운 프로세스가 생성되어 애플리케이션에 할당됩니다.
Hot start
애플리케이션을 시작할 때 이미 시스템에 애플리케이션 프로세스가 있습니다(예: 뒤로 키 누르기, 홈 키, 애플리케이션은 종료되지만 애플리케이션의 프로세스는 여전히 백그라운드에 남아 있습니다.
Difference
콜드 스타트: 시스템에 애플리케이션에 대한 프로세스가 없으며 새 프로세스를 생성해야 합니다. 애플리케이션에 할당되므로 먼저 Application 클래스가 생성 및 초기화된 다음 MainActivity 클래스(일련의 측정, 레이아웃, 드로잉 포함)가 인터페이스에 표시됩니다. 핫 스타트: 기존 프로세스에서 시작합니다. Application 클래스가 생성 및 초기화되지 않습니다. MainActivity 클래스가 직접 생성 및 초기화되고(일련의 측정, 레이아웃 및 드로잉 포함) 최종적으로 인터페이스에 표시됩니다.
콜드 스타트 프로세스
Fork는 Zygote 프로세스에서 새로운 프로세스를 생성하고, MainActivity를 생성하며, onCreate/onStart/onResume 메소드가 완료되면; 인터페이스에 표시됩니다.
콜드 스타트 최적화
애플리케이션 및 첫 번째 활동의 작업 부하를 줄입니다. 애플리케이션이 비즈니스 작업에 참여하지 않도록 합니다. 애플리케이션에서 정적 변수를 사용하지 마세요. 데이터 저장, 레이아웃 복잡성 및 깊이 감소
8.1. MVP 패턴
MVP 아키텍처는 MVC에서 개발되었습니다. MVP에서 M은 모델, V는 보기, P는 발표자를 의미합니다.
모델 레이어: 주로 데이터 기능, 비즈니스 로직 및 엔터티 모델을 얻는 데 사용됩니다.
View 레이어(View): Activity 또는 Fragment에 해당하며, 뷰의 부분 표시 및 비즈니스 로직 사용자 상호 작용을 담당합니다.
Control 레이어(Presenter): View 레이어와 Model 레이어 간의 상호 작용을 완료하고 가져오는 작업을 담당합니다. M 계층에서 P 계층을 거쳐 데이터를 검색한 후 V 계층으로 반환하므로 V 계층과 M 계층 사이에 결합이 없습니다.
MVP에서 Presenter 계층은 View 계층과 Model 계층을 완전히 분리하고, 주요 프로그램 로직을 Presenter 계층에 구현합니다. Presenter는 특정 View 계층(Activity)과 직접적인 관련이 없고 인터페이스를 정의하여 구현됩니다. . 대화형이므로 보기 레이어(활동)가 변경되어도 Presenter는 변경되지 않은 상태로 유지됩니다. 뷰 레이어 인터페이스 클래스에는 set/get 메소드만 있어야 하며 일부 인터페이스에는 콘텐츠와 사용자 입력이 표시되어야 합니다. 또한 중복된 콘텐츠가 없어야 합니다. View 레이어는 Model 레이어에 직접 접근할 수 없습니다. 이것이 MVC와의 가장 큰 차이점이자 MVP의 핵심 장점입니다.
9. 가상 머신
9.1, Android Dalvik 가상 머신과 ART 가상 머신의 비교
Dalvik
Android 4.4 및 이전 Dalvik 가상 머신 비교 우리는 Apk가 먼저 Java 등을 패키징한다는 것을 알고 있습니다. javac를 통해 .class 파일로 변환하지만 Dalvik 가상 머신은 .dex 파일만 실행합니다. 이때 dx는 .class 파일을 Dalvik 가상 머신에서 실행되는 .dex 파일로 변환합니다. Dalvik 가상 머신이 시작되면 먼저 .dex 파일을 빠르게 실행되는 머신 코드로 변환합니다. 65535의 문제로 인해 애플리케이션이 콜드 스타트될 때 공동 패키징 프로세스가 있습니다. 앱이 느리게 시작됩니다. 이는 Dalvik 가상 머신의 JIT(Just In Time) 기능입니다.
ART
ART 가상 머신은 Android 5.0부터 사용되기 시작한 Android 가상 머신입니다. ART 가상 머신은 Dalvik 가상 머신의 기능과 호환되어야 하지만 ART에는 AOT( 즉, APK를 설치할 때 ART 가상 머신에서 직접 사용할 수 있는 머신 코드로 dex를 직접 처리합니다. ART 가상 머신은 본질적으로 다중 dex를 지원하므로 공동 패키징 프로세스가 없으므로 ART 가상 머신은 APP 콜드 스타트 속도를 크게 향상시킵니다.
