

mysql 마스터-슬레이브 동기화란 무엇입니까?

MySQL 마스터-슬레이브 동기화는 백업을 의미합니다. 마스터 라이브러리(Master)는 자체 라이브러리의 쓰기를 슬레이브 라이브러리(Slave)에 동기화합니다. 마스터 라이브러리에서 예측할 수 없는 상황이 발생하면 전체 서버를 사용할 수 없습니다. 슬레이브 데이터베이스에도 데이터 복사본이 있으므로 데이터 손실을 유발하거나 줄이지 않고 데이터를 신속하게 복원할 수 있습니다.

mysql 마스터-슬레이브 동기화란 무엇입니까?
마스터 데이터베이스의 데이터가 변경되면 변경 사항이 실시간으로 슬레이브 데이터베이스에 동기화됩니다.
데이터는 애플리케이션의 중요한 부분입니다. 마스터-슬레이브 동기화는 목적상 약간의 백업 의미가 있습니다. 마스터 라이브러리(Master)는 자체 라이브러리에 있는 쓰기를 슬레이브 라이브러리(Slave)에 동시에 동기화합니다. 전체 서버를 사용할 수 없게 된 경우, 슬레이브 데이터베이스에도 데이터의 복사본이 있기 때문에 데이터 손실을 유발하거나 줄이지 않고 빠르게 데이터를 복원할 수 있습니다.
물론 이것은 첫 번째 레벨에 불과합니다. 마스터-슬레이브 라이브러리의 역할이 이에 국한된다면 개인적으로 데이터베이스를 두 개로 나눌 필요는 없다고 생각합니다. 콘텐츠를 스냅샷으로 다른 서버에 전송하거나, 작성된 콘텐츠를 작성할 때마다 실시간으로 다른 서버로 전송하면 자원 절약뿐만 아니라 재해 복구 및 백업 목적에도 도움이 된다면 좋지 않을까요?물론 마스터-슬레이브 동기화의 역할은 이에 국한될 수 없습니다. 마스터-슬레이브 구조를 구성하면 일반적으로 슬레이브 노드가 백업 데이터베이스 역할만 하도록 두지 않습니다. 그에 따라 분리( MyCat이나 다른 미들웨어를 사용할 수 있고, 직접 배울 수도 있습니다. 이에 대해서는 다음 MyCat 블로그에서 다루겠습니다. 조금 길 수 있으므로 따로 작성하겠습니다.)
실제 환경에서는 데이터베이스에 대한 읽기 작업 수가 데이터베이스에 대한 쓰기 작업 수보다 훨씬 많기 때문에 마스터가 쓰기 기능만 제공하도록 하고 모든 읽기 작업을 슬레이브 데이터베이스로 옮길 수 있습니다. . 우리가 흔히 말하는 읽기와 쓰기를 분리하는이것은 마스터의 부담을 줄일 수 있을 뿐만 아니라 재해 복구 백업도 제공하여 일석이조를 제공합니다.
마스터-슬레이브 동기화의 이점은 무엇인가요?- 데이터베이스의 로드 용량을 수평으로 확장합니다.
- 내결함성, 고가용성. 장애 조치/고가용성
- 데이터 백업.
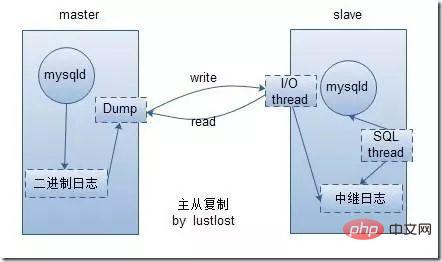
I/0 스레드: 이 스레드는 마스터 시스템의 binlog가 슬레이브로 전송되면 IO 스레드가 로컬 릴레이 로그(릴레이 로그)에 로그 내용을 기록합니다. .
SQL 스레드: 이 스레드는 릴레이 로그의 내용을 읽고 릴레이 로그의 내용을 기반으로 슬레이브 데이터베이스에서 해당 작업을 수행합니다.
가능한 문제: 쓰기 요청이 많은 경우 슬레이브 데이터와 마스터 데이터가 일치하지 않을 수 있습니다. 이는 로그 전송 프로세스가 짧게 지연되거나 쓰기 명령이 많기 때문입니다. 시스템 속도 불일치로 인해 발생합니다.
