

웹 크롤러는 웹 스파이더라고도 합니다. 각 웹 사이트는 스파이더를 사용하여 원하는 리소스를 크롤링할 수 있습니다. 가장 간단한 예를 들자면, 바이두와 구글에 '파이썬'을 입력하면 수많은 파이썬 관련 웹페이지가 검색됩니다. 바이두와 구글은 어떻게 그 방대한 웹페이지에서 원하는 리소스를 검색하는 걸까요? 수많은 스파이더를 보내 웹 페이지를 크롤링하고, 키워드를 검색하고, 인덱스 데이터베이스를 구축하고, 복잡한 정렬 알고리즘을 거친 후 검색 키워드의 관련성에 따라 결과를 표시합니다.
천 마일의 여행도 한 걸음부터 시작됩니다. 가장 기본적인 것부터 웹 크롤러를 작성하는 방법을 배우고 Python을 사용하여 언어를 구현해 봅시다.
Python에서는 urllib 패키지를 사용하여 인터넷에 액세스합니다.
(Python3에서는 이 모듈이 크게 조정되었습니다. 예전에는 urllib와 urllib2가 있었습니다. Python 3에서는 이 두 모듈이 통합되어 병합되어 urllib 패키지라고 불렸습니다. 패키지에는 urllib.request, urllib.error라는 네 개의 모듈이 포함되어 있습니다. , urllib.parse, urllib.robotparser), 현재 주로 사용되는 것은 urllib.request입니다. 하지 말고 소스 코드에서 하지 마세요. 로컬에서는 Youdao Translation에 전화하여 작은 번역 소프트웨어를 작성하는 것입니다.
3.1 이미지 링크에 따라 이미지를 다운로드합니다. 코드는 다음과 같습니다.
import urllib.request response = urllib.request.urlopen('https://docs.python.org/3/') html = response.read()print(html.decode('utf-8'))
입력:
response.geturl() ->'http://www. 3lian.com/e/ ViewImg/index.html?url=http://img16.3lian.com/gif2016/w1/3/d/61.jpg'.client.HTTPMessage 객체(0x10591c0b8>
) ep 2004 01:23: 20 GMT. 날짜: 2016년 8월 14일 일요일 07:16:01 GMT
연결 )
3.1 Youdao 사전을 사용하여 번역 기능 구현
번역 기능을 구현하고 싶습니다. 요청 링크를 가져와야 합니다. 먼저 Youdao 홈페이지에 들어가서 번역을 클릭하고 번역 인터페이스에 번역할 내용을 입력한 다음 번역 버튼을 클릭하면 서버에 요청이 시작됩니다. 요청 주소와 정보를 가져오는 것뿐입니다. 요청 매개변수.
我在此使用谷歌浏览器实现拿到请求地址和请求参数。首先点击右键,点击检查(不同浏览器点击的选项可能不同,同一浏览器的不同版本也可能不同),进入图一所示,从中我们可以拿到请求请求地址和请求参数,在Header中的Form Data中我们可以拿到请求参数。
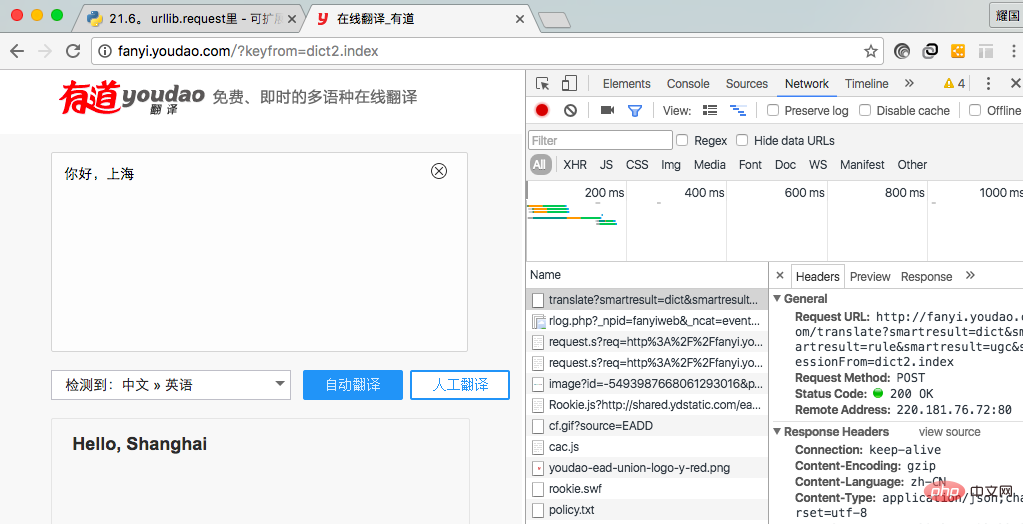
(图一)
代码段如下:
import urllib.requestimport urllib.parse
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'data = {}
data['type'] = 'AUTO'data['i'] = 'i love you'data['doctype'] = 'json'data['xmlVersion'] = '1.8'data['keyfrom'] = 'fanyi.web'data['ue'] = 'UTF-8'data['action'] = 'FY_BY_CLICKBUTTON'data['typoResult'] = 'true'data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url,data)
html = response.read().decode('utf-8')print(html)上述代码执行如下:
{"type":"EN2ZH_CN","errorCode":0,"elapsedTime":0,"translateResult":[[{"src":"i love you","tgt":"我爱你"}]],"smartResult":{"type":1,"entries":["","我爱你。"]}}
对于上述结果,我们可以看到是一个json串,我们可以对此解析一下,并且对代码进行完善一下:
import urllib.requestimport urllib.parseimport json
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'data = {}
data['type'] = 'AUTO'data['i'] = 'i love you'data['doctype'] = 'json'data['xmlVersion'] = '1.8'data['keyfrom'] = 'fanyi.web'data['ue'] = 'UTF-8'data['action'] = 'FY_BY_CLICKBUTTON'data['typoResult'] = 'true'data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url,data)
html = response.read().decode('utf-8')
target = json.loads(html)print(target['translateResult'][0][0]['tgt'])服务器检测出请求不是来自浏览器,可能会屏蔽掉请求,服务器判断的依据是使用‘User-Agent',我们可以修改改字段的值,来隐藏自己。代码如下:
import urllib.requestimport urllib.parseimport json
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'data = {}