ART 장점:
APP 콜드 스타트 속도 향상
GC 속도 향상
提供功能全面的Debug特性
ART缺点:
APP安装速度慢,因为在APK安装的时候要生成可运行.oat文件
APK占用空间大,因为在APK安装的时候要生成可运行.oat文件
arm处理器
关于ART更详细的介绍,可以参考Android ART详解
总结
熟悉Android性能分析工具、UI卡顿、APP启动、包瘦身和内存性能优化
熟悉Android APP架构设计,模块化、组件化、插件化开发
熟练掌握Java、设计模式、网络、多线程技术
Java基本知识点
1、Java的类加载过程
jvm将.class类文件信息加载到内存并解析成对应的class对象的过程,注意:jvm并不是一开始就把所有的类加载进内存中,只是在第一次遇到某个需要运行的类才会加载,并且只加载一次
主要分为三部分:1、加载,2、链接(1.验证,2.准备,3.解析),3、初始化
1:加载
类加载器包括 BootClassLoader、ExtClassLoader、APPClassLoader
2:链接
验证:(验证class文件的字节流是否符合jvm规范)
准备:为类变量分配内存,并且进行赋初值
解析:将常量池里面的符号引用(变量名)替换成直接引用(内存地址)过程,在解析阶段,jvm会把所有的类名、方法名、字段名、这些符号引用替换成具体的内存地址或者偏移量。
3:初始化
主要对类变量进行初始化,执行类构造器的过程,换句话说,只对static修试的变量或者语句进行初始化。
范例:Person person = new Person();为例进行说明。
Java编程思想中的类的初始化过程主要有以下几点:
- 找到class文件,将它加载到内存
- 在堆内存中分配内存地址
- 初始化
- 将堆内存地址指给栈内存中的p变量
2、String、StringBuilder、StringBuffer
StringBuffer里面的很多方法添加了synchronized关键字,是可以表征线程安全的,所以多线程情况下使用它。
执行速度:
StringBuilder > StringBuffer > String
StringBuilder牺牲了性能来换取速度的,这两个是可以直接在原对象上面进行修改,省去了创建新对象和回收老对象的过程,而String是字符串常量(final)修试,另外两个是字符串变量,常量对象一旦创建就不可以修改,变量是可以进行修改的,所以对于String字符串的操作包含下面三个步骤:
- 创建一个新对象,名字和原来的一样
- 在新对象上面进行修改
- 原对象被垃圾回收掉
3、JVM内存结构
Java对象实例化过程中,主要使用到虚拟机栈、Java堆和方法区。Java文件经过编译之后首先会被加载到jvm方法区中,jvm方法区中很重的一个部分是运行时常量池,用以存储class文件类的版本、字段、方法、接口等描述信息和编译期间的常量和静态常量。
3.1、JVM基本结构
类加载器classLoader,在JVM启动时或者类运行时将需要的.class文件加载到内存中。
执行引擎,负责执行class文件中包含的字节码指令。
本地方法接口,主要是调用C/C++实现的本地方法及返回结果。
内存区域(运行时数据区),是在JVM运行的时候操作所分配的内存区,
主要分为以下五个部分,如下图: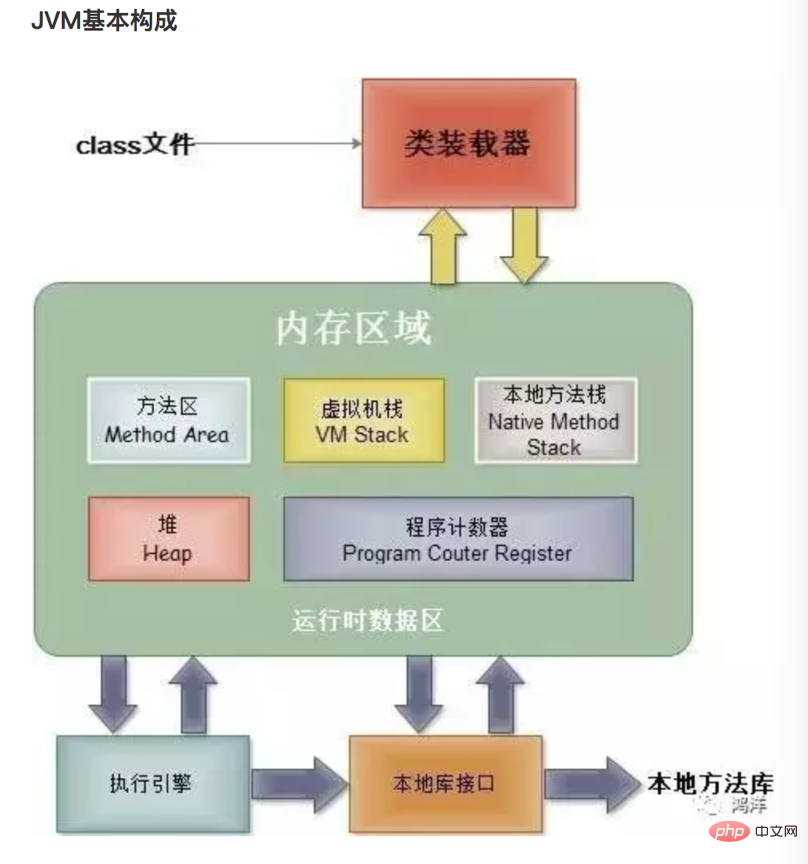
- 方法区:用于存储类结构信息的地方,包括常量池、静态变量、构造函数等。
- Java堆(heap):存储Java实例或者对象的地方。这块是gc的主要区域。
- Java栈(stack):Java栈总是和线程关联的,每当创建一个线程时,JVM就会为这个线程创建一个对应的Java栈。在这个java栈中又会包含多个栈帧,每运行一个方法就创建一个栈帧,用于存储局部变量表、操作栈、方法返回值等。每一个方法从调用直至执行完成的过程,就对应一个栈帧在java栈中入栈到出栈的过程。所以java栈是线程私有的。
- 程序计数器:用于保存当前线程执行的内存地址,由于JVM是多线程执行的,所以为了保证线程切换回来后还能恢复到原先状态,就需要一个独立的计数器,记录之前中断的地方,可见程序计数器也是线程私有的。
- 本地方法栈:和Java栈的作用差不多,只不过是为JVM使用到的native方法服务的。
3.2、JVM源码分析
https://www.jianshu.com/nb/12554212
4、GC机制
垃圾收集器一般完成两件事
- 检测出垃圾;
- 回收垃圾;
4.1 Java对象引用
通常,Java对象的引用可以分为4类:强引用、软引用、弱引用和虚引用。
强引用:通常可以认为是通过new出来的对象,即使内存不足,GC进行垃圾收集的时候也不会主动回收。
Object obj = new Object();
软引用:在内存不足的时候,GC进行垃圾收集的时候会被GC回收。
