

Oracle 인터뷰 질문 및 답변 구성


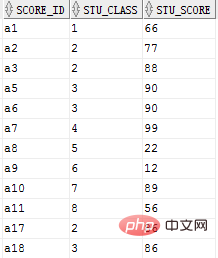
다음 질문은 이 테이블에 따라 변환됩니다
1. 테이블: table1(FId, Fclass, Fscore), 가장 효율적이고 간단한 SQL을 사용하여 각 클래스의 최고 점수 목록을 나열합니다. 클래스와 두 개의 점수 필드를 표시합니다.
select stu_class, max(stu_score) from core group by stu_class ;
2 두 개의 필드 FID와 Fno가 있는 테이블 table1이 있는데 둘 다 비어 있지 않습니다. 테이블의 여러 Fno에 해당하는 하나의 FID 레코드를 나열하는 SQL 문을 작성하세요.
select t2.* from table1 t1, table1 t2 where t1.fid = t2.fid and t1.fno <> t2.fno;
작성하는 세 가지 방법:
select * from core co1 where co1.STU_CLASS in ( select co.STU_CLASS from CORE co group by co.STU_CLASS having count(co.STU_CLASS) >1); select DISTINCT c2.* from core c1 ,core c2 where c1.STU_CLASS = c2.STU_CLASS and c1.STU_SCORE <> c2.STU_SCORE; SELECT * FROM core c1 where 1=1 and EXISTS (select 1 from core c2 where c1.STU_CLASS = c2.STU_CLASS and c1.STU_SCORE <> c2.STU_SCORE);
3. 직원 테이블이 있습니다. empinfo
( Fempno varchar2(10) not null pk, Fempname varchar2(20) not null, Fage number not null, Fsalary number not null );
데이터의 양이 매우 큰 경우 약 1천만 개 정도가 가장 효율적이라고 생각되는 SQL을 작성하고 사용하세요. 다음 네 가지 유형의 사람을 계산하는 하나의 SQL:
fsalary>9999 and fage > 35 fsalary>9999 and fage < 35 fsalary <9999 and fage > 35 fsalary <9999 and fage < 35
직원 유형별 수
select sum(case when fsalary > 9999 and fage > 35then 1else 0end) as "fsalary>9999_fage>35",sum(case when fsalary > 9999 and fage < 35then 1else 0end) as "fsalary>9999_fage<35",sum(case when fsalary < 9999 and fage > 35then 1else 0end) as "fsalary<9999_fage>35",sum(case when fsalary < 9999 and fage < 35then 1else 0end) as "fsalary<9999_fage<35"from empinfo;
select sum(case when stu_score < 60 then 1 else 0 end ) as "60分以下人数" ,sum(case when stu_score > 60 and stu_score <= 70 then 1 else 0 end ) as "60到70分人数" ,sum(case when stu_score > 70 and stu_score <= 80 then 1 else 0 end ) as "70到80分人数" ,sum(case when stu_score > 80 and stu_score <= 100 then 1 else 0 end ) as "80分以上人数" from core;
4. 표 A의 필드는 다음과 같습니다. 매월 및 전월의 사무실 소유자(인원을 구분하지 않음)의 SQL 문(1개임)입니다.
필수 목록 출력은 month person income 당월 수입 지난 달 다음 달 수입입니다. 소득
MONTHS PERSON INCOME ---------- ---------- ----------200807 mantisXF 5000200806 mantisXF2 3500200806 mantisXF3 3000200805 mantisXF1 2000200805 mantisXF6 2200200804 mantisXF7 1800200803 8mantisXF 4000200802 9mantisXF 4200200802 10mantisXF 3300200801 11mantisXF 4600200809 11mantisXF 6800
11행 선택됨
months, (incomes), (prev_months), (( ), ), ), lag(incomes) ( months), ) prev_months, decode(lead(months) ( months), to_char(add_months(to_date(months, ), ), ), lead(incomes) ( months), ) next_months ( months, (income) incomes a months) aa) aaagroup (INCOMES) (PREV_MONTHS) (NEXT_MONTHS)
5, 테이블 B C1 c2
2005-01-01 1
2005-01-01 32005-01-02 5
필수자료
2005-01-01 4
2005-01-02 5
SQL 문을 사용하여 완료하세요.
select nvl(to_char(t02,'yyyy-mm-dd'),'合计'),sum(t01)from test group by rollup(t02)
6, 데이터베이스 1, 2, 3 패러다임의 개념과 이해.