Master:IP :192.168.43.201 Port:3306 Slave1:IP:192.168.43.202 Port:3306 Slave2:IP:192.168.43.203 Port:3306
#该配置为Master的配置 server-id=201 #Server id 每台MySQL的必须不同 log-bin=/var/lib/mysql/mysql-bin.log #代表开启binlog日志 expire_logs_days=10 #日志过期时间 max_binlog_size=200M #日志最大容量 binlog_ignore_db=mysql #忽略mysql库,表示不同步此库
#该配置为Slave的配置,第二台Slave也是这么配置,不过要修改一下server-id server-id=202 expire_logs_days=10 #日志的缓存时间 max_binlog_size=200M #日志的最大大小 replicate_ignore_db=mysql #忽略同步的数据库
사용자 생성 'Slave'@'%' '123456'으로 식별;create user 'Slave'@'%' identified by '123456';
给新创建的用户赋权:grant replication slave on '*.*' to 'Slave'@'%';새로 생성된 사용자 부여: '*.*'의 복제 슬레이브를 'Slave'@'%'에 부여;
마스터 노드 상태 보기
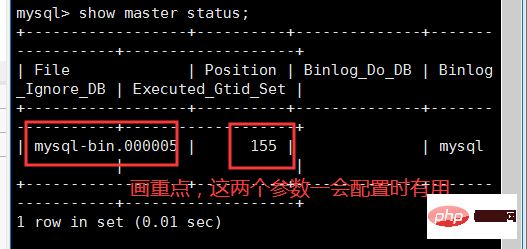
위 작업에 문제가 없으면 클라이언트에 show master status를 입력하여 마스터의 binlog 로그를 봅니다.
配置两个Slave节点
打开两个Slave节点客户端,在我们的另外两个Slave节点中输入如下命令:
change master to master_user='Slave',master_password='123456',master_host='192.168.43.201',master_log_file='mysql-bin.000005',master_log_pos=155,get_master_public_key=1; #注意,这里的master_log_file,就是binlog的文件名,输入上图中的mysql-bin.000005,每个人的都可能不一样。 #注意,这里的master_log_pos是binlog偏移量,输入上图中的155,每个人的都可能不一样。
配置完成后,输入start slave;开启从节点,然后输入show slave status\G;查看从节点状态
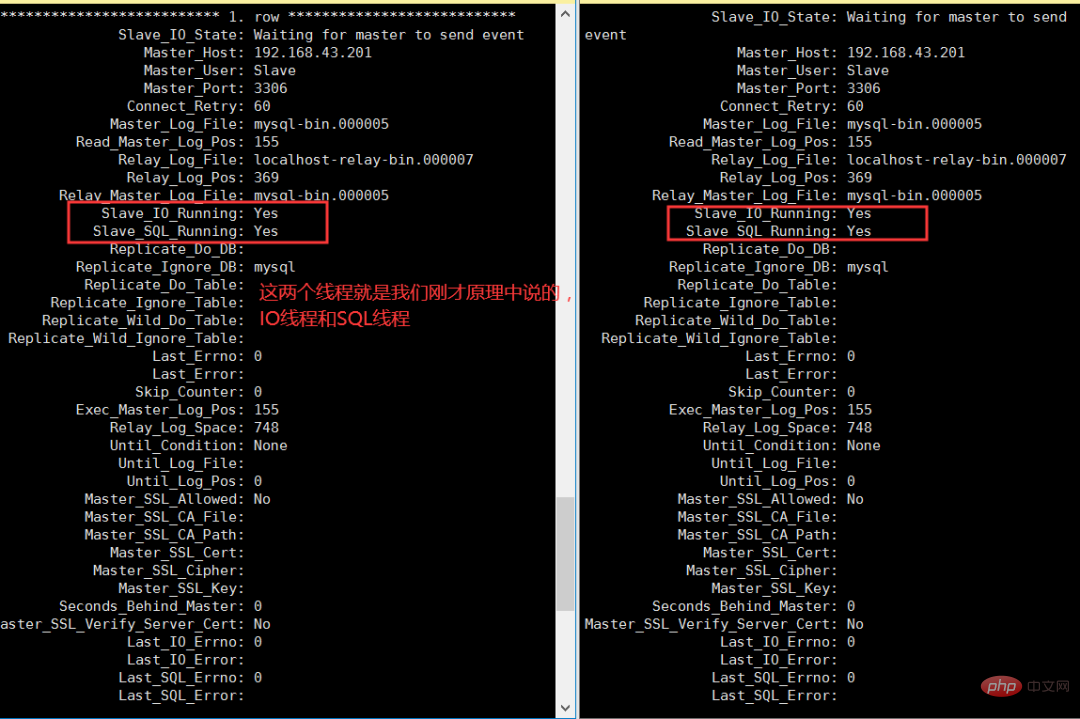
可以看到,在两台Slave的状态中,我们能亲眼看到IO线程和SQL线程的运行状态,这两个线程必须都是yes,才算配置搭建完成。
搭建完成
通过上述步骤,就完成了MySQL主从同步的搭建,相对Redis而言MySQL配置相当简单。下面我们可以进行测试。
先看看三个MySQL的数据库状态:SHOW DATABASES;

可以看到现在数据库都是初始默认状态,没有任何额外的库。
在Master节点中创建一个数据库,库名可以自己设置。
CREATE DATABASE testcluster;
<img class="has lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/024/fefa55750f9a4ddaec29168c6cc022e9-4.png" alt="">