Object obj = new Object(); SoftReference<Object> softReference = new SoftReference<>(obj);
弱引用:无论内存是否充足,GC进行垃圾收集的时候都会回收。
Object obj = new Object(); WeakReference<Object> weakReference = new WeakReference<>(obj);
虚引用:和弱引用类似,主要区别在于虚引用必须和引用队列一起使用。
Object obj = new Object(); ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>(); PhantomReference<Object> phantomReference = new PhantomReference<>(obj, referenceQueue);
引用队列:如果软引用和弱引用被GC回收,JVM就会把这个引用加到引用队列里,如果是虚引用,在回收前就会被加到引用队列里。
垃圾检测方法:
引用计数法:给每个对象添加引用计数器,每个地方引用它,计数器就+1,失效时-1。如果两个对象互相引用时,就导致无法回收。
可达性分析算法:以根集对象为起始点进行搜索,如果对象不可达的话就是垃圾对象。根集(Java栈中引用的对象、方法区中常量池中引用的对象、本地方法中引用的对象等。JVM在垃圾回收的时候,会检查堆中所有对象是否被这些根集对象引用,不能够被引用的对象就会被垃圾回收器回收。)
垃圾回收算法:
常见的垃圾回收算法有:
标记-清除
标记:首先标记所有需要回收的对象,在标记完成之后统计回收所有被标记的对象,它的标记过程即为上面的可达性分析算法。
清除:清除所有被标记的对象
缺点:
效率不足,标记和清除效率都不高
空间问题,标记清除之后会产生大量不连续的内存碎片,导致大对象分配无法找到足够的空间,提前进行垃圾回收。
复制回收算法
将可用的内存按容量划分为大小相等的2块,每次只用一块,当这一块的内存用完了,就将存活的对象复制到另外一块上面,然后把已使用过的内存空间一次清理掉。
缺点:
将内存缩小了原本的一般,代价比较高
大部分对象是“朝生夕灭”的,所以不必按照1:1的比例划分。
现在商业虚拟机采用这种算法回收新生代,但不是按1:1的比例,而是将内存区域划分为eden 空间、from 空间、to 空间 3 个部分。
其中 from 空间和 to 空间可以视为用于复制的两块大小相同、地位相等,且可进行角色互换的空间块。from 和 to 空间也称为 survivor 空间,即幸存者空间,用于存放未被回收的对象。
在垃圾回收时,eden 空间中的存活对象会被复制到未使用的 survivor 空间中 (假设是 to),正在使用的 survivor 空间 (假设是 from) 中的年轻对象也会被复制到 to 空间中 (大对象,或者老年对象会直接进入老年带,如果 to 空间已满,则对象也会直接进入老年代)。此时,eden 空间和 from 空间中的剩余对象就是垃圾对象,可以直接清空,to 空间则存放此次回收后的存活对象。这种改进的复制算法既保证了空间的连续性,又避免了大量的内存空间浪费。
标记-整理
在老年代的对象大都是存活对象,复制算法在对象存活率教高的时候,效率就会变得比较低。根据老年代的特点,有人提出了“标记-压缩算法(Mark-Compact)”
标记过程与标记-清除的标记一样,但后续不是对可回收对象进行清理,而是让所有的对象都向一端移动,然后直接清理掉端边界以外的内存。
这种方法既避免了碎片的产生,又不需要两块相同的内存空间,因此,其性价比比较高。
分带收集算法
根据对象存活的周期不同将内存划分为几块,一般是把Java堆分为老年代和新生代,这样根据各个年代的特点采用适当的收集算法。
新生代每次收集都有大量对象死去,只有少量存活,那就选用复制算法,复制的对象数较少就可完成收集。
老年代对象存活率高,使用标记-压缩算法,以提高垃圾回收效率。
5、类加载器
程序在启动的时候,并不会一次性加载程序所要用的所有class文件,而是根据程序的需要,通过Java的类加载机制(ClassLoader)来动态加载某个class文件到内存当中的,从而只有class文件被载入到了内存之后,才能被其它class所引用。所以ClassLoader就是用来动态加载class文件到内存当中用的。
5.1、双亲委派原理
每个ClassLoader实例都有一个父类加载器的引用(不是继承关系,是一个包含的关系),虚拟机内置的类加载器(Bootstrap ClassLoader)本身没有父类加载器,但是可以用做其他ClassLoader实例的父类加载器。