data['type'] = 'AUTO'data['i'] = 'i love you'data['doctype'] = 'json'data['xmlVersion'] = '1.8'data['keyfrom'] = 'fanyi.web'data['ue'] = 'UTF-8'data['action'] = 'FY_BY_CLICKBUTTON'data['typoResult'] = 'true'data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36')
response = urllib.request.urlopen(url, data)
html = response.read().decode('utf-8')
target = json.loads(html)print(target['translateResult'][0][0]['tgt'])View Code
上述做法虽然可以隐藏自己,但是还有很大问题,例如一个网络爬虫下载图片软件,在短时间内大量下载图片,服务器可以可以根据IP访问次数判断是否是正常访问。所有上述做法还有很大的问题。我们可以通过两种做法解决办法,一是使用延迟,例如5秒内访问一次。另一种办法是使用代理。
延迟访问(休眠5秒,缺点是访问效率低下):
import urllib.requestimport urllib.parseimport jsonimport timewhile True:
content = input('please input content(input q exit program):') if content == 'q': break;
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'
data = {}
data['type'] = 'AUTO'
data['i'] = content
data['doctype'] = 'json'
data['xmlVersion'] = '1.8'
data['keyfrom'] = 'fanyi.web'
data['ue'] = 'UTF-8'
data['action'] = 'FY_BY_CLICKBUTTON'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36')
response = urllib.request.urlopen(url, data)
html = response.read().decode('utf-8')
target = json.loads(html) print(target['translateResult'][0][0]['tgt'])
time.sleep(5)View Code
代理访问:让代理访问资源,然后讲访问到的资源返回。服务器看到的是代理的IP地址,不是自己地址,服务器就没有办法对你做限制。
步骤:
1,参数是一个字典{'类型' : '代理IP:端口号' } //类型是http,https等
proxy_support = urllib.request.ProxyHandler({})
2,定制、创建一个opener
opener = urllib.request.build_opener(proxy_support)
3,安装opener(永久安装,一劳永逸)
urllib.request.install_opener(opener)
3,调用opener(调用的时候使用)
opener.open(url)
图片下载来源为煎蛋网(http://jandan.net)
图片下载的关键是找到图片的规律,如找到当前页,每一页的图片链接,然后使用循环下载图片。下面是程序代码(待优化,正则表达式匹配,IP代理):
import urllib.requestimport osdef url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0')
response = urllib.request.urlopen(req)
html = response.read() return htmldef get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']',a) return html[a:b]def find_image(url):
html = url_open(url).decode('utf-8')
image_addrs = []
a = html.find('img src=') while a != -1:
b = html.find('.jpg',a,a + 150) if b != -1:
image_addrs.append(html[a+9:b+4]) else:
b = a + 9
a = html.find('img src=',b) for each in image_addrs: print(each) return image_addrsdef save_image(folder,image_addrs): for each in image_addrs:
filename = each.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(each)
f.write(img)def download_girls(folder = 'girlimage',pages = 20):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url)) for i in range(pages):
page_num -= i
page_url = url + 'page-' + str(page_num) + '#comments'
image_addrs = find_image(page_url)
save_image(folder,image_addrs)if __name__ == '__main__':
download_girls() 代码运行效果如下: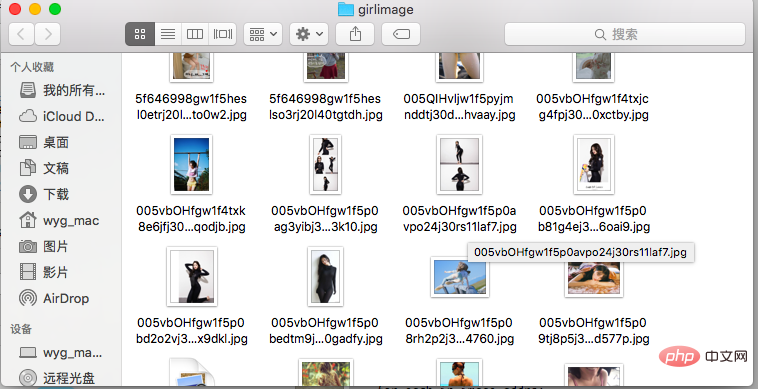
更多相关免费学习推荐:python视频教程
위 내용은 파이썬의 거미의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



