

Redis6.0에서 멀티스레딩을 도입하는 이유는 무엇입니까?

다음 칼럼에서는 Redis Tutorial 칼럼에서 Redis 6.0이 멀티스레딩을 도입한 이유를 소개하겠습니다. , 도움이 필요한 친구들에게 도움이 되길 바랍니다!

저자 소개: 그는 한때 Alibaba 및 Daily Youxian과 같은 인터넷 회사에서 기술 이사로 근무했습니다. 전자상거래 인터넷 경력 15년.
100일 전, Redis 작성자 antirez가 자신의 블로그(antirez.com)에 큰 소식을 발표했고, Redis 6.0이 정식 출시되었습니다. 가장 눈길을 끄는 변경 사항 중 하나는 Redis 6.0에 멀티스레딩이 도입되었다는 것입니다.
이 글은 크게 두 부분으로 나누어져 있습니다. 먼저 Redis가 6.0 이전에 단일 스레드 모델을 채택한 이유에 대해 이야기해 보겠습니다. 그럼 Redis6.0의 멀티스레딩에 대해 자세히 설명하겠습니다.

Redis가 6.0 이전에 단일 스레드 모델을 채택한 이유는 무엇입니까?
엄밀히 말하면 Redis 4.0 이후에는 단일 스레드가 아닙니다. 메인 스레드 외에도 쓸모없는 연결 해제, 큰 키 삭제 등과 같은 일부 느린 작업을 처리하는 일부 백그라운드 스레드도 있습니다.
싱글 스레드 모델, 성능이 왜 이렇게 높나요?
Redis 작성자는 디자인 초기부터 여러 측면을 고려했습니다. 궁극적으로 명령 처리를 위해 단일 스레드 모델을 사용하기로 선택되었습니다. 단일 스레드 모델을 선택하는 몇 가지 중요한 이유가 있습니다.
Redis 작업은 메모리를 기반으로 하며 대부분 작업의 성능 병목 현상은 CPU에 있지 않습니다.
단일 스레드 모델은 성능 문제를 방지합니다. 스레드 간 전환으로 인한 오버헤드
싱글 스레드 모델을 사용하면 클라이언트 요청도 동시에 처리할 수 있습니다(다중 I/O)
싱글 스레드 모델을 사용하면 유지 관리성이 높고 개발, 디버깅 및 유지 관리가 적습니다.
위에서 언급한 세 번째 이유는 Redis가 마침내 단일 스레드 모델을 채택하게 된 결정적인 요인입니다. 나머지 두 가지 이유는 단일 스레드 모델을 사용하는 경우의 추가 이점입니다. 여기서는 위의 이유를 순서대로 소개합니다. .
성능 병목 현상은 CPU에 있지 않습니다
다음 그림은 Redis 공식 홈페이지에서 가져온 싱글 스레드 모델에 대한 설명입니다. 일반적인 의미는 Redis의 병목 현상은 CPU가 아니라 주요 병목 현상이 메모리와 네트워크라는 것입니다. Linux 환경에서 Redis는 초당 100만 개의 요청을 제출할 수도 있습니다.

왜 Redis의 병목 현상은 CPU가 아니라고 하는 걸까요?
먼저 Redis의 작업은 대부분 메모리 기반이고 순수 kv(키-값) 작업이므로 명령 실행 속도가 매우 빠릅니다. Redis의 데이터는 큰 HashMap에 저장된다는 것을 대략적으로 이해할 수 있습니다. HashMap의 장점은 검색 및 쓰기의 시간 복잡도가 O(1)이라는 것입니다. Redis는 이 구조를 사용하여 내부적으로 데이터를 저장하며, 이는 Redis의 고성능을 위한 기반을 마련합니다. Redis 공식 웹사이트의 설명에 따르면 이상적인 상황에서 Redis는 초당 100만 개의 요청을 제출할 수 있으며 각 요청을 제출하는 데 필요한 시간은 나노초 정도입니다. 모든 Redis 작업은 매우 빠르고 단일 스레드로 완벽하게 처리할 수 있으므로 굳이 다중 스레드를 사용할 이유가 없습니다!