当一个ClassLoader 实例需要加载某个类时,它会试图在亲自搜索这个类之前先把这个任务委托给它的父类加载器,这个过程是由上而下依次检查的,首先由顶层的类加载器Bootstrap CLassLoader进行加载,如果没有加载到,则把任务转交给Extension CLassLoader视图加载,如果也没有找到,则转交给AppCLassLoader进行加载,还是没有的话,则交给委托的发起者,由它到指定的文件系统或者网络等URL中进行加载类。还没有找到的话,则会抛出CLassNotFoundException异常。否则将这个类生成一个类的定义,并将它加载到内存中,最后返回这个类在内存中的Class实例对象。
5.2、 为什么使用双亲委托模型
JVM在判断两个class是否相同时,不仅要判断两个类名是否相同,还要判断是否是同一个类加载器加载的。
避免重复加载,父类已经加载了,则子CLassLoader没有必要再次加载。
考虑安全因素,假设自定义一个String类,除非改变JDK中CLassLoader的搜索类的默认算法,否则用户自定义的CLassLoader如法加载一个自己写的String类,因为String类在启动时就被引导类加载器Bootstrap CLassLoader加载了。
关于Android的双亲委托机制,可以参考android classloader双亲委托模式
6、集合
Java集合类主要由两个接口派生出:Collection和Map,这两个接口是Java集合的根接口。
Collection接口是集合类的根接口,Java中没有提供这个接口的直接的实现类。但是却让其被继承产生了两个接口,就是 Set和List。Set中不能包含重复的元素。List是一个有序的集合,可以包含重复的元素,提供了按索引访问的方式。
Map是Java.util包中的另一个接口,它和Collection接口没有关系,是相互独立的,但是都属于集合类的一部分。Map包含了key-value对。Map不能包含重复的key,但是可以包含相同的value。
6.1、区别
List,Set都是继承自Collection接口,Map则不是;
List特点:元素有放入顺序,元素可重复; Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的,加入Set 的Object必须定义equals()方法;
LinkedList、ArrayList、HashSet是非线程安全的,Vector是线程安全的;
HashMap是非线程安全的,HashTable是线程安全的;
6.2、List和Vector比较
Vector是多线程安全的,线程安全就是说多线程访问同一代码,不会产生不确定的结果。而ArrayList不是,这个可以从源码中看出,Vector类中的方法很多有synchronized进行修饰,这样就导致了Vector在效率上无法与ArrayList相比;
两个都是采用的线性连续空间存储元素,但是当空间不足的时候,两个类的增加方式是不同。
Vector可以设置增长因子,而ArrayList不可以。
Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
6.3、HashSet如何保证不重复
HashSet底层通过HashMap来实现的,在往HashSet中添加元素是
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();在HashMap中进行查找是否存在这个key,value始终是一样的,主要有以下几种情况:
- 如果hash码值不相同,说明是一个新元素,存;
- 如果hash码值相同,且equles判断相等,说明元素已经存在,不存;
- 如果hash码值相同,且equles判断不相等,说明元素不存在,存;
- 如果有元素和传入对象的hash值相等,那么,继续进行equles()判断,如果仍然相等,那么就认为传入元素已经存在,不再添加,结束,否则仍然添加;
6.4、HashSet与Treeset的适用场景
- HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
- TreeSet 是二叉树(红黑树的树据结构)实现的,Treeset中的数据是自动排好序的,不允许放入null值
- HashSet是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。
- HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。为快速查找而设计的Set,我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
6.5、HashMap与TreeMap、HashTable的区别及适用场景
HashMap 非线程安全,基于哈希表(散列表)实现。使用HashMap要求添加的键类明确定义了hashCode()和equals()[可以重写hashCode()和equals()],为了优化HashMap空间的使用,您可以调优初始容量和负载因子。其中散列表的冲突处理主要分两种,一种是开放定址法,另一种是链表法。HashMap的实现中采用的是链表法。