可以看到,在Slave中也出现了Master中创建的数据库,说明我们的配置没有问题,主从搭建成功。这里就不再创建表了,大家可以自己试试,创建表再往表中插入数据,也是没有任何问题的。
注意事项
如果出现IO线程一直在Connecting状态,可以看看是不是三台机器无法相互连接,如果可以相互连接,那么有可能是Slave账号密码写错了,重新关闭Slave然后输入上面的配置命令再打开Slave即可。
如果出现SQL线程为NO状态,那么有可能是从数据库和主数据库的数据不一致造成的,或者事务回滚,如果是后者,先关闭Slave,然后先查看master的binlog和position,然后输入配置命令,再输入set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;,再重新start slave;即可,如通过是前者,那么就排查一下是不是存在哪张表没有被同步,是否存在主库存在而从库不存在的表,自己同步一下再重新配置一遍即可。
结语
在写这篇文章之前自己也被一些计算机领域的“名词”吓到过,相信有不少同学都有一样的体会,碰上某些高大上的名词总是先被吓到,例如像“分布式”、“集群”等等等等,甚至在没接触过nginx之前,连”负载均衡“、”反向代理“这样的词都让人觉得,这么高达上的词,肯定很难吧,但其实自己了解了nginx、ribbon等之后才发现,其实也就那么回事吧,没有想象中的那么难。
所以写这篇文章的初衷是想让大家对集群化或者分布式或者其他的一些技术或者解决方案不要有一种望而却步的感觉(感觉计算机领域的词都有这么一种特点,词汇高大上,但是其实思想是比较好理解的),其实自己手动配置出一个简单的集群并没有那么难。
如果学会docker之后再来配置就更加简单了,但是更希望不要只局限于会配置,配置出来的东西只能说你会配置了,但是在这层配置底下是前人做了相当多的工作,才能使我们通过简单配置就能实现一些功能,应该要深入底层,了解配置下面的工作原理,这个才是最重要的,也是体现一个程序员水平的地方。
推荐教程:mysql视频教程
위 내용은 mysql 마스터-슬레이브 동기화란 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7642
7642
 15
1392
52
91
11
72
19
33
150
15
1392
52
91
11
72
19
33
150

 phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
phpmyadmin을 여는 방법
Apr 10, 2025 pm 10:51 PM
다음 단계를 통해 phpmyadmin을 열 수 있습니다. 1. 웹 사이트 제어판에 로그인; 2. phpmyadmin 아이콘을 찾고 클릭하십시오. 3. MySQL 자격 증명을 입력하십시오. 4. "로그인"을 클릭하십시오.
 MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL : 세계에서 가장 인기있는 데이터베이스 소개
Apr 12, 2025 am 12:18 AM
MySQL은 오픈 소스 관계형 데이터베이스 관리 시스템으로, 주로 데이터를 신속하고 안정적으로 저장하고 검색하는 데 사용됩니다. 작업 원칙에는 클라이언트 요청, 쿼리 해상도, 쿼리 실행 및 반환 결과가 포함됩니다. 사용의 예로는 테이블 작성, 데이터 삽입 및 쿼리 및 조인 작업과 같은 고급 기능이 포함됩니다. 일반적인 오류에는 SQL 구문, 데이터 유형 및 권한이 포함되며 최적화 제안에는 인덱스 사용, 최적화 된 쿼리 및 테이블 분할이 포함됩니다.