스레드 컨텍스트 전환 문제
또한 멀티 스레드 시나리오에서는 스레드 컨텍스트 전환이 발생합니다. 스레드는 CPU에 의해 예약됩니다. CPU의 한 코어는 시간 분할 내에서 동시에 하나의 스레드만 실행할 수 있습니다. CPU가 스레드 A에서 스레드 B로 전환하면 일련의 작업이 발생합니다. 주요 프로세스에는 실행 저장이 포함됩니다. 스레드 A의 장면을 로드한 다음 스레드 B의 실행 장면을 로드합니다. 이 프로세스가 "스레드 컨텍스트 전환"입니다. 여기에는 스레드 관련 명령어를 저장하고 복원하는 작업이 포함됩니다.
잦은 스레드 컨텍스트 전환으로 인해 성능이 급격히 저하될 수 있으며, 이로 인해 요청 처리 속도가 향상되지 않을 뿐만 아니라 성능도 저하됩니다. 이는 Redis가 멀티스레딩 기술에 대해 신중한 이유 중 하나입니다. .
Linux 시스템에서는 vmstat 명령을 사용하여 컨텍스트 전환 횟수를 확인할 수 있습니다. 다음은 vmstat를 사용하여 컨텍스트 전환 횟수를 확인하는 예입니다.
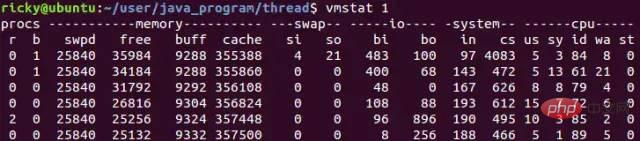 vmstat 1은 초당 한 번 계산한다는 의미입니다. 여기서 cs는 다음과 같습니다. 열은 컨텍스트 전환 수를 나타냅니다. 일반 상황 이 조건에서 유휴 시스템의 컨텍스트 전환은 초당 1500개 미만입니다.
vmstat 1은 초당 한 번 계산한다는 의미입니다. 여기서 cs는 다음과 같습니다. 열은 컨텍스트 전환 수를 나타냅니다. 일반 상황 이 조건에서 유휴 시스템의 컨텍스트 전환은 초당 1500개 미만입니다.
클라이언트 요청을 병렬로 처리(I/O 멀티플렉싱)
위에서 언급했듯이 Redis의 병목 현상은 CPU가 아니라 주요 병목 현상은 메모리와 네트워크입니다. 소위 메모리 병목 현상은 이해하기 쉽습니다. Redis를 캐시로 사용하는 경우 많은 양의 데이터를 캐시해야 하므로 많은 양의 메모리 공간이 필요합니다. 이는 클러스터 샤딩과 같은 방법으로 해결할 수 있습니다. Redis의 자체 센터리스 클러스터 샤딩 솔루션과 에이전트를 위한 Codis 기반 클러스터 샤딩 방식입니다.
네트워크 병목 현상의 경우 Redis는 네트워크 I/O 모델의 멀티플렉싱 기술을 사용하여 네트워크 병목 현상의 영향을 줄입니다. 많은 시나리오에서 단일 스레드 모델을 사용한다고 해서 프로그램이 작업을 동시에 처리할 수 없다는 의미는 아닙니다. Redis는 단일 스레드 모델을 사용하여 사용자 요청을 처리하지만 I/O 다중화 기술을 사용하여 클라이언트의 여러 연결을 "병렬" 처리하고 동시에 여러 연결에서 보낸 요청을 기다립니다. I/O 멀티플렉싱 기술을 사용하면 시스템 오버헤드가 더 이상 각 연결에 대해 전용 수신 스레드를 생성할 필요가 없어 많은 수의 스레드 생성으로 인한 막대한 성능 오버헤드를 피할 수 있습니다.