TreeMap:非线程安全基于红黑树实现,TreeMap没有调优选项,因为该树总处于平衡状态
7、 常量池
7.1、Interger中的128(-128~127)
当数值范围为-128~127时:如果两个new出来Integer对象,即使值相同,通过“”比较结果为false,但两个对象直接赋值,则通过“”比较结果为“true,这一点与String非常相似。
当数值不在-128~127时,无论通过哪种方式,即使两个对象的值相等,通过“”比较,其结果为false;
当一个Integer对象直接与一个int基本数据类型通过“”比较,其结果与第一点相同;
Integer对象的hash值为数值本身;
@Override
public int hashCode() {
return Integer.hashCode(value);
}7.2、为什么是-128-127?
在Integer类中有一个静态内部类IntegerCache,在IntegerCache类中有一个Integer数组,用以缓存当数值范围为-128~127时的Integer对象。
8、泛型
泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。 Java语言引入泛型的好处是安全简单。
泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
它提供了编译期的类型安全,确保你只能把正确类型的对象放入 集合中,避免了在运行时出现ClassCastException。
使用Java的泛型时应注意以下几点:
- 泛型的类型参数只能是类类型(包括自定义类),不能是简单类型。
- 同一种泛型可以对应多个版本(因为参数类型是不确定的),不同版本的泛型类实例是不兼容的。
- 泛型的类型参数可以有多个。
- 泛型的参数类型可以使用extends语句,例如。习惯上称为“有界类型”。
- 泛型的参数类型还可以是通配符类型。例如Class> classType =
Class.forName(“java.lang.String”);
8.1 T泛型和通配符泛型
- ? 表示不确定的java类型。
- T 表示java类型。
- K V 分别代表java键值中的Key Value。
- E 代表Element。
8.2 泛型擦除
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。
泛型是通过类型擦除来实现的,编译器在编译时擦除了所有类型相关的信息,所以在运行时不存在任何类型相关的信息。例如 List在运行时仅用一个List来表示。这样做的目的,是确保能和Java 5之前的版本开发二进制类库进行兼容。你无法在运行时访问到类型参数,因为编译器已经把泛型类型转换成了原始类型。
8.3 限定通配符
限定通配符对类型进行了限制。
하나는 유형이 T의 하위 클래스여야 함을 보장하여 유형의 상한을 설정하는 T>입니다. 유형은 T의 상위 클래스여야 합니다. 유형의 하한을 설정합니다.
반면에 >는 어떤 유형으로도 대체될 수 있으므로 정규화되지 않은 와일드카드를 나타냅니다.
예를 들어 List 확장 번호>
저희 프로그램 설계에 따라 클라이언트가 실제 개체를 직접 조작할 수 없습니다. 그렇다면 왜 직접적으로 할 수 없습니까? 한 가지 상황은 호출해야 하는 개체가 다른 컴퓨터에 있고 네트워크를 통해 해당 개체에 액세스해야 하는 경우입니다. 이를 호출하기 위해 직접 코딩하면 네트워크 연결, 패키징, 언패킹 및 기타 매우 복잡한 단계를 처리해야 합니다. 따라서 클라이언트 처리를 단순화하기 위해 프록시 모드를 사용하여 클라이언트에서 원격 개체에 대한 프록시를 설정합니다. 클라이언트는 로컬 개체를 호출하는 것처럼 프록시를 호출한 다음 프록시가 실제 개체에 연결합니다. 클라이언트가 없을 수도 있습니다. 호출되는 것이 네트워크의 반대편에 있는 것처럼 느껴집니다. 이것이 실제로 웹 서비스가 작동하는 방식입니다. 또 다른 경우에는 호출하려는 개체가 로컬이지만 호출에 시간이 많이 걸리기 때문에 정상적인 작업에 영향을 미칠까 봐 특별히 에이전트를 찾아 이러한 시간이 많이 걸리는 상황 중 하나를 찾습니다. 이해하려면 Word에 큰 그림이 설치되어 있습니다. Word를 열면 그 안에 있는 내용을 로드해서 함께 열어야 합니다. 그러나 사용자가 Word를 열기 전에 큰 그림이 로드될 때까지 기다리면 사용자가 이미 점프했을 수 있습니다. 대기 중에 프록시를 설정하고 프록시가 Word의 원래 열기 기능에 영향을 주지 않고 그림을 천천히 열도록 할 수 있습니다. Word에서 이 작업이 수행될 수 있다고 추측했음을 명확히 하겠습니다. 그 작업이 어떻게 수행되는지 정확히 모르겠습니다.