관계형 데이터베이스를 설계할 때는 특정 규칙을 따라야 합니다. 특히 데이터베이스 설계 패러다임 1NF(첫 번째 정규형), 2NF(두 번째 정규형), 3NF(세 번째 정규형),
첫 번째 정규형(1NF)에 대한 간략한 소개: 관계형 스키마 R의 각 특정 관계 r에서, 각 속성 값이 더 이상 나눌 수 없는 데이터의 가장 작은 단위인 경우 R은 제1정규형 관계라고 합니다.
예: 예를 들어 사원번호, 이름, 전화번호가 테이블을 구성합니다(사람은 사무실 전화번호와 집 전화번호를 가질 수 있음). 이를 1NF로 표준화하는 방법은 세 가지가 있습니다.
하나는 반복적으로 저장하는 것입니다. 직원 번호와 이름. 이 경우 키워드는 전화번호만 가능합니다.
둘째, 사원번호가 키워드이고, 전화번호는 직장 전화번호와 거주지 전화번호 두 가지 속성으로 구분됩니다.
위의 세 가지 방법 중 첫 번째 방법은 실제 상황에 따라 후자의 두 가지 경우를 선택하는 것이 가장 바람직하지 않습니다.
두 번째 정규형(2NF): 관계 스키마 R(U, F)의 모든 비기본 속성이 후보 키워드에 완전히 종속되는 경우 관계 R은 두 번째 정규형에 속한다고 합니다.
예: 과목 선택 관계 SCI(SNO, CNO, GRADE, CREDIT) 여기서 SNO는 학번, CNO는 과목 번호, GRADEGE는 성적, CREDIT는 학점입니다. 위 조건을 기준으로 키워드가 결합된 키워드(SNO, CNO)입니다. 위의 관계 모델을 응용 프로그램에서 사용하면 다음과 같은 문제가 있습니다.
a. 동일한 과목을 40명의 학생이 이수한다고 가정하면, 40회 반복됩니다.
b. 업데이트 이상. 과목의 학점이 조정되면 해당 튜플 CREDIT 값이 업데이트되며, 동일한 과목의 학점이 다를 수 있습니다.
c. 예외 삽입. 예를 들어, 새로운 과목을 개설하려는 경우, 수강하는 사람이 없고 학생 ID 키워드도 없기 때문에 수강할 때까지 과목과 학점만 입금할 수 있습니다.
d. 삭제 예외. 학생이 과정을 완료한 경우 현재 데이터베이스에서 선택 기록을 삭제합니다. 신입생이 아직 수강하지 않은 과목이 있을 경우 해당 과목 및 학점기록이 저장되지 않습니다.
예: S1(SNO, SNAME, DNO, DNAME, LOCATION)과 같은 각 속성은 학생 번호,이유: 키워드가 아닌 속성인 CREDIT는 기능적으로만 CNO에 종속됩니다. 즉, CREDIT는 완전히 결합된 키워드(SNO, CNO)에 종속되지 않고 부분적으로 종속됩니다.
해결 방법: SC1(SNO, CNO, GRADE), C2(CNO, CREDIT)의 두 가지 관계 모드로 나눕니다. 새로운 관계에는 SCN의 외래 키워드 CNO를 통해 연결되는 두 개의 관계 패턴이 포함되며, 필요할 경우 자연스럽게 연결되어 원래의 관계를 복원합니다(3NF): 관계 패턴 R(U, All non- F)의 기본 속성이 후보 키워드에 전이적 종속성을 가지지 않으면 관계 R은 세 번째 정규형에 속한다고 합니다.
이름, 부서, 부서 이름 및 부서 주소를 나타냅니다.