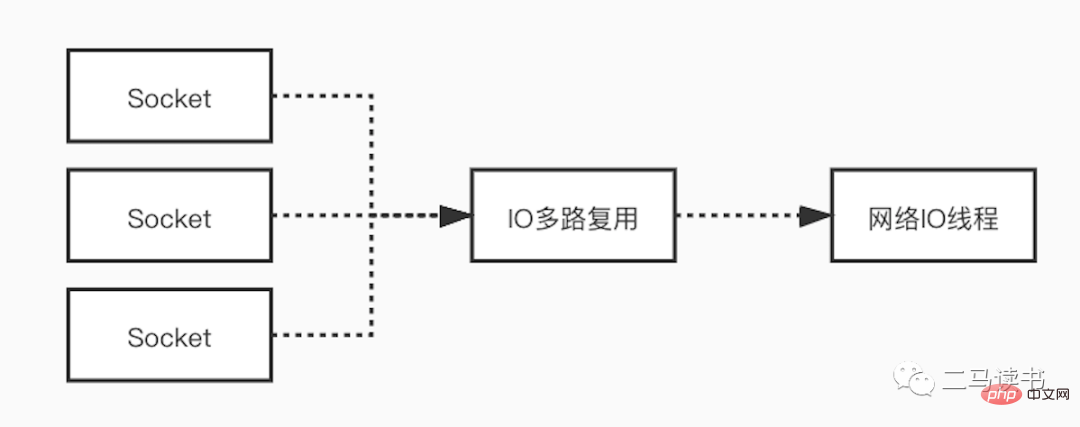
다중화 I/O 모델에 대해 자세히 설명하겠습니다. 더 완벽하게 이해하기 위해 먼저 몇 가지 기본 개념을 이해합니다.
소켓: 소켓은 두 애플리케이션이 네트워크를 통해 통신할 때 두 애플리케이션의 통신 끝점으로 이해될 수 있습니다. 통신 중에 한 응용 프로그램은 소켓에 데이터를 쓴 다음 네트워크 카드를 통해 다른 응용 프로그램의 소켓에 데이터를 보냅니다. 우리가 일반적으로 HTTP 및 TCP 프로토콜이라고 부르는 원격 통신은 최하위 계층의 소켓을 기반으로 구현됩니다. 5가지 네트워크 IO 모델도 모두 소켓 기반 네트워크 통신을 구현합니다.
차단 및 비차단: 소위 차단이란 요청이 즉시 반환될 수 없으며 모든 논리가 처리될 때까지 응답이 반환될 수 없음을 의미합니다. 반면 Non-Blocking은 모든 로직이 처리될 때까지 기다리지 않고 즉시 요청을 보내고 응답을 반환합니다.
커널 공간과 사용자 공간: 리눅스에서는 응용프로그램의 안정성이 운영체제 프로그램에 비해 훨씬 뒤떨어집니다. 운영체제의 안정성을 보장하기 위해 리눅스는 커널 공간과 사용자 공간을 구분합니다. 커널 공간은 운영 체제 프로그램과 드라이버를 실행하고 사용자 공간은 응용 프로그램을 실행하는 것으로 이해될 수 있습니다. 이러한 방식으로 Linux는 운영 체제 프로그램과 응용 프로그램을 격리하여 응용 프로그램이 운영 체제 자체의 안정성에 영향을 미치지 않도록 합니다. 이는 Linux 시스템이 매우 안정적인 이유이기도 합니다. 디스크 파일 읽기 및 쓰기, 메모리 할당 및 재활용, 네트워크 인터페이스 호출 등과 같은 모든 시스템 리소스 작업은 커널 공간에서 수행됩니다. 따라서 네트워크 IO 읽기 과정에서 데이터는 네트워크 카드에서 사용자 공간의 애플리케이션 버퍼로 직접 읽히지 않고 먼저 네트워크 카드에서 커널 공간 버퍼로 복사된 다음 커널에서 사용자 공간으로 복사됩니다. 공간. 네트워크 IO 쓰기 프로세스의 경우 프로세스는 반대입니다. 먼저 사용자 공간의 애플리케이션 버퍼에서 커널 버퍼로 데이터가 복사된 다음 네트워크 카드를 통해 커널 버퍼에서 데이터가 전송됩니다.