이유 2: 이적 절차를 어떻게 진행해야 할지 모르거나, 지금 할 수 있는 일 외에 목표를 달성하기 위해 다른 일을 해야 합니다.
우리 프로그램 디자인에 해당합니다. 현재 클래스가 제공할 수 있는 기능 외에도 몇 가지 다른 기능을 추가해야 합니다. 가장 쉽게 생각할 수 있는 상황은 권한 필터링입니다. 그러나 보안상의 이유로 특정 사용자만 이 클래스를 호출할 수 있습니다. 이때 모든 요청을 요구하는 이 클래스의 프록시 클래스를 만들 수 있습니다. 통과하려면 이 프록시 클래스에서 권한 판단을 내리며, 안전한 경우 실제 클래스의 비즈니스를 호출하여 처리를 시작합니다. 어떤 사람들은 왜 추가 프록시 클래스를 추가해야 하는지 물을 수 있습니다. 원래 클래스의 메서드에 권한 필터링만 추가하면 되는 거겠죠? 프로그래밍에는 클래스의 단일성 원칙에 문제가 있습니다. 이 원칙은 매우 간단합니다. 즉, 각 클래스의 기능은 가능한 한 단일합니다. 단일 함수를 가진 클래스만이 변경될 가능성이 가장 적기 때문에 왜 싱글이어야 합니까? 지금 예를 들어 현재 클래스에 권한 판단을 넣으면 현재 클래스가 자체 비즈니스 로직을 담당해야 합니다. 또한 권한 판단을 담당하는 이 클래스를 변경하는 데에는 두 가지 이유가 있습니다. 이제 권한 규칙이 변경되면 이 클래스를 변경해야 합니다. 이는 분명히 좋은 디자인이 아닙니다.
알겠습니다. 원칙에 대해 거의 이야기했습니다. 오랫동안 이야기하면 모두가 벽돌을 던질 것입니다. 하하, 다음에는 에이전시 구현 방법을 살펴보겠습니다.
데이터 구조 및 알고리즘
https://zhuanlan.zhihu.com/p/27005757?utm_source=weibo&utm_medium=social
http://crazyandcoder.tech/2016/09/14/android 알고리즘 및 데이터 구조 정렬 /
1. 정렬
정렬에는 내부 정렬과 외부 정렬이 있는데, 외부 정렬은 정렬된 데이터가 너무 커서 정렬된 모든 레코드를 한 번에 수용할 수 없기 때문입니다. 정렬 프로세스 외부 저장소에 액세스해야 합니다.
1.1. 직접 삽입 정렬
아이디어:
첫 번째 숫자와 두 번째 숫자를 정렬한 다음 순서가 지정된 시퀀스를 만듭니다.
세 번째 숫자를 삽입하여 새 순서를 만듭니다.
네 번째 숫자, 다섯 번째 숫자... 마지막 숫자까지 두 번째 단계를 반복합니다.
코드:
먼저 삽입 횟수, 즉 루프 횟수를 설정합니다. (int i=1;i
2. 디자인 패턴
참고: Android 개발의 일부 디자인 패턴
2.1. 싱글톤 디자인 패턴
싱글 케이스는 크게 게으른 스타일 싱글톤, 배고픈 스타일 싱글톤, 등록된 싱글톤으로 나뉩니다.
특징:
- 싱글턴 클래스에는 인스턴스가 하나만 있습니다.
- 싱글턴 클래스는 고유한 인스턴스를 만들어야 합니다.
- 싱글턴 클래스는 이 인스턴스를 다른 모든 객체에 제공해야 합니다.
컴퓨터 시스템에서 스레드 풀, 캐시, 로그 개체, 대화 상자, 프린터 등과 같은 것들은 종종 싱글톤으로 설계됩니다.