SNO라는 키워드가 각 속성을 결정합니다. 단일 키워드이므로 부분의존 문제가 없으므로 2NF가 되어야 한다. 하지만 이 관계에는 학생의 위치와 관련된 여러 속성인 DNO, DNAME, LOCATION이 저장, 삽입, 삭제, 수정을 반복하게 되어 위의 예와 유사한 상황이 발생하게 됩니다.원인: 관계에 전이적 종속성이 있습니다. SNO -> DNO 입니다. 하지만 DNO -> SNO는 존재하지 않습니다. DNO -> LOCATION이므로 SNO와 LOCATIO가 중요합니다
N 函数决定是通过传递依赖 SNO -> LOCATION 实现的。也就是说,SNO不直接决定非主属性LOCATION。
解决目地:每个关系模式中不能留有传递依赖。
解决方法:分为两个关系 S(SNO,SNAME,DNO),D(DNO,DNAME,LOCATION)
注意:关系S中不能没有外关键字DNO。否则两个关系之间失去联系。
7,简述oracle行触发器的变化表限制表的概念和使用限制,行触发器里面对这两个表有什么限制。
变化表mutating table
被DML语句正在修改的表
需要作为DELETE CASCADE参考完整性限制的结果进行更新的表也是变化的
限制:对于Session本身,不能读取正在变化的表
限制表constraining table
需要对参考完整性限制执行读操作的表
限制:如果限制列正在被改变,那么读取或修改会触发错误,但是修改其它列是允许的。
8、oracle临时表有几种。
临时表和普通表的主要区别有哪些,使用临时表的主要原因是什么?
在Oracle中,可以创建以下两种临时表:
a。会话特有的临时表
CREATE GLOBAL TEMPORARY ( ) ON COMMIT PRESERVE ROWS;
b。事务特有的临时表
CREATE GLOBAL TEMPORARY ( ) ON COMMIT DELETE ROWS; CREATE GLOBAL TEMPORARY TABLE MyTempTable
所建的临时表虽然是存在的,但是你试一下insert 一条记录然后用别的连接登上去select,记录是空的,明白了吧。
下面两句话再贴一下:
ON COMMIT DELETE ROWS说明临时表是事务指定,每次提交后ORACLE将截断表(删除全部行)ON COMMIT PRESERVE ROWS说明临时表是会话指定,当中断会话时ORACLE将截断表。
9,怎么实现:使一个会话里面执行的多个过程函数或触发器里面都可以访问的全局变量的效果,并且要实现会话间隔离?
--个人理解就是建立一个包,将常量或所谓的全局变量用包中的函数返回出来就可以了,摘抄一短网上的解决方法Oracle数据库程序包中的变量,在本程序包中可以直接引用,但是在程序包之外,则不可以直接引用。对程序包变量的存取,可以为每个变量配套相应的存储过程<用于存储数据>和函数<用于读取数据>来实现。 3.2 实例 --定义程序包 create or replace package PKG_System_Constant is C_SystemTitle nVarChar2(100):='测试全局程序变量'; --定义常数 --获取常数<系统标题> Function FN_GetSystemTitle Return nVarChar2; G_CurrentDate Date:=SysDate; --定义全局变量 --获取全局变量<当前日期> Function FN_GetCurrentDate Return Date; --设置全局变量<当前日期> Procedure SP_SetCurrentDate (P_CurrentDate In Date); End PKG_System_Constant; / create or replace package body PKG_System_Constant is --获取常数<系统标题> Function FN_GetSystemTitle Return nVarChar2 Is Begin Return C_SystemTitle; End FN_GetSystemTitle; --获取全局变量<当前日期> Function FN_GetCurrentDate Return Date Is Begin Return G_CurrentDate; End FN_GetCurrentDate; --设置全局变量<当前日期> Procedure SP_SetCurrentDate (P_CurrentDate In Date) Is Begin G_CurrentDate:=P_CurrentDate; End SP_SetCurrentDate; End PKG_System_Constant; / 3.3 测试 --测试读取常数 Select PKG_System_Constant.FN_GetSystemTitle From Dual; --测试设置全局变量 Declare Begin PKG_System_Constant.SP_SetCurrentDate(To_Date('2001.01.01','yyyy.mm.dd')); End; / --测试读取全局变量 Select PKG_System_Constant.FN_GetCurrentDate From Dual;
10,aa,bb表都有20个字段,且记录数量都很大,aa,bb表的X字段(非空)上有索引,
请用SQL列出aa表里面存在的X在bb表不存在的X的值,请写出认为最快的语句,并解译原因。
select aa.x from aa where not exists (select 'x' from bb where aa.x = bb.x) ;
以上语句同时使用到了aa中x的索引和的bb中x的索引
11,简述SGA主要组成结构和用途?