다중화 I/O 모델은 다중 채널 이벤트 분리 기능인 select, poll 및 epoll을 기반으로 구축되었습니다. Redis에서 사용하는 epoll을 예로 들면, 읽기 요청을 시작하기 전에 epoll의 소켓 모니터링 목록이 먼저 업데이트된 다음 epoll 함수가 반환될 때까지 기다립니다(이 프로세스는 차단 중이므로 다중화 IO는 본질적으로 차단 IO 모델입니다). . 특정 소켓에서 데이터가 도착하면 epoll 함수가 반환됩니다. 이때 사용자 스레드는 데이터를 읽고 처리하기 위해 공식적으로 읽기 요청을 시작합니다. 이 모드는 전용 모니터링 스레드를 사용하여 여러 소켓을 확인하며, 특정 소켓에 데이터가 도착하면 처리를 위해 작업자 스레드로 전달됩니다. Socket 데이터가 도착하기를 기다리는 과정은 매우 시간이 많이 걸리기 때문에 Blocking IO 모델에서 하나의 Socket 연결에 하나의 스레드가 필요한 문제를 해결하고 Non 모드에서는 바쁜 폴링으로 인한 CPU 성능 손실 문제가 없습니다. -IO 모델 차단. 다중화된 IO 모델에 대한 실제 애플리케이션 시나리오는 많이 있습니다. 친숙한 Redis, Java NIO 및 Dubbo에서 사용하는 통신 프레임워크인 Netty는 모두 이 모델을 채택합니다.
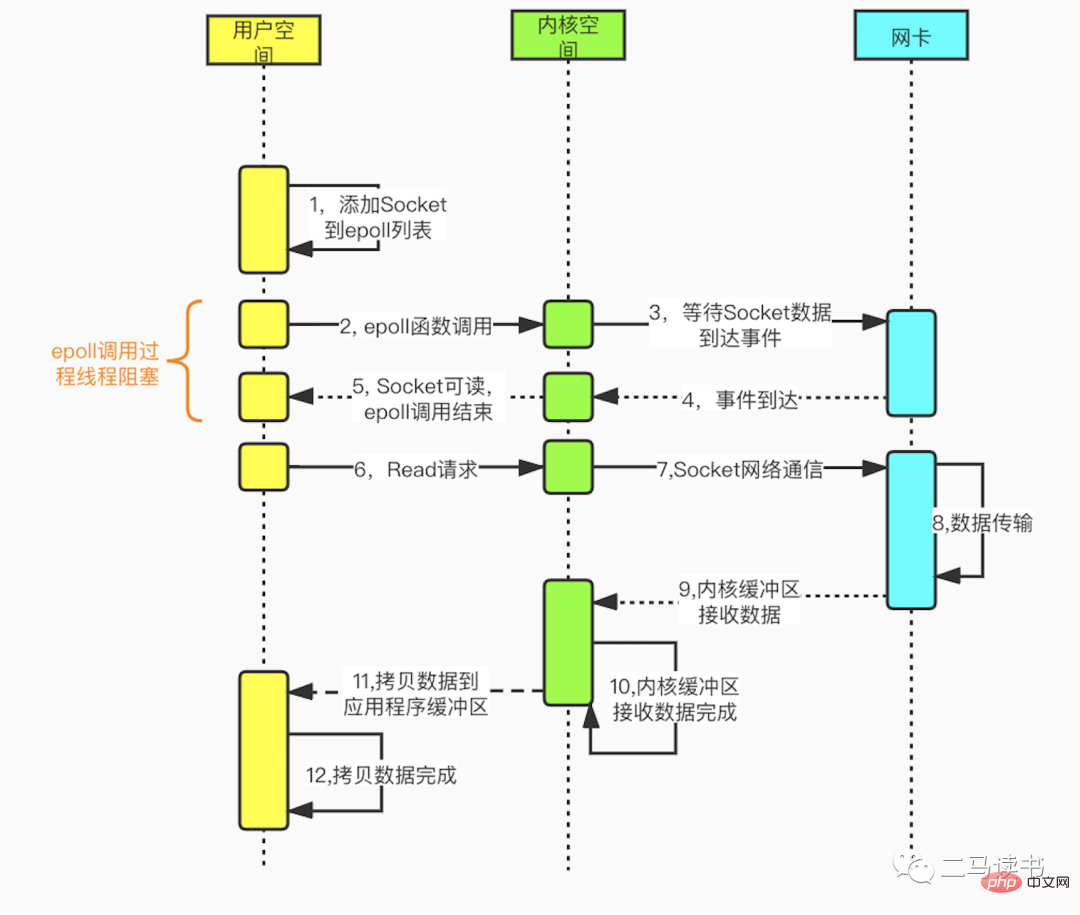
다음 그림은 epoll 기능을 기반으로 한 소켓 프로그래밍의 세부 과정이다.