Lazy Singleton:
Singleton은 생성 방법을 비공개로 제한하여 클래스가 외부에서 인스턴스화되는 것을 방지합니다. 동일한 가상 머신 범위 내에서 Singleton의 유일한 인스턴스는 getInstance() 메서드를 통해서만 액세스할 수 있습니다. (실제로 Java 리플렉션 메커니즘을 통해 개인 생성자를 사용하여 클래스를 인스턴스화할 수 있으며, 이는 기본적으로 모든 Java 싱글톤 구현을 무효화합니다. 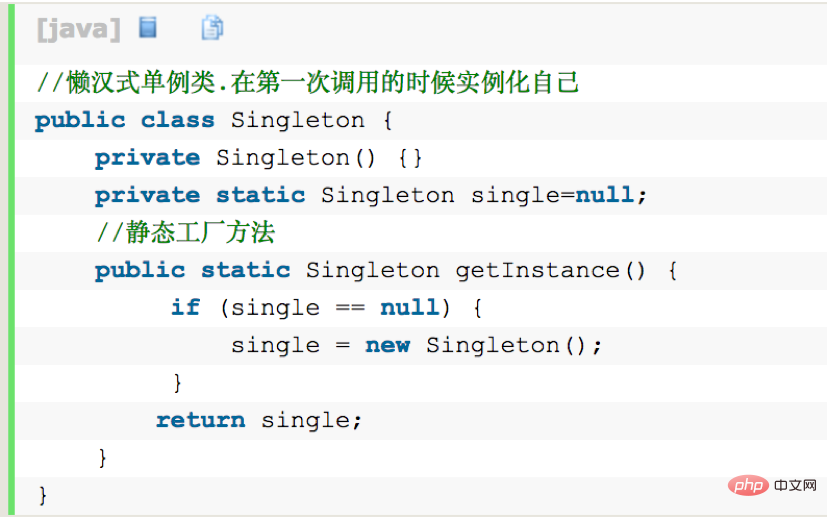
스레드에 안전하지 않으며 동시 상황에서 발생할 가능성이 매우 높습니다. 여러 싱글톤 인스턴스에 대한 스레드 안전성을 얻으려면 다음 세 가지 방법이 있습니다.
1. getInstance 메소드에 동기화 추가 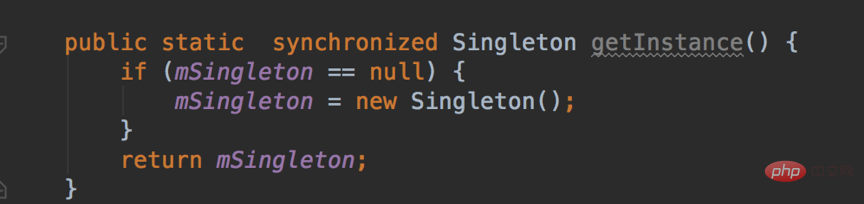
2. 이중 확인 잠금 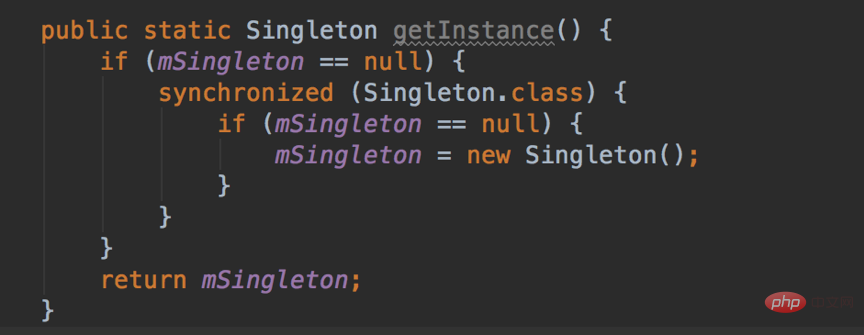
3. 이 메소드는 이전 메소드와 비교됩니다. one 두 방법 모두 스레드 안전성을 달성하고 동기화로 인한 성능 영향을 방지합니다. 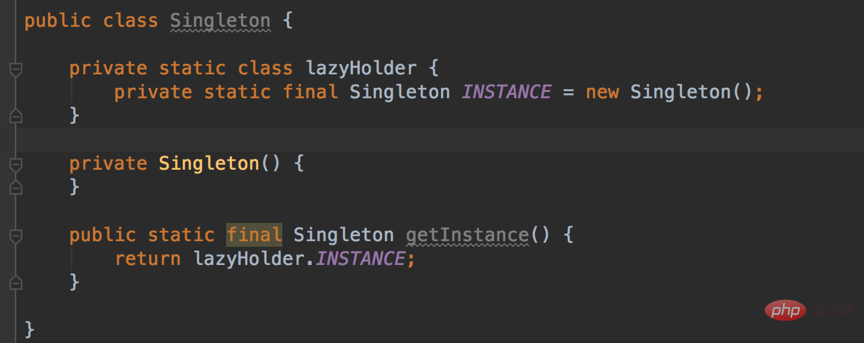 Hungry 스타일 싱글톤:
Hungry 스타일 싱글톤:

.