SGA是Oracle为一个实例分配的一组共享内存缓冲区,它包含该实例的数据和控制信息。SGA在实例启动时被自动分配,当实例关闭时被收回。数据库的所有数据操作都要通过SGA来进行。
SGA中内存根据存放信息的不同,可以分为如下几个区域:
a.Buffer Cache:存放数据库中数据库块的拷贝。它是由一组缓冲块所组成,这些缓冲块为所有与该实例相链接的用户进程所共享。缓冲块的数目由初始化参数DB_BLOCK_BUFFERS确定,缓冲块的大小由初始化参数DB_BLOCK_SIZE确定。大的数据块可提高查询速度。它由DBWR操作。
b. 日志缓冲区Redo Log Buffer:存放数据操作的更改信息。它们以日志项(redo entry)的形式存放在日志缓冲区中。当需要进行数据库恢复时,日志项用于重构或回滚对数据库所做的变更。日志缓冲区的大小由初始化参数LOG_BUFFER确定。大的日志缓冲区可减少日志文件I/O的次数。后台进程LGWR将日志缓冲区中的信息写入磁盘的日志文件中,可启动ARCH后台进程进行日志信息归档。
c. 共享池Shared Pool:包含用来处理的SQL语句信息。它包含共享SQL区和数据字典存储区。共享SQL区包含执行特定的SQL语句所用的信息。数据字典区用于存放数据字典,它为所有用户进程所共享。
12什么是分区表?简述范围分区和列表分区的区别,分区表的主要优势有哪些?
使用分区方式建立的表叫分区表
范围分区
每个分区都由一个分区键值范围指定(对于一个以日期列作为分区键的表,“2005 年 1 月”分区包含分区键值为从“2005 年 1 月 1 日”
到“2005 年 1 月 31 日”的行)。
列表分区
每个分区都由一个分区键值列表指定(对于一个地区列作为分区键的表,“北美”分区可能包含值“加拿大”“美国”和“墨西哥”)。
分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务。通过分区,数据库设计人员和管理员能够解决前沿应用程序带来的一些难题。分区是构建千兆字节数据系统或超高可用性系统的关键工具。
13. 배경: archivelog에서 특정 데이터가 실행되고 있으며 RMAN을 사용하여 데이터베이스의 전체 백업 및 콜드 백업을 수행했습니다.
이제 모든 아카이브 로그가 손상되었으며 다른 모든 파일도 있습니다. 그대로 데이터베이스를 복원하는 방법, 한두 가지 방법을 알려주십시오.
답장 방법:
1. 콜드 백업을 사용하고 모든 콜드 백업 파일을 원본 디렉터리에 직접 복사한 다음 데이터베이스를 다시 시작합니다.
2. 아카이브 로그를 사용하여
NOMOUNT 데이터베이스 시작
- backup controlfile Until cancel 명령을 사용하여 RECOVER DATABASE를 사용하여 데이터베이스를 복원할 수 있습니다.
- ALETER DATABASE. OPEN RESETLOGS;
- 데이터베이스 및 제어 파일을 다시 백업하세요
관련 학습 권장 사항:
[특별 권장 사항]:
위 내용은 Oracle 인터뷰 질문 및 답변 구성의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7529
7529
 15
1378
52
81
11
54
19
21
75
15
1378
52
81
11
54
19
21
75

 Oracle에서 사용자와 역할을 어떻게 생성합니까?
Mar 17, 2025 pm 06:41 PM
Oracle에서 사용자와 역할을 어떻게 생성합니까?
Mar 17, 2025 pm 06:41 PM
이 기사는 SQL 명령을 사용하여 Oracle에서 사용자 및 역할을 만드는 방법을 설명하고 최소 특권의 원칙 및 정기 감사에 따라 역할 사용을 포함하여 사용자 권한을 관리하는 모범 사례에 대해 설명합니다.
 투명한 데이터 암호화 (TDE)를 사용하여 Oracle에서 암호화를 어떻게 구성합니까?
Mar 17, 2025 pm 06:43 PM
투명한 데이터 암호화 (TDE)를 사용하여 Oracle에서 암호화를 어떻게 구성합니까?
Mar 17, 2025 pm 06:43 PM
이 기사는 Oracle에서 투명한 데이터 암호화 (TDE)를 구성하고 지갑 생성을 자세히 설명하고 TDE를 활성화하고 다양한 수준에서 데이터 암호화를위한 단계를 간략하게 설명합니다. 또한 데이터 보호 및 규정 준수와 같은 TDE의 이점, Veri의 방법에 대해서도 설명합니다.