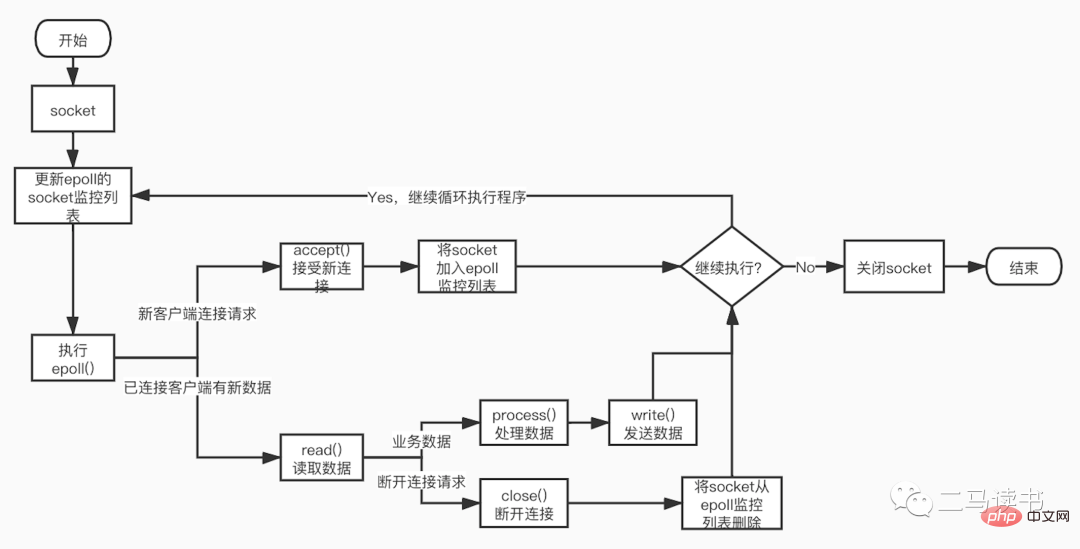
유지 관리 가능성
우리는 멀티 스레딩이 멀티 코어 CPU를 최대한 활용할 수 있다는 것을 알고 있습니다. 동시성 시나리오에서는 I/O 대기로 인한 CPU 손실을 줄이고 좋은 성능을 가져올 수 있습니다. . 그러나 멀티스레딩은 양날의 검이지만 코드 유지 관리의 어려움, 온라인 문제 찾기 및 디버깅의 어려움, 교착 상태 및 기타 문제도 발생합니다. 멀티스레딩 모델의 코드 실행 프로세스는 더 이상 직렬적이지 않으며 여러 스레드가 동시에 액세스하는 공유 변수도 제대로 처리되지 않으면 이상한 문제를 일으킬 수 있습니다.
멀티 스레드 시나리오에서 발생하는 이상한 현상을 예제를 통해 살펴보겠습니다. 아래 코드를 보세요.
class MemoryReordering {
int num = 0;
boolean flag = false;
public void set() {
num = 1; //语句1
flag = true; //语句2
}
public int cal() {
if( flag == true) { //语句3
return num + num; //语句4
}
return -1;
}
}flag가 true일 때 cal() 메서드의 반환 값은 무엇입니까? 많은 사람들이 이렇게 말할 것입니다. 물어볼 필요가 있나요? 2
结果可能会让你大吃一惊!上面的这段代码,由于语句1和语句2没有数据依赖性,可能会发生指令重排序,有可能编译器会把flag=true放到num=1的前面。此时set和cal方法分别在不同线程中执行,没有先后关系。cal方法,只要flag为true,就会进入if的代码块执行相加的操作。可能的顺序是:
语句1先于语句2执行,这时的执行顺序可能是:语句1->语句2->语句3->语句4。执行语句4前,num = 1,所以cal的返回值是2
语句2先于语句1执行,这时的执行顺序可能是:语句2->语句3->语句4->语句1。执行语句4前,num = 0,所以cal的返回值是0
我们可以看到,在多线程环境下如果发生了指令重排序,会对结果造成严重影响。
当然可以在第三行处,给flag加上关键字volatile来避免指令重排。即在flag处加上了内存栅栏,来阻隔flag(栅栏)前后的代码的重排序。当然多线程还会带来可见性问题,死锁问题以及共享资源安全等问题。
boolean volatile flag = false;
Redis6.0为何引入多线程?