위 내용은 안드로이드 면접 질문의 가장 상세한 공유의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7518
7518
 15
1378
52
81
11
53
19
21
67
15
1378
52
81
11
53
19
21
67

 useeffect 란 무엇입니까? 부작용을 수행하는 데 어떻게 사용합니까?
Mar 19, 2025 pm 03:58 PM
useeffect 란 무엇입니까? 부작용을 수행하는 데 어떻게 사용합니까?
Mar 19, 2025 pm 03:58 PM
이 기사에서는 Data Fetching 및 기능 구성 요소의 DOM 조작과 같은 부작용을 관리하기위한 후크 인 React의 useEffect에 대해 설명합니다. 메모리 누출과 같은 문제를 방지하기 위해 사용법, 일반적인 부작용 및 정리를 설명합니다.
 React Reconciliation 알고리즘은 어떻게 작동합니까?
Mar 18, 2025 pm 01:58 PM
React Reconciliation 알고리즘은 어떻게 작동합니까?
Mar 18, 2025 pm 01:58 PM
이 기사는 가상 Dom 트리를 비교하여 DOM을 효율적으로 업데이트하는 React의 조정 알고리즘을 설명합니다. 성능 이점, 최적화 기술 및 사용자 경험에 미치는 영향에 대해 설명합니다. 문자 수 : 159
 JavaScript의 고차 기능은 무엇이며 어떻게 간결하고 재사용 가능한 코드를 작성하는 데 어떻게 사용할 수 있습니까?
Mar 18, 2025 pm 01:44 PM
JavaScript의 고차 기능은 무엇이며 어떻게 간결하고 재사용 가능한 코드를 작성하는 데 어떻게 사용할 수 있습니까?
Mar 18, 2025 pm 01:44 PM
JavaScript의 고차 기능은 추상화, 공통 패턴 및 최적화 기술을 통해 코드 간접성, 재사용 성, 모듈성 및 성능을 향상시킵니다.
 카레는 JavaScript에서 어떻게 작동하며 그 이점은 무엇입니까?
Mar 18, 2025 pm 01:45 PM
카레는 JavaScript에서 어떻게 작동하며 그 이점은 무엇입니까?
Mar 18, 2025 pm 01:45 PM
이 기사는 다중 연계 기능을 단일 연계 함수 시퀀스로 변환하는 기술 인 JavaScript의 카레에 대해 논의합니다. Currying의 구현, 부분 응용 프로그램 및 실제 용도와 같은 혜택, 코드 읽기 향상을 탐색합니다.
 Connect ()를 사용하여 React 구성 요소를 Redux 상점에 어떻게 연결합니까?
Mar 21, 2025 pm 06:23 PM
Connect ()를 사용하여 React 구성 요소를 Redux 상점에 어떻게 연결합니까?
Mar 21, 2025 pm 06:23 PM
기사는 Connect ()를 사용하여 React 구성 요소를 Redux Store에 연결하고 MapStateToprops, MapDispatchtoprops 및 성능 영향을 설명합니다.
 usecontext는 무엇입니까? 구성 요소간에 상태를 공유하는 데 어떻게 사용합니까?
Mar 19, 2025 pm 03:59 PM
usecontext는 무엇입니까? 구성 요소간에 상태를 공유하는 데 어떻게 사용합니까?
Mar 19, 2025 pm 03:59 PM
이 기사는 REACT의 USECONTEXT를 설명하며, 이는 PROP 시추를 피함으로써 상태 관리를 단순화합니다. 중앙 집중식 상태 및 성능 개선과 같은 렌더링을 통해 성능 향상과 같은 이점에 대해 논의합니다.
 이벤트 핸들러의 기본 동작을 어떻게 방지합니까?
Mar 19, 2025 pm 04:10 PM
이벤트 핸들러의 기본 동작을 어떻게 방지합니까?
Mar 19, 2025 pm 04:10 PM
기사에서는 extentdefault () 메서드를 사용하여 이벤트 처리기의 기본 동작 방지, 향상된 사용자 경험과 같은 이점 및 접근성 문제와 같은 잠재적 문제에 대해 논의합니다.
 제어 및 제어되지 않은 구성 요소의 장점과 단점은 무엇입니까?
Mar 19, 2025 pm 04:16 PM
제어 및 제어되지 않은 구성 요소의 장점과 단점은 무엇입니까?
Mar 19, 2025 pm 04:16 PM
이 기사는 예측 가능성, 성능 및 사용 사례와 같은 측면에 중점을 둔 React의 제어 및 통제되지 않은 구성 요소의 장단점에 대해 설명합니다. 그것은 그들 사이에서 선택할 때 고려해야 할 요소에 대해 조언합니다.