 단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
단일 스레드 레 디스를 사용하는 방법
Apr 10, 2025 pm 07:12 PM
Redis는 단일 스레드 아키텍처를 사용하여 고성능, 단순성 및 일관성을 제공합니다. 동시성을 향상시키기 위해 I/O 멀티플렉싱, 이벤트 루프, 비 블로킹 I/O 및 공유 메모리를 사용하지만 동시성 제한 제한, 단일 고장 지점 및 쓰기 집약적 인 워크로드에 부적합한 제한이 있습니다.
 MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
MySQL의 장소 : 데이터베이스 및 프로그래밍
Apr 13, 2025 am 12:18 AM
데이터베이스 및 프로그래밍에서 MySQL의 위치는 매우 중요합니다. 다양한 응용 프로그램 시나리오에서 널리 사용되는 오픈 소스 관계형 데이터베이스 관리 시스템입니다. 1) MySQL은 웹, 모바일 및 엔터프라이즈 레벨 시스템을 지원하는 효율적인 데이터 저장, 조직 및 검색 기능을 제공합니다. 2) 클라이언트 서버 아키텍처를 사용하고 여러 스토리지 엔진 및 인덱스 최적화를 지원합니다. 3) 기본 사용에는 테이블 작성 및 데이터 삽입이 포함되며 고급 사용에는 다중 테이블 조인 및 복잡한 쿼리가 포함됩니다. 4) SQL 구문 오류 및 성능 문제와 같은 자주 묻는 질문은 설명 명령 및 느린 쿼리 로그를 통해 디버깅 할 수 있습니다. 5) 성능 최적화 방법에는 인덱스의 합리적인 사용, 최적화 된 쿼리 및 캐시 사용이 포함됩니다. 모범 사례에는 거래 사용 및 준비된 체계가 포함됩니다
 MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL을 사용하는 이유는 무엇입니까? 혜택과 장점
Apr 12, 2025 am 12:17 AM
MySQL은 성능, 신뢰성, 사용 편의성 및 커뮤니티 지원을 위해 선택됩니다. 1.MYSQL은 효율적인 데이터 저장 및 검색 기능을 제공하여 여러 데이터 유형 및 고급 쿼리 작업을 지원합니다. 2. 고객-서버 아키텍처 및 다중 스토리지 엔진을 채택하여 트랜잭션 및 쿼리 최적화를 지원합니다. 3. 사용하기 쉽고 다양한 운영 체제 및 프로그래밍 언어를 지원합니다. 4. 강력한 지역 사회 지원을 받고 풍부한 자원과 솔루션을 제공합니다.
 Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache는 데이터베이스에 연결하여 다음 단계가 필요합니다. 데이터베이스 드라이버 설치. 연결 풀을 만들려면 Web.xml 파일을 구성하십시오. JDBC 데이터 소스를 작성하고 연결 설정을 지정하십시오. JDBC API를 사용하여 Connections, 명세서 작성, 매개 변수 바인딩, 쿼리 또는 업데이트 실행 및 처리를 포함하여 Java 코드의 데이터베이스에 액세스하십시오.
 Redis Exporter 서비스로 Redis 액 적을 모니터링하십시오
Apr 10, 2025 pm 01:36 PM
Redis Exporter 서비스로 Redis 액 적을 모니터링하십시오
Apr 10, 2025 pm 01:36 PM
Redis 데이터베이스의 효과적인 모니터링은 최적의 성능을 유지하고 잠재적 인 병목 현상을 식별하며 전반적인 시스템 신뢰성을 보장하는 데 중요합니다. Redis Exporter Service는 Prometheus를 사용하여 Redis 데이터베이스를 모니터링하도록 설계된 강력한 유틸리티입니다. 이 튜토리얼은 Redis Exporter Service의 전체 설정 및 구성을 안내하여 모니터링 솔루션을 원활하게 구축 할 수 있도록합니다. 이 자습서를 연구하면 완전히 작동하는 모니터링 설정을 달성 할 수 있습니다.
 SQL 데이터베이스 오류를 보는 방법
Apr 10, 2025 pm 12:09 PM
SQL 데이터베이스 오류를 보는 방법
Apr 10, 2025 pm 12:09 PM
SQL 데이터베이스 오류를 보는 방법은 다음과 같습니다. 1. 오류 메시지보기 직접; 2. 표시 오류 및 경고 명령을 사용하십시오. 3. 오류 로그에 액세스; 4. 오류 코드를 사용하여 오류의 원인을 찾으십시오. 5. 데이터베이스 연결 및 쿼리 구문을 확인하십시오. 6. 디버깅 도구를 사용하십시오.