Redis6.0引入的多线程部分,实际上只是用来处理网络数据的读写和协议解析,执行命令仍然是单一工作线程。
从上图我们可以看到Redis在处理网络数据时,调用epoll的过程是阻塞的,也就是说这个过程会阻塞线程,如果并发量很高,达到几万的QPS,此处可能会成为瓶颈。一般我们遇到此类网络IO瓶颈的问题,可以增加线程数来解决。开启多线程除了可以减少由于网络I/O等待造成的影响,还可以充分利用CPU的多核优势。Redis6.0也不例外,在此处增加了多线程来处理网络数据,以此来提高Redis的吞吐量。当然相关的命令处理还是单线程运行,不存在多线程下并发访问带来的种种问题。
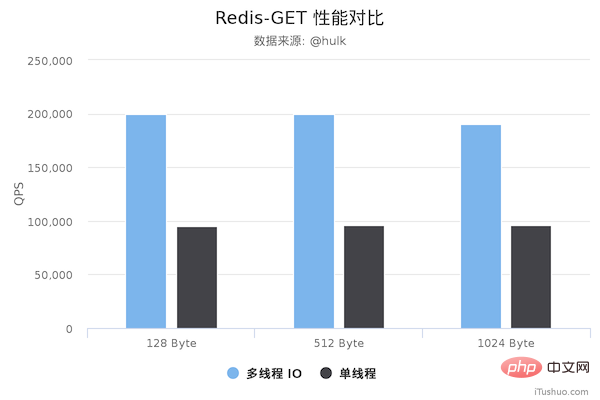
性能对比
压测配置:
Redis Server: 阿里云 Ubuntu 18.04,8 CPU 2.5 GHZ, 8G 内存,主机型号 ecs.ic5.2xlarge Redis Benchmark Client: 阿里云 Ubuntu 18.04,8 2.5 GHZ CPU, 8G 内存,主机型号 ecs.ic5.2xlarge
多线程版本Redis 6.0,单线程版本是 Redis 5.0.5。多线程版本需要新增以下配置:
io-threads 4 # 开启 4 个 IO 线程 io-threads-do-reads yes # 请求解析也是用 IO 线程
压测命令: redis-benchmark -h 192.168.0.49 -a foobared -t set,get -n 1000000 -r 100000000 --threads 4 -d ${datasize} -c 256
图片来源于网络 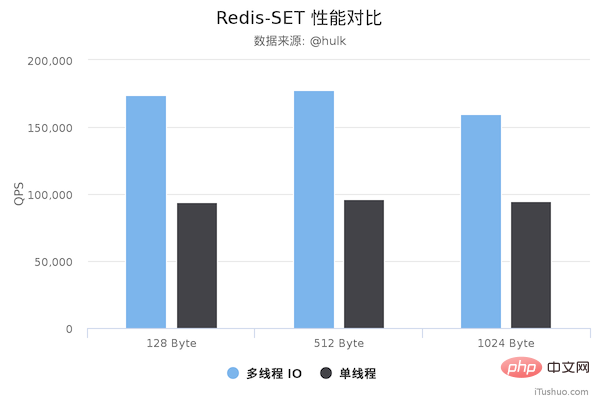
图片来源于网络
从上面可以看到 GET/SET 命令在多线程版本中性能相比单线程几乎翻了一倍。另外,这些数据只是为了简单验证多线程 I/O 是否真正带来性能优化,并没有针对具体的场景进行压测,数据仅供参考。本次性能测试基于 unstble 分支,不排除后续发布的正式版本的性能会更好。
最后
可见单线程有单线程的好处,多线程有多线程的优势,只有充分理解其中的本质原理,才能灵活运用于生产实践当中。
위 내용은 Redis6.0에서 멀티스레딩을 도입하는 이유는 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7530
7530
 15
1379
52
82
11
54
19
21
76
15
1379
52
82
11
54
19
21
76

 Redis 클러스터에서 Shard Key를 어떻게 선택합니까?