 최소한의 가동 중지 시간으로 Oracle에서 온라인 백업을 어떻게 수행합니까?
Mar 17, 2025 pm 06:39 PM
최소한의 가동 중지 시간으로 Oracle에서 온라인 백업을 어떻게 수행합니까?
Mar 17, 2025 pm 06:39 PM
이 기사는 RMAN을 사용하여 최소한의 가동 중지 시간으로 Oracle에서 온라인 백업을 수행하는 방법, 다운 타임을 줄이고 데이터 일관성을 보장하며 백업 진행 상황을 모니터링하기위한 모범 사례에 대해 설명합니다.
 Oracle에서 자동 워크로드 리포지토리 (AWR) 및 ADDM (Automatic Database Diagnostic Monitor)을 어떻게 사용합니까?
Mar 17, 2025 pm 06:44 PM
Oracle에서 자동 워크로드 리포지토리 (AWR) 및 ADDM (Automatic Database Diagnostic Monitor)을 어떻게 사용합니까?
Mar 17, 2025 pm 06:44 PM
이 기사는 데이터베이스 성능 최적화에 Oracle의 AWR 및 ADDM을 사용하는 방법을 설명합니다. AWR 보고서를 생성 및 분석하고 ADDM을 사용하여 성능 병목 현상을 식별하고 해결합니다.
 Oracle PL/SQL Deep Dive : 마스터 링 절차, 기능 및 패키지
Apr 03, 2025 am 12:03 AM
Oracle PL/SQL Deep Dive : 마스터 링 절차, 기능 및 패키지
Apr 03, 2025 am 12:03 AM
Oraclepl/SQL의 절차, 기능 및 패키지는 각각 작업, 반환 값 및 구성 코드를 구성하는 데 사용됩니다. 1. 프로세스는 출력 인사와 같은 작업을 수행하는 데 사용됩니다. 2. 함수는 두 숫자의 합계와 같은 값을 계산하고 반환하는 데 사용됩니다. 3. 패키지는 관련 요소를 구성하고 재고를 관리하는 패키지와 같은 코드의 모듈성 및 유지 가능성을 향상시키는 데 사용됩니다.
 Oracle Goldengate : 실시간 데이터 복제 및 통합
Apr 04, 2025 am 12:12 AM
Oracle Goldengate : 실시간 데이터 복제 및 통합
Apr 04, 2025 am 12:12 AM
OracleGoldengate는 소스 데이터베이스의 트랜잭션 로그를 캡처하고 대상 데이터베이스에 변경 사항을 적용하여 실시간 데이터 복제 및 통합을 가능하게합니다. 1) 변경 사항 캡처 : 소스 데이터베이스의 트랜잭션 로그를 읽고 트레일 파일로 변환합니다. 2) 전송 변경 : 네트워크를 통해 대상 시스템으로의 전송 및 데이터 펌프 프로세스를 사용하여 전송이 관리됩니다. 3) 응용 프로그램 변경 : 대상 시스템에서 복사 프로세스는 트레일 파일을 읽고 변경 사항을 적용하여 데이터 일관성을 보장합니다.
 Oracle Data Guard에서 전환 및 장애 조절 작업을 수행하려면 어떻게해야합니까?
Mar 17, 2025 pm 06:37 PM
Oracle Data Guard에서 전환 및 장애 조절 작업을 수행하려면 어떻게해야합니까?
Mar 17, 2025 pm 06:37 PM
이 기사는 Oracle Data Guard의 전환 및 장애 조치에 대한 절차를 자세히 설명하여 데이터 손실을 최소화하고 원활한 작업을 보장하기 위해 차이점, 계획 및 테스트를 강조합니다.
 Oracle의 테이블 스페이스 크기를 확인하는 방법
Apr 11, 2025 pm 08:15 PM
Oracle의 테이블 스페이스 크기를 확인하는 방법
Apr 11, 2025 pm 08:15 PM
Oracle 테이블 스페이스 크기를 쿼리하려면 다음 단계를 따르십시오. 쿼리를 실행하여 테이블 스페이스 이름을 결정하십시오. 쿼리를 실행하여 테이블 스페이스 크기를 쿼리하십시오. sum (bytes)을 total_size, sum (bytes_free)으로 sum (bytes_free), sum (bytes) - sum (bytes_free)으로 dba_data_fices where tablespace_.