Mar 17, 2025 pm 06:55 PM
Redis 클러스터에서 Shard Key를 어떻게 선택합니까?
Mar 17, 2025 pm 06:55 PM
이 기사에서는 Redis 클러스터에서 샤드 키 선택에 대해 논의하여 성능, 확장 성 및 데이터 배포에 미치는 영향을 강조합니다. 주요 문제는 데이터 배포 고도 보장, 액세스 패턴에 맞추기, 일반적인 실수를 피하는 것이 포함됩니다.
 Redis에서 인증 및 승인을 어떻게 구현합니까?
Mar 17, 2025 pm 06:57 PM
Redis에서 인증 및 승인을 어떻게 구현합니까?
Mar 17, 2025 pm 06:57 PM
이 기사는 Redis에서 인증 및 승인 구현, 인증 활성화, ACL 사용 및 Redis 보안을위한 모범 사례에 중점을 두는 것에 대해 논의합니다. 또한 Redis 보안을 향상시키기위한 사용자 권한 관리 및 도구를 다룹니다.
 작업 대기열 및 배경 처리에 Redis를 어떻게 사용합니까?
Mar 17, 2025 pm 06:51 PM
작업 대기열 및 배경 처리에 Redis를 어떻게 사용합니까?
Mar 17, 2025 pm 06:51 PM
이 기사에서는 작업 대기열 및 배경 처리에 Redis 사용, 설정 설정, 작업 정의 및 실행에 대해 설명합니다. 원자 운영 및 작업 우선 순위와 같은 모범 사례를 다루고 Redis가 처리 효율성을 향상시키는 방법을 설명합니다.
 Redis에서 캐시 무효 전략을 어떻게 구현합니까?
Mar 17, 2025 pm 06:46 PM
Redis에서 캐시 무효 전략을 어떻게 구현합니까?
Mar 17, 2025 pm 06:46 PM
이 기사는 시간 기반 만료, 이벤트 중심 방법 및 버전 관리를 포함하여 REDIS에서 캐시 무효화를 구현하고 관리하기위한 전략에 대해 설명합니다. 또한 캐시 만료를위한 모범 사례와 모니터링 및 자동 매트를위한 도구도 다룹니다.
 Redis 클러스터의 성능을 어떻게 모니터링합니까?
Mar 17, 2025 pm 06:56 PM
Redis 클러스터의 성능을 어떻게 모니터링합니까?
Mar 17, 2025 pm 06:56 PM
기사는 Redis CLI, Redis Insight 및 Datadog 및 Prometheus와 같은 타사 솔루션과 같은 도구를 사용하여 Redis 클러스터 성능 및 건강 모니터링에 대해 논의합니다.
 Pub/Sub 메시징에 Redis를 어떻게 사용합니까?
Mar 17, 2025 pm 06:48 PM
Pub/Sub 메시징에 Redis를 어떻게 사용합니까?
Mar 17, 2025 pm 06:48 PM
이 기사는 펍/서브 메시징에 Redis를 사용하는 방법, 설정, 모범 사례, 메시지 신뢰성 보장 및 성능 모니터링 방법을 설명합니다.
 웹 응용 프로그램에서 세션 관리에 Redis를 어떻게 사용합니까?
Mar 17, 2025 pm 06:47 PM
웹 응용 프로그램에서 세션 관리에 Redis를 어떻게 사용합니까?
Mar 17, 2025 pm 06:47 PM
이 기사에서는 웹 응용 프로그램에서 세션 관리에 Redis를 사용하고 설정 세부 설정, 확장 성 및 성능과 같은 이점 및 보안 측정에 대해 설명합니다.
 일반적인 취약점에 대해 Redis를 어떻게 보호합니까?
Mar 17, 2025 pm 06:57 PM
일반적인 취약점에 대해 Redis를 어떻게 보호합니까?
Mar 17, 2025 pm 06:57 PM
기사는 REDIS가 취약성에 대한 보안, 강력한 비밀번호, 네트워크 바인딩, 명령 장애, 인증, 암호화, 업데이트 및 모니터링에 중점을 둔 것에 대해 논의합니다.
